Linux课程设计报告
内核模块编程
一、 相关原理介绍分析
1.1内核模块编程简介
Linux操作系统的内核是单一体系结构(Monolithic kernel)的,也就是说,Linux内核是一个单独的非常大的程序。这种体系结构导致了Linux内核的可扩展性和可维护性比较差,为了弥补单一内核的缺陷,Linux采用了一种全新的机制——模块(Module)编程[1]。模块具有十分突出的优点:模块本身不被编译入内核映像,这控制了内核的大小;模块一旦被加载,它就和内核中的其它部分完全一样。Linux采用了内核模块编程之后,编写设备驱动和修改系统内核变得易于实现。因为用户可以根据需要,在不需要对内核进行重新编译的情况下,内核模块可以动态的载入内核或从内核移出改变内核,极大缩短了驱动编写和内核开发的时间。
1.2 Linux内核模块程序结构
一个Linux内核模块主要由如下几个部分组成:
(1) 模块加载函数
通过insmod或modprobe命令加载内核模块时,模块的加载函数会自动被内核执行,完成本模块的相关初始化工作。
(2) 模块卸载函数
当通过rmmod命令卸载某模块时,模块的卸载函数会自动被内核执行,完成与模块加载函数相反的功能。
(3) 模块许可证声明
许可证(LICENSE)声明描述内核模块的许可权限,这一部分是必须声明的,如果不声明LICENSE,模块被加载时,将收到内核被污染(module license ‘unspecified’ taints kernel)的警告。在Linux 2.6内核中,可接受的LICENSE有“GPL”、“GPL v2”、“GPL and additional rights”、“Dual BSD/GPL”、“Dual MPL/GPL”和“Proprietary”。大多数情况下,内核模块应遵循GPL兼容许可权。其中最常用的许可是GPL和Dual BSD/GPL。
(4) 其他可选部分
模块参数,模块参数是模块被加载的时候可以被传递给它的值,它本身对应模块内部的全局变量;模块导出符号,内核模块可以导出符号(symbol,对应于函数或变量),这样其它模块可以使用本模块中的变量或函数;模块作者等信息声明。
1.3 内核模块的编译
在Linux 2.6内核中,模块的编译需要配置过的内核源代码;编译过程首先回到内核目录下读取顶层的Makefile文件,然后返回模块源码所在目录,经过编译、链接后生成的内核模块文件的后缀为.ko。故内核模块的编译需要自己写Makefile文件,当在命令行中执行make命令时,将调用Makefile文件。
二、 设计实现
2.1 内核线程查看
设计一个模块,该模块功能是列出系统中所有内核线程的程序名、PID号和进程状态。
该内核模块的功能类似于命令ps,只不过该模块专查看内核线程信息。首先在文件开始声明一下模块的许可证,即在文件中加入:
MODULE_LICENSE("GPL");
根据内核模块编程的模式,一个内核模块应该至少包含两个函数。一个初始化函数 ,还有一个退出(干一些收尾清理的工作)的函数,当内核模块被rmmod卸载时被执行。从内核版本2.3.13开始,可以为初始化和结束函数起任意的名字。 在该模块内。两个函数分别命名为:static int kernel_thread_init(void)和static void kernel_thread_exit(void)。调用宏module_init()和module_exit()去注册初始化和退出这两个函数,即:
module_init(kernel_thread_init);
module_exit(kernel_thread_exit);
到此内核模块基本框架基本完成。
为了获取到所有的内核线程,可以使用宏for_each_process()。在内核中有内核线程组长链表,每个线程组长通过task_struc结构的tasks成员加入该链表中。利用for_each_process()可以访问到链表中的每一个进程。具体实现如下:
struct task_struct *p;
for_each_process(p)
{
//相关函数及操作
}
对遍历到的每一个线程,读取它的线程号、线程名称以及线程状态并输出。当线程状态为0时输出runnale,为-1时输出unrunnable,为其他时则输出stopped。
在这里输出函数并不能使用printf,printf是用户空间的输出函数,内核空间使用的是printk,因为内核没有链接标准的C 函数库。而实际上printk和printf的功能类似,printk是在内核中运行的向控制台输出显示的函数。printk日志输出的级别一共有8个,由高到低分别为:KERN_EMERG"<0>"、KERN_ALERT"<1>"、KERN_CRIT"<2>"、KERN_ERR"<3>"、KERN_WARNING"<4>"、KERN_NOTICE"<5>"、KERN_INFO"<6>"、KERN_DEBUG"<7>",默认采用的级别是 DEFAULT_ MESSAGE_LOGLEVEL(这个默认级别一般为<4>,即与KERN_WARNING在一个级别上)。
2.2 带参模块的实现
设计一个带参数的模块,参数为进程的PID号,功能是列出进程的家族信息,包括父进程、兄弟进程和子进程的程序名、PID号。
该模块的基本框架和上一个模块类似,声明模块许可证,注册初始化和结束函数。不同之处是在该模块中涉及到了模块参数。在Linux操作系统内核中提供了一种模块带参数的机制,是模块的编写者可以在加载模块的时候提供一下信息,这些参数对于模块来说都是一个全局变量。定义一个模块参数可通过module_param()实现:
module_param(name,type,perm);
参数name是用户可见的参数名,也是模块中存放模块参数的变量名。参数type代表参数的类型,它可以是byte、short、int、long等类型。最后一个参数perm制定了模块在sysfs文件系统下对应的文件权限,可以使八进制的,也可以是S_Ifoo的定义形式,如S_RUGO|S_IWUSR等。
在该模块中,定义一个进程的PID作为参数,以实现任意进程家族信息的查询,默认进程号为1,即在不添加参数情况下查看进程号为1的进程家族信息,具体实现如下:
static int pid=1;
module_param(pid,int,0644);
为找到指定PID的进程,可以使用for_each_process(p)遍历内核所有进程,查找进程号为PID的进程。找到具体进程后,获取进程的名称。接下来判断进程的父进程是否存在,若存在,在输出父进程信息:
if(p->real_parent==NULL)
{
printk("No Parent\n");
}
else
{
printk("Parent : %d %s\n",p->real_parent->pid,p->real_parent->comm);
}
下一步就是该搜索线程号为PID线程的兄弟进程及子进程。在Linux中采用多个链表确保有效查找系统里的进程,双向链表list_head内核中广泛的使用。因为list_head一般嵌入到啮合数据结构中,为了便于访问链表中的数据,内核提供了一系列的宏来实现链表的常规操作[2]。在这里使用list_for_each()和list_entry()来实现兄弟进程和子进程的查找。
在上一步中得到了要查找的进程,可以由此进程得到他父进程的所有子进程组成的链表p->real_parent->children和此进程子进程的链表p->children。定义一个list_head结构体用于list_entry()中:
struct list_head *pp;
宏list_for_each(pp,&p->real_parent->children)遍历p->real_parent->children链表,每次pp指向一个对象成员,而宏list_entry(pp,struct task_struct,sibling);进一步得到该对象的指针。具体实现兄弟进程和子进程遍历如下:
struct task_struct *p,*psibling;
list_for_each(pp,&p->real_parent->children)
{
psibling=list_entry(pp,struct task_struct,sibling);
printk("sibling %d %s \n",psibling->pid,psibling->comm);
}
list_for_each(pp,&p->children)
{
psibling=list_entry(pp,struct task_struct,sibling);
printk("children %d %s \n",psibling->pid,psibling->comm);
}
上述过程将输出得到的兄弟进程和子进程的pid号和进程名称。
2.3 Makefile文件的编写
Make工具最主要也是最基本的功能就是通过makefile文件来描述源程序之间的相互关系并自动维护编译工作。而makefile 文件需要按照某种语法进行编写,文件中需要说明如何编译各个源文件并连接生成可执行文件,并要求定义源文件之间的依赖关系。makefile 文件是许多编译器--包括 Windows NT 下的编译器--维护编译信息的常用方法,只是在集成开发环境中,用户通过友好的界面修改 makefile 文件而已。在Linux内核模块编程中,Makefile文件模版都类似,具体结构如下:
ifneq ($(KERNELRELEASE),)
obj-m :=目标文件.o
else
KDIR :=/lib/modules/$(shell uname -r)/build
PWD :=$(shell pwd)
default:
$(MAKE) -C $(KDIR) M=$(PWD) modules
clean:
$(MAKE) -C $(KDIR) M=$(PWD) clean
endif
KERNELRELEASE是在内核源码的顶层Makefile中定义的一个变量,在第一次读取执行此Makefile时,KERNELRELEASE没有被定义,所以make将读取执行else之后的内容。如果make的目标是clean,直接执行clean操作,然后结束。当make的目标为all时,-C $(KDIR) 指明跳转到内核源码目录下读取那里的Makefile;M=$(PWD)表明然后返回到当前目录继续读入、执行当前的Makefile。当从内核源码目录返回时,KERNELRELEASE已被被定义,此时第一行的ifneq成功,make将继续读取else之前的内容。ifneq的内容为kbuild语法的语句,指明模块源码中各文件的依赖关系,以及要生成的目标模块名。
三、 测试总结
3.1内核线程查看测试
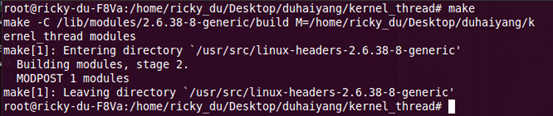
(1) 切换到内核模块所在路径kernel_threads,在命令行中输入make,得到如下结果:
(2) 输入ls 列出当前目录文件,可以看已生成kernel_threads.ko文件

(3) 用命令insmod kernel_threads.ko载入模块,并用lsmod查看模块是否已载入,由下图结果看以看到内核已经被载入。

(4) 此时在控制台无法看到内核模块输出的信息,可以用dmesg查看内核输出信息,可以看到内核已经将搜索到的内核线程信息输出。
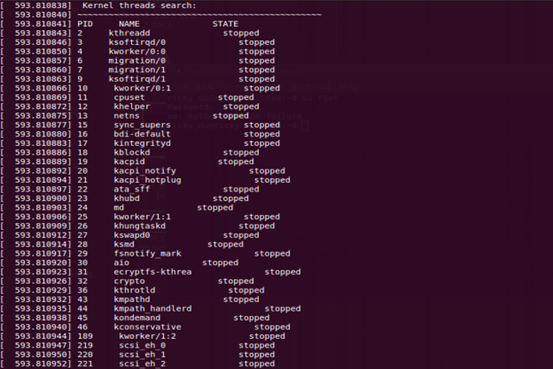
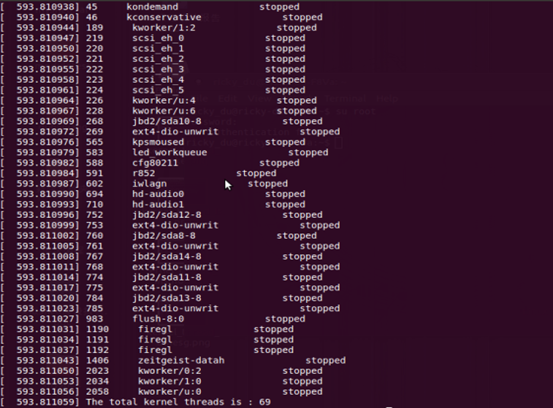
(5) 最后用命令rmmod kernel_threads.ko将已加载的内核卸载
3.2 带参模块的实现测试
(1) 切换到内核模块所在路径thread_pid,在命令行中输入make,得到如下结果:

(2) 输入ls 列出当前目录文件,可以看已生成thread_pid.ko文件

(3) 用命令insmod thread_pid.ko载入模块,并用lsmod查看模块是否已载入,由下图结果看以看到内核已经被载入。

(4) 此时在控制台无法看到内核模块输出的信息,可以用dmesg查看内核输出信息,可以看到内核已经将搜索到的内核线程信息输出。
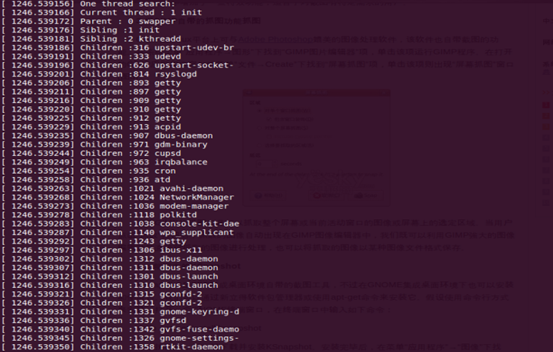
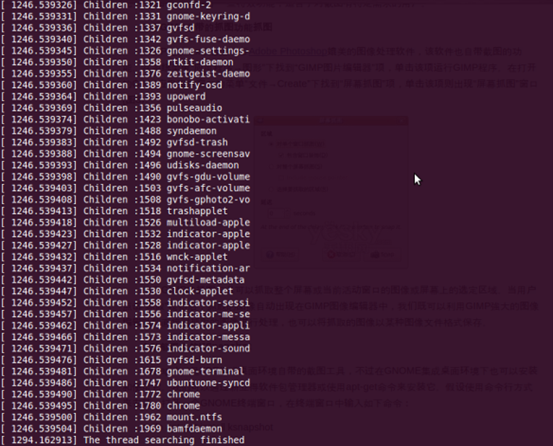
(5) 最后用命令rmmod thread_pid.ko将已加载的内核卸载
3.3 总结
Linux模块是在内核空间运行的程序,实际上是一种目标对象文件,没有链接,不能独立运行,但是可以装载到系统中作为内核的一部分运行,从而可以动态扩充内核的功能。Linux提供了内核模块这种功能强大的扩展方式,它不仅弥补了单内核的一些不足,而且对性能没有影响。通过内核模块机制,可以方便的进行内核开发和驱动开发,而事实上Linux中大多数驱动和文件系统都是已内核模块方式实现的。在内核模块机制下,可以随时在需要的情况下加载新的内核模块,而不需要重新编译内核和引导系统。
当内核被加载到系统中时,他就成为内核源代码的一部分,与其他内核代码地位完全相同。模块自身并不是独立的进程,它可以认为就是核心态运行。同样,既然内核模块和内核其他部分地位一样,这就导致在开发式必须谨慎,因为可能一个小错误就会导致整个系统崩溃。深刻理解Linux内核模块编程,利用好Linux内核模块的优势,无论是进行Linux学习还是内核模块开发都是十分有益的。
【参考文献】
1. 邱铁,于玉龙,徐子川. Linux应用与开发典型实例精讲. 北京:清华大学出版社,2010.5
2. 罗宇,陈燕晖,文艳军 等. Linux曹所系统实验教程. 北京:电子工业出版社,2009.2
3. Linux操作系统及网络资料
第二篇:Linux课程设计报告
Linux课程设计报告
班级:_____网络二班_________
学号:_____20094527_________
姓名:_______陈晨___________
2012 年 06 月 03 日
一、设计目标
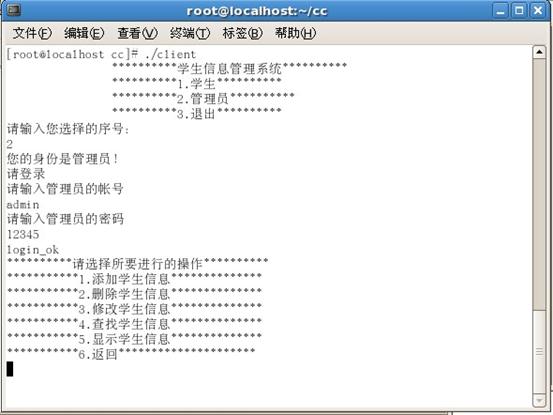
.管理员端:1.基本信息录入2.删除信息3.查找信息4.修改信息5.信息排序
学生端:1.查看信息2.修改信息
二、原理分析及实现过程
Socket通信原理:
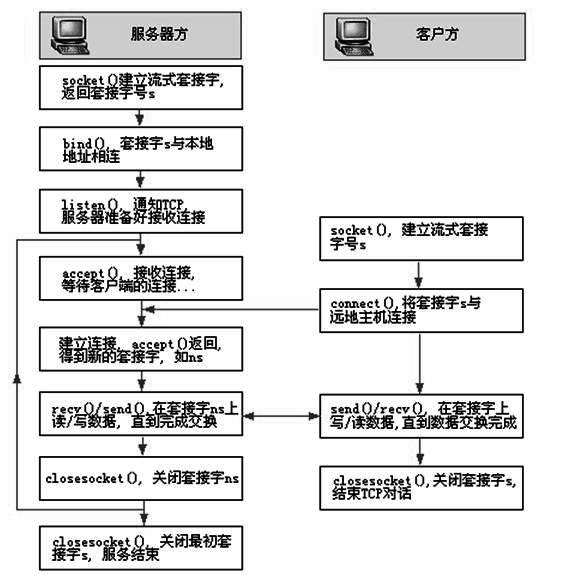
操作系统的进程是一个具有独立功能的程序关于某个数据集合的一次运行活动。不同的进程运行在各自不同的内存空间中,进程之间的信息传递不可能通过变量或其它数据结构直接进行,只能通过进程间通信来完成。本机进程之间通信可以通过管道、命名管道、信号等实现通信,网间进程通信就要通过Socket进行通信。
网间进程通信时通过端口号来唯一标识主机的进程。端口号被分为三类,一类是0~1023范围内的端口,被称为熟知端口,这些端口号已被分配给了因特网上的著名应用程序,第二类端口被称为登记端口,范围是1024~49151,为没有熟知端口号的应用程序使用的。第三类是客户端口号或短暂端口号,数值为49152~65535,留给客户进程选择暂时使用。
网络应用进程间通信普遍采用客户/服务器交互模式,该模式通常简记为C/S模式。在该模式中,通信双方中发起通信的一方被称为客户端,被动接受通信请求的一方被称为服务器。服务器方必须先启动,并时刻监听是否有客户端的请求到达。服务器通过多线程技术实现一对多通信。
本系统是基于TCP/IP协议栈使用C语言来实现进程间的通信。
进程通信过程:
服务器端:
1.先用socket函数来建立一个套接字,用这个套接字完成通信的监听。
2.用bind函数来绑定一个端口号和IP地址。
3.调用listen函数,使服务器的这个端口和IP处于监听状态,等待客户机的连接。
4.用accept函数来接受远程计算机的连接,建立起与客户机之间的通信。
主要代码解析:
#define PORT 4000 //定义端口号为4000,使用宏定义方便以后的修改
int main(int argc, char **argv){
{
int sockfd = -1, ret = -1;
struct sockaddr_in sockaddr;
if((sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0){//使用socket()建立套接字,并返回套接字号
perror("create socket failed");
return -1;
}
memset(&sockaddr, 0, sizeof(sockaddr));
sockaddr.sin_family = AF_INET; //地址信息
sockaddr.sin_port = htons((uint16_t)PORT);
sockaddr.sin_addr.s_addr = INADDR_ANY;
if((ret = bind(sockfd, (const struct sockaddr *)&sockaddr, //套接字和本地地址绑定
sizeof(sockaddr))) < 0){
perror("bind failed");
return -1;
}
if(listen(sockfd, MAX_UNRESOLVE_LINK_NUMBER) < 0){//通知服务器准备接受连接
perror("listen failed");
return -1;
}
clntfd = accept(sockfd, (struct sockaddr *)&clntaddr, &len);//接受连接,创建子进程,用于处理客户端的请求
}
客户端:
1.用socket函数建立一个套接字,设定远程IP和端口。
2.调用connect函数连接远程计算机指定的端口。
3.建立连接以后,客户机用send函数通过socket发送数据。也可以用recv函数从socket读取服务器发送来的数据。服务器同样也可以用recv函数和send函数来收发数据。
主要代码解析:
#define PORT 4000
int main(){
int sockfd = -1, ret = -1;
struct sockaddr_in clntaddr;
sockfd = socket(AF_INET, SOCK_STREAM, 0); //创建套接字
if(sockfd < 0){
perror("create failed");
return -1;
}
memset(&clntaddr, 0, sizeof(clntaddr));
clntaddr.sin_family = AF_INET; //地址信息
clntaddr.sin_port = htons((uint16_t)PORT);
inet_pton(AF_INET, "127.0.0.1", &clntaddr.sin_addr.s_addr);
ret = connect(sockfd, (const struct sockaddr *)&clntaddr, //将套接字与服务器端进行连接
sizeof(clntaddr));
if(ret < 0){
perror("connect failed");
}
write(sockfd, &msg, sizeof(msg));//向服务器发送信息
memset(buf, 0, sizeof(buf));
read(sockfd, buf, sizeof(buf));//接受服务器端的信息
}
功能实现的过程:
整体功能框架图
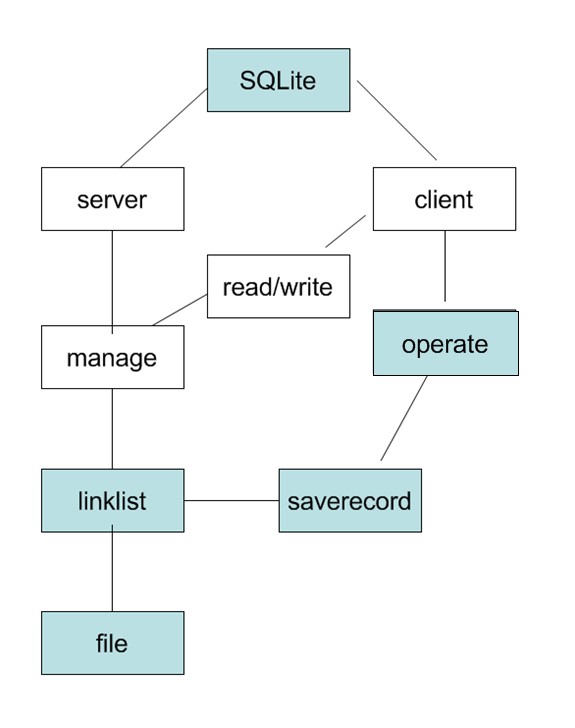
蓝色部分为未实现
Client 网络通信的客户端,分别定义了不同用户的不同菜单,在这没有实现operiont,采用直接像服务器传递客户端的请求。
Server 管理端,实现管理者的功能及网络通信的服务器端
Manage 定义了实现学生成绩管理系统的一系列函数,在这由于一开始时没有设计file和linklist的功能,以后会增加linklis和file,file实现对文本文件中的信息的读取和写入,linklist用于实现读取的信息形成链表,已经对链表进行操作。
Makefile 定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,makefile就像一个shell脚本一样。
CC:=gcc
CPP:=g++
SOBJ=server.o manage.o
COBJ=client.o
TARGET=server client
FLAG = -02
server:$(SOBJ)
$(CC) $^ -o $@ $(FLAG)
client:$(COBJ)
$(CC) $^ -o $@ $(FLAG)
%.o:%.c
$(CC) $^ -o $@ -c $(FLAG)
%.o:%.cpp
$(CPP) $^ -o $@ -c $(FLAG)
clean:
rm *.o -fr //删除所有的.o文件
三、测试与总结(结果如何)
客户端连接服务器端,连接成功后进入主菜单界面
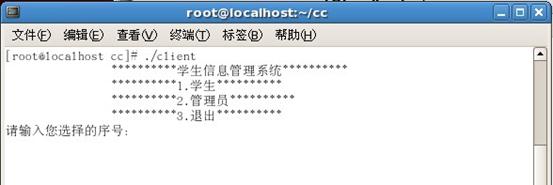
学生菜单界面
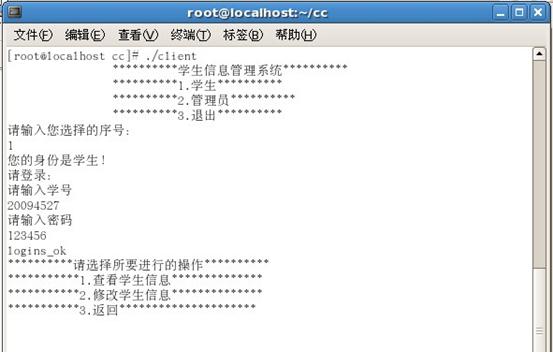
管理员菜单
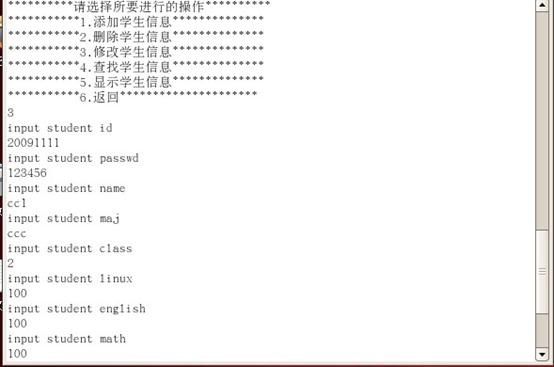
添加学生信息

修改学生信息
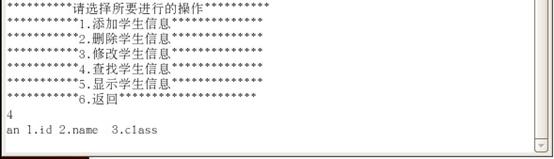
删除学生信息

查询学生信息
遇到的问题:
我们以前就学习过网络编程,这次课程设计,老师又教会我们一些新的东西,像是makefile,多线程等。系统中最主要的问题还是怎么实现服务器端和客户端的通信。一开始的时候实现了简单的通信,但是当实现服务器和客户端的多次通信时,我便在这里出现了问题,后来发现时while(1)放错了位置,调整顺序后变能实现服务器和客户端的连续通信。
遇见最多的问题便是乱码,后来发现是读取文本时用的是char型变量,在字符串末尾没有添加'\0'。
总结:
以前做过多次学生成绩管理系统,每次都会有新的收获。我们课上所学习的东西总是侧重于理论,很多时候做系统时,会遇到很多的bug,这个时候我们就要思路清晰,找出自己的错误。
以前对于文件的读写,我一直掌握的不是很好,通过这次课程设计,使我对文件的读取有了较好的掌握。
在这次课程设计中,系统产生了很多错误,我也遇到很多不懂得知识, 但通过看书上网查找资料,这些困难也一一克服了,让我真正体验了通过不断的努力获得成功的喜悦。虽然整个系统还有一些不完善的地方,但通过这次的课程设计我还是收获了很多,不仅锻炼了自己动手操作的能力,更是培养了我们的自学能力以及与同学合作和向别人学习的基本素养。通过老师对知识的讲解,我也体会到自己所学的知识和以后在工作中应具备的知识还差很多。在今后的学习中,我会更加注重对实践能力的培养。
-
linux课程设计
Linux课程设计姓名:**学号:**学院:信息科学与工程学院班级:网络一班题目:Linux环境下服务器配置与实现20**年12月…
-
Linux课程设计报告
内核模块编程一相关原理介绍分析11内核模块编程简介Linux操作系统的内核是单一体系结构Monolithickernel的也就是说…
-
Linux课程设计报告书
Linux操作系统与程序设计课程设计A报告书姓名学号班级专业指导老师提交日期20xx年06月14日1实验项目目的Linux操作系统…
-
重庆大学linux课程设计报告
重庆大学课程设计报告课程设计题目学院专业班级年级姓名学号月日成绩指导教师重庆大学教务处制课程设计指导教师评定成绩表张浩20xx53…
-
linux课程设计报告
《Linux操作系统》课程设计报告题目:Linux对进程和线程的管理机制研究所在院系:软件学院完成学生:**计算机科学与技术指导教…
-
linux课程实验报告ww - 副本 (6)
sadfawerfreeewwweee实验内容21安装Apache软件22配置www服务器23建立个人web站点24建立虚拟主机2…
-
linux课程实验报告ww - 副本 (2)
eeeasfasdfaswwweee实验内容21安装Apache软件22配置www服务器23建立个人web站点24建立虚拟主机25…
- 网络操作系统课程实验报告6-Linux网络参数的配置
-
Linux课程设计报告 编写proc文件系统相关的内核模块
Linux课程设计报告学院信息学院专业班级08级网络二班姓名学号实验目的1通过课程设计对操作系统基本原理进行更深入的认识以Linu…
-
linux课程设计报告
《Linux操作系统》课程设计报告题目:Linux对进程和线程的管理机制研究所在院系:软件学院完成学生:**计算机科学与技术指导教…
-
Linux课程设计
河南大学软件学院河南大学软件学院Linux课程设计方案二零一一年六月1河南大学软件学院1课程设计参加人员与时间11参加人员10级网…