高分子化学实验报告9
高分子化学实验报告(9)
实验者姓名:贺学兵 试验时间:2014/05/12
第二篇:实验报告9 查询优化(1)
《数据库系统概论》实验报告
题目:实验九 查询优化 姓名 Vivian 日期 2006-1-1 实验内容及完成情况(写明你的优化方案):
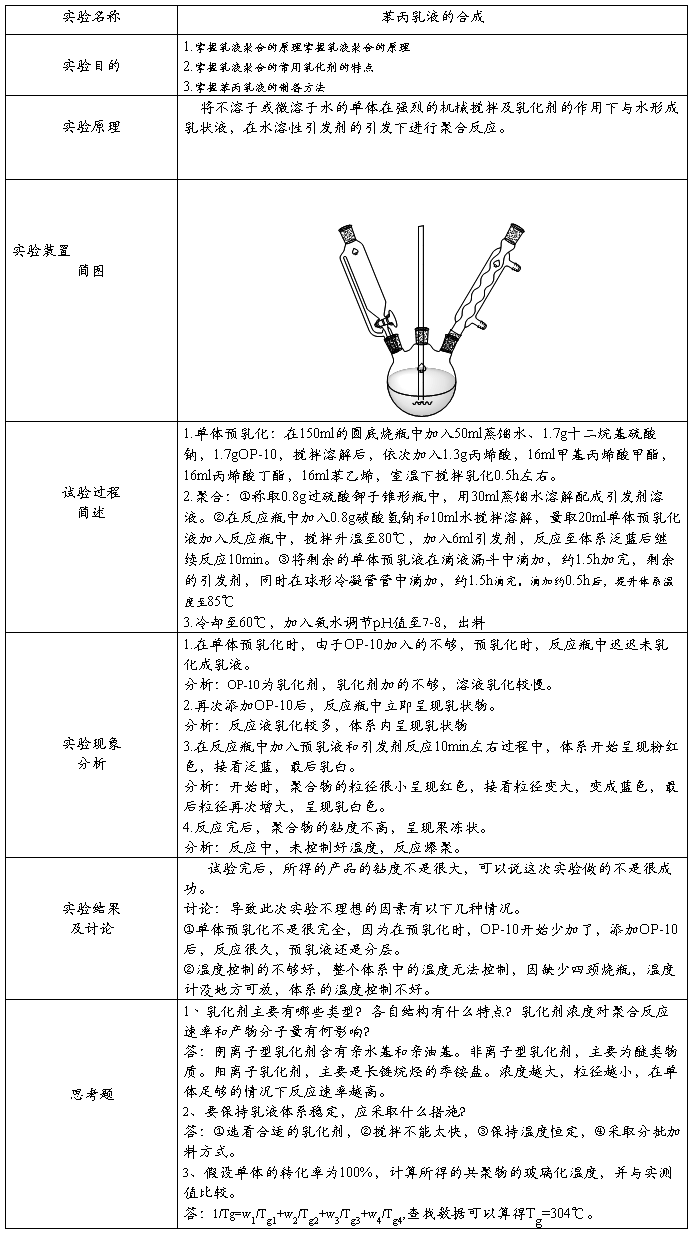
一.实验运行环境:
CPU:P3 800
内存:512MB
硬盘:30G
操作系统:WINDOWS 2000 ADVANCED SERVER
数据库系统:KingbaseES V4.1
二.设计数据库及其数据状况:
1.为本实验建立一个新的数据库,其中包括Student、Course、SC表和STU、COU、S_C表,
它们的结构与《概论》书中的“学生课程数据库”类似。
2.本实验中,表Student共有30条记录,表Course共有20条记录,表SC共有100条记录;
表STU共有10000条记录,表COU共有100条记录,表S_C共有1000000条记录。其中,Student、Course、SC表已在自动建立的“学生课程数据库”中;STU、COU、S_C表中的数据可以通过执行存储过程INSERT_STU、INSERT_COU、INSERT_S_C,在建立的库中导入数据。
3.单表查询实验中,我们设计的数据情况如下:表Student中>20岁的学生记录为0条,占
总元组数的0%;表STU中>20岁的学生记录为150条,占总元组数的1.5%。
(一) 单表查询
【例1】查询Student 表中20岁以上学生的信息(表中元组数少,查询结果元组数所占比例小)
[例1-1]直接查询
SELECT * FROM Student WHERE sage>20;
查看预查询计划:EXPLAIN SELECT * FROM STUDENT WHERE sage>20;
执行语句并查看查询计划:sage>20;
查询计划:
QUERY PLAN
----------------------------------------------------------------------------------
Seq Scan on STUDENT (cost=0.00..1.38 rows=1 width=51) /*表示系统的预查询计划*/
(actual time=0.000..0.000 rows=0 loops=1) /*表示系统实际执行的查询计划*/
Filter: (SAGE > 20) /*Student表的过滤条件sage>20*/
Total runtime: 0.000 ms /*表示系统的实际执行时间*/
[例1-2]建立索引后再查询
CREATE INDEX stuage ON Student(sage);
SELECT * FROM Student WHERE sage>20;
查询计划:
QUERY PLAN
----------------------------------------------------------------------------------
loops=1)
Filter: (SAGE > 20)
Total runtime: 0.000 ms
【例2】查询Student 表中20岁以下学生的信息(表元组数少,查询结果元组数所占比例大)
[例2-1]直接查询
SELECT * FROM Student WHERE sage<20;
查询计划:
QUERY PLAN
----------------------------------------------------------------------------------
Seq Scan on STUDENT (cost=0.00..1.38 rows=23 width=51) (actual time=0.000..0.000 rows=22 loops=1)
Filter: (SAGE < 20)
Total runtime: 0.000 ms
[例2-2]建索引后再查询
CREATE INDEX stuage ON Student(sage);
SELECT * FROM Student WHERE sage<20;
查询计划:
QUERY PLAN
----------------------------------------------------------------------------------
Seq Scan on STUDENT (cost=0.00..1.38 rows=23 width=51) (actual time=0.000..0.000 rows=22 loops=1)
Filter: (SAGE < 20)
Total runtime: 0.000 ms
【例3】查询STU表中20岁以上学生的信息(表元组数多,查询结果元组数所占比例小)
[例3-1]直接查询。
SELECT * FROM STU WHERE age>20;
查询计划:
QUERY PLAN
----------------------------------------------------------------------------------
loops=1)
Filter: (AGE > 20)
Total runtime: 30.000 ms
[例3-2]建立索引后再查询。
CREATE INDEX stuage ON STU(age);
SELECT * FROM STU WHERE age>20;
查询计划:
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using AGE on STU (cost=0.00..196.01 rows=57 width=48) (actual time=0.000..0.000 rows=150 loops=1) /*利用索引扫描表STU*/
Index Cond: (AGE > 20) /*索引条件:AGE>20*/
Total runtime: 0.000 ms
[例3-3]建立索引后增加限定条件再查询
SELECT * FROM STU WHERE age > 20 AND sex = 1;
查询计划:
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using AGE on STU (cost=0.00..196.15 rows=29 width=48) (actual time=0.000..0.000 rows=75 loops=1)
Index Cond: (AGE > 20)
Filter: (SEX = 1)
Total runtime: 0.000 ms
【例4】查询STU表中20岁以下学生的信息(表元组数多,查询结果元组数所占比例大)
[例4-1]直接查询。
SELECT * FROM STU WHERE age<20;
QUERY PLAN
----------------------------------------------------------------------------------
Seq Scan on STU (cost=0.00..356.16 rows=2949 width=48) (actual time=0.000..20.000 rows=7388 loops=1)
Filter: (AGE < 20)
Total runtime: 60.000 ms
[例4-2]建立索引后再查询。
CREATE INDEX stuage ON STU(age);
SELECT * FROM STU WHERE age<20;
查询计划:
QUERY PLAN
----------------------------------------------------------------------------------
Seq Scan on STU (cost=0.00..432.00 rows=7497 width=48) (actual time=10.000..21.000 rows=7388 loops=1)
Filter: (AGE < 20)
Total runtime: 61.000 ms
注释:
1.查询计划中的第一个括号内表示的是系统的预查询计划。其中,cost等号后的两个数字,分别代表“预计的启动时间”和“预计的总时间”(以磁盘页面存取为单位计量);rows代表“预计输出的行数”;width代表“预计的行的平均宽度(以字节计算)”。
2.查询计划中的第二个括号内表示的是系统实际执行时的计划。其中,actual time等号后的数字表示“在每个计划节点内部花掉的总时间”(以ms为单位);rows代表实际返回的结果行数;loops代表进行查询循环的次数。(这是因为我们在显示查询计划是用的是explain analyze,analyze导致查询语句实际执行,而不仅仅是一个预期计划)
3.Total runtime包括优化器启动和关闭的时间,以及花在处理结果行上的时间。对于SELECT查询,总运行时间通常只是比从顶层计划节点汇报出来的总时间略微大些。
4.在建立表之后,执行查询计划的步骤是:
? 执行命令:analyze <表名>。这实际上是系统对数据库的数据进行新的统计。这样做
的原因是为了让查询优化器在优化查询的时候做出合理的判断,防止因为统计信息
的陈旧造成系统选择错误的查询计划。
? 选择查看预查询计划还是查看实际执行的查询计划。
查看预查询计划的语句是: EXPLAIN <SQL语句>
查看实际查询计划的语句是:EXPLAIN ANALYZE <SQL语句>
5.因为系统对每一个查询语句都会进行一次优化,每次运行时系统环境和数据也会变化,因此每次得到的查询计划数据也可能有所变化。
总结分析(有索引时不同条件下的查询执行计划):
表的元组数量
查询结果的比例大
查询结果的比例小 元组数多 顺序扫描全表(有无索引的实际执行时间几乎相等) 利用索引扫描提取(使用索
引比顺序扫描表的查询时间
大大减少了) 元组数少 顺序扫描全表(有无索引的实际执行时间几乎相等) 顺序扫描全表(有无索引的实际执行时间几乎相等)
1.我们可以看到,以上四个查询中【例1】【例2】【例4】有索引和没有索引的查询计划都是相同的,即都是顺序扫描全表;只有【例3】在建立了索引后使用了索引进行扫描。可见,在建立索引后系统并不一定对所有的查询都使用索引。
2.【例3】在建立索引后使用索引的原因分析:在[例3-2]中,我们把WHERE条件变得足够有选择性,即表中总的元组数非常大而结果数所占比例非常小(5%-10%)。系统优化器经过代价估算后得到利用索引将比全表顺序扫描快的结果。因为有索引,这个计划将只需要访问 150 条记录,所以选择使用索引。
3. [例3-2]和[例3-3]的开销比较分析:在[例3-3]中,我们增加了查询的限定条件,可以看出,增加的条件减少了预计的结果行数(从57减少为29),但是却没有减少开销(预计总时间分别为196.01ms和196.15ms),因为查询时仍然需要访问相同的行。性别上不同值的个数只有男、女两个,不合适建立索引。sex = 1只能做为对索引中检索出的元组的过滤器,实际上开销还略微增加了一些以反映这个检查。
(二)多表查询
【例5】嵌套查询(表元组数少)
[例5-1]查询选修了2号课程的学生姓名。
SELECT Sname
FROM Student
WHERE Sno IN
(SELECT Sno
FROM SC
WHERE Cno= ‘2’);
查询计划:
QUERY PLAN
----------------------------------------------------------------------------------
Hash IN Join (cost=22.51..23.97 rows=1 width=21) (actual time=0.000..0.000 rows=16 loops=1)/*对Student表和Hash表进行连接*/
Hash Cond: ("outer".SNO = "inner".SNO)
?Seq Scan on STUDENT (cost=0.00..1.30 rows=30 width=32) (actual time=0.000..0.000 rows=30 loops=1)


?Index Scan using STU_NUM_50304_KEY on STU (cost=0.00..2.01 rows=1 width=28) (actual time=0.045..0.048 rows=1 loops=10000) /*利用主码索引对STU表进行扫描*/
Index Cond: (STU.NUM = "outer".S_NUM)
Total runtime: 3074.000 ms
分析:在STU表上使用了索引,因为STU表的元组数足够大,系统在分析后选择了代价较小的索引查找方法。
这个例子产生的查询计划是一个嵌套循环,并且是将选择完后的S_C表作为外表对STU表进行循环扫描。这样做的原因是对S_C进行过滤之后,产生的中间结果元组数不比STU表的元组数多很多,而STU表上有选择率较高的索引STU_NUM_50304_KEY,在查询时可以利用索引STU_NUM_50304_KEY对元组快速定位抓取。对S_C表进行选择之后共产生10000条记录,因此需要对STU表进行10000次的循环索引查找。
[例5-1]和[例6-1] 是2个相同的查询语句,系统实际执行的查询计划是不同的。原因是,
[例5-1]中Student表和SC表都很小而[例6-1]中操作的表都很大。说明KingbaseES的查询优化器是依据统计信息进行代价估算来选择高效的操作算法或存取路径的,从而产生了不同的查询计划。
[例6-2-1]查询没有选修1号课程的学生姓名。
SELECT name
FROM STU
WHERE NOT EXISTS
(SELECT *
FROM S_C
WHERE s_num = STU.num AND c_num = 1);
查询计划:
QUERY PLAN
----------------------------------------------------------------------------------
Seq Scan on STU (cost=0.00..250407.00 rows=5000 width=24)(actual time=9695461.000..9695461.000 rows=0 loops=1)
Filter: (NOT (subplan))
SubPlan
?Seq Scan on S_C (cost=0.00..25.00 rows=1 width=12) (actual time=969.430..969.430 rows=1 loops=10000)
Filter: ((S_NUM = $0) AND (C_NUM = 1))
Total runtime: 9695461.000 ms
分析:从这个实例可以看到,在没有任何索引,数据量非常大的表上进行相关子查询所耗费的时间非常长(约为2.7小时),代价将是非常大的。因为查询的过程是从外表取记录,对内表检测是否符合EXIST条件的重复过程,需要对内表进行多次循环扫描。
我们可以考虑通过建立索引、改写查询语句等方法对该查询进行一些优化。以下分别尝试了四种优化方式,可以和[例6-2-1]进行查询计划和查询代价比较。
[例6-2-2]在S_C表的属性s_num上建立索引snumindex,然后进行查询。
CREATE INDEX snumindex ON S_C (s_num) ;
SELECT name
FROM STU
WHERE NOT EXISTS
(SELECT *
FROM S_C
WHERE s_num = STU.num AND c_num = 1);
查询计划:
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------rows=0 loops=1)
Filter: (NOT (subplan))
SubPlan
time=0.177..0.177 rows=1 loops=10000)
Index Cond: (S_NUM = $0)
Filter: (C_NUM = 1)
Total runtime: 1823.000 ms
分析:在属性s_num上建立索引之后,系统在对S_C表进行扫描时就不再是顺序扫描了,而是对每一条外表STU记录的num值利用索引snumindex定位,然后再根据过滤条件c_num=1查找是否符合EXIST条件。可以看到,在[例6-2-1]中,每对S_C表扫描一次所花费的时间为969.430ms,而使用了索引之后,定位扫描的时间仅为0.177ms,大大减少了查询时间。
[例6-2-3]如果我们改变表S_C的定义,在创建时将s_num和c_num定义为主码。
CREATE TABLE S_C(
s_num INT,
c_num INT,
grade INT,
PRIMARY KEY (s_num,c_num));
SELECT name
FROM STU
WHERE NOT EXISTS
(SELECT *
FROM S_C
WHERE s_num = STU.num AND c_num = 1);
查询计划为:
QUERY PLAN
------------------------------------------------------------------------------------
Seq Scan on STU (cost=0.00..53325.91 rows=5044 width=24) (actual time=300.000..300.000 rows=0 loops=1)
Filter: (NOT (subplan))
SubPlan
-> Index Scan using S_C_1041627_PKEY on S_C (cost=0.00..5.27 rows=1 width=12) (actual time=0.016..0.016 rows=1 loops=10000)
Index Cond: ((S_NUM = $0) AND (C_NUM = 1))
Total runtime: 300.000 ms
分析:由于在定义表时将s_num和c_num定义为了主码,因此系统将在s_num和c_num上建立一个主码索引S_C_1041627_PKEY。和[例6-2-3]相比,在查询时,在对外表记录的num值利用索引定位之后,c_num=1不是当作一个过滤条件对所有与外表num值相等的记录进行过滤,而能够直接通过c_num上的索引快速定位,判断是否存在着c_num=1的记录。将对S_C表每次扫描的时间降低到0.016ms,查询时间进一步减少,得到更优的查询计划。
由此,我们可以看出,正确合适的使用索引是提高查询效率的一个有效手段,能够使查询时间得到数量级上的改进。
[例6-2-4]利用临时表将嵌套查询改写成连接查询。
SELECT name
FROM (
SELECT DISTINCT s_num
FROM S_C
WHERE c_num = 1)
AS TEMP RIGHT JOIN STU ON TEMP.s_num = STU.num
WHERE TEMP.s_num IS NULL;
查询计划:
QUERY PLAN
---------------
Merge Left Join (cost=22.60..254.72 rows=10088 width=24) (actual time=2353.000..2353.000 rows=0 loops=1) /*左连接,连接条件为STU.num = S_C.s_num*/ Merge Cond: ("outer".NUM = "inner".S_NUM)
Filter: ("inner".S_NUM IS NULL)
-> Index Scan using STU_NUM_17388_KEY on STU (cost=0.00..206.88 rows=10088 width=28) (actual time=0.000..80.000 rows=10000 loops=1)
-> Sort (cost=22.60..22.61 rows=1 width=4) (actual time=2193.000..2203.000 rows=10000 loops=1)
Sort Key: "TEMP".S_NUM
-> Subquery Scan "TEMP" (cost=22.56..22.59 rows=1 width=4) (actual
time=2033.000..2143.000 rows=10000 loops=1)
-> Unique (cost=22.56..22.58 rows=1 width=4) (actual time=2033.000..2093.000 rows=10000 loops=1) /*因为s_num要求唯一,因此需要进行唯一性检查*/ -> Sort (cost=22.56..22.57 rows=5 width=4) (actual
time=2033.000..2063.000 rows=10000 loops=1) /*对s_num进行排序以便下一步排除重复值*/ Sort Key: S_NUM
-> Seq Scan on S_C (cost=0.00..22.50 rows=5 width=4) (actual time=0.000..1983.000 rows=10000 loops=1)
Filter: (C_NUM = 1)
Total runtime: 2363.000 ms
分析:在本实例中,我们将原有的嵌套查询改写成为一个连接查询,将S_C表中所有选修了1号课程的学生学号形成一个临时TEMP,与STU表进行外连接,如果存在着无法满足连接条件的元组,即连接后TEMP.s_num为NULL值的元组,则是没有选修1号课程的学生记录。虽然改写后的查询计划层次更多了,但查询时间大大减少,达到了优化的目的。
另外,需要注意的一点是,我们在些查询语句时,是将TEMP表与STU表进行右外连接,
而系统在经过代价分析之后,选择将STU表作为外表,TEMP表作为内表,因此将语句中的右外连接改写成为实际执行的左外连接。
[例6-2-5]利用集合查询和连接查询的方式改写原有查询语句。
SELECT name
FROM STU
EXCEPT
SELECT DISTINCT name
FROM STU LEFT JOIN S_C ON (STU.num = S_C.s_num)
WHERE c_num = 1;
查询计划:
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------rows=0 loops=1) /*集合差操作,由两个结果集合相减得到最后结果*/ rows=20000 loops=1)
Sort Key: NAME
rows=20000 loops=1)
-> Subquery Scan (actual time=0.000..91.000 rows=10000 loops=1)
-> Seq Scan on STU (cost=0.00..204.88 rows=10088 width=24) (actual time=0.000..40.000 rows=10000 loops=1)
-> Subquery Scan "*SELECT* 2" (cost=20515.51..20659.36 rows=9590 width=24) (actual time=2513.000..2684.000 rows=10000 loops=1)
-> Unique (cost=20515.51..20563.46 rows=9590 width=24) (actual time=2513.000..2623.000 rows=10000 loops=1)
-> Sort (cost=20515.51..20539.48 rows=9590 width=24) (actual time=2513.000..2563.000 rows=10000 loops=1)
Sort Key: STU.NAME
-> Merge Join (cost=19505.37..19881.26 rows=9590 width=24) (actual time=2053.000..2263.000 rows=10000 loops=1)
Merge Cond: ("outer".NUM = "inner".S_NUM)
-> Index Scan using STU_NUM_17388_KEY on (cost=0.00..206.88 rows=10088 width=28) (actual time=0.000..120.000 rows=10000 loops=1)
-> Sort (cost=19505.37..19529.35 rows=9590 width=4) (actual time=2053.000..2053.000 rows=10000 loops=1)
Sort Key: S_C.S_NUM
-> Seq Scan on S_C (cost=0.00..18871.13 rows=9590 width=4) (actual time=0.000..1993.000 rows=10000 loops=1)
Filter: (C_NUM = 1)
Total runtime: 3435.000 ms
分析:在本实例中,我们利用了集合查询中的EXCEPT差操作,用全部学生记录减去选
修了1号课程的学生记录即得到我们要查询的结果,没有选修1号课程的学生记录。因此,整个查询计划包含两个子查询计划,第一个子查询计划是顺序扫描STU表选择属性列name;第二个子查询计划是一个左外连接,查询选修了1号课程的name唯一值,查询过程与[例6-2-4]相似。最后根据两个子查询的结果,进行集合操作,得到最终查询结果。可以看到,查询效率也得到了很大的提高。
从[例6-2-2]至[例6-2-5]可以看出,一个效率低下的查询计划,可以通过建立索引、改写语句等多种方式对它进行优化,优化后的查询结果将得到很大的改善(从2.7小时降低到数秒甚至300ms)。因此,如何选择最优的查询计划要求我们进行更多的分析和实践才能有所体会。
-
高分子化学实验报告
摘要离子交换法是液相中的离子和固相中离子间所进行的的一种可逆性化学反应当液相中的某些离子较为离子交换固体所喜好时便会被离子交换固体…
- 高分子化学实验报告9
- 高分子化学实验报告7
- 高分子化学实验报告10
-
高分子化学实验报告
高分子方向研究性实验报告姓名陈杭南班级10材化生实验班学号Q10100116指导老师张伟叶鹏浙江理工大学陈杭南Q10100116目…
-
高分子化学实验总结
高分子化学实验报告一实验目的1了解本体聚合的原理熟悉有机玻璃的制备方法2掌握减压蒸馏的原理及操作过程二实验原理甲基丙烯酸甲酯在过氧…
-
高分子化学实验报告
高分子方向研究性实验报告姓名陈杭南班级10材化生实验班学号Q10100116指导老师张伟叶鹏浙江理工大学陈杭南Q10100116目…
-
高分子化学实验报告
聚乙酸乙烯酯的制备及分子量的测定一偶氮二异丁腈的精制1实验原理引发剂是影响聚合反应速率和聚合物相对分子质量的重要因素其用量必须准确…
-
高分子化学实验报告
摘要离子交换法是液相中的离子和固相中离子间所进行的的一种可逆性化学反应当液相中的某些离子较为离子交换固体所喜好时便会被离子交换固体…
-
高分子化学实验
高分子化学实验课程性质独立设课课程属性专业基础学时学分总学时54实验学时54实验学分15开出时间三年级5学期适用专业化学教育专业综…