算法与数据结构栈与队列实验报告
实验二栈和队列实现四则运算
一、实验目的及要求:
1、掌握栈和队列的基本操作:建立、插入、删除、查找、合并
2、掌握用栈和队列的储存
3、熟悉C语言上机编程环境
4、掌握编译、调试程序的方法
二、实验内容:
采用栈进行表达式的求值,表达式求值是程序设计语言编译中的一个最基本问题。它的实现是栈应用的又一个典型例子,本报告使用的是“算符优先法”求表达式的值。
要把一个表达式翻译成正确求值的一个机器指令序列,或者直接对表达式求值,首先要能够正确解释表达式。若要正确翻译则首先要了解算术四则运算的规则。即:
(1)、先乘除,后加减;
(2)、从左算到右;
(3)、先括号内后括号外。
任何一个表达式都是由操作数、运算符和界限符组成的,我们称它们为单词。一般地,操作数既可以是常数也可以是被说明为变量或常量的标识符;运算符可以分为算术运算符、关系运算符和逻辑运算符3类;基本界限符有左右括号和表达式结束符等。为了叙述的简洁,我们仅讨论简单算术表达式的求值问题。这种表达式只包含加、减、乘、除4种运算符。
我们把运算符和界限符统称为算符,它们构成的集合命名为OP。根据上述3条运算规则,在运算的每一步中,任意两个相继出现的算符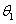 和
和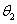 之间的优先级之多是以下3种关系之一:
之间的优先级之多是以下3种关系之一:
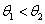 的优先级低于
的优先级低于
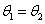 的优先级等于
的优先级等于
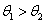 的优先级高于
的优先级高于
根据实际情况推导出如下的优先关系
算符间的优先关系表

有规则(3),+、-、*和/为时优先性均低于“(”但高于“),”由规则(2),当时,令,“#”是表达式的结束符。为了算法简洁,在表达式左右括号的最左边也虚设了一个“#”构成整个表达式的一对括号。表中的“(”=“)”表示当左右括号相遇时,括号内的运算已经完成。同理,“#”=“#”表示整个表达式求值完毕。“)”与“(、“#”与“)”以及“(”与“#”之间无优先级,这是因为表达式中不允许它们相继出现,一旦遇到这种情况,则可以认为出现语法错误。
为实现算符优先算法,可以使用两个栈。一个称作OPTR,用以寄存运算符;另一个称作OPND,用以寄存操作数户哟运算结果。算法的基本思想是:
(1)首先输入一个表达式,用一数组记录;
(2)置操作数栈为空栈,表达式起始符“#”为运算符栈的栈底元素;
(3)依次读入表达式中的每个字符,若是操作数则进OPND栈,若是运算符则和OPTR栈的栈顶元素比较优先权后作相应操作,直至整个表达式求值完毕(即OPTR栈的栈顶元素和当前读入的字符均为“#”)。
三、程序代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define error 0 //错误标志
#define ok 1 //正确标志
#define overflow -1 //溢出标志
#define Stack_Size 100 //一般表达式运算符和运算数不会很长,100足够用
#define OP_Size 7 //一共7种运算符
char OP[OP_Size]={'+','-','*','/','(',')','#'}; //运算符
unsigned char Prior[7][7] = {
'>','>','<','<','<','>','>',
'>','>','<','<','<','>','>',
'>','>','>','>','<','>','>',
'>','>','>','>','<','>','>',
'<','<','<','<','<','=',' ',
'>','>','>','>',' ','>','>',
'<','<','<','<','<',' ','='
}; // 算符间的优先关系
template <typename T>
struct SqStack
{
T *top;
T *base;
int stacksize;
};//顺序栈结构模板
template <typename T1,typename T2>
int InitStack(T1 &S)
{
S.base=(T2 *)malloc(Stack_Size*sizeof(T2));
if(!S.base) exit (overflow);
S.top=S.base;
S.stacksize=Stack_Size;
return ok;
}//初始化栈函数模板
template <typename T1,typename T2>
int Push(T1 &S,T2 e)
{
if(S.top-S.base>=S.stacksize)
{
S.base=(T2 *)realloc(S.base,(S.stacksize+1)*sizeof(T2));
if(!S.base) exit (overflow);
S.top=S.base+S.stacksize;
S.stacksize+=1;
}
*S.top++=e;
return ok;
}//入栈函数模板
template <typename T1,typename T2>
int Pop(T1 &S,T2 &e)
{
if(S.top==S.base) return error;
e=*--S.top;
return ok;
}//出栈函数模板
template <typename T1,typename T2>
T2 GetTop(T1 S)
{
if(S.top==S.base)
return error;
else
return *(S.top-1);
}//获取栈顶元素模板
int In(char Test,char* TestOp) {
bool Find=false;
for (int i=0; i< OP_Size; i++) {
if (Test == TestOp[i]) Find= true;
}
return Find;
}//判断是否为运算符
float Operate(float a,unsigned char theta, float b) {
switch(theta) {
case '+': return a+b;
case '-': return a-b;
case '*': return a*b;
case '/': return a/b;
default : return 0;
}
}//运算
int ReturnOpOrd(char op,char* TestOp) {
int i;
for(i=0; i< OP_Size; i++) {
if (op == TestOp[i]) return i;
}
return 0;
}
char precede(char Aop, char Bop) {
return Prior[ReturnOpOrd(Aop,OP)][ReturnOpOrd(Bop,OP)];
}//ReturnOpOrd和precede组合,判断运算符优先级
float EvaluateExpression() {
// 算术表达式求值的算符优先算法。
// 设OPTR和OPND分别为运算符栈和运算数栈,OPSET为运算符集合。
SqStack<char> OPTR; // 运算符栈,字符元素
SqStack<float> OPND; // 运算数栈,实数元素
char TempData[20];
float Data,a,b;
char theta,c,x,Dr[2];
InitStack<SqStack<char>,char> (OPTR);
Push (OPTR, '#');
InitStack <SqStack<float>,float>(OPND);
strcpy(TempData,"\0");//将TempData置为空
c=getchar();
while (c!= '#' || GetTop<SqStack<char>,char>(OPTR)!= '#')
{
if (!In(c, OP))
{
Dr[0]=c;
Dr[1]='\0';//存放单个数
strcat(TempData,Dr);//将单个数连到TempData中,形成字符串
c=getchar();
if(In(c,OP))//如果遇到运算符,则将字符串TempData转换成实数,入栈,
//并重新置空
{
Data=(float)atof(TempData);
Push(OPND, Data);
strcpy(TempData,"\0");
}
}
else
{ // 不是运算符则进栈
switch (precede(GetTop<SqStack<char>,char>(OPTR), c)) {
case '<': // 栈顶元素优先权低
Push(OPTR, c);
c=getchar();
break;
case '=': // 脱括号并接收下一字符
Pop(OPTR, x);
c=getchar();
break;
case '>': // 退栈并将运算结果入栈
Pop(OPTR, theta);
Pop(OPND, b);
Pop(OPND, a);
Push(OPND, Operate(a, theta, b));
break;
} // for switch
}
} // for while
return GetTop<SqStack<float>,float>(OPND);
} // EvaluateExpression
void main()
{
printf("请输入表达式,并以#结尾:\n");
printf("%f\n",EvaluateExpression());
}
四、运行结果:

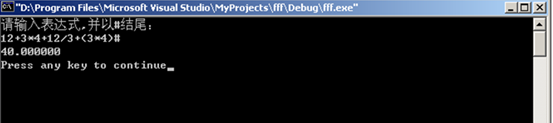
五、实验心得
运用栈来实现最简单的四则运算,从实例中了解栈和队列的结构,以及进栈和出栈的过程。有关栈的构造、入栈、出栈等模块的代码都有源程序可参考,完成本实验的代码只需要组合学过的各个模块,结合起来进行相应的调试就可以实现。从中学会了写程序不一定所有代码都是自己重新写的,只要会运用、会调试就能高效地完成。这就要求在学习的过程中多积累好的源代码以备不时之需,也应该多尝试着自己去调试程序完成一些功能。这样在学好了算法与数据结构的前提下就能很快地写出自己需要的程序。
第二篇:本科生《算法与数据结构》实验报告3
《算法与数据结构》实验报告
学院 专业 姓名 学号
实验1: ADT List(线性表)(3学时)
[问题描述]
线性表是典型的线性结构,实现ADT List,并在此基础上实现两个集合的交运算或并运算。
[实验目的]
(1)掌握线性表链表存储结构。
(2)掌握在单链表上基本操作的实现。
(3)在掌握单链表的基本操作上进行综合题的实现。
[实验内容及要求]
(1) 要求用带头结点的单链表存储两个集合中的元素和最终的结果。
(2) 集合的元素限定为十进制数,程序应对出现重复的数据进行过滤,即链表中没有
重复数据。
(3) 显示两个集合的内容及其运算结果。
[测试数据]
(1) set1={3, 8, 5, 8,11},set2={22, 6, 8, 3, 15,11,20 }
set1∪set2=
set1∩set2=
(2) set1={1, 3, 5, 7},set2={2, 3, 7, 14, 25,38}
set1∪set2=
set1∩set2=
[思考]
(1)分析你所设计的算法的时间复杂度?
(2) 若输入两个集合内的元素是递增的,见测试数据(2),请你提出一种时间复杂度更少的
算法思想,并分析时间复杂度是多少?
《算法与数据结构》实验报告
学院 专业 姓名 学号
实验2:利用栈将中缀表达式转换为后缀表达式并进行计算(3学时)
[问题描述]
中缀表达式是最普通的一种书写表达式的方式,而后缀表达式不需要用括号来表示,计算机可简化对后缀表达式的计算过程,而该过程又是栈的一个典型应用。
[实验目的]
(1) 深入理解栈的特性。
(2) 掌握栈结构的构造方法。
[实验内容及要求]
(1) 中缀表达式中只包含+、-、×、/ 运算及( 和 )。
(2) 可以输入任意中缀表达式,数据为一位整数。
(3) 显示中缀表达式及转换后的后缀表达式(为清楚起见,要求每输出一个数据用逗
号隔开)。
(4) 对转换后的后缀表达式进行计算。
栈的类定义如下:
#include <iostream.h>
const int StackSize=50;
class Stack{
char *StackList;
int top;
public:
Stack(){
StackList=new char[StackSize];
top=-1;
}
bool IsEmpty();
bool IsFull();
void Push(char x);
char Pop();
char GetTop();
void postexpression();
}; // Stack
[测试数据]
(1) 6+3*(9-7)-8/2
转换后的后缀表达式为:
计算结果为:
(2) (8-2)/(3-1)*(9-6)
转换后的后缀表达式为:
计算结果为:
[思考]
(1) 把中缀表达式转化为后缀表达式的好处?
(2) 考虑当表达式中数据的位数超过一位时,如何修改你的程序?困难在哪?
《算法与数据结构》实验报告
学院 专业 姓名 学号
实验3:n皇后问题(6学时)
[问题描述]
在一个n×n的国际象棋棋盘上按照每行顺序摆放棋子,在棋盘上的每一个格中都可以摆放棋子,但任何两个棋子不得在棋盘上的同一行、同一列、同一斜线上出现,利用递归算法解决该问题,并给出该问题的n个棋子的一个合理布局。
[实验目的]
(1) 深入理解栈的特性。
(2) 掌握使用递归实现某些问题。
(3) 设计出应用栈解决在实际问题背景下对较复杂问题的递归算法。
[实验内容及要求]
(1) 从棋盘的第一行开始放起。
(2) 输出最后每个棋子的在棋盘上的坐标(最好以矩阵形式输出)。
[测试数据]
自定n值。
[思考]
(1) 设计一个递归算法的三要素是什么?
(2) 考虑用非递归实现该问题,并从中总结递归算法和非递归算法的优、缺点各是什
么?
(3) 通过对递归算法的理解,总结把一个递归算法转换为非递归算法的方法(可查参考书),并把求n的阶乘的递归算法转换为非递归算法。
《算法与数据结构》实验报告
学院 专业 姓名 学号
实验4:打印二项展开式(a+b)n的系数(3学时)
[问题描述]
将二项式(a+b)n展开,系数构成著名的杨辉三角形,这是典型的对队列的应用。
[实验目的]
(1)深入理解队列的特性。
(2)掌握使用队列实现某些问题。
[实验内容及要求]
要求打印形式为 1 1
1 2 1
1 3 3 1
1 4 6 4 1
……………
[测试数据]
自定n值。
[思考]
(1)杨辉三角形中系数之间的关系是什么?
(2)栈和队列各应用于什么范围?
《算法与数据结构》实验报告
学院 专业 姓名 学号
实验5:实现二叉树的基本操作 (6学时)
[问题描述]
树和二叉树是最常用的非线性结构(树型结构),其中以二叉树最为常见,本实验题要求实现二叉树的最基本操作,其中遍历二叉树是二叉树各种操作的基础,它分为先序、中序和后序。
[实验目的]
(1) 熟练掌握二叉树的结构特性。
(2) 掌握二叉树的各种存储结构的特点及实用范围。
(3) 通过二叉树的基本操作的实现,从而思考一般树的基本操作的实现。
(4) 熟练掌握各种遍历二叉树的递归和非递归算法。
[实验内容及要求]
(1)创建二叉树:createBTree(…)
所谓创建二叉树是指按照某一种或某两种遍历序列建立起来的二叉树的存储结构。
(2)求叶结点的数目:getLeavesNum()
(3)画二叉树:drawBTree()
(4)输出二叉树的中序遍历序列。
[测试数据]
(1) 以下图所示1或2的形状画出二叉树(不需画线),从中体会画这两种形状的图的
难易程度。
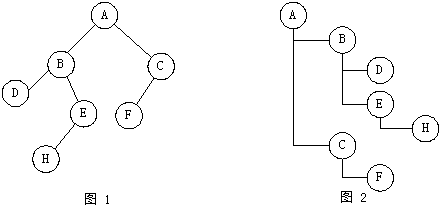
中序遍历序列结果为:
(2)自己设定几组序列来验证程序的正确性。
[思考]
(1)若二叉树采用顺序存储,有什么缺点?
(2)根据任意两种遍历序列重建二叉树,然后给出另外一种遍历序列。
(3)在遍历二叉树的算法中,你用的是递归算法?还是非递归算法?若你用的是递归算法,请考虑用非递归算法实现对二叉树的遍历;反之考虑用递归算法实现对二叉树的遍历。
《算法与数据结构》实验报告
学院 专业 姓名 学号
实验6:哈夫曼树的编/译码器系统的设计(6学时)
[问题描述]
利用哈夫曼编码进行通讯可以大大提高信道利用率,缩短信息传输时间,降低传输成本。但是,这要求在发送端通过一个编码系统对待传数据进行预先编码;在接受端将传来的数据进行解码(复原)。对于可以双向传输的信道,每端都要有一个完整的编/译码系统。试为这样的信息收发站写一个哈夫曼的编译码系统。
[实验目的]
(1) 通过哈夫曼树的定义,掌握构造哈夫曼树的意义。
(2) 掌握构造哈夫曼树的算法思想。
(3) 通过具体构造哈夫曼树,进一步理解构造哈夫曼树编码的意义。
[实验内容及要求]
(1) 从终端读入字符集大小为n(即字符的个数),逐一输入n个字符和相应的n个权值(即字符出现的频度),建立哈夫曼树,将它存于文件 hfmtree 中。并将建立好的哈夫曼树以树或凹入法形式输出;对每个字符进行编码并且输出。
(2) 利用已建好的哈夫曼编码文件 hfmtree ,对键盘输入的正文进行译码。输出字符正文,再输出该文的二进制码。
[测试数据]
用下表给出的字符集和频度的实际统计数据建立哈夫曼树:

并实现以下报文的译码和输出:THIS PROGRAM IS MY FAVORITE
[思考]
(1) 利用哈夫曼编码,为什么能使报文中的电文总长度减少?
(2) 为什么利用哈夫曼算法求出的一个字符的编码都不是其它字符编码的前缀?
《算法与数据结构》实验报告
学院 专业 姓名 学号
实验7:图的遍历(6学时)
[问题描述]
给定一个无向图或有向图,利用深度优先遍历和广度优先遍历对给定图进行遍历。
[实验目的]
(1) 熟悉图的两种常用的存储结构。
(2) 掌握对图的两种遍历方法,即深度优先遍历和广度优先遍历。
(3) 进一步掌握利用递归或队列结构进行算法设计方法。
[实验内容及要求]
(1)构造一个具有n个顶点的无向图或有向图。
(2)输出以深度优先遍历和广度优先遍历后的顶点序列。
[测试数据]
以下图作为测试数据:
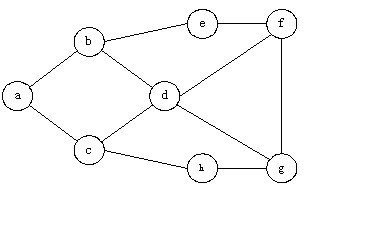
输出结果:
[思考]
(1) 在你所设计的算法中,使用了什么数据结构?
(2) 考虑如何把书上给出的递归实现的深度优先遍历算法改为非递归算法?
《算法与数据结构》实验报告
学院 专业 姓名 学号
实验8:利用Kruskal算法求无向网的最小生成树(6学时)
[问题描述]
如要在n个城市之间建设通信网络,只需架设n-1条线路即可。如何以最低的经济代价建设这个通信网,是求一个无向网的最小生成树问题。
[实验目的]
(1) 掌握图的各种存储结构和基本操作。
(2) 对于实际问题的求解会选用合适的存储结构。
(3) 通过Kruskal算法理解如何求无向网的最小生成树。
[实验内容及要求]
(1)构造具有n个顶点的无向网,并利用Kruskal算法求网的最小生成树。
(2)以文本形式输出所求得的最小生成树中各条边以及它们的权值。
[测试数据] 以下图作为测试数据:
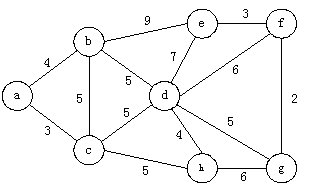
输出结果:
[思考]
(1) 如何判断输入的无向网存在最小生成树? 若不存在,请分析是何缘故?
(2) 在输入数据过程中,你如何处理一条边(权值不同)输入1次以上的情况?
(3) 在设计该算法时,你遇到的最大困难是什么? 你是如何解决的?
《算法与数据结构》实验报告
学院 专业 姓名 学号
综合设计实验题目
以下综合题目可根据实际情况选做。
题目1:内部排序算法比较(6学时)
[问题描述]
排序是计算机程序设计中一种重要操作,它的功能是将一个数据元素(或记录)的任意序列重新排列成一个按关键字有序的序列。本实验熟悉几种典型的排序方法,并对各种算法的特点、使用范围和效率进行进一步的了解。
[实验目的]
(1) 深刻理解排序的定义和各类排序的算法思想,并能灵活应用。
(2) 掌握各类排序的时间复杂度的分析方法,能从“关键字间的比较次数”分析算法的平均情况、最好情况和最坏情况。
(3) 理解排序方法“稳定”和“不稳定”的含义。
[实验内容及要求]
① 数据由输入或随机函数产生。
② 实现快速排序、堆排序和归并排序算法。
③ 至少要用5组不同的输入数据做比较(每组数据不小于100),统计测试数据的准确的关键字的比较次数和移动次数(需在算法的适当位置插入对关键字的比较次数和移动次数的计数)
④ 对结果作出简单的分析。
[测试数据]
由随机函数产生(还应考虑正序、逆序和随机序列)。
[思考]
(1) 对于快速排序,就平均时间而言,它被认为是目前最好的一种内部排序方法,但它对应某些特殊序列(例如正序和逆序),时间复杂度是最差的,你认为这种原因是如何造成的?对算法如何做改进可以避免这一情况?
(2) 为什么利用堆排序比用简单选择排序能降低时间复杂度?
(3) 归并排序适用于元素个数少的还是多的? 空间利用率怎么样?
(4) 分析快速排序、堆排序和归并排序的时间复杂度在平均情况下和最坏情况下各为多少?
《算法与数据结构》实验报告
学院 专业 姓名 学号
题目2:伙伴系统(6学时)
[问题描述]
伙伴系统属于动态存储管理系统中的一种,系统通过响应用户提出的“请求”和“释放”内存的大小而对内存进行管理,在用户提出“请求”时,分配一块大小“恰当” 的内存区给用户;在用户释放内存区时及时回收。与其它动态存储管理方法不同的是:无论是占用块还是空闲块,其大小均为2的k次幂(k为某个正整数)。
[实验目的]
(1) 掌握数组的应用;
(2) 掌握静态链表的应用;
(3) 掌握内存管理的分配与回收;
[实验内容及要求]
(1) 最小内存块是4字节,最大是64K。
(2) API有: initiate(int k):初始化, k 是空间的大小,即2的k次方。
new(int k): 分配大小为2的k次方的块。
free(int ad):释放首地址为ad的块。
getMap():按地址顺序显示内存块的情况,如:
0 - 15 : 0 4 // 0 – 15 表示内存块的首尾地址, 0表示该块空闲
16 - 31 : 1 4
32 - 95 : 1 5
……
每行的格式为:a – b : t k
a – b: 表示内存块的首尾地址;
t: 0表示该块空闲,1表示占用;
k: 表示内存块的大小为2的k次方;
(3) 构造2个分配回收序列进行测试,其中至少有5次分配,3次回收。
[测试数据]
(1) 你的测试序列1是:
按测试序列执行分配回收后内存情况是:
(2)你的测试序列2是:
按测试序列执行分配回收后内存情况是:
(3)执行new(16) 后的结果是什么?
之后在执行new(4) 的结果是什么?
- 数据结构栈和队列实验报告
-
数据结构顺序栈实验报告
一设计人员相关信息1设计者姓名学号和班号12地信李晓婧120xx2429832设计日期20xx3上机环境VC60二程序设计相关信息…
-
数据结构出栈、入栈实验报告
数据结构实验报告院系应用科技学院专业电子信息工程姓名学号班1实验目的123熟悉栈的定义和栈的基本操作掌握顺序存储栈和链接存储栈的基…
-
数据结构实验报告(栈的应用)
实习报告题目编制一个演示表达式求值的操作的程序班级计算机信息安全姓名学号完成日期需求分析本演示程序中元素限定为int整型和char…
-
数据结构实验报告二栈的应用
数据结构实验指导书姓名修凌云姓名李赛赛信息与计算科学教研室实验一栈及其应用实验目的熟悉栈的基本概念熟练掌握并实现栈的基本操作以及两…
-
云南大学软件学院数据结构实验六实验报告——赫夫曼编码译码器
云南大学软件学院数据结构实验报告本实验项目方案受教育部人才培养模式创新实验区X3108005项目资助实验难度ABC学期任课教师实验…
-
数据结构实验报告(C语言)(强力推荐)
数据结构实验实验内容和目的掌握几种基本的数据结构集合线性结构树形结构等在求解实际问题中的应用以及培养书写规范文档的技巧学习基本的查…
-
数据结构实验报告 栈和队列
20xx级数据结构实验报告实验名称实验二栈和队列日期20xx年11月15日1实验要求实验目的通过选择下面五个题目之一进行实现掌握如…
- 数据结构栈和队列实验报告
- 数据结构栈和队列实验报告
-
栈和队列实验报告
规格为A4纸或A3纸折叠注1实验报告的内容一实验目的二实验原理三实验步骤四实验结果五讨论分析完成指定的思考题和作业题六改进实验建议…