数据挖掘实验报告
管理学院实验(实训)报告
课程:商务智能与数据挖掘 地点:2607 时间:20##年5月7日

3. 单击Filter选区中的Choose按扭,选择unsupervised/attribute/Discretize命令,进行无监督离散化,单击Close按扭,如下界面:
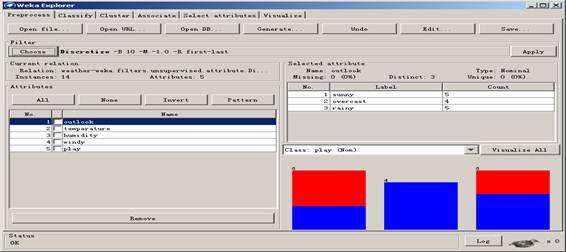
4.Choose后面的文本框中的discretize –B 10 –M -1.0 –R first-last处,看到如下图:

此图中的attributeIndices中的first-last,表示第一个属性用first代表,最后一个属性用last代表,则其他属性用数字代表,应数据要求,可作相应调整.在useEqualFrequency中的选项False表示的是采用的等间隔的离散化方法,True表示的是等频率的方法.
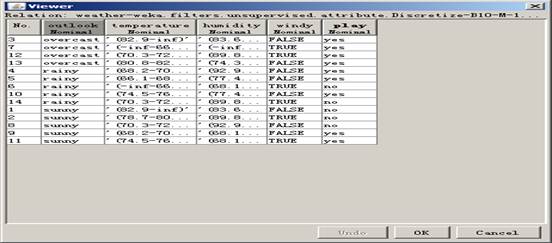
5.离散化第二和第三个属性,则将first-last改为2-3,在bins后修改间隔个数为3,单击ok回到主界面.单击Apply按钮,执行离散化,离散化结束,单击Edit,离散化后的数据如图所示:
关联分析:
1进行关联分析.打开数据集weather-disc.arff.选择Associate选项卡,单击Choose后面的文本框,得到如下图:

改变其属性得下图:
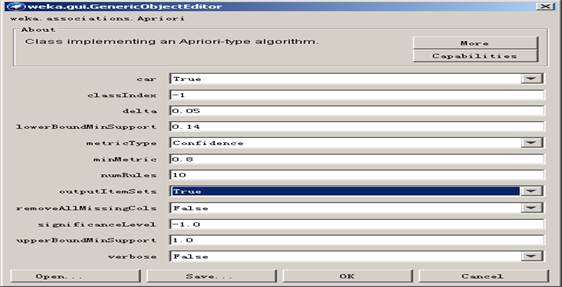
True代表发现的关联规则的右边是类别属性;-1代表数据表中的最后一列是类别属性;0.05代表最小支持度阀值的递减幅度。在这之中,从支持度阀值等于1开始找,每次降低0.05,最低不得低于0.14,关联规则的数目为10.关联规则的另一个约束由metricType指定,如果用置信度,则选择Confidence.相应的,0.8指的是最小置信度为0.8.outputItemSets:Ttue指的是输出满足支持度阀值的频繁项集。
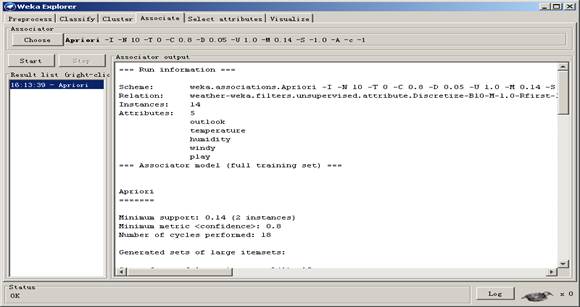
2单击Start执行关联规则的发现,挖掘结果如下图:
分类
决策树分类器部分输出结果
打开weather数集,选择classify选项卡后单击choose,选择tree类型下的J48决策树算法。,在test options中选择use traiing set选项,将数据集作为训练集使用。在more options中选取output predictions选项,看到样本类别的预测情况。在result list区域右键选择Visualize tree,生成决策树。
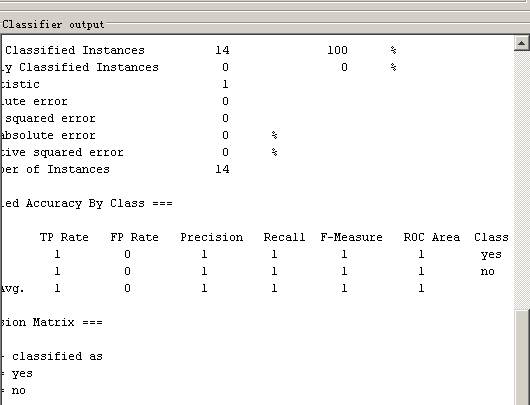
可视化决策树
数据规范化与聚类
数据预处理
通过normalize命令预处理数据。设置scale为1,0。Translation为0.0。
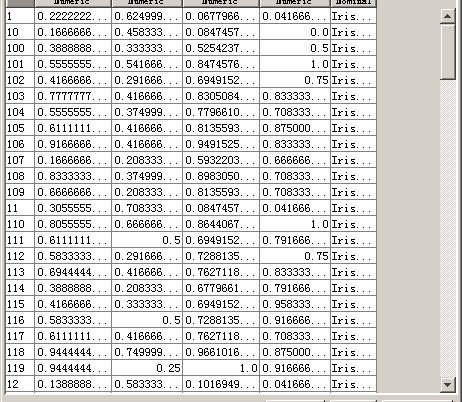
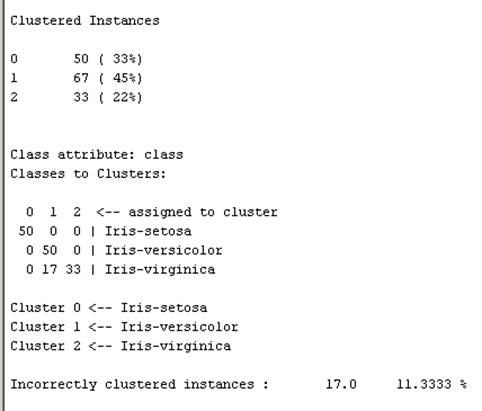
数据集K-均值聚类结果
在cluster选项卡中采取simplekmeans命令。在参数设置框中,将numclustres改为3.执行聚类分析。
数据集DBscan聚类结果
选择DBSCan命令,调整参数epsilon为0.2和minpoints为20。选择执行输出

数据集层次积累结果
选择hierachicalclusterer命令,设置linktype为average。选择输出
基于密度的聚类方法DBSCAN和层次聚类方法操作方法同上。
第二篇:数据挖掘作业2实验报告
数据挖掘作业2实验报告
牛罡?
mg0733079
(南京大学 计算机科学与技术系, 南京 210093)
A Report on the 2nd Assignment of DM Course
G. Niu*
(Department of Computer Science and Technology, Nanjing University, Nanjing 210093, China)
Abstract: This paper discusses how to build a probabilistic predicting model based Bayesian method on a classification-used training set. It is on a perspective for application. The techniques include attribute selection, co-training etc. In order to moderate the lopsided prior of the two classes and improve the accuracy, a resample method called support vector boosting and error-driven grading boosting is taken into account, which can be seen as a special AdaBoost to an AODE classifier. There are some thought to the problems during the experiment at the end of this paper.
Key words: Bayesian method; attribute selection; co-training; support vector boosting; error-driven grading boosting;
AODE.
摘 要: 本文从一个应用问题出发,讨论了在一个用于分类的训练数据集上建立一个基于贝叶斯方法的概率预测模型时使用的技术,包括属性选择,协同训练等.为了缓解两个类别的先验概率的不平衡并提高精度,而使用了一种重复取样方法,称为支持向量提升和错误驱动分级提升,可以看作是对AODE分类器的特殊AdaBoost提升.本文的最后对实验中遇到的问题进行了思考.
关键词: 贝叶斯方法;属性选择;协同训练;支持向量提升;错误驱动分级提升;AODE.
中图法分类号: TP301 文献标识码: A
1 引言
1.1 问题描述
这次的实验内容来源于一个应用问题.当前大部分的手机用户仍在使用2G通信网络,一个亚洲电话公司希望挖掘现有的顾客数据,以预测出哪些顾客最有可能转换到3G通信网络.数据集一共有24000位顾客(样本),每个样本有250个属性和1个类标号(2G/3G).数据集分成两部分,一部分包含18000个样本,作为训练集;另一部分包含6000个样本,类标号缺失,作为测试集(注意这里的概念与通常的测试集不同).最终目的是对测试集的6000个样本进行排序,按照用户成为3G的可能性降序.
? 作者简介: 牛罡(1984-),男,河北石家庄人,目前在南京大学计算机科学与技术系攻读硕士研究生,主要研究领域为统计学习.
2
1.2 设计思路与方案概述 数据挖掘作业2实验报告
因为要对测试集的6000个样本进行排序,所以我选择使用基于贝叶斯方法的分类器AODE,并把预测概率作为可能性的度量对样本排序.选择AODE的原因有三个:首先,AODE不像朴素贝叶斯那样严格要求属性之间统计独立,精确性比较高[7];其次,AODE结构简单,训练AODE分类器速度非常快,使得在较大的属性空间上穷举搜索最佳子集成为可能;最后,AODE支持增量学习,无需元学习器便可提升.
具体工作的第一步是属性选择,希望能选择出所有属性的集合的一个子集,其中每个属性都和类标号强相关,而这些属性之间相关性很弱,最好能达到统计独立.否则任何基于贝叶斯方法的分类器的精度都会受到一定程度的影响[1,2].
考虑到训练集的18000个样本和测试集的6000个样本是从相同的总体中取样的,为了能有效利用测试集中的未标记数据,我在训练集上训练了3个分类器,分别是NBTree, RBFNetwork和LogitBoost.然后在测试集上用这3个协分类器对主分类器AODE进行协同训练.
最后,为了增大3G样本的先验概率,提高预测精确度,在原始训练集上对支持点加权,再对依然被错分的那部分支持点进行加权,更新分类器,达到提升的效果.
本文的第2部份描述建立模型的过程并给出一些实验数据,第3部分对实验中遇到的问题进行了思考. 2 建立模型
2.1 属性选择
属性选择使用分层10折交叉验证方法,评分函数为正确分类的样本个数.具体来说,设原始训练集为S,而{S1,...,S10}为对S分层操作后随机取样得到的10个子集,分层可以保证每个子集中两个类别样本数量的比例与原来大致相同[1].设A为从原始属性集中选择出的候选属性集,πx为属性子集x的投影函数,aode(s)为用训练集s构造出的AODE分类器,correct(c,s)为s中能被分类器c正确分类的样本数量,于是
score(x)=∑i=1correct(aode(πx(S?Si)),Si),
bestattsubset=argmaxscore(x).
x∈ρ(A)10
初始属性选择时,按照信息增益和增益率排名前8的属性,去掉只有2个3G样本的属性VAS_VMN_FLAG后得到A={8,11,17,23,26,77,88,98,132,137,139,219,224,227,251}(属性编号从1开始,最后的251为类标号,下同),候选集C0=ρ(A),采用1次分层10折交叉验证,评分大于16272的子集共有230个,选择其中大于16285的62个子集进入第1轮筛选.属性筛选第1轮的评分方法为10次分层10折交叉验证取平均(每次交叉验证前都随机打乱样本然后分层再分成10折,下同),候选集C1={x|x∈C0,score(x)>16285},62个候选中有28个平均分大于16285,进入第2轮.第2轮的评分方法为25次分层10折交叉验证取平均,选出7个进入第3轮.第3轮100次交叉验证取平均,得到2个子集
a1={23,26,77,132,224,251},
a2={23,26,77,132,139,224,251}.
这两个子集的1000次分层10折交叉验证平均正确分类个数分别为16297.755和16296.368.因为在传统t
2测试下t统计量的自由度为9999,故使用修正重复取样t测试(此时不能用正态分布N(σd/k)近似,但有t近似
2服从N(,σd))[4,1],这个差异可认为不显著.但减少一个属性会带来时间和空间上的节省,所以最终结果
bestattsubset={23,26,77,132,224,251},它们分别是HS_AGE,
STD_VAS_GPRS加上CUSTOMER_TYPE. HS_MODEL, AVG_BILL_AMT, AVG_VAS_GAMES,
2.1.1 技术细节
以下是分层10折交叉验证,其中data为原始训练集经过投影函数生成的样本集, ran为随机数生成器.第5行使用ran打乱data,第6行对data分层.第7至13行进行交叉验证.
数据挖掘作业2实验报告
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15. Instances train, test; AODE aode = new AODE(); Evaluation eval = new Evaluation(data); data.randomize(ran); data.stratify(10); for (int i = 0; i < 10; i++) { train = data.trainCV(10, i, ran); eval.setPriors(train); test = data.testCV(10,i); aode.buildClassifier(train); eval.evaluateModel(aode, test); } return eval.correct(); } 3
以下是初始属性选择,对A中的属性从1到15编号, remove为移除属性过滤器.第9行打开remove的反向选择,第11至18行生成ρ(A)的遍历,第19至28行移除属性,第29至32行对属性子集进行评估. 2. int[] flags = new int[16];
3. int[] oldflags = new int[16];
4. double cur;
5. String attr;
6. Random ran = new Random(1);
7. Instances data;
8. weka.filters.unsupervised.attribute.Remove remove = new weka.filters.unsupervised.attribute.Remove();
9. remove.setInvertSelection(true);
10. for (int i = 1; i < 16384; i++) {
11. int j = 0, tmp = i;
12. flags[j] = tmp % 2;
13. while(flags[j] != oldflags[j] && j != 15) {
14. oldflags[j] = flags[j];
15. j++;
16. tmp /= 2;
17. flags[j] = tmp % 2;
18. }
19. attr = "15";
20. for (j = 0; j < 15; j++) {
21. if (flags[j] == 1) {
22. attr += "," + (j+1);
23. }
24. }
25. remove.setAttributeIndices(attr);
26. remove.setInputFormat(m_data);
27. data = Filter.useFilter(m_data, remove);
28. data.setClassIndex(0);
29. cur = evaluate(data, ran);
30. if (cur > 16272) {
31. System.out.println("candi: " + attr + "; " + cur);
32. }
33. }
34. }
以下是最后一轮的属性筛选.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18. String[] candi = {"15,4,5,6,9,13", "15,4,5,6,9,11,13"}; double cur; Instances data; weka.filters.unsupervised.attribute.Remove remove = new weka.filters.unsupervised.attribute.Remove(); remove.setInvertSelection(true); for (int i = 0; i < candi.length; i++) { remove.setAttributeIndices(candi[i]); remove.setInputFormat(m_data); data = Filter.useFilter(m_data, remove); data.setClassIndex(0); cur = 0; for (int j = 0; j < 1000; j++) { cur += evaluate(new Instances(data), new Random()); } System.out.println(candi[i] + "; " + cur/1000); } }
2.2 AUC评分
ROC是接受者操作特性(Receiver Operating Characteristic)的缩写,体现噪声信道击中率和错误报警之间的平衡[1]. ROC曲线可以在不考虑成本的情况下描述非成本敏感的分类器的性能[6,1]. AUC(the Area Under the
4 数据挖掘作业2实验报告 ROC Curve)是指ROC曲线与x轴和直线x=1围成的面积,其中x轴为错误肯定率FP/(FP+TN), y轴为正确肯定率TP/(TP+FN)[6,1]. ROC曲线实际上是锯齿状的,很容易计算围成的面积.
但是最终目的是排序,而且分类器也是概率型的,所以可以使用一种替代的AUC计算方法.首先进行排序,然后按照排名,每出现一个3G的样本ROC向上Δy,每出现一个2G的样本ROC向右Δx,其中Δx是2G样本个数的倒数,Δy是3G样本个数的倒数,最后计算ROC曲线围成的面积[6].
关于AUC评分的讨论,将在3.2节给出.
2.2.1 技术细节
以下是AUC评分函数,其中m_data为经过属性选择的训练集, id为已排序的样本编号, unitarea为纵横轴各增加1时AUC增加的面积,即Δx?Δy, roc记录当前y值和Δx的乘积.第5至8行计算2G样本的数量,第9行计算unitarea,第10至15行计算auc. 2. int num2d = 0;
3. double roc = 0, auc = 0;
4. double unitarea;
5. for (int i = 0; i < m_data.numInstances(); i++) {
6. if ((int)m_data.instance(i).classValue() == 0)
7. num2d++;
8. }
9. unitarea = 1 / (double)(num2d * (m_data.numInstances() - num2d));
10. for (int i = 0; i < m_data.numInstances(); i++) {
11. if ((int)m_data.instance(id[i]-1).classValue() == 0)
12. auc += roc;
13. else
14. roc += unitarea;
15. }
16. return auc;
17. }
以下是排序函数,其中m_aode为经过训练的AODE分类器.第6至9行预测概率,第10至23行进行直接选择排序. 2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24. Instances data = new Instances(m_data); int N = data.numInstances(); id = new int[N]; prob = new double[N]; for (int i = 0; i < N; i++) { id[i] = i + 1; prob[i] = m_aode.distributionForInstance(data.instance(i))[1]; } for (int i = 0; i < N - 1; i++) { int max = i; for (int j = i + 1; j < N; j++) if (prob[j] > prob[max]) max = j; if (i != max) { int tid = id[i]; double tprob = prob[i]; id[i] = id[max]; prob[i] = prob[max]; id[max] = tid; prob[max] = tprob; } } }
2.3 离散化
AODE分类器要求离散化,但这不是进行离散化的唯一理由.第一,几个数值属性明显不服从正态分布,又不能很容易的估计出真实分布,离散化成名词属性后,贝叶斯方法将用频率来估计概率,提高精确度;第二,数据中存在孤立点,离散化有排除孤立点的效果;第三,当样本集较小时,离散化对于频率的平滑作用很明显,这对建立NBTree很有意义.
经过属性选择后,在没有离散化的数据上NB的分层10折交叉验证正确率为0.878611,κ统计量为0.2199;在经过离散化的数据上NB的分层10折交叉验证正确率为0. 895389,κ统计量为0.5062.这说明离散化有效果.
离散化使用weka.filters.supervised.attribute.Discretize,使用最短描述长度准则和优化的分割点编码.
数据挖掘作业2实验报告 5
2.4 协同训练?
本节先简要介绍一下所用的分类器.
AODE,平均单一相关评估器(Averaged One-Dependence Estimators),它通过建立一些类似朴素贝叶斯模型的分类器再对其取平均,以减弱朴素贝叶斯对属性独立性的要求来提高精确度,且拥有比朴素贝叶斯更高的计算效率[7,8]. NBTree,朴素贝叶斯决策树(Naive Bayes Tree),在决策树的叶子建立朴素贝叶斯分类器,通过局部性减弱属性非独立性的影响[9]. RBFNetwork,径向基函数网络(Radial Basis Function Network),使用k-均值聚类算法生成基函数,标准多元正态分布拟合聚类,最后使用logistic回归估计激活函数的参数[1,2].最后一个是元学习器LogitBoost,它使用决策树桩(DecisionStump)作为基学习器,实现了加法logistic回归(Additive Logistic Regression)[10].
由于原始训练集中3G样本比例太小,故训练3个协分类器时对原3G样本进行一次复制,以提高3G类别的先验概率.注意在只有两类的情况下,如果在原始训练集(没有经过复制操作)上进行检验,其检验结果等价于成本敏感的学习[1].
在测试集的6000个样本中,如果3个协分类器对某个样本的预测之和大于2.1,则把这个样本作为3G加入临时训练集(有468个样本被加入);如果3个协分类器对某个样本的预测之和小于0.08,则把这个样本作为2G加入临时训练集(有501个样本被加入).这样使得被加入的两类样本数量相差不大.最后使用刚才的临时训练集更新原始的AODE分类器.
以下是协同训练中的AUC评分: AUC 分类器
original AODE 0.90106822
co-trained AODE 0.89980822
经过协同训练, AUC评分反而下降了,关于这点在3.3节会有讨论.
2.4.1 技术细节
以下是建立原始AODE的程序,其中
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16. m_dis为离散化过滤器.第2至4行离散化,第5行建立分类器,第6至10行保存刚建立的分类器m_aode,第11至15行保存离散化过滤器m_dis. m_dis.setUseBetterEncoding(true); m_dis.setInputFormat(m_data); Instances data = Filter.useFilter(m_data, m_dis); m_aode.buildClassifier(data); FileOutputStream fout = new FileOutputStream("myClassifier.model"); ObjectOutputStream objout = new ObjectOutputStream(fout); objout.writeObject(m_aode); objout.flush(); fout.close(); fout = new FileOutputStream("myFilter.model"); objout = new ObjectOutputStream(fout); objout.writeObject(m_dis); objout.flush(); fout.close(); }
以下是建立3个协分类器的程序.有两处相似的代码被省略了.第3至6行通过重复取样实现加权,因为决策树对于加权样本支持不够好.省略的两处代码是用来保存m_rbfnet和m_logitboost的.
? 真正意义上的协同训练应该是相互作用的,在这里只是用3个分类器去协助训练另1个分类器,只能勉强算是协同训练.其中包含了部分直推学习的思想.
6
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18. 数据挖掘作业2实验报告 Instances data = new Instances(m_data); for (int i = 0; i < m_data.numInstances(); i++) { if ((int)data.instance(i).classValue() == 1) data.add(data.instance(i)); } m_nbtree.buildClassifier(data); FileOutputStream fout = new FileOutputStream("coNBTree.model"); ObjectOutputStream objout = new ObjectOutputStream(fout); objout.writeObject(m_nbtree); objout.flush(); fout.close(); m_rbfnet.buildClassifier(data); ...... m_logitboost.setNumIterations(25); m_logitboost.buildClassifier(data); ...... }
以下是协同训练的程序,其中m_data为含有6000个未标记样本的测试集经过与原始训练集相同的离散化而生成的数据集,这就是建立原始AODE时保存离散化过滤器的原因.相似的代码被省略了.第2至7行载入3个经过训练的分类器,第13至15行预测单一样本的类别是3G的概率,第16至22行根据预测的概率对比较有把握确定类别的样本进行标记后更新AODE分类器.前两处省略的代码载入m_rbfnet和m_logitboost,最后一处省略的代码保存更新后的m_aode. 2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25. FileInputStream fin = new FileInputStream("coNBTree.model"); ObjectInputStream objin = new ObjectInputStream(fin); m_nbtree = (NBTree)objin.readObject(); fin.close(); ...... ...... Instances data = new Instances(m_data); Instance ins; double[] ctp = new double[3]; for (int i = 0; i < data.numInstances(); i++) { ins = data.instance(i); ctp[0] = m_nbtree.distributionForInstance(ins)[1]; ctp[1] = m_rbfnet.distributionForInstance(ins)[1]; ctp[2] = m_logitboost.distributionForInstance(ins)[1]; if (ctp[0] + ctp[1] + ctp[2] > 2.1) { ins.setClassValue(1); m_aode.updateClassifier(ins); } else if (ctp[0] + ctp[1] + ctp[2] < 0.08) { ins.setClassValue(0); m_aode.updateClassifier(ins); } } ...... }
2.5 支持向量和错误驱动分级AdaBoost
此处不想深入支持向量理论,只做简单说明.设对某一样本x, AODE分类器预测它是3G的概率为?(x)=Pr(x∈3G),则分类函数为 p
?(x)≥0.5?3G,pg(x)=?, ?Gpx<2,()0.5?
?(x)=0.5.令p(x)为样本的真实概率,即 分类边界为p
?1,x∈3Gp(x)=? x∈0,2G?
?(x)?0.5)<0}.除了考虑错分的样本外,还有一类样本也可则所有被错分的样本为Error={x|(p(x)?0.5)(p
以改进分类器,这些样本虽然没有被分错,但是已经比较接近分类边界了,这类样本可表示为
?(x)?0.5<2δ,δ>0}.两者的并集为 Boundaryδ={x|p
?(x)?0.5)<δ,δ>0}, SVδ={x|(p(x)?0.5)(p
数据挖掘作业2实验报告 7
其中的每个点称为支持点(支持向量),δ为边界余量.同样是被错分的样本,错误程度却不尽相同,所以定义
?(x)?0.5)<δ,?0.25<δ<0}, Errδ={x|(p(x)?0.5)(p
?threshold?0.5.该方δ越小,错误越大,Errδ中的样本越少.边界余量和分类边界对应的概率阈值满足方程2δ=p
法称为支持向量AdaBoost(以下简写为SVB).
关于支持向量的详细内容可参考[11],[2],[3].
实际操作中,因为AODE本身具有增量学习功能,所以不需要额外的元学习器(事实上,weka自带的AdaBoostM1元学习器对AODE不起作用).在SVB后,对依然被错分的部分支持点重复取样,错误程度越高,加权越重.该方法称为错误驱动分级AdaBoost(以下简写为EDGB).
以下是实验的AUC评分(提升前AUC为0.89980822, 3G先验为0.14,协同训练前3G先验概率为0.12): AUC AUC 3G先验概率 3G先验概率
(3G单边提升) (3G单边提升)(双边提升) (双边提升)
1.SVB,=0.05
2.SVB,=0.05
3.SVB,=0.05
4.SVB,0.05
提升次数
可以看出,双边AUC在第2次EDGB之后开始下降.事实上,先10次双边SVB,接着3次3G单边EDGB的效果较好.此时,AUC为0.930800399,3G先验概率为0.43.
更多的讨论在3.4节.
2.5.1 技术细节 以下程序可进行一次提升,其中
threshold大于m_data为有类标号的训练集, threshold为分类边界对应的3G概率阈值, 0.5为SVB,否则为EDGB, unilateral为单双边指示,若unilateral为true则只对3G支持点重复取样,为false则对两类支持点重复取样.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19. Instances data = new Instances(m_data); Instance ins; if (unilateral) { for (int i = 0; i < data.numInstances(); i++) { ins = data.instance(i); if (ins.classValue() == 1 && m_aode.distributionForInstance(ins)[1] < threshold) m_aode.updateClassifier(ins); } } else { threshold = 0.5 * threshold - 0.25; for (int i = 0; i < data.numInstances(); i++) { ins = data.instance(i); if ((ins.classValue() - 0.5) * (m_aode.distributionForInstance(ins)[1] - 0.5) < threshold) m_aode.updateClassifier(ins); } } }
3 讨论与思考
3.1 属性选择的损失函数
在属性选择时过程中,交叉验证使用的是0-1损失函数
?(x)?0.5)<0?1,(p(x)?0.5)(p. L0?1(x)=??(x)?0.5)≥0?0,(p(x)?0.5)(p
8 数据挖掘作业2实验报告 这里我们有两个可选择的替代函数,一个是二次损失函数Lquad,另一个是信息损失函数Linfo,其中
?(x)?p(x))2+((1?p?(x))?(1?p(x)))2=2(p?(x)?p(x))2,Lquad(x)=(p
?(x)?(1?p(x))log2(1?p?(x)).Linfo(x)=?p(x)log2p
这两个函数都是用来评价输出概率的分类器的,较之0-1损失函数更为准确.但现阶段的任务不是选择分类器,而是选择属性集,结果并没有差别.而且0-1损失函数是分层交叉验证默认的,所以属性选择时使用它作为损失函数.
3.2 关于AUC的讨论
从原则上说,用于测试精度的数据是不能用于构建分类器的,所以也应该像属性选择一样使用分层10折交叉AUC评分取平均.但是考虑到要使用尽可能多数据构建分类器,尤其是协同训练之后的基于重复取样的提升,很难做到测试数据不参与分类器的构建.并且,如果协同训练中要求3个协分类器也只用9/10的训练样本构造,NBTree分类器的构建将会消耗大量的时间,有一点得不偿失.另外一点,只用1/10的训练集作出的ROC曲线呈现明显的锯齿形,这对于用差分近似积分值(样本个数趋于无穷大的情形)再取平均来说,带来的误差也许更大.
现在的目的并不是绝对的AUC评价,只是想要得到一个相对的AUC评价,所用的策略还是可行的.唯一的问题是,如何避免过拟合?用参与构建分类器而且加权过的数据评价得到的分类器,结果肯定是乐观的,而且是绝对的乐观.因为很有可能得到的分类器已经过拟合训练数据了.我还想不出有什么便捷的方法可以解决该问题,除了上面提到的分层10折交叉AUC评分.现在只能寄希望于贝叶斯方法和AODE本身抵抗过拟合的能力,以及训练集中的样本充分代表总体的能力.
再来谈谈AUC本身.AUC只是在一定程度上对排位敏感.具体来说,考虑某一2G样本p,只有在p之前的3G样本的个数(ROC曲线中p到x轴距离)对p有影响(AUC值增加),而p之前的3G样本的具体排名无关紧要,每个3G样本对AUC的贡献都是一样的;反过来,p的负影响(AUC最大可能值减小)只和p之后的3G样本的个数(ROC曲线中p到直线y=1距离)有关,而与p之后的3G样本的具体排名无关.
一个充分的排位敏感的评分函数可以形如 D1(rank)=
x∈2G,y∈3G,rank(x)<rank(y)∑1rank(y)?rank(x)
D2(rank)=
x∈2G,y∈3G,rank(x)<rank(y)∑rank(y)?rank(x),
其中rank是一个样本的排序,函数数值越小说明排序越精确.函数D1对排位差较小的错分给予较大的权从而更关注排位的局部性,D2对排位差较大的错分给予较大的权从而更关注排位的全局性.
把AUC写成类似上面的形式,就是
AUC(rank)=
x∈2G,y∈3G,rank(x)>rank(y)∑u=1?x∈2G,y∈3G,rank(x)<rank(y)∑u,其中常数u=x∈2G1. 1?1y∈3G
至于这些评分对分类器提升的影响的差别目前还不清楚.
3.3 关于协同训练的讨论
前面曾提到,经过协同训练分类器的AUC评分下降了,这可能有以下几个原因.
第一,进行AUC评分时,测试集其实就是原始训练集,所以不是完全客观的评价.用来协同训练的临时训练集中的样本没有出现在测试集中,因为在不客观的评价下这样做完全没有意义.第二,AODE分类器要求离散化数据,其内部用频率来近似概率.当新加入的样本从不同的角度体现总体的特征时,会导致原训练集中样本的频率变小.第三,AODE虽然对属性的独立性的要求减弱,但依然要求样本的独立性.实际上,这个问题中的样本应
数据挖掘作业2实验报告 9
该不是独立的,样本构成若干组,每加入一个样本,都会影响同组的样本的先验,从而又影响这个样本本身.所有基于贝叶斯方法的分类器都具有这种效果,尤其是贝叶斯网络.
即使如此,我依然认为协同训练不是没有意义.因为AUC只下降了1‰,而且有1/6的测试数据参与了模型构建.
3.4 关于支持向量和错误驱动分级AdaBoost的讨论
我们可以把每个样本看作一个向量(原始样本有250维,经过属性选择后剩下5维),而每个向量又对应5维空间中的一个点?.两个类别的样本子集各自的中心称为质心,质心的权值为其对应类别的先验概率,它们一定处于分类边界(超曲面)的两侧.两个质心的连线与分类边界交于一点,该点即为两个质心的加权平均点.当训练
?threshold]. 集和测试集中的样本独立同分布时,该点的位置对应分类概率阈值在测试集上的期望ET[p
进一步讨论前,先看一下以下实验数据(对经过协同训练的AODE提升): SVB的次数 支持点个数 3G支持点个数2G支持点个数支持点总个数
(δ=0.05) (3G单边提升) (双边提升) (双边提升) (双边提升)
EDGB的次数
(未经SVB) 支持点个数 (3G单边提升) 3G支持点个数(双边提升)
2G支持点个数(双边提升) 支持点总个数 (双边提升) 1-1,δ=1-2,δ=1-4,δ=1-3,δ=1-5,δ=2-1,δ=2-2,δ=2-3,δ=2-4,δ=2-5,δ=上面的15次SVB和2次EDGB过程中,AUC评分均单调上升.
?确切的说,数值性属性离散化之后丧失线性性质不能构成线性空间,丧失距离性质不能构成度量空间,甚至在没有定义运算时已不能构成代数系统.但是,原本有序的数值属性经过离散化生成的名词性属性后还是隐含有序的,这种隐含的顺序在语义层次体现,并被学习器发现.在这里,我们只是假想样本投影成为欧氏空间中的点.
10 数据挖掘作业2实验报告 先看SVB的实验数据.表中的第2列说明随着提升次数的增加,3G支持点的个数越来越少,可能的原因如下:虽然针对3G支持点的提升使得3G的质心向2G的质心移动,但是3G的先验增加的更强烈,所以分类边界向着3G群体移动,从而在原始训练集中的3G支持点越来越少.
再看上表的后3列,两类支持点的个数都在增加,但2G支持点的个数增加的速度更快,到第13次时,2G支持点的个数已经超过3G支持点的个数.可能的原因如下:虽然3G的先验也在增加,但因为两类支持点实际上都是把分类边界向着自己吸引,也就是拉向对方的质心,其结果就是分类边界的位置没有太大变化,超曲面却变得越来越扭曲.此时,AODE分类器的内部原理引出了一个问题,不考虑类别的先验,对于单个样本而言,支持点的
?threshold].也就是说,越来越先验在不断增大,导致分类器对样本的预测的方差不断变小,预测值越来越接近ET[p
多的点被原来的支持点吸引,成为了新的支持点.在没有过拟合的情况下,这个结果还是好的.至于2G支持点增加的速度更快是因为2G的先验概率大,所以2G支持点的吸引力强.
下表给出了在没有经过SVB的情况下2次EDGB的实验数据.总的来看,越接近分类边界,支持点的个数越多,第2次尤其明显.第2次与第1次相比,支持点的个数较少,δ越小越明显.我们看到,第2次双边EDGB时,所
?均低于0.8,并且只有1个高于0.7,一共有601个2G被错分.虽然原始AODE只有534个2G有的2G样本的p
被错分,但此时3G的先验概率几乎是原来的3倍,而且错分总数1612小于原来的1702,AUC评分也比以前高,所以EDGB是有意义的.顺便一提,15次SVB接3次EDGB,错分数降低到1322,正确率为92.66%.
最后,如同上文提到的,分类边界越来越扭曲,以至过拟合的风险越来越大.关键之处在于支持点是否具有代表性,也就是支持点充分代表总体的能力.在这里,噪声与(相对的)孤立点是不同的.噪声是数据本身有错误,而孤立点的数据是无误的.有这样的可能(只是可能),一些孤立点构成了几个低密度聚类,而这些低密度聚类正是将来的发展趋势.极端的EDGB(极端是指δ稍大于-0.25,重复很多次)对于发现这种低密度聚类也许是有帮助的.
致谢 在此,我要特别感谢周志华老师,他那精妙绝伦的讲解使我对数据挖掘有了一个全面而又不乏深度的认识;感谢我的导师商琳老师,我对机器学习理论的大部分知识得自于她孜孜不倦的教诲;如果没有贾修一,于绍越和吉阳生三位师兄的帮助,我的作业不会如此顺利完成;和陈小强同学的讨论也对我很有启发,使我受益颇深.
References:
[1] I.H. Witten, E. Frank. Data Mining: Practical Machine Learning Tools and Techniques, 2nd edition. Elsevier, 2005, p143-183,
p365-424, p461-483.
[2] T. Hastie, R. Tibshirani, J. Frideman. The Elements of Statistical Learning: Data mining, Inference, and Prediction.
Springer-Verlag, 2001, p55-77, p115-132, p135-179, p210-220, p259-272.
[3] N. Cristianini, J. S-Taylor. An Introduction to Support Vector Machines and Other Kernel-based Learning Methods. Cambridge
University Press, 2000, p26-76.
[4] J.A. Rice. Mathematical Statistics and Data Analysis, 2nd edition. Thomson Learning, 1995, p387-424, p571-597.
[5] I.H. Witten, E. Frank. Machine Learning Algorithms in Java. Morgan Kaufmann, 2000, p265-320.
[6] A.P. Bradley. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognition,
30(7), 1145-1159, 1997.
[7] G. Webb, J. Boughton, Z. Wang. Averaged One-Dependence Estimators: Preliminary Results. Proceedings of Australian Data
Mining Workshop (ADM 2002), Australia, 2002, p65-73.
[8] G. Webb, J. Boughton, Z. Wang. Not so naive Bayes: Aggregating one-dependence estimators. To be published.
[9] R. Kohavi. Scaling Up the Accuracy of Naive-Bayes Classifiers: a Decision-Tree Hybrid. Proceedings of the Second International
Conference on Knowledge Discovery and Data Mining, 1996, p202-207.
[10] J. Frideman, T. Hastie, R. Tibshirani. Additive Logistic Regression: a Statistical View of Boosting. Dept. of Statistics, Stanford
University Technical Report, 1998.
[11] N. Cristianini. Support Vector and Kernel Machines. ICML-2001 tutorial, 2001.
-
数据挖掘实验报告
数据挖掘实验报告K最临近分类算法学号311062202姓名汪文娟一数据源说明1数据理解选择第二包数据IrisDataSet共有15…
- 数据挖掘实验报告
-
数据挖掘实验报告4
甘肃政法学院本科生实验报告四姓名贾燚学院计算机科学学院专业信息管理与信息系统班级10级信管班实验课程名称数据仓库与数据挖掘实验日期…
-
数据挖掘实验报告
数据挖掘实验报告药物研究专业学号姓名时间20xx1208数据挖掘实验报告药物分析一实验目的1学习数据挖掘的理论知识理解数据挖掘的目…
-
数据挖掘实验报告
计算机科学与技术系数据挖掘实验报告姓名学号授课教师完成时间1数据挖掘实验报告评分2目录1数据挖掘综述411什么是数据挖掘412数据…
-
数据挖掘实验报告
数据挖掘实验报告一实验名称有线电视服务销售CampR树二实验目的1学习和了解数据挖掘的基础知识学会使用SPSSClementine…
-
《数据挖掘实训》weka实验报告
论文报告案例分析院系信息学院专业统计班级10级统计3班学生姓名李健学号20xx210453任课教师刘洪伟20xx年01月17日课程…
-
数据挖掘 报告正文
河南科技大学课程设计说明书课程名称软件项目综合实践题目图书借阅数据挖掘系统院系电子信息工程学院班级计科083学生姓名陈亚杰指导教师…
-
数据挖掘课程设计报告正文
目录第1章数据挖掘基本理论211数据挖掘的产生212数据挖掘的概念313数据挖掘的步骤3第2章系统分析421系统用户分析422系统…
-
数据挖掘课程设计报告
ID3算法的改进摘要本文基于ID3算法的原有思路再把属性的重要性程度值纳入了属性选择的度量标准中以期获得更适合实际应用的分类划分结…
-
数据挖掘读书报告
读书报告数据挖掘可以看成是信息技术自然化的结果。数据挖掘(Datamining),又译为资料探勘、数据采矿。它是数据库知识发现(K…