分场景剧本
<<弹跳青春.>>分场景剧本
一个步入大学的懵懂青年,在被期待的校园里经历友情,爱情的洗礼。黄新宇由最初的怀抱梦到梦想模糊。在大二这个人生的重要节点他面对诱惑,面对梦想,面对未来,他的决定再一次碰撞之中有了新的抉择。
1、黑屏,艺术白体字。
一边受伤,一边长大,这便是青春。
2、寝室,早晨。推镜头。旁白。
黄新宇,一个经历大一沉沦刚步入大二的男生。
3、寝室,早晨。
闹钟响起,铃声为:
新宇挣扎的从床上爬起,寝室里的其他室友还在熟睡之中。穿上衣服,起床洗漱等,收拾完自己的床铺后。
新雨喊道:起床了,快上课了。
之后,一个人拿着书走出宿舍。
无人回应。
4、食堂。早晨。
此刻的食堂的人还是比较少的。新宇放将手中的书放在桌上,打早饭。周围吃饭的人有说有笑,只有他在一个不被注意的角落吃着清淡的早餐。
5、课堂上。
老师在讲台上激情的讲述着某节知识点,幽默的讲课模式让课堂欢声笑语,镜头慢慢由老师往后拉。
新宇急急忙忙地往教室赶去。
老师:清最后登场的黄新宇同学起来回答一下这个问题。
新宇:老师能给我一分钟的时间吗?因一些事情而迟到了。
老师:姗姗来迟,还如此大牌,不愧是我们系的第一名。可以。
新宇思考片刻,便对答如流。
全场哑语。
6、校园走道。
林建平:怎么今天上课迟到了,是不是又玩游戏玩过头了?
新宇:哪有?今天我和她吵架了。
7、校园小径。与女朋友散步。下午。
女;,没什么可说的了,我们分手吧。
男;皱眉头。
女;能不能不要再用这种眼神看着我!
男:疑惑的表情,一挑眉毛。
女:总是这样,总是这样!你能不能考虑下我的感受?总是一幅漠不关心的模样,总是用表情代替一切。
男;眼神黯淡了一下,略低下头。
女(绝望);一年了,你还是这个样子、、、、、、分手吧。
{分手吧,分手吧为在男孩脑海中的回音]。
(男生的视角)女孩子转身离去。{画面淡出}]
8、寝室。晚上。
(画面是他与朋友在寝室大游戏。)光线昏暗,几个男生在一起打游戏。打游戏的键盘声,桌上堆积如山的泡面与杂物。
新宇,电脑电源开启的次数与泡面的的数量成正比。时钟的指针的旋转。(岁月的流逝,面对失恋的一种发泄方式。)
9、公园的路上。黄昏。
黄昏,新宇走在路上。路面的汽车匆匆急速飞驰。红绿灯闪烁变换。
10、公园的草坪上。黄昏。
一个人躺在草坪上,紧闭双目。
{一对情侣}。
女;你以后会娶我吗?
男:会啊。
女:可是你什么都没有,我爸妈肯定不同意的。怎么办?亲爱的。
男;没关系,宝贝。不要考虑那么多嘛,那些事情我来考虑,傻瓜你就不要考虑咯。、、、(甜蜜、温馨)
11、傍晚,天略黑。公路边。
黄昏的天空,略带一丝霞红。黄昏的来临面对的是黑夜的降临,阐释着今日的劳作。对于上班族,是下班的时间[马路上急速飞驰的汽车,匆匆的,];
12、傍晚,天略黑。校园门口。
对于学生,是回家的时间。下午最后一节课后即将迎来国庆假期,学生都从教室里涌出,说笑声,打闹声,一天虽然有些疲惫,但是收获的心情还是很好的。
女:放假啦,轻松。
女2:嗯嗯,我要回家和爸爸去外地玩玩,你呢?
女:我就在家啊,然后和朋友聚聚贝。。
新宇默默地看着这人潮,拿起手中的电话,拨打了妈妈的电话。略带激动的他,脸上露出微微的笑容,但很快又恢复了原先的平静的表情。
妈妈:新宇啊,在那边生活得可好,在那边一个人要学会好的照顾自己,不能生病了,要多吃米饭,少吃路边的小吃,那些都不干净,我和你爸爸都挺好的,放假了,回不了家就和朋友出去走走,别总是呆在寝室。(电话里传来妹妹“哥哥,我好想你”)得声音。
新宇抑郁的脸色在夕阳的照射下显得模糊不清:妈,你和爸不用担心我,我很独立,这几天我会打打球,学习的。我一切都好,不要牵挂,我可以的。
妈妈:嗯嗯,我和你爸、、、、妈妈的声音慢慢得模糊。新宇的背影消失在画面中。]
13、晚上。寝室。
[寝室里。他摸着往日打游戏的键盘,收拾这些天吃完的泡面盒。躺在床上,拿出日记本
(闪回当时进入大学时的自己。新语被这双肩背包走在校园中,表情富有思想,与一同进入大学的迷茫的大学生相比更显得有思想,有理想。身穿靓丽的颜色,俩耳塞着耳机、走路的节奏感,侧面的烘托。)。写日记:异地求学的我,在沉沦的岁月里,理想被消磨已剩无几,面对当初的理想自己是沉睡还是崛起、、、、]
14、篮球场。黄昏。
[假期里的一个黄昏时分。新宇和他玩得比较好的一个朋友林建平打球。
失去平静心情的他,似乎如跃动的篮球蠢蠢欲动。篮球撞击篮板发出“哐哐、、、、、”的声音急速而刺耳。
林建平:小黄,今天你怎么了?怎么总是不进球?
汗水顺着脸颊旁滑落,新宇没有说话,手带球更用力,蓝球再双手之间穿梭着。。
林建平:小黄,你这是在干什么?
新雨:为什么篮球一定要穿越篮筐?
林建平;哈哈,这是他的宿命和目标嘛。它不进去我们怎么能赢,怎么迎来大家的喝彩呢?
新雨:恩,不一定吧,不过他也是牛气的哦。你觉得他是怎么做到的呢?
林建平思索片刻,停下手: 因为建平:ng做到成功的呢?能获得成功呢.i篮球可以再用力不同的情况作出相应的变形,而我们却没有没有因为环境的不同而作出相应的变换,目标也没有那么的坚定。
新雨:呵呵,也许青春就是一边手上以边长大。
说完,俩人又继续激烈的搏斗。
心中思绪澎湃的他。拾起手中的球,向篮筐砸去,内心在呐喊:我可以的。
这次的的撞击声敲击着每一个人的心灵,似乎时间瞬间凝固,只有被撞击的篮球在高空中划出美丽的弧线。美丽过后往往是悲剧的开始,入迷的撞击声,身临其境的忘我,球砸向新雨。新宇眼前一黑,可是心中的理想却一直在鼓励她:新宇未来的你是优秀的,坚持。
躺在地上有些昏迷的新宇面目显得有些沧桑。无力爬起。就这样躺在篮球场地。
镜头由远及近,推倒新宇面目表情至眼睛
15.篮球场,日,外
[又是一天正常的早上,新雨照常的早起。迅速的洗漱完后的他,急忙的叫醒还在熟睡的室友。他一边清理寝室一边等待室友洗漱一起吃早饭。上课时也不再坐在角落里,而是和好朋友一起坐在中间依旧认真地听课。下午和朋友一起打篮球,周围围满了观赏者,时不时传来尖叫声和呼声。
黄昏时分再一次的来临,新雨躺在舒适的草地上。晚霞如一幅山水画,虽是黄昏却美丽无瑕。
青春的味道是苦涩中夹杂着一点甜味,长大的历程并不是一帆风顺的,我们必须理解受伤是最好的成长法则]结束。
躺在地上的新宇逐渐恢复力气,眼睛慢慢的望向太阳升起的地方。
这是的阳光虽已是黄昏,但依旧青春诬陷,。
上帝关上一扇门总会开启一扇窗[画外音]。
zy
第二篇:章2-动画创作技术(剧本、场景、分镜头)
第二章动画创作技术
2.1前言
动漫产业被称为21世纪知识经济的核心产业之一,已逐渐成为许多国家经济发展的重要产业和新的经济增长点
相信大家对动画这个名词都不陌生,动画随着时代的进步渐渐走近人们的生活,那么,动画是什么?
动画,顾名思义,是动起来的画面。它是通过连续播放一系列的画面,给视觉造成连续变化的图画。它的基本原理和电影、电视都是一样,是“视觉暂留”的原理—人的眼睛在看到一个画面之后,在1/24秒内不会消失。那么,利用这个原理,在一个画面还没有消失之前,播放下一个画面,就会给人造成一种流畅的视觉效果。
动画的分类没有确切的规定。如果从制作的技术和方法手段来看,可以分作以手工绘制为主的传统动画,和以计算机为主的电脑动画。如果按照动作的表现形式来区分,又可以分作基本接近自然动作的“完善动画”,和简化、夸张的“局限动画”。当然,如果按照空间的视觉效果来看,自然又有2维、3维动画之分了。
有一种新的动画框架,叫交互式高效动画框架,如图1所示。系统的输入是创意良好的故事或剧本,通过分镜头描述生成模块对故事和剧本的分析理解,得到分镜头描述信息,生成分镜头剧本;场景和角色建模模块根据分镜头描述信息,通过用户交互半自动地创建角色以及虚拟角色表演活动的场所;角色动画模块利用运动捕获技术赋予角色动的元素;渲染与合成模块将动画场景以及在其上表演的虚拟角色用多种方式绘制出来;动画制作模块渲染后的结果通过后期制作模块进行合成和剪辑,最后形成一部创意动画影片。
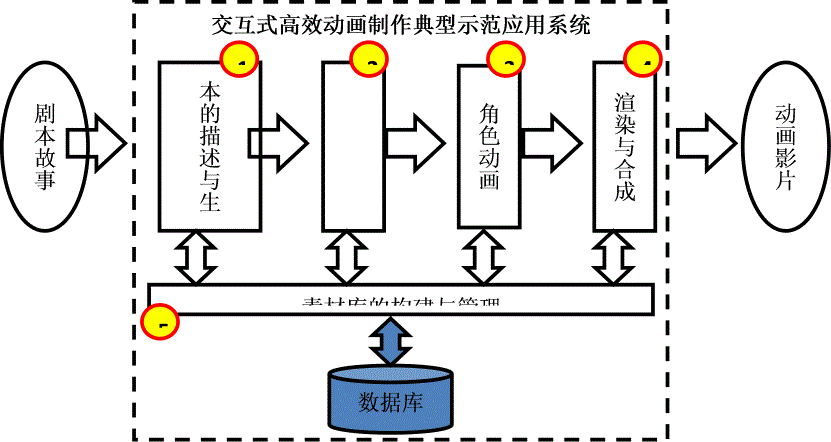
图1
2.2剧本
2.2.1 剧本的概念与意义
这里说动画,我们先来看看动画剧本。
动画剧本,就是由动画讲述出来的一个故事。动画片是影视剧的一种类型,那么谈到动画剧本,也要从影视剧本的基本概念谈起。
如果说视听语言是一种特有的讲述故事的方式,那么剧本就是未来视听语言的一种文字表述:美国最畅销的电影剧作家—悉德·费尔德,在谈到电影剧本这一基本概念的时候,首先就强调了“它既不是小说,也不是戏剧……而是由画面讲述出来的一个故事。”
从功能性上说,一部影片或者动画片的创作,也是从剧本开始的。剧本是整个片子的基础,它不仅是作品创作的第一道工序,也是未来影片成败的前提。
影视剧本的创作,是为今后影像拍摄做准备、打基础。那么在剧本的创作中,就不仅要把故事讲好,把人物塑造好,还有一个很重要的要求:你的剧本是否具有视听表现力。当文字隐藏到作品背后,故事、人物以及细节都要用视听语言来表达的时候,这部作品的感染力是削弱了,还是会因为影像的独特表现力而增长了?如果没有达到这些要求,那么无论剧本之后的工作做的多好,画面制作的多么精妙,这个作品只能是一个失败的作品。
在我们阅读小说的时候,即使没有画面,我们也经常会被那些优美、独特的文学表达方式所打动:精妙的比喻、优美的景物描写、细腻的心理活动……然而这些文学的表达方式,却是无法直接转化为影像或声音的。你所展现出来的,必然也只能是具象的东西,而“感情”、“氛围”这些内部的抽象的东西只能让观众自己去感受、体会。正如悉德·费尔德所说:“剧本涉及的都是外部情景,是具体细节。”
因而,富于视听表现力的情节设置,简洁准确的语言才是剧本所需要的特征。
2.2.2自然语言理解技术在动画领域的应用现状
由于自然语言理解技术和计算机动画技术的不断发展,探索从自然语言故事到动画剧本、再到图形图像的动画自动生成技术,取得了阶段性的成果。
目前该领域的研究主要包括有:
交互式情节自然语言指令驱动的动画[1],这种技术在高层次界面中采用了自然语言的方式描述运动,并按计算机内部解释方式控制运动,虽然用户描述运动变得自然和简捷,但对运动描述的准确性却带来了不利因素,甚至可能引起模糊性、二义性问题。解决这个问题的途径是借鉴自然语言理解、机器人学、人工智能中发展成熟的语义分析、反向运动学、路径设计和碰撞检测等理论方法。
交互式故事系统[2],它是支持交互式情节的动态产生、管理和冲突解决的计算框架,它让用户充当故事的主角来确定当前的行为,同时根据角色的说明、关系、目标等来控制角色的行为。该框架的核心模块是一个情节管理器,它的输入是一系列初始情节条件,输出是角色动作序列。
自然语言故事到计算机动画的翻译[3,4],从故事篇章中推导出脚本、角色动作生成、动画环境构造和虚拟摄像机定位,但自然语言中的对话理解和篇章二义性的处理方面不够稳健。比较著名的国内外系统还有多瑞塞利格曼开发的一个通用的、由文本描述生成图像(非连续动画)的IBIS系统[5]、马里兰大学的PETS系统[6],以及“天鹅”系统[7,8]和LIREC系统[9]。
近年来这方面的研究更多转移到文本指导的动画场景构建(text-to-scene)的实际应用。Richard Sproat的WordsEye系统[10]利用自然语言处理技术对故事场景描述进行分析,确定动画角色特征及方位、朝向、动作,指导三维场景的构建,WordsEye系统要求文本描述中包括大量明确的方位信息。Oshita[11]将自然语言理解与运动库相结合,从脚本式输入文本中抽取语义信息来指导运动的搜索与重组织,进而构建动画场景。
2.2.3 故事理解
不论是怎么样的故事,要生成一个剧本,对故事的理解都是最为重要的一个部分。故事理解是人工智能中的一个重要基础问题,是计算语言学的一个终极目标,它本身包含了自然语言处理的各个困难问题:文本语义理解、知识获取、建模与推理、认知理论等。
早期的故事理解工作大都基于大量的手工知识,研究者通过构建复杂的知识模型和推理机制来进行理解工作。Schank等[12]使用脚本、计划和目标这些知识结构来构建故事理解程序。BORIS系统[13]将这些知识结构和其他的知识结构相结合:包括情感、人际关系、空间-时间图以及故事情景。自上世纪80年代以后,受困于故事理解的健壮性问题,不少研究者致力于研究广覆盖的浅层故事理解问题。目前研究界尚无法解决广覆盖下的深层理解问题,但有两种可行的探索方略:其一是从一个广覆盖的浅层理解问题入手,逐渐加深理解的深度[14],将现有的自然语言理解的成果,比如信息抽取,应用到故事理解的工作中,期望通过这种结合来缓解知识获取和歧义消解这两方面的压力;其二是通过一个窄覆盖的深层理解问题入手,逐渐扩展方法的适用面[15]。近年来故事理解新的研究成果屈指可数[15][16]。究其根源,在于研究者陷于迷惘:如何使得故事理解程序能处理的不仅仅是几个小故事?现有的故事理解的方法无一例外的遇到了知识工程上的瓶颈:如何获取并处理海量的知识。这本身是一个非常困难的问题。另一方面,已有的研究或多或少的忽略了语言处理中的歧义性问题,而是把注意力放在了下一步的知识推理上。而歧义是在自然语言处理中不可避免的问题,也是自然语言处理的主要对象。因此,对于今后的故事理解研究者的一个挑战是如何将现有的较为成熟的统计自然语言处理方法应用到故事理解中,这其中一些例如统计词性标注已经得到了应用,而一些例如浅层句法、语义分析则给故事理解中的语言理解提供了非常好的方法[17][18]。
2.2.4 从自然语言描述的故事中生成动画情节的技术
从自然语言描述的故事中生成动画情节的技术,早在上个世纪70年代就已经开始有人研究。 Rumelhart[19]在1975 年提出了一种基于故事分析的形式化文法,并为故事文法拟定了11条句法规则和相应的语义解释,试图用这一系列规则获取句法结构以及故事的语义。但其中有不少的缺陷:表达力相当有限,不容易理解一些复杂的形式及场景,存在明显的句法导向性(syntax oriented)。这些方法不能够满足提取深层次语义信息的要求。Schank[20]提出了依赖于概念上、以相关技术为基础的脚本去理解一个故事的理论。这一理论把每个故事看作由一系列的脚本模板组成,而每个脚本模板又由一系列概念驱动的子情节(atom actions)组成[21]。基于这个理念,Cullingford[22]在1978年研发了一个SAM系统,该系统可理解简单故事和回答故事相关的简单问题,并提供多种语言的摘要。1979年,DeJong[23]公布了FRUMP(快速阅读理解和记忆程序)系统,这个系统只是基于一个很简单的原则。之后,Schank[20]的方法经发展成为所谓的MOPs(memory organization packets)[24],它对故事的理解是通过当前信息来预测下一个脚本,这种理解很大程度上依赖于组织记忆单元。SAM和FRUMP系统都存在知识结构不能共享的问题,从而导致它们无法分析脚本以外的非正常故事,实际上现实生活很少的故事能完全满足脚本的标准。此外,Lebowitz[25]还提出了采用情节单元达到故事总结的方法。该方法的核心思想是依照人物角色的感情来理解故事。这一理论假设每个角色在故事发展的每一刻都处于某种角色状态,例如,开心时用“+”,否则用“-”号,其它情况下用“M”表示无关紧要。两个状态及连接它们的语义链构成一个情节单元。
2.2.5 结构化剧本模型
我们提出一种新的剧本模型,即结构化剧本模型。
现在,我们面临的问题是,如何将一个儿童故事分析为一个剧本表现形式,这种剧本表现形式同时要满足人、机两方面的需求:1)对于可能发生的分析错误,能够及时发现并修改;
2)能够将结果方便地呈现给导演,并且提供简单智能的修改调整工具;
3)同时能够提供所有必须的信息供动画生成步骤修改。
以上这些要求互相交织纠缠在一起,又有互相冲突矛盾之处。例如,为了提高可读性,最终的表现形式需要简明扼要。而对于动画生成的任务来说,更完备的信息则更有用。
为解决这个问题,我们将表示模型拆分为两个子模型:叙述模型N和剧本模型S。叙述模型表示了儿童故事的自然语言理解结果,剧本模型面向用户(人或者计算机)。特殊地,S并不是一个“物理存在”的模型,而是N的一个视图。
一个叙述模型N是对于故事的直译。对于故事中的每一个语句,我们仅区分两种情况:描述性和叙事性语句。描述性语句包括环境描写、外貌描写等,一般是静态的,即不包含角色动作,但可能包括场景构建所需的信息。叙事性语句主要包括动画角色动作,语言及心理活动等。描述性语句提供角色、场景、道具信息,而叙事性语句提供事件流。描述和事件在时空坐标中标记。时间轴由一个带“刻度”的时间箭头组成,分段上可能有具体时间的标记(比如“星期天”、“早晨”等等),也可能仅仅是根据故事发展而自然构成的时间戳。空间轴上离散地标记了故事发生的不同地点。比如说“蛋糕在桌上”,这是一个描述,被分析为(蛋糕,位置,(桌,上)),同时这是在故事开头描述的,所以时间戳是Time0,同时前面分析得到了地点是“房间里”。这样,可以初步把这一句分析为((蛋糕,位置,(桌,上)),Time 0,房间里)。
剧本模型实际上是一个更为复杂的映射模型,将一个简单的叙述性表示形式映射为复杂的剧本呈现形式。比如,有了((蛋糕,位置,(桌,上)),Time 0,房间里)之后,需要将之后所有地点表示为“房间里”的场景都标示上这个蛋糕的描述。对于用户来说剧本的修改是透明的,也就是说用户看到的只是形式化的剧本视图。由于剧本表示形式和叙述表示形式是以一一对应的,这样对于剧本上的每一个修改实际上都能映射到对于叙述层面上的修改,然后这个修改又通过剧本模型的映射反馈到视图上,使得视图的现状和用户的修改保持一致。
2.2.6 剧本元素抽取
另外一点,在拥有剧本之后,剧本的元素抽取也是十分重要的一环。剧本元素抽取的对象主要是故事角色,故事中的道具,时间信息以及地点信息。一般来讲角色名和道具在故事文本出现频率较高,而时间、地点信息大多是“一次性”的,即一个时间、地点词只出现一次。我们针对不同抽取目标的特点采用不同的抽取方法。
剧本元素抽取主要分为三个步骤:文本预处理,候选项抽取和剧本元素判别。首先使用未登录词识别方法和ICTCLAS2009分词工具对故事文本预处理,然后利用词频等信息从分词结果中抽取候选项,最后使用分类器结合规则方法对候选项进行判别,最终得到剧本元素集。系统流程如图4所示。
故事角色名和道具名一般在故事文本中具有较高的出现频率。其分布分为两种情况:一种是在整个文本中高频出现,另一种是只在局部高频出现。根据这一现象,我们采取了TF-IDF和LOC-TF-IDF特征进行候选项筛选。候选项筛选本质上是一个二元分类问题,我们使用已标注的数据及其属性集训练SVM分类器进行分类。
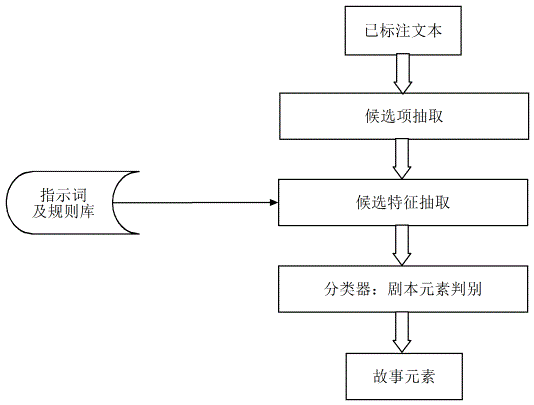
图4 剧本元素抽取流程
时间和地点转换词并不是高频词,一般只在文中出现一次。因此在抽取这些剧本元素时主要根据POS标注结果,并结合构词规则和指示词信息。时间转换词识别规则主要包括时间特征词(例如X天、X年)、时间指示词(例如X以后)、构词规则(例如第二/m天/q)。地点转换词识别规则主要包括地点特征词(例如X省)、地点指示词(例如来到XX)、构词规则(例如名词+方位词)。
另外一个需要解决的问题是指代消解。在故事叙述中,经常会出现用人称代词,如:“他”,“他们”等代替角色。由于童话故事情节比较简单,我们采用基于最近前驱的指代消解。根据代词的类型可以判断其代指的对象是人(角色)还是物(道具),对象的性别是男还是女,是群体还是个体(单复数)。根据这些信息,在前文中查找最近出现的,单复数、性别等信息相符的角色。
2.3场景
2.3.1 场景介绍及其意义
场景就是场面描写,组成小说或者剧本的最小板块,是对一个特定的时间、地点内许多人物活动的总体情况的描写,即由人物、事件、环境组成。它是某一段时间社会生活的横截面,如舞会、晚餐、战斗场面。 主要考虑以人物为中心的环境描写。
场景环境的描述也很重要,如果是自然环境,那么人物活动的时间、地点、季节、气候以及景物等要表述清楚,如季节变化、风霜雨雪、山川湖海、森林原野、草木虫鱼等;如果是社会环境,那么建筑、陈设、风土人情和时代气氛等要一一阐述。它所描写的范围可大可小,大至整个社会、整个时代,小至一个家庭、一处住所。
场景的作用有以下几点:
如果剧本以场景描写作为开头,会定下感情基调,举个例子:
“月亮从树林边上升起来了,放出冷冷的光辉,照得积雪的田野分外白,越发使人感到寒冷。”
这就是一个悲情的基调。
第二,还能渲染气氛和营造意境。
如:“月牙儿下边,柳梢上面,有一对星好像微笑的仙女的眼,逗着那歪歪的月牙儿和轻摆的柳枝。”
这很显然是一个欢快的气氛。
第三,表现人物的特性,也就是刻画人物,这一点就不细细赘述了,相信大家都能理解。
第四点,也是最重要的,就是这个场景对情节发展和主题表现的作用,如果一个场景在这些方面完全没有意义,那这个场景就没有存在的必要,也就是说这个场景很失败。
鲁迅的《药》开头对时令的描写:
“秋天的后半夜,月亮下去了,太阳还没有出,只剩下一片乌蓝的天;除了夜游的东西,什么都睡着。华老栓忽然坐起身,擦着火柴,点上遍身油腻的灯盏,茶馆的两间屋子里,便弥满了青白的光。”
这个场景描述的作用就很大,它不仅勾勒出黎明前最黑暗的时刻的突出特征:阴暗、凄清,还有几分恐怖,还交待了活动背景,渲染了沉寂而肃杀的气氛,奠定了悲剧基调,暗示了小栓和夏瑜的悲惨命运,这就是一个成功的场景描述。
2.3.2含空间推理的场景的构建技术
场景和角色建模技术包括含空间推理的场景自动创建技术、个性化角色造型自动创建技术两方面。
现在来详细介绍一下含空间推理的场景自动创建技术。
创建3D场景是个非常复杂而又耗时的工作。用户首先得掌握复杂的建模软件、渲染工具,然后才开始漫长的场景设计与创建过程。我们需要开发新的更有效、操作更简单的3D场景创建方法。由于丰富的自然语言可以准确地描述3D场景,因此基于自然语言自动创建3D场景是目前先进而又实用的方法。早期的系统如G.Adorni[26]开发的语言驱动的图像生成系统和S.R.Clay[27]开发的基于自然语言的对象摆放系统。其中S.R.Clay的摆放系统更接近于我们的研究目标,但是其仅限于对已有对象的空间排列与分布。Pennsylvania大学的人体模型与仿真中心[28][29]研究了如何在封闭虚拟环境中基于自然语言控制实体的动态特征。这与T.Winograd[30]的SHRDLU系统类似,即在虚拟环境中通过自然语言与实体对象交互。Johansson[31]等人开发了根据语言描述还原交通事故3D场景的系统Carsim。Coyne[32]等人实现了基于语言描述的3D场景生成系统WordsEye,如图3.2-1所示。WordsEye系统依赖于一个庞大的可以描述实体及其动作的3D模型库,并且其中的每个模型都有相关联的形状位移、空间标签以及功能属性等描述。WordsEye系统通过语言分析从文本描述中提取实体的特征,从3D模型库中获取合适的模型,然后参照空间标签以及形状位移正确地摆放模型。

图3.2-1 Coyne等人开发的基于文本描述产生的3D场景的WordsEye系统。图中场景根据如下文本描述生成:“John使用弩,他骑在商场边的马上,商场在大柳树下,一只小恐龙在马前,恐龙面向John,一个巨大的茶杯在商店前,一个巨大的蘑菇在茶杯中,城堡在商店右边。”
通过对已有系统的分析,我们认为一套完整的含空间推理的场景自动创建技术包括空间推理算法,含有定位信息的模型存储,基于内容的三维模型检索以及场景描述模型。以上的技术方案以三维动画为主,同时兼顾二维动画场景的自动生成。
(A)空间推理算法
目前空间推理的研究主要集中在GIS研究领域,研究对复杂地学对象的管理和处理;能够对由各种空间对象表达形式表示的地学复杂对象进行有效的空间存取;能够对各种空间对象进行有效的空间操作。由于空间知识和空间推理本质上是定性的,因此我们这里主要是指定性空间推理技术。郭平[33]详细阐述了在二维空间的定性推理技术的发展趋势。定性空间推理主要包括基于组合表推理逻辑演算等方面。虽然关于定性空间推理的研究已有十几年,获得了一些推理方法,但是基于组合表的推理仍是定性空间推理最常用的推理方法[34-41]。组合表推理是从两个已知关系R1(a,b)和R2(b,c)推出仅含a和c的关系R3(a,c)。组合表推理的合法性在于多数情况下推理不依赖于已知事实而依赖于关系的逻辑属性,组合表推理的可行性在于无论是拓扑关系还是方位关系其关系全集均是有限集合。通过逻辑演算来进行推理是定性空间推理的另一种方法。Randell等[42]通过空间谓词C(x,y)定义空间逻辑系统,将空间对象间的拓扑关系表示为谓词公式,利用一阶谓词逻辑建立了一阶逻辑范畴下的空间拓扑关系推理技术。Bennett[44]用命题逻辑来表示空间对象间的拓扑关系,由此使得空间推理成为命题演算。Bennett [45]还在将模态逻辑引入空间拓扑关系的描述与推理方面进行了一些尝试性研究。石纯一等[43]将定性空间推理问题划分为易处理类与非易处理类,并给出了易处理类的分层逼近推理方法。为了表达三维空间对象的拓扑关系,一些学者开发了基于拓扑关系的数据模型,如3DFDS模型(3D Formal Data Structure)[46]。3DFDS模型基于二维拓扑数据结构,定义了结点、弧段、边、面四种基本的几何元素以及基本元素与点、线、面、体四种几何目标之间的拓扑关系。该模型具有很强的表达拓扑关系和位置的能力,但由于没有考虑空间实体的内部结构,仅适于表达具有规则形状的简单空间实体,难以表达没有规则边界的复杂实体。一些学者对3DFDS模型进行了扩展,发展了新的模型,如SSM(Simplified Spatial Model)[47]。目前空间推理算法主要用于对GIS中二维空间对象的检索,而3D GIS的空间推理算法还处于初级研究阶段,并没有形成实用的系统。因此目前根据文本描述自动生成3D场景的实用系统如Carsim[31]、WordsEye[32]以及Lee[48]等人实现的实时3D场景自动生成系统都没有使用GIS空间推理算法确定空间对象间的位置关系,而仅仅使用“上”、“下”、“前”、“后”、“左”、“右”等基本位置关系附加上基于物理的约束条件以及基于常识的约束条件或者其他类型的各种约束来精确定义各个空间对象之间的方位关系。
(B)含有定位信息的模型存储和基于内容的三维模型检索
基于内容的三维模型检索首先从模型数据中自动计算并提取三维模型的特征,如形状、空间关系、材质的颜色及纹理等,建立三维模型的多维信息索引;然后在多维特征空间中计算待查询模型与目标模型之间的相似程度,实现对三维模型数据库的浏览和检索[61]。基于内容的含义就是试图利用反映三维模型视觉特征的内容信息自动建立特征索引,达到检索三维模型的目的。杨育彬等人[60]对基于内容的三维模型检索算法做了很好的归纳和总结。三维模型存在一些特殊之处。首先,三维模型同时具有几何特性(geometrical properties) 和表面属性(appearanceattributes) 两方面的数据。其中,表面属性主要包括材质种类及其颜色、透明度、反射系数以及纹理贴图等;而几何特性则存在多种表示方式,如参数化曲面或多边形网格包围的实体表示、体元集合、隐性函数以及类似于VRML 模型的多边形混合模型等[53]。由于表面属性的多样性和复杂性,目前的三维模型检索算法往往针对特定的三维模型数据表示方法,只根据其形状特征进行相似性检索。例如,Hilaga 等人[54]和Vranic 等人[55]都以多边形网格包围的实体表示模型作为检索对象;Regli[56]、McWherter[57]、Corney[58]和Mukai[59]等人则以几何CAD 模型作为检索对象;而Keim 等人[60]则采用体元集合表示模型作为检索对象;Zhang 等人[61]和Ohbuchi 等人[62]采用VRML 模型作为检索对象。目前还没有一种统一的形状描述能综合所有三维模型表示方法的优点,而且不同的模型表示方法之间有时并不能相互转换[62]。这增加了基于内容的三维模型检索研究的复杂性。其次,许多三维模型尽管视觉上得到优化,但是缺乏语义上的结构层次,是弱定义(ill defined)结构[63],模型表面并不能进行简单的参数化描述。另外,由于三维表面之间可能具有任意的拓扑关系,许多对二维图像媒体有效的方法,如傅立叶变换等,并不能直接扩展应用于三维表面模型。
(C)场景描述模型
经过语法和语义分析,整个场景将通过图形级别的低等级描述格式来定义。图形级别的描述格式用于控制对象的可见性、尺寸、位置、方向以及颜色、透明度属性等对对象特征的描述。在现有的3D场景描述模型中,为了方便三维图形应用的开发和对图形性能进行优化,产生了场景图的概念。场景数据库包含欲表现的几何图形及其状态信息,它被组织成分级层次结构,称为场景图。场景图是通常意义上图的子集,它是一种有向、无环图。也就是说,场景图中节点之间的关系有确定的方向性,即自顶向下,从左到右;场景图中没有环,否则当遍历场景图时可能导致无限循环。场景图技术普遍应用于如今的CAD、视景仿真等软件中,大多数3D 游戏都实现了私有的场景图并将其作为其游戏引擎的一部分,但较通用的场景图不多。比较著名的有SGI(SiliconGraphics 公司)开发的IRIS Inventor 和IRIS Performer。Inventor 面向对象,多用于快速图形应用开发;Performer 则面向性能,多用于虚拟现实和视景仿真应用。著名的视景仿真引擎Vega,在Windows NT 上的版本中实现了其私有的场景图系统——Jolt,而在IRIX 版本中则利用了Performer 作为其内核[65]。
(D)二维动画中的场景自动生成技术
目前的动画制作主要分为三维动画和二维动画两种形式。三维动画是以三维模型为基础。对于大多数二维动画来说,若以二维模型的方式存储空间对象,则依然可以沿用三维场景自动生成技术。但是若以图片的方式存储二维动画素材,则无法通过图片根据语言解析的结果直接构造完整的动画场景,但是可以从数据库中选择合适的图片,按照场景描述文本在二维空间合理排列这些图片,形成动画场景的初步印象,从而为动画制作者手工绘画整个场景提供很好的预览效果和启迪作用。 Mihalcea 等人[67]开发了在机场环境下的基于图片的公共交流系统,方便持不同语言的人利用图片系统进行交流。Zhu等人[66]发展了Text-to-Picture技术,基于简单的文本描述生成能反映该描述的图片场景。如下图所示:

图3.2-2 Zhu等人开发的Text-to-Picture 系统
2.3分镜头
2.3.1 分镜头的概念
要谈分镜头画面设计,首先要谈什么是镜头画面。就像我们所知道的那样:“镜头是画面构成的基础,每一个画面都是镜头最终的外在体现。镜头是画面的承载形式,镜头也是构成影像画面的最基本的元素。” 镜头和画面是相辅相成密不可分的,镜头画面是承载影像的物质载体。镜头画面是导演用来展示镜头面前发生事件人物的现实,而这种现实又是围绕导演的意图而设置的。从这个意义上讲影视动画的镜头设计,镜头与画面之间不是并列关系,而是相互影响、相辅相成并融为一个整体的。画出来的镜头画面其视觉效果都是根据视听艺术的规律,把画面镜头画,把视角拟人化,以期达到艺术作品与观众的共鸣。
先来看看大家熟悉的电影镜头,在影视动画电影中,所谓电影镜头,就是用摄影机不间断地拍摄下来的片断。它也是构成影片的基本单位,当然也是影视造型语言的基本视觉元素。在动画片中其镜头画面设计最终是以银幕为载体出现的。如果把银幕看作是画面,那么镜头画面都是围绕银幕这个画面来设计的。
再来看看镜头画面的意义。镜头画面是承载影像的物质载体。电影,不是将思想简单地处理成画面,而是要通过画面去让人思考。镜头画面的突出表现就在于:一方面,能准确、可观地重现镜头面前的现实;另一方面,这种表现得活动又是根据导演的具体意图进行的。
分镜头剧本也叫导演剧本,是导演案头工作的集中表现。“将影片的文学内容分切成一系列可以设置的镜头画面的一种剧本”。对“电影镜头”“电影画面”“镜头画面”、“风景头剧本”这些概念有了认识后我们来看看关于分镜头画面的阐述。
2.3.2 分镜头的主要内容
电视节目编导在编写分镜头脚本时,工作的主要内容有:
将文字脚本的画面内容加工成一个个具体形象的,可供拍摄的画面镜头,并按顺序列出镜头的镜号。
确定每个镜头的景别,如远、全、中、近、特等。
排列组成镜头组,并说明镜头组接的技巧。
用精炼具体的语言描述出要表现的画面内容,必要时借助图形,符号表达。
相应镜头组的解说词。
相应镜头组或段落的音乐与音响效果。
分镜头脚本的作用,就好比建筑大厦的蓝图,是摄影师进行拍摄,剪辑师进行后期制作的依据和蓝图,也是演员和所有创作人员领会导演意图,理解剧本内容,进行再创作的依据。
分镜头脚本的格式: 电视节目的分镜头脚本,通常采用表格的形式。
分镜头脚本的写作方法是从电影分镜头剧本的创作中借鉴来的。一般按镜头号,镜头运动,景别,时间长度,画面内容,广告词,音乐音响的顺序,画成表格,分项填写。对有经验的导演,在写作时格式上也可灵活掌握,不必拘泥于此。
镜号:即镜头顺序号,按组成电视画面的镜头先后顺序,用数字标出。它可作为某一镜头的代号。拍摄时不一定按次顺序号拍摄,但编辑时必须按顺序编辑。
机号:现场拍摄时,往往是用2台到3台摄像机同时进行工作,机号代表这一镜头是由哪一号摄像机拍摄。前后两个镜头分别用两台以上摄像机拍摄时,镜头的组接,就在现场通过特技机将两个镜头进行编辑。单机拍摄就无须标明。
景别:根据内容需要,情节要求,反映对象的整体或突出局部。一般有远景,全景,中景,近景,特写等。
2.3.3 分镜头的设计过程
动画导演的职责是把文学剧本描写的形象运动动画的表现手段创造性的表达出来。具体任务是将动画片文学剧本转化成为形象化的视觉剧本--画面分镜头剧本,然后再搬上银幕。这一系列工程的顺序是:
1、动画创作者在提供的文学剧本的基础上进行整体的艺术构思。
2、写出导演阐述。就是导演对影片创作意图和完整构思向摄制组成员所作的说明,用以保证整部影片思想艺术的统一。
主要内容包括:对剧中主要角色的分析;对影片风格样式的确立;对节奏的处理;对各种造型要素的提示和要求。
3、完成文字风景头剧本。将影片准备表现得银幕形象,按分镜头的方式用文字描述出来,以便符合拍摄规律。
其中包括:镜头号、镜头长度、景别、表现方式、画面内容、声音效果的起止位置等项目。
4、人物与环境设定。
包括人物性格描述、人物外形特征分解、人物与环境的视觉关系设计等。场景将启发或者限制角色的行为方式,是画面视觉风格构成的基础。
5、分镜头画面设计。分镜头画面虽然是纸面上的表述,缺是对未来影片视听效果的预演。
每一个镜头的创作意图由镜头画面与文字描述组成,将如何实施或制作的意图都应尽量详细地表达清楚。分镜头的几种形式。它不同于一般的绘画画面概念,不是孤立的画面,而是受前后镜头的内在逻辑关系制约的。
分镜头画面设计的方法是对电影镜头感的认识和表达。导演不仅要熟练掌握叙事技巧,并且要了解工艺技术的操作原理,根据叙事目的或风格特征确定表现方式。画面分镜头设计不仅仅是简单描述动作和事件的外貌,还必须有一条根本的、能够推动事件发展的内在逻辑线索。有特点的动作逻辑是由设计者所选择的主题而生成和发展的,一个动作或者事件必须紧跟着另一个动作或另一个事件,在描述动作与事件的单元之间必须有一些逻辑关系将他们合理地连接起来。这种设计思维和表述方式,本身不是简单地直接表达思想,但是长生的效果却能够准确地表达思想。
2.3.4 分镜头的描述与生成
首先我们来看看文本分镜头描述,首先在于未登录词的识别。未登录词,即未收录在词典中的词。在儿童故事中我们关心的未登录词主要分以下几类:1)角色名:包括满足一般中文人名规则的名字、特定称谓、昵称、用角色职业或特征代指的故事角色名等。2)道具名:包括动画作者的新造词、特定词组等。3)场景地点名称:包括一般性的地点词、音译地点词、虚构的地点名等。从来源上来看,这些未登录词又可以分为:1)音译词:在翻译的童话故事中经常出现音译的人名和地名。2)在故事中有特定意义或指代对象的词组:在故事中经常出现一个词组来代指某个角色,如“扫烟囱的人”。
这些词未必是传统意义上的一个中文词,有可能是一个短语,但在特定的故事中,这些词指代一个特定的对象或者是表示一个特定的意义。我们需要识别出这些词,才能保证切词的正确率,从而提高下一步情节抽取工作的正确率。
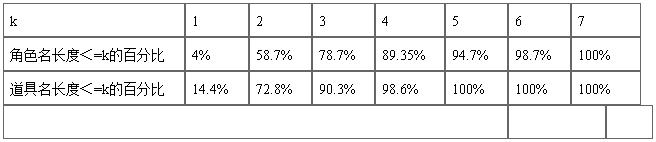
通过对100个儿童故事的故事角色和道具进行统计,统计结果见表1。长度在4个中文字以下的角色名占总数的89.35%,在7个中文字以下的为100%,道具名的长度都在5个中文字以下。比较长的主要是外文译名和使用职业命名的角色。试验中我们将抽取目标限定为长度不超过7的字串。
表1 未登录词长度统计
由于故事文本数据规模较小,所以我们采用了统计与规则相结合的方法进行未登录词识别。首先从未切分的故事文本中抽取长度在7以下的高频字串(出现频率大于或等于2)。然后对前缀及后缀词进行过滤,获得极大高频字串。极大高频字串集合里面不仅包括词语,并且还包括了噪音和固定搭配。通过计算字串内部的互信息,对极大高频字串集合进行筛选,根据分词词典,我们将筛选结果中的已登录词去除。并利用未登录词过滤规则对候选未登录词进行过滤,得到最终的未登录词识别结果。面向童话故事文本的未登录词识别框架如图3所示。
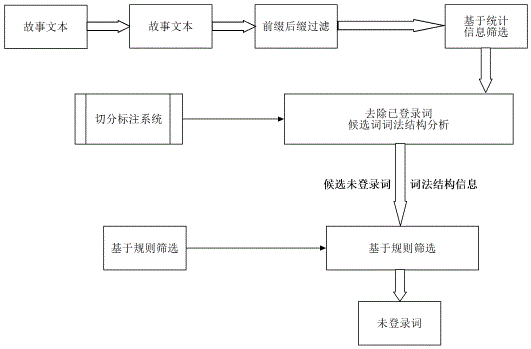
图3未登录词抽取流程
我们采用的未登录词过滤规则是人工抽取的匹配规则,主要是一些否定规则。下面是一些否定规则的例子:
规则1:词性分析结果以副词(d)结尾的字串不是未登录词;
规则2:词性分析结果以前缀字(h)结尾的字串不是未登录词(前缀字:只能用于词首的字);
规则3:词性分析结果以后缀字(k)开头的字串不是未登录词(后缀字:只能用于词尾的字);
规则4:词性分析结果以助词(u)开头的字串不是未登录词。
之后运用在之前提到的剧本元素抽取和将剧本结构化的方法,即可实现文本分镜头。
再来看看可视化分镜头。
在定性文本分镜头描述产生后,我们利用可视化工具来交互定义三维分镜场景。可视化工具支持三维模型的导入、虚拟相机放置、添加光源、对象属性的描述(大小、颜色、纹理等)、对象行为的描述(移动、旋转、改变大小等)、事件的描述(鼠标、键盘消息),通过简单功能的组合实现复杂功能,允许用户交互的生成可视化场景。
我们以《开心菜园》样片为例来进行说明,其中青蛙王子有一个行为“扑通一声跳下水”:
[并行-
Frog以一定速度移动(向上)(速度1米/秒)
Frog以一定速度移动(向右)(速度0.8米/秒)
Frog以一定速度移翻转 (向右)(速度0.01圈/秒)
]
等待 0.1秒
[并行-
Frog以一定速度移动(向下)(速度1米/秒)
Frog以一定速度移动(向右)(速度1米/秒)
Frog以一定速度移翻转 (向右)(速度0.01圈/秒)
]
图5为导入的模型场景及生成的青蛙跳下水的行为。


图5 导入的模型场景及生成的青蛙跳下水行为
参考文献:
[1] Ulysse http://www.info.unicaen.fr/~nugues/research.html
[2] Sgouros N.M., Dynamic generation,management and resolution of interactive plots.Artificial Intelligence,1999,107:29-62.
[3] Noma T,Kai K,Nakamural J,Okada N.Translating from natural language story to computer animation. In Proc. of SPICIS’92, 1992, 475-480.
[4] Takashima Y et al., Story driven animation, InProc CHI+GI’87,149-153,1987.
[5] Seligmann D.D.,Feiner S.,Automated Generation of intent based 3Dillustrations[J],Computer Graphics,1991,123-132.
[6] DruinA., Designing PETS:A Personal Electronic Teller of Stories[C],In Proceedingsof the SIGCHI Conference on Human Factors in Computing Systems:the CHI Is the Limit,Pittsburgh,Pennsylvania,United States,1999:326-329.
[7] Lu R., ZhangS., SWAN:Full Life Cycle Automation of Computer Animation.AutomaticGeneration of Computer Animation:Using AI for Movie Animation [J].Vol.2160, 29-65,2002.
[8] 陆汝钤等, 从故事到动画片——全过程计算机辅助动画自动生成.自动化学报, 2002年第28卷第3期, 321-348.
[9] PaivaA.,From Pencil to Magic Wand Tangibles as Gateways to Virtual Stories [J], Transactions on Edutainment, Vol. 5080, 161-171, 2008.
[10] Coyne B.,Richard S., WordsEye:An Automatic Text-to-Scene Conversion System [C], Proceedings of the SIGGRAPH 2001 Annual Conference on Computer graphics,Los Angeles,2001.
[11] OshitaM., Generating Animation from Natural Language Texts andSemantic Analysis for Motion Search and Scheduling [J], The Visual Computer: International Journal of Computer Graphics - Special Issue on Cypberworlds'2009 archive, 26(5): 339-352, May 2010.
[12] Winograd T., Procedures as a Representation for Data in a Computer Program for Understanding Natural Language [D], Ph.D. dissertation, Massachusetts Institute of Technology, 1971.
[13] Akerberg O.,Svensson H.,Schulz B.,Nugues P., CarSim:an automatic 3D text-to-scene conversion system applied to road accident reports [C], Proceedings of the tenth conference on European chapter of the Association for Computational Linguistics,Budapest,Hungary,2003.
[14] Coyne B., Rambow O., Hirschberg J., Sproat R., Frame semantics in text-to-scene generation [C], In Knowledge-Based and IntelligentInformation and Engineering Systems, Volume 6279 of Lecture Notes in Computer Science, pp. 375-384. Springer Berlin/Heidelberg,2010.
[15] Xu K., Automatic object layout using 2D constrains and semantics [M], Master thesis, University of Toronto, 2002.
[16] Ma M., Automatic Conversion of Natural Language to 3D Animation [D], PhD thesis, School of Computing & Intelligent Systems, University of Ulster, 2006.
[17] Tappan D., Knowledge-Based Spatial Reasoning for Scene Generation from Text Descriptions [C], In Proceedings of AAAI, 1888-1889, 2008.
[18] Kovar L., l GleicherM.,Pighin F., Motion graphs [C],In proceedings: SIGGRAPH 2002, San Antonio, Texas, pp.473-482, 2002.
[19] Li Y., Wang T., Shum H., Motion texture:A two-level statistical model for character motion synthesis [C], In Proceedings of SIGGRAPH, ACM Press, 465-472, 2002.
[20] Brand M.,HertzmannA., Style machine [C],In proceedings: SIGGRAPH 2000, New Orleans, 183-192, 2000.
[21] Gleicher M., Joon H.S., Kovar L., Jepsen A., Snap-Together Motion: Assembling Run-Time Animations [C], Proceedings of the ACM SIGGRAPH 2003.
[22] Zhao L., Normoyle A., Khanna S., Safonova A., Automatic construction of a minimum size motion graph [C],SCA’09: Proceedings of the 2009 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, August 2009.
[23] Park,S.I.,Shin,H.J., Shin,S.Y.On-line locomotion generation based on motion blending [C], In ACMSIGGRAPH/EurographicsSymp.On Comp.Animation105-112, 2002.
[24] 高岩, 基于内容的运动检索与运动合成[D], 上海:上海交通大学, 2006, 10.
[25] AllaSafonova, Jessica K. Hodgins,Construction and Optimal Search of interpolated Motion Graphs [J]. ACM Transactions on Graphics, Vol.26. July 2007.
[26]G. Adorni, M. Di Manzo, and F. Giunchiglia. Natural Language Driven Image Generation. In COLING 84, pages 495–500, 1984.
[27]S. R. Clay and J. Wilhelms. Put: Language-Based Interactive Manipulation of Objects. IEEE Computer Graphics and Applications, pages 31–39, March 1996.
[28]N. Badler, R. Bindiganavale, J. Allbeck, W. Schuler, L. Zhao, and M. Palmer. Parameterized Action Representation for Virtual Human Agents. In J. Cassell, J. Sullivan, S. Prevost, and E. Churchill, editors, Embodied Conversational Agents, pages 256–284. MIT Press, Cambridge, MA, 2000.
[29]R. Bindiganavale, W. Schuler, J. Allbeck, N. Badler, A. Joshi,and M. Palmer. Dynamically Altering Agent Behaviors Using Natural Language Instructions. In Autonomous Agents, pages 293–300, 2000.
[30]T. Winograd. Understanding Natural Language.PhD thesis,Massachusetts Institute of Technology, 1972.
[31]Richard Johansson, Anders Berglund, Magnus Danielsson, and Pierre Nugues.Automatic text-to-scene conversion in the traffic accident domain. In IJCAI-05, Proceedings of the Nineteenth International Joint Conference on Artificial Intelligence, pages 1073--1078, Edinburgh, Scotland, July 2005.
[32]Bob Coyne, Richard Sproat. 2001. WordsEye: An Automatic Text-to-Scene Conversion System. Proceedings of the SIGGRAPH 2001 Annual Conference on Computer graphics, Los Angeles, CA USA.
[33]郭平,定性空间推理技术及应用研究,重庆大学,博士论文,2004.
[34]A.G.Chon,S.M.Hazarika.Qualitative Spatial representation and reasoning:an overview,Fundament Information,May 2001,Vol. 46 Issue 1 pp.2-32.
[35]Egenhofer,M.,Franzosa,R.Point-Set topological spatial relations.International Journal of eographical Information System,1991,5(2):161-174.
[36]Vilain,M.,Kautz,H. Constraint Propogation Algorithm for Temporal Reasoning,Proc.5th mericanConf.onAI(AAAI-86),Philadelphia,1986,pages 377-382.
[37]Schlieder,C.,Reasoning about ordering,A.U.Frank and W.Kuhn(eds.)Spatial Information heory-A Theoretical Basis for GIS,Proc.COSIT'95,LNCS No.988,Springer,1995,pages 341-349.
[38]Rohrig,R. A theory of Qualitative Spatial Reasoning based on order relations. Proc.12th mericanConf.onAI(AAAI-94),1994,pages 1418-1423.
[39]Randell,D.A.,Cohn,A.G.andCui,Z.,Computing Transitivity Tables:A challenge for utomated theorem provers,Proc.CADE 11,Springer-Verlag,1992.
[40]Freksa,C.Temporal Reasoning based on semi-intervals,Artificial Intelligence,54,1992, 99-227.
[41]Cohn,A.G.,Gooday,J., Bennett,B.Acomparison of structures in spatial and temporal ogics,R.Casati,B.Smith and G.White(eds.)Philosophy and the Cognitive Sciences,Proc. 6th Intl.WittgensteinSymposium,Holder-Pichler-Tempsky,Vienna 1994.
[42]D.Randell,Z.Cui,andA.Cohn,A spatial logic based on regions and connection,inroceedings of the 3rd International Conference on Knowledge Representation and Reasoning, p.165–176.Morgan Kaufmann,(1992).
[43]石纯一,廖士中,定性推理方法北京清华大学出版社2002.9.
[44]B.Bennett.Spatial reasoning with propositional logic.In Proceedings of the 4th International onference on Knowledge Representation and Reasoning,pages 51--62.Morgan Kaufmann, 994.
[45]B Bennett.Modal logics for qualitative spatial reasoning.Bulletin of the Interest Group in Pure and Applied Logic(IGPL),1996.
[46]Molennar M.A topology for 3D Vector map[j].ITC Journal, 1992-01.
[47]Zlaanova S.3D GIS for Urban Development[D].PhD.ITC,2000.
[48]Lee M. Seversky, Lijun Yin: Real-time automatic 3D scene generation from natural language voice and text descriptions. ACM Multimedia 2006: 61-64.
[49]Ken Xu, James Stewart, Eugene Fiume. Constraint-Based Automatic Placement for Scene Composition. 25-34,Graphics Interface 2002.
[50]Z. Li. Compaction algorithms for non-convex polygons and their applications.PhD thesis, Harvard University, Cambridge, Massacusettes, 1994.
[51]杨育彬,林珲 基于内容的三维模型检索综述, 计算机学报, 第27卷,第10期,004.
[52]Funkhouser T., Min P., Kazhdan M. et al. A search engine for 3d models. ACM Transactions on Graphics , 2003 , 22 (1) : 83~105.
[53]M. Heczko, D. Keim, D. Saupe, D. Vranic. A method for similarity search of 3d objects. In : Proceedings of German Database Conference (BTW) , Oldenburg , Germany , 2001 , 384~401.
[54]Hilaga M., Shinagawa Y., Kohmura T., Kunii T. Topologymatching for fully automatic similarity estimation of 3d shapes. In :Proceedings of ACM SIGGRAPH , Los Angeles ,USA , 2001 , 203~212.
[55]DV.Vranic, D.Saupe, J. Richter. Tools for 3d-object retrieval: Karhunen-Loeve transform and spherical harmonics. In: Proceedings of IEEE Workshop on Multimedia Signal Processing, Cannes, France , 2001 , 293~298.
[56]Regli W., Cicirello V. Managing digital libraries for computer2aided design. Computer Aided Design , 2000 , 32 (2) : 110~132.
[57]McWherter D., Peabody M., Shokoufandeh A., Regli W. Database techniques for archival of solid models. In : Proceedingsof ACM Symposium on Solid Modeling and Applications , Ann Ar2bor , Michigan , USA , 2001 , 78~87.
[58]Corney J., Rea H., Clark D. et al. Coarse filter for shapematching. IEEE Computer Graphics and Applications , 2002 , 22(3) : 65~73.
[59]Mukai S., Furukawa S., Kuroda M. An algorithm for decidingsimilarities of 3d objects. In : Proceedings of ACM Symposium onSolid Modeling and Applications, Saarbrücken , Germany , 2002, 367~375.
[60]Keim D. Efficient geometry-based similarity search of 3d spatial databases. In: Proceedings of ACM SIGMOD International Con2ference on Management of Data , Philadelphia , USA , 1999 , 419~430.
[61]Zhang C., Chen T. Efficient feature extraction for 2d/3d objects in mesh representation. In : Proceedings of IEEE International Conference on Image Processing, Thessaloniki, Greece, 2001, pp.935~938.
[62]Ohbuchi R., Otagiri T., Ibato M., Takei T.. Shape-similarity search of three-dimensional models using parameterized statistics.In : Proceedings of Pacific Conference on Computer Graphics and Applications , Beijing , China , 2002 , 265~275.
[63]David B..Methods for content-based retrieval of 3d models. School of Electronics and Computer Science, Southampton University , U K: Technical Report MMS2003249, 2003.
[64]Vranic D., SaupeD..3d model retrieval. In: Proceedings of Spring Conference on Computer Graphics , Budmerice , Slovakia , 2000 , 89~93.
[65]罗朔锋,李雪耀,高性能面向对象场景图系统,系统仿真学报,Vol.17 No.2,Feb. 2005.
[66]X Zhu, AB Goldberg, M Eldawy, CR Dyer, BStrock: A Text-to-Picture Synthesis System for Augmenting Communication. AAAI 2007.
[67]Mihalcea R., Leong B. Toward Communicating Simple Sentences Using Pictorial Representations. In Proc. Conf. Association for Machine Translation in the Americas (AMTA). 2006.