商务智能实验报告——商务智能 元数据的发展与标准
四川大学
课程实验报告

四川大学工商管理学院实验中心制
20xx年10月
实验报告书
一、实验目的
通过搜索总结元数据的发展与评判标准。
二、实验内容与实验步骤
? 实验内容:
BI的发展与应用
? 实验步骤:
通过INTERNET检索了解:
1> 商务智能发展历史概述、功能、技术支柱、应用前景、发展趋势;
2> 商务智能在各行业的总体应用状况;
3> 应用案例;
4> 商务智能的软件应用情况;
三、实验环境
1、VMware TOOL
2、SQL2000 AS
3、win2003 sever
4、联网计算机
四、实验过程与分析
1.1> 商务智能发展历史概述——数据仓库的发展及相关人物
? 萌芽阶段:
数据仓库概念最早可追溯到20世纪70年代,MIT的研究院致力于研究一种优化的技术架构,该架构试图将业务处理系统和分系统分来,即将业务处理系统和分析处理系统分为不同层次,针对各自的特点采取不同的架构设计原则MIT的研究员认为这两种信息处理方式有显著差别,以至于必须采取完全不同的架构和设计方法。但受限于当时的信息处理能力,这个研究仅仅停留在理论层面。 ? 探索阶段:
20世纪80年代中后期,DEC公司结合MIT的研究结论,建立了TA2(Technical Archtecture2)规范,该规范定义了分析系统的四个组成部分:数据获取,数据访问,目录和用户服务。这是系统架构的一次重大转变,第一次明确提出分析系统架构并将其运用到实践中。
? 雏形阶段
19xx年,为解决全企业集成问题,IBM公司第一次提出了信息仓库(InformationWarehouse)的概念,秉承着为VITAL规范(VirtuallyIntegrated 1
实验报告书
Technical Archtecture Lifecycle)。VITAL定义了85中数据仓库的基本原理,技术架构以及分析系统的住哟啊原则都已确定,数据仓库初具雏形。
? 确立阶段
19xx年Bill Inmon出版了他的第一本关于出具仓库的书《Building the data warehouse》,标志着数据仓库概念的确立。该书指出,数据仓库(Datawarehouse)是一个面向主题的(Subject Oriented),集成的(Integrated),相对稳定的(Non-Volatile),反映历史变化的(Time Variant)数据集合,用于支持管理决策(Decision-Making Support)。该书还提供了建立数据仓库的知道以及那和基本原则。凭着这本书,Bill Inmon被称为数据仓库之父。
浏览了数据仓库的一个简单发展历史,我们来了解一下数据仓库之父Bill Inmon。
? 数据仓库重要人物
比尔·恩门(Bill Inmon),被称为数据仓库之父,最早的数据仓库概念提出者,在数据库技术管理与数据库设计方面,拥有逾35年的经验。他是“企业信息工厂”的合作创始人与“政府信息工厂”的创始人。
比尔·恩门的思想与见识在所有重量级的计算机协会、许多产业会议、技术研讨会上,都博得了无比的敬重。他写过650多篇文章,大多发布在世界最知名的IT刊物里,DMReview杂志每期都有恩门先生的专栏文章,他写了46本书籍,最著名的要数“Building the Data Warehouse”(《建立数据仓库》),这本数据仓库精典读物倍受读者喜爱,一而再在而三地升级出版发行,到目前已经是第三版本,发行量达50多万册。也正是这本《建立数据仓库》为恩门赢得“数据仓库之父”的殊荣,国内机械工业出版社也分别将第2第3版本引进翻译,
恩门先生的著作也一直是亚马逊电子商务网站的畅销书,都深受广大数据仓库技术读者喜欢。同时恩门又是最知名的数据仓库咨询顾问专家,他为许多名列《财富》1000排行榜的公司提供过数据仓库设计和数据库管理方面的咨询服务。恩门这些年还创立过公司办过网上教育,1995创建了现在的Ambeo公司。
其《建立数据仓库》一书中定义了数据仓库的概念,随后又给出了更为精确的定义:数据仓库是在企业管理和决策中面向主题的、集成的、与时间相关的、不可修改的数据集合。
与其他数据库应用不同的是,数据仓库更像一种过程,对分布在企业内部各处的业务数据的整合、加工和分析的过程。而不是一种可以购买的产品。正是他当初对数据仓库的这个定义,已成为了业界引用最多、说得最广的名言,每一个启蒙的数据仓库学习者都是从这一句名言开始的。
? 分歧
随着拉尔夫·金博尔(Ralph Kimball)博士出版了他的第一本书“The DataWarehouse Toolkit”(《数据仓库工具箱》),数据仓库行业就开始喧哗起来,恩门的“Building the Data Warehouse”主张建立数据仓库时采用自上而下 2
实验报告书
(DWDM)方式,以第3范式进行数据仓库模型设计,而他生活上的好朋友Ralph Kimball在“The DataWarehouse Toolkit”则是主张自下而上(DMDW)的方式,力推数据集市建设,以致他们的FANS吵闹得差点打了起来,直至恩门推出新的BI架构CIF(Corporation information factory),把Kimball的数据集市包括了进来才算平息。
Ralph Kimball和Bill Inmon一直是商业智能领域中的革新者,开发并测试了新的技术和体系结构。他们都撰写了关于数据仓库的多本书籍,这些书也经常被参考。Kimball 和 Inmon 都同意组织需要一个与遗留系统和联机事务处理(OLTP)系统分开的数据仓库,以捕获组织的有关信息并且使之可用。他们也同意数据仓库中的数据应该是净化的、一致的,并且不受到其来源的遗留系统和 OLTP 系统设计的牵制。他们还同意用针对整个体系结构的思想重复构建数据仓库。到这里,他们的意见就发生了分歧。
Bill Inmon将数据仓库定义为“一个面向主题的、集成的、随时间变化的、非易变的用于支持管理的决策过程的数据集合”(Building the data warehouse,第 2 版,第 33 页)。Inmon通过“面向主题”表示应该围绕主题来组织数据仓库中的数据,例如客户、供应商、产品等等。每个主题区域仅仅包含该主题相关的信息。数据仓库应该一次增加一个主题,并且当需要容易地访问多个主题时,应该创建以数据仓库为来源的数据集市。换言之,某个特定数据集市中的所有数据都应该来自于面向主题的数据存储。Inmon 的方法包含了更多上述工作而减少了对于信息的初始访问。但他认为这个集中式的体系结构持续下去将提供更强的一致性和灵活性,并且从长远来看将真正节省资源和工作。
Ralph Kimball说“数据仓库仅仅是构成它的数据集市的联合”(Figure 2,The Data Warehouse Lifecycle Toolkit,第 27 页)。他认为“可以通过一系列维数相同的数据集市递增地构建数据仓库”。每个数据集市将联合多个数据源来满足特定的业务需求。通过使用“一致的”维,能够共同看到不同数据集市中的信息,这表示它们拥有公共定义的元素。Kimball的方法将提供集成的数据来回答组织迫切的业务问题并且要快于Inmon的方法。Inmon的方法是只有在构建几个单主题区域之后,集中式的数据仓库才创建数据集市。而Kimball认为该方法缺乏灵活性并且在现在的商业环境中所花时间太长。
? 影响
从Inmon被人尊称为数据仓库之父,就可以看出,inmon对于数据仓库领域的技术发展的作用是巨大的,无数数据仓库爱好者甚至把《建设数据仓库》看作是数据仓库的“圣经”。inmon自己创建的网站上的文章被广为传颂,每当有inmon公开演讲的时候,很多用户和技术人员都以能够聆听inmon的最新成果为荣。在企业信息工厂的设计蓝图中,inmon清楚地描述了如何从各种业务系统当中捕获需要的数据,并在随后的流程中,为适应不同的需求,而逐渐演变为各种不同的形态,所有的这一切都围绕着一个最重要的部件来运转,这就是企业数据仓库。 3
实验报告书
在国内数据仓库领域,inmon和kimball的理论也一度争论不休,但是随着数据仓库建设的逐步深化,把企业数据仓库作为企业数据整合平台的思路深得人心,越来越多的企业开始强调在企业内部建立一个企业级别的数据仓库来支持整个企业的发展和运作。
2> 商务智能应用——网络爬虫 网络爬虫是捜索引擎抓取系统的重要组成部分。
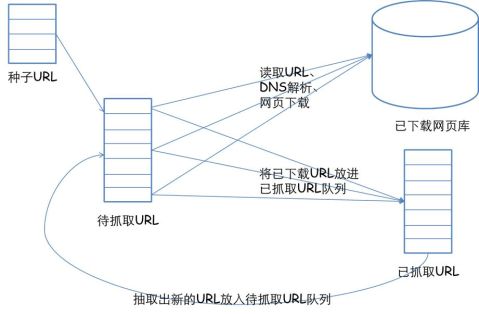
爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份。一个通用的网络爬虫的框架如图所示:
? 网络爬虫的基本工作流程
1.首先选取一部分精心挑选的种子URL; 2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
? 应用案例
Xenu Link Sleuth,检查网站死链接1的软件。可以打开一个本地网页文件来检查它的链接,也可以输入任何网址来检查。它可以分别列出网站的活链接以及死链接,转向链接也能分析得一清二楚;支持多线程2,可以把检查结果存储成文本文件或网页文件。
商业智能软件
4
实验报告书
3> 商务智能应用软件简介
自商业智能这一领域被开拓以来,国内外商业智能软件层出不穷。IBM cognos、SAP BO、oracle
BIEE、Microsoft BI、MicroStrategy、思迈特 BI、奥威智动 Power-BI等都是传统的BI软件,而Qliktech QlikView、tableau、永洪科技 Yonghong Z-Suite等是下一代BI的代表。
? 传统商务智能
传统商业智能基于数据驱动,以瀑布开发模式建设商业智能系统。传统商业智能软件需要预先形成CUBE,交付时间在半年左右,如果需求发生变化,相关模块调整周期按月计算。通常传统商业智能软件模块较多,操作复杂,无法形成自服务商业智能系统。
? 新一代商务智能
新一代商业智能软件区别于传统商业智能软件,基于业务驱动,无需预生成Cube,交付周期按周、月计算,能够形成自服务BI系统。对于需求变化,交付周期按天、周计算,相关模块调整不大。Yonghong Z-Suite、tableau、QlikView等新一代BI工具带有数据集市,可以处理海量数据。以Yonghong Z-Suite为例,其主要有以下特点:
驱动模式:业务驱动。
开发模式:以敏捷开发模式建设BI系统。
交付周期:交付周期偏短,项目失败率低;乐意在客户现场做POC(Proof of Concept)。需求变化:可以应对变化,新需求交付周期很短;相关模块调整不大,交付周期在一两天之内。成本:一站式平台提供数据集市和BI软件,无需购买MPP数据仓库,费用低。自服务BI:能够形成自服务BI。 分析:展现只是起点,分析功能强大。
海量数据:X86通用平台,以Scale-out扩展模式处理海量数据。基于CPU收费,具有较高性价。数据集市:Yonghong Z-Data Mart是一款专业的数据集市软件,实时分析海量数据。
五、实验结果总结
通过本次实验,
1)深入了解商务智能重要角色——数据仓库的发展历程,以及对其发展作出重大贡献的人物;
2)使用网络爬虫——体现了商务智能在互联网中的应用,感受网络爬虫的便捷与智能,对商务智能有了更好的认识。
六、附录
网络爬虫软件Xenu Link Sleuth的操作步骤如下:
? 启动界面
5
实验报告书
? 输入要检查的网址
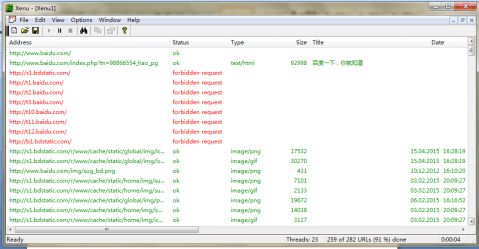
? 运行结果——红色的为死链接
6
实验报告书
1页面已经无效化,无法给用户提供任何有价值信息的页面 2在同一时间执行多于一个线程
7
第二篇:数据挖掘实验报告
管理学院实验(实训)报告
课程:商务智能与数据挖掘 地点:2607 时间:20##年5月7日

3. 单击Filter选区中的Choose按扭,选择unsupervised/attribute/Discretize命令,进行无监督离散化,单击Close按扭,如下界面:
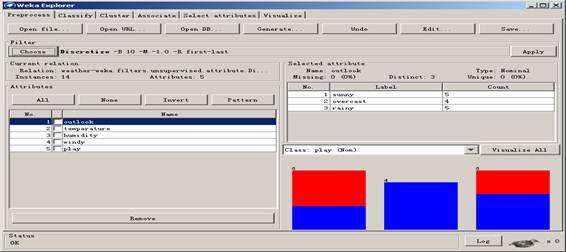
4.Choose后面的文本框中的discretize –B 10 –M -1.0 –R first-last处,看到如下图:

此图中的attributeIndices中的first-last,表示第一个属性用first代表,最后一个属性用last代表,则其他属性用数字代表,应数据要求,可作相应调整.在useEqualFrequency中的选项False表示的是采用的等间隔的离散化方法,True表示的是等频率的方法.
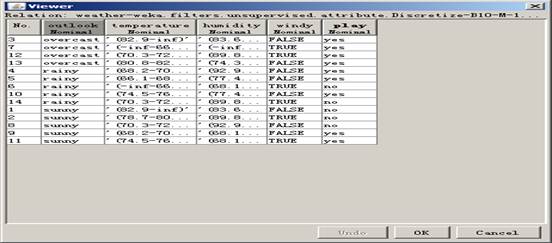
5.离散化第二和第三个属性,则将first-last改为2-3,在bins后修改间隔个数为3,单击ok回到主界面.单击Apply按钮,执行离散化,离散化结束,单击Edit,离散化后的数据如图所示:
关联分析:
1进行关联分析.打开数据集weather-disc.arff.选择Associate选项卡,单击Choose后面的文本框,得到如下图:

改变其属性得下图:
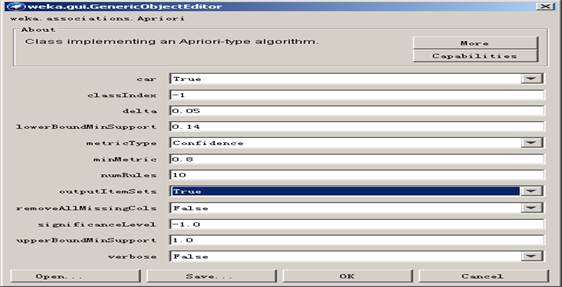
True代表发现的关联规则的右边是类别属性;-1代表数据表中的最后一列是类别属性;0.05代表最小支持度阀值的递减幅度。在这之中,从支持度阀值等于1开始找,每次降低0.05,最低不得低于0.14,关联规则的数目为10.关联规则的另一个约束由metricType指定,如果用置信度,则选择Confidence.相应的,0.8指的是最小置信度为0.8.outputItemSets:Ttue指的是输出满足支持度阀值的频繁项集。
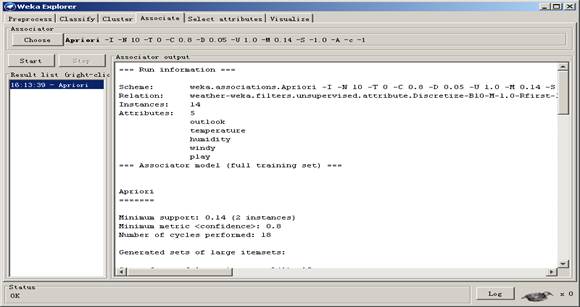
2单击Start执行关联规则的发现,挖掘结果如下图:
分类
决策树分类器部分输出结果
打开weather数集,选择classify选项卡后单击choose,选择tree类型下的J48决策树算法。,在test options中选择use traiing set选项,将数据集作为训练集使用。在more options中选取output predictions选项,看到样本类别的预测情况。在result list区域右键选择Visualize tree,生成决策树。
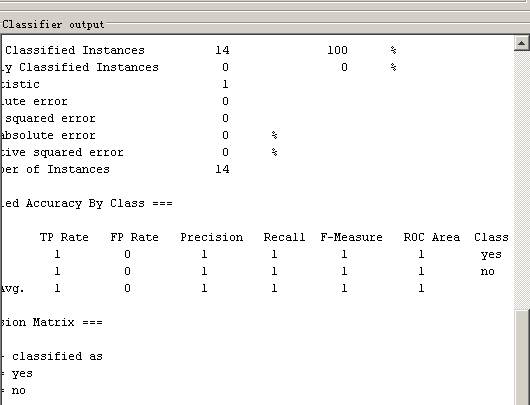
可视化决策树
数据规范化与聚类
数据预处理
通过normalize命令预处理数据。设置scale为1,0。Translation为0.0。
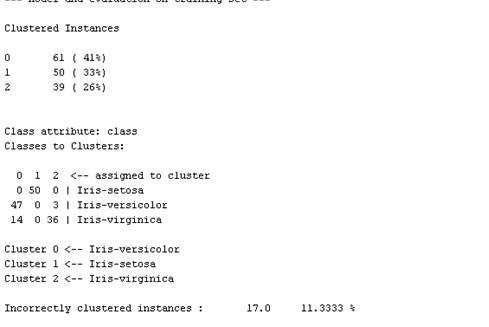
数据集K-均值聚类结果
在cluster选项卡中采取simplekmeans命令。在参数设置框中,将numclustres改为3.执行聚类分析。
数据集DBscan聚类结果
选择DBSCan命令,调整参数epsilon为0.2和minpoints为20。选择执行输出

数据集层次积累结果
选择hierachicalclusterer命令,设置linktype为average。选择输出
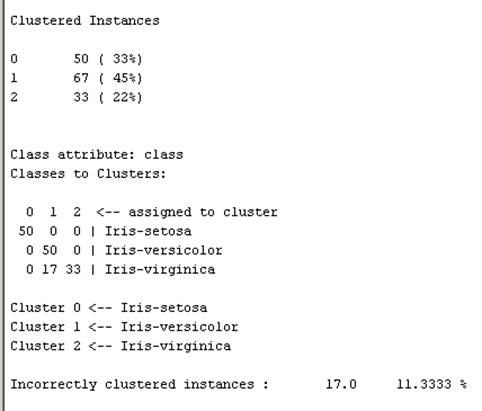
基于密度的聚类方法DBSCAN和层次聚类方法操作方法同上。
-
商务智能实验报告
商务智能实验报告姓名学号班级一实验目的通过使用SPSSClementine数据挖掘平台了解商务智能中决策树和聚类技术的目的过程理解…
-
《商务智能》实验指导书
商务智能实验指导实验1数据仓库的建立一实验目的与任务1了解SQLServer20xx环境掌握建立数据库的基本操作2设计并创建基于维…
- 商务智能 上机实验报告1 运用SPSS完成数据挖掘过程
- 商务智能实验五
-
数据挖掘与商务智能实验
数据挖掘与商务智能实验共两个实验3课时实验共6课时实验一分析历年双十一1111经营数据及产生原因实验要求1简单介绍双十一11112…
-
20xx-20xx年中国商业智能(BI)软件行业市场发展趋势及投资规划分析报告
中金企信北京国际信息咨询有限公司国统调查报告网20xx20xx年中国商业智能BI软件行业市场发展趋势及投资规划分析报告第一章中国商…