Linux服务器巡检报告
Linux服务器巡检指导
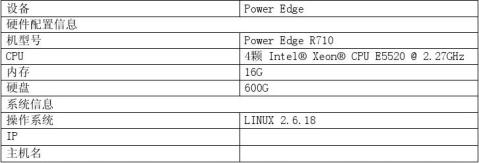
(一)服务器硬件检查
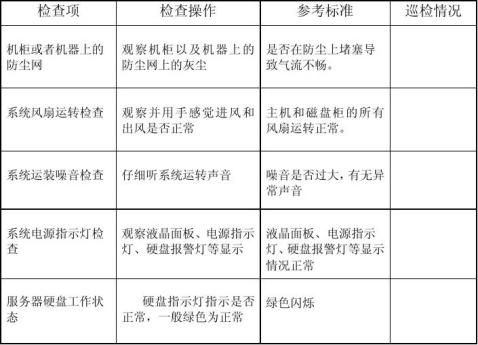
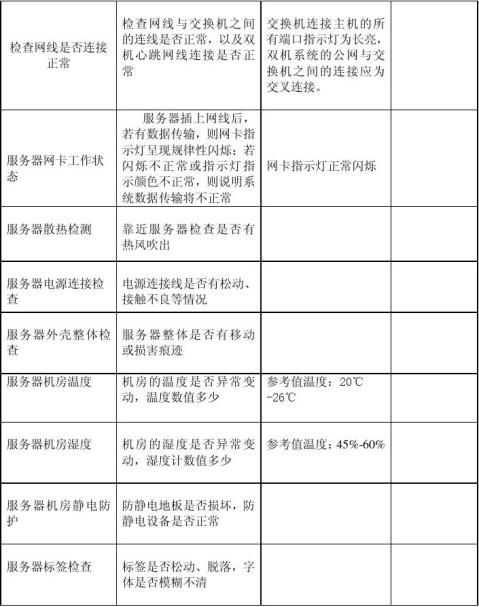
(二)操作系统检查
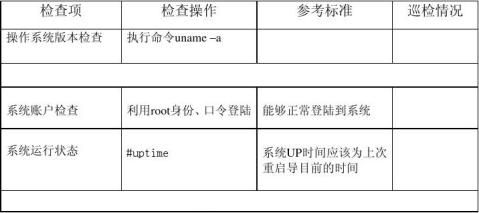
(二)性能检查
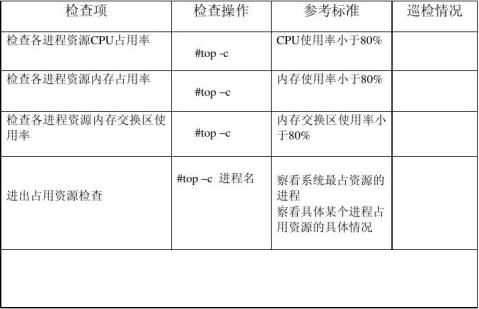
Top命令
统计信息区
前五行是系统整体的统计信息。第一行是任务队列信息,同 uptime 命令的执行结果。其内容如下:
16:35:22
up 17 day 5:45
4 user
load average: 0.15,
0.15, 0.08 当前时间 系统运行时间,格式为时:分 当前登录用户数 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、
5分钟、15分钟前到现在的平均值。
Tasks: 366 total 进程总数
1 running 正在运行的进程数
364 sleeping 睡眠的进程数
0 stopped 停止的进程数
1 zombie 僵尸进程数
Cpu(s): 0.3% us 用户空间占用CPU百分比
0.0% sy 内核空间占用CPU百分比
0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比
99.9% id 空闲CPU百分比
0.0% wa 等待输入输出的CPU时间百分比
0.0% hi
0.0% si
第五行以后内容是内存信息。内容如下:
Mem:
16429816k
total
16366812k
used
63004k free 物理内存总量 使用的物理内存总量 空闲内存总量
377544k
buffers
Swap:
18481144k
total
320k used
18480824k
free
7835708k
cached 用作内核缓存的内存量 交换区总量 使用的交换区总量 空闲交换区总量 缓冲的交换区总量。 内存中的内容被换出到交换区,而后又被换入到
内存,但使用过的交换区尚未被覆盖, 该数值即为这些内容已存在于
内存中的交换区的大小。 相应的内存再次被换出时可不必再对交换区
写入。
PID 每个进程的父进程ID。
USER 每个进程所有者的用户名。
PR 每个进程的优先级别。
NI 该进程的优先级值。
VIPT 该进程的代码大小加上数据大小再加上堆栈空间大小的总数。单位是KB。
RES 该进程占用的物理内存的总数量,单位是KB。
SHR 该进程使用共享内存的数量。
S 该进程的状态。其中S代表休眠状态;D代表不可中断的休眠状态;R代表运行状态;
Z代表僵死状态;T代表停止或跟踪状态。
CPU % 该进程自最近一次刷新以来所占用的CPU时间和总时间的百分比。
MEM% 该进程占用的物理内存占总内存的百分比。
TIME+ 该进程自启动以来所占用的总CPU时间。如果进入的是累计模式,那么该时间还包括这个进程子进程所占用的时间。且标题会变成CTIME。
COMMAND 该进程的命令名称,如果一行显示不下,则会进行截取。内存中的进程会有一个完整的命令行。
(三)安全检查
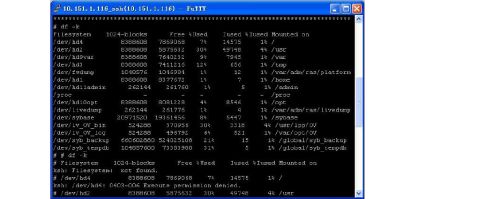
2、文件系统占用率df –k表示的是文件系统名称 使用空间、空闲空间、使用率、文件所在位置。
(四)网络管理命令
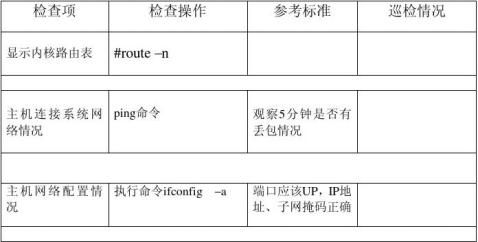

第二篇:如何对Linux服务器运行状况全面监测
如何对Linux服务器运行状况全面监测?Linux服务器监测技
巧有哪些?
今天上海快网讲解主要监测Linux服务器的CPU、硬盘、内存、网络接口、主板等硬件的工作状态。随着Linux应用的日益广泛,有大量的网络服务器使用Linux操作系统。为了全面衡量网络运行状况,Linux服务器监测技巧就还是很需要的,就需要对网络状态做更细致、更精确的测量。SNMP协议的制订为互联网测量提供了有力支持。计算机系统是由软件系统硬件系统组成的,Linux服务器监测技巧检测硬件状态对于保障整个系统的稳定是非常重要的。不论操作系统是使用Linux、还是Windows,一旦硬件出现故障,那么整个系统的安全就严重了。
一、/proc文件系统特点
Linux 系统向管理员提供了非常好的方法,使他们可以在系统运行时更改内核,而不需要重新引导内核系统。这是通过 /proc虚拟文件系统实现的。/proc文件虚拟系统是一种内核和内核模块用来向进程 (process) 发送信息的机制 (所以叫做 /proc)。这个伪文件系统让你可以和内核内部数据结构进行交互,获取有关进程的有用信息,在运行中 (on the fly) 改变设置 (通过改变内核参数)。与其他文件系统不同,/proc存在于内存之中而不是硬盘上。不用重新启动而去看 CMOS ,就可以知道系统信息。这就是 /proc的妙处之一。/proc目录里主要文件内容,
每个Linux系统根据软硬件不同/proc虚拟文件系统的内容也有些差异。/proc虚拟文件系统有三个很重要的目录:net,scsi和sys。Sys目录是可写的,可以通过它来访问或修改内核的参数,而net和scsi则依赖于内核配置。例如,如果系统不支持scsi,则scsi目录不存在。除了以上介绍的这些,还有的是一些以数字命名的目录,它们是进程目录。net目录包括多个 ASCII 格式的网络伪文件, 描述了网络层的部分情况,可以用arp、netstat、route等命令来查询这些文件。除了以上介绍的这些,还有的是一些以数字命名的目录,它们是进程目录。系统中当前运行的每一个进程都有对应的一个目录在/proc下,以进程的 PID号为目录名,它们是读取进程信息的接口。而self目录则是读取进程本身的信息接口,是一个link。Proc文件系统的名字就是由之而起。
二、proc文件系统主要实现的五大功能:
1. 进程信息:对于系统中的任何一个进程来说,在proc的子目录里都有一个同名的进程ID。你将可以找到以下的信息:cmdline, mem, root, stat, statm, 以及status。某些信息只有超级用户可见,例如进程根目录。到每一个单独的含有现有进程信息的进程有一些可用的专门链接。对于系统里的任何一个进程来说,都有一个单独的自链接指向进程信息。它的用处就是从进程中获取命令行信息。
2. 系统信息:如果你需要了解整个系统信息,你也可以从/proc/stat中获得。它包括:包括CPU占用、磁盘空间、内存页、内存对换、全部中断、接触开关以及上次系统自举时间。
3. CPU信息:利用/proc/cpuinfo文件,你可以获得中央处理器当前的准确信息。
4. 负载信息: /proc/loadavg文件包含了系统负载信息。
5. 系统内存信息:meminfo文件包含了系统内存的详细信息。它显示了物理内存的数量,可用交换空间的数量,空闲内存的数量等等。
1. 监测服务器全面统计状态
每个磁盘驱动器的如下数据:
单个磁盘块读;单个磁盘块写;单个磁盘I/O总数;单个磁盘I/O读;单个磁盘I/O写。
2.监测网络流量
如果要了解网络流量,可以使用命令: #cat /proc/net/dev
以上数字依次代表:接收到的字节;接收到的压缩字节;收到的误码数;收到的漏失误码;收到的FIFO误码;收到的帧误码;收到的多播误码;收到的总包数;已传输的字节;已传输的压缩字节;传输误码总数;传输载波误码;传输冲突误码;传输漏失误码;传输FIFO误码;传输的总包数。
3.使用uptime命令
使用uptime命令可以查看系统负载,系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数目。如果一个进程满足以下条件则其就会位于运行队列中:没有在等待I/O操作的结果、它没有主动进入等待状态(也就是没有被调用、没有被停止。
# uptime
9:51pm up 3 days, 4:43, 4 users, load average:6.02, 5.90, 3.94
上面命令显示示最近1 分钟内系统的平均负载是6.02,在最近5分钟内系统的平均负载是5.90,在最近的15 分钟内系统的平均负载是3.94。一共四个用户。通常来说只要每个CPU的当前活动进程数不大于3那幺系统的性能就是良好的,如果每个CPU的任务数大于5,那幺就表示这台机器的性能有严重问题。对于上面的例子来说,由于笔者系统使用是双CPU,那幺其每个CPU的当前任务数为:6.02/2=3.01。这表示该服务器的性能是可以接受的。
四、服务器主板工作状况监测:
服务器主板以及CPU工作温度是否正常是服务器稳定的核心。迄今为止还没有一种CPU
散热系统能保证永不失效。失去了散热系统保护伞的“芯”,往往会在几秒钟内永远停止“跳动”。值得庆幸的是,聪明的工程师们早已开发出有效的处理器温度监控、保护技术。以特殊而敏锐的“嗅觉”随时监测CPU的温度变化,并提供必要的保护措施,使CPU免受高温下的灭顶之灾。lm_sensors可以有效监控主板和CPU的工作电压、风扇转速、温度等核心数据。软件安装:
#mv lm_sensors-2.8.8.tar.gz /usr/local/src/
#cd /usr/local/src/
#tar zxvf lm_sensors-2.8.8.tar.gz
#cd /usr/local/src/lm_sensors-2.8.8
#tar xzf i2c-2.8.8.tar.gz
#make clean ;make dep;make all ;make install
#/sbin/depmod -a
修改配置文件:“/etc/ld.so.conf”加入一行:/usr/local/lib
#ldconfig
#sensors-detect #扫描主板所有芯片,选择缺省选项即可(按会车)# 加载模块,注意主板不一定相同。 #modprobe i2c-isa #modprobe lm78 #modprobe sis5595 开始检测 #sensors 高级应用:定时检测主板运行情况: 这里可以使用Linux组合命令: #watch --interval=450 “sensors ”
这样每隔450秒运行因此sensors 令,就可以得知主板运行情况。
五、P2P通信监测
P2P(Peer-to-Peer)是一种用于文件交换的新技术,通过Internet允许建立分散的、动态的、匿名的逻辑网络。P2P为对等连接或对等网络,点对点网络技术,可应用于文件共享交换,深度搜索、分布计算等领域。它允许个体的PC通过Internet共享文件。随着P2P文件交换应用的普及,ISP在维持和增加宽带网的收益上也面临着新的挑战和机遇。据有关资料统计,现有的网络中有超过70%的带宽被P2P通信占据着。P2P通信会导致异常的流量峰值,对网络资源造成意外的变形;所带来的网络拥塞、性能下降等问题,已影响到正常的网络应用,如WWW、Email等,缓慢的网页浏览和收发邮件速度更引起普通用户的不满。
识别P2P通信
若想控制P2P通信,就必须对P2P通信进行有效地识别,然而,许多P2P通信使用了不同的通信技术和协议,使用传统的技术来识别它们非常困难。比如,许多P2P协议不使用固定的端口,而是动态地使用端口,包括使用一些知名服务的端口。KaZaA就是可以使用端口80(通常是http/web来使用)来通信的,从而穿透传统的基于IP和端口的防火墙和包过滤器。所以,通过简单的基于IP和端口的分类技术(分析IP包头、IP地址、端口号等)很难识别、跟踪或控制这类通信。过去有一段时间,有人使用监测6881~6889端口来识别BT(BitTorrent),但这种做法现在早已失效——BT已不再使用固定的6881~6889端口来通信,而是动态地使用端口。随着P2P应用的不断增长,更多的通信协议被使用;识别和分类P2P的技术必须快速、简单,以适应这种技术的变化。现在,识别P2P通信的方法是在应用层分析数据包,看是否有某个应用协议的特征码,然后确定通信的种类。应用层分析数据包的基本方法是,如果应用层数据包的头部有“220 ftp server ready”的特征串,可以确定是在使用ftp程序;如果有“HTTP/1.1 200 ok”的特征串,可以确定是在使用http传送数据。谈到网络流量监控,相信大家都熟悉MRTG这个工具。但是MRTG存在许多缺点:
1. 使用文本式的数据库,数据不能重复使用;。
2. 只能按日、周、月、年来查看数据;
3. 只能画两个DS(一条线、一个块);
4. 无管理功能;
5. 没有日志系统;
6. 无法详细了解一一流量具体构成;
这里介绍一个工具:ntop能够更加直观的将网络使用量的情况和每个节点计算机的网络带宽使用详细情况显示出来。ntop是一种网络嗅探器,嗅探器在协助监测网络数据传输、排除网络故障等方面有着不可替代的作用。可以通过分析网络流量来确定网络上存在的各种问题,如瓶颈效应或性能下降;也可以用来判断是否有黑客正在攻击网络系统。如果怀疑网
络正在遭受攻击,通过嗅探器截获的数据包可以确定正在攻击系统的是什么类型的数据包,以及它们的源头,从而可以及时地做出响应,或者对网络进行相应的调整,以保证网络运行的效率和安全。通过ntop网管员还可以很方便地确定出哪些通信量属于某个特定的网络协议、占主要通信量的是那个主机、各次通讯的目标是哪个主机、数据包发送时间、各主机间数据包传递的间隔时间等。这些信息为网管员判断网络问题及优化网络性能,提供了十分宝贵的信息。
ntop提供以下一些功能:
1. 自动从网络中识别有用的信息;
2. 将截获的数据包转换成易于识别的格式;
3. 对网络环境中的通讯失败进行分析;
4. 探测网络环境下的通讯瓶颈;
5. 记录网络通信时间和过程。
ntop和MRTG相比相比它的安装配置比较简单,可以不使用Apache服务器。同时也可以和MRTG配合使用。目前市场上可网管型的交换机、路由器都支持SNMP协议,Ntop支持简单网络管理协议所以可以进行网络流量监控。ntop几乎可以监测网络上的所有协议: TCP/UDP/ICMP、(R)ARP、IPX、Telnet、DLC、Decnet、DHCP-BOOTP、AppleTalk、Netbios、TCP/UDP、FTP、HTTP、DNS、Telnet、SMTP/POP/IMAP、SNMP、NNTP、NFS、X11、SSH和基于P2P技术的协议eDonkey, Overnet, Bittorrent, Gnutella (Bearshare, Limewire,etc), (Kazaa, Imesh, Grobster)。在 可以下载最新的源代码安装使用。
软件下载:
官方网站: /ntop.html,最新的版本源代码(2005nian八月)和相关函数库:
wget http://www.mirrors.wiretapped.ne ... g/ntop/ntop-3.2.tgz
wgrt ftp://ftp.rediris.es/sites/ftp.r ... p-0.6.2-12.i386.rpm
软件安装:(注意安装顺序)
#rpm –ivh libpcap-0.6.2-12 RPM for i386
#tar zxvf ntop-3.2.tgz
#cd ntop/gdchart0.94c
#./configure
??
do not forget to build: #系统提示你先编译gd、zlib模块 #
1. gd-1.8.3/libpng-1.2.1
2. zlib-1.1.4/
#cd gd-1.8.3/libpng-1.2.1/
#cp scripts/makefile.linuxMakefile
#make #cd ../../zlib-1.1.4 # ./configure # make cd .. # make 下面回到Ntop目录下编译: #tar zxvf ntop-2.2.tgz #cd ../ntop/ # ./configure #make;make install 然后建立log目录 #mkdir /var/log/ntop/ 启动ntop #ntop -P /var/log/ntop/ -u nobody &
第一次运行系统它会要你输入管理员的密码,预设密码是:admin,第二次执行就不用再输入.这时你可以打开浏览器输入:http://IP:3000即可打开管理界面。查看网络整体流量用鼠标点击“Stats”按钮后下载“Triffic”选项。网络流量会以柱面图和明细表格的形式显示出,如果你想查看某个用户的计算机流量,用鼠标点击“IP Traffic”-“Host”按钮即可。如果想了解该计算机传输了那些数据,可以双击“CAO”即可分析出用户各种网络传输的协议类型和占用带宽的比例。
Ntop可以监测的数据包括:网络流量、使用协议、系统负载、端口情况、数据包发送时间、数据生存时间TTL等。透过它﹐基本上所有进出数据都无所遁形,不管拿来做例行的网络监测工作﹐还是拿来做报告﹐都是非常优秀的工具,让您的网络流量透明化。它工作的时候就像一部被动声纳,默默的接收看来自网络的各种信息,通过对这些数据的分析,网络管理员可以深入了解网络当前的运行状况。不过﹐由于ntop本质上是嗅探器,它是一把双刃剑﹐如何保护这些信息只能给授权的人士获得﹐将变得额外重要。
总结:
Linux服务器监测是很重要的工作,服务器运行应该提供最有效的系统性能。网络服务器的资料总流量(网卡的资料传送总数),以及CPU使用率和特殊服务等的封包传送率(或者说是流量),都是网络管理人员所必须要注意的事项,因为当主机的CPU使用率过高的时候,系统可能呈现不稳定的状态,而当流量发生异常变化的时候,就需要注意可能有黑客在尝试窃取我们的信息。当建立一个系统性能的可靠底线后,可以利用Linux操作系统的灵活性对其进行设置。使其更加高效。
另外在网络管理方面,有必要了解我们Linux服务器的网络流量状态,并视流量来加以限制或者是加大带宽。本文介绍从Linux命令到一些简单的但是有用的工具来监测系统性能。依靠这些工具得到的数据,可以建立对系统性能的切身感受。
- 服务器巡检报告
-
机房服务器状况巡检报告
上海巡检报告电信机房服务器巡检报告上海公司20专业IT服务上海公司上海巡检报告目录123456概述3基本信息3服务器信息3服务器状…
- PC服务器巡检报告
- 网站-服务器巡检报告
-
Windows服务器巡检报告
Windows系统健康检查报告一服务器巡检的重要性windows服务器是系统重要的业务运行平台对服务器进行巡检能够及时发现服务器的…
-
Windows服务器巡检报告
Windows系统健康检查报告一服务器巡检的重要性windows服务器是系统重要的业务运行平台对服务器进行巡检能够及时发现服务器的…
- 网站-服务器巡检报告
- PC服务器巡检报告
- 服务器巡检报告
-
机房服务器状况巡检报告
上海巡检报告电信机房服务器巡检报告上海公司20专业IT服务上海公司上海巡检报告目录123456概述3基本信息3服务器信息3服务器状…
- 运维服务服务器网络设备日常巡检报告