光谱分析实验报告
仪器分析实验----光谱分析
实验一:光谱分析
食质(检测)2010级02班 钟凯成 学号:20105782
一、实验目的:
1、了解主要光学仪器(AAS,AFS,V2S等)的结构;
2、了解原子吸收分光光度计的基本结构和基本方法;
3、紫外吸收曲线的绘制。
二、实验原理:
原子吸收分光光度法又称原子吸收光谱法。它是基于物质所产生的基态原
子蒸气对特定谱线吸收作用来进行定量的一种方法。在高温下试样中的待测元
素的化和物解离而产生代测元素的基态原子。当光源发出的光辐射通过含有基
态原子的蒸气层时,待测元素的基太原子对入射光产生选择性吸收,,即吸收
其特征波长的辐射线,同时,原子由基态跃迁到激发态,光源发出的光强度由
于被吸收而明显减弱,即伴随有吸收光源的产生。此吸收过程符合比耳吸收定
律。
既: I=I0e-K.N.L
式中 K---吸收系数; N---自由原子总数;L---吸收层厚度
其吸光度值A可用下式表示:A=2.303KNL
此式表明,吸光度A与自由原子数N成正比,在一定条件下,N正比于待
测元素的浓度c,则A也正比于待测元素的浓度c。因此,以标准系列法做出标
准曲线后,测的样品溶液吸光度的大小,可从标准曲线上找到相应的浓度值,
再求得待测元素的含量。
三、基本操作技术:
1、样品处理
<1>无机物: 干法, 湿法, 微波
<2>有机物: 分离, 萃取, 显色(衍生)
2、器皿洗涤(原子光谱分析):
1
仪器分析实验----光谱分析
稀硝酸浸泡过夜——洗涤液洗涤——清洗——自然晾干备用
3、实验用水:
蒸馏水、双蒸水、超纯水
4、苯及其衍生物紫外吸收曲线绘制
四、实验仪器简单介绍。
1、原子吸收分光光度计
原子吸收分光光度计一般由四大部分组成,即光源(单色锐线辐射源)、试样 原子化器、单色仪和数据处理系统(包括光电转换器及相应的检测装置)。
2、紫外分光光度计
<1>紫外分光光度计原理:
许多有机化合物在紫外区具有特征的吸收光谱,因此可用紫外分光光度法对有机物质进行定性鉴定,结构分析及定量测定.紫外分光光度法定量测定的依据是比耳定律。首先确定化合物的紫外吸收光谱,确定最大吸收波长。在选定的波长下,作出化合物溶液的工作曲线,根据在相同条件下测得待测液的吸光度值来确定待测液中化合物的含量。
物质的吸收光谱本质上就是物质中的分子和原子吸收了入射光中的某些特定波长的光能量,相应地发生了分子振动能级跃迁和电子能级跃迁的结果。由于各种物质具有各自不同的分子、原子和不同的分子空间结构,其吸收光能量的情况也就不会相同,因此,每种物质就有其特有的、固定的吸收光谱曲线,可根据吸收光谱上的某些特征波长处的吸光度的高低判别或 测定该物质的含量,这就是分光光度定性和定量分析的基础。分光光度分析就是根据物质的吸 收光谱研究物质的成分、结构和物质间相互作用的有效手段。
紫外可见分光光度法的定量分析基础是朗伯-比尔(Lambert-Beer)定律。即物质在一定浓度 的吸光度与它的吸收介质的厚度呈正比
2
仪器分析实验----光谱分析
<2>光度测量:
可同时测量1~6个波长处的透过率和吸光度. ·光谱测量:在波长范围内进行透过率、吸光度和能量的图谱扫描,并可进行各种数据处理如峰谷检测、导数运算、谱图运算等. ·定量测量:单波长、双波长、三波长和多波长测
定.1~9点工作曲线(1~4次)回归. ·动力学测定:在任意设定的波长处进行透过率和吸光度的时间扫描并可进行各种数据运算. ·数据输出:可进行数据文件和参数文件的存取,测量结果以标准通用的数据文件格式输出.下图为紫外吸收曲线的样图。
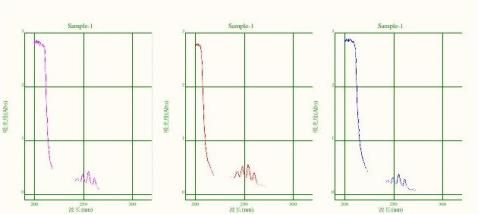
五、结论分析:
由于任何元素的原子都是由原子核和绕核运动的电子组成的,原子核外电子按其能量的高低分层分布而形成不同的能级,因此,一个原子核可以具有多种能级状态。能量最低的能级状态称为基态能级(E0=0),其余能级称为激发态能级,而能最低的激发态则称为第一激发态。
正常情况下,原子处于基态,核外电子在各自能量最低的轨道上运动。如果将一定外界能量如光能提供给该基态原子,当外界光能量E恰好等于该基态原子中基态和某一较高能级之间的能级差E时,该原子将吸收这一特征波长的光,外层电子由基态跃迁到相应的激发态,而产生原子吸收光谱。光谱分析则是在此基础上展开研究的。
3
第二篇:主成分分析和因子分析实验报告
主成分分析实验报告
一、实验数据
20##年,在国内外形势错综复杂的情况下,我国经济实现了平稳较快发展。全年国内生产总值568845亿元,比上年增长7.7%。其中第三产业增加值262204亿元,增长8.3%,其在国内生产总值中的占比达到了46.1%,首次超过第二产业。经济的快速发展也带来了就业的持续增加,年末全国就业人员76977万人,其中城镇就业人员38240万人,全年城镇新增就业1310万人。随着我国城镇化进程的不断加快,加之农业用地量的不断衰减,工业不断的转型升级,使得劳动力就业压力的缓解需要更多的依靠服务业的发展。
(一)指标选择
根据指标选择的可行性、针对性、科学性等原则,选择13个指标来衡量服务业的发展水平,指标体系如表1所示:
表1 服务业发展水平指标体系

(二)指标数据
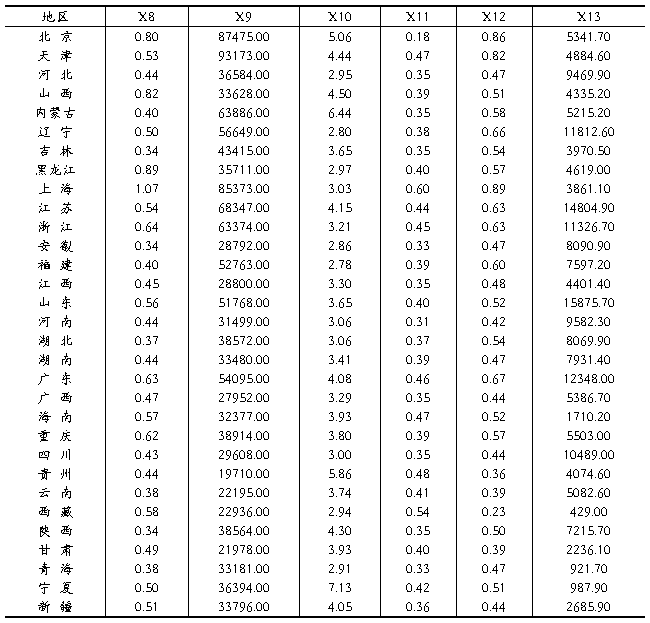
本次实验采用的数据是我国31个省(市、自治区)20##年的数据,原数据均来自《2013中国统计年鉴》以及20##年各省(市、自治区)统计年鉴,不能直接获得的指标数据是通过对相关原始数据的换算求得。原始数据如表2所示:
表2 20##年各地区服务业发展水平统计数据表
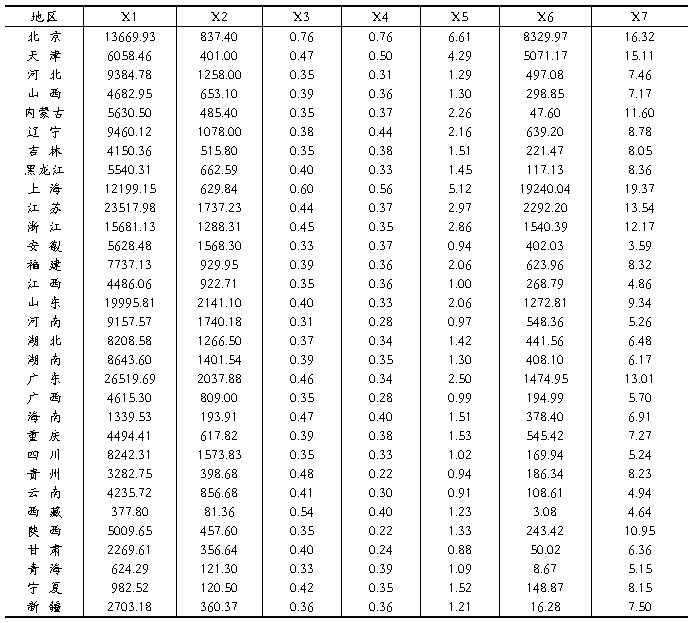
表2(续)
二、实验步骤
本次实验是在SPSS中实现主成分分析,具体步骤如下:
(一)数据标准化,单击主菜单“Analyze”(分析)展开下拉菜单,在下拉菜单中寻找“Descriptive Statistics”,在小菜单中寻找“Descriptives”(描述),展开Descriptives对话框,将左面的矩形框中的变量X1、X2、…、X13,通过单击向右的箭头按钮,调入到右面的“Variables”(变量)框中。选中Save standardized values as variables(对变量进行标准化)复选框,点击OK按
(二)单击主菜单“Analyze”(分析)展开下拉菜单,在下拉菜单中寻找“Data Reduction”弹出小菜单,在小菜单中寻找“Factor”(因子),展开“Factor Analysis”(因子分析)主对话框。
(三)选择分析变量。将左面的矩形框中参与分析的标准化后的变量ZX1、ZX2、…、ZX13,通过单击向右的箭头按钮,调入到右面的“Variables”(变量)框中。
(四)因子分析过程选项,主对话框选择项中共有5个功能按钮:
1.单击【Descriptives】(描述统计量)按钮,展开“Descriptives”对话框,在Statistics中选中Univariate descriptive(单变量描述统计量)和Initial solution(初始因子分析结果),在Correlation Matrix中选择coefficients(相关系数矩阵)、Significance levels(显著性P值),KMO and Bartlett’s test of sphericity,点击Continue按钮。
2.在主对话框中,单击【Extraction】(因子提取)按钮,展开“Extraction”对话框,在Method中选择Principal components(主成分法),其他均为系统默认,点击Continue按钮。
3.在主对话框中,单击【Scores】(因子得分)按钮,展开“Scores”对话框,选中Save as variables(将因子得分作为新变量保存在数据文件中)复选框,单击Continue按钮。
(五)在主对话框中,单击【OK】按钮执行运算。
三、实验结果
(一)利用SPSS进行因子分析
输出结果表3至表4所示。


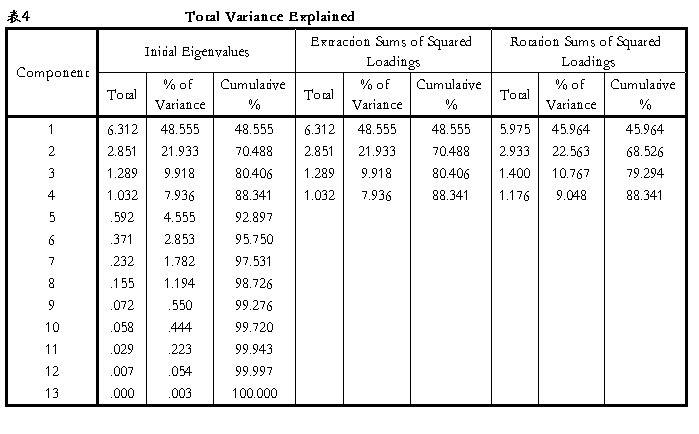
表3中Total列为各因子对应的特征根,本实验中共提取4各公因子;% of Variance列为各因子的方差贡献率;Cumulative %列为各因子累积方差贡献率,由表中可以看出,前四个因子已经可以解释88.341%的方差。
(二)利用因子分析结果进行主成分分析
1.将表4中因子载荷阵中的数据输入SPSS数据编辑窗口,分别命名为a1、a2、a3和a4。
2.为了计算第一个特征向量,点击菜单项中的Transform-Compute,调出Compute variable对话框,在对话框中输入等式:
z1=a1/SQRT(6.312)
点击OK按钮,即可在数据编辑窗口中得到以z1为变量名的第一特征向量。
然后以同样的方式,分别在对话框中输入等式:
z2=a2/SQRT(2.851)
z3=a3/SQRT(1.289)
z4=a4/SQRT(1.032)
得到以z2、z3、z4为变量名的第二、三、四特征向量。这样,可得到如表6所示的特征向量矩阵。
表5 特征向量矩阵
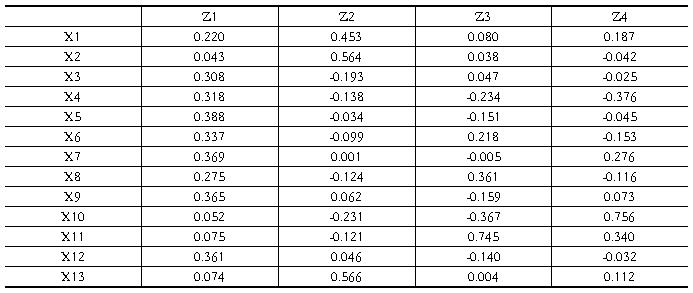
根据表5可以得到主成分的表达式:
Y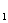 =0.220X+0.043X
=0.220X+0.043X +0.308X
+0.308X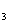 +0.318X
+0.318X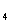 +0.388X
+0.388X +0.337X
+0.337X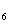 +0.369X
+0.369X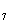 +0.275X
+0.275X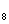 +0.365X
+0.365X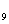 +0.052X
+0.052X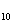 +0.075X
+0.075X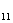 +0.361X
+0.361X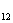 +0.074X
+0.074X
Y=0.453X+0.564X-0.193X-0.138X-0.034X-0.099X+0.001X-0.124X +0.062X-0.231X-0.121X+0.046X+0.566X
Y=0.080X+0.038X+0.047X-0.234X-0.151X+0.218X-0.005X+0.361X -0.159X-0.367X+0.745X-0.140X+0.004X
Y=0.187X-0.042X-0.025X-0.376X-0.045X-0.153X+0.276X-0.116X +0.073X+0.756X+0.340X-0.032X+0.112X
再以特征根为权,对4个主成分进行加权综合,得出各地区的综合得分,具体数据见表6。
综合得分的计算公式是
Y=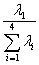 Y+
Y+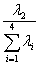 Y+
Y+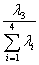 Y+
Y+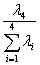 Y
Y
根据上式可以计算出各地区的综合得分,并可据此排序。
表6 各地区主成分得分及排序
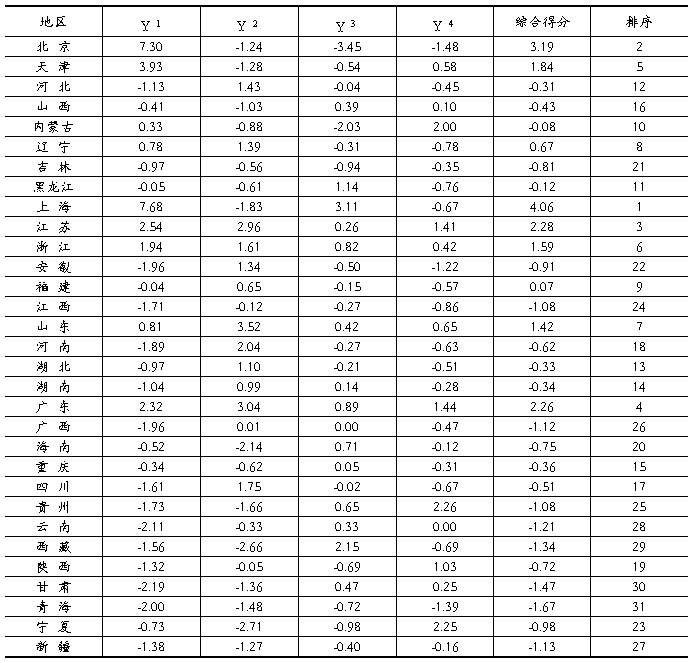
从表6可以看出,上海市的综合评价排在第一,原始数据也反映出其存在明显的规模优势,另外从第一个主成分看,上海市也排在第一位,同样存在效益优势;而排在最后三位的分别是西藏、甘肃、青海。
因子分析实验报告
本次实验采用的是20##年反映我国31个省(直辖市、自治区)服务业发展水平的14个指标(数据见主成分分析报告表2)。14个指标分别为:服务业增加值(X1)、服务业就业人数(X2)、服务业产值比重(X3)、服务业就业比重(X4)、人均服务产品占有量(X5)、服务密度(X6)、服务综合生产率(X7)、服务业贡献率(X8)、人均GDP(X9)、服务业增长速度(X10)、工业化水平(X11)、城市化水平(X12)、服务业全社会固定资产投资(X13).这些指标之间有很强的相关性,如果利用所有14个指标对31个省(直辖市、自治区)进行服务业发展水平分析,难免会出现信息的重叠,而利用因子分析可以解决这个问题。
一、实验步骤
本次实验是在SPSS中实现主成分分析,具体步骤如下:
(一)定义变量及标签 。
(二)输入数据,建立数据文件。
(三)数据标准化,单击主菜单“Analyze”(分析)展开下拉菜单,在下拉菜单中寻找“Descriptive Statistics”,在小菜单中寻找“Descriptives”(描述),展开Descriptives对话框,将左面的矩形框中的变量X1、X2、…、X13,通过单击向右的箭头按钮,调入到右面的“Variables”(变量)框中。选中Save standardized values as variables(对变量进行标准化)复选框,点击OK按钮。
(四)单击主菜单“Analyze”(分析)展开下拉菜单,在下拉菜单中寻找“Data Reduction”弹出小菜单,在小菜单中寻找“Factor”(因子),展开“Factor Analysis”(因子分析)主对话框。
(五)选择分析变量。将左面的矩形框中参与分析的标准化后的变量ZX1、ZX2、…、ZX13,通过单击向右的箭头按钮,调入到右面的“Variables”(变量)框中。
(六)因子分析过程选项,主对话框选择项中共有5个功能按钮:
1.单击【Descriptives】(描述统计量)按钮,展开“Descriptives”对话框,在Statistics中选中Univariate descriptive(单变量描述统计量)和Initial solution(初始因子分析结果),在Correlation Matrix中选择coefficients(相关系数矩阵)、Significance levels(显著性P值),点击Continue按钮。
2.在主对话框中,单击【Extraction】(因子提取)按钮,展开“Extraction”对话框,在Method中选择Principal components(主成分法),其他均为系统默认,点击Continue按钮。
3.在主对话框中,单击【Rotation】(旋转)按钮,展开“Rotation”对话框,在Method(旋转方法)栏中选择Varimax(最大方差旋转项);在Display栏中选择要求的输出项,这里选择Rotated solution(输出旋转后的结果);在Maximum Iterations for Convergence(参数框中指定旋转收敛的最大迭代次数),这里选择系统默认值为25,点击Continue按钮。
4.在主对话框中,单击【Scores】(因子得分)按钮,展开“Scores”对话框,选中Save as variables(将因子得分作为新变量保存在数据文件中)复选框,在Method(方法)框中,选择计算因子得分的方法,这里选用Regression(回归法);选中Display factor score coefficient matrix(输出因子得分系数矩阵)复选框,单击Continue按钮。
5.在主对话框中单击【Options】输出的选择按钮,展开Options对话框,在Missing Value(缺失值)栏中,选择Exclude cases Listwise(有缺失值的观测量一律剔除),在Coefficent display format(选择因子载荷系数的输出方式)中选择Sorted by size(按绝对值大小排列),单击Continue按钮。
(七)在主对话框中,单击【OK】按钮执行运算。
二、实验结果
(一)实验结果输出
输出结果如表1至表7所示:



(二)实验结果解释
1.表1中的KMO值为0.821,说明适合进行因子分析。
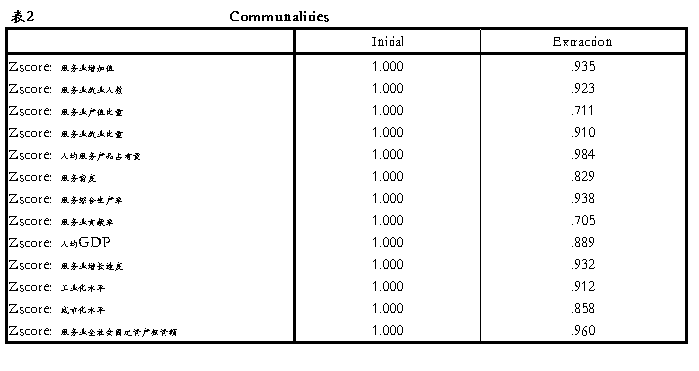
2.Communalities(给出变量共同度)。变量共同度反映了每个变量对所提取的所有公共因子的依赖程度,它描述了全部公共因子对变量的总方差所作的贡献。提取的因子个数不同,变量共同度也不同。从表2可以看出,各变量的共同度均较高,说明全部公共因子对变量的总方差所作的贡献较大,特殊因子的贡献较小。
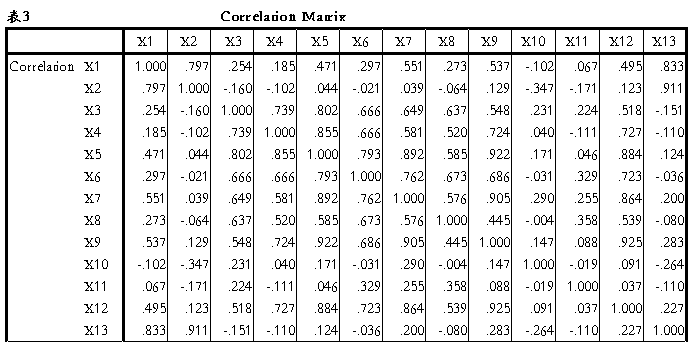
3.Correlation Matrix(相关系数矩阵),从表3可以看出,变量间的相关系数大部分都大于0.3,说明各变量间大多是直接相关的,适合做因子分析。
4.Total Variance Explained(给出各公因子方差贡献表),从表4可以看出,Total列为各因子对应的特征值,本实验中共有4个因子对应的特征值大于1,因此应提取相应的4个公因子;% of Variance列为各因子的方差贡献率;Cumulative %列为各因子的累积方差贡献率,本实验中前四个因子已经可以解释88.341%的方差。Rotation Sums of Squared Loadings给出提取出的公因子经过旋转后的方差贡献情况。
5.Component Matrix(给出旋转前的因子载荷阵),根据表5可以写出每个原始变量的因子表达式:
X=0.553F+0.765F+0.0911F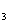 +0.190F
+0.190F
X=0.108F+0.952F+0.043F-0.043F
X=0.775F-0.326F+0.053F-0.025F
…
从表5还可以看出,每个因子在不同原始变量上的载荷没有明显的差别,为了便于对因子进行命名,需要对因子载荷阵进行旋转。
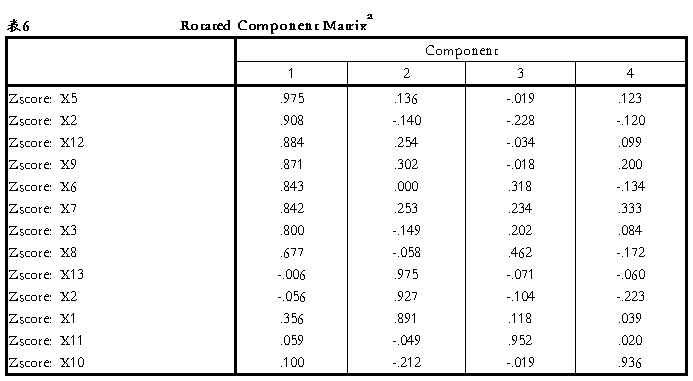
6. Rotated Component Matrix(旋转后因子载荷阵),从表6可以看出,经过旋转后的载荷系数已经明显地两级分化了。第一个公共因子在指标X3、X4、X5、X6、X7、X8、X9、X12上有较大的载荷,说明这8个指标有较强的相关性,可以归为一类,这8个指标属于服务业发展质量指标;第二个公共因子在指标在X1、X2、X13上有较大的载荷,同样可以归为一类,这三个指标属于服务业发展规模指标;同理,X11可以归为一类,这一指标属于服务业发展环境指标;X10可以归为一类,这一指标属于服务业发展潜力指标。
7. Component Score Coefficient Matrix(给出因子得分系数矩阵),根据表7中的因子得分系数和原始变量的标准化值可以计算每个观测值得各因子的得分数,并可以据此对观测量进行进一步的分析。本实验中旋转后的因子得分表达式可以写成:
F=-0.003X-0.037X+0.138X+0.226X+0.175X +0.145X
+0.145X +0.093X+0.103X
+0.093X+0.103X +0.136X
+0.136X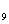 -0.055X-0.093X+0.153X-0.049X
-0.055X-0.093X+0.153X-0.049X
F=0.315X+0.316X-0.086X-0.134X-0.001X-0.049X+0.085X-0.055X +0.074X+0.007X+0.033X+0.045X+0.349X
F=0.104X-0.033X+0.064X-0.292X-0.111X+0.148X+0.117X+0.273X -0.085X+0.003X+0.732X-0.106X-0.003X
F=0.094X-0.111X-0.007X-0.220X+0.031X-0.189X+0.257X-0.208X +0.127X+0.821X+0.049X+0.029X+0.038X
8.由于在Scores子对话框中选择了Save as variables复选框,因此,因子得分已经作为新的变量保存在数据文件中,变量名分别为fac1_1,fac2_1,fac3_1,fac4_1,将各因子整理得到表8,这里以特征根为权重,计算综合得分:
F=F+F+F+F
表8 各地区的4个因子得分表

-
光谱分析实验报告
仪器分析实验光谱分析实验一光谱分析食质检测20xx级02班钟凯成学号20xx5782一实验目的1了解主要光学仪器AASAFSV2S…
-
报告发射光谱定性与定量分析
华南师范大学实验报告学生姓名杨秀琼学号20xx2401129专业化学年级班级08化二课程名称仪器分析实验实验项目发射光谱定性分析实…
-
红外光谱分析实验报告
一实验题目红外光谱分析实验二实验目的1了解傅立叶变换红外光谱仪的基本构造及工作原理2掌握红外光谱分析的基础实验技术3学会用傅立叶变…
-
仪器分析实验一 紫外吸收光谱定性分析的应用
实验一紫外吸收光谱定性分析的应用一实验目的1掌握紫外吸收光谱的测绘方法2学会利用吸收光谱进行未知物鉴定的方法3学会杂质检出的方法二…
-
实验10 碳酸钙、聚乙烯醇、丙三醇、乙醇的红外光谱定性分析(罗娅君)
实验十碳酸钙聚乙烯醇丙三醇乙醇的红外光谱定性分析一实验目的1了解傅立叶变换红外光谱仪的基本构造及工作原理2掌握红外光谱分析的基础实…
-
光谱分析 实验报告
实验报告课程名称材料科学基础实验指导老师乔旭升成绩实验名称光谱分析实验类型同组学生姓名一实验目的和要求必填三主要仪器设备必填五实验…
-
分光光度计实验报告
实验六分光光度法测溴酚蓝的电离平衡常数王思雨PB1220xx07中国科学技术大学生命科学院摘要本实验中我们通过使用722型分光光度…
-
紫外分光光度计实验报告
UV2550紫外分光光度计的使用和分光光度法测定对苯二酚姓名XXX专业有机化学学号3120xx303004时间20xx10211目…
-
分析化学实验报告(分光光度法)(2)
广西师范学院化学系化学实验报告册课程名称分析化学实验班级高分班学号姓名组别20xx年至20xx年第一学年第二学期广西师范学院化学实…
-
紫外可见分光光度计实验报告
实验报告一实验题目浓度为01的TiO2水悬浮液的光谱分析二实验日期三实验人员四实验目的本实验目的是掌握TiO2的光学特性特别是在紫…
-
红外光谱分析实验报告
一实验题目红外光谱分析实验二实验目的1了解傅立叶变换红外光谱仪的基本构造及工作原理2掌握红外光谱分析的基础实验技术3学会用傅立叶变…