数据挖掘课程设计报告正文
目录
§第1章 数据挖掘基本理论. 1
§1.1 数据挖掘的产生. 1
§1.2 数据挖掘的概念. 2
§1.3 数据挖掘的步骤. 3
§第2章 系统分析. 3
§2.1 系统用户分析. 3
§2.2 系统功能分析. 4
§2.3 系统算法分析. 4
§第3章 数据管理. 5
§3.1 数据管理的方法. 5
§第4章 数据采集. 6
§4.1 数据采集的方法. 6
§第5章 数据预处理. 6
§5.1 数据预处理的方法. 6
§第6章 数据挖掘. 6
§6.1算法描述与流程图. 6
§6.1.1 算法描述. 6
§6.1.2 算法流程图. 8
§第7章 结果显示与解释评估. 8
§7.1结果显示界面的具体实现. 8
§7.1.1 系统主界面的具体实现. 9
§7.1.2 超市销售记录界面的具体实现. 9
§7.1.3 数据采集界面的具体实现. 10
§7.1.4 挖掘条件界面的具体实现. 11
§7.1.5 数据挖掘界面的具体实现. 12
§7.1.6 帮助界面的具体实现. 13
§7.1.7 系统主界面运行后显示的结果. 13
学习体会. 14
参考文献. 15
§第1章 数据挖掘基本理论
§1.1 数据挖掘的产生
随着计算机硬件和软件的飞速发展,尤其是数据库技术与应用的日益普及,人们面临着快速扩张的数据海洋,如何有效利用这一丰富数据海洋的宝藏为人类服务业已成为广大信息技术工作者的所重点关注的焦点之一。与日趋成熟的数据管理术与软件工具相比,人们所依赖的数据分析工具功能,却无法有效地为决策者提其决策支持所需要的相关知识,从而形成了一种独特的现象“丰富的数据,贫乏知识”。为有效解决这一问题,自二十世纪年代开始,数据挖掘技术逐步发展来,数据挖掘技术的迅速发展,得益于目前全世界所拥有的巨大数据资源以及对这些数据资源转换为信息和知识资源的巨大需求,对信息和知识的需求来自各行业,从商业管理、生产控制、市场分析到工程设计、科学探索等。数据挖掘可以为是数据管理与分析技术的自然进化产物,如图1.1所示。
自八十年到中期开始,关系数据库技术被普遍采用,新一轮研究与开发新型强大的数据库喜用悄然兴起,并提出了许多先进的数据模型:扩展关系模型、面向对象模型、演绎模型等;以及应用数据库系统:空间数据库、时序数据库、多媒体数据库等;日前异构数据库系统和基于互联网的全球信息系统也已开始出现并在信息工业中开始扮演重要角色。

图1-1 数据挖掘进化过程示意描述
§1.2 数据挖掘的概念
数据挖掘(Data Mining,简称 DM),简单地讲就是从大量数据中挖掘或抽取出知识,数据挖掘概念的定义描述有若干版本,一下给出一个被普遍采用的定义描述:
数据挖掘,又称为数据库中知识发现(Knowledge Discovery from Database,简称 KDD),它是一个从大量数据中抽取挖掘出未知的、有价值的模式或规律等知识的复杂过程。
§1.3 数据挖掘的步骤
整个知识挖掘(KDD)过程是有若干挖掘步骤组成的,而数据挖掘近视其中的一个主要步骤。整个知识挖掘的主要步骤有:
数据清洗(data clearning),其作用就是清除数据噪声和与挖掘主题明显无关的数据;
数据集成(data integration),其作用就是将来自多数据源中的相关数据组合到一起;
数据转换(data transformation),其作用就是将数据转换为易于进行数据挖掘的数据存储形式;
数据挖掘(data mining),它是知识挖掘的一个基本步骤,其作用就是利用智能方法挖掘数据模式或规律知识;
模式评估(pattern evaluation),其作用就是根据一定评估标准(interesting measures)从挖掘结果筛选出有意义的模式知识;
知识表示(knowledge presentation),其作用就是利用可视化和知识表达技术,向用户展示所挖掘出的相关知识。
尽管数据挖掘仅仅是整个知识挖掘过程中的一个重要步骤,但由于目前工业
界、媒体、数据库研究领域中,“数据挖掘”一词已被广泛使用并被普遍接受,因此本书也广义地使用“数据挖掘”一词来表示整个知识挖掘过程,即数据挖掘就是一个从数据库、数据仓库或其它信息资源库的大量数据中发掘出有趣的知识。
§第2章 系统分析
§2.1 系统用户分析
利用数据挖掘技术可以帮助获得决策所需的多种知识。在许多情况下,用户并不知道数据存在哪些有价值的信息知识,因此对于一个数据挖掘系统而言,它应该能够同时搜索发现多种模式的知识,以满足用户的期望和实际需要。此外数据挖掘系统还应能够挖掘出多种层次(抽象水平)的模式知识。数据挖掘系统还应容许用户指导挖掘搜索有价值的模式知识。比如:作为一个商场主管,肯定想要知道商场顾客的购物习惯;尤其是希望了解在(一次)购物过程中,那些商品会在一起被(顾客所)购买。为帮助回答这一问题,就需要进行市场购物分析,即对顾客在商场购物交易记录数据进行分析。所分析的结果将帮助商场主管制定有针对性的市场营销和广告宣传计划,以及编撰合适的商品目录。比如:市场购物分析结果将帮助商家对商场内商品应如何合理摆放进行规划设计。其中一种策略就是将常常一起购买的商品摆放在相邻近的位置,以方便顾客同时购买这两件商品;如:如果顾客购买电脑的同时常也会购买一些金融管理类软件,那么将电脑软件摆放在电脑硬件附近显然将有助于促进这两种商品的销售;而另一种策略则是将电脑软件与电脑硬件分别摆放在商场的两端,这就会促使顾客在购买两种商品时,走更多的路从而达到诱导他们购买更多商品的目的。比如:顾客在决定购买一台昂贵电脑之后,在去购买相应金融管理软件的路上可能会看到安全系统软件,这时他就有可能购买这一类软件。市场购物分析可以帮助商场主管确定那些物品可以进行捆绑减价销售,如一个购买电脑的顾客很有可能购买一个捆绑减价销售的打印机。
§2.2 系统功能分析
我们组所开发的超市销售记录数据挖掘系统是采用关联规则挖掘的方法来挖掘出商家希望得到的销售信息。关联规则挖掘就是从大量的数据中挖掘出有价值描述数据项之间相互联系的有关知识。我们开发的超市销售记录数据挖掘系统主要应用就是市场购物分析。根据被放到一个购物袋的(购物)内容记录数据而发现的不同(被购买)商品之间所存在的关联知识无疑将会帮助商家分析顾客的购买习惯。如图- 所示。发现常在一起被购买的商品(关联知识)将帮助商家制定有针对性的市场营销策略。比如:顾客在购买牛奶时,是否也可能同时购买面包或会购买哪个牌子的面包,显然能够回答这些问题的有关信息肯定会有效地帮助商家进行有针对性的促销,以及进行合适的货架商品摆放。如可以将牛奶和面包放在相近的地方或许会促进这两个商品的销售。
将商场所有销售商品设为一个集合,每个商品(item)均为一个取布尔值(真/假)的变量以描述相应商品是否被(一个)顾客购买。因此每个顾客购物(袋)就可以用一个布尔向量来表示。分析相应布尔向量就可获得那些商品是在一起被购买(关联)的购物模式。如顾客购买电脑的同时也会购买金融管理软件的购物模式就可以用以下的关联规则来描述:
computer=>financial_management_software[support=2%,confidence=60%]
关联规则的支持度(support)和信任度(confidence)是两个度量有关规则趣味性的方法。它们分别描述了一个被挖掘出的关联规则的有用性和确定性。规则的支持度为2%,就表示所分析的交易记录数据中有交易记录同时包含电脑和金融管理软件(即在一起被购买)。规则的60%信任度则表示有60%的顾客在购买电脑的同时还会购买金融管理软件。通常如果一个关联规则满足最小支持度阈值(minimum support threshold)和最小信任度阈值(minimum confidence threshole),那么就认为该关联规则是有意义的;而用户或专家可以设置最小支持度阈值和最小信任度阈值。
§2.3 系统算法分析
设I={i1,i2,…,im}为数据项集合;设为与任务相关的数据集合,也就是一个交易数据库;其中的每个交易T是一个数据项子集,即T包含于I;每个交易均包含一个识别编号TID。设A为一个数据项集合,当且仅当A包含于T时就称交易T包含A。一个关联规则就是具有“A=>B”形式的蕴含式;其中有A包含于I,B包含于I且A∩B =UNLL。规则A=>B在交易数据集D中成立,且具有s支持度和c信任度。这也就意味着交易数据集D中有s比例的交易T包含A∪B数据项;且交易数据集D中有c比例的交易T满足“若包含A就包含B条件”。具体描述就是:
support(A=>B)=P(A∪B)
confidence(A=>B)=P(B|A)
满足最小支持度阈值和最小信任度阈值的关联规则就称为强规则(strong)。通常为方便起见,都将最小支持度阈值简写为min_sup;最小信任度阈值简写为min_conf。这两个阈值均在0%到100%之间,而不是0到1之间。
一个数据项的集合就称为项集(itemset);一个包含k个数据项的项集就称为 k-项集。因此集合{computer,financial_management_software},就是一个2-项集。一个项集的出现频度就是整个交易数据集D中包含该项集的交易记录数;这也称为是该项集的支持度(support count)。而若一个项集的出现频度大于最小支持度阈值乘以交易记录集D中记录数,那么就称该项集满足最小支持度阈值;而满足最小支持度阈值所对应的交易记录数就称为最小支持频度(minmum support count)。满足最小支持阈值的项集就称为频繁项集(frequent itemset)。所有频繁k-项集的集合就记为Lk
挖掘关联规则主要包含以下二个步骤:
步骤一:发现所有的频繁项集,根据定义,这些项集的频度至少应等于(预先设置的)最小支持频度;
步骤二:根据所获得的频繁项集,产生相应的强关联规则。根据定义这些规则必须满足最小信任度阈值。
此外还可利用有趣性度量标准来帮助挖掘有价值的关联规则知识。由于步骤二中的相应操作极为简单,因此挖掘关联规则的整个性能就是由步骤一中的操作处理所决定。
§第3章 数据管理
§3.1 数据管理的方法
软件的开发是离不开数据库的,本次超市销售记录数据挖掘系统共使用到了14张数据表来存储数据帮助软件完成相关的功能。如:销售记录,数据采集,数据预处理,挖掘条件,一元频繁项集,二元频繁项集等等。对数据的管理主要有对数据表的增、删、改和对各个数据表数据结构的设计以及对内容的增、删、改操作,当然具体到每一个数据表时管理办法略有区别。
§第4章 数据采集
§4.1 数据采集的方法
本软件在开发中,数据采集主要是借用程序和人工来实现的。通过人工的录入来输入超市的销售记录数据,然后再借用所编写的程序来筛选出所要挖掘的销售物品的信息,以备后期数据预处理和数据挖掘所使用。
§第5章 数据预处理
§5.1 数据预处理的方法
本软件在开发中,数据预处理主要是借用程序和人工来实现的。通过人工的录入来检查超市的销售记录数据,去除或者修改错误数据(物品名),实现数据的完整性、一致性、正确性。然后再借用所编写的程序来转换成满足软件挖掘的数据形式或类型,以备后期数据挖掘所使用。
§第6章 数据挖掘
§6.1算法描述与流程图
§6.1.1 算法描述
Apriori算法是挖掘产生布尔关联规则所需频繁项集的基本算法;它也是一个很有影响的关联规则挖掘算法。Apriori算法就是根据有关频繁项集特性的先验知识(prior knowledge)而命名的。该算法利用了一个层次顺序搜索的循环方法来完成频繁项集的挖掘工作。这一循环方法就是利用k-项集来产生(k+1)-项集。具体做法就是:首先找出频繁1-项集,记为L1;然后利用L1来挖掘L2,即频繁2-项集;不断如此循环下去直到无法发现更多的频繁k-项集为止。每挖掘一层Lk就需要扫描整个数据库一遍。为提高按层次搜索并产生相应频繁项集的处理效率。Apriori算法利用了一个重要性质,又称为Apriori性质来帮助有效缩小频繁项集的搜索空间。
Apriori性质:一个频繁项集中任一子集也应是频繁项集。
Apriori性质是根据以下观察而得出结论。根据定义:若一个项集I不满足最小支持度阈值s,那么该项集I就不是频繁项集,即P(I)<s;若增加一个项A到项集I中,那么所获得的新项集I∪A在整个交易数据库所出现的次数也不可能多原项集I出现的次数,因此I∪A也不可能是频繁的,即P(I∪A)<s。这样就可以根据逆反公理:即若一个集合不能通过测试,该集合所有超集也不能通过同样的测试。因此很容易确定Apriori性质成立。
为了解释清楚Apriori性质是如何应用到频繁项集的挖掘中的,这里就以用 Lk-1来产生Lk为例来说明具体应用方法。利用Lk-1来获得Lk主要包含两个处理步骤,即连接和删除操作步骤。
(1) 连接步骤。为发现Lk,可以将Lk-1中两个项集相连接以获得一个Lk的候选集合Ck。设l1和l2为Lk-1中的两个项集(元素),记号表示li[j] 中的第j个项;如li[k-2]就表示li中的倒数第二项。为方便起见,假设交易数据库中各交易记录中各项均已按字典排序。若Lk-1的连接操作记为Lk-1⊕Lk-1 ,它表示若l1和l2中的前(k-2)项是相同的,也就是说若有(l1[1]=l2[1])∧…∧(l1[k-2]=l2[k-2]) ∧(l1[k-1]<l2[k-1]),则Lk-1中l1和l2的内容就可以连接到一起。而条件(l1[k-1]<l2[k-1])可以确保不产生重复的项集。
(2) 删除步骤。Ck是Lk的一个超集,它其中的各元素(项集)不一定都是频繁项集,但所有的频繁-项集一定都在Ck中,即有Lk包含于Ck。扫描一遍数据库就可以决定Ck中各候选项集(元素)的支持频度,并由此获得Lk中各个元素(频繁k-项集)。所有频度不小于最小支持频度的候选项集就是属于Lk的频繁项集。然而由于Ck中的候选项集很多,如此操作所涉及的计算量(时间)是非常大的,为了减少Ck的大小,就需要利用Apriori性质:“一个非频繁(k-1)-项集不可能成为频繁k-项集的一个子集”。因此若一个候选k-项集中任一子集((k-1)-项集)不属于Lk-1,那么该候选k-项集就不可能成为一个频繁k-项集,因而也就可以将其从Ck中删去。
在从数据库D中挖掘出所有的频繁项集后,就可以较为容易获得相应的关联规则。也就是要产生满足最小支持度和最小信任度的强关联规则,可以利用公式Confidence(A=>B)=P(B|A)=support_count(A∪B)/support_count(A)来计算所获关联规则的信任度。其中support_count(A∪B)为包含项集A∪B的交易记录数目;support_count(A)为包含项集A的交易记录数目;基于上述公式,具体产生关联规则的操作说明如下:
(1) 对于每个频繁项集l,产生l的所有非空子集;
(2) 对于每个l的非空子集s,若support_count(l)/ support_count(s)>=min_conf; 则产生一个关联规则s=>(l-s);其中min_conf为最小信任度阈值。
由于规则是通过频繁项集直接产生的,因此关联规则所涉及的所有项集均满足最小支持度阈值。
§6.1.2 算法流程图
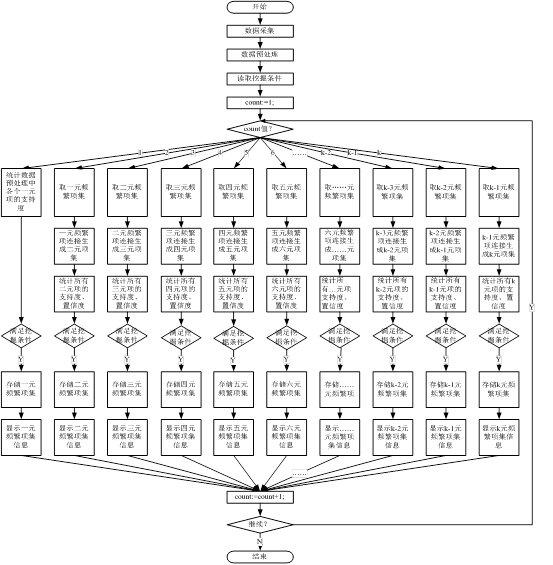 图6-1 算法流程
图6-1 算法流程
§第7章 结果显示与解释评估
§7.1结果显示界面的具体实现
§7.1.1 系统主界面的具体实现
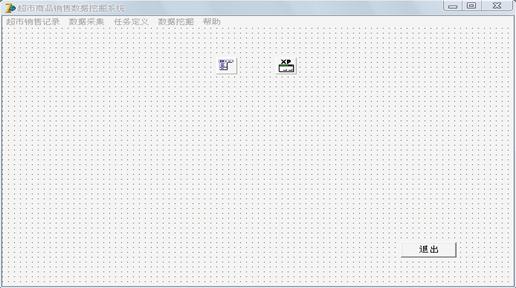
图7-1 系统主界面具体实现图
系统主界面主要使用的组件有:Mainmenu,XPManifest,Button.
各个组件的功能:
Mainmenu的功能是创建超市商品销售数据挖掘系统的各个菜单;
XPManifest的功能是在软件运行后美化界面;
Button(退出)的功能是执行退出挖掘系统的命令。
§7.1.2 超市销售记录界面的具体实现
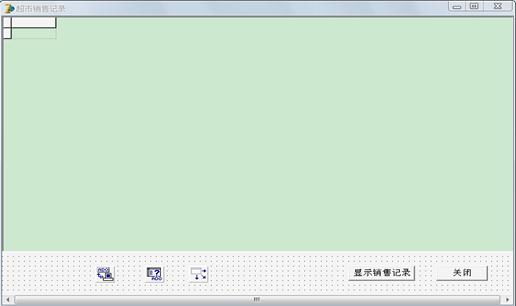
图7-2 超市销售记录界面具体实现图
超市销售记录界面主要使用的组件有:ADOConnection, ADOQuery, DataSource, DBGrid, Button.
各个组件的功能:
ADOConnection的功能是建立与数据库的连接;
ADOQuery的功能是用于检索和操作由合法的SQL语句产生的数据集,也可以执行一条SQL命令;
DataSource的功能是作为数据控制组件DBGrid,DBEdit的数据传送通道;
DBGrid的功能是为前端应用程序提供浏览数据库数据的表格,这些表格操作者编辑数据;
Button(显示销售记录)的功能是执行输出销售记录表XSJL中数据的命令;
Button(关闭)的功能是执行关闭当前窗口的命令。
§7.1.3 数据采集界面的具体实现
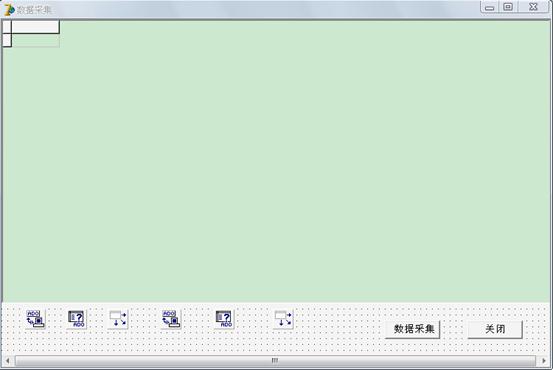
图7-3 数据采集界面具体实现图
数据采集界面主要使用的组件有:ADOConnection, ADOQuery, DataSource, DBGrid, Button.
各个组件的功能:
ADOConnection的功能是建立与数据库的连接;
ADOQuery的功能是用于检索和操作由合法的SQL语句产生的数据集,也可以执行一条SQL命令;
DataSource的功能是作为数据控制组件DBGrid,DBEdit的数据传送通道;
DBGrid的功能是为前端应用程序提供浏览数据库数据的表格,这些表格操作者编辑数据;
Button(数据采集)的功能是执行输出销售记录表SJCJ中的数据的命令;
Button(关闭)的功能是执行关闭当前窗口的命令。
§7.1.4 挖掘条件界面的具体实现

图7-4 挖掘条件界面具体实现图
挖掘条件界面主要使用的组件有:ADOConnection, ADOQuery, DataSource, Label,edit,GroupBox,ListBox,Button。
各个组件的功能:
ADOConnection的功能是建立与数据库的连接;
ADOQuery的功能是用于检索和操作由合法的SQL语句产生的数据集,也可以执行一条SQL命令;
DataSource的功能是作为数据控制组件DBGrid,DBEdit的数据传送通道;
Label(支持度阈值,置信度阈值,%)的功能是显示文字符号作为标签使用;
Edit的功能是显示、修改数据库表中当前记录的字段数据;
GroupBox的功能是组合框,把一些相关组件组合一起;
ListBox显示数据库表中一个指定字段的数据;
Button(确定)的功能是执行输入数据支持度阈值和置信度阈值到WJTJ表中;
Button(关闭)的功能是执行关闭当前界面命令。
§7.1.5 数据挖掘界面的具体实现

图7-5 数据挖掘界面具体实现图
数据挖掘界面主要使用的组件有:ADOConnection, ADOQuery, DataSource, Label,GroupBox,Button.
各个组件的功能:
ADOConnection的功能是建立与数据库的连接;
ADOQuery的功能是用于检索和操作由合法的SQL语句产生的数据集,也可以执行一条SQL命令;
DataSource的功能是作为数据控制组件DBGrid,DBEdit的数据传送通道;
Label(支持度阈值,置信度阈值,%)的功能是显示文字符号作为标签使用;
GroupBox的功能是组合框,把一些相关组件组合一起;
Button(开始)的功能是执行挖掘命令;
Button(退出)的功能是执行退出挖掘命令。
§7.1.6 帮助界面的具体实现
图7-6 帮助界面具体实现图
帮助界面主要使用的组件有:Button.
各个组件的功能:
Button(关闭)的功能是执行关闭当前窗体的命令。
§7.1.7 系统主界面运行后显示的结果

图7-7 系统主界面
程序运行后系统主界面显示如上图,界面标签是超市商品销售数据挖掘系统。系统主界面有五个主菜单:超市销售记录、数据采集、任务定义、数据挖掘、帮助,和一个退出软件使用的按钮。
学习体会
利用数据挖掘技术可以帮助获得决策所需的多种知识。在许多情况下,用户并不知道数据存在哪些有价值的信息知识,因此对于一个数据挖掘系统而言,它应该能够同时搜索发现多种模式的知识,以满足用户的期望和实际需要。此外数据挖掘系统还应能够挖掘出多种层次(抽象水平)的模式知识。数据挖掘系统还应容许用户指导挖掘搜索有价值的模式知识。
我们组所开发的超市销售记录数据挖掘系统是采用关联规则挖掘的方法来挖掘出商家希望得到的销售信息。关联规则挖掘就是从大量的数据中挖掘出有价值描述数据项之间相互联系的有关知识。我们开发的超市销售记录数据挖掘系统主要应用就是市场购物分析。根据被放到一个购物袋的(购物)内容记录数据而发现的不同(被购买)商品之间所存在的关联知识无疑将会帮助商家分析顾客的购买习惯。
通过这次的课程设计,然我对数据挖掘技术有了一个整体的认识。同样在编写程序的时候也遇到了这样或那样的问题。但在老师及同学们的帮助下,艰难的完成了这个系统。这让我对数据挖掘技术以后的深入学习打下了良好的基础。
参考文献
[1]敬喜,王钧.·Delphi7数据库编程学习捷径.·北京:·科海电子出版社,·20##·
[2]吕伟臣,霍言,高小山.·Delphi 20## 入门与提高.·北京:·清华大学出版社,·20##·
[3]刘瑞新,汪远征,李凤华.·Delphi程序设计教程. ·北京:·机械工业出版社,·20##·
[4]毛国君.·数据挖掘原理与算法. ·北京: ·清华大学出版社, ·20##·
-
数据挖掘课程设计报告
ID3算法的改进摘要本文基于ID3算法的原有思路再把属性的重要性程度值纳入了属性选择的度量标准中以期获得更适合实际应用的分类划分结…
-
数据挖掘课程设计
本科课程设计及实验期末成绩评估系统的数据仓库和数据挖掘设计课程名称数据挖掘课程编号08060116学生姓名cwl学号20xx052…
-
数据挖掘课程设计报告正文
目录第1章数据挖掘基本理论211数据挖掘的产生212数据挖掘的概念313数据挖掘的步骤3第2章系统分析421系统用户分析422系统…
-
数据挖掘课程设计报告
数据挖掘课程设计报告题目姓名班级学号关联规则挖掘系统xxxxxx计算机0901xxxxxxxxxxx20xx年6月19日1一设计目…
-
数据挖掘聚类算法课程设计报告
数据挖掘聚类问题PlantsDataSet实验报告1数据源描述11数据特征本实验用到的是关于植物信息的数据集其中包含了每一种植物种…
-
数据挖掘课程设计报告
ID3算法的改进摘要本文基于ID3算法的原有思路再把属性的重要性程度值纳入了属性选择的度量标准中以期获得更适合实际应用的分类划分结…
-
数据挖掘课程设计
本科课程设计及实验期末成绩评估系统的数据仓库和数据挖掘设计课程名称数据挖掘课程编号08060116学生姓名cwl学号20xx052…
-
数据挖掘课程设计报告
数据挖掘课程设计报告题目姓名班级学号关联规则挖掘系统xxxxxx计算机0901xxxxxxxxxxx20xx年6月19日1一设计目…
-
数据挖掘课程设计报告
一设计目的1更深的了解关联规则挖掘的原理和算法2能将数据挖掘知识与计算机编程相结合编写出合理的程序3深入了解Apriori算法二设…
-
数据挖掘聚类算法课程设计报告
数据挖掘聚类问题PlantsDataSet实验报告1数据源描述11数据特征本实验用到的是关于植物信息的数据集其中包含了每一种植物种…
-
数据挖掘实验报告
数据挖掘实验报告一实验名称有线电视服务销售CampR树二实验目的1学习和了解数据挖掘的基础知识学会使用SPSSClementine…