上机实验报告
编译原理报告
----正规式转化为NFA

班级:191131班
学号:20131002284
姓名:李豪强
指导老师:刘远兴
日期:20##/10/20
前期准备
摘要
题目:正规表达式→NFA 问题
实习时间:20##/10/12
【问题描述】
正规表达式→NFA问题的一种描述是:
编写一个程序,输入一个正规表达式,输出与该文法等价的有限自动机。
【基本要求】
①掌握有限自动机、正规表达式、正规文法之间的转换算法,有些可帮助掌握有限自动机的确定化与最小化,还有些可帮助理解整个词法分析器的构造过程。
②以班为单位,每个班内3-5人为一组,自由组合。选一人为组长,要适当分工,要分工明确。
③需上交:源程序,实验报告。实验报告要交电子档报告,重点写自己那部分的设计思路和实现方法。
分工:
我们小组具体分工如下:
陈 渊:负责总体规划,以及系统整合
李豪强:负责整个程序架构的设计及软件测试;
蔡 路:负责伪代码(核心算法)的实现;
李 涛,陈 渊:负责输入输出处理及用户界面设计
祝莹倩,樊润宇:数据结构的分析处理 ;
1.需求分析
(1)首先要获取用户需要转化的正规式;
(2)然后判断用户输入的正确与否,并予以提示;
(3)运用正规式转化NFA的算法思想进行词法分析
(4)设置初始状态X,终态Y,过程态用数字表示:0 1 2 3………
测试数据:abb
输出结果应为:X X-a->0
Y
0 0-b->1
1 1-b->Y
测试数据:(a|b)*abb
输出结果应为:X X - ~ ->3
Y
0 0-a->1
1 1-b->2
2 2-b->Y
3 3- ~ ->0 3-a->3 3-b->3
2.设计
2.1总体设计
2.1.1设计思想
(1)数据结构
*** 该部分由小组成员樊润宇和祝莹倩同学共同完成 ***
2.2模块设计(重点)
程序架构的设计:
此次实验的要求是将一个输入的任意合法正规式转换为相应的不确定的有穷自动机(NFA),由教材上所提出的方法可知,在构造有穷自动机的时候,第一步应先将正规式分解为可以直接转换为NFA的正规式,然后将所有的状态经过条件连接得到最终的NFA。所以应设计函数将正规式分解,然后由转换函数得出NFA。
(1) 过程或函数调用关系图(流程图)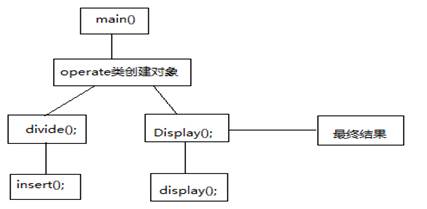
2.3函数的功能实现(解释所写函数的作用,写函数的声明原型及其注释。)
void divide(string s, vector <Node*> *N, int begin, int end);//用于将正规式细化
void insert(string s, vector <Node*> *N, int head, int tail, char state[]);//将细化后的正规式转
//化为应的NFA状态并将其转换条件一起存储到N中
void Display(vector <Node*> N);//输出NFA
void display();//输出当前状态以及条件和经此条件所能到达的状态
2.4 算法设计
从正则表达式到NFA的转换方法(核心算法):
**** 该部分由小组成员蔡路同学完成 ***
3.使用手册
(1)数据输入:
在输入时对于任何符号都从左到右直接输入(例:不必对于*进行特别的输入处
理,直接按键输入即可)
(1)功能键用法:
“请输入正规式:”后的文本框用于用户输入正规式
“转化结果:”后的文本框由于新显示正规式对应的NFA
“转化”按钮用于执行将输入文本框中的正规式转化为NFA并在输出文本框中输
出结果
“关闭”按钮用于关闭对话框。
4.测试结果
测试数据:abb
输出结果应为:X X-a->0
Y
0 0-b->1
1 1-b->Y
屏幕截图:

测试数据:(a|b)*abb
输出结果应为:X X - ~ ->3
Y
0 0-a->1
1 1-b->2
2 2-b->Y
3 3- ~ ->0 3-a->3 3-b->3
屏幕截图:

5.总结
首先,这次上机实验增强了我们团队合作能力,我们小组成员在一起商讨设计思路之后,由组长安排每个人的任务,然后每人完成自己的任务后交由组长整理整合,在这个过程中每人都要参与商讨确定每部分内容应安排在哪部分,这不仅增强了我们的团队合作能力更加深了彼此之间的友情。另外,在此次上机实习中我相信我们都对正规式到NFA的转换有了更加深刻的理解,例如,在转换时可以对正规式有两种处理,一是将正规式从左到右扫描进行类似计算器的操作将正规式转换为后缀式,然后对‘或’、‘连接’和‘闭包’进行操作定义进行转换;二是将正规式分解为可直接转换为NFA的诸多分解正规式,即此次实习中所说的细化操作,然后再讲每个NFA经条件连接得到最后结果。相信再遇到此类问题大家都可以较为快速的解决。
第二篇:统计上机实验报告
统计学实验报告
姓名: 学号:班级:成绩:
一、实验步骤总结 成绩:
实验一 数据的搜集与整理
(一)数据的搜集:
1.间接数据的搜集
间接统计数据主要是公开出版或报道的数据,可以通过年鉴、期刊、报纸、广播、电视等途径搜集获取。在网络广泛普及的今天,通过网络搜集间接数据已经成为了一种主流手段。一般,在网络上搜集数据可以采用两种方式。
一种方式是直接进入网站查询数据。
第二种通过网络获取二手数据的方式是使用搜索引擎。
2.直接数据的搜集
直接统计数据可以通过两种途径获得:一是统计调查或观察,二是实验。统计调查是取得社会经济数据的最主要来源,它主要包括普查、重点调查、典型调查、抽样调查、统计报表等调查方式。抽样调查的步骤如图1所示:
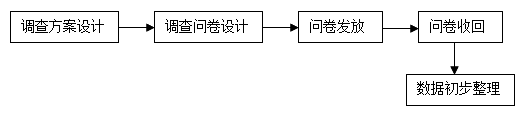
图1
(二)数据的整理
(1)数据的编码(2)数据的录入(3)数据文件的导入(4)数据的筛选(5)数据的排序(6)数据的分组(7)数据文件的保存
实验二 描述数据的图表方法
(一)Frequency函数
用途:以一列垂直数组返回某个区域中数据的频率分布。它可以计算出在给定的值域和接收区间内,每个区间包含的数据个数。
语法:FREQUENCY(data_array,bins_array)
(二)直方图分析工具
“工具”——“数据分析”——“直方图”
实验三 统计数据的描述
(一)使用函数描述
“插入”—“函数”
(二) “描述统计”工具
“工具”——“数据分析”——“描述统计”
实验四 参数估计
(一)抽样
工具-数据分析-抽样
“抽样”分析工具将输入区域视为总体,并使用总体来建立样本。当总体过大而无法处理或制成图表时,就可以使用代表样本。如果输入数据是周期性的,也可以建立只包含某个周期特定部分数值的样本。例如.若输入区域包含了每季的销售量,就可以在输入区域的同一季4个地点数值中以周期性比率来抽样。
(二)参数估计
1)点估计
点估计是依据样本估计总体分布中所含的未知参数或未知参数的函数。通常它们是总体的某个特征值,如数学期望、方差和相关系数等。点估计问题就是要构造一个只依赖于样本的量,作为未知参数或未知参数的函数的估计值。例如,设一批产品的废品率为θ。为估计θ,从这批产品中随机地抽出n个作检查,以X记其中的废品个数,用X/n估计θ,这就是一个点估计。
2)区间估计
区间估计是依据抽取的样本,根据一定的正确度与精确度的要求,构造出适当的区间,作为总体分布的未知参数或参数的函数的真值所在范围的估计。例如人们常说的有百分之多少的把握保证某值在某个范围内,即是区间估计的最简单的应用。
实验五 假设检验
(一)假设检验的函数表单
函数表单构建的基本思路是:
1.确定需进行假设检验的总体参数
2.确定抽样样本统计量及其服从的分布
3.进行假设设计(单侧,双侧)
4.确定置信水平
5.计算检验统计量
6.计算置信水平下的检验区间(或检验临界值)
7.比较检验统计量与检验区间(或检验临界值) ,得出结论
(二)分析工具库
1. F-检验:双样本方差
该工具通过双样本的F检验,对两个样本的方差进行比较。用于说明两个样本的方差是否存在显著差异。
2.t-检验: 双样本等方差假设
该工具是在一定置信水平之下,在两个总体方差相等的假设之下,检验两个总体均值的差值等于指定平均差的假设是否成立的检验。
3.t-检验:双样本异方差假设
该分析工具可以进行双样本t-检验,与双样本等方差假设检验不同,该检验是在两个数据集的方差不等的前提假设之下进行两总体均值差额的检验,故也称作异方差t-检验。可以使用t-检验来确定两个样本均值实际上是否相等。当进行分析的样本个数不同时,可使用此检验。如果某一样本组在某次处理前后都进行了检验,则应使用“成对检验”。
4. t-检验:成对双样本均值分析
该分析工具可以进行成对双样本t-检验,用来确定样本均值是否不等。此t-检验并不假设两个总体的方差是相等的。当样本中出现自然配对的观察值时,可以使用此成对检验,例如,对一个样本组进行了两次检验,抽取实验前的一次和实验后的一次。
5. Z-检验:双样本均值分析
该分析工具可以进行方差已知的双样本均值z-检验。此工具用于检验两个总体均值之间存在差异的假设。例如,可以使用此检验来确定两种汽车模型性能之间的差异情况。
实验六 方差分析
(一)单因素方差分析
单因素方差分析表

结论判断:
(1)由方差分析表中的统计量F与F临界值比较。前者大则说明分类自变量对数值型因变量具有显著影响;反之,则说明分类自变量对数值型因变量影响不显著。
(2)由P值和给定的显著性系数α比较。前者小则说明分类自变量对数值型因变量具有显著影响;反之,则说明分类自变量对数值型因变量影响不显著。
(二)无重复双因素方差分析
无重复双因素方差分析表
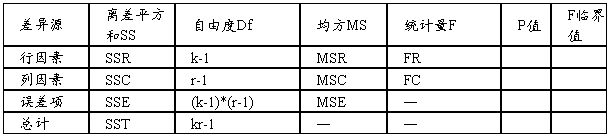
结论判断:
(1)由方差分析表中的统计量F与F临界值比较。前者大则说明分类自变量对数值型因变量具有显著影响;反之,则说明分类自变量对数值型因变量影响不显著。
(2)由P值和给定的显著性系数α比较。前者小则说明分类自变量对数值型因变量具有显著影响;反之,则说明分类自变量对数值型因变量影响不显著。
(三)可重复双因素方差分析
可重复双因素方差分析表

结论判断:
(1)由方差分析表中的统计量F与F临界值比较。前者大则说明分类自变量对数值型因变量具有显著影响;反之,则说明分类自变量对数值型因变量影响不显著。
(2)由P值和给定的显著性系数α比较。前者小则说明分类自变量对数值型因变量具有显著影响;反之,则说明分类自变量对数值型因变量影响不显著。
实验七 相关与回归
(一)利用函数Correl计算相关系数
语法:CORREL(array1,array2)
作用:返回单元格区域 array1 和 array2 之间的相关系数。使用相关系数可以确定两种属性之间的关系。例如,可以检测某地的平均温度和空调使用情况之间的关系。
(二)“相关系数”分析工具
(三)回归分析的函数方法

实验八 时间序列
测定增长量和平均增长量:利用Excel的拖拉权柄计算逐期增长量、累计增长量和平均增长量。 注意相对地址和绝对地址的使用
测定发展速度和平均发展速度:利用Excel的拖拉权柄计算定基发展速度、环比发展速度和平均发展速度。注意相对地址和绝对地址的使用
计算长期趋势:利用Excel的拖拉权计算移动平均值,辅助作图反应结果。
计算季节变动:剔除季节变动后的趋势状态
用移动平均法进行预测和用指数平滑法进行预测
趋势预测法进行预测:(1)Forecast函数(2)Trend函数
二、实验心得报告 成绩:
(一)心得体会
《统计学》是一门收集,整理,显示和分析统计数据,研究统计方式方法论的学科,它与实践是紧密结合的。
在几次的统计学实验学习中,通过实验操作可使我们加深对理论知识的理解,学习和掌握统计学的基本方法,并能进一步熟悉和掌握EXCEL的操作方法,培养我们分析和解决实际问题的基本技能,提高我们的综合素质。下面是我这几次实验的一些心得和体会。
实验过程中,首先就是对统计数据的输入与分析了。按Excel对输入数据的要求将数据正确输入的过程并不轻松,既要细心又要用心。不仅仅是仔细的输入一组数据就可以,还要考虑到整个数据模型的要求,合理而正确的分配和输入数据,有时候分成的行列数不同也会影响到实验的结果。因此,输入正确的数据也就成为了整个统计实验的基础。
数据的输入固然重要,但如果没有分析的数据则是一点意义都没有。因此,统计数据的描述与分析也就成了关键的关键。对统计数据的众数,中位数,均值的描述可以让我们对其有一个初步的印象和大体的了解,在此基础上的概率分析,抽样分析,方差分析等则更具体和深刻的向我们揭示了统计数据的内在规律性。每一个操作命令都包含了我们所学的基础知识。在对数据进行描述和分析的过程中,Excel软件的数据处理功能得到了极大的发挥,工具栏中的工具和数据功能对数据的处理使问题解决起来事半功倍。
通过实验过程的进行,对统计学的有关知识点的复习也与之同步。在将课本知识与实验过程相结合的过程中,实验步骤的操作也变的得心应手。也给了我们一个启发,在实验前应该先将所涉内容梳理一遍,带着问题和知识点去做实验可以让我们的实验过程不那么枯燥无味。同时在实验的同步中亦可以反馈自己的知识薄弱环节,实现自己的全面提高。
通过这几次的实验,不仅仅是掌握操作步骤完成实验任务而已,更重要的是在实验中验证自己的所学知识的掌握和运用。统计学的学习就是对数据的学习,而通过实验可以加强我们对统计数据的认知和运用,更好的学习统计学的知识。虽然实验时间很短暂,但对统计知识掌握的要求并没有因时间的短暂而减少,相反我们更得努力掌握和运用统计学的新知识,提高自己的数据分析和处理能力。
统计在现代化管理和社会生活中的地位日益重要。随着社会、经济和科学技术的发展,统计在现代化国家管理和企业管理中的地位,在社会生活中的地位,越来越重要了,统计学广泛吸收和融合相关学科的新理论,不断开发应用新技术和新方法,深化和丰富了统计学传统领域的理论与方法,并拓展了新的领域。今天的统计学已展现出强有力的生命力。。人们的日常生活和一切社会生活都离不开统计。英国统计学家哈斯利特说:“统计方法的应用是这样普遍,在我们的生活和习惯中,统计的影响是这样巨大,以致统计的重要性无论怎样强调也不过分。”甚至有的科学有还把我们的时代叫做“统计时代”。显而易见,可以说统计学已经融入了我们的生活中,因此,学好统计学以及能流利应用Excel进行实际统计操作对我们来说变得至关重要。
以上就是我这几次实验的一些心得体会。
已知1996-2003 年我国一、二、三产业的GDP 如表1。试根据这些数据计算
各产业的产值比重。
表1 1996-2003 年我国一、二、三产业的GDP(亿元)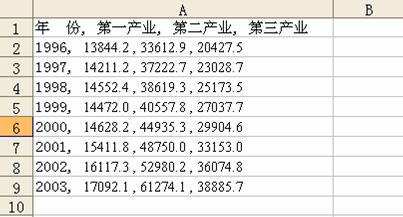
在Excel 中可以按照如下方法计算。首先计算各年的GDP,等于各年一、二、三产业的
GDP 之和。在E2 中输入一个等号,编辑栏下面的“名称”框将变成“函数”框,如图2
所示。单击“函数”按钮右侧的下拉箭头,打开函数列表框,从中选择所需的函数(SUM),
Excel 将打开"公式选项对话框"(图3)。将求和函数的参数改为B2:D2(通过点击折叠按
钮选择相应的区域来实现),单击"确定"按钮即可完成函数的输入,得到1996 年的GDP。
然后利用Excel 的自动填充功能在E3-E9 中复制E2 的公式得到各年的GDP。注意这里各填
充单元格的公式是自动调整的,例如E9 单元格的公式为“=SUM(B9:D9)”。
图2函数选择框
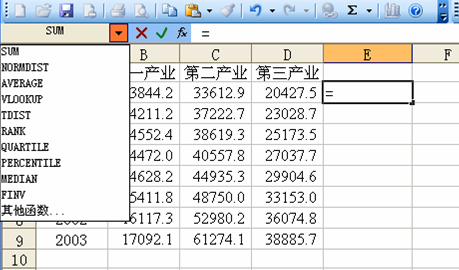
图3 指定函数参数的对话框
要计算第一产业的产出比重,在F2 中输入“=”,然后单击B2 单元格,再输入“/”,
最后点击E2 单元格,回车,就在F2 中输入了公式“=B2/E2”,F2 中显示的是1996 年第一产业的比重。要在G2、H2 中计算第二、多三产业的比重,可以先把F2 的公式先修改为
“=B2/$E2”,然后用自动填充把这个公式复制到G2、H2 单元格。这时G2 中的公式为
“=C2/$E2”。
接下来选中区域F2:H2,把鼠标移至区域的右下角,指针变为黑色实心十字时按住鼠标
左键向下拖动至H9,1997-2003 年的产值比重就计算出来了。
最后,还可以选中区域F2:H9,将数据格式改为百分数。计算结果如表4。
表4 1996-2003 年我国一、二、三产业的产值比重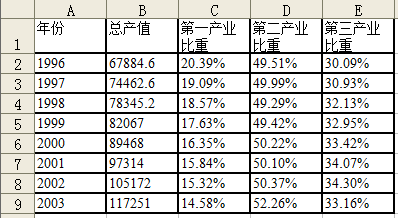
通过excel对数据的处理我们可以明显的得出结论:1996-20##年间,我国第一产业比重明显下降,第二,三产业比重上升,说明我国产业结构逐步趋向合理。
从上个例子中我们可以看出excel在统计学中的应用时非常重要的,它对与我们更方便,快捷的得出统计结论提供l很好的工具。因此,学好统计学以及能流利应用Excel进行实际统计操作对我们来说变得至关重要。
(二)意见和建议:
1、应该通过多种途径,让学生参加实践教学。
2、允许学生选择老师;实行教学质量评估,由学生给老师上课效果进行无记名的评估,促进教风、学风的好转。
3、建议老师多给我们操作的时间,并且督处学生完成。
4、充分运用现代化教育技术手段。在现有实验教室数量有限的条件下,尽可能地采用多媒体教学,计算机软件辅助教学的应用,从而调动了学生学习兴趣和学习动机,提高了教学效果。
-
上机实验报告格式
网页设计实验报告院部热能学院专业热能与动力工程班级112姓名范金仓学号20xx031388一实验目的及要求1确定网站主题和网站的用…
-
计算机上机实验报告模板
交通与汽车工程学院实验报告课程名称课程代码学院直属系交通与汽车工程学院年级专业班学生姓名学号实验总成绩任课教师开课学院交通与汽车工…
-
上机实验报告格式要求
VB上机实验报告要求1预习报告课程名称姓名实验名称班级学号实验日期指导教师一实验目的及要求本次上机实验所涉及并要求掌握的知识点二实…
-
C语言集中上机实验报告
重庆邮电大学移通学院C语言集中上机实验报告学生学号班级专业重庆邮电大学移通学院20xx年5月重庆邮电大学移通学院目录第一章循环31…
-
上机实验报告
编译原理报告编译原理报告正规式转化为NFA班级19xx31班学号20xx1002284姓名李豪强指导老师刘远兴日期20xx1020…
-
ERP上机实验心得体会
工商101320xx610083林冰冰首先感谢王家聚老师再这一学期中对我们的ERP知识传授,你教会我们的绝不仅仅是ERP课程上的知…
-
erp上机实验心得
ERP上机实验心得通过该实验,对所学的知识有了进一步的了解。在实验的过程中,出现了一些问题,不过最后都得以解决。然而通过这些错误,…
-
C语言上机实验心得
在科技高度发展的今天,计算机在人们之中的作用越来越突出。而C语言作为一种计算机的语言,学习它将有助于我们更好的了解计算机,与计算机…
-
电子商务实验心得体会
完成电子商务实验课的心得体会通过这段时间的电子商务实验,我了解到很多关于电子商务的实践知识。伴随着商品经济和网络技术的不断发展,网…
-
java上机实验心得体会报告
北京联合大学信息学院“面向对象程序设计”课程上机实验报告题目:JAVA上机实验心得体会姓名(学号):专业:计算机科学与技术编制时间…
-
电子商务上机实验报告模板
电子商务上机实验报告专业班级:会计0905姓名:郭馨学号:20xx1304220指导教师:叶双林实验日期:20xx.10.15-2…