SPSS上机实验报告
 四川理工学院
四川理工学院
SPSS上机实验报告
课程名称:SPSS统计分析高级教程
专业班级:20##级统计2班
姓 名:雷鹏程
学 号:12071050109
指导教师:林旭东
实验日期: 20##年12月24日
实验名称:主成分分析、因子分析
一、实验案例
现希望根据全国30个省、市、自治区经济发展基本情况的8项指标对其进行分析与排序。具体指标有:GDP、居民消费水平、固定资产投资、职工平均工资、货物周转量、居民消费价格指数、商品零售价格指数、工业生产总值,具体的数据见文件factor1.sav。
二、实验预分析
本案例中的指标较多,所以首先想到的是看看各个指标见的相关系数矩阵,然后对其进行主成分分析。由于还要进行对各个省、市、自治区进行排序,所以利用因子分析计算出各个省、市、自治区综合得分,得到最后的实验结论。
三、实验目的
3.1、掌握利用SPSS进行主成分、因子分析。
3.2、解释运行结果。
3.3、得出最终的实验结论
四、实验操作步骤和结果描述
4.1初步分析:
(1)选择“ ”→“
”→“  ” →“
” →“ ”菜单项。
”菜单项。
(2)将8个指标 ~
~ 选人“
选人“ ”列表框。
”列表框。
(3)在“ ”对话框中选择“
”对话框中选择“ ”,点击“
”,点击“ ”。
”。
(4)点击“ok”。
得到如下表1、2、3:

表1各个指标间的相关系数矩阵
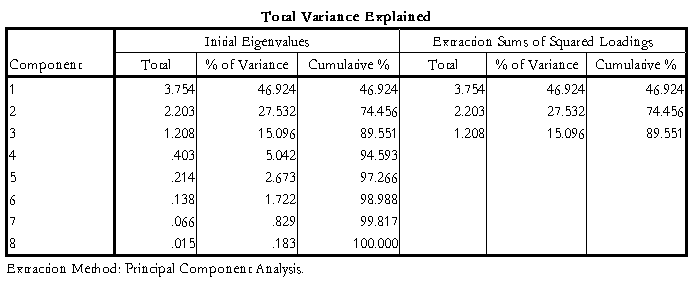
表2解释的总方差
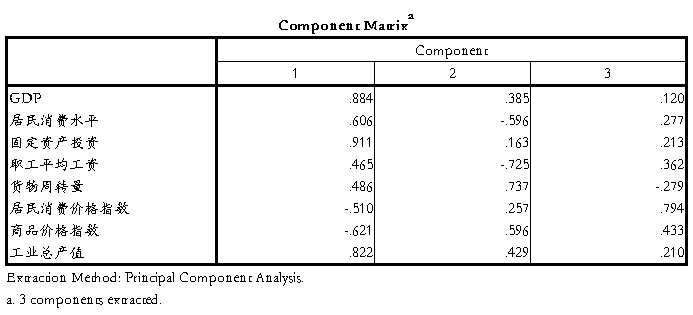
表3主成分矩阵
结果解释:由表1相关系数表可得,可见许多变量之间直接的相关性较强,的确存在信息上的重叠,说明有信息浓缩的必要性。表2可得的是各个成分的方差贡献率和累计贡献率,可见只有前3个主成分的特征根大于1,并且前三个主成分的累计方差贡献率达到89.55%,因此选前三个主成分就能足够描述经济的发展水平。由表3知道第一个主成分主可以看成是反映GDP、固定资产投资、居民消费水平和工业总产值的综合指标,第二个主成分看成是反映平均工资和货物周转量方面的综合指标,第三个主成分看成反映居民消费价格指数的综合指标。显然这个并没有解释出排序结果,所以下面继续进行因子分析后的综合排序。
4.2进阶分析:
(1)在“”对话框中选择“ ”。
”。
(2)在“ ”对话框中选择“
”对话框中选择“ ”。
”。
(3)在“ ”对话框中选择“
”对话框中选择“ ”。
”。
(5)在“ ”对话框中勾选“
”对话框中勾选“ ”。
”。
(6)点击“ok”。
得到下表4、5、6、7:

表4 KMO和Bartlett检验表
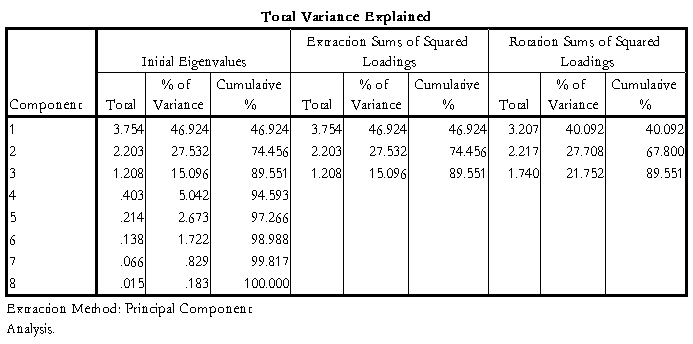
表5解释的总方差表

表6 旋转前成分矩阵

表7 旋转后成分矩阵

图1 碎石图
结果解释:由表4可得KMO的值为0.62,并且Bartlett检验显著,说明可以做因子分析,由表5可得前三个主成分在旋转过后的3个公因子的方差贡献率均发生了变化,彼此的差距有所缩小,但是其方差贡献率仍然是89.55%,表6表7看出在旋转过后主成分更好的表示出来,由碎石图可以得到可以提取前3个主成分。
由于上述3个公因子分别从不同的方面反映当地经济发展状况的总体水平,利用各个因子对应的方差贡献率比例为权数计算出综合得分,计算的方程如下:
Socer=40.09/89.55*FAC1-1+27.71/89.55*FAC2-1+21.75/89.55*FAC3-1
计算出综合因子得分socer,得分前5个地区如下表8所示:

表8 综合排序的前5位地区
可见上海的综合得分最高,其消费因子表现的最为突出,排名第二三是江苏与山东;广东虽然总量因子和消费因子表现不错,但过高物价拉低了综合得分,但四川刚好与广东表现相反。上述的综合比较结果可以很好的解释各个地区的整个经济发展的有点与劣势。
五、 实验总结
本次实验通过对案例预分析后,选定了解决案例的模型,通过在实验中步步对模型的优化与检验,找到了案例的最优的结果,对案例的问题进行了回答与解释。并且在本次SPSS上机实验让我对这门软件有了较深刻的认识,SPSS是一款菜单式的软件,操作简便,易于理,利用将有助于提高工作效率。利用SPSS进行统计分析,变量和数据是必不可少的。数据输入后通常需要对数据进行进一步的处理,其中最有价值的是数据的预处理以及问题预处理。
第二篇:上机实验报告 SPSS数据文件的建立和管理
上机实验报告 SPSS数据文件的建立和管理
班级 行政0902 姓名李静 学号2009012401 网站_WWW.0991LA.COM
一、实验内容
SPSS数据文件的建立、读取其他格式的数据文件等
二、预期目标
1.明确SPSS数据的基本组织方式和数据行列的含义。
2.熟练掌握建立SPSS数据文件以及管理SPSS数据的基本操作。
3.熟练掌握SPSS中读取Excel工作表数据的基本操作,了解读取文本和数据库数据的基本方法。
三、基本概念(教材P46页)
1.SPSS中有哪两种基本的数据组织方式?各自的特点和应用场合是什么?
一是原始数据的组织方式,二是计算数据的组织方式;
在原始数据的组织方式中,数据编辑窗口中的一行称为一个个案,所有个案组成完整的SPSS数据。数据编辑窗口中的一列称为一个变量。每个变量都有一个名字,称为变量名,它是访问和分析SPSS每个变量的唯一标识。该种方式应用于所采集的数据是原始的调查问卷数据这种场合。
在计算组织方式中,数据编辑窗口中的一行为变量的一个分组。所有行囊括了该变量的所有分组情况。数据编辑窗口中的一列仍为一个变量,代表某个问题以及相应的计算结果。该种方式应用于所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的计算数据这种场合。在SPSS中该类数据应按计算数据的组织方式组织。
2.在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?
字母VAR开头,后面不足5位数字;数值型、字符型、日期型; 变量名标签,变量值标签
3.你认为 SPSS数据窗口与Excel工作表在基本操作方式和数据组织方式方面有什么异同?
SPSS的数据直观地显示在数据编辑窗口中,形成一张平面的二维表格。待分析的数据将按原始数据方式和计数数据方式组织。
其中,原始数据的组织方式,数据编辑窗口中的一行成为一个个案,所有个案组成完整的SPSS数据;而计数数据方式是经过分组汇总后的计数数据。
四、练习内容(书中例题以及教材P46页习题)
1. 纵向合并:教材P40页案例2-3
程序:1)在数据编辑窗口中打开一个需合并SPSS数据文件;
(2)选择菜单:“数据”—〉“合并文件”—〉“添加个案”;
(3)“将个案添加到”框中显示的变量名是两个数据文件中的同名变量,SPSS默认他们有相同的数据含义,并将他们作为合并后新的数据文件中的变量。;(4)然后对相同数据进行配对;
(5)点击确定
结果: 结果如数据所示 
2. 横向合并:教材P44页案例2-4
程序: (1)在数据编辑窗口中打开一个需合并SPSS数据文件;
(2)选择菜单:“数据”—“合并文件”—“添加变量”;
(3) 然后将 “已排除的变量” 添加 为“关键变量”;
(4)再将选上 “按照排序文件中的关键变量匹配个案”前面的小勾;
(5)点击确定
结果: 结果如图 数据所示 
3. 现有两个数据文件,分别名为“学生成绩一.sav”和“学生成绩二.sav”,存放了关于学生学号、性别和若干门课程成绩的数据。请将这两份数据文件以学号为关键变量进行横向合并,形成一个完整的数据文件。
程序: (1)先打开“学生成绩一.sav”;
(2)选择菜单:“数据”—〉“合并文件”—〉“添加变量”->选择 “学生成绩二.sav”;
(3) 然后将 “已排除的变量”(学号) 添加 为“关键变量” ;
(4)再将选上 “按照排序文件中的关键变量匹配个案”前面的小勾
结果: 结果如数据所示
4. 收集到以下关于两种减肥产品使用情况的调查数据,请问在SPSS中应如何组织该份资料?

答:结果如数据所示

5. 有一份关于居民储蓄调查的模拟数据储存在Excel中,文件名为“居民储蓄调查数据.xls”。该数据的第一行是变量名。请将该份数据转换成SPSS数据文件,并在SPSS中指定其变量名标签和变量值标签(该份数据的具体含义见Excle文件的后半部分)。.
程序: (1)打开SPSS软件;
(2)选择菜单“文件”—“新建”—“数据”;
(3) 在文件扩展名处选择EXCEL类型—打开“居民储蓄调查数据.xls”并且填写有效数据范围;
(4)双击第一行进入“数据集”;
(5)编辑“标签”,即EXCEL中的15项题干;
(6)点击“值” 后边的省略号进行编辑,将EXCEL中相应题干的选项编辑到值中 ; 结果:
-
上机实验报告格式
网页设计实验报告院部热能学院专业热能与动力工程班级112姓名范金仓学号20xx031388一实验目的及要求1确定网站主题和网站的用…
-
计算机上机实验报告模板
交通与汽车工程学院实验报告课程名称课程代码学院直属系交通与汽车工程学院年级专业班学生姓名学号实验总成绩任课教师开课学院交通与汽车工…
-
上机实验报告格式要求
VB上机实验报告要求1预习报告课程名称姓名实验名称班级学号实验日期指导教师一实验目的及要求本次上机实验所涉及并要求掌握的知识点二实…
-
C语言集中上机实验报告
重庆邮电大学移通学院C语言集中上机实验报告学生学号班级专业重庆邮电大学移通学院20xx年5月重庆邮电大学移通学院目录第一章循环31…
-
上机实验报告
编译原理报告编译原理报告正规式转化为NFA班级19xx31班学号20xx1002284姓名李豪强指导老师刘远兴日期20xx1020…
-
ERP上机实验心得体会
工商101320xx610083林冰冰首先感谢王家聚老师再这一学期中对我们的ERP知识传授,你教会我们的绝不仅仅是ERP课程上的知…
-
erp上机实验心得
ERP上机实验心得通过该实验,对所学的知识有了进一步的了解。在实验的过程中,出现了一些问题,不过最后都得以解决。然而通过这些错误,…
-
C语言上机实验心得
在科技高度发展的今天,计算机在人们之中的作用越来越突出。而C语言作为一种计算机的语言,学习它将有助于我们更好的了解计算机,与计算机…
-
电子商务实验心得体会
完成电子商务实验课的心得体会通过这段时间的电子商务实验,我了解到很多关于电子商务的实践知识。伴随着商品经济和网络技术的不断发展,网…
-
java上机实验心得体会报告
北京联合大学信息学院“面向对象程序设计”课程上机实验报告题目:JAVA上机实验心得体会姓名(学号):专业:计算机科学与技术编制时间…
-
电子商务上机实验报告模板
电子商务上机实验报告专业班级:会计0905姓名:郭馨学号:20xx1304220指导教师:叶双林实验日期:20xx.10.15-2…