前端整个javascript中的学习总结
一 :javascript 的组成
Javascript是一门轻量级的脚本编程语言
由ECMAScript DOM BOM 这三部分组成
1、 ECMAScript(4 5) :定义了JS里面的命名规范,变量,数据类型,基本语法,和操作语句最核心的东西等
2、 DOM document object model 文档对象模型
3、 BOM browser object model 浏览器对象模型
第一块: ECMAScript
1、命名规范 避开关键字 保留字 (1、在JS当中严格区分大小 2、驼峰命名法 首字母小写,其他有意义的单词首字母大写 3、可以使用数字 字母下划线 和$符号----数字不能作为首位)
------------------关键字:在JS当中有特殊意义的字
保留字:未来可能成为关键字的
2、变量 :可变的量
JS当中的变量是个抽象的概念,用来存储值和代表值的!
在JS当中定义一个变量非常简单 var 变量名=变量值;
=是赋值操作,左边是变量名 右边是存储的值
JS当中的变量是松散类型的,通过一个var 变量名就可以存储任何的数据类型!
3、数据类型
Js当中的数据类型的分类
1基本数据类型 :由简单的结构组成
数字number 字符串 string 布尔 boolean null undefined
2 引用数据类型 :结构相对复杂一些的
对象数据类型:object (数组和正则 都是对象数据类型)
函数数据类型:function
具体的数据类型详解
1,number 数据类型:整数 负数 0 小数 NaN (不是一个有效数但是他属于number类型的)
NaN==NaN是不相等的
isNaN检测是不是一个有效的数,是一个有效的数返回false 不是一个有效的数是true ,如果检测的值不是number类型的 浏览器会默认的转换成number 类型的 然后在判断是否是有效数组isNaN(”123”) 先经过Number(“123”) 转化成123,Number 强制将其他的数据类型转化成number 要求如果是字符串的话一定是数字才可以转化; 案例:Number(“12px”)=èNaN
非强制数据类型转化:parseInt parseFloat
parseInt:从左到右一个个查找,把是数字的转化为有效的数字,中途如果遇到一个非有效的数字就不再查找了!
Console.log(parseInt(“12px”));===>12
parseFloat:和上面的一样只是可以多识别一个.点
console.log(parseInt(“12.333px”));-------------------12
console.log(parseFloat(“12.2333px”));--------------12.2333
案例:var =Number(“12px”);
if(var ==12){
console.log(12);
}else if(var ==NaN){
Console.log(“我是NaN”);
}else{
Console.log(以上俩个条件都不成立);
}
重点2.boolean !一个叹号是取反,先将值转化为布尔类型值,然后再取反
数据类型转化的规则:
判断一个值是真是假,只有 null 0 NaN “” undefined 为假 其余的值都为真 ,[] {} 空数组和空对象都为真
如果俩个值比较,遵循这个规律:
//val1==val2 俩个值不是同一种数据类型的:如果是==进行比较的话 会进行默认的数据类型转化:
1.对象和对象比较永远不相等 []==[]----false {}=={}---false function fn(){}=function fn(){}-------false
2 对象和字符串 先将对象转化为字符串 然后在进行比较
[]==”” [].toString()-----------经过toString方法把对象转化为字符串[]数组转化为字符串为空字符串 true
{}转化为字符串为“[ object Object]” 所以{}==“” ------------false
3,对象==布尔类型 对象先转化为字符串(toString())然后在转化为数字(Number()) 布尔类型也转化为数字 (true 为1,false为0)
4,对象和数字 : 对象先转化为字符串(toString()) 然后在转化为数字(Number()) []==1false
5数字 和 布尔 布尔转化为数字
6,字符串和数字 字符串转化为数字
7字符串和布尔 都转化为数字
8.null ==undefined true
9.null 和undefined 和其他数据类型比较都是false
3 ===这也是比较 如果数据类型不一样 绝对不相当
Null===undefined false 数据类型不同 false
对象数据类型:
由多组属性名和属性值组成;属性名和属性值是用来描述这个对象特征的!
Var obj={name:”hewenbang”,age:13};------字面量创建方式
Var obj =new Object();实例的创建的方式,
给一个对象增加一组属性名和属性值
Obj.name=”hewenbang”,
Obj[“name”]=”hewenbang”;
修改原有的属性名和属性值,规定一个对象当中的属性名不能重复,如果有的 话就是修改,没有的话就是新增
Obj[“name”]=”zhufengpeixun”;
获取属性值:
Console.log(Obj[“name”]);
如果属性名不存在默认返回的结果是undefined
删除属性名字和属性值:
假删除:obj[“name”]=null;
真删除:delete obj[“name”];
对象数据类中还可以具体的细分:对象类(Object) 数组类(Array) 正则类(RegExp) 时间类(Date)数学函数(Math) 字符串类(String) 布尔类(boolean)
Var obj={};
Var array=[];
Var reg=/^ww$/;
Js中对象,类 和实例的区别: 对象是个泛指,JS中万物皆对象,类是对对象的具体的细分,实例是类中一个具体的事物!
自然界中万物皆对象,可以分为人类 植物类 低等动物类 物体类 每一个人都是人类中的一个实例
Function 数据类型
Function:函数数据类型 相当于一个方法或者功能
------定义一个函数的步骤:开辟一块堆内存地址叫xxxfff111,把函数体中的代码当作字符串存储到这块堆内存地址中;因为这一点:如果一个函数只是定义了,并没有执行的话,这个函数没有任何意义!
在把我们的地址给我们的函数名
Function fn(){
//函数体
//一个功能或者一个功能的实现
Alert(“欢迎来到珠峰培训”);
}
函数体里执行的代码在堆内存里用字符串的形式存储起来

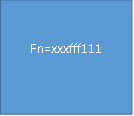 本质的存储 这块堆内存的地址:xxxfff111
本质的存储 这块堆内存的地址:xxxfff111

fn()执行这个函数,首先会形成一个自己的私有地盘,然后把定义的时候,存在空间的js代码字符串当作js代码执行!
Js中函数一个特别大的功能:将实现一个功能的代码进行分装,以后如果用到了这个功能,这些代码没有必要重写了,只需要执行以下这个方法就好了 我们把这个叫做函数的封装!
Function sum(a,b){
Return a+b;
}
Arguments 是函数内置接受参数的机制!(天生自带的)
1, 不管你传递没传递 写没写形参 arguments一直存在
2, Arguments 是一个类数组:以数字作为索引,索引从0开始,还有一个length的属性代表了传递了多少个参数
3, Arguments.callee :代表的是当前函数本身
Function fn(){
Var total=0;
For(var i=0;i<arguments.length;i++){
Var cur =arguments[i]; //argumets是类数组只能用argument[i]这样的形式来获取
Cur= Number(cul);
If(!isNaN(cul)){}
Total+=cul;
}
Return total;
}
闭包:函数执行的时候,会形成一个新的私有的作用域来保护里面的变量不受外界的干扰,我们把这种保护机制,叫做闭包!
外面想用什么就直接在函数里面return什么,函数执行完成的整体就是这个值;
1,如果一个方法没有写return 的话,函数默认返回的值是undefined 在函数体中 return 后面的代码不在执行!
2,控制函数体中的代码执行到指定位置就结束
函数的种类:实名函数,匿名函数
上面的都是实名函数;
匿名函数:函数表达式,把一个匿名函数的定义部分当作一个值赋值给一个变量或者一个元素的事件!
Var fn=function(){}
Fn();
自执行函数--定义和执行一起完成了! (function(){})();
~function(){}();!function(){}();+function(){}();-function(){}();
都是我们的自执行函数
(重点)基本数据类型和引用数据类型的本质区别
Var num1=11;var num2=num1; 把num1代表的值 给了num2这个变量
Num2++;相当于在num2=num2+1也就是在自己原有的基础上加1;也相当于num2+=1;
Console.log(num1);---------------------输出11
Var obj={name:”zhufeng”};
Var obj1=obj;
Obj1[“name”]=”hewenbang”;
Console.log(obj[“name”]);-----------------------输出hewenbang
--------发现基本数据类型没有跟着发生改变,而引用类型跟着发生了改变
基本数据类型和引用数据类型的本质区别
------基本类型操作的是值,而引用类型操作的是新空间的地址
----------基本数据类型是吧值直接给的变量。接下来的操作过程中,直接拿这个值进行操作,可能俩个变量存储的值一样,但你的是你的 ,我的是我的 没有任何的影响,其中一个改变,另一个没有任何影响!(全在栈空间)
--------引用数据类型 1.定义一个变量 2.开辟一个新的堆内存空间,然后把属性名和属性值保存在这个空间,并且有一个空间地址 3.把空间的地址给了这个变量,变量并没有存储这个数值,而是存储的对这个空间的引用地址4.接下来我们把这个地址又给了另外一个变量,另外一个变量存储的也是这个地址,此时俩个变量操作的是同一个空间 5.其中一个改变了空间的内容,另外一个也跟着改变了
JS 中检测数据类型的方式:
Typeof运算符 instanceof 运算符 constructor Object.prototype.toString.call();
Console.log(typeof “zhiufeng”);
Typeof 用法:typeof 要检测的值
返回值:是个字符串 包含数据类型 字符 “string” “number” “boolean” “object” “function” “undefined”
Typeof null -----------------“object”
Typeof 的局限性:不能具体检测object下细分的类型,检测放回的是object
操作语句部分
三个判断语句:if else 用的最多的 可以解决js当中所有的项目需求
三元运算符 应于于简单if else 操作
Switch case 运用于不同值 情况下的不同操作
Var num=10;
If(num<0){
Console.log(“负数”);
}else if(num>0&&num<=10){
Console.log(“0-10之间”);
}else{
Console.log(“大于10”);
}
If条件里面可以是大于 小于 等于 也可以是一个值(判断一个值是真是假) 也可以多个小条件组成 ||(条件一个成立即可)&&(条件都成立才行)
三木运算符
Var num=12;
Num>=0?num=13:num=-8;
?号是条件成立时执行的 : 是条件不成立时执行的 当不需要执行的时候用void 0;来占位
Switch case
Switch (num){
Case 1:
Alert(1);
Break;
Case 2:
Alert(2);
Break;
Default:
Alert(“我是NaN”);
}
每一中case 相当于===在比较,一定要注意数据类型,
循环语句:
For 循环
四部曲:1,设置初始值var i=0, 2,设置循环执行条件i<6; 3,执行循环体中的内容{}包起来的部分 4,每一轮循环完成后都执行我们i++累加操作
For(var i=0;i<6;i++){
Console.log(“hah ”);
}
Break:在循环体中出现break 整个循环就整体的结束了,i++最后的这个累加操作也不知行了,
Continue:在循环体中出现continue 当前这一轮的循环就结束了,继续下一轮循环,i++操作继续执行
在循环体中遇到这俩个关键字,循环体中后面的代码就不执行了
For(var i=0;i<10;i++){
If(i<=5){
i+=2;
continue;
}
i+3;
break;
}
Console.log(i); --------------9
For in 循环
就是用来循环对象中的属性名和属性值的对象中有多少键值对,我们就循环多少次
顺序问题:首先循环键名为数字的属性值,按照从小到大 ,剩下的按照我们写的顺序循环
Var obj ={
Name:”hewenbagn”,
Age:”15”;
Height:”20”;
}
For(var key in obj){
Console.log(obj[key]);
获取属性值:在for in 循环中只能通过obj[key]来获取属性值
}
数组Array
Var arr=[1,2,3,4]----------字面量创建方式
Var arr=new Array();实例创建方式
Console.dir(arr); 看数组的详细信息,包含我们数组中常用的几个方法(找到—prototpe__展开这个里面提供了我们数组中常用的方法)
Var ary=[“zhufeng”,”liji”,28,true,null,undefined,{},function fn(){}];
1,//数组是由多个项组成的,每一项之间用逗号隔开,并且每一项存储的数据类型,可以是任何的数据类型!
2,数组也是对象数据类型,对象数据类型是由属性名:熟悉值组成,健名我们在数组中我们称之为索引 ary[索引]就是获取数组中地索引加1项的内容
3,获取当前数组的长度 ary.length
4,如果我们写的索引超过了总长度 返回的结果是undefined
5,在操作数组的时候我们一般用for循环来操作
数组中常用的方法:学习数组方法注意事项:
1, 方法是做什么用的,实现了什么功能!
2, 传递的参数是什么
3, 返回值是什么
4, 原数组是否发生了变化
关于数组的增删改查
Push----向数组的末尾添加新的元素(一个或者多个),传递的参数就是要添加的元素,返回值内容是添加后新数组的最终的长度 原有的数改变了
Unshift 向数组的开头添加新的元素(一个或者多个),传递的参数就是要添加的元素,返回值内容是添加后新数组的最终的长度 原有的数组也改变了
Ary.push(“14”,”15”);、
Splice(n ,0, x) 向数组的某个位置添加新的内容 ,
从索引n开始,删除0个内容,把索引x放在索引n的前面,返回的是一个空数组,原有数组发生了改变
Splice(n,m) 从索引n开始(包含n)删除m个元素删除数组中指定的某些项 把删除的内容当做一个新的内容返回,原有数组发生了变化
Splice(n,m,x) 把原有数组中的某些项进行替换 先进行删除,然后用x替换,从索引n开始,删除m个元素,用x替换原来的,把删除的内容当做一个新数组返回,原有数组发生了变化
Splice(0,0,x)相当于unshift
Splice(ary.length,0,x)相当于我们的push
Pop删除数组最后一个 返回的是删除的那一项 原有数组发生改变
Shift删除数组最后一个 返回的是删除的那一项,原有数组发生改变
数组的查询和复制
Slice(n,m)从索引n开始包含n找到索引为m数 不包含m然后把找到内容作为一个新的数组返回,原数组没有发生变化
Slice(n) 索引n开始一直查找到末尾 ,把找到数组返回 原有数组不发生变化
Slice(0) 将原有的数组原封不动的复制一份 这属于数组的克隆
Concat 也可以实现数组的克隆
Ary.concat(); 原来的数组也不改变相当于slice(0)
Concat 是实现数组的拼接的
Var arr=[1,2] ; var ar2=[3,4];
Arr.concat(ar2);
将数组转化为字符串
toString 把数组中的每一项用逗号隔开,组成一个字符串 原有数组不变
join(“分隔符”) 把数组中的每一项拿出来,按照指定分隔符隔开
实现数组中数字的求和
Eval 将指定的字符串 变成真正的表达式来执行
5, 数组的排列排序
Reverse 让数组到过来排列
Sort排序 sort(function(a,b){return a-b;});
A代表每一次循环的时候当前这个项,b是后面的这个项;
Return a-b;当前项减去后一项如果大于0说明当前项大于后一项 这样的话就交换位置
第五组:常用但不兼容:ForEach indexOf map
正式课总结
第一周 预解释 和作用域
在刚开始加载页面的时候,浏览器会天生自带一个供我们当期JS代码执行的环境,我们把这个环境称之为“栈内存”,我们也可以叫他为作用域
而且开始加载页面的那个作用域称之为全局作用域(window)
在全局作用域下声明的变量叫做全局变量,(功能用函数)
预解释是发生在当前作用域下的,刚开始只是声明或者定义全局下的var 或者function
只有funciton里面的不是全局的
带var和带function关键字的,进行预解释的时候是不一样的,
var 只是提前声明
function 在预解释的时候就声明和定义
一个function在代码执行之前(预解释的时候)就把声明和定义完成了 ,在接下来执行代码的过程中,如果遇到了函数定义的那块代码直接的跳就OK了
函数执行可以写在任何位置,原因是定义的这个操作在预解释就完成了
函数的执行 sum(1.2.3)会形成一个新的私有作用域(栈内存:执行代码和存储基本数据类型),进来之后第一步首先进行的就是把这个私有作用域预解释
其次代码执行
在函数的这个私有作用域定义的变量都是私有的变量,形成的这个作用域保护里面的私有变量不受外界的干扰,我们把这种机制叫做闭包!
函数执行一次形成一个新的私有作用域,上述的步骤重复一次
//预解释是发生在当前作用域下的,
一般情况下,函数在每一次执行完成,函数新形成的作用域都自动销毁
JS 当中只有window 和funciton会产生作用域:预解释是一种毫无节操的变态机制
1.预解释只发生在当前作用域下
2.不管条件成立与否,都要进行预解释
3.预解释时发生在=的左边,等号的右边不进行预解释
4.只有预解释只发生在同一个JS脚本里面
5,;(function(){})();自执行函数不进行预解释(在全局下不把()包起来的那个function预解释,但是执行的时候形成的私有作用域的进行预解释)
6,函数中return后面的代码也要进行预解释
7.在预解释的时候,如果发现重名了,不重新声明,但要重新定义
fn();//预解释好无节操
var fn=12;
fn();//12();Error: number is a not function;
function fn(){
console.log("预解释好无节操");
}
------预解释是发生在当前作用域下的
如何的判断他的上一级作用域
看存储这个函数的堆内存在哪一个作用域下(比如这个作用域是A),那么这个函数执行的上一级作用域就是A
如何判断是私有的还是全局的
在一个函数中只有预解释声明过的和形参是私有的,否则的话往他的上一级作用域找,如果上一级也没有则继续找,一直找到window作用域
在JS当中,如果当前行JS报错,下面代码都不执行了,(前提是:没有进行异常捕获处理)
全局作用域下才有的这样一个机制
我们return 的是一个堆内存地址,当前这个堆内存在这个fn这个作用域
一个大函数,返回的是引用数据类型(经常是function) 那么当前这个大的函数形成的作用域就不能销毁(里面的私有变量也一直存在)
一个大函数,套一个小函数 给这个小函数绑定点击事件 这种大的作用域也不销毁
// var name="china";
// var age=5000;
// ;(function (name,age) {//是自执行函数的俩个形参变量
// //私有作用域中私有变量name和age,这个和全局的没有半毛线关系
// var name="zhufeng";
// var age=6;
// })(name,age);//把全局变量name和age所存储的值传入到函数中,给函数的俩个形参变量
//函数执行。
//1.如果有形参,先给形参变量赋值
//2.然后在预解释
//然后在执行代码
var name="china";
var age=5000;
;(function (name,age) {//是自执行函数的俩个形参变量
//私有作用域中私有变量name和age,这个和全局的没有半毛线关系
console.log("name+"+name+"age"+age);
})(name,age);
//通过window.属性名 直接查找全局的
//这个是移动端Zepto.js实现的原理
var fn=(function(){
function fn(){};
function sum(){};
function dd(){};
return fn;
})();
//在真是项目当中 ,为了避免全局变量污染,静止使用全局变量(尤其是大公司)我们把要实现的功能用闭包的机制封装起来
;(function(){
function fn(){}
window.fn=fn;
})();
fn();
(function(window,undefined){
var jQuery=function(){}
window.jQuery=window.$=jQuery;
})(window);
绿色经典不容复制
This关键字
this: 是当前行为执行的主体
context:上下文
this:行为执行的主体
函数执行();
方法(),前面有点 那么点前面是谁。this就是谁。 前面没有点的话就是window
自执行函数里面的this 指向的window
给事件绑定的函数中,this指向被绑定的元素
this是谁和
在哪执行和在哪定义没有半毛线关系
第二周
简单介绍为啥要用面向对象
基于对象,描述复杂的数据
面向对象的:第一个任务解决数据的生产问题,用什么方式生产
面向即时方法论也是世界观
实例识别:解决实例识别的构造函数模式
工厂模式的方法,生产出来的“东西”都是object类型的,是个笼统的数据类型
不便于数据的差异化
function shitFactory(shirt){
this.shirt=shirt;
this.size="";
this.weight="";
}
var shirt1=new shitFactory("毛衣");
用new 关键字来执行一个函数
则这个函数就被当成一个类来使用,这个函数就叫构造函数
shitFactory();
创建一个实例 这个实例属于shitFactory类型的属于object类型的
在以这个实例为上下文(content)运行这个shitFactory这个函数(这会shitFactory变成一个函数)
构造函数的作用是初始化
实例识别的作用
方法函数的服用 原型模式
shitFactory.prototype任何一个函数都有此属性 但他只有当函数当成类来使用才有意思
把所有共享的方法都保存在这个属性上 ,这个属性明显是对象类型的
/shitFactory.prototype.holdWarm=function(){console("我是你的小苹果")};
原型模式解决的是类上的方法共享的问题
一个类上的方法都要保存在原型上 所以天生就会保存在prototype上
理解原型连 是实现继承的
数据类型的发展史--基本数据类型-对象数据类型 分组归类
单例模式:(就是给一个堆内存,然后创建一个对象,然后起个名字):把描述一件事物的特性进行分组,放在某个实例下面,某一个特性就是他的属性名
----优点:实现了分组,每一个属性都是啥自己私有的,和别人不冲突,避免了全局变量的冲突,
命名空间:对象是开辟了一个空间,然后我们个这个空间起个名字叫person ,所以这个person既可以叫做对象名也可以叫做命名空间
为了提高逼格单例模式也可以这样写:
var searchRender =(function(){
var n=0;
return {
eat:function(){
console.log(n);
}
};
})();
叫做高级单例模式: 命名空间是一个自执行函数,并且形成一个不销毁的作用域,返回一个对象;
searchRender.eat(); //惰性载入函数,定义了一个不销毁的作用域
-----弊端:虽然实现了分组,但还是太原始了,手工作业模式太落后,不能实现我们的大批量生产,为了解决这个弊端,我们进行了第一次工业革命,引入了我们的工厂模式!
二:工厂模式开始:实际上就是一个函数,把创建一个对象的步骤放在函数中,实现相同代码的封装,以后再创建直接执行我们的函数就OK了,没必要在写一遍了
高逼格的说话:减少代码冗余,减低代码的耦合度,(低耦合,高内聚)
function createPerson(name){
var obj={};
obj.name=name;
obj.age="";
obj.eat=function(){
consoel.log("我是你的小苹果");
}
return obj;
}
var P1=createPerson("cidy");
P1.eat();
工厂模式虽然解决了批量生产的问题,但是我们在喝多情况下不仅需要批量生产,而且还需要进行品牌区分,我们把品牌区分叫做实例识别;为了解决这个弊端,我们进行了一次工业革命,引入我们的构造函数模式
构造函数模式
构造函数模式:实现我们的实例识别;(用new关键字去执行一个函数,则这个函数被当成一个类来使用,这个函数就叫做构造函数)
作用:初始化,实例识别的作用
对象:世界万物皆对象
类:类是对对象的具体细分
实例:是类中的一个具体的实例
Person.portotype//任何函数都有这个属性,但是只有当函数当成类来使用的时候才有意思
JS中的内置类:Number类 String 字符串类(每一个字符串都是他的实例所以字符串拥有这些方法) boolean Object Array Date RegExp,Math,HTMLDIVElement,(每一个div元素对象都是他的实例)HTMLCollection(DOM 方法获取的类数组都是这个方法的实例)
HTMLElement、Element、Node、EventTarget
var obj=new Object();创建Object这个内置类的实例,所以叫做实例创建的方式
var oDiv=document.getElementById("div1");
var oDivs=document.getElementsByTagName("div");
console.dir(oDiv);
开一看都继承了那些类
面想对象编程需要我们了解:继承 ,封装,多态
用构造函数模式创建我们的类和实例
一般构造函数的函数名要大写
和工厂模式的区别:执行的时候不是直接的函数()执行了,而是需要new 函数名()来执行,我们把new这样的形式称之为构造函数执行,通过这种方式,原来的函数名叫做类,这个类就会创建一个实例
接下来像普通函数一样执行,形成一个私有作用域,在这个作用域中浏览器会默认创建一个对象,然后把这个对象当做当前函数行为执行的主体(this),然后给这个行为主体赋值属性名和属性值
function CreateJsPerson(name){
var age=18;
this.name = name;
this.writeCss = function () {
console.log("我叫做" + this.name + ",我会写css啦!");
}
this.writeJs = function () {
console.log("我叫做" + this.name + ",我会写JS啦!");
}
}
var p=new CreateJsPerson("刘骥");
//console.log(typeof p);//"object"
//console.log(typeof CreateJsPerson);//"function"
var p2=new CreateJsPerson("田赛");
//console.log(p.writeCss==p2.writeCss);//false
//这里面的writeCss等都是每一个实例的私有属性
//构造函数模式中的this就是当前的一个实例
//类:所有的类本身就是一个函数,属于函数数据类型
//实例:所有的实例都是对象数据类型的
Call和apply的用法
//基类Function 对应的prototype是一个函数数据类型,,他的名字叫做Empty
每一个函数都是这个内置类的实例,Function.prototype上定义了俩个常用的方法,call 。apply
所以每一个函数都可以个用这俩个方法
call和apply只有一个作用、
1.让函数执行
2,把函数里面的this改变成我们想要的
//想让this是谁,第一个参数是谁就是谁
//----------细节只是点
//在非严格模式下,不传参数this是window 传null是window 传undefined也是window
//----------------严格模式 ”use strict“
//在严格模式I下 不传 参数 undefined 传null 是null 传 undefined 也是 undefined
//在非严格下
instanceof检测一个实例是否属于某个类
in是来检测某一个属性是否属于这个对象,不管是私有的还是公有的
hasOwnProperty :检测某个属性是否是这个对象的私有属性; 只能检测私有的,私有的没有就是false(不管公有的有木有)
构造函数模式:虽然解决了实例识别;但是如果一些属性需要公用,就必须用到我们接下来的模式:基于构造函数模式的原型链模式;
function fn(){
var a=12;
console.log(fn.a);
}
fn.a=13;//私有的属性名
fn();
//JS 中的函数数据类型比较特殊:他一方面是函数数据类型,一方面是对象数据类型;
基于构造函数的原型链模式
function Fn(){
var n=12;
this.a=12;
this.b=function(){}
}
Fn.prototype.c=function(){}
var f=new Fn();//var f=new Fn;//如果不传值的情况下,可以这样写
var s=new Fn();
//console.dir(document.getElementsByTagName("div"));
操作n是操作作用域里面的属性,操作带this的是操作实例里面的属性
//f.c();首先在自己的私有中查找,如果有就是就是私有属性,没有的话通过__proto__找对应类的prototype,如果有的话就是公有属性,如果原型中也没有的话,就继续通过原型上的__proto__找到基类Object的prototype,如果基类原型也没有,就报错了,------》我们把这一级级的查找方式就做原型链
JSON数据形式
json是一种该数据形式,把对象名用""包起来,我们就说这个对象json格式的对象
将json格式的对象,转化为json格式的字符串
json.stringify();//在IE67不兼容只有属性名是""才是JS格式的字符串
i将Json格式的字符串转化为JS格式的对象
JSON.parse();在IE6到7下也不兼容在不兼容的浏览器中报错
为了解决这个问题
var jsonObj=eval("("+str+")");
遗留问题:arguments try catch 数组的高级排序 检测数据类型的四种方法 –20##-6-4
表格排序实例中注意的事项:
//DOM结构的回流,只要我们的节点树发生了变化(当页面中的html结构发生了改变,(增加,删除,))
// 需要重新的加载我们的DOM结构
//优势:事先将要添加的内容都拼接成字符串,然后一次性重新的加载进去,只需要重新的渲染DOM一次就完成
//弊端:每次一的添加,都相当于把原有的字符串拿出来,然后和我们新的拼在一起,最后在重新添加,那么我们之前给元素绑定的方法事件等都消失了,还需要添加完成后重新的绑定
//重绘:给元素的样式发生变化,(例如:让盒子的颜色变成红色)
//动态创建元素
//优势:不会对之前的影响,而且不需要重新获取之前获取的HTMLCollection集合里面的内容会自动的增加(DOM的渲染);
//劣势:非常损耗性能,每增加一个元素都的重新渲染页面,所以你懂的
//文档碎片
//利用DOM创建 ,但是每创建一个就把他放到容器中,最后都创建完成后,在统一的添加到页面中,
RegExp的 全粘贴
//正则:就是一个规则。用来检测和处理字符串的规则
// var str="11";
// var reg=/\d/;//必须写个元字符。要不然就是单行注释
//包含0-9中间的任何一个字符
// console.log(reg.test(str)
// );
//元字符 我们把正则中用来定义规则的那些字符称之为我们的元字符
//1.具有特殊意义的元字符
//\d:匹配0-9之间的任何一个数字,
//\b:匹配一个边界或者空格的
// var b=" ";
// var reg=/\s/;
// console.log(reg.test(b));
//\w:匹配包含(数字 ,字母 下划线)的任意一个字符
// var w="_";
// var reg=/\w/;
// console.log(reg.test(w));
//\n:匹配一个换行符
//\s:匹配一个空白字符(空格,制表格(Tab),回车)
// .:匹配除了\n之外的任意字符
// var n="A";
// var reg=/./;
// console.log(reg.test(n));
//\:本身没意义,用来转译其他字符的
//^:以某一个元字符开始
//$:以某一个元字符结尾
//[xyz]:xyz这个单这三个中的任意一个
// var x="bbo";
// var reg=/[x0o]/;
// console.log(reg.test(x));
//[x-y]:x-y这个范围中的任意一个
//[^x-y]:匹配除了x-y这个范围中的任意一个
//x|y x或者Y
// var x="2";
// var reg=/2|5/;
// console.log(reg.test(x));
//():大正则中的的小正则
// 2.代表数量的量词元字符
/*
* +;出现一到多次
*/
// var n="abcd";
// var reg=/w?/;//出现一次或者多
// console.log(reg.test(n));
/*
* *:出现零到多次
*
* ?:出现零次或者一次
*
* {n}//出现恰好n次
*/
// var n="abcdd";
// var reg=/d{4,10}/;
// console.log(reg.test(n));
/*
* {n,}//至少出现n次
* {n,m}//出现n到m次
* -------------?比较特殊
* 放在普通的元字符后面,代表出现0-1次的量词元字符
* 放在一个量词元字符后面,取消捕获时候的贪婪模式
* 出现在分组中的的”?:" :代表只匹配不捕获
*
*出现在分组中的的”?=" :正向预查匹配
* */
//3.代表的是本身意义的普通元字符
//JS中的任何一个字符都可能是正则的元字符
//实例创建和字面量创建的区别
//1.实例可以识别有效的变量
// var reg=new RegExp(""+num+"");
// //2对于特殊意义的字符在实例和字面量方式中的写法不一样
// var reg=new RegExp("\\d");
//3.想让我们的特殊的字符就代表本身的意义,需要转意
var reg=/^[0-9]+$/;
//分组:改变原有的优先级
var reg=/^[+-]?(\d|([1-9]\d+))(\.\d+)?$/;
var n=0.3;
console.log(reg.test(n));
//[16-85] 1或者6-8之间的或者5
//
var reg=/^[1-9]\d{16}(\d|X)]$/;
//身份证
//分组:可以根据分组获取指定的小的内容,获取指定的内容
//exec 正则中的exec用来捕获正则匹配到的内容 先匹配如果匹配在进行捕获,不匹配返回的结果是null
//把匹配到内容捕获到
//通过正则捕获到的内容是一个数组(__proto__指向的是Array),索引0:是当前大正则捕获到的内容
//index属性:大正则捕获内容的开始的索引
//input属性:我们匹配的那个字符串
//除了0以为索引,分别对应每一个小正则捕获到的内容,索引1就是第一个分组的内容
//正则贪婪的,默认是把最长匹配的内容捕获到
//我们为了优化性能,通常要阻止他的贪婪性 在量词元字符后面在加一个?后
//18到65之间的年龄
var age=/^(?:1[89])|(?:[2-5]\d)|(?:6[0-5])$/;
//中国标准真是姓名
var reg=/^[\u4e00-\u9fa5]{2,4}]$/;
//昵称 只能包含数字字母,下划线,_ - 3位以上
var reg=/^[0-9a-zA-Z_-]{3,}]/;
//手机号
var reg=/^1\d{10}$/;
//邮箱左边@右边
var reg=/^([0-9a-zA-Z._-]+])@([0-9a-zA-Z-]+)(\.[a-zA-Z]+){1,2}/;
/ //正向预测,和负向预测,带条件的正则,但是条件只参与匹配,不参与捕获
// var str="12ab44cd98ef73";//把一个字符中所有不在最右边的数字找出来
// var reg=/(?!^)\d{2}(?!$)/g;//括号里的是条件 !表示非 不等
// alert(str.match(reg));
// var reg=/(?=^)\d{2}(?=$)/;
// var str="abcdefg";
// str=str.replace(/\w/g,function(a,b,c){
// //a第一个参数(argument0)是捕获到的字符串
// //c倒数第一个参数是输入的字符串(是input输入字符串)
// //b倒数第二个参数:捕获到的字符串在输入字符串中的位置
// //如果正则中没有分组,就是这三个参数 如果有分组第二个参数就会增加
// return ++b;
// });
// alert(str);
//var str="234456567";
// var a=["零","一","二","三","四","五","六","七","八","九",];
// str=str.replace(/\d/g, function () {
// return a[arguments[0]];
//
// })
//var str="My name id.{0}.{1}.{2}"
//var a=["zhufeng",38,4,5];
// str=str.replace(/{(\d)}/g,function(){
// return a[arguments[1]]
// });
// alert(str);
var a=[1,2,3,4,6,7];
var b=[2,3,5,8,9,10];
var ary= a.concat(b);
var newary=arr.sort(function(a,b){
return a-b;
});
console.log(newary);
var reg=/\d/;//一个模型表示了任意一个数组的字符
var reg=/888/;//直接量的方式定义了一个正则
var reg=new RegExp("888");
var re=/8{3}/;
//原子:构成正则的最小单位
//元字符:表示某些特定字符的特殊符号,比如\d,+,?*,\w
var reg=/^\d+$/;//包括四个元字符:^ $表示位置的元字符,|d表示数组,+表示数量;元字符的分类
//正则的作用:用来验证一个字符串是否满足这个正则表达式的模式的定义这个规范,并且满足验证的查找出来,
//用术语来表示匹配,捕获
//用术语来表示,匹配(test),捕获(exec)
var str1="abcd1234";
var str2="164939";
reg.test(str);//
var reg.exec();//exec只执行一次,查找一次
//exec是一个数组,他把捕获到的项目放数组里面,并且给这个数组添加俩个自定义的属性,,一个叫:index,捕获到的字符串在元字符串的位置,另外一个叫input,就是指元字符串,(专业术语叫:输入字符串)
//正则是既懒惰 又贪婪 (模式匹配符)---global简写g
alert(reg.lastIndex);//lastIndex下一次匹配开始的位置
var str="abc849t90";
alert(reg.lastIndex)
reg.test(str);
alert(reg.lastIndex);
alert(reg.lastIndex);
//一但找不到结果 他就重新赋值为0
var str="abcba";
var reg=/^(\w)(\w)\w\2\1$/;
//分组的引用
第三周 盒子模型
offsetLeft offsetTop offsetParent
元素相对于offsetParent这个元素产生的偏移量
在默认情况下所有元素产生的偏移量是相对于文档产生的偏移,只要是能产生距离就会产生偏移(从自己的border外面计算到浏览器的左边和上边)
形成新的层级关系的时候(offsetParent这个元素),这个元素的offsetLeft就会从他自己的border外面计算到 offsetparent这个元素的border外面
OffsetTop就会从他自己border的外面计算到offsetParent这个元素的外面
scrollTop:上面卷出去的高度
scrollLeft:左面卷出去的高度
clientWidth:内容加上左右padding
clientHeight内容的高加上上下的padding
offsetWidht: 内容的宽加上左右padding+左右边框
offsetHeight:内容的高+上下padding+上下边框(不算溢出的内容)
scrollHeight:实际的高度(包括溢出的)+上下padding(如果没有溢出此时和clientHeigth)如果内容有溢出只包含上padding
scrollWidth:实际的宽度(包括溢出的)+左右padding(如果没有溢出此时和clientWidth)如果内容有溢出只包含左padding
主要有这个方法:
Function offset(ele){
l=ele.offsetLeft;
t=ele.offsetTop;
p=ele.offsetParent;
while(p){
if(window.navigator.userAgent.indexOf(“MSIE 8”)>-1){
l+=p.offsetLeft;
t+=p.offsetTop;
}else{
L+=p.offsetLeft+p.clientLeft;
T+=p.offsetTop+p.clientTop;
}
P=p.offsetParent;
}
Return {left:l,top:t};
}
第四周 动画
GetCss()方法
SetCss()方法
Animate()方法
function getCss(ele,attr) {
if ("getComputedStyle" in window) {
return getComputedStyle(ele, null)[attr];
} else {
if (attr == "opacity") {
var val = ele.currentStyle.filter;
var reg = /alpha\(opacity=(\d+(\.\d+)?)\)/;
if (reg.test(val)) {
return parseFloat(RegExp.$1) / 100;
} else {
return 1;
}
} else {
return ele.currentStyle[attr];
}
}
}
function setCss(ele,attr,value){
switch (attr){
case "opacity":
ele.style.opacity=value;
ele.style.filter=alpha(opacity=value*100);
break;
case "zIndex" :
ele.style.zIndex=value;
break;
case "float":
ele.style.cssFloat=value;
ele.style.styleFloat=value;
break
default :
ele.style[attr]=!isNaN(value)?value+"px":value;
}
}
function animate(ele,obj,duration,fncallback){
var oChange={};
var oBegin={};
for(attr in obj){
var begin=getCss(ele,attr);
var target=obj[attr];
var change=target - begin;
if(change){
oBegin[attr]=begin;
oChange[attr]=change;
flag++;
}
if(flag===0)return ;
}
var interval=13;
var times=0;
clearInterval(ele.timer);
ele.timer=null;
function step(){
times+=interval;
if(times>=duration){
clearInterval(ele.timer);
ele.timer=null;
for( attr in obj){
setCss(ele,attr,obj[attr]);
}
if(typeof fncallback=="function"){
fncallback();
}
}
for( attr in oChange){
var value=times/duration*oChange[attr]+oBegin[attr];
setCss(ele,attr,value);
}
}
ele.timer=window.setInterval(step,interval);
}
-
javascript学习总结
脚本语言:1、介于html与java,php之间的语言,能力比java,php弱,比html强,单独使用起不了大作用,需要配合其他…
-
javascript学习总结
一JavaScriptJavaScript被设计用来向HTML页面添加交互行为JavaScript是一种脚本语言脚本语言是一种轻量…
-
Javascript学习总结
JavaScript学习总结1234567JavaScript概述3数据类型3数字3字符串3布尔类型4函数4对象4a创建JavaS…
-
JavaScript考点总结
Netscape公司为了扩展其浏览器的功能开发了一种名为LiveScript的脚本语言Sun公司联合宣布把其更名为Javascri…
-
JavaScript学习总结
JavaScript学习总结由于以前JavaScript用的比较的少所以对JavaScript的认识非常的肤浅这周看了蛮多关于ja…
-
JavaScript学习总结
1、JavaScript变量可以使用var事先进行声明,也可以用赋值语句隐藏声明。对于一个变量,它存在指的是它拥有值。检查一个变量…
-
javascript 总结
JavaScript总结PreviousPageNextPage现在您已经学习了JavaScript,接下来该学习什么呢?Java…
-
javascripe学习笔记自己总结
Document对象内容集合document文挡对象-JavaScript脚本语言描述——————————————————————…
-
Javascript之jQuery学习总结
Javascript之jQuery学习总结三个学期来我小组按照自己的分工各自展开了自己的学习与实践而作为小组成员之一我主要负责网页…
-
javascript学习总结
Javascrip基础与实践教程电子工业出版社一javascrip语言概述1ECMAScript是许多软件厂商对JavaScrip…
-
javascript学习总结
脚本语言:1、介于html与java,php之间的语言,能力比java,php弱,比html强,单独使用起不了大作用,需要配合其他…