操作系统课程设计实验报告
操作系统课程设计实验报告
——nachos
专业:计算机科学与技术
班级:2011级2班
姓名:李霜
学号:201100130082
目录
Laboratory 3:Synchronization Using Semaphores
—— 信号量实现同步 Laboratory 5:Extendable Files
—— 扩展文件系统
Laboratory 7-8:Extension of AddrSpace & System Calls Exec()and Exit()
——扩展地址空间 & 实现系统调用 Laboratory 9:设计并实现具有优先级的线程调度策略 Laboratory 10:设计并实现具有二级索引的文件系统
Laboratory 3:Synchronization Using Semaphores
—— 信号量实现同步
一、实验目的:
1、 在原有的程序框架的基础上,通过使用信号量添加关键代码实现生产者/消
费者同步问题。
2、 深入理解Nachos的信号量的使用、实现,以及在Nachos中是如何创建线程,
实现多线程。
3、 掌握生产者/消费者问题是如何用信号量实现的。
二、实验步骤
1.首先初始化三个信号量,代码如下:
mutex = new Semaphore("mutux",1);信号量初始化为1,才能起到加锁功能 nfull = new Semaphore("full",0);nfull的大小在生产者没生产前为0 nempty = new Semaphore("empty",BUFF_SIZE);nempty的大小应该为buffer的大小
2.首先考虑生产者进程,首先要查看buffer是否有空, nempty->P();if nempty>0,nempty=nempty -1,当对缓冲区操作时必须要加锁:mutex->P();加锁. 然后向ring中放入message信息,其次还要解锁mutex->V();解锁.最后通知消费者buffer有新信息, nfull->V();nfull=nfull+1;具体实现代码如下:
3. 考虑消费者进程,像生产者进程一样,查看buffer中是否有信息
nfull->P();if nfull>0,nfull-1;取消息时也要上锁,即:mutex->P();加锁. 然后从ring buffer中取出信息;其次mutex->V();解锁;最后通知生产者buffer有空nempty->V();nempty=nempty+1,具体代码如下:
4. 创建线程生成一个生产者的代码:
producers[i] = new Thread(prod_names[i]);
producers[i] -> Fork(Producer,i);
5. 创建线程生成一个消费者的代码:
consumers[i]=new Thread(cons_names[i]);
consumers[i]->Fork(Consumer,i);
三、实验关键代码
在prodcons++中,定义ring的BUFF_SIZE大小为3。
生产者
void
Producer(_int which)
{
int num;
slot *message = new slot(0,0);
//建立slot实例,此信息message将被放到ring buffer里。每个信息message有一个id和一个value。
//每个生产者产生的商品的个数必须使用N_MESSG限定,否则程序没有结束 for (num = 0; num < N_MESSG ; num++) {
message->thread_id=which; //生产者的id
message->value=num; //产生的message的编号
nempty->P(); //查看buffer是否有空,if nempty>0,nempty=nempty -1 mutex->P(); //加锁
ring->Put(message);//向ring中放入message信息
mutex->V(); //加锁
nfull->V(); //通知消费者buffer有新信息,nfull=nfull+1.
}
}
消费者
void
Consumer(_int which)
{
char str[MAXLEN];
char fname[LINELEN];
int fd;
slot *message = new slot(0,0); //建立slot实例,此信息message将被放到
ring buffer里。每个信息message有一个id和一个value。n // 为消费者线程建立message信息文件
sprintf(fname, "tmp_%d", which);
// create a file. Note that this is a UNIX system call. if ( (fd = creat(fname, 0600) ) == -1)
{
perror("creat: file create failed");
exit(1);
}
//不需要规定每个消费者消费的商品的个数
for (; ; ) {
nfull->P(); //查看buffer中是否有信息,if nfull>0,nfull=nfull-1
mutex->P();// 加锁
ring->Get(message);//从ring buffer中取出信息
mutex->V(); //加锁
nempty->V(); //通知生产者bufferr有空nempty=nempty+1.
// 生成一个字符串来记录信息
sprintf(str,"producer id --> %d; Message number --> %d;\n", message->thread_id,
message->value);
// 将生成的字符串写入消费者的输出文件
if ( write(fd, str, strlen(str)) == -1 ) {
perror("write: write failed");
exit(1);
}
}
}
生产者/消费者问题的解决
void
ProdCons()
{
int i;
DEBUG('t', "Entering ProdCons");
//建立信号量
nfull=new Semaphore("nfull",0); //nfull的大小在生产者没生产前为0
nempty=new Semaphore("nempty",BUFF_SIZE); //nempty的大小应该为buffer的
大小
mutex=new Semaphore("mutex",1); //信号量初始化为1,才能起到加锁功能 // 建立ring buffer,大小为BUFF_SIZE
ring=new Ring(BUFF_SIZE);
// 建立并唤醒 N_PROD个生产者线程
for (i=0; i < N_PROD; i++)
{
// this statemet is to form a string to be used as the name for // produder i.
sprintf(prod_names[i], "producer_%d", i);
//使用prod_names[i]创建线程
producers[i]=new Thread(prod_names[i]);
//行为为Producer定义,i为Producer参数
producers[i]->Fork(Producer,i);
};
// 建立并唤醒N_CONS 个消费者线程
for (i=0; i < N_CONS; i++)
{
sprintf(cons_names[i], "consumer_%d", i);
//使用cons_names[i]创建线程
consumers[i]=new Thread(cons_names[i]);
//定义行为为Consumer,i为Consumer参数
consumers[i]->Fork(Consumer,i);
};
}
四、调试记录
源代码中exit(0)没有大写,增加了许多无谓的劳动。调试过程中因为消费
者消费记录写入文件部分一直报错,曾打算将写入文件改为终端显示,但这最终将会看到生产者产生的商品按产生顺序被顺序打印,根本无法看出是那个被消费者获取。后来终于注意到Exit,顺利通过调试。
五、运行结果及分析 生成
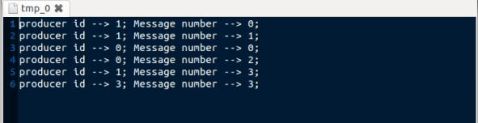
3个文件分别代表4个消费者取得的产品的记录
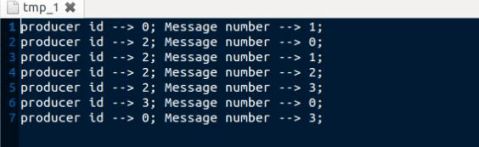
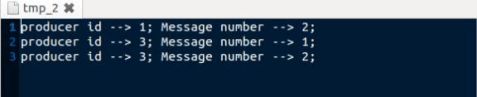
分析结果:
从实验结果中可以看出,16条message(N_PROD*N_MESSG)分布在3个文件中。Message按照其产生顺序被消费者取走。
六、实验总结
在本次实验中,实现生产者/消费者同步问题,通过使用信号量,即Nachos 提供的系统调用,进一步理解Nachos的信号量的使用以及实现。同时,学会在Nachos中是如何创建线程,实现多线程,理解了多线程的问题。
Laboratory 5:Extendable Files
—— 扩展文件系统
一、实验背景
Nachos的文件系统是一个简单并且能力有限的系统,限制之一就是文件的大小是不可扩展的:一旦我们在创建一个文件时规定了它的大小,文件的大小就不能再改变。
二、实验目的
1、设计扩展Nachos的文件系统,使得文件的大小是可以被扩展的。
2、可以实现在一个文件尾部或者中间追加文件。
三、实验分析
Nachos的文件系统包含以下几个类:
class Disk
class SynchDisk
class BitMap
class FileHeader
class OpenFile
class Directory
class FileSystem
其中,class Disk, SynchDisk, BitMap, Directory, FileSystem是文件系统的底层类,里面描述了Nachos的文件系统的基本文件信息以及和磁盘操作的结合。
class FileSystem中描述的是文件的创建、打开、删除等操作。拥有私有变量OpenFile* freeMapFile和OpenFile* directoryFile。
class FileHeader定义操作是文件头的初始化文件头、为数据在磁盘上分配空间、磁盘上文件的读取和写回,包含描述头文件信息的私有变量int numBytes; int numSectors; int dataSectors[NumDirect]。
class OpenFile 中主要涉及文件的读、写、读写指针的重定位等动作。拥有私有变量FileHeader *hdr,当前文件的文件头;int seekPosition,文件中读写头当前的位置。
扩展当前Nachos的文件系统的功能使之可以在文件中追加新的内容并不需要改变整个文件系统的文件存储结构或是和磁盘的交互访问,所以所有的更改只需要在涉及文件访问和文件打开后的操作中进行更改:首先,扩展文件必定需要获取文件头,并申请新的空间,申请成功后,更改文件头的信息,所以必定会用到class FileHeader;其次,对文件的扩充的实际任务自然是在class OpenFIle中进行的,当文件被打开之后,重新定位文件读写指针,进行追加appd操作,最后将修改的数据写回。
四、关键源代码及注释
class FileHeader
头文件内容:bool ChangeHeader(int numbytes,int half) bool
FileHeader::ChangeHeader(int numbytes,int half)//numbytes表示增加的字节数
{
BitMap *freeMap;
OpenFile *freeMapFile;
if(half) //如果是从文件中间扩展文件,则首先恢复位示图中该文件后半部分分配的扇区号
{
int oldnumBytes=numBytes;//记录原来的字节数
int oldnumSectors=numSectors;//记录原来的扇区数
numBytes=numBytes/2;//如果从中间扩展文件,则原字节数减半 numSectors=(numSectors/2)+1;//原扇区数减半
freeMapFile = new OpenFile(FreeMapSector);//打开位示图文件 freeMap = new BitMap(NumSectors);
//获取空闲的扇区号
freeMap->FetchFrom(freeMapFile);//得到位示图
for(int i=0;i<oldnumSectors-numSectors;i++)
freeMap->Clear(i);
freeMap->WriteBack(freeMapFile);
}
bool flag=TRUE;//是否会超过文件的最大长度
freeMapFile = new OpenFile(FreeMapSector);//打开位示图文件
int moreBytes=numBytes+numbytes-numSectors*SectorSize;//超出原文件所拥有扇区所能存储的字节数
int numsectors=0;
if(numBytes+numbytes>MaxFileSize)//超过最大文件长度
{
numsectors=NumSectors-numSectors;//截断,只存储最大文件长度的文本
flag=FALSE;
}
if(moreBytes>0)//需要则增加扇区
{
numsectors=divRoundUp(moreBytes, SectorSize);//要增加的扇区数
freeMap = new BitMap(NumSectors);
freeMap->FetchFrom(freeMapFile);//得到位示图
if (freeMap->NumClear() < numsectors)
return FALSE; //空间不足
for(int i=0;i<numsectors;i++)//修改dataSectors字段,分配增加的扇区
dataSectors[i+numSectors] = freeMap->Find(); }
numSectors+=numsectors;//修改numSectors字段
numBytes+=numbytes;//修改numBytes字段
freeMap->WriteBack(freeMapFile);
delete freeMap;
delete freeMapFile;
return flag;
}
Class OpenFile
int
OpenFile::WriteAt(char *from, int numBytes, int position)
{
int fileLength = hdr->FileLength();
int i, firstSector, lastSector, numSectors;
bool firstAligned, lastAligned;
char *buf;
if ((numBytes <= 0) || (position >= fileLength))
return 0; // check request
DEBUG('f', "Writing %d bytes at %d, from file of length %d.\n", numBytes, position, fileLength);
firstSector = divRoundDown(position, SectorSize);//position在文件中的位置
lastSector = divRoundDown(position + numBytes - 1, SectorSize); numSectors = 1 + lastSector - firstSector;//还要占用的扇区数 buf = new char[numSectors * SectorSize];
firstAligned = (bool)(position == (firstSector * SectorSize));//判断position是否在某个扇区的开头
lastAligned = (bool)((position + numBytes) == ((lastSector + 1) * SectorSize));//判断结尾是否是某个扇区的结尾
// read in first and last sector, if they are to be partially modified if (!firstAligned)
ReadAt(buf, SectorSize, firstSector * SectorSize);
if (!lastAligned && ((firstSector != lastSector) || firstAligned)) ReadAt(&buf[(lastSector - firstSector) * SectorSize], SectorSize, lastSector * SectorSize);
// copy in the bytes we want to change
bcopy(from, &buf[position - (firstSector * SectorSize)], numBytes); // write modified sectors back
for (i = firstSector; i <= lastSector; i++)
synchDisk->WriteSector(hdr->ByteToSector(i * SectorSize), &buf[(i - firstSector) * SectorSize]);
delete [] buf;
return numBytes;
}
//修改文件头的numBytes字段
void
OpenFile::WriteBack(int AddedFileLength,int half)
{
if(!hdr->ChangeHeader(AddedFileLength,half))
printf("超过文件最大长度!将截断文件!");//超过最大文件长度 hdr->WriteBack(headerSector);
}
五、实验结果及分析
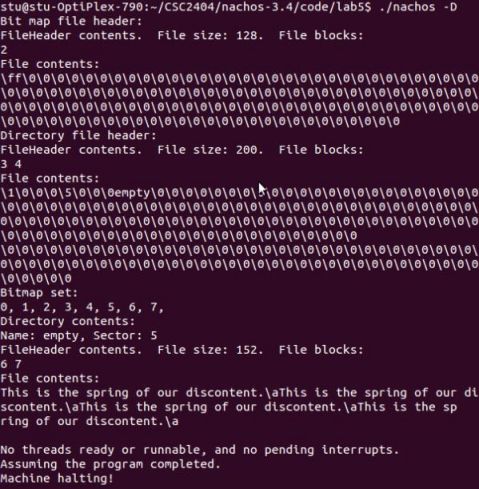
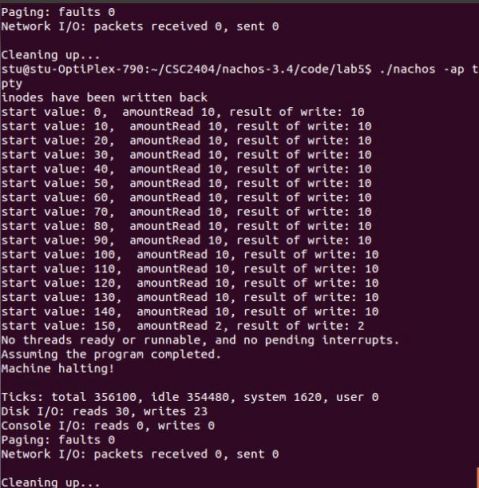
结果分析:从bitmap和dirctory的content中可以看出,bitmap中的前0-7号扇区全部占满,0号为bitmap头、1号为directory头,(程序定义)bitmap占用2号存储单元存储具体内容,dirctory占用3、4号存储文件头指针信息。经过复制到Nachos下medium文件占用5、6、7号扇区,5号为其头文件,6、7里面的内容为medium文件经追加之后的结果。
六、实验总结
在本次实验中,通过增加Nachos文件系统对文件的追加功能,理解了文件系统的管理方式,通过目录,目录项,文件头,进一步理解了文件的存储方式,以及空闲磁盘空间的管理,使用位试图 的方式管理空闲的磁盘空间。
Laboratory 7-8:Extension of AddrSpace & System Calls Exec()and Exit()
——扩展地址空间 & 实现系统调用
一、实验目的
1、扩展现有的class AddrSpace的实现,使得Nachos可以实现多用户程序;
2、实现Nachos系统调用:Exec(),使Nachos按页分配内存空间。
二、实验分析
(一)扩展AddrSpace
制约Nachos实现多用户程序的根本原因在于Nachos在建立用户程序的时候,令虚拟地址和物理地址一一映射。每当一个新的用户程序建立的时候,虚拟地址和物理地址都是从0开始分配,这样新的用户程序将会冲掉原来在物理0开始的旧用户程序,发生错误。克服此种缺陷的方法之一是使用位示图分配物理地址。在做虚存和物理地址的映射时,使用bitmap的find函数分配虚存对应的物理地址,但是如此使用bitmap之后,当处理虚地址到内存的映射的时候,就又不得不改用一个一个segment地读取,那么如果采用code segment 和 data segment连续地在物理地址中存放,那么在读取code和data的时候必须首先判断是否是从一个segment 0 端开始,如果是,万事大吉,如果不是,那么以后每次都要分两次读一个segment,控制逻辑十分复杂,找data的初始位置的时候也很混乱。所以采取如下方案:保留一部分内存碎片,code和data 存放的时候都始终从一个segment的0开始,如果最后一部分不满一个segment,算为一个segment,剩余部分为碎片。
(二)实现Nachos系统调用Exec()
实现Nachos的系统调用的时候,程序的执行采用的是异常中断的方法,接住异常的类在userprog/exception.cc,必须在此类中添加处理Exec的方法。在系统调用一个新的用户程序的时候,系统所有需要就是获取描述执行文件的位置的参数,根据在AdvancePC中的描述,此参数的地址存放在4号寄存器中。
三、关键源代码及注释
1.首先编写实验6的Print函数,为了可以显示内存空间的分配。以下为Print函数的实现:
void
AddrSpace::Print()
{
int i;
printf("Page table has:%d pages in total\n",numPages);
printf("*********************************information*****************************\n");
printf("\tvirtual\t\t\tphysical\n");
for(i=0;i<numPages;i++)
printf("\t%d\t\t\t%d\n",pageTable[i].virtualPage,pageTable[i].physicalPage);
printf("**************************************************************************\n");
}
2.编写一个exec.c的源码,然后编译生成一个可执行文件,exec.noff exec.c的源码:
#include "syscall.h"
int
main()
{
SpaceId pid;
pid=Exec("../test/halt.noff");
Halt();
}
3.Nachos原来实现AddressSpace分配的时候没有使用bitmap来寻找空闲页,而是直接的从0号内存空间开始分配,因而需要修改成使用bitmap的find函数分配内存空间.
// first, set up the translation
pageTable = new TranslationEntry[numPages];
for (i = 0; i < numPages; i++) {
pageTable[i].virtualPage = i;// for now, virtual page # = phys page# pageTable[i].physicalPage = freeMap->Find();//要执行多任务,分配物理页需要从位图中找到下一个空闲的页
pageTable[i].valid = TRUE;
pageTable[i].use = FALSE;
pageTable[i].dirty = FALSE;
pageTable[i].readOnly = FALSE; // if the code segment was entirely on; // a separate page, we could set its
// pages to be read-only
}
其中,要声明一个位试图的是对象,在AddrSpace中
BitMap* AddrSpace::freeMap=new BitMap(NumPhysPages);
并且数据段代码段按页存储。
if (noffH.code.size > 0) { //为代码段部分分配空间
DEBUG('a', "Initializing code segment, at 0x%x, size %d\n", noffH.code.virtualAddr, noffH.code.size);
for(i=0;i<noffH.code.size/PageSize;i++) //分配整数部分 {
executable->ReadAt(&(machine->mainMemory[pageTable[i].physicalPage*PageSize]),
PageSize,noffH.code.inFileAddr+PageSize*i);
}
if(noffH.code.size%PageSize!=0)//分配不足一页的部分 {
executable->ReadAt(&(machine->mainMemory[pageTable[i].physicalPage*PageSize]),
noffH.code.size%PageSize,noffH.code.inFileAddr+PageSize*i); }
}
if(noffH.initData.size > 0) //初始化数据部分
{
if(noffH.code.size%PageSize==0)//如果之前代码部分使用一整页,则从一个新页开始
{
for(i=noffH.code.size/PageSize;i<noffH.code.size/PageSize+noffH.initData.size/PageSize;i++)
{
executable->ReadAt(&(machine->mainMemory[pageTable[i].physicalPage*PageSize]),
PageSize,noffH.initData.inFileAddr+PageSize*(i-noffH.code.size/PageSize));
}
if(noffH.initData.size % PageSize!=0)//分配数据部分不足一页 {
executable->ReadAt(&(machine->mainMemory[pageTable[i].physicalPage*PageSize]),
noffH.initData.size%PageSize,noffH.initData.inFileAddr+PageSize*(i-noffH.code.size/PageSize));
}
}
else//如果之前的代码部分使用的页数不是整数
{
if(noffH.initData.size <= PageSize-(noffH.code.size%PageSize))//如果初始化数据部分需要空间小于该页剩余空间
{
executable->ReadAt(&(machine->mainMemory[pageTable[i].physicalPage*PageSize+noffH.code.size%PageSize]),
noffH.initData.size,noffH.initData.inFileAddr);
}
else//否则,先将该页剩余部分分配,之后再在新一页进行分配 {
executable->ReadAt(&(machine->mainMemory[pageTable[i].physicalPage*PageSize+noffH.code.size%PageSize]),
PageSize-noffH.code.size%PageSize,noffH.initData.inFileAddr);
for(i=i+1;i<i+(noffH.initData.size-(PageSize-noffH.code.size%PageSize))/PageSize;i++)
{
executable->ReadAt(&(machine->mainMemory[pageTable[i].physicalPage*PageSize]),
PageSize,noffH.initData.inFileAddr+PageSize-noffH.code.size); }
if(noffH.initData.size-(PageSize-noffH.code.size%PageSize)% PageSize!=0)
{
executable->ReadAt(&(machine->mainMemory[pageTable[i].physicalPage*PageSize]),
noffH.initData.size%PageSize,noffH.initData.inFileAddr+PageSize*(i-noffH.code.size/PageSize-1)+PageSize-noffH.code.size);
}
}
4.计算加载一个程序需要的页表的数目
size = noffH.code.size + noffH.initData.size + noffH.uninitData.size + UserStackSize;
numPages = divRoundUp(size, PageSize);
size = numPages * PageSize;
5.实现Nachos的系统调用,采用的是触发异常中断的, 在exception.cc,添加SC_Exec异常,存放要执行的文件的路径的字符串的首地址存放在4号寄存器中,因此可以通过这个方式找到文件的路径,从而使用文件系统提供的方法打开这个文件:
if ((which == SyscallException) && (type == SC_Halt)) {
DEBUG('a', "Shutdown, initiated by user program.\n");
interrupt->Halt();
}
else if((which == SyscallException) && (type == SC_Exec)) { DEBUG('a', "Shutdown, initiated by user program.\n");
int parameter = machine->ReadRegister(4);//读出要执行的文件的地址
char filename[40]; //要执行的文件名程 for(int i=0;i<10;i++)
{
machine->ReadMem(parameter+4*i,4,(int*)(filename+4*i)); }
printf("Execuate filename is:%s\n",filename);
StartProcess(filename); //执行程序
}
else {
printf("Unexpected user mode exception %d %d\n", which, type); ASSERT(FALSE);
}
}
四、实验结果及分析
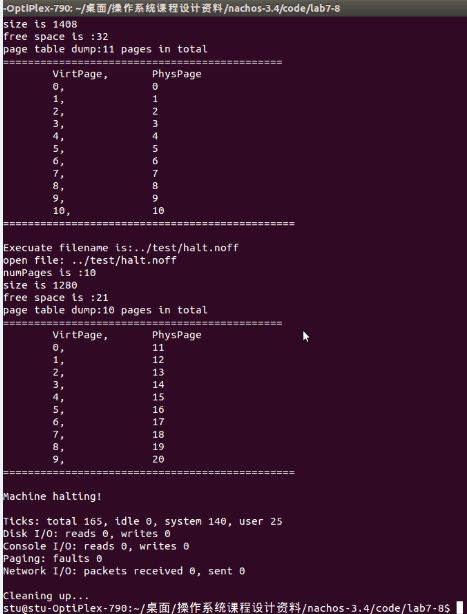
五、实验总结
Nachos之前没有实现按页分配地址空间,物理页和逻辑页地址一致,而且数据段代码段连续分配。每当一个新的用户程序建立的时候,虚拟地址和物理地址都是从0开始分配,这样新的用户程序将会冲掉原来在物理0开始的程序。因而使用位示图分配物理地址。使用bitmap的find函数分配虚存对应的物理地址,在为数据段和代码段写入数据的时候是以扇区为单位的,而不是原有的连续一个文件的读入连续的内存。
Nachos操作系统通过中断的方式实现系统调用。需要增加userprog/exception.cc中的内容,即必须在此类中添加处理Exec的方法。
Laboratory 9:设计并实现具有优先级的线程调度策略
一、实验目的
1、熟悉Nachos原有的先来先服务的基本的线程调度策略;
2、设计并实现具有优先级的线程调度策略。
二、实验分析
将原有的先来先服务的线程调度策略改为按优先级调度的策略,那么每个线程需添加属性priority,决定当前线程的优先级高低。定义优先级取值范围为1-6,其中1为最高,6为最低。那么在当前线程被阻塞时,调度函数通过判断当前就绪队列中的线程谁的优先级最高,就调度谁,使其运行。更为优化的方法是,每次将一个线程插入到就绪队列中时,就按线程的优先级顺序插入,让List中的等待时间片的线程按照优先级从高到低排好序,那么每次查询下一要执行的线程时,无需再遍历List,直接从头指针上截取即可,如此插入和移除的平均时间将节省一半。
三、实验步骤
1、修改thread类头文件,新增一个实例priority变量用于保存线程的优先数,本实验中约定,优先数高的线程优先级反而低。新增方法getpriority(),用于获得线程实例的优先数。
2、修改scheduler类中的ReadyToRun()方法和 FindNextToRun()方法。在当前线程插入等待队列中时,根据他的优先数按顺序的排列,使用list类中的SortedInsert()方法实现。
3、创建线程的时候使每个线程调用setpriority()方法传进一个参数,这个参数指明了该线程的优先数。使每个线程执行测试方法SimpleThread(),该方法中使用开关中断的方式使时钟向前推进,当时钟到期时,发生时钟中断,实现线程之间的切换。从而实现该调度算法。
四、关键源代码及注
1、修改Thread类的构造函数,加入优先级priority属性,并且加入getPriority方法。以便在线程的等待队列中找到优先级最高的线程。其中,线程优先级的范围从1到6,默认为6,即最低优先级。
修改代码如下:(thread.cc,thread.h)
class Thread {
public:
??????????????
Thread(char* debugName,int pri=6); // initialize a Thread ??????????????
int getpriority() {return pri;} //获得线程的优先级
Thread::Thread(char* threadName,int p)
{
//定义线程的优先级
if(p<1) pri=1;
else if(p>=1&&p<=6) pri=p;
else pri=6;
name = threadName;
stackTop = NULL;
stack = NULL;
status = JUST_CREATED;
#ifdef USER_PROGRAM
space = NULL;
#endif
}
2,首先,了解Nachos系统原来的线程调度方式。通过读threadtest.cc,thread.cc,scheduler.cc文件中的内容了解线程调度的方式。 首先,修改threadtest.cc 文件中的ThreadTest方法,创建有优先级的Thread,代码如下:
void
ThreadTest()
{
DEBUG('t', "Entering SimpleTest");
Thread *t = new Thread("forked thread 1",3); //声明线程,优先级初 始化为3
Thread *t2 =new Thread("forked thread 2",2); //声明线程,优先级初 始化为2
Thread *t3 =new Thread("forked thread 3",5);//声明线程,优先级初始 化为5
Thread *t4 =new Thread("forked thread 4",4);//声明线程,优先级初始 化为4
//调用Fork方法,让新产生的线程去执行SimpleThread方法
t->Fork(SimpleThread, 1);
t2->Fork(SimpleThread,2);
t3->Fork(SimpleThread,3);
t4->Fork(SimpleThread,4);
}
然后,从Thread类中找到Fork方法,代码如下:
void
Thread::Fork(VoidFunctionPtr func, _int arg)
{
#ifdef HOST_ALPHA
DEBUG('t', "Forking thread \"%s\" with func = 0x%lx, arg = %ld\n", name, (long) func, arg);
#else
DEBUG('t', "Forking thread \"%s\" with func = 0x%x, arg = %d\n", name, (int) func, arg);
#endif
StackAllocate(func, arg);
IntStatus oldLevel = interrupt->SetLevel(IntOff);
scheduler->ReadyToRun(this);//ReadyToRun assumes that interrupts // are disabled!
(void) interrupt->SetLevel(oldLevel);
}
void
SimpleThread(_int which)
{
int num;
for (num = 0; num < 5; num++) {
printf("*** thread %d looped %d times\n", (int) which, num); currentThread->Yield();
}
}
这说明ThreadTest方法的目的是,实例化新的线程,调用Fork方法,也就是让新产生的线程去执行SimpleThread方法,并且把当前执行的线程加入到等待队列。
从simpleThread的定义中可以知道,新生产的线程就是打印一条信息然后去执行Yield();
通过查看yield,可知,先从等待队列中找到一个线程保留在nextThread中,并将当前线程加到等待队列,然后使nextThread运行。
void
Thread::Yield ()
{
Thread *nextThread;
IntStatus oldLevel = interrupt->SetLevel(IntOff);
ASSERT(this == currentThread);
DEBUG('t', "Yielding thread \"%s\"\n", getName());
nextThread = scheduler->FindNextToRun();
if (nextThread != NULL) {
scheduler->ReadyToRun(this);
scheduler->Run(nextThread);
}
(void) interrupt->SetLevel(oldLevel);
}
3、为了实现按优先级调度,需要按优先级选择等待队列中的,即状态为ready的线程,因而,在线程插入,移除等待队列的时候使用List类中提供好的SortedInsert(void *item, int sortKey)、 SortedRemove(int *keyPtr)方法,而不是原来使用的Append,Remove方法。
void
Scheduler::ReadyToRun (Thread *thread)
{
DEBUG('t', "Putting thread %s on ready list.\n", thread->getName()); thread->setStatus(READY);
readyList->SortedInsert((void *)thread,thread->getpriority()); //按照线程的优先级顺序往队列插入线程
}
//------------------------------------------------------------------ Thread *
Scheduler::FindNextToRun ()
{
int p;
return (Thread *)readyList->Remove();//每次都返回优先级最高的线程 }
五、调试记录
首先是阅读理解源代码,了解到当前nachos的调度策略是FCFS,然后通过查看List,Thread和Scheduler类理解其实现方法,然后在尽量少改动的情况下进行修改,并通过测试运行。本次实验较为简单,在调试的过程中基本没遇到困难。
六、实验结果及分析
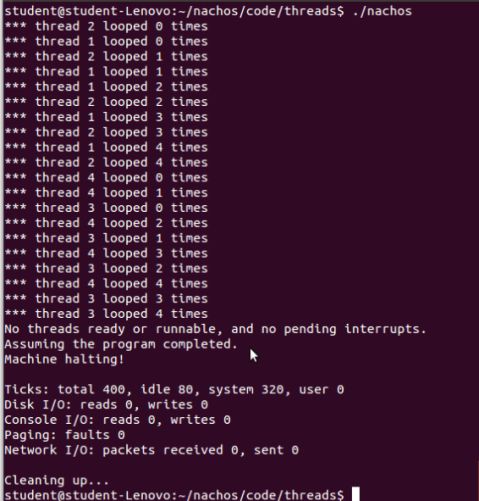
结果分析:可以看出,线程执行的顺序不是在ThreadTest中的生成Threads(1,2,3,4,5)的顺序,而是按照优先级的顺序调度的。首先从等待队列中找一个优先级最高的线程,然后把当前运行的线程加入到等待队列中,然后再运行。
七、实验总结
Nachos默认采用FCFS的调度策略,线程一旦占据了CPU便会一直运行到结束或者阻塞。为了实现具有优先级的调度策略,对等待队列的进入方式进行修改,使线程按照优先级进入等待队列的相应位置,这样当CPU选择线程执行时,优先级高的线程就先执行了。
通过本次实验,自己对线程的调度有了深入的体会,并且动手实现了具有优先级的线程调度策略,对Nachos操作系统有了进一步了解。
Laboratory 10:设计并实现具有二级索引的文件系统
一、实验目的
1、理解文件系统的组织结构
2、扩展原有的文件系统,设计并实现具有二级索引的文件系统。
二、实验设计思想
Nachos的文件系统中保存文件内容所在扇区索引的“文件头“目前只占用一个扇区,为了可以使Nachos文件系统创建较大的文件,将”文件头”扩大到两个扇区,也就是实现二级索引。
三、实验分析
已知在文件头的定义中描述了:
#define NumDirect ((SectorSize - 2 * sizeof(int)) / sizeof(int)) 为了说明方便,经过实际计算,NumDirect = 30.
二级索引的文件系统的filehdr
首先,通过观察Nachos原有的filehdr(即上图左边的部分),可知Nachos的单级索引的文件系统最大只支持存取29个扇区大小的文件。为了扩展二级索引,取数组的最后一个dataSectors[29]作为存取新的dataSectors数组块的索引,定义dataSectors[0] - dataSectors[28]存取数据所在的块号,dataSectors[29] == -1表示无二级索引块,为正值表示二级索引dataSectors2所在的索引块。当文件超过原dataSectors数组所能能够存取的大小28的时候,通过bitmap为文件头的dataSectors2分配空间,返回的Sector号存在dataSectors[29]中。
fileSys每次读取filehdr的时候,仍然只读取原filehdr,如果想要访问和修改dataSectors2中的内容,则在filehdr中先通过dataSectors[29]获取到dataSectors2的扇区号通过调用synchDisk -> ReadSector(dataSectors[lastIndex], (char *)dataSectors2),读入dataSectors2的内容,然后再进行dataSectors数组29-62号所对应的数据块的读取。
因为本次实验是在实验5的基础上进行更改的,即支持文件的扩展,这就要求不仅要有读取dataSectors2数组的方法,还要可以重新写入dataSectors2的方法。实现方法也就是首先如果需要访问dataSectors2,那么首先调用synchDisk -> ReadSector (dataSectors[lastIndex], (char *)dataSectors2),读入dataSectors2的内容,然后进行各种应用程序的读写操作,最后调用synchDisk -> WriteSector (dataSectors[lastIndex], (char *)dataSectors2), 将更改后的结果写回。
由分析可知,文件系统的二级索引功能的扩展只针对filehdr,所有的修改的都只在filehdr.cc中进行,连头文件filehdr.h也不涉及。
四、关键源代码及注释
bool
FileHeader::Allocate(BitMap *freeMap, int fileSize)
{ printf("NumDirect :%d NumDirect2 : %d",NumDirect,NumDirect2); numBytes = fileSize;
numSectors = divRoundUp(fileSize, SectorSize);
//增加以下变量
int last=NumDirect-1;
int i;
if (freeMap->NumClear() < numSectors)
{
printf("ALLOCATE 失败!!\n");
return FALSE; // not enough space
}
else if(NumDirect + NumDirect2 <= numSectors)
{
printf("###文件太大,空间不足###\n");
return FALSE;//not enough pointer space
}
if(numSectors<=NumDirect-1)
{//此时用不到二级索引
printf("*****Allocate ******一级索引\n");
for(i=0;i<numSectors;i++)
{
dataSectors[i]=freeMap->Find();
printf("%d 映射freeMap %d\n",i,(int)dataSectors[i]); }
printf("****Succeed ALLOCATION***\n");
dataSectors[last]=-1; //why,you should known
}
else{
//此时需要扩展二级索引
printf("*****Allocate ******二级索引\n");
for(i=0;i<last;i++)
dataSectors[i]=freeMap->Find();
dataSectors[last]=freeMap->Find();
int dataSector2[NumDirect2];
for(i=0;i<numSectors-last;i++)
dataSector2[i]=freeMap->Find();
synchDisk->WriteSector(dataSectors[last], (char *)dataSector2);
}
return true;
printf("****Succeed***\n");
}
void
FileHeader::Deallocate(BitMap *freeMap)
{ int i ;
if(dataSectors[NumDirect-1]==-1)
{
for (i=0; i < numSectors; i++) {
ASSERT(freeMap->Test((int) dataSectors[i])); // ought to be marked! freeMap->Clear((int) dataSectors[i]);
}
}else
{
for (i=0; i <NumDirect-1 ; i++) {
ASSERT(freeMap->Test((int) dataSectors[i])); // ought to be marked! freeMap->Clear((int) dataSectors[i]);
}
//放掉二级索引
int dataSectors2[NumDirect+2] ;
synchDisk->ReadSector(dataSectors[NumDirect-1], (char *)dataSectors2);
freeMap->Clear((int) dataSectors[NumDirect-1]);
for(i=0;i<numSectors-NumDirect+1;i++)
freeMap->Clear((int) dataSectors2[NumDirect-1]);
}
}
int
FileHeader::ByteToSector(int offset)
{//这里也需要分两种情况
int temp=offset / SectorSize;
if(temp<NumDirect-1)
return(dataSectors[offset / SectorSize]);
else
{
int dataSectors2[NumDirect+2] ;
synchDisk->ReadSector(dataSectors[NumDirect-1], (char *)dataSectors2);
return(dataSectors2[temp-NumDirect+1]);
}
}
bool
FileHeader::AppendSector(BitMap *bitmap,int fileSize)
{
int addSectors;
int rest;
int needSize;
int i;
rest = numSectors*SectorSize -numBytes;
if(rest>=fileSize)
{//here we needn't allocate new sector
numBytes=numBytes+fileSize;
return true;
}
else
{
needSize=fileSize-rest;
addSectors=needSize/SectorSize+1;
// is there enough place in the bitMap?
if (bitmap->NumClear() < addSectors)
return FALSE;
//在这里要区分加add个sector后是否超出一级索引的范围 int nowSector=numSectors+addSectors;
if(nowSector<NumDirect)
{
for(i=numSectors;i<nowSector;i++)
dataSectors[i]=bitmap->Find();
dataSectors[NumDirect-1]=-1;
}
else
{
printf("\n*********************\n启动二级\n***********************\n");
int j;
for(j=numSectors;j<NumDirect-1;j++)
dataSectors[j]=bitmap->Find();
dataSectors[j]=bitmap->Find();
int dataSector2[NumDirect+2];
for(j=0;j<numSectors+addSectors-NumDirect+1;j++) dataSector2[j]=bitmap->Find();
synchDisk->WriteSector(dataSectors[NumDirect-1], *)dataSector2);
}
//change the NumSector and numBytes in fileHeader
printf("-----Append Sector------:%d\n",addSectors); printf("-----Append fileSzie------:%d\n",fileSize); numSectors=i;
numBytes=numBytes+fileSize;
return true;
} 索引(char
}
int
FileHeader::FileLength()
{
return numBytes;
}
int
FileHeader::FindSectors(int index)
{
if(index<NumDirect-1)
return dataSectors[index];
else
{
int dataSectors2[NumDirect+2]; ; synchDisk->ReadSector(dataSectors[NumDirect-1],(char*)dataSectors2); return(dataSectors2[index-NumDirect+1]);
}
}
void
FileHeader::Print()
{
/*revised*/
int i, j, k;
/*toNextNode 是保留第二个索引节点的扇区号*/
int toNextNode = NumDirect - 1;
char *data = new char[SectorSize];
//test if there is a second node
if(dataSectors[toNextNode] == -1) //没有用到二级索引时的打印
{
printf("FileHeader contents. File size: %d. File blocks:\n", numBytes);
printf("*状态:未启动二级索引*\n打印dataSector中的内容\n"); for (i = 0; i < numSectors; i++)
printf("%d ", dataSectors[i]);
printf("\nFile contents:\n");
//读取文件内容
for (i = k = 0; i < numSectors; i++) {
synchDisk->ReadSector(dataSectors[i], data);
for (j = 0; (j < SectorSize) && (k < numBytes); j++, k++) { if ('\040' <= data[j] && data[j] <= '\176') // isprint(data[j]) printf("%c", data[j]);
else
printf("\\%x", (unsigned char)data[j]);
}
printf("\n");
}
}
else
{
printf("状态:**启动二级索引**\n");
int dataSectors2[NumDirect+2];
synchDisk->ReadSector(dataSectors[toNextNode], (char *)dataSectors2); //1, print the filedre items
printf("FileHeader contents. File size: %d. File blocks:\n", numBytes);
//打印一级索引文件tou
for (i = 0; i < toNextNode; i++)
printf("%d ", dataSectors[i]);
//打印二级索引文件头
for(; i < numSectors; i++)
printf("%d ", dataSectors2[i - toNextNode]);
printf("\nFile contents:\n");
//2,print the content of the first node pointed(一级内容)
for (i = k = 0; i < toNextNode; i++) {
synchDisk->ReadSector(dataSectors[i], data);
for (j = 0; (j < SectorSize) && (k < numBytes); j++, k++) { if ('\040' <= data[j] && data[j] <= '\176') // isprint(data[j]) printf("%c", data[j]);
else
printf("\\%x", (unsigned char)data[j]);
}
printf("\n");
}
//3,print the content of the second node pointed(二级内容) for( ; i < numSectors; i++) {
synchDisk->ReadSector(dataSectors2[i - toNextNode], data);
for (j = 0; (j < SectorSize) && (k < numBytes); j++, k++) { if ('\040' <= data[j] && data[j] <= '\176') // isprint(data[j]) printf("%c", data[j]);
else
printf("\\%x", (unsigned char)data[j]);
}
printf("\n");
}
}
delete [] data;
/*revised*/
}
五、实验结果及分析
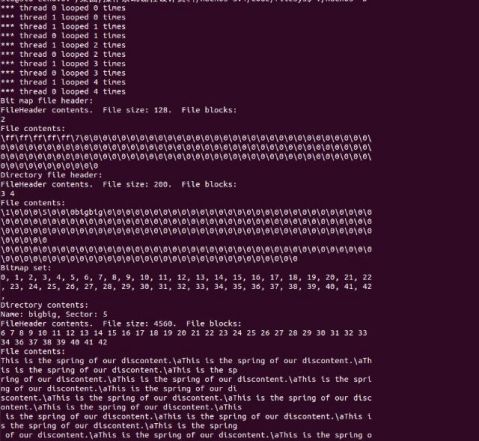
实结果分析:
Directory contents:
Name: bigbig, Sector: 5
FileHeader contents. File size: 4560. File blocks:
6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 36 37 38 39 40 41 42
原有的nachos 系统中,一个索引节点,一个扇区的大小事128byte,所以,可以保存32个int类型的元素。
private:
int numBytes;//Number of bytes in the file
int numSectors;//Number of data sectors in the file
int dataSectors[NumDirect];//Disk sector numbers for each data //block in the file
其中dataSectors数组最多有30个元素,改为二级索引时,最多有29个有效的元素,加上第二个索引的扇区一共可以有效指向文件的扇区最多有29+32=61个,这个Name:bigbig的文件所有占有的最多的扇区数目也就是
34-5+42-35=36 ,符合。说明实现了二级索引节点的文件系统。
六、实验总结
本次实验中,为了使Nachos文件系统创建较大的文件,将”文件头”扩大到两个扇区,也就是实现二级索引。进一步了解了文件系统里面的概念以及实现细节的部分。深刻的理解了对于索引式的文件存储管理方式中,文件在磁盘上的扇区号如何在索引节点中保存,索引节点空间如何扩大成为使用两个扇区的索引等问题。同时,注意了对磁盘操作时需要写回磁盘中的操作。
-
操作系统课程设计实验报告(附代码)
操作系统课程设计报告题目银行家算法设计学院专业班级学生学号指导教师1摘要银行家算法是一个用来预防系统进入死锁状态的算法用它可以判断…
-
操作系统课程设计实验报告
操作系统课程设计实验报告学部专业班级姓名学号指导教师摘要目录1概论2系统设计3系统实现4系统测试5结论参考文献附件摘要操作系统是计…
-
操作系统课程设计实验报告(以Linux为例)
操作系统课程设计实验报告学号姓名苏州大学计算机科学与技术学院20xx年9月操作系统课程设计实验报告目录目录1一实验环境2二实验报告…
-
何洲操作系统课程设计实验报告
武汉工程大学计算机科学与工程学院综合设计报告设计名称操作系统综合设计设计题目线程同步学生学号120xx80205专业班级学生姓名何…
-
操作系统课程设计实验报告
题目题目编号院系班级小组成员操作系统课程设计实验报告书售票员与乘客信号量操作2计算机科学与技术软件服务与外包学院11级9班组长杨扬…
-
操作系统课程设计试验报告格式
四川大学操作系统课程设计报告学院专业年级组编号组成员软件学院第X组乔心轲姓名0743111340学号张雯姓名XXXXXXXX学号康…
-
计算机操作系统课程设计报告
《操作系统原理》实验报告院(部):管理工程学院专业:信息管理与信息系统实验项目:实验一二三五班级:信管102姓名:学号:目录引言.…
-
操作系统课程设计报告
操作系统课程设计报告专业学号姓名提交日期操作系统课程设计报告设计目的1本实验的目的是通过一个简单多用户文件系统的设计加深理解文件系…
-
操作系统课程设计报告
上海电力学院计算机操作系统原理课程设计报告题目名称编写程序模拟虚拟存储器管理姓名杜志豪学号20xx1798班级20xx053班同组…
-
操作系统课程设计报告
课程设计说明书设计题目操作系统课程设计班级信管学号姓名山东科技大学20xx年12月15日课程设计任务书学院信息学院专业信息管理与信…
-
系统设计实验报告内容
实验项目案例名学生饭卡管理系统一实验目的能够正确运用系统设计的过程与方法结合一个模拟课题复习巩固管理信息系统中系统设计知识提高系统…