篇一 :hadoop认识总结
一、对hadoop的基本认识 Hadoop是一个分布式系统基础技术框架,由Apache基金会所开发。利用hadoop,软件开发用户可以在不了解分布式底层细节的情况下,开发分布式程序,从而达到充分利用集群的威力高速运算和存储的目的。
Hadoop是根据google的三大论文作为基础而研发的,google的三大论文分别是:MapReduce、GFS和BigTable。因此,hadoop也因此被称为是
google技术的山寨版。不过这种“山寨版”却成了当下大数据处理技术的国际标准(因为它是世界上唯一一个做得相对完善而又开源的框架)。
Hadoop框架中最核心的设计就是:MapReduce和HDFS。MapReduce的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释
MapReduce就是“任务的分解与结果的汇总”。HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。
MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。这不是什么新思想,其实它的本质就是一种“分治法”的思想,把一个巨大的任务分割成许许多多的小任务单元,最后再将每个小任务单元的结果汇总,并求得最终结果。在分布式系统中,机器集群就可以看作硬件资源池,将并行的任务拆分,然后交由每一个空闲机器资源去处理,能够极大地提高计算效率,同时这种资源无关性,对于计算集群的扩展无疑提供了最好的设计保证。任务分解处理以后,那就需要将处理以后的结果再汇总起来,这就是Reduce要做的工作。
…… …… 余下全文
篇二 :Hadoop学习总结
Hadoop学习总结
一、 背景
随着信息时代脚步的加快,各类数据信息越来越多,海量数据的来源列举如下:
◎纽约证券交易所每天产生1TB的交易数据。
◎Facebook存储着约100亿张照片,约1PB数据。
◎Ancestry.com,一个家谱网站,存储着2.5PB数据。
◎The Internet Archive(互联网档案馆)存储着约2PB的数据,并以每月至少20TB的速度增长。
◎瑞士日内瓦附近的大型强子对撞机每年产生约15PB数据。
面对海量数据,如何存储和分析,从中获取有价值信息,变得十分重要。Hadoop正是在这样的背景下产生的,它提供了一个可靠的共享存储和分析系统。由于具备低成本和前所未有的高扩展性,Hadoop已被公认为是新一代的大数据处理平台,就像30年前的SQL出现一样,Hadoop正带来了新一轮的数据革命。
二、Hadoop相关概念
1、Hadoop简述
Hadoop是Apache的一个分布式计算开源框架,它可以运行于大中型集群的廉价硬件设备上,为应用程序提供了一组稳定可靠的接口。同时它是Google集群系统的一个开源项目总称。底层是Google文件系统(GFS)。
…… …… 余下全文
篇三 :hadoop总结
Hadoop
概念:
Hadoop是一个能够对大量数据进行分布式处理的软件框架!
Hadoop的特点:
1.可靠性(Reliable):hadoop能自动地维护数据的多份副本,并且在任务失败后能自动地重新部署(redeploy)计算任务。
2.高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行的(parallel)处理它们,这使得处理非常的快速。
3.扩容能力(Scalable):能可靠的(reliably)存储和处理千兆字节(PB)数据。 4.成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
{简单来说: 1.可靠性 (体现在它维护多个工作数据的副本,确保节点宕掉了重新进行分布式处理)
2.高效性(体现在它通过并行(计算机同时执2个或者多个处理机的一种计算方法)的方式处理数据,从而加快了数据处理速度)
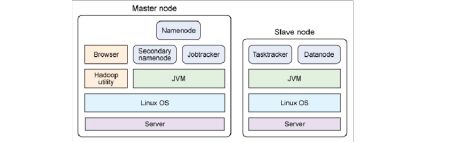
3.可伸缩性(能处理PB级别的数据量)
4.廉价性 (它使用了社区服务器,因此它的成本很低,任何人都可以去用)
}
它实现了一个分布式文件系统,简称之为HDFS
…… …… 余下全文
篇四 :hadoop原理_自己的总结
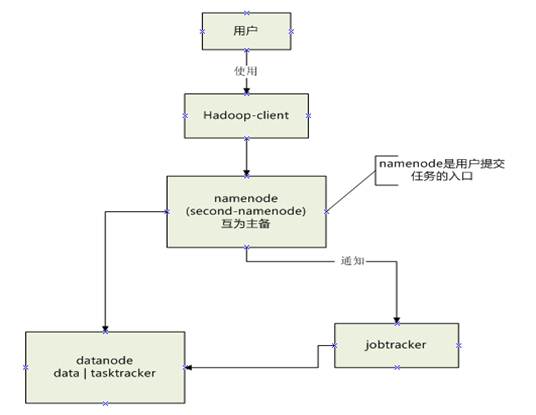
用户提交给hadoop client的command,指定了输入路径,输出路径,如下所示:
cmd="${HADOOP_HOME}/bin/hadoop bistreaming \
-input ${LINK_PATH}/part-* \
-input ${PATCH_PATH}/* \
-output ${UNI_PATH} \
-inputformat org.apache.hadoop.mapred.SequenceFileAsBinaryInputFormat \
-outputformat org.apache.hadoop.mapred.SequenceFileAsBinaryOutputFormat \
…… …… 余下全文
篇五 :最新hadoop应用总结
Hadoop 应用总结
一、 系统配置
1. 安装linux ubuntu系统
2. 安装开启openssh-server:$ sudo apt-get install openssh-server
3. 建立ssh 无密码登录
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
直接回车,完成后会在~/.ssh/生成两个文件:id_dsa 和id_dsa.pub。
这两个是成对出现,类似钥匙和锁。再把id_dsa.pub 追加到授权key 里面(当前并没有authorized_keys文件):
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys。
完成后可以实现无密码登录本机:$ ssh localhost。
4. 关闭防火墙 $ sudo ufw disable
5. 安装jdk 1.6
6. 安装后,添加如下语句到/etc/profile 中:
export JAVA_HOME=/home/Java/jdk1.6
export JRE_HOME=/home/Java/jdk1.6/jre
…… …… 余下全文
篇六 :hadoop常见启动问题总结
Hadoop 节点问题总结 1. hadoop主节点意外关机重启后hadoop不能启动.
Hadoop namenode由于某些原因关机重启,重新启动后hadoop服务不能正常启动. 每次开机都得重新格式化一下namenode才可以.其实问题就出在tmp文件,默认的tmp文件每次重新开机会被清空,与此同时namenode的格式化信息就会丢失于是我们得重新配置一个tmp文件目录.
首先在home目录下建立一个Hadoop_tmp目录:sudo mkdir ~/hadoop_tmp 接着修改core-site.xml文件:
gedit /home/user/hadoop-x.x.x/conf/core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/home/user/hadoop_tmp</value>
<description>A base for other temporary directories.</description> </property>
…… …… 余下全文
篇七 :Hadoop搭建总结
Hadoop之集群搭建总结
Summershyn夏超俊
这是个人在参照网上一下文章,自己尝试搭建,并碰到一些困难和问题,最后终于成功之后的总结,希望可以对你有点帮助。
有三台机子
192.168.1.101 master
192.168.1.102 slave1
192.168.1.103 slave2
1. SSH:ubuntu server 版安装时可选择安装OpenSSH(若没装,则可以sudo apt-get install openssh)
2. JDK:虽然ubuntu有openjdk,但是还是感觉sun的好一些。把jdk-()-.bin拷到ubuntu下,例如放/home/ubuntu/下,命令:chmod 777 jdk-().bin赋予可执行权限。然后运行。等待….
安装完之后配置环境变量:向/etc/encironment文件中添加
JAVA_HOME=”/home/ubuntu/jdk1.6.0_27(视版本而定)”
PATH=“……….:$JAVA_HOME/bin”
CLASS_HOME=”$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar”(好像可不填) 配置环境变量得重启生效
…… …… 余下全文
篇八 :hadoop学习心得
1.FileInputFormat splits only large files. Here “large” means larger than an HDFS block. The split size is normally the size of an HDFS block, which is appropriate for most applications; however,it is possible to control this value by setting various Hadoop properties.
2.So the split size is blockSize.
3.Making the minimum split size greater than the block size increases the split size, but at the cost of locality.
4.One reason for this is that FileInputFormat generates splits in such a way that each split is all or part of a single file. If the file is very small (“small” means significantly smaller than an HDFS block) and there are a lot of them, then each map task will process very little input, and there will be a lot of them (one per file), each of which imposes extra bookkeeping overhead.
…… …… 余下全文