计算机维修检测报告
计算机维修检测报告

拟解方案
第二篇:计算机应用技术检测报告
论文系统自动分四部分检测:
整体复制比: 45%
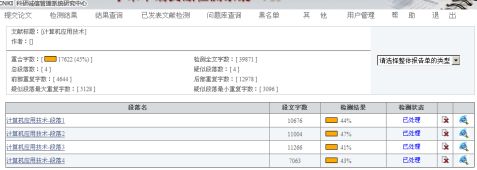
详细结果及截图如下:

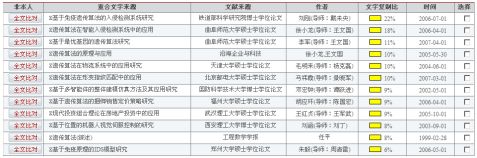
第一部分:

改进混合遗传算法在免疫入侵检测模型中的应用研究入侵检测与生物免疫技术入侵检测的功能与分类入侵检测(Intrusion Detection)是指通过对计算机网络或计算机系统中的一些关键点的信息进行收集、整理和分析,从中发现网络或系统中是否有违反安全策略的行为以及被攻击和入侵的迹象。进行入侵检测的软件与硬件的组合便是入侵检测系统(Intrusion Detection System 简称IDS)。总的来说,入侵检测系统的主要功能有:监测并分析用户和系统的活动;核查系统配置和漏洞;评估系统关键资源和数据文件的完整性;识别已知的攻击行为;统计分析异常行为;操作系统日志管理,并识别违反安全策略的用户活动;并对已经发现的入侵做出及时的相应和必要的防御措施。成功的入侵检测系统不但可使系统管理员时刻了解网络系统中程序、文件和硬件设备等的变更,还能给网络安全策略的制订提供指南。具体来说,入侵检测系统的功能如下:1. 识别常规入侵与攻击手段。通过分析各种攻击的特征,可以全面快速地识别探测攻击、拒绝服务攻击、缓冲区溢出攻击、电子邮件攻击、浏览器攻击等各种常用攻击手段,并做相应的防范。一般来说,黑客在进行入侵的第一步探测、收集网络及系统信息时,就应该会被IDS捕获,并向管理员发出警告。2. 监控网络异常通信IDS系统会对网络中不正常的
通信连接做出反应,保证网络通信的合法性。任何不符合网络安全策略的网络数据都会被IDS侦测到并发出警告。3. 鉴别对系统漏洞及后门的利用IDS系统一般带有系统漏洞及后门的详细信息,通过对网络数据包连接的方式、连接端口以及连接中特定的内容等特征分析,可以有效地发现网络通信中针对系统漏洞进行的非法行为。4. 完善网络安全管理IDS通过对攻击或入侵的检测及反应,可以有效地发现和防止大部分的网络犯罪行为,给网络安全管理提供一个集中、方便、有效的工具。使用IDS系统的监测、统计分析、报表功能,可以进一步完善网络管理。通过对现有的入侵检测系统和技术的研究,我们可以按照原始数据的信息来源,将入侵检测系统分为基于主机的入侵检测系统、基于网络的入侵检测系统和基于应用的入侵检测系统[11]。(1)基于主机的入侵检测系统用于保护关键应用的服务器,实时监视可疑连接、系统日志、非法访问和闯入等,通常采用查看可疑行为的审计记录来执行。优点是:内在结构没有任何束缚,可以利用操作系统本身提供的功能、并结合异常分析,更准确的报告攻击行为。主机入侵检测系统与网络入侵检测系统相比通常能够提供更详尽的相关信息。主机入侵检测系统通常情况下比网络入侵检测系统误报率要低,因为检测在主机上运行的命令序列比检测网络流更简单,系统的复杂性也少得多。缺点是:安装在我们需要保护的设备上。这会降低应用系统的效率。此外,它也会带来一些额外的安全问题,安装了主机入侵检测系统后,将本不允许安全管理员有权力访问的服务器变成他可以访问的了。主机入侵检测系统必须为不同平台开发不同的程序、增加系统负荷、所需安装数量众多。全面部署主机入侵检测系统代价较大,企业中很难将所有主机用主机入侵检测系统保护,只能选择部分主机保护。那些未安装主机入侵检测系统的机器将成为保护的盲点,入侵者可利用这些机器达到攻击目标。主机入侵检测系统除了监测自身的主机以外,根本不监测网络上的情况。对入侵行为的分析的工作量将随着主机数目增加而增加。(2)基于网络的IDS主要用于实时监控网络关键路径的信息。侦听网络上的所有分组来采集数据分析可疑现象。使用原始网络包作为数据源,通常利用工作在混杂模式下的网卡实时监视和分析所有通过共享网络的传输,一般被放置在比较重要的网段内,也可以利用交换式网络中的端口映射功能来监视特定端口的网络入侵行为。网络IDS 的优点主要是简便:一个网段上只需安装一个或几个这样的系统,便可以监测整个网段的情况。配置起来相当方便。由于往往分出单独的计算机做这种应用,不会对运行关键业务的主机带来负载上的增加。它不会成为系统中的关键路径, 因此网络入侵检测系统发生故障不会影响正常业务的运行,风险小。缺点是:它只检查它直接连接网段的通信,不能检测在不同网段的网络包。在使用交换以太网的环境中就会出现监测范围的局限。而安装多台网络入侵检测系统的传感器会使部署整个系统的成本大大增加。为了性能目标通常采用特征检测的方法,它可以检测出普通的一些攻击,但很难实现一些复杂的需要大量计算与分析时间的攻击检测。处理加密的会话过程较困难,目前通过加密通道的攻击尚不多,但随着IPv6的普及,这个问题会越来越突出。它通过在网段上对通信数据的监听来采集数据。当它同时检测多台主机的时候,系统性能将会下降,特别是在网速日益加快的情况下。(3)基于应用的入侵检测可以说是基于主机的入侵检测系统的一个特殊子集,也可以说是基于主机的入侵检测系统实现的进一步细化,所以其特性,优缺点与基于主机的入侵检测系统基本相同。主要特征是使用监控传感器在应用层收集信息。由于这种技术可以更准确的监控用户某一应用的行为,所以这种技术在日益流行的电子商务中也越来越受到注意。它监控在某个软件应用程序中发生活动,信息来源主要是应用程序日志。它监控的内容更为具体,相应的监控的对象更为狭窄。因此很多IDS的同时采用来自主机和来自网络的数据源,形成一种混合形的系统,这也是当前大型入侵检测系统的发展趋势。入侵检测系统都具有自己的优点和不足,3种入侵检测系统具有互补性,基于网络的入侵检测能够客观地反映网络活动,特别是能够监视到系统审计的盲区;而基于主机的和基于应用的入侵检测能够更加精确地监视系统中的各种活动。入侵检测系统基本结构及工作流程在不同的网络环境和不同的系统安全策略中,入侵检测系统在具体的实现上也有所不同。从系统构成上看,入侵检测系统至少包括数据提取、入侵分析、响应处理三个部分,另外还可能结合安全知识库、数据存储等功能模块,提供更为完善的安全检测及数据分析功能(如图2-1所示)。数据提取模块在入侵检测系统中居于基础地位,负责提取反映受保护系统运行状态的运行数据,并完成数据的过滤及其它预处理工作,为入侵分析模块和数据存储模块提供原始的安全审计数据,是入侵检测系统的数据采集器。入侵分析模块是入侵检测系统的核心模块,包括对原始数据的同步、整理、组织、分类、特征提取以及各种类型的细致分析,提取其中所包含的系统活动特征或模式,用于正常和异常行为的判断。这种行为的鉴别可以实时进行,也可以是事后分析。响应处理模块负责在发现攻击行为之后实施响应措施。数据提取模块的功能和效率直接影响IDS系统的性能。如何选择正确的数据源,如何进行合适并高效的预处理,是数据提取模块乃至整个入侵检测系统需要首先解决的问题。?图2-1入侵检测的基本工作流程Fig.2-1 The basic working flow chart of intrusion detection入侵检测系统通常只有一个监听端口,不跨接多个物理网段,无需转发任何流量,只需在网络上收集它所关心的报文即可。对收集来的报文,入侵检测系统提取相应的流量,统计其特征值,并利用内置的知识库与这些流量的特征进行智能匹配。根据预设的阈值,匹配耦合度较高的报文流量将被认为是入侵行为,系统将进行报警和防御。入侵检测的分析方法入侵检测分析方法主要包括误用检测和异常检测,本节将对这两类分析方法进行详细介绍[12]。误用检测误用检测的基本原理是首先判断这个活动是否对系统是恶意的。误用入侵检测根据已知的入侵模式来检测入侵。入侵者常常利用系统和应用软件中的弱点来实施攻击,而这些弱点易编成某种模式,如果入侵者的攻击方式正好匹配上检测系统中的模式库,则就认为有入侵行为发生。其模型如图2-2所示。?图2-2 误用入侵检测模型Fig.2-2 Intrusion detection model of misuse误用入侵检测成功与否依赖于模式库的建立,若没有构造出好的模式库,则不能检测到入侵行为。误用入侵检测主要用于检测那些假设能够被精确地按某种方式进行编码的攻击。通过捕获攻击及整理分析,可确认入侵活动是否是基于同一弱点进行攻击的入侵方法的变种。理论上讲,以编码的方式,不能完全肯定能够有效的捕获独特的入侵。某些模式的估算有其固有的不准确性,这样就会造成误报警和漏报警。误用入侵检测的局限性是其只适用于已使用模式的可靠性检测,仅能检测到已知的入侵方式。1. 模式匹配方法模式匹配的误用入侵检测方法是最基本
的误用入侵检测方法,该方法将已知的入侵特征转换成模式,存放于模式数据库中。在检测过程中,模式匹配模型把实时的事件与模式数据库中的入侵模式进行匹配,若匹配成功,则认为有入侵行为发生。2. 专家系统方法基于专家系统的误用入侵检测方法是传统的,通用的误用入侵检测方法。比如在MIDAS、IDES、NIDES、DIDS和CMDS中都使用了这种方法。使用专家系统的好处是把推理从问题的描述中分离出来。它允许使用类似于条件判断规则一样的输入信息,然后以审计事件的形式输出事实,系统根据输入信息评估这些事实。这个过程不需要用户理解专家系统的内部功能。输入的攻击信息使用类似于if-then规则的条件判断语法。入侵条件被放在规则的左边(if端)。当满足这些规则时,执行右边(then端)的动作。入侵检测专家系统的缺点主要是:(1) 不适合处理大批量的数据。专家系统中使用的说明性表达一般用来解释系统实现,因此解释器总是比编译器慢。(2) 并没有提供对连续有序数据的处理功能。(3) 不能处理固有不确定性。考虑到在知识系统中,由于其他规则的变化和影响而必须改变规则时,如何维护规则系统的稳定也是一个很具有挑战性的问题。3. 状态转换方法我们可以通过使用最优模式匹配技巧以及执行误用检测的状态转换方法,来结构化误用检测问题,使其灵活性、检测速度、入侵检测能力得到提高。状态转换方法使用系统状态和状态转换表达式来描述和检测已知的入侵。实现入侵检测状态转换的主要方法是状态转换分析和有色Petri网。(1)状态转换分析状态转换分析方法使用高级状态转换图表来体现和检测已知的入侵攻击方式。状态转换图表采用图形化的方式表现贯穿模型。如图2-3所示,是一个状态转换图表的组成及其代表的一个序列。“节点”代表状态,“弧”代表转换。用状态转换表格来表示入侵的基本思想是:所有的入侵都是从拥有有限权限的起始点出发,并利用系统的脆弱性来获取一些入侵成果。开始点的有限权限处和入侵成功的越权权限处都可以用系统状态来表示。使用状态转换图表来表示入侵序列时,初始和入侵状态之间的路径可能是相当主观的,系统自身仅限于表示导致一次状态改变的关键活动。每一个状态由一个或多个状态声明组成。状态转换分析系统利用有限状态机图表模拟入侵。入侵由从系统初始状态到入侵状态的一系列动作组成,初始状态代表入侵执行前的状态,入侵状态代表入侵完成时的状态。系统状态根据系统属性进行描述。转换由一个用户动作驱动。状态转换引擎保存着一套状态转换图表。在一个给定的时间内,假定一系列的动作驱动系统到图表中某个特定的状态。当一个新的动作发生时,引擎拿它与每一个图表对比,看是否能驱动下一个状态。如果这个动作驱动到结速状态,指示一次入侵,则以前的转换信息被送到决定引擎,它向安全人员发出入侵存在的警报。?图2-3 状态转换图Fig.2-3 Chart of states switch状态转换方法的优点如下:状态转换图表提供了一个直接的、高级的、与审计记录独立的概要描述。转换允许一个人去描绘构成攻击概要的部分顺序信号动作。当攻击成功时,状态转换必须使用最小可能的信号动作子集。因此,监测器能归纳出相同的攻击。系统保存的硬连接信息使它更容易表示攻击情景。系统能检测出协同的缓慢攻击。状态转换方法的缺点如下:① 状态声明和信号的动作的列表是手工编写的。②状态声明和信号可能不能充分表达更复杂的攻击情景。③某个状态的评估可能要求推论引擎从目标系统获取额外信息。这个处理会导致性能下降。④系统不能检测出许多常见的攻击,因此必须与其他监测器写作使用。⑤基于该方法的原形系统与其他基于状态转换方法的系统相比效率低。(2)有色Petri网优化误用检测的另一个基于状态转换的方法是有色Petri网的方法,这个方法是在IDIOT系统中实现的。它使用一种CP-Net的变种来表示和检测入侵模式。在这种模式下,一个入侵被表示为一个CP-Net。CP-Net中通过令牌的颜色服务来模拟事件的上下文。通过审计记录驱动信号匹配,并通过从起始状态到结束状态逐步移动令牌来指示入侵或攻击,并且当模式匹配时动作被执行。这个模式匹配模型由下面几部分组成。① 一个上下文描述:允许匹配相关的构成入侵信号的各种事件。②语义学:容纳了几种混杂在同一事件流中的入侵模式的可能性。③一个动作的规格:当模式匹配时,提供某种动作的执行。图2-4显示了一个TCP/IP连接的CP-Net模式。?图2-4 TCP/IP连接的CP-Net模式Fig.2-4 Connective CP-Net model of TCP/IP用此方法进行误用检测的优缺点,具体如下:① 速度非常快。②模式匹配引擎独立于审计格式。这样它就能应用在IP包和其它检测问题中。③ 特征在跨越审计记录方面非常方便,使它们能在不同的系统中移动。④模式能根据需要进行匹配。⑤事件的顺序和其它排序约束条件可以直接体现出来。异常检测异常检测需要建立正常的用户行为特征轮廓,然后将实际用户行为和这些轮廓相比较,并标识正常的偏离。也就是说,异常检测是根据系统或用户的非正常的情况来检测入侵行为,如图2-5所示。异常检测的基础是异常行为模式的误用。轮廓定义成度量集,度量衡量用户的特定方面的行为,每一个度量与一个阈值相联系。设置异常的阈值不当,往往就会造成IDS出现许多误报警或漏检,漏检对于重要的安全系统来说是相当危险的,因为给安全管理员造成了虚假的系统安全。同时,误报警会增添安全管理员的负担,也会导致IDS的异常检测器计算开销增大。因此,异常检测的完成必须验证,因为没有人知道任何给定的度量集是否足够完备,并是否能表示所有的异常行为。?图2-5 异常检测模型Fig.2-5 Model of abnormal detection其他检测方法还有一些入侵检测方法既不是误用检测也不属于异常检测的范围,这些方案可应用于上述两类检测之中。它们可以驱动或精练这两种检测形式的先行活动,或以不同于传统观点的方式影响检测策略。1.免疫系统方法系统首先被用来进行异常检测。系统按两个阶段进行入侵检测分析处理,第一个阶段建立一个形成正常行为特征轮廓的知识库。以系统处理为中心,与这个特征轮廓的偏差被定义为异常。第二个阶段,检测系统的特征轮廓用于监控随后的异常系统行为。系统的特征轮廓由长度为10的序列组成。使用3个度量描述正常行为的偏离。2.遗传算法遗传算法是一类被称为进化算法的实例,进化算法吸收达尔文自然选择法则和适者生存的思想来解决问题。遗传算法允许染色体的结合或突变以形成新个体的方法来使用已编码的表格。这些算法在多维优化问题处理方面的能力已经得到认可,在多维最优化问题中,染色体由优化的变量编码值组成。遗传算法对异常检测的实验结果是令人满意的。
3.基于代理的检测基于代理的入侵检测方法是指在一个主机上执行的某种安全监控功能的软件实体。它们由操作系统控制而不依赖于其他进程,并且自动运行。基于代理的方法连续运作,除了与其他相似的结构代理交流和协作外,还从运作过程中学习。基于代理的检测在保护大规模的分布式网络方面,有广阔的发展前景。4.数据挖掘数据挖掘是指从大量的实体数据中抽出模型的处理过程。数据挖
掘中挖掘审计数据最有用的三种方法是:分类、关联分析、序列模式分析。研究者已开发出标准数据挖掘算法来扩展并适应一些审计和其他系统事件日志的特殊需求。其中,使用现场数据实验初始结果是很有效的。现有入侵检测系统的不足目前,根据国外权威机构近来发布的入侵检测产品评测报告,目前主流的入侵检测系统大都存在以下不足[4,5]:1. 存在过多的报警信息,即使在没有直接针对入侵检测系统本身的恶意攻击时,入侵检测系统也会发出大量报警,这种误报警容易给管理工作带来很大压力,迫使管理员去分析这些警报的真伪。2. 入侵检测系统自身的抗攻击能力一般。入侵检测系统的智能分析能力越强,处理越复杂,抗强力攻击的能力就越差。3. 缺乏检测高水平攻击者的有效手段。现有的入侵检测系统一般都设定了阈值,只要攻击者将网络探测、攻击速度和频率控制在阈值之下,入侵检测系统就不会报警。4. 随着网络速度的大幅度提升,现有入侵检测系统的丢包现象明显。这对网络入侵检测系统的检测算法、检测速度和效率也提出了一个严峻的挑战。有必要研究新算法或提升现有算法的效率。5. 必须不断跟踪最新的安全技术。攻击者不断增加的知识、日趋成熟多样自动化工具、以及越来越复杂细致的攻击手法,迫使入侵检测系统必须不断跟踪最新的安全技术,才能不致被攻击者远远超越。6. 难以识别恶意信息采用加密的方法传输。网络入侵检测系统通过匹配网络数据包发现攻击行为,入侵检测系统往往假设攻击信息是通过明文传输的,因此对信息的稍加改变可能骗过入侵检测系统的检测。特别是IPV6,SSL等协议应用以后,这样的情况会越来越多。7. 交换机导致网络环境变化。传统的入侵检测通过设置网卡为“混杂”模式,从而读取集线器式局域网中传输的网络数据包,交换式局域网造成网络数据流的可见性下降。8. 入侵检测系统的厂家在规定标准上缺乏互通。不能与其他安全措施很好结合。生物免疫系统综述在现代科学研究中,人们采用仿生途径从生物系统中获得灵感,提出了神经网络(ANN)、遗传算法(GA)、蚁群系统(Ant System)等若干现实的学习系统[15,16]。生物免疫系统是一个高度进化的系统,它能区分外部有害抗原和自身组织,清除病原并保持有机体的稳定,是一个高度并行、分布、自适应、自组织的系统,具有很强的学习、识别、记忆和特征提取能力,具有强大的信息处理能力。免疫系统具有以下的信息处理能力[17]:系统层次识别;信息存储;自学习;多样性的产生;能够识别自我和非我物质。本章主要介绍目前人工免疫系统(Artificial Immune System, AIS)最常借鉴的一些生物免疫机制以及与入侵检测有关的人工免疫系统模型[18,19]。免疫的功能免疫是指机体的免疫系统识别自我与非我,排斥抗原和异物,用以维护内环境的生理平衡和稳定的一种生物学功能[21],通常表现为对机体有利的生理性保护作用,但在一定条件下也可表现为对机体有害的病理损伤作用。现代免疫学[22,23]认为:生物体内存在一个负责免疫功能的完整解剖系统,即免疫系统,与神经系统和内分泌系统等其它生理系统一样,这个系统有着自身固有的运行机制,并可与其他系统相互配合、相互制约,共同维持机体在生命过程中生理平衡。生物免疫系统是由免疫分子、免疫细胞、免疫组织和免疫器官组成的复杂系统。这个系统一般表现出以下三种生理功能。1. 免疫防御:这是机体排斥外来抗原性异物的一种免疫保护功能。正常时可产生抗感染免疫的作用,防御功能过强则会产生超敏反应,过弱则产生免疫缺陷,后两种情况均属于异常状况。2. 自身稳定:这是机体免疫系统维持内环境相对稳定的一种生理功能。正常时,机体可及时清除体内损伤、衰老、变性的不正常血细胞、抗原及抗体复合物,而对自身成份保持免疫耐受;异常时,无法区分正常与异常,发生生理功能紊乱、自身免疫病等。3. 免疫监控:这是机体免疫系统及时识别、清除体内突变、畸变的细胞和病毒干扰细胞的一种生理保护作用。生物免疫系统原理与运行机制生物界中的病原体存在于各个角落,有些病原体一旦进入生物体,便会造成致命的损害,生物体靠一套完善的免疫系统来防御自然界中的入侵者。生物免疫系统一般通过几道屏障来防御外来入侵者,如图2-6所示,最外层是皮肤粘膜及其附属物,它可以将某些类型的抗原拒之门外,这是生物体预防传染病的第一道屏障,一旦病原体微生物通过第一道屏障进入机体,这时就要由第二道屏障来保护,即物理环境的保护,也就是提供不利于病原体存活的PH值和温度;第三层是先天性免疫系统,先天性免疫又称为非特异性免疫,是机体在长期发育进化过程中逐渐形成的一种天然防御功能,经遗传获得;最后一层是可适应性免疫又称特异性免疫,它的名称来源于它具有可适应性,能随外界环境的变化适应或学会识别特定种类的抗原,并且保留对这些抗原的记忆以便加快未来的反应。 图2-6 自然免疫系统的多层次结构Fig.2-6 Multi-hiberarchy of natural immuno-system从免疫系统的各个层次来看,可适应性免疫系统是整个免疫系统中最为复杂的一层,从信息学角度来看,它实际是一个大规模的分布式信息处理系统,它对于计算机安全来说也最具有研究价值;这里要借鉴的就是生物体的可适应性免疫,即后天免疫。可适应性免疫系统可适应性免疫系统能学会识别特定种类的抗原,并且保留对它们的记忆以便加快以后的识别速度。可适应性免疫系统主要由淋巴细胞构成,机体的免疫功能主要来自淋巴细胞,根据免疫功能的不同,淋巴细胞主要有两类:B细胞(bone marrow)与T细胞(thymus),B细胞是抗体分泌细胞,在骨髓中发育;T细胞在胸腺中发育,作用是杀死抗原或抑制B细胞的过度繁殖。T细胞是一种重要的淋巴细胞,成熟的T细胞在抵御外来攻击时,起着协调免疫系统各部分功能的作用。当还处于胚胎阶段时,在骨髓中产生的未成熟的T细胞进入胸腺,胸腺是另一个中枢免疫器官,在其中分化发育为两大类T细胞,不合格的T细胞产生自体免疫被消灭,而成熟的T细胞分布在脾和淋巴结中以防御外来人侵。另一种重要的淋巴细胞是B细胞,B细胞在骨髓中发育成熟后,进入脾和淋巴结中。每个B细胞产生一种依附于其表面的抗体,用以探测相应的抗原,B细胞可以产生很多种抗体存在于体液中,识别、排斥和杀灭病原体微生物,称为体液免疫;B细胞继续分化,一部分成为能产生抗体的浆细胞,产生与抗原相应的抗体,并与抗原结合使之失去活性,从而达到消除抗原的目的,这个过程就是先天免疫。另一部分没有转化为浆细胞的B细胞发展为记忆细胞,记忆细胞对抗原非常敏感,能记住入侵过的抗原,当有同样的抗原再次入侵时,记忆细胞就能很快地做出反应,这就是后天免疫或适应性免疫[24]。生物体内的这些淋巴细胞并不是静止不动的,它们随着血液和淋巴系统在人体内不断循环。淋巴细胞在检测抗原时相互协作并对抗原的清除起到辅助作用。淋巴细胞可以被抽象的看作可以移动的、独立的检测器。生物体内成千上万的淋巴细胞就形成了一个分布式检测系统,在这个系统中没有指挥中心,抗原的检测和消灭都是靠这些淋巴细胞通过局部的相互作用完成。具体分析,可适应性免疫系统主要包括识别机制、
受体多样性机制、亲密度变异机制、记忆机制、容忍机制等。免疫系统有两种免疫应答类型:固有免疫应答和适应性免疫应答[25,26]。
1. 固有免疫应答第一层免疫系统为固有免疫系统,是天生就有的,不随特异病原体变化,由化学应答系统(补体)、内吞作用系统和噬菌细胞系统组成。固有免疫系统本身就具有辨别并消灭一些微生物和细菌的能力,具有与病原体第一次遭遇时就消灭它们的能力,而且可以消灭许多种第一次遇到的病原体。固有免疫反应的一个重要组成部分是补体,协助或者互补抗体活动。病原体关联分子模型只由病原体微生物产生,而不会由宿主组织产生;因此他们被模式识别时可以指明病原体存在的信号。这样,与免疫识别相关的结果必须与人体自身细胞和分子结构不相同,从而避免免疫系统破坏宿主自己的组织。因此,固有免疫也能够辨别自体与非自体组织结构,参与到自体与非自体识别过程中,并起到促进适应性免疫的重要作用。固有免疫识别最重要的方面是它诱导抗原细胞中的协同刺激信号的表达,这种信号会激活T细胞,促使适应性免疫应答产生。这样,没有固有免疫识别的适应性免疫识别会导致淋巴细胞的阴性选择,这些阴性选择表示与适应性免疫识别有关的受体。2. 自适应性免疫应答自适应免疫系统也称为适应性免疫系统,使用两种类型的淋巴细胞:T细胞和B细胞。这两种细胞是无性系划分的体细胞分裂产生的抗原受体。这些抗原受体通过随机过程产生,而自适应免疫系统一般性能的设计和形成是在淋巴细胞的克隆选择基础上进行的,这些淋巴细胞以精确的特异性表示抗体。抗体在自适应免疫系统中扮演主要角色,免疫应答中使用的受体是由基因片段结合在一起形成的。每一个细胞使用得到的不同的基因片段形成一个特异的受体,使细胞能够在一起以集体方式在生物体一生中识别可能遭受感染的组织。自适应免疫是指抗体能够识别任何微生物并对其反应,即使对以前从未遇到过的“入侵者”也一样。自适应免疫能够完成固有免疫系统不能完成的免疫功能,清除固有免疫系统不能清除的病原体。自适应免疫系统直接作用于一些特定的病原体。一旦病原体进入身体,固有免疫系统和自适应免疫系统就开始处理,此时,两个系统的细胞都由多种细胞和分子以复杂的方式交互作用来检测和消除病原体。检测和消除都依赖化学结合:免疫细胞表面都覆盖着不同的受体,其中的一些结合病原体,而另一些结合其他免疫系统细胞或者分子,使系统发信号触发免疫应答。生物免疫系统的特点生物免疫系统是一个高度分布、并行和自适应的系统。它具有如下特点:l. 分布性:免疫系统是一个包括免疫器官、免疫细胞和免疫分子的复杂系统其各组成部分分布于生物的全身。免疫应答是无中央控制的,它通过分布在全身众多的局部免疫成分之间的相互作用,来实现对整个机体的保护。2. 多样性:当一种抗原侵入机体时,都能在机体内选择出可识别和消灭相应抗原地免疫细胞,并使之激活,分化和克隆,进行免疫应答,最终消除抗原。免疫系统地多样性启发我们可以在不同的节点或网络用不同的安全系统,保证一个节点或网络受到攻击破坏时,其它节点或网络不易受到同样的攻击与破坏。
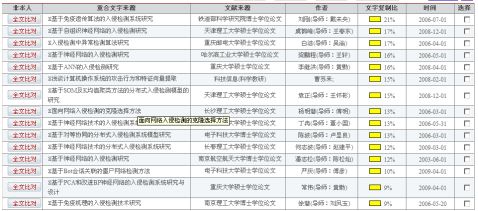
第二部分:

3. 动态性:淋巴细胞在体内不断地循环和更新,使免疫保护呈现动态特性。通常,免疫细胞地生存期比较短,它们不断地被新产生的淋巴细胞代替,使免疫细胞多样性。这种多样性扩大了免疫系统地免疫范围。4. 自适应能力:免疫系统具有自我学习能力。如果免疫系统检测到以前未遇到的病毒,它将经历初次免疫应答,并将学习该特定病毒的结构,以后再次遇到相同的病毒模式时,免疫系统将会作出快速反应。借助于这个特性可以解决目前网络入侵检测系统的通病—不能识别出新出现或变形的入侵模式。5. 不完全匹配性:免疫应答是特异性的,每种抗体只能识别特定的抗原,但医学研究发现,人体内大概有?种不同的淋巴细胞,却能够识别?种不同的外来抗原模式。所以,抗原与抗体的匹配并非一一对应的,而是不完全匹配的,一个淋巴细胞可以对几种不同的,但结构相近的抗原作出反应。借
鉴这个特性,我们可以使用有限的检测器检测出更多的入侵模式。生物免疫系统的特点为我们构筑基于免疫学的入侵检测提供了思路。生物免疫系统与入侵检测系统的相似性比较通过对入侵检测系统和生物免疫系统的研究,可以看出入侵检测系统和免疫系统具有一定的相似性。对于入侵检测系统,尤其是网络入侵检测来说,生物免疫原理有着很大的借鉴意义,生物免疫原理也可以适用于基于主机的入侵检测中,阴性选择算法可以用于入侵检测系统的检测器生成以及对于系统异常行为的检测上。生物免疫系统与入侵检测在功能上也有很多相似之处。免疫系统的分布性、多样性、自成体系、完备性和精简性使它精确有效地保护着生物个体,这使得人们希望借助于前者的原理更好地实现后者的功能,在合法的“自体”行为中判别出非法的“非自体”行为。在免疫系统中起检测作用的是抗体,抗体的生成演化和工作过程是关键,而如何模拟基因库更新、阴性选择、克隆选择等抗体生成过程建立入侵检测器是建立基于免疫系统的入侵检测系统的关键。免疫系统和网络入侵检测系统在概念上的相似之处见表2-1。表2-1生物免疫和入侵检测的类比Table2-1 Comarison of natural immunity and intrusion detection免疫系统?入侵检测系统?? 缩氨酸/抗原决定基? 被检测的行为模式串??受体? 检测模式串??单克隆淋巴细胞(T细胞、B细胞) ?检测器 ??抗原?非自体模式串 ??绑定?检测模式串和非自体模式串的匹配 ??耐受?阴性选择??淋巴细胞克隆?检测器复制??抗原检测?入侵检测系统检测??抗原消除?检测系统响应??免疫遗传算法免疫算法的不足免疫算法主要模拟生物免疫系统中有关抗原处理的核心思想,包括抗体的产生、自体耐受、克隆扩增和免疫记忆等。在用免疫算法解决具体问题时,首先需要将问题的有关描述与免疫系统的有关概念及免疫原理对应起来,定义免疫元素的数学表达,然后设计相应的免疫算法。免疫算法[27]大致包含“定义抗原、产生初始抗体群体、计算亲和力、克隆选择、评估新的抗体群体”几个步骤。评估时若不能满足终止条件,则重新计算亲和力;若满足终止条件,则当前的抗体群体为问题的最佳解。1. 否定选择算法否定选择算法[28]是对免疫细胞的成熟过程的模拟,经历耐受的检测器模拟成熟的免疫细胞。算法主要包括了两个阶段:耐受和检测。耐受阶段主要负责产生成熟检测器。在检测阶段,检测器检测受保护的系统以发现变化。2. 克隆选择算法克隆选择算法[29]是用来解释免疫系统是如何与抗原对抗的。当外部病菌入侵后,B细胞大量克隆并开始消灭入侵病菌,能够识别抗原的细胞根据识别的程度通过分裂增加自身数量,与抗原具有较高亲和力的细胞能产生更多的后代。在分裂过程中,还要经历一个变异过程,结果是使细胞与抗原有更高的亲和力。父细胞与抗原具有越高的亲和力,则它们就会经历越小的变异。Forrest曾在19xx年模拟T淋巴细胞在胸腺中经历的免疫耐受建立了阴性选择算法来建立抗体,将这种算法应用于病毒检测过程中并取得了成功,但当Kim等人在20xx年将这种算法应用于网络入侵检测系统中却发现该算法在处理真实的网络流量数据中存在着严重的伸缩性(:caling)问题。他们所做的实验表明要达到80%的非自身检测率,利用上述阴性选择算法生成检测器的时间需要1429年。所以在网络入侵检测中直接采用阴性选择算法在计算时间方面是不可行的。免疫遗传算法的优势遗传算法是将生物进化原理引入待优化参数形成的编码串群体中,按照一定的适值函数及一系列的遗传操作对各个体进行筛选,从而使适值高的个体保留下来,组成新的群体,新群体包含上一代的大量信息,并且引入了新的优于上一代的个体。这样周而复始,群体中各个体适值不断提高,直至满足一定的极限条件。此时,群体中的适值最高的个体即为待优化参数的最优解。正是由于遗传算法独具的工作原理,使它能够在复杂空间进行全局优化搜索,并具有较强的鲁棒性。我们将遗传算法应用于基于免疫机理的入侵检测器生产算法中,可以有效地提高寻优速度、改善寻优质量,在保持全局搜索能力的同时有效地进行局部搜索,同时算法还具有多解搜索能力,对于有效入侵检测器的生成具有重要的意义。本章小结本章介绍了入侵检测的概念,系统的功能,讨论了入侵检测技术的分类、发展、模型及其原理。对现今入侵检测技术进行了细致的介绍。分析了现有入侵检测系统的不足。对免疫学的基本概念、免疫应答运行机制及免疫细胞的主要功能进行分析;对自适应免疫应答所包含运行机制进行理论阐述,概括了免疫系统的主要特征,对生物免疫系统的概念与网络入侵检测系统的概念做了对比,最后引出了免疫遗传算法。为本文研究基于免疫遗传算法的入侵检测系统模型奠定了基础,为以后章节研究模型的提出提供了理论依据。改进的混合遗传算法与免疫遗传算法遗传算法与混合遗传算法遗传算法(Genetic Algorithm,GA) 是由Holland教授于19xx年提出的[8]。它是一种基于自然选择和基因遗传学原理的搜索算法,它根据“优胜劣汰,适者生存”的生物进化规则来进行搜索计算和问题求解。对许多用传统数学难以解决的复杂问题,特别是最优化问题,GA提供了一个行之有效的新途径。GA是一类被称为进化算法的实例,进化算法吸收达尔文自然选择法则来解决问题[29]。遗传算法允许染色体的结合或突变以形成新个体的方法来使用已编码的表格。遗传算法在处理多维优化问题方面的能力已经得到认可,在多维最优化问题中,染色体由优化的变量编码值组成。遗传算法对异常检测的实验结果是令人满意的。基于生物免疫系统的入侵检测和遗传算法相结合,对促进当前网络安全的研究具有十分重要的意义。遗传算法抽象于生物体的进化过程,通过全面模拟自然选择和遗传机制,形成具有“生成”加“检验”特征的优化算法。它以编码空间代替问题的参数空间,以适应度函数为评价依据,以编码群体为进化基础,以对群体中个体位串的遗传操作实现选择和遗传机制,建立起一个迭代过程。在这一过程中,通过随机重组“编码位串”中重要的基因片段,使新一代的“位串集合”优于老一代的“位串集合”,群体中的个体不断进化,逐渐接近于最优解,最终达到求解问题的目的。遗传算法同其它传统的搜索方法相比,具有以下特点:(1) 遗传算法是处理参数集合的编码,而不是直接对参数本身。也就是说,其操作在给定字符串上进行的。(2) 遗传算法的搜索是从问题解的“编码组”开始搜索,而不是从单个解开始。也就是说遗传算法同时搜索“解空间”中的许多点,而不是单个点,因而能够快速全局收敛。(3) 遗传算法使用目标适应度函数值这一信息进行搜索,而不需导数等其它信息,因而具有广泛的适应性。(4) 遗传算法使用的选择、交叉、变异这三个算子都是随机操作,而不是确定规则,因此能搜索离散的有噪声的多峰值复杂空间。(5) 遗传算法在“解空间”内进行充分的搜索,评价为选择提供了依据,因此,搜索并不是盲目的穷举,其搜索时间和效率往往优于其它优化算法。自从系统地提出遗传算法的完整结构和理论以来,很多学者一直致力于推动遗传算法的发展[32],针对遗传算法的不足,提出了各种相应的解决方案和变形的遗传
算法(Variants of Canonical Genetic Algorithm, VCGA)[33]。将这些变形的遗传算法中一些有价值的做法和因素适当提取出来,所形成的新的遗传算法称为混合遗传算法(Hybrid Genetic Algorithm, HGA)[8],改进HGA是提高遗传算法运行效率和求解质量的一个有效手段。免疫遗传算法的基本流程1.免疫遗传算法的基本工作原理为:①随机创建抗体和抗原的群体;②抗体和抗原匹配;③根据抗体的亲和力对抗体做评价,引入适应度函数;④用标准遗传算法进化抗体。基本遗传算子包括选择、交叉、突变。这个模型使免疫系统能够通过学习,知道哪些抗体对抗原的识别有帮助。根据上述几点工作原理的简单遗传算法(Simle Genetic Algorithms, SGA)工作原理结构图如下图3-1所示(方框中部分为遗传算法中的基本遗传算子)。其中选择算子[28]在常见的算法当中,父代的选择概率通常与检测器群中个体适应度成正比,即某个个体的适应度越高,被选择的概率就越大。被选出父代再繁殖生成子代,但是这样很容易使得检测器群中类似适应度的个体迅速增加,整个检测器群仅向着一个已知的相对较小的“非我”集进化,从而破坏了检测器的多样性。遗传算法通常是直截了当的,但许多情况下也可能比较复杂。例如,交叉操作可能是单点交叉也可能是多点交叉。也有并行遗传算法。有时参数系列,例如:交叉概率、突变概率、种群大小、染色体大小、进化代数、进化结束条件。需要根据具体的问题进行考虑。最终目标是在一个相对短的时间内搜索解空间。一般的遗传算法由四个部分组成:编码机制、适应度函数、遗传算子、控制参数。?图3-1免疫遗传算法的基本结构Fig.3-1 The basic structure of Simle Genetic Algorithms(SGA)2.遗传算法的一般描述:Begin t:=0; //t表示进化代数,第t代Initialize (t);Evaluate (t);Reeatt:=t+1; Select (t) from (t-1);Recombine (t);Evaluate (t);Until (termination condition)End改进方法简述混合遗传算法中的改进主要体现在以下几个方面:利用均匀设计抽样的理论,对遗传算法中的交叉遗传算子进行了重新设计。选择高效遗传算子,在计算选择概率的时候,把抗体的相似性考虑进来,保持了种群的多样性,高效性以及其适应度水平。对染色体的相似度及其相关内容进行了改进。结合进局部搜索策略改进遗传算法,协调了全局搜索和局部搜索,寻找全局最优解。改进的混合遗传算法免疫遗传算法不像穷举法,只是简单地随机生成候选检测器,与“自我”集匹配,丢弃匹配成功的候选检测器。遗传算法将生成一个成熟检测器集,采用交叉、变异等遗传操作对其进行进化,使成熟检测器群体向“非我”进化,从而成为合格的记忆检测器集。遗传算法的主要特点是群体搜索策略和群体中个体之间的信息交换,搜索不依赖梯度信息,也不需要求解函数可微,只需要该函数在约束条件下可解,因此GA适用于处理传统方法难以解决的复杂和非线性问题。免疫遗传算法(IGA)的核心思想则是将生物免疫的相关内容引入到传统GA中来,使整个系统具有免疫学习的自学习进化能力。我们基于理想浓度模型,利用均匀设计抽样的理论和方法,对GA中的交叉算子[41]进行重新设计,并结合局部搜索策略,给出了一种新的IGA改进方案,我们称之为HGA(Hybrid Immuno-Genetic Algorithm)。遗传算子包含5个基本要素:编码、适应度函数(fitness function)、克隆选择(reroduction)、交叉算子(crossover)和变异算子(mutation)。这5个要素构成了遗传算子的核心内容,下面将具体介绍改进的遗传算子的设计。编码的表示方法和设计编码就是把参数空间的点转换成字符串来表示。编码机制(Encoding Mechanism) 是GA的基础。GA不是对研究对象直接进行讨论,而是通过某种编码机制把对象统一赋予由特定符号按一定顺序排成的串。正如研究生物遗传是从染色体着手,而染色体则是由基因排成的串。在简单遗传算法(SGA:Simle Genetic Algorithms)中,字符集由0与1组成,码为二元串。对一般的GA,自然可不受此限制。串的集合构成总体,个体就是串。对GA的码可以有十分广泛的理解。在优化问题时,一个串对应于一个可能解;在分析问题时,“串”可解释为一个规则,即:串的前半部为输入或前件,后半部为输出或后件,等等。这也正是GA有广泛应用的重要原因。编码一般应满足以下3个原则:①完备性:问题空间的所有的点(可行解)都能成为GA编码空间中的点(染色体位串)的表现型;②健全性:GA编码空间中的“染色体位串”必须与问题空间中的某一潜在的解相对应;③非冗余性:染色体和潜在解必须一一对应。目前,遗传算法经常采用二进制编码,因为有其自身的优点,关键是它能使交叉和变异操作容易实现,采用二进制编码时算法处理的模式数最多。因此,我们采用传统的二进制编码方式,有利于模拟生物染色体的组成,能比较接近真实的反映生物体的特征,并使得模拟遗传操作变得容易实现。这里我们就采用二进制编码,编码包括以下几步:(1)根据具体问题确定待寻优的参数。(2)对每个参数确定它的变化范围,并用一个二进制数来表示。设参数а的取值区间为[аmin, аmax],要用字长为L的二进制数b来表示,则二者之间应满足以下公式:? (3-1)确定后的参数区间应覆盖全部的寻优空间,字长L的取值应该在满足精确度要求的情况下尽量小,从而减少遗传算法的复杂性。 (3)将所有表示参数的二进制数字串接起来组成一个长的二进制字串。该字串的每一位只有0或1两种取值。由此获得的该“二进制串”即为遗传算法的操作对象。适应度函数的设计优胜劣汰是自然进化的原则,优、劣要有标准。在GA中,用适应度函数描述每一个体的适宜程度。对优化问题,适应度函数就是目标函数。引进适应度函数的目的在于可根据该函数值对个体进行评估比较,定出优劣程度。为方便起见,在SGA,适应度函数的值域常取为[0,1]。适应度函数(Fitness Function)是GA中最重要的参数之一,下面的步骤用来计算适应度函数:根据网络与染色体的匹配情况先计算下面公式的值? (3-2)其中M的取值为0或1,当对应域匹配时取值为1,不匹配时取值为0;Wi是不同域的权重;n是染色体数。其基本思想是将“TCP/IP包”按其不同的重要性划分成不同域的,s值比较大的网络连接为可疑连接,可以用它来判断入侵。公式中权值的顺序见表4-1,从上到下为由低到高排列,顺序编号越大表示级别越高,权值越高,越重要。(2)当其将一正常连接误判为入侵时,需要对其进行一定的惩罚,使其适应度减小。我们将惩罚值定义为,并按如下方法计算惩罚值:? (3-3)? (3-4)其中R是指错误的程度,L为染色体串长,N为染色体数。(3)综上,一个染色体的适应度F可以按下面方法计算:? (3-5)这样适应度高的染色体被加入到特征库中,从而实现了特征库的智能动态更新。(4)另外,为了将冗余优化引入进来,适应度值还应该在上述值的基础上随时间的推移和染色体彼此之间相似度的升高而进行动态减小的微调。调整后用于检测器的生成。表3-1 公式中不同域的权重顺序Table3-1 The order of right weight in formula1?源端口号??2? 协议类型??3? 接收主机发送的字节??4?发送主机发送的字节??5? 目的端口号??6?源IP地址??7?目的IP地址??
这个顺序后面的基本思想是“TCP/IP包”中不同域的重要性不同。这种安排简单直接。目标IP地址是攻击的目标而源IP地址是攻击的发源地,这些是为了捕捉一个入侵最重要的信息。目标端口号显示了目标系统正在运行的程序,比如FTP服务通常运行于21号端口。一些IP地址被攻击的可能性更大一些,比如军事领域中的IP等。其它的参数例如连接时间、发送主机发送的字节数、接受者发送的字节数等的重要性通常低一些,但仍然比较有用。“协议”和“源端口号”通常不是必要的,一般用于确定一些特定的攻击。种群选择选择算子也称复制(reroduction)算子。它的作用在于根据个体的优劣程度决定它在下一代是被淘汰还是被复制。一般地说,通过选择,将使适应度大的个体有较大的存在机会,而适应度小的个体继续存在的机会也较小。有很多方式可以实现有效的选择。例如,两两对比的方式,即随机从父代抽取一对个体进行比较,较好的个体在下一代将被复制继续存在。SGA采取的则是按比例选择的模式,即适应度为的fi个体以fi/∑fk的概率继续存在,其中分母为父代中所有个体适应度之和。如果只有选择算子,GA不会有什么新意。因为后代的群体不会超出初始群体的范围。选择算子[37,38]在常见的算法当中,父代的选择概率通常与检测器群中个体适应度成正比,即某个个体的适应度越高,被选择的概率就越大。被选出父代再繁殖生成子代,很容易使得检测器群中类似适应度的个体迅速增加,整个检测器群仅向着一个已知的相对较小的“非我”集进化,从而破坏来多样性,为了克服算法的这一缺点,本文将各个检测器的相似度(抗体与抗体以及抗体与抗原相似程度)的考虑进来。在这里检测器的相似性采用欧几里德距离求取。检测器?与?之间的欧几里德距离为:? (3-6)d值越大,表示二者的相似度越低;如果d=0则表示两个检测器完全相同。于是检测器的浓度为:? (3-7)其中:?为某一确定的阈值,N为检测器集合的个数,这样,基于相似度和适应度相结合的选择概率为:? (3-8)其中:?(0≤?≤1)和?(0≤?≤1)为常数调节因子,?是适应度函数,可以看到该选择概率既与适应度函数有关,也与该检测器的相似性有关,这样选择出的检测群体,在一定程度上可以克服检测器陷入局部最优问题,保持了检测器多样性。种群交叉交叉算子有多种形式,最简单的是单点交叉(single oint crossover),这也是SGA使用的交叉算子,即从群体中随机取出两个字符串,设串长为L,随机确定交叉点,它是1到L-1间的正整数。于是,将两个串的右半段互换,再重新连接得到两个新串。当然,得到的新串不一定都能保留在下一代,需和原来的串(亲本)进行比较,保留适应度大的两个,如图3-2所示,是单点交叉算子的示意图。??图3-2 单点交叉Fig.3-2 Single oint crossover交叉算子[40,41]是模仿自然界有性繁殖的基因重组过程,其作用在于将原有的优良基因遗传给下一代个体,并生成包含新的基因结构的新个体,并希望这些新的染色体保留上一代的优良的特征,期望得到更好的基因结构,从而产生更好的个体。这里我们基于理想浓度模型,将交叉算子设计为基于均匀设计抽样的交叉算子。理想浓度模型[43]指出,遗传算法是一个具有定向制导的搜索,其定向原则是:导向“以高适应度模式为祖先”的种群方向。通常的GA中交叉操作多数就是从适应度高的祖先中取出染色体进行交叉,这是很片面的,所以容易陷于局部最优。设在传统GA基础上,在进行选择复制之后,对池中的染色体随机选择两个C1,C2进行均匀设计抽样交叉操作。其中C1,C2为如下形式:? (3-9)具体方法和步骤如下:随机取出两个染色体C1,C2进行直接比较,记录下彼此不同值的位置存于J中,由此不同值的位置构成一个t维空间,记为T,然后在T上进行均匀设计抽样。对于固定的t和n(每个染色体有n位),选取均匀设计的生成向量(n:T1, T2,…Tt);从多项分布?中抽取t个样本e1,e2,…,et;令?,k=1,2,…,n其中?,k=1,…,n,j=1,…,t这里?与?,j=1,…,t独立且都为来自?上均匀分布的样本。父代染色体我们前面用C/c表示,这里我们将其子代染色体用D/d表示,令交叉后产生的n个后代中第k个染色体为?,其中:?,?表示,若?的小数部分小于0.5,则?=0;否则?=1。如上所述产生n个后代,取其中适应度最大的几个,作为交叉后的后代,称为均匀设计抽样交叉操作。个体变异突变算子是改变字符串的某个位置上的字符。在SGA中,即为0与1互换:0突变为1,1突变为0,如图3-3所示。一般认为,突变算子的重要性次于交叉算子,但其作用也不能忽视。例如,若在某个位置上,初始群体所有串都取0,但最优解在这个位置上却取1,于是只通过交换达不到1而突变则可做到。??图3-3 突变示意图Fig.3-3 Simle mutation in SGA抗体变异是指抗体空间到自身的随机映射,是产生高亲和力抗体及多样化抗体的主要环节。变异算子的作用方式是:对染色体的各个基因,依次以变异概率改变其相应的码值,替换值(称为等位基因)则以一定概率从用于编码的字母表中选取。变异方式有:均匀变异,边界变异,非均匀变异,多点非均匀变异,这里选择均匀变异,首先确定参加变异的个体数m ,m 为? 的整数部分(N 为种群规模?,为变异概率),在这里选择突变概率函数为:? (3-10)均匀变异简单地在指定范围内随机选一个实数替代原基因。令要变异的染色体为X=[x1,x2,…,xm]。首先,选一随机整数k∈[1,m],然后产生后代?其中,?是[ak,bk]中均匀分布的一个随机值。ak,bk通常可取为变量xk的上下界,一般可由约束域确定,也可以根据约束集动态计算。均匀变异因为在染色体上选取的随机性,且对选中操作是在区间上的均匀随机性,能保证个体的多样性,预防早熟现象。然后分别在适应值最大的m 个体附近搜索以适应值更大的抗体,若能则取代原抗体,否则原抗体不变。由于快速的种群进化要求最优抗体不断更迭,不断变优,故在最优个体附近搜索新抗体的次数明显多于在其它抗体附近的搜索次数。变异的主要目的是不断产生适应值更大的最优个体,引导整个种群进化。这一点完全不同于二进制编码.在二进制编码GA中,变异是为了恢复某些丢失的重要信息,防止因所有个体某个基因位具有相同的基因码,使搜索限制在搜索空间的某个仿射子空间上.这种现象在实数编码GA中不可能发生。随着抗体种群的进化,群体中抗体的相似度不断提高,多样性不再保持原有水平。为了保证抗体的多样性,提高全局搜索能力,防止未成熟收敛,当群体相似度大于阈值As时(As值随群体规模增加而减小,因此应根据不同群体规模设置不同的As值。参数控制与搜索策略在IGA的不同的实际操作中,需适当确定某些不同的参数值以提高选优的效果。这些参数是:串长,记为L;群体的容量,记为N;交叉概率(corssover rate),记为Pc;变异概率(mutation rate),记为Pm;在SGA中,若群体容量较大如N=100,通常取Pc=0.6,Pm=0.001:若群体容量较小,如n=30,通常取Pc=0.9,Pm=0.01。此外,还有遗传的“代”数,或最大适应度达到某一给定值等其他可供终止迭代,退出算法的指标。采用把全局搜索算子和局部搜索算子相结合的方法可以得到更为理想的
效果。这里把全局搜索算子定义为具有高变异率和低杂交率的均匀杂交法。把局部搜索算子定义为具有低变异率和高杂交率的普通常规的分基因单点杂交法,并同时采用每代优化。由于在解决优化问题前一般对精确解都是未知状态,所以采取迭代到规定次数后就退出的算法。我们采用将全过程分为两个阶段的方法,第一阶段采用全局搜索算子,约占总迭代次数的3/4,第二阶段使用局部搜索算子,占其余的1/4。有实验表明,通过这种优化在相对合理的时间复杂度内搜索较小的解空间就能得到最优解的概率高达0.94。改进的免疫遗传算法流程在确定出交叉和变异的概率参数Pc和Pm后,上述基于均匀设计抽样和全局及局部搜索策略的遗传算法,我们这里暂时称之为HIGA(Hybrid Immuno Genetic Algorithm)可以描述为:产生初始种群。计算适应度函数并将每个染色体的适应度随时间的推移和染色体彼此之间相似度的升高而进行动态减小的微调。如经比较得到两个相似度高于规定值的染色体,则将其中适应度值高的保留,降低适应度低的染色体的适应度。每次进行遗传操作时,以概率?复制Ai,其中?是Ai的适应度值。评估适应度是否达到标准,判断子代数及适应度是否已经达到算法终止条件。总子代数的前3/4以概率Pc对其进行均匀设计抽样交叉操作;后1/4以概率Pc对其进行普通单点交叉操作。以概率Pm进行变异遗传操作。把经过遗传操作后得到的染色体都放到染色体池中,对新得到的染色体计算其适应度值。染色体数量要求一定,如果超过容量时,就将适应度小的染色体从池中删去,或按百分比进行删除。进行上述遗传算法至第T代(T是预先给定的常数)。该代群体将具备相对比较满意的优良特征可用于入侵检测。改进的免疫遗传算法的特点遗传算子与免疫算子相互作用,共同合作能完成最佳抗体群的任务。该算法的特点表现在如下几方面:1. 抗体的选择是确定性和随机性的统一;2. 克隆选择及亲和突变的协作体现了邻域搜索及并行搜索特性,并由此产生新抗体基因信息;3. 抗体的选择及突变受其适应度制约,突变概率反比于抗体的适应度;4. 搜索过程处于探测、选择、自我调节的协调合作过程,体现了免疫应答中抗体学习抗原的行为特性;5. 搜索过程处于开放,随时有自我抗体被加入进化群体,此不仅能增强群体多样性,而且增强了全局搜索能力;6. 算法收敛性对初始群体的分布无依赖性。免疫遗传算法既保留了遗传算法随机全局并行搜索的特点,在免疫算子的作用下又避免未成熟收敛,确保快速收敛于全局最优解,保证了搜索最佳抗体群的完成。本章小结本章对遗传算法及混合遗传算法进行了理论分析,把遗传算法融入到基于免疫原理的入侵检测当中,提出了改进的混合遗传算法,并基于改进的混合遗传算法对免疫遗传算法也进行了改进,给出了算法的流程以及各算子的数学描述。分析了改进的免疫遗传算法的特点。基于改进混合遗传算法的免疫入侵检测模型基于免疫机制的入侵检测模型基于免疫机理的入侵检测实际上是一种模式分类问题,但是由于入侵检测任务的特殊性使得传统的模式识别方法直接应用到攻击检测中比较困难,通过前面章节的介绍,自然免疫系统可以看作是一个分布的具有自适应性和自学习能力的分类器,它通过学习、记忆和联想提取完成识别和分类任务,可以根据免疫系统与入侵检测系统的相似性,设计一个基于生物免疫机理的入侵检测系统,完成对入侵行为的检测[30]。基于免疫机制的入侵检测模型的组成基于生物免疫的原理和特性。
第三部分:


设计一种入侵检测系统,用于检测被保护的内容的完整性,该模型主要包括五个核心模块,如图4-1所示。?图4-1 基于免疫机理的入侵检测系统模型Fig.4-1 Intrusion detection system model based on immuno-mechanism基于生物免疫系统的计算机网络入侵检测系统组成为:1. 数据采集模块:它负责抓取网络中的数据包,送入分析模块。2. 数据分析模块:数据分析理模块可采用snort、Tcdum或开发数
据包协议分析程序,它的功能是对数据包进行筛选和分类,这样得到所需要的数据包头信息,并保存起来。主要做初步的过滤工作,对IP包进行格式检查,若有分片则进行重组。接着,判别它是TCP包、UDP包或是CIMP包事件,根据包的不同协议类型,调用不同的分析器程序段进行语义分析,将符合要求的数据包中的信息,供入侵检测引擎进行分析,并将数据提供给自体集,供免疫学习模块进行自学习。3. 免疫学习模块:依据生物免疫系统的否定选择算法,由所取得的自体集产生检测器集合。4. 入侵检测引擎:接收免疫学习模块生成的检测器,对网络数据流进行检测,对于入侵攻击,采取某种方式做出响应,如与防火墙相互联动,及时向管理员报警等。5. 响应模块:把确定的入侵行为和报警信息通知网络管理员或采取相应的措施,如切断连接、追踪攻击者等。首先约定:不论“自我”还是“非我”都用定长字符串的集合来表示,这两个集合互补。“自我”指受保护的内容,如系统数据、程序文件、操作系统及网络等,而“非我”指被保护内容发生了异常的变化(类似于生物体细胞受到感染),例如:对“自我”集合元素进行的恶意修改,或向“自我”集合擅自增加新元素(不包括集合元素被删除的情况)。并约定:检测器相当于免疫系统中淋巴细胞表面的抗体或受体,也用定长字符串来表示,它用于识别受保护系统是否被修改。约定字符串的匹配相当于淋巴细胞表面抗体或受体与“非我”的结合。根据免疫系统的阴性选择原则,检测器只能与“非我”结合,它不能与“自我”结合,即检测器集合必须与“自我”集合互补。检测器集合的产生[31,32]:首先准确定义“自我”,即需要保护的内容,并将其划分为有限符号表上定长字符串,构成“自我”的字符串集合,记为M。然后,根据生物免疫系统否定选择原则,产生有效检测器集合,记为S,检测器基本工作方式如图4-2所示,有效检测器集合产生过程如图4-3所示。设置一个随机字符串发生器,它产生的每一个定长字符串与M中的全部元素逐一进行比较,那些不发生匹配的字符串成为S的元素,而发生了匹配的字符串将被清除掉。由此而产生的集合S中的元素不会与集合M中的元素发生匹配,即S与M互补,这一过程又称为“审查”。?图4-2检测器基本工作方式图Fig.4-2 The basic working manner of detector?图4-3检测器集产生流程图Fig.4-3 The flow chart of detectors roduced检测器产生算法的基本设计与分析1. 算法实现的环境及约束条件假设系统定义于一个全集U上,U是一个有限符号表上的字符串集合,其中有限符号表的大小为m,U集合的所有元素均是长度为l的字符。U被划分为“自己”集合M和“非己”集合N两部分。“自己”集合M代表被保护的数据或活动,“非己”集合N代表异常变化,即不可接受的或非法的数据或活动[34,35]。在算法中,需满足以下约束条件U是封闭和有限的。对于给定的问题域,以固定长度的字符串作为问题表达的基本单位,所以U是一个封闭和有限的集合。① M∪N=U,M∩N= ?。② M、N、 S中的各元素均是相互无关的。③ M、N和S中的元素均为无序的,并且是可重复的。为了描述方便,字符串空间U和检测空间Ud相同,但为了清晰起见,我们将二者分开定义。先介绍以下概念:④ Matching(Q)=P(P匹配Q),当且仅当P包含了所有可与Q中任意一个字符串匹配的检测器。⑤ 匹配概率?:为选择一个随机字符串和一个检测器进行比较时,二者匹配的概率。对于“自己”集合M?U,需要寻找一个检测器集合S?Ud,使其尽可能多的匹配“非己”集合N=U-M中的字符串,但不能匹配集合M中的任何字符串。集合N被划分为N’和H两部分。对于集合N’,可以从候选检测器集合C中选取有效检测器集合S(S?C),C=Ud-Matching(M),用S对集合N’进行检测。 如果S中包括了候选集合C中的所有元素,则可以检测到集合N’中所有元素(N’≤N)。一般S只包含集合C中的一小部分,用来检测到集合D(D?N’ ?N)中的“非己”字符串;对于集合H,有H=N-N’,它不能被任何检测器所检测到。把有限资源a∈U分两类:正常和异常。对应于M中的元素均为正常,N中的元素均为异常,检测系统企图通过分类的方式定义两个集合的边界。但是检测系统进行实际分类时可能会出现两种分类错误:当M中的字符串被分类为异常时,就出现了正误差,即通常人们所说的误报警;当N中的字符串被分类为正常时,就出现了负误差,即漏报警,又称为“洞” [33]。2. 编码方式抗体/抗原的编码方式在免疫系统中具有重要的意义。目前抗体/抗原的编码方式主要有二进制编码、实数编码、字符编码和灰度编码等[37]二进制编码因使用简单而得到广泛的应用。将抗体/抗原表示成二进制字符串的编码形式,从生物学角度来看,是一种简化,抗体/抗原之间的识别基于它们的匹配关系,它具有较大的优势:容易实现,并可用来研究少数抗体是如何识别较大范围内的抗原。因此,我们为了便于分析和讨论问题,令m=2,即符号表为{0,1},使其所表达的任何位串模式均可直接在计算机中存储与处理。“自己”字符串、“非己”字符串和检测器均用符号表{0,l}上长度为1的字符串表示,字符串空间U为?。并以Ra表示随机产生的候选检测器集合,R表示经选择后的有效检测器集合。3. 匹配规则在基于免疫原理的IDS中,匹配规则是一个关键点:在产生检测器时,匹配规则用于判断检测器是否“合格”;在入侵检测时,匹配规则用于识别是否有异常变化发生[38,39]。匹配分为完全匹配和部分匹配。如果两个等长字符串的每个对应位上的符号都相同,那么这样的匹配称为完全匹配。然而,在生物免疫系统中,受体(或抗体)和抗原的结合,更多地表现出不完全匹配特性,完全匹配只是其中一个特例,因此人们更关心部分匹配规则。利用部分匹配规则可以对于一些结构上近似的模式进行匹配,从而达到对于异常模式的覆盖。目前有许多部分匹配规则,如海明规则、连续r位的匹配规则等。在海明规则中,通过设定阈值r(0<r<1的大小,以确定两串是否匹配。当两个串之间的海明距离大于等于阈值,称这两个串是匹配的,反之则不匹配;海明距离是指两个字符串中相同位置上不同位的值的和,如串a=100001,b=101101,则字符串a、b的海明距离为2。当且仅当r<3时,串a,b匹配。两个随机字符串在海明距离下的匹配概率是:? (4-1)连续r位的匹配规则是指两个字符串至少有连续r个对应位上的符号相同,即有任意两个字符串x和y,如果x和y至少有连续r个对应位上的符号数相同,则有match(x,y),否则为?match(x,y)。例如,符号表{A,B,C,D},x和y为定义于其上的任意两个字符串,其中有三个连续对应位上的符号相同。X ABCDABABY CABDABBC当r≤3时,为match(x,y);当r>3时,为?match(x,y)。这种匹配规则可应用于任意符号表上定义的字符串。最通用的符号表为{0,1},还有更复杂的情况,如符号表为某个机器指令集等等。在连续r位的匹配规则中,它需要根据连续匹配的位数来确定两个字符串是否匹配。在连续r位匹配规则中,r表示了当检测器(受体)与“非自体”字符串(抗原)至少有r个对应位取值相同(形成r个化学键)时,才能检测(激活
免疫细胞)出“非自体”字符串。连续r位的部分匹配规则,更接近于生物免疫系统的匹配过程和特性。以上匹配规则都是部分的匹配,规则中的阈值或r值,类似于生物免疫系统中免疫细胞的激活门限。每一个淋巴细胞表面有许多相同的的受体,当有足够多的受体被抗原结合,即细胞表面结合的抗原数量超过某个值时,该免疫细胞被激活,这个值就是免疫细胞的激活门限。如果一个检测器能够检测到的字符串数目越多,则它的专一性越差。反之,符串数目越少,则其专一性会越强。例如:当r=1 时一个检测器只能检测到的一个“非己”字符串,它的专一性最强。在检测器产生算法设计中,利用连续r位的匹配规则,可实现以较小的检测器集合,检测到较大范围的“非己”行为。基于混合遗传算法的检测器的改进与设计本节将遗传算法应用到基于免疫机理入侵检测系统的检测器生成算法中,引入检测器冗余优化的概念并结合局部搜索策略,设计出具有良好全局搜索能力,又具有快速局部搜索能力的改进的检测器,并给出改进后的检测器的生成流程与工作流程。检测器优化的必要性入侵检测系统的主要部件是检测器,检测器生成算法是生成有效检测器的关键,是检测异常变化的核心所在。检测器模块是入侵检测中非常重要的模块,检测器的设计对入侵检测系统的性能有着重要的影响。目前,国内外在检测器生成算法的研究和应用中大多使用基于检测规则的检测器生成算法,存在一定的局限性。在基于特征的入侵检测中,我们通过判定某一行为与已有的检测器是否匹配来断定这是入侵行为还是正常行为,从而决定是否进一步确定为入侵并作出响应。检测器从产生到成熟再到被丢弃,有其自身固有的过程和生命周期。我们可以利用遗传算法来生成一个成熟检测器集,采用交叉、变异等遗传操作对其进行进化,使成熟检测器群体向“非我”进化,从而成为合格的检测器集。检测器的基本工作是对异常行为的识别。要解决的问题是如何在实时检测中确定出异常对象。否定选择算法(NSA)是目前检测器生成中的主要技术。检测器应该有一定的数量规模的限制,否则如果检测器太多会大大降低系统的运行速度,耗时巨大。但是,检测器数量如果被限制,检测的误报率和漏检率又可能提高,这是一个此消彼长的现象。一般来说,一个成熟的检测器,应该能够检测出至少一种异常行为,也就是说,它包含的异常行为的特征应该至少符合一种入侵行为的特点。所以多个检测器所覆盖的检测范围可能是有重复和冗余的,原则上说,这种冗余是不理想的,因为它从某种程度上破坏了检测器的多样性,但是实际上形成这种某种程度上的重复情况又是不可避免的。实际上,恰到好处的冗余情况是有利于检测器检测出更多形式的入侵的,因为当某一个包含某个入侵特征检测器处于消亡时期或者适应度降低时,甚至是出现了某种不可预知的问题不能正常工作时,那么冗余检测器就发挥作用了。我们想要这种冗余达到某种恰到好处的状态,既能有利于入侵检测又不至于冗余过度。检测器优化机理分析一种入侵行为往往具有多种特征,不可能只用一个命令就完成整个入侵行为,通常都是以一个命令序列或组合手段的形式存在的。假设有一种入侵,它具有多个入侵特征,因此辨别此入侵的方法可能也不止一种,如果假设每个检测器可以检测出一种入侵特征,那么就可能存在有多个用来检测不同入侵特征的检测器,实际上都只是为了用来检测出一种入侵而存在的情况。我们把这种情况称为检测器冗余。同时,检测器与检测器之间可能是有某种联系的,由于入侵行为往往是由组合操作手段的形式存在,所以当某一个检测器检测出一种可能是入侵行为组合操作中某一步骤的异常时,往往还不能够立即肯定这究竟是不是入侵行为,可能还需要一些与之相关联的检测器检测出符合入侵行为的后续异常,然后才能确定为入侵行为,进而进行报警响应及后续手段。检测器之间的冗余状态也可以看作是它们之间的一种联系。我们应该尽量保留可用于判断出入侵行为组合操作的检测器之间的联系,一定程度的忽略冗余检测器之间的联系,并同时把低适应度的检测器丢弃。假设有一个检测器集合D,集合中的检测器之间可能具有多种联系,我们要从中挑选出一定数量的检测器子集D’,使包含有价值关联的检测器尽量多保留,从而有利于检测出更多的入侵,使没有包含有价值联系的检测器和低适应度的检测器尽量得到删除。我们把这称为检测器冗余优化。检测器可靠性冗余优化[46]是提高检测器可靠性的重要方法,如何确定检测器的数量,既要尽量提高检出率,降低误报率和漏报率,又不能使系统运行的负担过重,是冗余优化中的一个难点。我们引入检测器可靠性冗余优化模型,使得检测器在一定的冗余约束下,能够以一定的概率达到最佳的检测效率。根据系统可靠性理论,冗余方式一般有并行冗余和备用冗余两种。在并行冗余中,所有可能是冗余的部件同时工作。在备用冗余中,只有当一个部件发生故障时,另一个冗余部件才开始工作。因为检测器在工作时都是同时处于工作状态的,所以采用第一种并行冗余的方式。假设有一个能检测出n种入侵的检测器集,设Xi是用于检测第i种入侵的检测器择优数目。可见,i=1,2,…,n变量Xi是正整数,但这Xi个检测器所处于检测器生命周期中的位置可能不同,其适应度值和能检测出异常的概率可能也不同。入侵检测要想运行出最优状态,与检测器数量有关,与每种入侵出现的频率有关,与检测器冗余状况以及其处于生命周期中的何种位置有关。基于上述分析,检测器可靠性冗余优化模型如下:
(1)系统中所有关于检测器数量的集合都有规模限制。大致分为:初始检测器集、成熟检测器集、记忆检测器集。其中记忆检测器集用来存放与最近发生的异常行为相匹配的成熟检测器,并且每个成熟检测器都有其固有的生命周期。(2)建立检测器关联库,用来存放成熟检测器之间的有利于检测出入侵的关联,以及每个检测器大概是用于检测哪种入侵行为的。(3)把检测器的相似度考虑进来,比较两个检测器的相似度,用欧几里德距离求取。进而去确定整个检测器池的浓度,并随时根据其变化进行调节。如果两个检测题的相似度高,那么就说明它们彼此冗余的可能性高,因此它们共存或第三个高相似度检测器与它们二者共存的可能性就要小。(4)根据不同入侵在近期的出现频率,适当增加用来检测出现频率高的入侵的检测器数量。(5)检测器适应度值适当的随时间的推移而减小,并在其适应度值不达标是被其它检测器替换。(6)用于检测同一种类入侵的检测器数量不能冗余过多,达到数量限制后要随时根据适应度值的高低采取以新换旧的替换策略或拒绝进入检测器池的策略。检测器优化模型与改进如图4-4所示,是改进后的检测器的生成及冗余优化的工作模型示意图。后面要将它应用到IGA中。图4-4 检测器的生成及冗余优化的工作模型示意图Fig.4-4 Detector generation and redundancy otimization schematic working model改进后的模型引入了检测器冗余优化的概念,加入了与其它成熟检测器相比较的环节,并在判断冗余情况之后,对成熟检测器集用GA进化,对有冗余的进行优化,并与适应度是否达标建立关联,计算适应度时进行了细部微调,从而
使检测器集向更优秀的方向发展,更有利于检测出异常和入侵。通过后面的实验表明,改进具有一定成效。改进后的入侵检测系统模型的体系结构本系统模型的设计要符合标准化的入侵检测体系结构规范。该入侵检测系统模型的主要任务是:采集和分析用户当前的行为,并将该用户当前的行为与其正常的行为模式和异常的行为模式进行分析比较,从而发现其异常的行为,并且给出异常警报。该模型拟达到如下设计目标:(1) 系统模型具备基本的和合理的功能模块、体系结构、工作流程。(2) 适用于共享式和交换式网络。(3) 可以适应从小型局域网到企业内部网、校园网规模的网络。(4) 系统模型的实验结果能证实算法的有效性和可行性。如图4-5所示,是改进后的基于上述检测器冗余优化理论的入侵检测系统[40]模型的逻辑结构示意图。即基于改进的HGA的入侵检测模型的逻辑结构。寻找更为有效的算法,提高免疫机制和GA在IDS中的配合与协作,通过改进现有IDS中检测器的结构,克服其可能影响效率的缺陷,使其能获得更好的检测效果,是当前IDS研究的热点和发展趋势,也是我们目前要解决的主要问题。研究重点是结构上的优化和工作流程上的改进。在图4-5所示改进后新的逻辑结构中,加入了检测器关联库与异常模式库配合发挥作用,并将GA分别应用于新检测器的生成和已有检测器的进化两个环节,在新检测器的生成中体现了检测器冗余优化的环节及其所处位置,将记忆检测器与成熟检测器分别考虑,将异常和入侵分别对待,从而在一定程度上优化了工作流程。经后面实验表明,改进后的逻辑结构具有更好的检测效率,使入侵检测模型的性能有了进一步的提高。图4-5 改进后入侵检测系统模型的逻辑结构示意图Fig.4-5 After the intrusion detection model to imrove the logical structure diagram模型工作流程模拟人体免疫系统的运行机理,检测器(抗体)的产生、检测过程及基因进化将在免疫系统的运行过程中同步进行。其工作流程为:(1) 提取正常网络通讯模式下网络通信数据,建立正常的“自我集”。与随机生成的候选初始检测器匹配,进行负选择,如果能够匹配到任一自我特征模式,则表明该检测器有可能将正常的网络行为误认为异常的网络行为,因此将其删除,如果不能够匹配,则进入下一个检测器冗余优化环节。(2) 在检测器冗余优化环节中,将上一步得到的检测器与成熟检测器进行比较和匹配,如果有冗余则进行检测器冗余优化,如果没有冗余现象则将其加入成熟检测器集并在适当时候(已经新加入若干数量后)用HGA对成熟检测器集进行进化。(3) 提取动态数据流,分别先后经过数据采集和数据预处理之后,形成待检测的模式串。将待检测模式串分别送入记忆检测器集和成熟检测器集中进行检测,如果经检测将其判定为入侵,则直接激活报警处理单元,然后将其记录加入到异常模式库和异常模式集中;如果经检测将其暂时判定为异常而非入侵行为,则调用检测器关联库,从中提取与此种异常相关联的检测器进入到成熟检测器集和记忆检测器集中,并将它们激活,以便能及时检测出与此异常行为可能相关的后续入侵行为。(4) 如果记忆检测器集在一个测试周期能够从检测器关联库中找到并匹配到足够数量的异常,则说明发现入侵行为。“记忆检测器集”中保存了在最近一段时间内,能检测出新近发生的异常或入侵的检测器,它与异常模式集直接发生交互,通过实时筛查,如果能从异常模式集中找到匹配的内容,则可以直接将其判断为入侵,从而节省了时间,提高了效率。异常模式集来源于异常模式库,已经被判定为入侵并报警的内容才会被收集到异常模式库中。系统的模型主要由以下几个核心模块组成,数据采集模块、数据处理模块、检测模块,响应模块、优化模块,数据库包括异常模式库和检测器关联库。各个模块和数据库的具体功能如下:(1) 数据采集模块:网络数据包截获机制是网络入侵检测系统的基础部件,收集信息的内容包括系统、网络、数据以及用户活动的的状态和行为等。而且,需要在计算机网络系统中若干关键点(不同网段,不同主机)收集信息,信息范围越广,入侵检测的范围越大,一般指通过截获整个网络的所有信息流量,根据信息源主机、目标主机、服务协议端口等信息简单过滤掉不关心的数据,再将用户感兴趣的数据发送给更上层的应用程序进行分析。入侵检测很大程度上依赖于所收集信息的可靠性和正确性。一般都是指嗅探器。(2) 数据预处理模块:预处理的目的有二个,首先是要去除明显错误的冗余噪音数据,并且通过分析噪音数据,以决定在后续步骤采取何种解决噪音问题的方法;然后是数据类型转换,转换成攻击软件中能识别的格式。是对系统获取到的各种相关数据进行归纳、转换等处理,使其符合系统的要求。一般采用从大量的数据属性中,提取部分对目标输出有重大影响的属性,通过降低原始数据的维数,来达到改善实例数据质量的目的。应用程序将网络数据从用户态缓冲区中取出,通过协议解析,提取数据包头中的基本特征。并组成字符串。在实际应用中大多数的端口是用户程序自定义使用的,因此可以把数字大的端口映射到比较小的数字上来。这样可缩小检测元的长度,节省检测时间和存储空间。(3) 数据检测模块:检测模块是入侵检测系统的核心模块,用什么方法来设计检测模块是入侵检测的关键技术,本文基于上述改进混合遗传算法,引入检测器冗余优化的概念,改进和优化了检测器,设计了改进的检测器和免疫入侵检测模型,并对生成的成熟检测器进行进化,提高检测器的多样性、高效性、以及适应度水平。检测模块主要由记忆检测器集、成熟检测器集以及与它们相关联的异常模式库,检测器关联库、异常模式集组成。它们彼此之间相互协调配合,完成检测任务,并对被检测内容作出是否为异常或者入侵的判断。(4) 报警处理模块:报警处理模块是直接面对系统管理用户的一个工作平台。系统根据判别出的结果,进行相应的响应并能够给出详细的解释信息,再把每一组数据对应的结果存入数据库中,作为历史的数据保存。当检测器检测到异常时会做出相应的报警和响应,即通知管理员系统正在遭受不良的行为的入侵,或者采取一定的措施阻止入侵行为的继续。由于基于免疫原理的入侵检测系统是基于异常的,所以不能判断具体的攻击类型,但是管理员可以通过系统提交的源IP地址和目标IP地址,找到受攻击的主机,检查其日志,以此检查黑客的行为。并根据其IP地址查找黑客所在位置,采取应对措施。当判断有入侵行为发生时,系统可以采取自动终止攻击、终止用户连接、禁止用户操作、重新配置防火墙阻塞攻击的源地址、记录事件日志与事件相关原始数据等方式进行响应。(5) 优化模块:优化模块主要是指在入侵检测系统模型的训练阶段及开始正常运行的阶段从事优化工作的部件集合。主要内容及功能包括对正常数据流的分析与采集、自我集的建立、自我集与候选初始检测器的负选择、检测器冗余优化、利用混合遗传算法对成熟检测器集进行进化等。(6) 异常模式库与检测器关联库:顾名思义,异常模式库用来保存和记录已被判定和检测出的入侵行为,检测器关联库用来保存和记录检测器之间可能存在的联系。本章小结本章研究并分析
了基于免疫机制的入侵检测模型,引入了检测器冗余优化的概念及相关内容并对检测器进行了改进和设计,将改进的HGA及免疫入侵检测原理运用到入侵检测系统模型的设计中。构造了一个基于改进的HGA的免疫入侵检测模型。给出了逻辑结构,并对该模型的工作流程和各模块的作用进行了研究。仿真实验及实验结果分析仿真实验由于本文的重点是在基于HGA的检测器的优化和在入侵检测系统中使用免疫遗传算法,以及对算法进行改进和检测器性能效率的提高,因此使入侵检测系统模型的功能有所改变。所以,作者所作的实验主要是对改进后算法性能的检测和入侵检测系统模型中基因库的建立(采用遗传算法进行优化)和应用(在进行入侵检测时,使用遗传算法所生成的基因库进行匹配检测)。数据源的选择我们采用目前国际上比较流行的MTI1998DARAP入侵检测评价计划数据集为实验数据。MIT1998DARPA入侵检测评价计划是美国国防部高级研究规划署(DARPA)的入侵检测评估项目,是由麻省理工学院林肯实验室主持,并由ADRAP机构和美国空军研究实验室资助的,目的是对入侵检测技术实现全面的技术评估。该项目开始于19xx年,在19xx年和20xx年也提供了评估数据。它是利用与空军基地相似的背景通信量来评估各种入侵检测的检测率和误报警率。其中19xx年的DARPA的评估数据是测试入侵检测系统性能的事实上的Benchmark。为了使试验具有可比性,我们利用该数据集进行测试和评估。19xx年的DARPA评估项目提供了一个模拟的局域网上采集来的9个星期的原始TCPDUMP格式的网络连接数据,其中模拟了政府和空军的1000个主机上的100多个用户的正常的通讯,同时包含了38种攻击。其中7个星期训练数据集包含5百万个连接数据,2个星期的测试数据集包含了2百万个连接数据。每个连接包含大约100bytes。试验数据中的38种攻击被分为4类,Dos类、Probing类、R2L类和UR2类。而R2L和UR2攻击所占比例很小。训练数据中包含有22种攻击,而测试数据中包含有17种未见攻击。攻击分类见下表5-1。为了从包含大量冗余信息的数据中提取出尽可能多的安全信息,抽象出有利于进行判断和比较的特征集合Wenke Lee在这方面已做了大量的工作,建立了KDDCUP99项目[45]。Lee从DARPA1998数据中抽取41维特征,分为基本特征(basic features)、内容特征(content features)、两秒钟内的流量特征(traffic features comuted using two-seconds time window)、主机流量特征(host-based traffic features)。由于KDDCUP99是针对数据挖掘的特征提取方法,数据特征项含有无数值意义的字符项。表5-1 19xx年DARPA评估数据中的攻击分类Table 5-1 The DARPA evaluate data’s attack classification of 1998类别?训练数据中出现的攻击?测试数据中出现的新攻击??DOS ?back,land,netune,od,smurf,teardro?Aache2,mailbombProcesstable,udstorm??Probe?Iswee,nma,ortswee,satan?Mscan,saint??R2L?ft-write,guess-assword,ima,multihoPhf,sy,warezclient,warezmaster?Named,sendmail,snmgetattackSnmguess,sqlattack,xlock,xsnoo??U2R?Buffer-overflow,loadmodule,erl,rootkit?htttunnel,s,worm,xterrn??1.基本特征(basic features)基本特征反映了一个独立连接的基本属性,有以下一些特征。(1) duration:连接持续时间。(2) rotocol tye:连接使用的协议,我们以IP协议中的协议类型进行骗码,TCP=6、ICMP=1、UDP=17。
(3) Service:服务类型。如htt、ft、time、telnet等,按服务常用的端口号进行编码。(4) flag:连接终止状态。flag有n个状态。我们对其进行编码。SF=0,TCP会话正常完成;SF=1,连接建立,却没有终止;S2=2,连接建立并被发起方关闭,接收方没有响应;S3=3,连接建立并被接收方关闭,发起方没有响应; S0=4,一方发出SYN,另一方没有应答;SH=5,发起方发出一个SYN和FIN,却没有收到SYN和ACK应答;OTH=6,没有SYN的大流量通讯;RST0=7,连接己建立,发起方发送RTS,放弃连接;RSTR=8,连接己建立,接收方放弃连接;RST0S0=9,发起方发出SYN和RTS,却没有收到SYN和ACK应答;RSTRH=10,接收方发送SNY和RTS,却没有收到从发起方发送的SYN;REJ=100,连接企图被拒绝;(5) src_bytes:从发送方到接收方的数据比特数。
第四部分:

(6) dst_bytes :从接收方到发起方的数据比特数。(7) land:发起方的地址和接收方地址是否一样。(8) wrong_fragment:错误分片个数。
(9) urgent:带外数据包个数。2.内容特征(content features)由于R2L和U2R攻击一般都潜藏在数据包的数据负载部分,而且从单一的数据包分析和正常连接没有什么区别。内容特征反映了在数据包负载部分可能的入侵信息,如num_fai1ed_loggins说明失败登陆次数信息,这对于检测guess_asswd之类的R2L攻击十分有效。但是13维的内容特征并不能反映数据包负载部分的全部特性。这样的特征抽取方法,对特洛伊木马一类的攻击,依然无法检测。(10) hot:访问系统敏感目录和文件的次数。(11) num_failed_logins:失败登录次数。(12) loggde_in:是否成功登录,成功为1,失败为0。(13) num_comromised:出现comromised情况的次数。(14) root_shell:是否获得了根shell,成功为1,失败为0。(15) su_attemted:是否出现“su_root”命令,是为1,否则为0。(16) num_root:根用户访问次数。(17) num_file_creations:创建文件操作次数。(18) num_shells:shell使用的次数。(19) num_aceess_files:访问文件操作次数。(20) num_outbound_cmds:在FTP会话中的outbound命令出现次数。(21) is_host_login:登录是否属于授权主机列表,YES=1,NO=0。(22) is_guest_login:是否为“guest”登录,YES=1,NO=0。3.两秒钟内的流量特征(traffic features comuted using a two-second time window)由于网络攻击事件通常在时间上具有很强的相关性,特别是对于Dos和Probing等攻击来说,在很短的时间内对同一主机会有多个连接。因此,考虑在检测数据中加入基于时间的统计特性,将会更好地反映攻击数据包之间的内在联系。采用时间窗的概念,即针对每一条连接记录,统计出在之前指定的时间内的连接记录与当前连接记录在属性上存在的某种联系。时间窗选为2秒。(23) count:在过去的2秒中目标主机和当前的记录中目标主机相同的连接记录个数。(24) srv_count:在过去的2秒中服务和当前的记录中服务相同的连接一记录个数。(25) serror_rate:在过去的2秒中出现SNY错误的连接的百分比。(26) srv_serror_rate:在过去的2秒中出现相同服务却有SYN错误的连接的百分比。(27) serror_rate:在过去的2秒中出现REJ错误的连接的百分比。(28) srv_serror_rate;在过去的2秒中出现相同服务却有REJ错误的连接的百分比。(29) same_srv_rate:在过去的2秒中与本连接记录相同服务的百分比。(30) diff_src_rate:在过去的2秒中与本连接记录不同服务的百分比。(31) srv_diff_host_rate:在过去的2秒中出现相同服务不同主机的百分比。4.主机流量特征(host-based traffic features)有一些Probing攻击使用慢速攻击模式。如每分钟扫描一次目标主机,而且从不同的主机发起扫描连接,两秒钟内的流量特征无法检测这类攻击。因此,主机流量特征用来更大范围的检测可疑活动,增加对该类攻击的检测能力。这里使用了一个100个连接记录窗口,统计本次连接之前,100个连接记录和本连接的关联关系。(32) dst_host_count:之前100个连接中和本次连接相同目标主机的连接个数。(33) dst_host_srv_count:相同目标主机相同服务的连接个数。(34) dst_host_same_srv_rate:相同目标主机相同服务的百分比。(35) dst_host_diff_svr_rate:相同目标主机不同服务的连接百分比。(36) dst_host_same_src_ort_rate:相同目标主机相同源端口连接百分比。(37) dst_host_srv_diff_host_rate:相同目标主机相同源端口不同源主机连接百分比。(38) dst_host_serror_rate:相同目标主机且出现YSN错误的连接百分比。(39) dst_host_srv_serror_rate:相同目标主机相同服务而且出现YSN错误的连接百分比。(40) dst_host_serror_rate:相同目标主机而且出现REJ错误连接百分比。(41) dst_host_srv_srerror_rate:相同目标主机相同服务而且出现REJ错误的连接百分比。以上就是经过数值混合编码后的41维特征,和传统的特征抽取方法比较,这些特征能够更好的反映多个数据连接之间的内在联系,可以使IDS检测出隐藏在多个数据连接内的攻击,克服了以往DIS中特征抽取中的不足。我们将这41维特征全部转换为数值特性,这样可以被免疫遗传算法处理,而且编码后的数据保留了网络连接信息,这将大大地增强免疫遗传算法对于入侵检测领域内各种问题的解决。下面我们将就对包含有41维特征的国际标准数据集DARAP1998进行实验,用来评估我们设计的基于免疫遗传算法在入侵检测上的有效性和可行性。试验环境描述运行环境:Windows2000,内存DDR512MB处理器:IntelPentium4,Cu2.40GHz仿真软件:MATLAB7.0 Release14由于1998DARPA入侵检测数据容量大约为4G,经过TCP包重组后,整理成近5百万条连接数据,每条数据有41个属性,这么大的数据量几乎无法使用单机进行仿真试验。本文采用一个精简数据集,共有4个不同的数据集合。第一个是在没有网络入侵时获取的tc包头,
即正常模式(自我模式),另外三个是网络有入侵时获取的tc包头,即异常模式(非我模式)。入侵方法分别是:smurf攻击,iswee攻击,netune攻击,back攻击。总共包含65170个连接记录,其中l39297条为正常连接,25873为入侵,包括smurf攻击11258条,iswee攻击658条,netune11955条,back攻击2002条等 我们将使用的入侵检测数据的特征分为基本特征(basic features)、内容特征(content features)、两秒钟内的流量特征(traffic features comuted using a two-second time window)、主机流量特征(host-based traffic features)四类。这些特征相当于自然免疫系统的抗原决定基,在自然免疫系统中,抗体对抗原的检测主要是通过淋巴细胞表面的细胞接收器与抗原表面的抗原决定基发生粘合(bind)反应而完成的,一个抗原可能带有多个不同类型的抗原决定基。类似的,我们建立的入侵检测抗体是根据从网络数据包中提取出来的特征进行应的检测从而区分出正常的数据包与异常的数据包。实验结果及分析第一步,在同等条件下,我们先仅对算法本身(非入侵检测),将经典遗传算法(SGA)和改进的免疫遗传算法(HIGA)进行比较,采用相同PC机和Matlab7.0计算平台对几个从国际标准数据库中选取的经典算例进行仿计,该库是用于测试各类算法的数学模型库。算例可描述为:给定染色体数和染色体之间的关联数,利用GA求取在保证关联不被破坏的情况下使得在迭代固定次数后满足适应度高于给定值的染色体数尽量少。仿计目标是,能够验证HIGA优于SGA。结果如下:表5-2 算例数据Table5-2 The examle data of exeriment问题?染色体数?染色体之间关联数??P_Queen52?25?160??P_David?87?406??P_Queen102?100?1470??P_Miles500?128?1170??P_Anna?138?493??上述算法参数为:种群规模100;交叉和变异概率分别为0.9和0.01;最大迭代代数200。如表所示在同等条件下,新方法除去了一定数量的冗余染色体,在种群数量限定于一定范围内的情况下,在既保持了染色体之间的关联和覆盖率的情况下,又使得染色体数量得到了控制。表5-3 实验比较结果Table5-3 The result of comare the two exeriment问题?算法?所取染色体最佳数目?所取染色体平均数目?标准差?算法平均时间耗费??P_Queen52?SGA?21?21.57?0.52?4.74???HIGA?20?20.39?0.53?3.30??P_David?SGA?51?52.46?1.04?15.85???HIGA?51?51?0?4.90??P_Queen102?SGA?91?91.72?0.62?12.86???HIGA?91?91?0?8.44??P_Miles500?SGA?111?112.72?0.96?12.00???HIGA?110?110.90?0.60?8.25??P_Anna?SGA?61?65.36?1.80?28.34???HIGA?59?59?0?6.40??第二步,检测入侵的检出准确率是衡量IDS性能的重要标准,主要是误报率和漏报率。对误用检测来说,如果检测规则设置的很精确,那么误报率会很低,但对新的入侵形式,会有较高的漏报率。对异常检测来说,可由预设的阈值来控制,由于误报率和漏报率成反比,和检出率成正比。当阈值低时,检出率上升,漏报率下降,误报率上升;反之,当阈值高时,误报率下降,检出率下降,漏报率上升。假设T为GA进化固定代数时模式库的建立时间;Ti为GA进化到第i代时模式库的建立时间,都以分钟为单位。表5-4是当进化代数固定,模式库总数增多时,模式库形成所需时间和检测效率。表5-5是当模式库大小固定,每代进化所需时间相同时,模式库形成所需时间和检测效率。由表中可见,在迭代次数固定,交叉概率为0.8,变异概率为0.05,初始种群为1万至2万时,群体越大,误报率和漏报率越低,检测率越高,但系统耗时越长,匹配速度越慢,性能越低。从第5代到第20代适应度提升很快,30代后开始收敛,适应度值在最优解之间徘徊不前。因此进化代数应根据群体大小来适当选择,而并非代数越多,检测效率就越高。表5-4 检测参数及生成模式库时间Table5-4 Time of building the DB of mode and arameters模式总数(万)?1.0?1.2?1.4?1.6?1.8?2.0??T(分钟)?40?50.2?65?72.2?87.1?93.2??检测率?0.455?0.562?0.721?0.812?0.855?0.912??误报率?0.003?0.005?0.011?0.023?0.025?0.035??漏报率?0.545?0.438?0.279?0.188?0.145?0.088??表5-5 检测参数及生成模式库时间Table5-5 Time of building the DB of mode and arameters进化代数?5?10?15?20?30?50??T(分钟)?30?60?90?120?180?300??检测率?0.491?0.745?0.811?0.835?0.904?0.901??误报率?0.004?0.005?0.016?0.026?0.031?0.028??漏报率?0.509?0.255?0.189?0.165?0.096?0.099??第三步,考虑到计算机性能及时间等因素,我们将精简数据集中的正常连接每隔10条记录抽取1条组成正例集,作为自体的学习集,通过设计的免疫遗传算法来进行免疫学习。并将入侵检测集中的入侵类型进行归类,进行检测实验,通过对比DARPA提供的检出率来验证免疫遗传算法的性能。这次我们设定种群规模osize=100,进化总代数为100,交叉概率为0.8,变异概率为0.08。表5-6到表5-9是上述步骤的实验结果。试验中,我们用自我模式分别去检验上述四种非我模式,进化到第100代检测结束。每种非我模式的检测各独立进行4次,得到以下的实验结果。表中为检测到的异常模式条数。表5-6 Smurf攻击实验结果Table5-6 The exeriment result of simulate Smurf attack实验号迭代次数?1?2?3?4??第0代?32?24?27?30??第1代?62?57?49?50??第2代?169?178?148?172??第5代?235?246?230?216??第10代?398?421?403?380??第40代?1321?1345?1337?1452??第70代?2340?2359?2345?2367??第100代?3189?3241?3258?3325??表5-7 Back攻击的实验结果Table5-7 The exeriment result of simulate Back attack 实验号迭代次数?1?2?3?4??第0代?5?4?2?9??第1代?19?17?14?16??第2代?45?42?39?40??第5代?123?107?87?98??第10代?192?185?156?175??第40代?357?339?327?332??第70代?443?439?415?427??第100代?570?546?532?540??表5-8 Netune实验结果Table5-8 The exeriment result of simulate Netune attack 实验号迭代次数?1?2?3?4??第0代?16?20?17?23??第1代?39?42?35?47??第2代?130?135?129?148??第5代?235?208?246?216??第10代?456?427?468?419??第40代?1427?1398?1459?1390??第70代?2347?2349?2435?2180??第100代?3268?3321?3620?3146??表5-9 Iswee攻击的结果Table5-9 The exeriment result of simulate Iswee attack 实验号迭代次数?1?2?3?4??第0代?10?9?12?8??第1代?19?17?22?16??第2代?26?23?28?21??第5代?36?32?38?30??第10代?45?41?52?39??第40代?83?79?92?75??第70代?148?145?156?139??第100代?215?210?219?203??从实验的结果能够看出,在对每种入侵数据的每次实验中,随着进化次数的
增加,识别到的未知入侵模式的记录数在稳步上升。比如在I Swee攻击中,一开始识别攻击数比较少,都是10条左右。但是随着进化代数的增加,攻击识别出的入侵越来越多,达到200多条。这就表明通过进化学习,算法逐步获得了入侵检测模式信息,从而验证了本算法对未知入侵模式的识别能力。使得系统有较高的动态性,从而验证了该模型的可用性和先进性。下表5-10给出了DARPA的评估检验结果[45,46]:表5-10 DARPA入侵检测评估结果Table5-10 The evaluate result of DARPA Intrusion Detection 检测率攻击类型?旧攻击? 新攻击??I swee攻击?80%? 28%??Netune攻击? 85%? 45%?? Smurf攻击? 78%? 35%?? Back攻击? 88%? 29%??表中所列的数据是进行评估的入侵检测系统能够检测的最好的结果。参照此评估方法来评估我们设计的基于免疫遗传算法的入侵检测系统。如下表5-11所示为旧攻击检测性能,表5-12为新攻击检测性能。表5-11 旧攻击检测结果Table5-11 The detection result of old tye attack 检测率攻击类型?旧攻击数目?检测数目? 检测率??I swee攻击? 458? 378?82.5%??Netune攻击? 10278? 10124? 98.5%??Smurf攻击? 9858? 9628? 97.6%??Back攻击? 1967? 1759? 89.4%??表 5-12 新攻击的检测结果Table5-12 The detection result of new tye attack 检测率攻击类型?新攻击数目? 检测数目?检测率??I swee攻击?278? 107?38.5%??Netune攻击? 3259? 1842? 56.5%??Smurf攻击?2986 ? 1345? 45.1%??Back攻击? 865? 285?32.9%??可以看出,在检测旧攻击方面,基于改进的HIGA的免疫入侵检测系统的评估检测结果表现良好,几乎能够检测出所有Smurf攻击,在检测新攻击方面,检测新攻击时,基于免疫遗传算法的入侵检测系统也能够非常好的完成入侵检测,但是对于新类型的back攻击,检测率却比较低,与DARAP评估方案的检测率相近,因此,必须进行免疫学习来更新轮廓,提高检测率。本论文的创新点“检测器冗余优化”是关于多检测器之间的协同,“检测器的优化”是提高单个检测器的检测能力,而“对GA中的交叉遗传算子进行了重新设计”是为了提高遗传算法的求解质量。上述几点是本文的主要创新之处。与现有同类研究比较,本文所提出的改进与优化策略具有如下特点和优势:继承了传统检测器的基本的生成和生命周期的架构。保留了其合理的有利的部分,并增加了新的改进环节。引入了检测器冗余优化的概念及相关内容,与以往的结构相比,改善了检测器结构及其生成过程和工作流程。与同类研究相比,为了获得更好的检测效果,同时采用了“均匀设计抽样理论重新设计交叉遗传算子,染色体相似度计算的改进,全局搜索和局部搜索策略的协调”。与以往同类研究不同的是,新的入侵检测模型将HGA分别应用于新检测器的生成和已有检测器的进化两个环节当中。将上述改进策略引入到入侵检测中,给出了基于改进的HGA的免疫入侵检测模型的逻辑结构。本章小结本章对前面所设计和改进的算法以及入侵检测模型进行了仿真实验,通过MATLAB仿真实验对该算法进行了验证,实验结果证实了改进算法的有效性和可行性。并简要介绍了本文的创新点。
- 维修检测报告表
- 检测维修报告
- 维修检测报告
-
维修检测分析报告
检测分析报告第一步我公司对2辊辊面进行维修后辊面锥度圆跳动均在001mm以内可以拆下验证第二步大辊两端轴套外圆与墙板内孔以前公差在…
- 检测维修报告表
-
汽车检测与维修 实习报告
顶岗实习报告时间过得飞快,半年的实习转眼就快过去了。这大半年来,我一直在汽车维修行业进行实习锻炼。没可否认,汽车维修很苦、很累,但…
-
汽车检测维修报告
汽车维修检测实习报告学生学院交通运输与物流院专业班级汽车服务工程一班学号20xx学生姓名时间20xx年6月中南林业科技大学目录一实…
-
电脑维修请示报告
请示检验科关于维修电脑显示屏的请示疾控中心办公室由于从业人员体检项目由乙肝检测变更为甲肝戊肝检测而甲肝戊肝检测需用带电脑的酶标仪目…
-
iPhone手机接机、三包检测及维修报告书样本
附件3iPhone手机接机三包检测及维修报告书样本一iPhone接机报告书用于无苹果授权维修网点地区电信销售点接机时填写二iPho…
- 维修检测报告
-
12电脑维修工作总结
电脑维修工作总结20xx年就已经离我们而去,20xx年已经到来。xx年的工作告一段落,我来到公司已经有6年。在公司中我担任维修部经…