数据挖掘大作业结果分析报告


数据仓库期末作业 - 数据挖掘分析报告
某药店常用药品信息数据挖掘解决方案
作 者 刘金龙
学 院 计算机信息管理学院
专 业 计算机科学与技术
年 级 2011
学 号 112103209
某药房常用药品价格、产地的数据挖掘解决方案
一、 提出问题
1、单位基本情况及相关业务流程介绍;
对于药店,储存大量的常用药品是必不可少的工作,随之而来的对药品的数据信息管理和储存成为了令人头疼的问题,在接到货源后,工作人员需要统计药品产地和价格的信息,为以后的货源供给地,用合理的价格出售药物,是至关重要的工作。
2、单位存在的问题。
由于货物种类、名称众多,在短时间内分析好相关数据几乎不可能,大量的数据,依靠人力或是非数据统计软件进行统计工作,事倍功半。严重影响药店的正常进货,出售药品的工作。
二、 分析问题
1、对该单位存在的问题进行分析;
由以上问题可见,利用数据挖掘进行相关数据的统计和整理工作,简单、省时、有效。
2、解决问题的可能途径和方法。
利用SQL SEVER 导入数据,再提取统计分析结果,很快会得到想要的数据分析结果。
三、 利用数据挖掘技术解决问题
1、设计数据挖掘算法;
决策树;
数据关联;
神经元算法;
2、对挖掘结果进行深入解释和分析
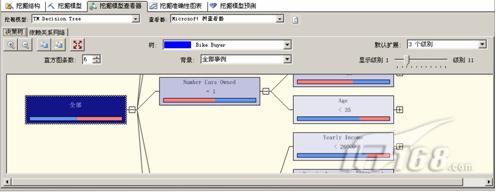
由此图可以看见在不不同的产地,由于地理因素和特产药品的原因,在药品相关的植物盛产区,进货比较便宜。
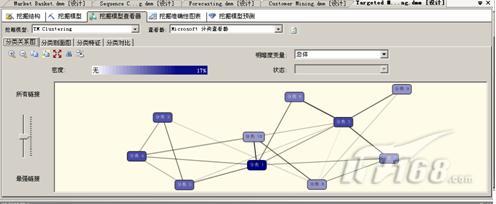
此图可以分析出,不同的消费人群对于同类的药品的购买需求,对于同样的功能的药,药存储不同价格的种类,以满足广大消费者的需求。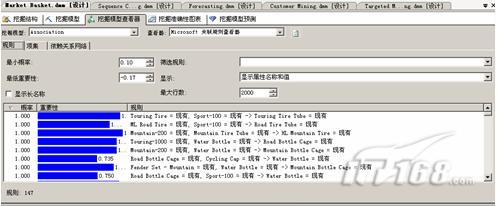
此图可以分析以前的销售结果,哪类、什么价格的更受消费者欢迎,方便以后进货。
四、 总结
通过自己的实践,对数据挖掘有了新的认识。简单来说,数据挖掘是基于“归纳”的思路,从大量的数据中(因为是基于归纳的思路,因此数据量的大小很大程度上决定了数据挖掘结果的鲁棒性)寻找规律,为决策提供证据。从这种角度上来说,数据挖掘可能并不适合进行科学研究,因为从本质上来说,数据挖掘这个技术是不能证明因果的,以一个最典型的例子来说,例如数据挖掘技术可以发现啤酒销量和尿布之间的关系,但是显然这两者之间紧密相关的关系可能在理论层面并没有多大的意义。不过,仅以此来否定数据挖掘的意义,显然就是对数据挖掘这项技术价值加大的抹杀,显然,数据挖掘这项技术从设计出现之初,就不是为了指导或支持理论研究的,它的重要意义在于,它在应用领域体现出了极大地优越性。一下是我参阅资料总结的设计数据挖掘的步骤:
① 理解数据和数据的来源
② 获取相关知识与技术
③ 整合与检查数据
④ 去除错误或不一致的数据。
⑤假设数据模型。
⑥ 实际数据挖掘工作(data mining)。
⑦ 测试和验证挖掘结果(testing and verfication)。 ⑧ 解释和应用(interpretation and use)。
由上述步骤可看出,数据挖掘牵涉了大量的准备工作与规划工作,事实上许多专家都认为整套数据挖掘的过程中,有80%的时间和精力是花费在数据预处理阶段,其中包括数据的净化、数据格式转换、变量整合,以及数据表的链接。可见,在进行数据挖掘技术的分析之前,还有许多准备工作要完成。
第二篇:数据挖掘课后作业
数据挖掘课后作业
5.4(实现项目)使用你熟悉的程序设计语言(如C++或Java),实现本章介绍的三种频繁项集挖掘算法:(1)Apriori [AS94B],(2)FP增长[HPY00]和(3)ECLAT [Zak00](使用垂直数据格式挖掘)。在各种类型的大型数据集上比较每种算法的性能。写一个报告,分析在哪些情况下(如数据大小、数据分布、最小支持阀度值设置和模式的稠密度),某种算法比其他算法好,并陈述理由。
三种算法的比较
1、对与项集较大,频繁项集较分散,是一个稀疏型的数据集,性能为Apriori>FP-growth>Eclat
2、对与数据集的项集较小,数据非常稠密的数据集,性能为:FP-growth>Apriori>Eclat
各算法采用的数据表示模式及挖掘策略不同。采用优化措施后的 Apriori算法,对于非稠密数据己经具有较高的效率,其性能甚至优于FP-growth 算法;但由于其采用的是广度优先的挖掘策略,对稠密数据效率仍较差。而 Eclat 算法采用的纵向表示法,对数据集较小的稠密数据,效率相对较高;但对于数据集较大的稀疏数据,效率较低,FP一树浓缩了数据库的主要信息,分而治之的挖掘策略也使挖掘问题的复杂程度有所降低。
答:(1)Apriori算法的实现:使用Java语言实现Apriori算法,AprioriAlgorithm类包含了频繁项集的挖掘过程和频繁关联规则的挖掘过程;ProperSubsetCombination辅助类用于计算一个频繁项集的真子集,采用组合原理,基于数值编码原理实现的组合求解集合的真子集。
Apriori算法的核心实现类为AprioriAlgorithm,实现的Java代码如下所示:
(一)核心类
package org.shirdrn.datamining.association;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Map;
- 1 -
import java.util.Set;
import java.util.TreeMap;
/**
* <B>关联规则挖掘:Apriori算法</B>
*
* <P>该算法基本上按照Apriori算法的基本思想来实现的。
*/
public class AprioriAlgorithm {
private Map<Integer, Set<String>> txDatabase; // 事务数据库
private Float minSup; // 最小支持度
private Float minConf; // 最小置信度
private Integer txDatabaseCount; // 事务数据库中的事务数
private Map<Integer, Set<Set<String>>> freqItemSet; // 频繁项集集合
private Map<Set<String>, Set<Set<String>>> assiciationRules; // 频繁关联规则集合
public AprioriAlgorithm(
Map<Integer, Set<String>> txDatabase,
Float minSup,
Float minConf) {
this.txDatabase = txDatabase;
this.minSup = minSup;
this.minConf = minConf;
this.txDatabaseCount = this.txDatabase.size();
freqItemSet = new TreeMap<Integer, Set<Set<String>>>();
assiciationRules = new HashMap<Set<String>, Set<Set<String>>>();
}
/**
* 扫描事务数据库,计算频繁1-项集
- 2 -
* @return
*/
public Map<Set<String>, Float> getFreq1ItemSet() {
Map<Set<String>, Float> freq1ItemSetMap = new HashMap<Set<String>, Float>(); Map<Set<String>, Integer> candFreq1ItemSet = this.getCandFreq1ItemSet();
Iterator<Map.Entry<Set<String>, Integer>> it = candFreq1ItemSet.entrySet().iterator(); while(it.hasNext()) {
Map.Entry<Set<String>, Integer> entry = it.next();
// 计算支持度
Float supported = new Float(entry.getValue().toString())/new Float(txDatabaseCount); if(supported>=minSup) {
freq1ItemSetMap.put(entry.getKey(), supported);
}
}
return freq1ItemSetMap;
}
/**
* 计算候选频繁1-项集
* @return
*/
public Map<Set<String>, Integer> getCandFreq1ItemSet() {
Map<Set<String>, Integer> candFreq1ItemSetMap = new HashMap<Set<String>, Integer>(); Iterator<Map.Entry<Integer, Set<String>>> it = txDatabase.entrySet().iterator();
// 统计支持数,生成候选频繁1-项集
while(it.hasNext()) {
Map.Entry<Integer, Set<String>> entry = it.next();
Set<String> itemSet = entry.getValue();
for(String item : itemSet) {
Set<String> key = new HashSet<String>();
- 3 -
key.add(item.trim());
if(!candFreq1ItemSetMap.containsKey(key)) {
Integer value = 1;
candFreq1ItemSetMap.put(key, value);
}
else {
Integer value = 1+candFreq1ItemSetMap.get(key);
candFreq1ItemSetMap.put(key, value);
}
}
}
return candFreq1ItemSetMap;
}
/**
* 根据频繁(k-1)-项集计算候选频繁k-项集
*
* @param m 其中m=k-1
* @param freqMItemSet 频繁(k-1)-项集
* @return
*/
public Set<Set<String>> aprioriGen(int m, Set<Set<String>> freqMItemSet) {
Set<Set<String>> candFreqKItemSet = new HashSet<Set<String>>();
Iterator<Set<String>> it = freqMItemSet.iterator();
Set<String> originalItemSet = null;
while(it.hasNext()) {
originalItemSet = it.next();
Iterator<Set<String>> itr = this.getIterator(originalItemSet, freqMItemSet);
while(itr.hasNext()) {
Set<String> identicalSet = new HashSet<String>(); // 两个项集相同元素的集合(集合的交运算)
- 4 -
identicalSet.addAll(originalItemSet);
Set<String> set = itr.next();
identicalSet.retainAll(set); // identicalSet中剩下的元素是identicalSet与set集合中公有的元素 if(identicalSet.size() == m-1) { // (k-1)-项集中k-2个相同
Set<String> differentSet = new HashSet<String>(); // 两个项集不同元素的集合(集合的差运算) differentSet.addAll(originalItemSet);
differentSet.removeAll(set); // 因为有k-2个相同,则differentSet中一定剩下一个元素,即differentSet大小为1
differentSet.addAll(set); // 构造候选k-项集的一个元素(set大小为k-1,differentSet大小为k)
candFreqKItemSet.add(differentSet); // 加入候选k-项集集合
}
}
}
return candFreqKItemSet;
}
/**
* 根据一个频繁k-项集的元素(集合),获取到频繁k-项集的从该元素开始的迭代器实例
* @param itemSet
* @param freqKItemSet 频繁k-项集
* @return
*/
private Iterator<Set<String>> getIterator(Set<String> itemSet, Set<Set<String>> freqKItemSet) {
Iterator<Set<String>> it = freqKItemSet.iterator();
while(it.hasNext()) {
if(itemSet.equals(it.next())) {
break;
}
}
return it;
- 5 -
}
/**
* 根据频繁(k-1)-项集,调用aprioriGen方法,计算频繁k-项集
*
* @param k
* @param freqMItemSet 频繁(k-1)-项集
* @return
*/
public Map<Set<String>, Float> getFreqKItemSet(int k, Set<Set<String>> freqMItemSet) { Map<Set<String>, Integer> candFreqKItemSetMap = new HashMap<Set<String>, Integer>(); // 调用aprioriGen方法,得到候选频繁k-项集
Set<Set<String>> candFreqKItemSet = this.aprioriGen(k-1, freqMItemSet);
// 扫描事务数据库
Iterator<Map.Entry<Integer, Set<String>>> it = txDatabase.entrySet().iterator();
// 统计支持数
while(it.hasNext()) {
Map.Entry<Integer, Set<String>> entry = it.next();
Iterator<Set<String>> kit = candFreqKItemSet.iterator();
while(kit.hasNext()) {
Set<String> kSet = kit.next();
Set<String> set = new HashSet<String>();
set.addAll(kSet);
set.removeAll(entry.getValue()); // 候选频繁k-项集与事务数据库中元素做差元算 if(set.isEmpty()) { // 如果拷贝set为空,支持数加1
if(candFreqKItemSetMap.get(kSet) == null) {
Integer value = 1;
candFreqKItemSetMap.put(kSet, value);
}
- 6 -
else {
Integer value = 1+candFreqKItemSetMap.get(kSet);
candFreqKItemSetMap.put(kSet, value);
}
}
}
}
// 计算支持度,生成频繁k-项集,并返回
return support(candFreqKItemSetMap);
}
/**
* 根据候选频繁k-项集,得到频繁k-项集
*
* @param candFreqKItemSetMap 候选k项集(包含支持计数)
*/
public Map<Set<String>, Float> support(Map<Set<String>, Integer> candFreqKItemSetMap) { Map<Set<String>, Float> freqKItemSetMap = new HashMap<Set<String>, Float>();
Iterator<Map.Entry<Set<String>, Integer>> it = candFreqKItemSetMap.entrySet().iterator(); while(it.hasNext()) {
Map.Entry<Set<String>, Integer> entry = it.next();
// 计算支持度
Float supportRate = new Float(entry.getValue().toString())/new Float(txDatabaseCount); if(supportRate<minSup) { // 如果不满足最小支持度,删除
it.remove();
}
else {
freqKItemSetMap.put(entry.getKey(), supportRate);
}
}
- 7 -
return freqKItemSetMap;
}
/**
* 挖掘全部频繁项集
*/
public void mineFreqItemSet() {
// 计算频繁1-项集
Set<Set<String>> freqKItemSet = this.getFreq1ItemSet().keySet();
freqItemSet.put(1, freqKItemSet);
// 计算频繁k-项集(k>1)
int k = 2;
while(true) {
Map<Set<String>, Float> freqKItemSetMap = this.getFreqKItemSet(k, freqKItemSet); if(!freqKItemSetMap.isEmpty()) {
this.freqItemSet.put(k, freqKItemSetMap.keySet());
freqKItemSet = freqKItemSetMap.keySet();
}
else {
break;
}
k++;
}
}
/**
* <P>挖掘频繁关联规则
* <P>首先挖掘出全部的频繁项集,在此基础上挖掘频繁关联规则
*/
public void mineAssociationRules() {
- 8 -
freqItemSet.remove(1); // 删除频繁1-项集
Iterator<Map.Entry<Integer, Set<Set<String>>>> it = freqItemSet.entrySet().iterator();
while(it.hasNext()) {
Map.Entry<Integer, Set<Set<String>>> entry = it.next();
for(Set<String> itemSet : entry.getValue()) {
// 对每个频繁项集进行关联规则的挖掘
mine(itemSet);
}
}
}
/**
* 对从频繁项集集合freqItemSet中每迭代出一个频繁项集元素,执行一次关联规则的挖掘
* @param itemSet 频繁项集集合freqItemSet中的一个频繁项集元素
*/
public void mine(Set<String> itemSet) {
int n = itemSet.size()/2; // 根据集合的对称性,只需要得到一半的真子集
for(int i=1; i<=n; i++) {
// 得到频繁项集元素itemSet的作为条件的真子集集合
Set<Set<String>> properSubset = ProperSubsetCombination.getProperSubset(i, itemSet);
// 对条件的真子集集合中的每个条件项集,获取到对应的结论项集,从而进一步挖掘频繁关联规则 for(Set<String> conditionSet : properSubset) {
Set<String> conclusionSet = new HashSet<String>();
conclusionSet.addAll(itemSet);
conclusionSet.removeAll(conditionSet); // 删除条件中存在的频繁项
confide(conditionSet, conclusionSet); // 调用计算置信度的方法,并且挖掘出频繁关联规则 }
}
}
- 9 -
/**
* 对得到的一个条件项集和对应的结论项集,计算该关联规则的支持计数,从而根据置信度判断是否是频繁关联规则
* @param conditionSet 条件频繁项集
* @param conclusionSet 结论频繁项集
*/
public void confide(Set<String> conditionSet, Set<String> conclusionSet) {
// 扫描事务数据库
Iterator<Map.Entry<Integer, Set<String>>> it = txDatabase.entrySet().iterator();
// 统计关联规则支持计数
int conditionToConclusionCnt = 0; // 关联规则(条件项集推出结论项集)计数
int conclusionToConditionCnt = 0; // 关联规则(结论项集推出条件项集)计数
int supCnt = 0; // 关联规则支持计数
while(it.hasNext()) {
Map.Entry<Integer, Set<String>> entry = it.next();
Set<String> txSet = entry.getValue();
Set<String> set1 = new HashSet<String>();
Set<String> set2 = new HashSet<String>();
set1.addAll(conditionSet);
set1.removeAll(txSet); // 集合差运算:set-txSet
if(set1.isEmpty()) { // 如果set为空,说明事务数据库中包含条件频繁项conditionSet
// 计数
conditionToConclusionCnt++;
}
set2.addAll(conclusionSet);
set2.removeAll(txSet); // 集合差运算:set-txSet
if(set2.isEmpty()) { // 如果set为空,说明事务数据库中包含结论频繁项conclusionSet
// 计数
conclusionToConditionCnt++;
- 10 -
}
if(set1.isEmpty() && set2.isEmpty()) {
supCnt++;
}
}
// 计算置信度
Float conditionToConclusionConf = new Float(supCnt)/new Float(conditionToConclusionCnt); if(conditionToConclusionConf>=minConf) {
if(assiciationRules.get(conditionSet) == null) { // 如果不存在以该条件频繁项集为条件的关联规则 Set<Set<String>> conclusionSetSet = new HashSet<Set<String>>();
conclusionSetSet.add(conclusionSet);
assiciationRules.put(conditionSet, conclusionSetSet);
}
else {
assiciationRules.get(conditionSet).add(conclusionSet);
}
}
Float conclusionToConditionConf = new Float(supCnt)/new Float(conclusionToConditionCnt); if(conclusionToConditionConf>=minConf) {
if(assiciationRules.get(conclusionSet) == null) { // 如果不存在以该结论频繁项集为条件的关联规则 Set<Set<String>> conclusionSetSet = new HashSet<Set<String>>();
conclusionSetSet.add(conditionSet);
assiciationRules.put(conclusionSet, conclusionSetSet);
}
else {
assiciationRules.get(conclusionSet).add(conditionSet);
}
}
}
- 11 -
/**
* 经过挖掘得到的频繁项集Map
*
* @return 挖掘得到的频繁项集集合
*/
public Map<Integer, Set<Set<String>>> getFreqItemSet() {
return freqItemSet;
}
/**
* 获取挖掘到的全部的频繁关联规则的集合
* @return 频繁关联规则集合
*/
public Map<Set<String>, Set<Set<String>>> getAssiciationRules() {
return assiciationRules;
}
}
(二)辅助类
ProperSubsetCombination类是一个辅助类,在挖掘频繁关联规则的过程中,用于生成一个频繁项集元素的非空真子集,实现代码如下:
package org.shirdrn.datamining.association;
import java.util.BitSet;
import java.util.HashSet;
import java.util.Set;
/**
* <B>求频繁项集元素(集合)的非空真子集集合</B>
* <P>从一个集合(大小为n)中取出m(m属于2~n/2的闭区间)个元素的组合实现类,获取非空真子集的集合
*/
public class ProperSubsetCombination {
private static String[] array;
- 12 -
private static BitSet startBitSet; // 比特集合起始状态
private static BitSet endBitSet; // 比特集合终止状态,用来控制循环 private static Set<Set<String>> properSubset; // 真子集集合
/**
* 计算得到一个集合的非空真子集集合
*
* @param n 真子集的大小
* @param itemSet 一个频繁项集元素
* @return 非空真子集集合
*/
public static Set<Set<String>> getProperSubset(int n, Set<String> itemSet) { String[] array = new String[itemSet.size()];
ProperSubsetCombination.array = itemSet.toArray(array);
properSubset = new HashSet<Set<String>>();
startBitSet = new BitSet();
endBitSet = new BitSet();
// 初始化startBitSet,左侧占满1
for (int i=0; i<n; i++) {
startBitSet.set(i, true);
}
// 初始化endBit,右侧占满1
for (int i=array.length-1; i>=array.length-n; i--) {
endBitSet.set(i, true);
}
// 根据起始startBitSet,将一个组合加入到真子集集合中
get(startBitSet);
while(!startBitSet.equals(endBitSet)) {
int zeroCount = 0; // 统计遇到10后,左边0的个数
- 13 -
int oneCount = 0; // 统计遇到10后,左边1的个数 int pos = 0; // 记录当前遇到10的索引位置
// 遍历startBitSet来确定10出现的位置 for (int i=0; i<array.length; i++) {
if (!startBitSet.get(i)) {
zeroCount++;
}
if (startBitSet.get(i) && !startBitSet.get(i+1)) { pos = i;
oneCount = i - zeroCount;
// 将10变为01
startBitSet.set(i, false);
startBitSet.set(i+1, true);
break;
}
}
// 将遇到10后,左侧的1全部移动到最左侧 int counter = Math.min(zeroCount, oneCount); int startIndex = 0;
int endIndex = 0;
if(pos>1 && counter>0) {
pos--;
endIndex = pos;
for (int i=0; i<counter; i++) {
startBitSet.set(startIndex, true);
startBitSet.set(endIndex, false);
startIndex = i+1;
pos--;
if(pos>0) {
- 14 -
endIndex = pos;
}
}
}
get(startBitSet);
}
return properSubset;
}
/**
* 根据一次移位操作得到的startBitSet,得到一个真子集
* @param bitSet
*/
private static void get(BitSet bitSet) {
Set<String> set = new HashSet<String>();
for(int i=0; i<array.length; i++) {
if(bitSet.get(i)) {
set.add(array[i]);
}
}
properSubset.add(set);
}
}
(2)FP增长算法的实现:使用C++语言实现,实现的代码如下:
(一)头文件
#include <iostream>
using namespace std;
#include <string>
#include <map>
#include <algorithm>
- 15 -
#include <stdio.h>
#include <vector>
#define debug(a) printf((a))
struct Item{
string item_name;//项目
Item *node_link; //节点链
Item *parent_link; //父节点链
map <string,Item *> child_link; //孩子节点
int support_count; //支持度
};
void print(vector< vector<const Item* > > ssvec)
{
for(int ii=0;ii<ssvec.size();ii++)
{
vector<const Item*> ss=ssvec[ii];
for(int jj=0;jj<ss.size();jj++)
cout<<"["<<ss[jj]->item_name<<":"<<ss[jj]->support_count<<"] "; cout<<endl;
}
}
bool comp(Item * a, Item* b)
{
if(a->support_count!=b->support_count)
return a->support_count>b->support_count;
return a->item_name<b->item_name;
}
#ifndef _PF_TREE_H
#define _PF_TREE_H
class PFTree{
map <string,Item *> head_table;
- 16 -
void insert(Item * root,Item **vec,int curP,int maxSize,int );
public :
Item * root;
vector<Item *> T;
int min_support;
void build_PFTree(vector< vector<string> >);//建表
void init_head_table(vector< vector<string> >);//建树
void build_PFTree(vector< vector<const Item *> >);//建表
void init_head_table(vector< vector<const Item *> >);//建树
vector< vector<const Item*> > generate_base_pattern(Item *);//生成基模式 bool is_signal_path(); //查看是否是单源树
void print_tree(Item *r);
void delte_all(Item *root);
void print_head_table();
};
////////////////////////////////生成基模式///////////////////////////////////////////////////////
vector< vector<const Item *> > PFTree::generate_base_pattern(Item * header) {
Item *tmp=header->node_link;
vector< vector<const Item *> > ret;
while(tmp)
{
// if(!tmp->parent_link)break;
Item* tt;
vector<const Item *> inn;
inn.push_back(tmp);
tt=tmp->parent_link;
// debug;
while(tt)
- 17 -
{
if(!tt->parent_link)break;
inn.push_back(tt);
tt=tt->parent_link;
}
ret.push_back(inn);
tmp=tmp->node_link;
}
// cout<<"in"<<endl;
// print(ret);
return ret;
}
/*void PFTree::output_change()
{
freopen("data.out","w",stdout);
}*/
void PFTree::print_head_table()
{
Item *tmp;
int i,s=T.size();
for(i=0;i<s;i++)
{
tmp=T[i];
while(tmp){
cout<<"["+tmp->item_name+":"<<tmp->support_count<<"]"; tmp=tmp->node_link;
}
if(i!=s-1)cout<<"-->";
}
cout<<endl;
- 18 -
}
////////////////////////////////////////// 建立表头 //////////////////////////////////////////////////// void PFTree::init_head_table(vector <vector<string> >ssvec) {
int i,j;
vector <string> svec;
for(i=0;i<ssvec.size();i++)
{
svec=ssvec[i];
for(j=0;j<svec.size();j++)
if(!head_table[svec[j]])
{
Item * n=new Item();
n->support_count=1;
n->item_name=svec[j] ;
n->node_link=NULL;
head_table[svec[j]]=n;
}else {
head_table[svec[j]]->support_count++;
}
}
map<string,Item *>:: iterator it;
for(it=head_table.begin();it!=head_table.end();it++)
{ if(((Item *)it->second)->support_count>=min_support)
{
T.push_back(((Item *)(*it).second));
}
}
- 19 -
sort(T.begin(),T.end(),comp);
}
/////////////////////////////////////// 建树/////////////////////////////////////////////// void PFTree::build_PFTree(vector< vector<string> >svec) {
root=new Item;
Item * t;
root->parent_link=NULL;
vector<string> vec;
Item * tmp[100];
int tmp_size;
for(int i=0;i<svec.size();i++)
{
vec=svec[i];
tmp_size=0;
for(int j=0;j<vec.size();j++)
{
t=head_table[vec[j]];
if(t->support_count>=min_support)
{
tmp[++tmp_size]=t;
}
}
if(tmp_size==0)continue;
sort(tmp+1,tmp+tmp_size+1,comp);
insert(root,tmp,1,tmp_size,1);
}
}
//////////////////////////////// //查看是否是单源树///////////////////////////// bool PFTree::is_signal_path()
- 20 -
{
Item * tmp=root;
while(tmp)
{
if(tmp->child_link.size()>1)return false;
if(tmp->child_link.size()==0)break;
tmp=( tmp->child_link.begin() )->second;
}
return true;
}
/////////////////////////////////////打印树/////////////////////////////////////////
void PFTree::print_tree(Item * r)
{
Item * tmp;
map<string,Item *>:: iterator it;
for(it=r->child_link.begin(); it!=r->child_link.end(); it++)
{
tmp=(Item *)(it->second);
cout<<"[";cout<<tmp->item_name<<":"<<tmp->support_count<<"]"; if((tmp->child_link).size()>0){
cout<<"{";
print_tree(tmp);
cout<<"}";
}
}
}
void PFTree::delte_all(Item * r)
{
if(!r)return ;
if(r->child_link.size()==0){
- 21 -
delete r;return ;
}
map<string,Item *>:: iterator it;
for(it=r->child_link.begin(); it!=r->child_link.end(); it++) {
delte_all(it->second);
}
delete r;
}
void PFTree::init_head_table( vector< vector<const Item *> > ssvec) {
int i,j,sup;
vector <const Item *> svec;
if(ssvec.size()>1)
for(i=0;i<ssvec.size();i++)
{
svec=ssvec[i];
if(svec.size()==1)min_support-=svec[0]->support_count; }
for(i=0;i<ssvec.size();i++)
{
svec=ssvec[i];
sup=svec[0]->support_count;
for(j=1;j<svec.size();j++)
if(!head_table[svec[j]->item_name])
{
Item * n=new Item();
n->item_name=svec[j]->item_name;
n->support_count=sup;
n->node_link=NULL;
- 22 -
head_table[svec[j]->item_name]=n;
}else {
head_table[svec[j]->item_name]->support_count+=sup; }
}
map<string,Item *>:: iterator it;
for(it=head_table.begin();it!=head_table.end();it++)
{
Item * tt=it->second;
if(tt->support_count>=min_support)
{
T.push_back(tt);
}
}
sort(T.begin(),T.end(),comp);
}
void PFTree::build_PFTree( vector< vector<const Item *> > ssvec) {
root=new Item;
Item * t;
root->child_link.clear();
root->parent_link=NULL;
root->support_count=-1;
vector<const Item *> vec;
Item * tmp[100];
int tmp_size;
for(int i=0;i<ssvec.size();i++)
{
vec=ssvec[i];
tmp_size=0;
- 23 -
for(int j=1;j<vec.size();j++)
{
t=head_table[vec[j]->item_name];
if(t->support_count>=min_support)
{
// cout<<t->item_name<<" ss:"<<t->support_count<<endl; tmp[++tmp_size]=t;
}
}
if(tmp_size==0)continue;
sort(tmp+1,tmp+tmp_size+1,comp);
insert(root,tmp,1,tmp_size,vec[0]->support_count);
}
}
void PFTree::insert(Item * root,Item**vec,int curP,int maxSize,int num) {
Item * tmp=NULL;
tmp=root->child_link[vec[curP]->item_name];
if(!tmp){
tmp=new Item;
tmp->item_name=vec[curP]->item_name;
tmp->parent_link=root;
tmp->support_count=num;
tmp->node_link=NULL; ///
root->child_link[tmp->item_name]=tmp;
Item * p=head_table[tmp->item_name];
Item *t=p->node_link;
while(t){
p=t;
- 24 -
t=t->node_link;
}
p->node_link=tmp;
}else {
tmp->support_count+=num;
}
if(curP<maxSize)insert(tmp,vec,curP+1,maxSize,num); }
#endif /* _PF_TREE_H */
(二)源文件
#include <iostream>
#include "PF_Tree.h"
using namespace std;
#define pr printf
#define MIN_SUPPORT 3
PFTree pf_tree;
Item * add_link(Item *a,Item *b)
{
Item *t, *ret,*tmp;
ret=new Item;
*ret=*a;
ret->child_link.clear();
tmp=ret;
while(a)
{
if(a->child_link.size()==0)break;
t=new Item;
*t=*(a->child_link.begin()->second);
t->child_link.clear();
- 25 -
tmp->child_link[t->item_name]=t;
tmp=tmp->child_link.begin()->second;
a=a->child_link.begin()->second;
}
while(b)
{
if(b->child_link.size()==0)break;
for(tmp=ret;;tmp=tmp->child_link.begin()->second) {
if(tmp->item_name==b->item_name)break; if(tmp->child_link.size()==0)break; }
if(tmp->child_link.size()==0){
t=new Item;
*t=*b;t->child_link.clear();
tmp->child_link[b->item_name]=t;
}
b=b->child_link.begin()->second;
}
return ret;
}
void delete_link(Item *a)
{
Item * tmp=a;
while(1)
{
if(tmp->child_link.size()==0){delete tmp;break;}
- 26 -
Item * t;
t=tmp;
tmp=tmp->child_link.begin()->second;
delete t;
}
}
void print(Item * head)
{
while(1)
{
cout<<head->item_name;
if(head->child_link.size()==0)break;
head=head->child_link.begin()->second;
}
}
void print_pattern(Item * now ,Item *now_suff,Item * suff,int sup) {
int cur_sup;
Item *it,*tmp=new Item;
for(it=now;;it=it->child_link.begin()->second)
{
now_suff->child_link.clear();
cout<<"(";
print(suff);
cout<<it->item_name;
cur_sup= sup< it->support_count? sup:it->support_count; cout<<":"<<cur_sup<<") ";
now_suff->child_link[tmp->item_name]=tmp; *tmp=*it;tmp->child_link.clear();
if(it->child_link.size()>0)print_pattern((Item
- 27 - *)it->child_link.begin()->second,(Item
*)now_suff->child_link.begin()->second,suff,cur_sup);
else break;
}
now_suff->child_link.clear();
delete tmp;
}
int flag=1;
void FP_growth( PFTree T,Item * suff)
{
if(T.is_signal_path())
{
print_pattern((Item *)(T.root->child_link.begin()->second),suff,suff,1000000); }else
{
int i,support;
for(i=((T.T).size()-1);i>=0;i--)
{//ai T[i]
Item * tmp=new Item;
*tmp=*T.T[i]; tmp->child_link.clear();
Item *b=add_link(tmp,suff);
delete tmp;
vector< vector<const Item *> > ssvec=T.generate_base_pattern(T.T[i]); PFTree T2;
support=T.T[i]->support_count;
T2.min_support=support;
T2.init_head_table(ssvec);
if(MIN_SUPPORT>T2.min_support){
//goto next;
printf("sup=%d %d\n",support,T2.min_support);
continue;
- 28 -
}
T2.build_PFTree(ssvec);
cout<<"("; print(b);cout<<":"<<T.T[i]->support_count;cout<<") "; if(T2.root->child_link.size()>0)
FP_growth(T2,b);
cout<<endl;
delete_link(b); //debug("end\n");
T2.delte_all(T2.root);
}
}
}
vector < vector<string> > read_data(string file_name);
int main(int argc, char** argv) {
freopen("data.out","w",stdout);
string file_name="data.in";
vector < vector<string> > data=read_data(file_name);
pf_tree.min_support=MIN_SUPPORT;
pf_tree.init_head_table(data);
pf_tree.build_PFTree(data);
if(pf_tree.root->child_link.size()!=0)
FP_growth(pf_tree,NULL);
pf_tree.delte_all(pf_tree.root);
return (EXIT_SUCCESS);
}
vector < vector<string> > read_data(string file_name)
{
int st,ed;
char ch[100];
FILE * fin=fopen(file_name.c_str(),"r");
vector < vector<string> > ret;
- 29 -
while(fgets(ch,100,fin))
{
vector <string>svec;
st=ed=0;
while(1)
{
if(ch[ed]==' ' ||ch[ed]=='\0' ||ch[ed]==13)
{
svec.push_back(string(ch+st,ch+ed));
if(ch[ed]=='\0' || ch[ed]==13 )break;
st=ed+1;
ed=st;
}else ed++;
}
if(svec.size()>0)
ret.push_back(svec);
}
return ret;
}
(3)ECLAT算法的实现:使用Java语言实现,实现代码如下: package com.ustc.eclat;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
- 30 -
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.TreeSet;
public class Eclat {
/** * @param args */ public static void main(String[] args) { /** * 1. 构造垂直数据格式,把原始数据的事务对应的元素集变为由元素对应的事务集 private int minSup; * 2. 对垂直数据格式中的元素Apriori算法
* 2.1 构造频繁1项集:遍历垂直数据格式中的元素并找出其事务集大小满足最小支持度的元素 作为频繁1项集
* 2.2 递归由频繁k-1项集构造频繁k项集:
* 2.2.1 根据Apriori方法判断两个k-1项集是否可连接为项集
* 2.2.2 对于已连接的k项集,判断它的所有k-1项集是否都在频繁k-1项集中出现 * 2.2.3 对于满足2.2.2的k项集,判断其支持度是否满足条件
* */ long startTime = System.currentTimeMillis(); Eclat eclat = new Eclat(); /* * eclat.setMinSup(2); List<String> datas = eclat.buildData(); //构造数据集 */ eclat.setMinSup(1000); List<String> datas = eclat.buildData("retail.dat"); Map<String, Set<String>> itemSetMap = eclat.buildItemSet(datas); // 构造垂直数据格式
- 31 -
// eclat.printVItemSet(itemSetMap); eclat.buildF1Items(itemSetMap); eclat.printItemSet(itemSetMap.keySet(), 1); int i = 2; do { } itemSetMap = eclat.buildFreqItemSet(itemSetMap); eclat.printItemSet(itemSetMap.keySet(), i); i++; } while (itemSetMap.size() != 0); long endTime = System.currentTimeMillis(); System.out.println("共用时:" + (endTime - startTime) + "ms"); // buildFreqItemSet(itemSetMap); //构造频繁集 /** * 1.构造数据集 */ public List<String> buildData(String... fileName) { List<String> data = new ArrayList<String>(); if (fileName.length != 0) { File file = new File(fileName[0]); try { BufferedReader reader = new BufferedReader(new FileReader(file)); String line; while ((line = reader.readLine()) != null) { } data.add(line); } catch (FileNotFoundException e) { e.printStackTrace();
- 32 -
} } catch (IOException e) { } e.printStackTrace(); } else { } return data; data.add("I1 I2 I5"); data.add("I2 I4"); data.add("I2 I3"); data.add("I1 I2 I4"); data.add("I1 I3"); data.add("I2 I3"); data.add("I1 I3"); data.add("I1 I2 I3 I5"); data.add("I1 I2 I3"); /** * 2.构造垂直数据格式 Map-Key为事务中的每一个频繁元素项 Map-Value为每一个事务项对应的事务行的集合
* * @param datas * @return */ public Map<String, Set<String>> buildItemSet(List<String> datas) { Map<String, Set<String>> itemSetMap = new HashMap<String, Set<String>>(); Set<String> tranSet; // 事务集 String[] items; int lineNum = 1; // 事务行号从1开始 for (String data : datas) { // 事务编号以"T" + 事务行号的形式表示;每一条data记录为一行.
- 33 -
} } String tran = "T" + lineNum; items = data.trim().split(" "); for (String item : items) { } lineNum++; if (itemSetMap.get(item) == null) { tranSet = new HashSet<String>(); tranSet.add(tran); itemSetMap.put(item, tranSet); } else { } itemSetMap.get(item).add(tran); return itemSetMap; /** * 3. 由垂直数据格式构造频繁1项集(这里直接在垂直数据格式上进行操作了) * * @param itemSetMap */ public void buildF1Items(Map<String, Set<String>> itemSetMap) { } String[] items = itemSetMap.keySet().toArray(new String[0]); for (String item : items) { } if (itemSetMap.get(item).size() < this.minSup) { } itemSetMap.remove(item);
- 34 -
项集
/** * 4 由频繁1项集开始构造频繁项集 */ public Map<String, Set<String>> buildFreqItemSet( Map<String, Set<String>> preItemSetMap) { String[] items = preItemSetMap.keySet().toArray(new String[0]); Map<String, Set<String>> result = new HashMap<String, Set<String>>(); for (int i = 0; i < items.length - 1; i++) { for (int j = i + 1; j < items.length; j++) { String[] iItems = items[i].split(" "); String[] jItems = items[j].split(" "); if (this.isCanLink(iItems, jItems)) { // 如果两个k-1项集可执行连接操作,则连接成k String[] kItems = new String[iItems.length + 1]; int k = 0; for (; k < iItems.length; k++) { } kItems[k] = jItems[k - 1]; Arrays.sort(kItems); // 对kItems中的元素进行排序 // 判断kItems的所有k-1子集是否包含在items里,如果不全包括,则该k项集kItems[k] = iItems[k]; 必定不频繁
Set<String> kitemSet = new TreeSet<String>(); for (String str : kItems) { } List<Set<String>> preItemSetList = new ArrayList<Set<String>>(); for (String str : items) { }
- 35 - preItemSetList.add(strToSet(str)); kitemSet.add(str);
} } } } if (!isNeedCut(preItemSetList, kitemSet)) { } Set<String> tranSet = this.buildIntersection( preItemSetMap.get(items[i]), preItemSetMap .get(items[j])); if (tranSet.size() >= this.minSup) { } StringBuffer sb = new StringBuffer(); for (String str : kItems) { } result.put(sb.toString().trim(), tranSet); sb.append(str + " "); return result; /** * 4.1 判断两个项集合是否可执行连接操作,由k-1项连接成k项 * * @param s1 * @param s2 * @return */ public boolean isCanLink(String[] s1, String[] s2) { boolean flag = true; if (s1.length == s2.length) { for (int i = 0; i < s1.length - 1; i++) { if (!s1[i].equals(s2[i])) {
- 36 -
} } } flag = false; break; if (s1[s1.length - 1].equals(s2[s2.length - 1])) { } flag = false; } else { } return flag; flag = false; /** * 4.2 把项字符串转为项的集合 * * @param str * @return */ public Set<String> strToSet(String str) { Set<String> itemSet = new TreeSet<String>(); String[] strs = str.split(" "); for (String s : strs) { } itemSet.add(s); } return itemSet; /**
- 37 -
* 4.3 判断set的所有k-1项子集是否都在setList,如果不全在,如果不在该k项集将被cut掉 * * @param setList * @param set * @return */ public boolean isNeedCut(List<Set<String>> setList, Set<String> set) { } boolean flag = false; List<Set<String>> subSets = getSubset(set); // 获得k项集的所有k-1项集 for (Set<String> subSet : subSets) { } return flag; // 判断当前的k-1项集set是否在频繁k-1项集中出现,如出现,则不需要cut // 若没有出现,则需要被cut if (!isContained(setList, subSet)) { } flag = true; break; /** * 4.3.1 获得k项集的所有k-1项集 * * @param set * @return */ List<Set<String>> getSubset(Set<String> set) { List<Set<String>> result = new ArrayList<Set<String>>(); String[] setArr = set.toArray(new String[0]); for (int i = 0; i < setArr.length; i++) {
- 38 -
} } Set<String> subSet = new TreeSet<String>(); for (int j = 0; j < setArr.length; j++) { } result.add(subSet); if (i != j) { } subSet.add((String) setArr[j]); return result; /** * 4.3.2 判断k项集的某k-1项集是否包含在频繁k-1项集列表中 * * @param setList * @param set * @return */ boolean isContained(List<Set<String>> setList, Set<String> set) { boolean flag = false; int position = 0; for (Set<String> s : setList) { String[] sArr = s.toArray(new String[0]); String[] setArr = set.toArray(new String[0]); for (int i = 0; i < sArr.length; i++) { if (sArr[i].equals(setArr[i])) { // 如果对应位置的元素相同,则position为当前位置的值 position = i; } else { }
- 39 - break;
} } } // 如果position等于了数组的长度,说明已找到某个setList中的集合与 // set集合相同了,退出循环,返回包含 // 否则,把position置为0进入下一个比较 if (position == sArr.length - 1) { flag = true; break; } else { } flag = false; position = 0; return flag; /** * 4.4 求两个集合的交集 * * @param s1 * @param s2 * @return */ public Set<String> buildIntersection(Set<String> s1, Set<String> s2) { Map<String, Integer> itemMap = new HashMap<String, Integer>(); Set<String> result = new HashSet<String>(); for (String str : s1) { } for (String str : s2) { if (itemMap.get(str) != null && itemMap.get(str) == 1) {
- 40 - itemMap.put(str, 1);
} } } result.add(str); return result; /** * 输出垂直数据格式 */ public void printVItemSet(Map<String, Set<String>> itemSetMap) { } Set<String> itemSet = itemSetMap.keySet(); Set<String> trans; for (String item : itemSet) { } System.out.print(item + ": "); trans = itemSetMap.get(item); for (String tran : trans) { } System.out.println(); System.out.print(tran + ", "); /** * 输出频繁项集 * @param items * @param i */ public void printItemSet(Set<String> items, int i) { System.out.print("频繁" + i + "项集: 共" + items.size() + "项:"); for (String item : items) {
- 41 -
} } System.out.print("{" + item + "}, "); System.out.println(); public void setMinSup(int minSup) { this.minSup = minSup; }
}
- 42 -
-
数据挖掘大作业结果分析报告
数据仓库期末作业数据挖掘分析报告某药店常用药品信息数据挖掘解决方案作者刘金龙学院计算机信息管理学院专业计算机科学与技术年级20xx…
-
证券客户数据挖掘应用分析报告
证券客户数据挖掘应用分析报告一、前言证券行业是中国计算机应用高度密集的行业之一,较高的信息化水平使其积累了大量的数据,既有企业内部…
-
数据挖掘报告
研究方向前沿读书报告数据挖掘技术的算法与应用目录第一章数据仓库511概论512数据仓库体系结构613数据仓库规划设计与开发7131…
-
数据挖掘实验报告
数据挖掘实验报告班级学号姓名一实验目的掌握使用weka对数据进行apriori算法分类以及聚类的实现方法二实验内容对数据进行apr…
-
分析报告、统计分析和数据挖掘的区别
分析报告统计分析和数据挖掘的区别分析报告给你后见之明hindsight统计分析给你先机foresight数据挖掘给你洞察力insi…
-
数据挖掘读书报告
读书报告数据挖掘可以看成是信息技术自然化的结果。数据挖掘(Datamining),又译为资料探勘、数据采矿。它是数据库知识发现(K…
-
数据挖掘实验报告 超市商品销售分析及数据挖掘
通信与信息工程学院课程设计说明书课程名称数据仓库与数据挖掘课程设计题目超市商品销售分析及数据挖掘专业班级电子商务理组长学号组员学号…
-
数据挖掘报告
研究方向前沿读书报告数据挖掘技术的算法与应用目录第一章数据仓库511概论512数据仓库体系结构613数据仓库规划设计与开发7131…
-
数据挖掘实验报告4
甘肃政法学院本科生实验报告四姓名贾燚学院计算机科学学院专业信息管理与信息系统班级10级信管班实验课程名称数据仓库与数据挖掘实验日期…
-
证券客户数据挖掘应用分析报告
证券客户数据挖掘应用分析报告一、前言证券行业是中国计算机应用高度密集的行业之一,较高的信息化水平使其积累了大量的数据,既有企业内部…
-
月度销售分析报告
月度销售报告(特别说明:以下内容均属模拟演练)过去的一个月,销售部门全体员工,奋发进取,团结协作,在公司的领导和支持下,努力扎实的…