信息编码实验报告
信息论与编码技术实验报告
实 验 题 目 香浓编码
学生专业班级 信息与计算科学 1001
学生姓名(学号)
指 导 教 师
完 成 时 间 20##年5月18日
20## 年 5 月 18 日
实验一 香农编码的实验报告
一、实验目的
1. 了解香农编码的基本原理及其特点;
2. 熟悉掌握香农编码的方法和步骤;
3. 掌握C语言或者Matlab编写香农编码的程序。
二、实验要求
对于给定的信源的概率分布,按照香农编码的方法进行计算机实现.
三、实验原理
给定某个信源符号的概率分布,通过以下的步骤进行香农编码
1.信源符号按概率从大到小排列
2. 对信源符号求累加概率,表达式: Gi=Gi-1+p(xi)
3. 求自信息量,确定码字长度。自信息量I(xi)=-log(p(xi));码字长度取大于等于自信息量的最小整数。
4. 将累加概率用二进制表示,并取小数点后码字的长度的码 。
四、实验内容
离散无记忆信源符号S的概率分布:

对离散无记忆信源分布S进行香农编码
1.画出程序设计的流程图,
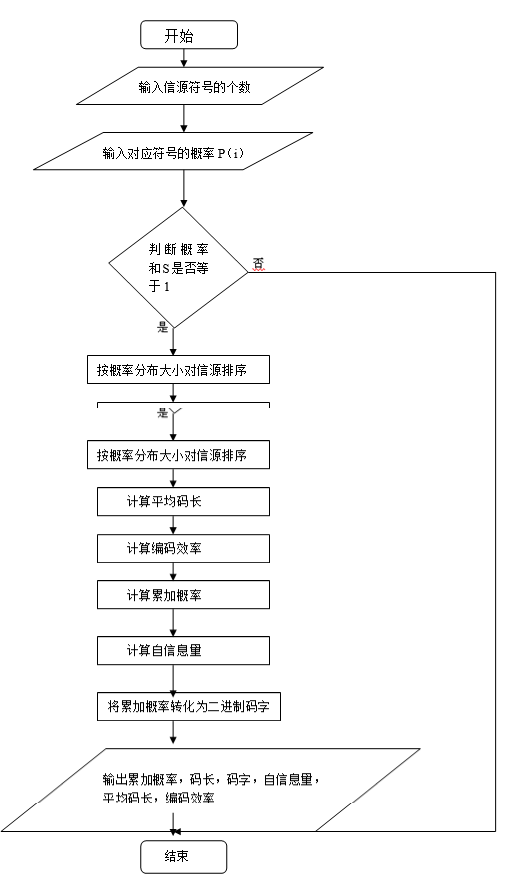
2.写出程序代码,
N=input('N='); %输入信源符号的个数
s=0;
l=0;
H=0;
for i=1:N
p(i)=input('p='); %输入信源符号概率分布矢量,p(i)<1
s=s+p(i)
H=H+(-p(i)*log2(p(i)));
I(i)=-log2(p(i)); %计算信源信息熵
end
if abs(s-1)>0,
error('不符合概率分布')
end
for i=1:N-1
for j=i+1:N
if p(i)
m=p(j);
p(j)=p(i);
p(i)=m;
end
end
end %按概率分布大小对信源排序
for i=1:N
a=-log2(p(i));
if mod(a,1)==0
w=a;
else
w=fix(a+1);
end %计算各信源符号的码长
l=l+p(i)*w; %计算平均码长
end
l=l;
n=H/l; %计算编码效率
P(1)=0
for i=2:N
P(i)=0;
for j=1:i-1
P(i)=P(i)+p(j);
end
end %计算累加概率
for i=1:N
for j=1:w
W(i,j)=fix(P(i)*2);
P(i)=P(i)*2-fix(P(i)*2);
end
end %将累加概率转化为L(i)位二进制码字
disp(W) %显示码字
disp(l) %显示平均码长
disp(n) %显示编码效率
disp(I) %显示自信息量
3.写出在调试过程中出现的问题 ,
问题1:自信量程序不会编写
问题2:累加概率时注意P(1)=0
问题3:程序运行时要依次输入各个符号概率
4.对实验的结果进行分析
由程序运行结果,得
2.34 2.41 2.48 2.56 2.74 3.34 6.66
所以我们得到每个信源符号的自信息量为
I(s1)=2.34 I(s2)=2.41 I(s3)=2.48 I(s4)=2.56 I(s5)=2.74 I(s6)=3.34 I(s7)=6.66
根据公式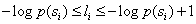 ,我们得到每个信源符号的码长为
,我们得到每个信源符号的码长为
l1=3 l2=3 l3=3 l4=3 l5=3 l6=4 l7=7
由程序运行结果,
0 0 0 0 0 0 0
0 0 1 1 0 0 0
0 1 1 0 0 0 0
1 0 0 1 0 0 0
1 0 1 1 0 0 0
1 1 1 0 0 0 0
1 1 1 1 1 1 0
我们得到每个信源符号的为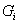 对应的二进制数为:
对应的二进制数为:
G1=0.0000000 G2=0.0011000 G3=0.0110000 G4=0.1001000 G5=0.1011000 G6=0.1110000 G7=0.1111110
所以我们得到每个信源符号的码字为:
S1=000 s2=001 s3=011 s4=100 s5=101 s6=1110 s7=1111110
平均码长为:3.14
编码效率为:0.831
五、实验结论与心得
此次实验让我认识和熟悉了及步骤,对MATLAB软件也有更加深刻的掌握,会用它求某个符号信源的香农编码程序算法,对我的实验能力有所提高。
Huffman编码软件实现实验报告
一、实验目的
1. 进一步熟悉Huffman编码过程;
2. 掌握Matlab程序的设计和调试技术。
二、实验要求
1. 输入:信源符号个数r、信源的概率分布P;
2. 输出:每个信源符号对应的Huffman编码的码字,编码效率。
三、实验原理:
1.二进制Huffman编码的基本原理
设信源s={ }其中对应的概率分布为P(
}其中对应的概率分布为P( )={
)={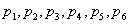 }则其编码步骤如下:
}则其编码步骤如下:
(1) 将q个信源符号按概率递减的方式排列。
(2) 用0、1码符号分别表示概率最小的两个信源符号,并将这两个概率最小的信源符号合并成一个新的符号,从而的得到的只含q-1个符号的新信源,称为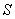 信源的缩减信源
信源的缩减信源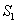
(3) 将缩减信源中的符号仍按概率大小以递减次序排列,重复步骤(2)
(4) 重复(1)(2)(3)三步骤,直至缩减信源只剩下两个符号为止,将这最后两个符号分别用0、1码字表示。
(5)从最后一级缩减信源开始,向前返回,得出各信源符号所对应的码符号序列,即为对应信源符号的码字。
2.二进制Huffman编码程序设计的原理(编码步骤)
(1)程序的输入:
以一维数组的形式输入要进行Huffman编码的信源符号的概率,在运行该程序前,显示文字提示信息,提示所要输入的概率矢量;然后对输入的概率矢量进行合法性判断,原则为:如果概率矢量中存在小于0的项,则输入不合法,提示重新输入;如果概率矢量的求和大于1,则输入也不合法,提示重新输入。
(2)Huffman编码具体实现原理:
<1>在输入的概率矩阵p正确的前提条件下,对p进行排序,并用矩阵L记录p排序之前各元素的顺序,然后将排序后的概率数组p的前两项,即概率最小的两个数加和,得到新的一组概率序列,重复以上过程,最后得到一个记录概率加和过程的矩阵p以及每次排序之前概率顺序的矩阵a。
<2>新生成一个n-1行n列,并且每个元素含有n个字符的空白矩阵,然后进行Huffman编码:将c矩阵的第n-1行的第一和第二个元素分别令为0和1(表示在编码时,根节点之下的概率较小的元素后补0,概率较大的元素后补1,后面的编码都遵守这个原则)然后对n-i-1的第一、二个元素进行编码,首先在矩阵a中第n-i行找到值为1所在的位置,然后在c矩阵中第n-i行中找到对应位置的编码(该编码即为第n-i-1行第一、二个元素的根节点),则矩阵c的第n-i行的第一、二个元素的n-1的字符为以上求得的编码值,根据之前的规则,第一个元素最后补0,第二个元素最后补1,则完成该行的第一二个元素的编码,最后将该行的其他元素按照“矩阵c中第n-i行第j+1列的值等于对应于a矩阵中第n-i+1行中值为j+1的前面一个元素的位置在c矩阵中的编码值”的原则进行赋值,重复以上过程即可完成Huffman编码。
<3>计算信源熵和平均码长,其比值即为编码密码效率。
3.部分伪代码:
(1)节点信息结构体
struct HuffNode
{
int weight;//信源符号的概率
int parent;
int lchild;
int rchild;
};
(2)算法
void Huffman(int weight[], int n, HuffNode hn[], HuffCode hc[])
{
for(i = 0; i != 2*n - 1; ++i) //create Huffman Node,step 1
{}
for(i = 0; i != n-1; ++i) //create Huffman Node, step 2
{
for(j = 0; j != n+i; j++)
{ if(hn[j].weight < min1 && hn[j].parent == 0)
{}
else if(hn[j].weight < min2 && hn[j].parent == 0)
{}else ;
}}
在此逆序存储Huffman编码
int temp[maxlen];
for(i = 0; i != n; ++i)
{
int parent = hn[i].parent;
while(hn[child].parent != 0)
 4. Huffman编码方法的特征
4. Huffman编码方法的特征
(1) 它是一种分组码,各个信源符号都被映射成一组固定次序的马符号。
(2) 它是一种唯一可解的码,任何符号序列只能以一种方式译码。
(3)它是一种即时码:由于代表信源符号的节点都是终端节点,因此其编码不可能是其他终端节点对应的编码的前缀,即Huffman编码所得的码字为即时码。
(4) Huffman码的译码:对接受到的哈弗曼码序列可通过从左到右检查各个符号进行译码。
(5) 哈夫曼编码过程中,当缩减信源的概率分布重新排列时,应使合并得到的概率和尽量处于高的位置,这样可使合并的元素重复编码次数减少,
四、实验内容
对离散无记忆信源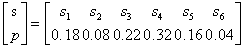 进行Huffman编码。
进行Huffman编码。
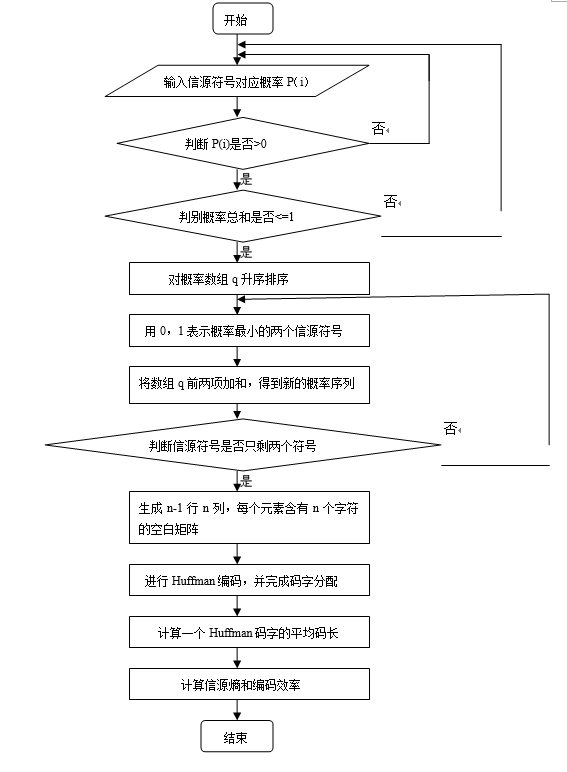
1. 画出Huffman编码的程序流程图(如下)
2. 写出Huffman编码的源程序
p=input('please input a number:')
n=length(p);
for i=1:n
if p(i)<0
fprintf('\n The probabilities in huffman can not less than 0!\n');
p=input('please input a number:') %若输入的概率数组中有小于0的值,则重新输入概率数组
end
end
if abs(sum(p)-1)>0
fprintf('\n The sum of the probabilities in huffman can more than 1!\n');
p=input('please input a number:')
end
q=p;
a=zeros(n-1,n); %生成一个n-1行n列的数组
for i=1:n-1
[q,l]=sort(q)
a(i,:)=[l(1:n-i+1),zeros(1,i-1)]
q=[q(1)+q(2),q(3:n),1];
end
for i=1:n-1
c(i,1:n*n)=blanks(n*n);
end
c(n-1,n)='0';
c(n-1,2*n)='1';
for i=2:n-1
c(n-i,1:n-1)=c(n-i+1,n*(find(a(n-i+1,:)==1))-(n-2):n*(find(a(n-i+1,:)==1)))
c(n-i,n)='0'
c(n-i,n+1:2*n-1)=c(n-i,1:n-1)
c(n-i,2*n)='1'
for j=1:i-1
c(n-i,(j+1)*n+1:(j+2)*n)=c(n-i+1,n*(find(a(n-i+1,:)==j+1)-1)+1:n*find(a(n-i+1,:)==j+1))
end
end
for i=1:n
h(i,1:n)=c(1,n*(find(a(1,:)==i)-1)+1:find(a(1,:)==i)*n)
ll(i)=length(find(abs(h(i,:))~=32))
end
l=sum(p.*ll);
fprintf('\n huffman code:\n');
h
hh=sum(p.*(-log2(p)));
fprintf('\n the huffman effciency:\n');
t=hh/l
3. 运行源程序后,实验过程中的测试结果
p = 0.32 0.22 0.18 0.16 0.08 0.04
q = 0.04 0.08 0.16 0.18 0.22 0.32
q = 0.12 0.16 0.18 0.22 0.32 1.00
q = 0.18 0.22 0.28 0.32 1.00 1.00
q = 0.28 0.32 0.40 1.00 1.00 1.00
q= 0.40 0.60 1.00 1.00 1.00 1.00
ll = 2 4 2 2 3 4
huffman code:
h =
00
1001
01
11
101
1000
the huffman effciency:
t = 0.9801
实验结果分析
信源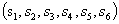 的码字长度分别为 2 4 2 2 3 4 ;
的码字长度分别为 2 4 2 2 3 4 ;
所对应的码字为 11 0110 10 00 010 0111 ;
编码效率为 0.9801。
5、总结实验过程遇到的问题及解决方法
1. 在实验过程中,遇到以下几个问题:
① 信源缩减不知怎么表示;
② 不知如何运用矩阵存储对应概率所对应的位置;
③ 起初忘记对输入的各个概率以及概率之和进行判断,导致的程序的不合理性与不可行性。
2. 解决方法:
通过查找资料和相关书籍,学习类似的哈夫曼编码的程序的编写,使得问题得到解决
六、实验心得
通过此次试验,使得我对Huffman编码的编写原理、基本步骤有了更加深刻的理解,此外,我还学到了有关MATLAB知识的运用,比如:一些特殊语句的应用、矩阵存储知识的应用等等。总之,我认为此次实验还是比较成功的。
-
大三下-信息论实验报告
实验1绘制二进熵函数曲线串联信道容量曲线一实验内容用Excel或Matlab软件制作二进熵函数曲线串联信道容量曲线二实验环境1计算…
-
信息论实验报告
信息论实验实验一哈夫曼编码HuffmanCoding是一种编码方式哈夫曼编码是可变字长编码VLC的一种Huffman于19xx年提…
-
信息论实验报告
信息论与编码上机实验报告实验名称信息论与编码学院计算机与通信工程学院专业班级计算机1004姓名李春醒学号4105034920xx年…
-
信息论实验报告
实验一唯一可译码的判决准则实验目的1进一步熟悉唯一可译码的判决准则2掌握程序字符处理程序的设计和调试技术实验要求已知信源个数r码字…
-
信息论与编码实验报告
中南大学信息论与编码实验报告姓名xxxxx学号xxxxxxxx专业电子信息工程班级电子信息xxxx班指导老师xx实验一关于信源熵的…
-
信息论与编码实验报告
课程名称姓名系专业年级学号指导教师职称实验报告信息论与编码年月日目录实验一信源熵值的计算1实验二Huffman信源编码5实验三Sh…
-
信息论与编码实验报告-Shannon编码
课程名称姓名系专业年级学号指导教师职称实验报告信息论与编码年月日1实验三Shannon编码一实验目的1熟悉离散信源的特点2学习仿真…
-
信息论与编码实验指导书
信息论与编码实验指导书河北工业大学信息工程学院信息论与编码课程组20xx年2月前言当前信息论与编码已经成为电子信息类专业高年级学生…
-
信息论与编码实验2-实验报告
中南大学信息论与编码题目关于编码的实验学生姓名杨家骏指导教师赵颖学院信息科学与工程学院学号0909101123专业班级电子信息10…
-
《信息论与编码》实验讲义
信息论与编码实验讲义学生实验守则1进实验室前必须根据每个实验的预习要求阅读有关资料2按时进入实验室保持安静和整洁独立完成实验3实验…