聚类分析 数据挖掘课程设计
数据挖掘课程设计
一.实验目的
1) 请根据所给的天津各区县经济和教育数据分别做聚类分析,并给出你的结论分析。
2) 聚类分析结果时候与你的直观感受相符合?如果不符,请解释并给出解决方法。
二.实验过程及结果分析
本实验采用聚类分析来对各个区县进行分类,这里我使用SPSS 20来进行聚类分析。
输入各区县经济数据如下图:
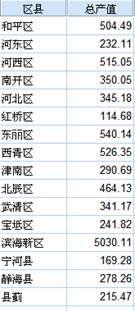
使用SPSS 进行K均值聚类分析,分为六类,得到如下结果:




上图中的第三列(QCL_1)即为分类情况,说明如下:
北辰区分为一类,标记为1;河东区、宝坻区、宁河县、蓟县分为一类,标记为2;南开区、河北区、津南区、武清区、静海县分为一类,标记为3;和平区、河西区、东丽区、西青区分为一类,标记为4;滨海新区为一类,标记为5;红桥区分为一类,标记为6 。
结果分析:
分类结果从整体来看还是比较合理的。滨海新区这一地区产值非常高,毫无疑问是单独的一类;红桥区产值最低,也分为一类,这个与我的直观感受不太相符,作为天津市市内六区之一的红桥区,产值最低,分为一类,我觉得很不可思议,问题可能是数据量不够大,或者说评价指标太少,这里我们只有一个评价指标(总产值),导致结果具有偶然性,适当增加评价指标应该可以增加结果的准确性。
输入各区县教育数据(中学数量和中学在校生以及教师数量)如下图:
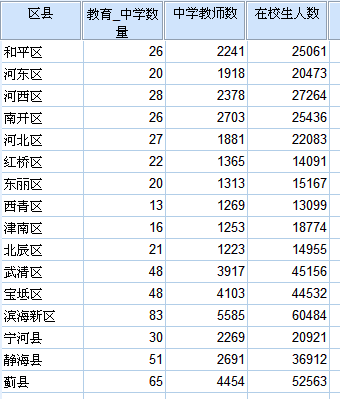
使用SPSS 对这三个变量进行K均值聚类分析,分为六类,得到如下结果:
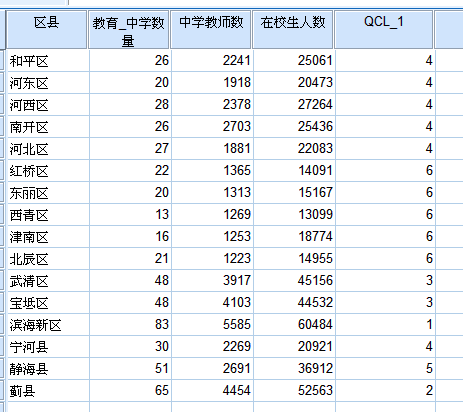



上图中的第五列(QCL_1)即为分类情况,说明如下:
滨海新区分为一类,标记为1;蓟县分为一类,标记为2;武清区、宝坻区分为一类,标记为3;和平区、河东区、河西区、南开区、河北区、宁河县分为一类,标记为4;静海县分为一类,标记为5;红桥区、东丽区、西青区、津南区、北辰区分为一类,标记为6 。
结果分析:
分类结果从整体来看还是比较合理的。滨海新区这一地区教育资源非常雄厚,应该与这个地方的经济总产值有很大的关系。另外,静海县和蓟县,这两个地方的学校数量和学生数量及教师数量都很多,资源也比较雄厚,这与我的直观感受不太相符,他们并不是天津市市内六区。原因可能是这两个地方对教育的重视程度高于其他县市。我们这里的评价指标有三个,还算比较充分。原因应该是区县政府对教育的重视程度不同。不过有个问题,学校数量多并不能表示教育水平高,教师数量多也不一定能代表教师质量高。这里给出的数据只有数量,没有具体的能够反应质量的数据,因此结果存在一定的偏差。
第二篇:数据挖掘CHAPTER8聚类分析
第八章 聚类分析
设想要求对一个数据对象的集合进行分析,但与分类不同的是,它要划分的类是未知的。聚类(clustering)就是将数据对象分组成为多个类或簇(cluster),在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。相异度是基于描述对象的属性值来计算的。距离是经常采用的度量方式。聚类分析源于许多研究领域,包括数据挖掘,统计学,生物学,以及机器学习。
在本章中,大家将了解基于大数据量上进行操作而对聚类方法提出的要求,将学习如何计算由各种属性和不同的类型来表示的对象之间的相异度。还将学习几种聚类技术,它们可以分为如下几类:划分方法(partitioning method),层次方法(hierarchical method),基于密度的方法(density-based method),基于网格的方法(grid-based method),和基于模型的方法(model-based method)。本章最后讨论如何利用聚类方法进行孤立点分析(outlier detection)。
8.1 什么是聚类分析?
将物理或抽象对象的集合分组成为由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。在许多应用中,一个簇中的数据对象可以被作为一个整体来对待。
聚类分析是一种重要的人类行为。早在孩提时代,一个人就通过不断地改进下意识中的聚类模式来学会如何区分猫和狗,或者动物和植物。聚类分析已经广泛地用在许多应用中,包括模式识别,数据分析,图像处理,以及市场研究。通过聚类,一个人能识别密集的和稀疏的区域,因而发现全局的分布模式,以及数据属性之间的有趣的相互关系。
“聚类的典型应用是什么?”在商业上,聚类能帮助市场分析人员从客户基本库中发现不同的客户群,并且用购买模式来刻画不同的客户群的特征。在生物学上,聚类能用于推导植物和动物的分类,对基因进行分类,获得对种群中固有结构的认识。聚类在地球观测数据库中相似地区的确定,汽车保险持有者的分组,及根据房子的类型,价值,和地理位置对一个城市中房屋的分组上也可以发挥作用。聚类也能用于对Web上的文档进行分类,以发现信息。作为一个数据挖掘的功能,聚类分析能作为一个独立的工具来获得数据分布的情况,观察每个簇的特点,集中对特定的某些簇作进一步的分析。此外,聚类分析可以作为其他算法(如分类等)的预处理步骤,这些算法再在生成的簇上进行处理。
数据聚类正在蓬勃发展,有贡献的研究领域包括数据挖掘,统计学,机器学习,空间数据库技术,生物学,以及市场营销。由于数据库中收集了大量的数据,聚类分析已经成为数据挖掘研究领域中一个非常活跃的研究课题。
作为统计学的一个分支,聚类分析已经被广泛地研究了许多年,主要集中在基于距离的聚类分析。基于k-means(k-平均值),k-medoids(k-中心)和其他一些方法的聚类分析工具已经被加入到许多统计分析软件包或系统中,例如S-Plus,SPSS,以及SAS。在机器学习领域,聚类是无指导学习(unsupervised learning)的一个例子。与分类不同,聚类和无指导学习不依赖预先定义的类和训练样本。由于这个原因,聚类是通过观察学习,而不是通过例子学习。在概念聚类(conceptual clustering)中,一组对象只有当它们可以被一个概念描述时才形成一个簇。这不同于基于几何距离来度量相似度的传统聚类。概念聚类由两个部分组成:(1)发现合适的簇;(2)形成对每个簇的描述。在这里,追求较高类内相似度和较低类间相似度的指导原则仍然适用。
在数据挖掘领域,研究工作已经集中在为大数据量数据库的有效且高效的聚类分析寻找适当的方法。活跃的研究主题集中在聚类方法的可伸缩性,方法对聚类复杂形状和类型的数据的有效性,高维聚类分析技术,以及针对大的数据库中混合数值和分类数据的聚类方法。
聚类是一个富有挑战性的研究领域,它的潜在应用提出了各自特殊的要求。数据挖掘对聚类的典型要求如下:
? 可伸缩性:许多聚类算法在小于200个数据对象的小数据集合上工作得很好;但是,
一个大规模数据库可能包含几百万个对象,在这样的大数据集合样本上进行聚类可能会导致有偏的结果。我们需要具有高度可伸缩性的聚类算法。
? 处理不同类型属性的能力:许多算法被设计用来聚类数值类型的数据。但是,应用
可能要求聚类其他类型的数据,如二元类型(binary),分类/标称类型(categorical/nominal),序数型(ordinal)数据,或者这些数据类型的混合。
? 发现任意形状的聚类:许多聚类算法基于欧几里得或者曼哈顿距离度量来决定聚
类。基于这样的距离度量的算法趋向于发现具有相近尺度和密度的球状簇。但是,一个簇可能是任意形状的。提出能发现任意形状簇的算法是很重要的。
? 用于决定输入参数的领域知识最小化:许多聚类算法在聚类分析中要求用户输入一
定的参数,例如希望产生的簇的数目。聚类结果对于输入参数十分敏感。参数通常很难确定,特别是对于包含高维对象的数据集来说。这样不仅加重了用户的负担,也使得聚类的质量难以控制。
? 处理“噪声”数据的能力:绝大多数现实中的数据库都包含了孤立点,缺失,或者
错误的数据。一些聚类算法对于这样的数据敏感,可能导致低质量的聚类结果。 ? 对于输入记录的顺序不敏感:一些聚类算法对于输入数据的顺序是敏感的。例如,
同一个数据集合,当以不同的顺序交给同一个算法时,可能生成差别很大的聚类结果。开发对数据输入顺序不敏感的算法具有重要的意义。
? 高维度(high dimensionality):一个数据库或者数据仓库可能包含若干维或者属性。
许多聚类算法擅长处理低维的数据,可能只涉及两到三维。人类的眼睛在最多三维的情况下能够很好地判断聚类的质量。在高维空间中聚类数据对象是非常有挑战性的,特别是考虑到这样的数据可能分布非常稀疏,而且高度偏斜。
? 基于约束的聚类:现实世界的应用可能需要在各种约束条件下进行聚类。假设你的
工作是在一个城市中为给定数目的自动提款机选择安放位置,为了作出决定,你可以对住宅区进行聚类,同时考虑如城市的河流和公路网,每个地区的客户要求等情况。要找到既满足特定的约束,又具有良好聚类特性的数据分组是一项具有挑战性的任务。
? 可解释性和可用性:用户希望聚类结果是可解释的,可理解的,和可用的。也就是
说,聚类可能需要和特定的语义解释和应用相联系。应用目标如何影响聚类方法的选择也是一个重要的研究课题。
记住这些约束,我们对聚类分析的学习将按如下的步骤进行。首先,学习不同类型的数据,以及它们对聚类方法的影响。接着,给出了一个聚类方法的一般分类。然后我们详细地讨论了各种聚类方法,包括划分方法,层次方法,基于密度的方法,基于网格的方法,以及基于模型的方法。最后我们探讨在高维空间中的聚类和孤立点分析(outlier analysis)。
8.2 聚类分析中的数据类型
在这一节中,我们研究在聚类分析中经常出现的数据类型,以及如何对其进行预处理。假设要聚类的数据集合包含n个数据对象,这些数据对象可能表示人,房子,文档,国家等。许多基于内存的聚类算法选择如下两种有代表性的数据结构:
? 数据矩阵(Data matrix,或称为对象属性结构):它用p个变量(也称为属性)来表现n个对象,例如用年龄,身高,性别,种族等属性来表现对象“人”。这种数据结构是关系表的形式,或者看为n*p维(n个对象*p个属性)的矩阵。
(8.1 p338?)
? 相异度矩阵(dissimilarity matrix,或称为对象-对象结构):存储n个对象两两之间的近似性,表现形式是一个n*n维的矩阵。
(8.2 p338?)
在这里d(i,j)是对象i和对象j之间相异性的量化表示,通常它是一个非负的数值,当对象i 和j越相似,其值越接近0;两个对象越不同,其值越大。既然d(i,j) = d(j,i),而且d(i,i)=0,我们可以得到形如(8.2)的矩阵。关于相异度,我们在这一节中会进行详细探讨。
数据矩阵经常被称为二模(two-mode)矩阵,而相异度矩阵被称为单模(one-mode)矩阵。这是因为前者的行和列代表不同的实体,而后者的行和列代表相同的实体。许多聚类算法以相异度矩阵为基础。如果数据是用数据矩阵的形式表现的,在使用该类算法之前要将其转化为相异度矩阵。
你可能想知道如何来估算相异度。在本节中,我们讨论如何计算用各种类型的属性来描述的对象的相异度,相异度将被用来进行对象的聚类分析。
8.2.1 区间标度(Interval-Scaled)变量
本节讨论区间标度变量和它们的标准化,然后描述距离度量,它通常用于计算用该类变量描述的对象的相异性。距离的度量包括欧几里得距离,曼哈顿距离,以及明考斯基距离。 “什么是区间标度变量?” 区间标度变量是一个线性标度的连续度量。典型的例子包括重量和高度,经度和纬度坐标,以及大气温度。
选用的度量单位将直接影响聚类分析的结果。例如,将高度的度量单位由“米”改为“英尺”,或者将重量的单位由“千克”改为“磅”,可能产生非常不同的聚类结构。一般而言,所用的度量单位越小,变量可能的值域就越大,这样对聚类结果的影响也越大。为了避免对度量单位选择的依赖,数据应当标准化。标准化度量值试图给所有的变量相等的权重。当没有关于数据的先验知识时,这样做是十分有用的。但是,在一些应用中,用户可能想给某些变量较大的权重。例如,当对篮球运动员进行聚类时,我们可能愿意给高度变量较大的权重。 “怎样将一个变量的数据标准化?”为了实现度量值的标准化,一种方法是将原来的度量值转换为无单位的值。给定一个变量f的度量值,可以进行如下的变换:
1.计算平均的绝对偏差(mean absolute deviation)Sf:
Sf = (|x1f-mf|+|x2f-mf|+…+|xnf-mf|)/n (8.3 p339?)
这里的x1f,…,xnf 是f的n个度量值,mf 是f的平均值,即
mf =(|x1f +x2f+…+xnf)/n
2.计算标准化的度量值,或z-score:
zif = (xif – mf) / sf (8.4 p840 ?)
这个平均的绝对偏差sf 比标准的偏差对于孤立点具有 更好的鲁棒性。在计算平均绝对偏差时,度量值与平均值的偏差没有被平方,因此孤立点的影响在一定程度上被减小了。虽然存在更好的对偏差的度量方法,例如中值绝对偏差(median absolute deviation),但采用平均绝对偏差的优点在于孤立点的z-score值不会太小,因此孤立点仍可以被发现。
在特定的应用中, 数据标准化可能有用,也可能没用。因此是否和如何进行标准化的选择被留给了用户。在第三章里数据预处理的规范化技术中也讨论了标准化的方法。
“好的,”现在你可能会问,“我已经对数据进行了标准化处理,我该如何计算对象间的相异度?”在标准化处理后,或者在某些应用中不需要标准化,对象间的相异度(或相似度)是基于对象间的距离来计算的。最常用的距离度量方法是欧几里得距离,它的定义如下:
d(I,j) = (?p340,8.5)
这里的i=(xi1,xi2,…,xip)和 j=(xj1,xj2,…xjp)是两个p维的数据对象。
另一个著名的度量方法是曼哈顿距离,其定义如下:
d(I,j)= |xi1-xj1|+|xi2-xj2|+…+|xip-xjp| (8.6 p340 ?)
上面的两种距离度量方法都满足对距离函数的如下数学要求:
1.d(i,j)≥0:距离是一个非负的数值。
2.d(i,i)=0:一个对象与自身的距离是0。
3.d(i,j)= d(j,i):距离函数具有对称性。
4.d(i,j)≤ d(i,h)+d(h,j):从对象I到对象j的直接距离不会大于途径任何其他对象的距离。
明考斯基距离是欧几里得距离和曼哈顿距离的概化,它的定义如下:
D(I,j)=(|xi1-xj1|q+|xi2-xj2|q+…+|xip-xjp|q)1/q (8.7 p341 ?)
这里的q是一个正整数。当q=1时,它表示曼哈顿距离;当a=2表示欧几里得距离。
如果对每个变量根据其重要性赋予一个权重,加权的欧几里得距离可以计算如下: d(I,j)= w1|xi1-xj1|2+ (?p341,8.8)
8.2.2 二元变量(binary variable)
本小节介绍如何计算用二元变量描述的对象间的相似度。
一个二元变量只有两个状态:0或1,0表示该变量为空,1表示该变量存在。例如,给出一个描述病人的变量smoker,1表示病人抽烟,而0表示病人不抽烟。像处理区间标度变量一样来对待二元变量会误导聚类结果,所以要采用特定的方法来计算其相异度。
“那么,我怎样计算两个二元变量之间的相似度?”一个方法涉及对给定的数据计算相异度矩阵。如果假设所有的二元变量有相同的权重,我们得到一个两行两列的可能性表8.1。在表中,q是对对象i和j值都为1的变量的数目,r是在对象i中值为1,在对象j中值为0的变量的数目,s是在对象i中值为0,在对象j中值为1的变量的数目,t是在对象i和j中值都为0的变量的数目。变量的总数是p,p=q+r+s+t。
表8.1 二元变量的可能性表
对象j
总和
对象I
(? p341)
“对称的二元变量和不对称的二元变量之间的区别是什么?”如果它的两个状态有相同的权重, 那么该二元变量是对称的,也就是两个取值0或1没有优先权。例如,属性“性别”就是这样的一个例子,它有两个值:“女性”和“男性”。基于对称二元变量的相似度称为恒定的相似度,即当一些或者全部二元变量编码改变时,计算结果不会发生变化。对恒定的相似度来说,评价两个对象i和j之间相异度的最著名的系数是简单匹配系数,其定义如下:
d(I,j) = (r+s) / (q+r+s+t) (8.9 p342 ?)
如果两个状态的输出不是同样重要,那么该二元变量是不对称的。例如一个疾病检查的肯定和否定的结果。根据惯例,我们将比较重要的输出结果,通常也是出现几率较小的结果编码为1(例如,HIV阳性),而将另一种结果编码为0(例如HIV阴性)。给定两个不对称的二元变量,两个都取值1的情况(正匹配)被认为比两个都取值0的情况(负匹配)更有意义。因此,这样的二元变量经常被认为好像只有一个状态。基于这样变量的相似度被称为非恒定的相似度。对非恒定的相似度,最著名的评价系数是Jaccard系数,在它的计算中,负匹配的数目被认为是不重要的,因此被忽略。
D(I,j) = (r+s) / (q+r+s) (8.10)
当对称的和非对称的二元变量出现在同一个数据集中,在8.2.4节中描述的混合变量方法可以被应用。
例8.1 二元变量之间的相异度:假设一个病人记录表(表8.2)包含属性name(姓名), gender(性别), fever(发烧), cough(感冒), test-1, test-2, test-3, 和test-4,这里的name是对象标识,gender是对称的二元变量,其余的属性都是非对称的二元变量。
表8.2 大部分为二元属性的关系变量
(p343 ?)
对非对称属性,值Y(yes)和P(positive)被置为1,值N(no或者negative)被置为0。假设对象(病人)之间的距离只基于非对称变量来计算。根据Jaccard系数公式(8.10),三个病人Jack,Mary,和Jim两两之间的相异度如下:
d(jack,mary) = (0+1)/(2+0+1) = 0.33 (8.11 p343)
d(jack,jim) = (1+1)/ (1+1+1) = 0.67 (8.12 p343 ?) d(jim,mary)=(1+2)/(1+1+2) = 0.75 (8.13 p343 ?)
上面的值显示Jim和Mary不可能有相似的疾病,因为他们有着最高的相异度。在这三个病人中,Jack和Mary最可能有类似的疾病。
8.2.3 标称型、序数型和比例标度型变量
本节讨论如何计算用标称(Nominal),序数(Ordinal)和比例标度(Ratio-Scaled)变量描述的对象之间的相异度。
标称变量
标称变量是二元变量的推广,它可以具有多于两个的状态值。例如,map_color是一个标称变量,它可能有五个值:红色 ,黄色,绿色,粉红色,和蓝色。
假设一个标称变量的状态数目是M。这些状态可以用字母,符号,或者一组整数(如1,2,…,M)来表示。要注意这些整数只是用于数据处理,并不代表任何特定的顺序。
“如何计算标称变量所描述的对象之间的相异度?”两个对象i和j之间的相异度可以用简单匹配方法来计算:
d(I,j) = (p-m)/p (8.14 p343)
这里m是匹配的数目,即对i和j取值相同的变量的数目;而 p是全部变量的数目。我们可以通过赋权重来增加m的影响,或者赋给有较多状态的变量的匹配更大的权重。
通过为每个状态创建一个二元变量,可以用二元变量来表示标称变量。对一个有特定状态值的对象,对应该状态值的二元变量值置为1,而其余的二元变量值置为0。例如,为了对标称变量map_color进行编码,对应于上面所列的五种颜色分别创建一个二元变量。如果一个对象是黄色,那么yellow变量被赋值为1,而其余的四个变量被赋值为0。对于这种形式的编码,可以采用在8.2.2节中讨论的方法来计算相异度。
序数型变量
一个离散的序数型变量类似于标称变量,除了序数型变量的M个状态是以有意义的序列排序的。序数型变量对记录那些难以客观度量的主观评价是非常有用的。例如,职业的排列经常按某个顺序,例如助理,副手,正职。一个连续的序数型变量看起来象一个未知刻度的连续数据的集合,也就是说,值的相对顺序是必要的,而其实际的大小则不重要。例如,在某个比赛中的相对排名(例如金牌,银牌,和铜牌)经常比事实的度量值更为必需。将区间标度变量的值域划分为有限个区间,从而将其值离散化,也可以得到序数型变量。一个序数型变量的值可以映射为排序。例如,假设一个变量f有Mf个状态,这些有序的状态定义了一个序列1,…,Mf。
“怎样处理序数型变量?”在计算对象的相异度时,序数型变量的处理与区间标度变量非常类似。假设f是用于描述n个对象的一组序数型变量之一,关于f的相异度计算包括如下步骤:
1.第i个对象的f值为xif,变量f有Mf个有序的状态,对应于序列1,…,Mf。用对应的rif代替xif,rif∈ {1,…,Mf}。
2.既然每个序数型变量可以有不同数目的状态,我们经常必须将每个变量的值域映射到 [0 .0, 1.0]上,以便每个变量都有相同的权重。这一点可以通过用zif代替rif来实现。
Zif = (rif –1) / (Mf-1) (8.15 p344)
3.相异度的计算可以采用8.2.1节所描述的任意一种距离度量方法,采用zif作为第i个对象的f值。
比例标度型变量
比例标度型变量在非线性的刻度取正的度量值,例如指数,近似地遵循如下的公式 (?8.16 p345)
这里的A和B是正的常数。典型的例子包括细菌数目的增长,或者放射性元素的衰变。
“如何计算用比例标度型变量描述的对象之间的相异度?”目前有三种方法:
? 采用与处理区间标度变量同样的方法。但是,这种作法通常不是一个好的选择,因
为刻度可能被扭曲了。
? 对比例标度型变量进行对数变换,例如对象i的f变量的值xif被变换为yif,yif =
log(xif)。变换得到的yif值可以采用在8.2.1节中描述的方法来处理。需要注意的是,对一些比例标度型变量,可以采用log-log或者其他形式的变换,具体的做法取决于定义和应用。
? 将xif看作连续的序数型数据,将其秩作为区间标度的值来对待。
尽管选用哪种方法取决于实际的应用,但后两种方法是比较有效的。
8.2.4 混合类型的变量
在8.2.1到8.2.3节中讨论了计算由同种类型变量描述的对象之间的相异度的方法,变量的类型可能是区间标度变量, 对称二元变量,不对称二元变量,标称变量,序数型变量 或者比例标度型变量。但是在许多真实的数据库中,对象是被混合类型的变量描述的。一般来说,一个数据库可能包含上面列出的全部六种类型。
“那么,我们怎样计算用混合类型变量描述的对象之间的相异度?”一种方法是将变量按类型分组,对每种类型的变量进行单独的聚类分析。如果这些分析得到兼容的结果,这种方法是可行的。但是,在实际的应用中,这种情况是不大可能的。
一个更可取的方法是将所有的变量一起处理,只进行一次聚类分析。一种技术将不同类型的变量组合在单个相异度矩阵中,把所有有意义的变量转换到共同的值域区间[0.0, 1.0]上。
假设数据集包含p个不同类型的变量,对象i和j之间的相异度d(i,j)定义为
d(I,j) = ( ? 8.17 p346)
如果xif或xjf 缺失(即对象i或对象j没有变量f的度量值),或者xif =xjf=0,且变量f是不对称的二元变量,则指示项(?)=0;否则,指示项(?)=1。变量f对i和j之间相异度的计算方式与其具体类型有关:
? 如果f是二元或标称变量:如果xif =xjf,dij(f)(?)=0;否则dij(f)(?)=1。 ? 如果f是区间标度变量:dij(f)(?)=(?),这里的h包含了所有有变量f值的对象。 ? 如果f是序数型或者比例标度型变量:计算秩rif和zif=(?),将zif作为区间标度变量
值对待。
这样,当描述对象的变量是不同类型时,对象之间的相异度也能够进行计算。
8.3 主要聚类方法的分类
目前在文献中存在大量的聚类算法。算法的选择取决于数据的类型, 聚类的目的和应
用。如果聚类分析被用作描述或探查的工具,可以对同样的数据尝试多种算法,以发现数据可能揭示的结果。
大体上,主要的聚类算法可以划分为如下几类:
划分方法(partitioning methods):给定一个n个对象或元组的数据库,一个划分方法构建数据的k个划分,每个划分表示一个聚类,并且k<=n。也就是说,它将数据划分为k个组,同时满足如下的要求:(1)每个组至少包含一个对象;(2)每个对象必须属于且只属于一个组。注意在某些模糊划分技术中第二个要求可以放宽。在参考文献中列出了对于该类技术的参照。
给定k,即要构建的划分的数目,划分方法首先创建一个初始划分。然后采用一种迭代的重定位技术,尝试通过对象在划分间移动来改进划分。一个好的划分的一般准则是:在同一个类中的对象之间的距离尽可能小,而不同类中的对象之间的距离尽可能大。还有许多其他划分质量的评判准则。
为了达到全局最优,基于划分的聚类会要求穷举所有可能的划分。实际上,绝大多数应用采用了以下两个比较流行的启发式方法:(1)k-means算法,在该算法中,每个簇用该簇中对象的平均值来表示。(2)k-medoids算法,在该算法中,每个簇用接近聚类中心的一个对象来表示。这些启发式聚类方法对在中小规模的数据库中发现球状簇很适用。为了对大规模的数据集进行聚类,以及处理复杂形状的聚类,基于划分的方法需要进一步的扩展。8.4节对基于划分的聚类方法进行了深入的研究。
层次的方法(hierarchical methods):层次的方法对给定数据集合进行层次的分解。根据层次的分解如何形成,层次的方法可以被分为凝聚的或分裂的方法。凝聚的方法,也称为自底向上的方法,一开始将每个对象作为单独的一个组,然后继续地合并相近的对象或组,直到所有的组合并为一个(层次的最上层),或者达到一个终止条件。分裂的方法,也称为自顶向下的方法,一开始将所有的对象置于一个簇中。在迭代的每一步中,一个簇被分裂为更小的簇,直到最终每个对象在单独的一个簇中,或者达到一个终止条件。
层次的方法的缺陷在于,一旦一个步骤(合并或分裂)完成,它就不能被撤消。这个严格规定是有用的,由于不用担心组合数目的不同选择,计算代价会较小。但是,该技术的一个主要问题是它不能更正错误的决定。有两种方法可以改进层次聚类的结果:(1)在每层划分中,仔细分析对象间的联接,例如CURE和Chameleon中的做法。(2)综合层次凝聚和迭代的重定位方法。首先用自底向上的层次算法,然后用迭代的重定位来改进结果。例如在BIRCH中的方法。8.5节讨论了层次的聚类方法。
基于密度的方法:绝大多数划分方法基于对象之间的距离进行聚类。这样的方法只能发现球状的簇,而在发现任意形状的簇上遇到了困难。随之提出了基于密度的另一类聚类方法,其主要思想是:只要临近区域的密度(对象或数据点的数目)超过某个阈值,就继续聚类。也就是说,对给定类中的每个数据点,在一个给定范围的区域中必须包含至少某个数目的点。这样的方法可以用来过滤“噪音”数据,发现任意形状的簇。
DBSCAN是一个有代表性的基于密度的方法,它根据一个密度阈值来控制簇的增长。OPTICS是另一个基于密度的方法,它为自动的,交互的聚类分析计算一个聚类顺序。 基于密度的聚类方法将在8.6节中进行详细的讨论。
基于网格的方法(grid-based methods):基于网格的方法把对象空间量化为有限数目的单元,形成了一个网格结构。所有的聚类操作都在这个网格结构(即量化的空间)上进行。这种方
法的主要优点是它的处理速度很快,其处理时间独立于数据对象的数目,只与量化空间中每一维的单元数目有关。
STING是基于网格方法的一个典型例子。CLIQUE和WaveCluster这两种算法既是基于网格的,又是基于密度的。对基于网格方法的详细讨论将在8.7节中进行。
基于模型的方法(model-based methods):基于模型的方法为每个簇假定了一个模型,寻找数据对给定模型的最佳匹配。一个基于模型的算法可能通过构建反映数据点空间分布的密度函数来定位聚类。它也基于标准的统计数字自动决定聚类的数目,考虑“噪音”数据和孤立点,从而产生健壮的聚类方法。基于模型的聚类方法将在8.8节予以讨论。
一些聚类算法集成了多种聚类方法的思想,所以有时将某个给定的算法划分为属于某类聚类方法是很困难的。此外,某些应用可能有特定的聚类标准,要求综合多个聚类技术。 在接下来的章节中,我们将详细讨论上述的五类聚类方法,同时也将介绍综合了多种聚类方法思想的算法。作为与聚类分析密切相关的孤立点分析将在8.9节中讨论。
8.4 划分方法(partitioning methods)
给定一个包含n个数据对象的数据库,以及要生成的簇的数目k,一个划分类的算法将数据对象组织为k个划分(k≤n),其中每个划分代表一个簇。通常会采用一个划分准则(经常称为相似度函数,similarity function),例如距离,以便在同一个簇中的对象是“相似的”,而不同簇中的对象是“相异的”。
算法:k-means。
输入:簇的数目k和包含n个对象的数据库。
输出:k个簇,使平方误差最小。
方法:
(1)任意选择k个对象作为初始的簇中心;
(2)repeat
(3) 根据与每个中心的距离,将每个对象赋给“最近”的簇;
(4) 重新计算每个簇的平均值;
(5)until 不再发生变化
图 8.1 k-means算法
(p349?)
8.4.1 典型的划分方法:k-Means和k-Medoids
最著名也是最常用的划分方法是k-means,k-medoids和它们的变种。
基于质心(centroid)的技术:k-Means方法
k-means算法以k为参数,把n个对象分为k个簇,以使类内具有较高的相似度,而类
间的相似度最低。相似度的计算根据一个簇中对象的平均值(被看作簇的重心)来进行。
“k-means算法是怎样工作的?”k-means算法的处理流程如下。首先,随机地选择k个对象,每个对象初始地代表了一个簇中心。对剩余的每个对象,根据其与各个簇中心的距离,将它赋给最近的簇。然后重新计算每个簇的平均值。这个过程不断重复,直到准则函数收敛。有代表性地,平方误差准则被采用,其定义如下:
(8. 18 p349 ?)
这里的E是数据库中所有对象的平方误差的总和,p是空间中的点,表示给定的数据对象,mi是簇Ci的平均值(p和mi都是多维的)。这个准则试图使生成的结果簇尽可能的紧凑和独立。图8.1给出了K-means过程的概述。
这个算法尝试找出使平方误差函数值最小的k个划分。当结果簇是密集的,而簇与簇之间区别明显时,它的效果较好。对处理大数据集,该算法是相对可伸缩的和高效率的,因为它的复杂度是O(nkt),n是所有对象的数目,k是簇的数目,t是迭代的次数。通常地,k<<n,且t<<n。这个算法经常以局部最优结束。
但是,k-means方法只有在簇的平均值被定义的情况下才能使用。这可能不适用于某些应用,例如涉及有分类属性的数据。要求用户必须事先给出k(要生成的簇的数目)可以算是该方法的一个缺点。K-means方法不适合于发现非凸面形状的簇,或者大小差别很大的簇。而且,它对于“噪音”和孤立点数据是敏感的,少量的该类数据能够对平均值产生极大的影响。
例子8.2 假设有一个分布在空间中的对象集合,如图8.2(a)所示。给定k=3,即用户要求将这些对象聚为三类。根据图8.1中的算法,我们任意选择三个对象作为三个初始的簇中心,簇中心在图中用“+”来标注。根据与簇中心的距离,每个对象被分配给最近的一个簇。这样的分布形成了如图8.2(a)中虚线所描绘的图形。
这样的分组会改变聚类中心,也就是说,每个聚类的平均值会根据类中的对象重新计算。依据这些新的聚类中心,对象被重新分配到各个类中。这样的重新分配形成了图8.2(b)中虚线所描绘的轮廓。
以上的过程重复,产生图8.2(c)的情况。最后,当没有对象的重新分配发生时,处理过程结束。聚类的结果被返回。
图8.2 基于k-means方法的一组对象的聚类(簇中心在图中用“+”来标注)
(p350 ?)
k-means方法有很多变种。它们可能在初始k个平均值的选择,相异度的计算,计算聚类平均值的策略上有所不同。经常会产生较好的聚类结果的一个有趣策略是首先采用层次的自底向上算法决定结果簇的数目,及找到初始的簇,然后用迭代的重定位来改进聚类结果。 k-means方法的一个变体是k-modes方法,它扩展了k-means方法,用模式来代替类的平均值,采用新的相异性度量方法来处理分类性质的数据,采用基于频率的方法来修改聚类的模式。K-means和k-modes方法可以综合起来处理有数值类型和分类类型属性的数据,这就是k-prototypes方法。
EM(Expectation Maximization,期望最大)算法以另一种方式对k-means方法进行了扩展。它不把对象分配给一个确定的簇,而是根据对象与簇之间隶属关系发生的概率来分派对象。换句话说,在簇之间没有严格的界限。因此,新的平均值基于加权的度量值来计算。
“怎样增强k-means算法的可扩展性?”最近提出的一种方法是识别数据的三种区域:可以压缩的区域,必须在主存中的区域,可废弃的区域。如果一个对象与某个簇的隶属关系是确定的,则它是可废弃的,。如果一个对象不是可废弃的,但属于某个较小的子簇,那么它是可压缩的。一个数据结构——聚类特征(clustering feature)用来汇总那些可废弃的或者可压缩的对象。如果一个对象既不是可废弃的,又不是可压缩的,那它就应该被保存在主存中。为了达到可扩展性,这个迭代的算法只包含可压缩的对象和必须在主存中的对象的聚类特征,从而将一个基于二级存储的算法变成了基于主存的算法。
基于有代表性的对象的技术:k-medoids 方法
既然一个有极大值的对象可能相当程度上扭曲数据的分布,k-means算法对于孤立点是敏感的。
大家可能想知道,“如何修改这个算法来消除这种敏感性?”。不采用簇中对象的平均值作为参照点,可以选用簇中位置最中心的对象,即medoid。这样划分方法仍然是基于最小化所有对象与其参照点之间的相异度之和的原则来执行的。这是k-medoids方法的基础。
k-medoids聚类算法的基本策略是:首先为每个簇随意选择选择一个代表对象;剩余的对象根据其与代表对象的距离分配给最近的一个簇。然后反复地用非代表对象来替代代表对象,以改进聚类的质量。聚类结果的质量用一个代价函数来估算,该函数评估了对象与其参照对象之间的平均相异度。为了判定一个非代表对象Orandom 是否是当前一个代表对象Oj的好的替代,对于每一个非代表对象p,下面的四种情况被考虑:
? 第一种情况:p当前隶属于代表对象 Oj。如果Oj被Orandom所代替,且p离OI最近,i≠j,
那么p被重新分配给OI。
? 第二种情况:p当前隶属于代表对象 Oj。如果Oj 被Orandom代替,且p离Orandom最近,那
么p被重新分配给Orandom。
? 第三种情况:p当前隶属于OI ,i≠j。如果Oj被Orandom代替,而p仍然离OI最近,那么
对象的隶属不发生变化。
? 第四种情况:p当前隶属于OI,i≠j。如果Oj被Orandom代替,且p离Orandom最近,那么p
被重新分配给Orandom。
1.重新分配给OI 2. 重新分配给Orandom 3. 不发生变化 4. 重新分配给Orandom 数据对象
簇中心
替代前
替代后
图8.3 k-medoids聚类代价函数的四种情况.(P352 ?)
图8.3描述了上述的四种情况。每当重新分配发生时,square-error所产生的差别对代价函数有影响。因此,如果一个当前的代表对象被非代表对象所代替,代价函数计算square-error值所产生的差别。替换的总代价是所有非代表对象所产生的代价之和。如果总代价是负的,那么实际的square-error将会减小,Oj 可以被Orandom替代。如果总代价是正的,则当前的代表对象是可接受的,在本次迭代中没有变化发生。一个典型的k-medoids算法描述在图8.4中给出。
PAM(Partitioning around Medoids,围绕k-medoids的划分)是最早提出的k-medoids算法之一。它试图对n个对象给出k个划分。最初随机选择k个代表对象后,该算法反复地
试图找出更好的代表对象。所有可能的对象对被分析,每个对中的一个对象被看作是代表对象,而另一个不是。对可能的各种组合,估算聚类结果的质量。一个对象Oj 被可以产生最大square-error值减少的对象代替。在一次迭代中产生的最佳对象的集合成为下次迭代的代表对象。当n和k的值较大时,这样的计算代价相当高。
“哪个方法更健壮:k-means或者k-medoids?”当存在“噪音”和孤立点数据时,k-medoids方法比k-means方法更健壮,这是因为medoid不象平均值那么容易被极端数据影响。但是,k-medoids方法的执行代价比k-means算法高。此外这两种方法都要求用户指定结果簇的数目k。
算法:k-medoids,
输入:结果簇的数目k,包含n个对象的数据库
输出:k个簇,使得所有对象与其最近代表对象的相异度总和最小。
方法:
(1)随机选择k个对象作为初始的代表对象;
(2)repeat
(3) 指派每个剩余的对象给离它最近的代表对象所代表的簇;
(4) 随意地选择一个非代表对象Orandom;
(5) 计算用Orandom代替Oj的总代价S;
(6) 如果S<0,则用Orandom替换Oj,形成新的k个代表对象的集合;
(7)until 不发生变化
--------------------------------------------------------------------- 图8.4 k-medoids算法 (p353 ?)
8.4.2 大规模数据库中的划分方法:从k-medoids到CLARANS “k-medoids算法在大数据集合上的效率如何?”典型的k-medoids算法,如PAM,对小的数据集合非常有效,但对大的数据集合没有良好的可伸缩性。为了处理较大的数据集合,可以采用一个基于样本的方法CLARA(Clustering LARge Applications)。
CLARA的主要思想是:不考虑整个数据集合,选择实际数据的一小部分作为数据的样本。然后用PAM方法从样本中选择代表对象。如果样本是以非常随机的方式选取的,它应当足以代表原来的数据集合。从中选出的代表对象很可能与从整个数据集合中选出的非常近似。CLARA抽取数据集合的多个样本,对每个样本应用PAM算法,返回最好的聚类结果作为输出。如同人们希望的,CLARA能处理比PAM更大的数据集合。每步迭代的复杂度现在是O(ks2 +k(n-k)),s是样本的大小,k是簇的数目,而n是所有对象的总数。CLARA的有效性取决于样本的大小。要注意PAM在给定的数据集合中寻找最佳的k 个代表对象,而CLARA在抽取的样本中寻找最佳的k个代表对象。如果任何取样得到的代表对象不属于最佳的代表对象,CLARA不能得到最佳聚类结果。例如,如果对象Oi 是最佳的k个代表对象之一,但它在取样的时候没有被选择,那CLARA将永远不能找到最佳聚类。这是为了效率而做的折中。如果样本发生偏斜,基于样本的一个好的聚类不一定代表了整个数据集合的一个好的聚类。
“我们怎样改进CLARA的聚类质量和可伸缩性?”作为k-medoids类的算法,CLARANS(Clustering Large Application based upon RANdomized Search)将采样技术和PAM结合起来。但是,与CLARA不同,CLARANS没有在任一给定的时间局限于任一样本。
CLARA在搜索的每个阶段有一个固定的样本,而CLARANS在搜索的每一步带一定随机性地抽取一个样本。聚类过程可以被描述为对一个图的搜索,图中的每个节点是一个潜在的解,也就是说,k个代表对象的集合。在替换了一个代表对象后得到的聚类结果被称为当前聚类结果的邻居。随机尝试的邻居的数目被用户定义的一个参数加以限制。如果一个更好的邻居被发现,也就是说它有更小的square-error值,CLARANS移到该邻居节点,处理过程重新开始。否则当前的聚类达到了一个局部最优。如果找到了一个局部最优,CLARANS从随机选择的节点开始寻找新的局部最优。
实验显示CLARANS比PAM和CLARA更有效。通过采用一个轮廓系数——对象的一个属性,定义该对象在多大程度上真的属于某个簇,能够发现最“自然的”的结果簇数目。CLARANS能够探测孤立点。但是CLARANS算法的计算复杂度大约是O(n2 ),n是对象的数目。而且,它的聚类质量取决于所用的抽样方法。通过采用空间数据结构,例如R*-tree,及一些调节技术,CLARANS的性能可以得到进一步的提高。
8.5 层次方法
一个层次的聚类方法将数据对象组成一棵聚类的树。根据层次分解是自底向上,还是自顶向下形成,层次的聚类方法可以进一步分为凝聚(agglomerative)和分裂(divisive)层次聚类。一个纯粹的层次聚类方法的聚类质量受限于如下特点:一旦一个合并或分裂被执行,就不能修正。最近的研究集中于凝聚层次聚类和迭代重定位方法的集成。
凝聚的
分裂的
图8.5 在对象集合{a,b,c,d,e}上的凝聚和分裂层次聚类 (p355 ?)
8.5.1 凝聚的和分裂的层次聚类
一般来说,有两种类型的层次聚类方法:
? 凝聚的层次聚类:这种自底向上的策略首先将每个对象作为一个簇,然后合并这些
原子簇为越来越大的簇,直到所有的对象都在一个簇中,或者某个终结条件被满足。绝大多数层次聚类方法属于这一类,它们只是在簇间相似度的定义上有所不同。 ? 分裂的层次聚类:这种自顶向下的策略与凝聚的层次聚类不同,它首先将所有对象
置于一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终结条件,例如达到了某个希望的簇数目,或者两个最近的簇之间的距离超过了某个阈值。
例8.3 图8.5描述了一个凝聚的层次聚类算法AGENES(Agglomerative NESting)和一个分
裂的层次聚类算法DIANA(Divisive ANAlysis)在一个包含五个对象的数据集合上的处理过程。最初,AGNES将每个对象作为一个簇,然后这些类根据某些准则被一步步地合并。例如,如果簇C1中的一个对象和簇C2 中的一个对象之间的距离是所有属于不同簇的对象间距离中最小的,C1和C2 可能被合并。这是一个single-link方法,以便每个聚类可以被簇中所有对象代表,簇间的相似度由两个簇中距离最近
的数据点间的相似度来确定。聚类的合并过程反复进行直到所有的对象最终合并形成一个簇。
在DIANA方法的处理过程中,所有的对象初始都放在一个簇中。根据一些原则,这个簇被分裂,簇的分裂过程反复进行直到最终每个新的簇只包含一个对象。
在凝聚或者分裂的层次聚类方法中,用户能定义希望得到的簇数目作为一个结束条件。 四个广泛采用的簇间距离度量方法如下:
最小距离:dmin(Ci,Cj) = min p∈Ci,p’∈Cj |p-p’|
最大距离:dmax(Ci,Cj) = max p∈Ci,p’∈Cj |p-p’|
平均值的距离:dmean(Ci,Cj) = | mI - mj |
平均距离:davg(Ci,Cj) =∑ p∈Ci ∑p’∈Cj |p-p’| ? ? ? ?
这里|p-p’|是两个对象p和p’之间的距离,mI是簇Ci 的平均值,而nI是簇Cj中对象的数目。
“层次聚类的困难之处在那里?”层次聚类方法尽管简单,但经常会遇到合并或分裂点选择的困难。这样的决定是非常关键的,因为一旦一组对象被合并或者分裂,下一步的处理将在新生成的簇上进行。已做的处理不能被撤消,聚类之间也不能交换对象。如果在某一步没有很好地选择合并或分裂的决定,可能会导致低质量的聚类结果。而且,这种聚类方法不具有很好的可伸缩性,因为合并或分裂的决定需要检查和估算大量的对象或簇。
改进层次方法的聚类质量的一个有希望的方向是将层次聚类和其他的聚类技术进行集成,形成多阶段聚类。在下面的章节中介绍了一些这类的方法。第一个方法称为BIRCH,它首先用树结构对对象进行层次划分,然后采用其他的聚类算法对聚类结果进行求精。第二个方法称为CURE,它采用固定数目的代表对象来表示每个簇,然后依据一个定义的分数向着聚类中心对它们进行收缩。 第三个方法ROCK基于簇间的互联性进行合并。第四个方法Chameleon在层次聚类中发现动态模型。
根
第一级
图 8。6 CF树结构
8.5.2 BIRCH:利用层次方法的平衡迭代约减和聚类(Balanced Iterative Reducing and Clustering Using Hierarchies)
BITCH是一个综合的层次聚类方法。它引入了两个概念:聚类特征和聚类特征树(CF tree),它们用于概括聚类描述。这些结构辅助聚类方法在大型数据库中取得高的速度和伸缩性。BIRCH方法对增量或动态聚类非常有效。让我们详细讨论一下上面提到的结构。一个聚类特征(CF)是一个三元组,对对象子类的信息给出了总结性描述。假设某个子类中有N个d维的点或对象{oI},则该子类的CF定义如下
CF = (N,LS,SS), (8.19 p357 ?)
这里N是子类中点的数目,LS(?)是N个点的线性和(即?),SS是数据点的平方和(即?)。
聚类特征是对给定子类的统计描述:从统计学的观点来看,子类的第零个,第一个,及第二个要素。它记录了计算聚类和有效利用存储的关键数值,因为它概括了关于子类的信息,而不是存储所有的对象。
一个CF 树是高度平衡的树,它为层次聚类存储了聚类特征。图8.6给出了一个例子。根据定义,树中的非叶节点有后代或“孩子”,它们存储了其孩子的CF的总和,即概括了关于其孩子的聚类信息。一个CF树有两个参数:分支因子B,和阈值T。分支因子定义了每个非叶节点的最大孩子数目,而阈值参数给出了存储在树的叶子节点中的子类的最大直径。这两个参数影响了结果树的大小。
“BIRCH算法是怎样工作的?”它包括两个阶段:
阶段一:BIRCH扫描数据库,建立一个初始存放于内存的CF树,它可以被看作数据的多层压缩,试图保留数据内在的聚类结构。
阶段二:BIRCH采用某个聚类算法对CF树的叶节点进行聚类。
在阶段一,随着对象被插入,CF树被动态地构造。所以这个方法支持增量聚类。一个对象被插入到最近的叶子条目(子类)。如果在插入后存储在叶子节点中的子类的直径大于阈值,那么该叶子节点及可能有其他节点被分裂。新对象插入后,关于该对象的信息向着树根传递。通过修改阈值,CF树的大小可以改变。如果存储CF树需要的内存大小大于主存的大小,可以定义一个较小的阈值,并重建CF树。重建过程从旧树的叶子节点建造一个新树。这样,重建树的过程不需要重读所有的对象。这类似于B+树构建中的插入和节点分裂。因此,为了建树,只需读一次数据。采用一些启发式规则和方法,通过额外的数据扫描来处理孤立点和改进CF树的质量。CF树建好后,可以在阶段二被采用任何聚类算法,例如典型的划分方法,。
BIRCH试图利用可用的资源来生成最好的聚类结果。给定有限的主存,一个重要的考虑是最小的I/O时间。BIRCH采用了一种多阶段聚类技术:数据集合的单遍扫描产生了一个基本的聚类,一或多遍的额外扫描可以进一步地改进聚类质量。这个算法的计算复杂性是O(n),这里的n是对象的数目。
“BIRCH的有效性如何?”实验显示该算法具有对对象数目的线性伸缩性,及较好的聚类质量。但是,既然CF树的每个节点由于大小限制只能包含有限数目的条目,一个CF树节点并不总是对应于用户所认为的一个自然聚类。而且,如果簇不是球形的,BIRCH不能很好地工作,因为它用了半径或直径的概念来控制聚类的边界。
8.5.3 CURE:利用代表点聚类(clustering using representative)
绝大多数聚类算法或者擅长处理球形和相似大小的聚类,或者在存在孤立点时变得比较脆弱。 CURE解决了偏好球形和相似大小的问题,在处理孤立点上也更加健壮。CURE采用了一种新的层次聚类算法,该算法选择了位于基于质心和基于代表对象方法之间的中间策略。它不用单个质心或对象来代表一个簇,而是选择了数据空间中固定数目的具有代表性的点。一个簇的代表点通过如下方式产生:首先选择簇中分散的对象,然后根据一个特定的分数或收缩因子向簇中心“收缩”或移动它们。在算法的每一步,有最近距离的代表点对(每个点来自于一个不同的簇)的两个簇被合并。
每个簇有多于一个的代表点使得CURE可以适应非球形的几何形状。簇的收缩或凝聚可以有助于控制孤立点的影响。因此,CURE对孤立点的处理更加健壮,而且能够识别非球形和大小变化较大的簇。对于大规模数据库,它也具有良好的伸缩性,而且没有牺牲聚类质量。
针对大数据库,CURE采用了随机取样和划分两种方法的组合:一个随机样本首先被划分,每个划分被部分聚类。这些结果簇然后被聚类产生希望的结果。
下面的步骤描述了CURE算法的核心:
1.从源数据对象中抽取一个随机样本S。
2.将样本S划分为一组分块。
3.对每个划分局部地聚类。
4.通过随机取样剔除孤立点。如果一个簇增长得太慢,就去掉它。
5.对局部的簇进行聚类。落在每个新形成的簇中的代表点根据用户定义的一个收缩因子a收缩或向簇中心移动。这些点描述和捕捉到了簇的形状。
6.用相应的簇标签来标记数据。
让我们来看一个例子。
例8.4 假设有一组点(或对象)位于一个长方形的区域。图8.7(a)描述了这些对象的一个
随机样本。这些对象被分为两个部分,每个部分分别基于最小平均距离进行局部聚类。如图8.7(b)所示,所形成的局部聚类结果被虚线标出。每个簇代表用“+”标记。这些局部聚类结果被进一步的聚类,产生图8.7(c)中实线所描出的两个簇。每个新的簇通过朝簇中心移动其代表点进行收缩或凝聚。这些代表点描述了每个簇的形状。这样,排除了孤立点后,初始的对象被划分为两个簇,如图8.7(d)所示。
(p360 ?)
图8.7 用CURE对一组对象进行聚类。(a)对象的一个随机样本。(b)对象被划分和局部聚类。每个簇的代表点被“+”标记。(c)局部聚类被进一步地聚类。对每个新簇,代表点向簇中心收缩或凝聚。(d)最后的结果簇是非球形的。
在孤立点存在的情况下,CURE可以产生高质量的聚类,支持复杂形状和不同大小的聚类。该算法要求整个数据库的一遍扫描。给定n个对象,CURE的复杂度是O(n)。“CURE对用户给出的参数的敏感度如何,例如样本大小,希望的聚类的数目,及收缩因子α?”敏感度分析显示,尽管一些参数变化可能不影响聚类质量,一般来说,参数设置确实对聚类结果有显著的影响。
CURE不处理分类属性。ROCK是一个可选的凝聚的层次聚类算法,适用于分类属性。它通过将集合的互连性与用户定义的互连性模型相比较来度量两个簇的相似度。两个簇C1和C2的互连性被定义为两个簇间交叉邻接(cross link)的数目,link(pi,pj)是两个点pI和pj共同的邻居的数目。换句话说,簇间相似度是基于来自不同簇而有相同邻居的点的数目。
ROCK首先根据相似度阈值和共同邻居的概念从给定的数据相似度矩阵构建一个稀疏的图,然后在这个稀疏图上运行一个层次聚类算法。
8.5.4 Chameleon(变色龙): 一个利用动态模型的层次聚类算法
chameleon是一个在层次聚类中采用动态模型的聚类算法。在它的聚类过程中,如果两个簇间的互连性和近似度与簇内部对象间的互连性和近似度高度相关,则合并这两个簇。基于动态模型的合并过程有利于自然的和相似的聚类的发现,而且只要定义了相似度函数就可应用于所有类型的数据。
Chameleon的产生是基于对两个层次聚类算法CURE和ROCK的缺点的观察。CURE及其相关的方案忽略了关于两个不同簇中的对象的互连性的信息,而ROCK及其相关的方
案强调对象间互连性,却忽略了关于对象间近似度的信息。
“chameleon怎样工作的呢?”图8.8中描述了chameleon的主要思想。Chameleon首先通过一个图划分算法将数据对象聚类为大量相对较小的子类,然后用一个凝聚的层次聚类算法通过反复地合并子类来找到真正的结果簇。它既考虑了互连性,又考虑了簇间的近似度,特别是簇内部的特征,来确定最相似的子类。这样它不依赖于一个静态的,用户提供的模型,能够自动地适应被合并的簇的内部特征。
k个最近的邻居图 最终的簇
数据集 构造稀疏图 划分图 合并图
图8.8 chameleon:基于K个最近的邻居和动态建模的层次聚类。见[KHK99] (p361 ?)
下面我们详细讨论chameleon算法。如图8.8所示,chameleon基于通常采用的k个最近的邻居图方法来描述它的对象。K个最近的邻居图中的每个点代表一个数据对象,如果一个对象是另一个对象的k个最类似的对象之一,在这两个点(对象)之间存在一条边。K个最近邻居图Gk动态地捕捉邻域的概念:一个对象的领域半径被对象所在区域的密度所决定。在一个密集区域,邻域的定义范围相对狭窄;在一个稀疏区域,它的定义范围相对较宽。与采用基于密度的全局邻域方法相比,如DBSCAN(在8.6节中描述),该方法能产生更自然的聚类结果。而且,区域的密度作为边的权重被记录下来。就是说,一个密集区域的边趋向于比稀疏区域的边有更大的权重。
Chameleon通过两个簇的相对互连性RI(Ci,Cj)和相对近似性RC(Ci,Cj)来决定簇间的相似度:
? 如果两个簇Ci和Cj之间的相对互连性RI(Ci,Cj)已经针对两个簇的内部互连性进
行标准化,则称为Ci和Cj之间的绝对互联性,即,
( 8.20 p362 ?)
这里EC{Ci,Cj}是包含Ci和Cj的簇必须切断的边的数目,以便该簇分裂为Ci和Cj。类似地,ECCi(或ECCj)是它的最小等分线的大小(即将图划分为两个大致相等的部分需要切断的边的加权总和)
? 如果两个簇Ci和Cj之间的相对封闭性已经针Ci和Cj的内部封闭性进行标准化,则
RC(Ci,Cj)称为Ci和Cj之间的绝对封闭性。它的定义如下:
(8.21 p362 ?)
这里(?)是连接Ci和Cj节点的边的平均权重,(?)是Ci(或Cj)的最小等分线的边的平均权重。
可以看出Chameleon跟CURE和DBSCAN相比,在发现高质量的任意形状的聚类结果方面有更强的能力。但是在最坏的情况下,高维数据的处理代价可能对n个对象需要O(n2)的时间。
8.6 基于密度的方法
为了发现任意形状的聚类结果,提出了基于密度的聚类方法。这类方法将簇看作是数据空间中由低密度区域分割开的高密度对象区域。
? 8.6.1 DBSCAN:一个基于密度和高密度的连结区域的聚类算法 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个基于密度的聚类算法。该算法将具有足够高密度的区域划分为簇,并可以在带有“噪音”的空间数据库中发现任意形状的聚类。它定义簇为密度相连的点的最大集合。
基于密度的聚类的基本想法涉及一些新的定义。我们先给出这些定义,然后用一个例子加以说明。
? 一个给定对象周围半径?内的区域称为该对象的? –邻域。
? 如果一个对象的?–邻域至少包含最小数目MinPts的对象,那么该对象称为核心对象。 ? 给定一个对象集合D,如果p是在q的?–邻域内,而q是一个核心对象,我们说对象p从对象q出发是直接密度可达的,。
? 如果存在一个对象链p1,p2,…,pn,p1=q, pn=p,对pi∈ D,1≤i≤n,pi+1是从pi关于?和 MinPts直接密度可达的,则对象p是从对象q关于?和MinPts密度可达的(density-reachable)。
? 如果对象集合D中存在一个对象o,使得对象p和q是从o关于?和MinPts密度可达的,那么对象p和q是关于?和MinPts密度相连的(density-connected)。
密度可达性是直接密度可达性的传递闭包,这种关系是非对称的。只有核心对象之间是相互密度可达的。不过,密度相连性是一个对称的关系。
图8.9 在基于密度的聚类中密度可达和密度相连。见[EKSX96] (p364 ?)
例8.5 考虑图8.9,给定?为圆的半径,MinPts=3。基于上述的定义:
? 在被标记的点中,M,P,O,及R是核心对象,因为它们在?-领域内包含了至少三个对象。
? Q是从M直接密度可达的。M是从P直接密度可达的,反之亦然。
? 因为Q是从M直接密度可达的,M是从P直接密度可达的,所以Q是从P间接密度可达的,但是,P并不是从Q密度可达的,因为Q不是一个核心对象。类似地,R和S是从O密度可达的,而O是从R密度可达的。
? O,R和S都是密度互连的。
一个基于密度的簇是基于密度可达性的最大的密度相连对象的集合。不包含在任何簇中的对象被认为是“噪音”。
“DBSCAN如何进行聚类?”DBSCAN通过检查数据库中每个点的?-邻域来寻找聚类。如果一个点p的?-邻域包含多于MinPts个点,则创建一个以p作为核心对象的新簇。DBSCAN然后反复地寻找从这些核心对象直接密度可达的对象,这个过程可能涉及几个密度可达簇的
合并。当没有新的点可以被添加到任何簇时,该过程结束。
如果采用空间索引,DBSCAN的计算复杂度是O(nlogn),这里n是数据库中对象的数目。
2否则,计算复杂度是O(n)。该算法对用户定义的参数是敏感的,DBSCAN在下面的章节中
会进一步的讨论,同时将与另一个基于密度的聚类算法OPTICS进行比较。
8.6.2 OPTICS:通过对象排序识别聚类结构(Ordering Points to Identify the Clustering Structure)
尽管DBSCAN(8.6.1节中描述的基于密度的聚类算法)能根据给定输入参数?和MinPts对对象进行聚类,它仍然将选择能产生可接受的聚类结果的参数值的责任留给了用户。事实上,这也是许多其他聚类算法存在的问题。对于真实的,高维的数据集合而言,参数的设置通常是依靠经验,难以确定。绝大多数算法对参数值是非常敏感的:设置的细微不同可能导致差别很大的聚类结果。而且,真实的高维数据集合经常分布不均,全局密度参数不能刻画其内在的聚类结构。
为了解决这个难题,提出了OPTICS聚类分析方法。OPTICS没有显式地产生一个数据集合簇,它为自动和交互的聚类分析计算一个簇次序(cluster ordering )。这个次序代表了数据的基于密度的聚类结构。它包含了信息,等同于从一个广域的参数设置所获得的基于密度的聚类。
考察DBSCAN,我们可以看到,对一个恒定的MinPts值,关于高密度的(即较小的?值)的聚类结果被完全包含在根据较低密度所获得的密度相连的集合中。记住参数?是距离,它是邻域的半径。因此,为了生成基于密度聚类的集合或次序,我们可以扩展DBSCAN算法来同时处理一组距离参数值。为了同时构建不同的聚类,对象应当以特定的顺序来处理。这个次序选择根据最小的?值密度可达的对象,以便高密度的聚类能被首先完成。基于这个想法,每个对象需要存储两个值——核心距离(core-distance)和可达距离(reachability-distance):
? 一个对象p的核心距离是使得p成为核心对象的最小?。如果p不是核心对象,p的核
心距离没有定义。
一个对象q关于另一个对象p的可达距离是p的核心距离和p与q的欧几里得距离之间?
的较大值。如果p不是一个核心对象,p和q之间的可达距离没有定义。
p的核心距离 可达距离(
可达距离(
图8.10 OPTICS术语。见[ABK99] (p366 ?)
例8.6 图8.10描述了核心距离和可达距离的概念。假设?=6,MinPts=5。p的核心距离是
p与第四个最近的数据对象之间的距离?’。q1关于p的可达距离是p的核心距离(即?’=3mm),因为它比从p到q1的欧几里得距离要大。q2关于p的可达距离是从p到q2的欧几里得距离,它大于p的核心距离。
“这些值怎样使用?”OPTICS算法创建了数据库中对象的一个次序,额外存储了每个对
象的核心距离和一个适当的可达距离。一种算法被提出基于OPTICS产生的次序信息来抽取聚类。这样的信息对于关于小于在生成该次序中采用的距离?的任何距离?’的基于密度的聚类都是足够的。
一个数据集合的聚类次序可以被图形化地描述,以有助于它的理解。例如,图8.11是一个简单的二维数据集合的可达性图表,它给出了数据如何被聚类的概述。也有在多个层次上观察高维数据的聚类结构的方法被研究。
可达距离
无定义
对象的簇次序
图8.11 OPTICS中的簇次序。图来自[ABK99]。
由于OPTICS算法与DBSCAN在结构上的等价性,OPTICS算法具有和DBSCAN相同的时间复杂度,即当空间索引被采用,复杂度为O(nlongn)。
8.6.3 DENCLUE:基于密度分布函数的聚类
DENCLUE(DENsity-based CLUstEring)是一个基于一组密度分布函数的聚类算法。该算法主要基于下面的想法:(1)每个数据点的影响可以用一个数学函数来形式化地模拟,它描述了一个数据点在邻域内的影响,被称为影响函数(influence function);(2)数据空间的整体密度可以被模拟为所有数据点的影响函数的总和;(3)然后聚类可以通过确定密度吸引点(density attractor)来得到,这里的密度吸引点是全局密度函数的局部最大值。
假设x和y是d维特征空间Fd中的对象。数据对象y对x的影响函数是一个函数fyB:Fd → R+0,它是根据一个基本的影响函数 fB来定义的:
fyB(x)= fB(x,y) (8.22 p367 ?)
原则上,影响函数可以是一个任意的函数,它由某个领域内的两个对象之间的距离来决定。距离函数d(x,y)应当是自反的和对称的,例如欧几里得距离函数(8.2.1节)。它用来计算一个方波影响函数(square wave influence function):
fSquare(x,y)= (8.23 p367 ?)
或者一个高斯(Gaussian)影响函数:
(8.24 p367 ?)
密度 密度
数据集 方波 高斯
图8.12 对一个2-D数据集的可能的密度函数(?p368)
在一个对象x(x∈Fd)上的密度函数被定义为所有数据点的影响函数的总和。给定n个对象,D={x1,…,xn}? Fd,在x上的密度函数定义如下:
(8.25 p368 ?)
例如,根据高斯影响函数得出的密度函数是
(8.26 p368 ?)
根据密度函数,我们能够定义该函数的梯度和密度吸引点(全局密度函数的局部最大值)。一个点x是被一个密度吸引点 x*密度吸引的,如果存在一组点x0,x1,…,xk,x0=x,xk=x*,对0<I<k,xi-1的梯度是在xI的方向上。对一个连续的,可微的影响函数,一个用梯度指导的爬山算法能用来计算一组数据点的密度吸引点。图8.12显示了一个二维数据集,高斯密度函数和密度吸引点。
基于这些概念,中心定义的簇(center-defined cluster)和任意形状的簇(arbitrary-shape cluster)能够被形式化地定义。一个根据密度吸引点 x*中心定义的聚类是一个被x*密度吸引的子集C,在x*的密度函数不小于一个阈值ξ;否则(即如果它的密度函数值小于ξ),它被认为是孤立点。一个任意形状的簇是一组子集C,每一个是密度吸引的,有不小于阈值ξ的密度函数值,从每个区域到另一个都存在一条路径P,该路径上每个点的密度函数值都不小于ξ。中心定义和任意形状的簇的例子在图8.13中给出。
图8.13 中心定义的簇(顶部)和任意形状的簇(底部)的例子。见[HK98]. (p369 ?)
“DENCLUE与其它聚类算法相比有什么主要的优点?”主要有如下一些:(1)它有一个坚实的数学基础,概括了其他的聚类方法,包括基于划分的,层次的,及基于位置的方法。
(2)对于有大量“噪音”的数据集合,它有良好的聚类特性。(3)对高维数据集合的任意形状的聚类,它给出了简洁的数学描述。(4)它使用了网格单元,只保存了关于实际包含数据点的网格单元的信息。它以一个基于树的存取结构来管理这些单元,因此比一些有影响的算法(如DBSCAN)速度要快。但是,这个方法要求对密度参数σ和噪音阈值ξ进行仔细的选择,因为这样的参数选择可能显著地影响聚类结果的质量。
8.7 基于网格的方法
基于网格的聚类方法采用一个多分辨率的网格数据结构。它将空间量化为有限数目的单元,这些单元形成了网格结构,所有的聚类操作都在网格上进行。这种方法的主要优点是处理速度快,其处理时间独立于数据对象的数目,仅依赖于量化空间中每一维上的单元数目。
基于网格方法的有代表性的例子包括STING,它利用了存储在网格单元中的统计信息;WaveCluster,它用一种小波转换方法来聚类对象;CLIQUE,它是在高维数据空间中基于网格和密度的聚类方法。
8.7.1 STING:统计信息网格(STatistical INformation Grid)
STING是一个基于网格的多分辨率聚类技术,它将空间区域划分为矩形单元。针对不同级别的分辨率,通常存在多个级别的矩形单元,这些单元形成了一个层次结构:高层的每个单元被划分为多个低一层的单元。关于每个网格单元属性的统计信息(例如平均值,最大值,和最小值)被预先计算和存储。这些统计变量可以方便下面描述的查询处理使用。
图8.14显示了STING聚类的一个层次结构。高层单元的统计变量可以很容易地从低层单元的变量计算得到。这些统计变量包括:属性无关的变量count;属性相关的变量m(平均值),s(标准偏差),min(最小值),max(最大值),以及该单元中属性值遵循的分布类型distribution,例如正态的,均衡的,指数的,或无(如果分布未知)。当数据被装载进数
据库,最底层单元的变量count,m,s,min,和max直接进行计算。如果分布的类型事先知道,distribution的值可以由用户指定,也可以通过假设检验来获得。一个高层单元的分布类型可以基于它对应的低层单元多数的分布类型,用一个阈值过滤过程来计算。如果低层单元的分布彼此不同,阈值检验失败,高层单元的分布类型被置为none。
“这些统计信息怎样用于回答查询?”统计变量的使用可以以自顶向下的基于网格的方法。首先,在层次结构中选定一层作为查询处理的开始点。通常,该层包含少量的单元。对当前层次的每个单元,我们计算置信度区间(或者估算其概率),用以反映该单元与给定查询的关联程度。不相关的单元就不再考虑。低一层的处理就只检查剩余的相关单元。这个处理过程反复进行,直到达到最底层。此时,如果查询要求被满足,那么返回相关单元的区域。否则,检索和进一步的处理落在相关单元中的数据,直到它们满足查询要求。
“与其它聚类算法相比,STING有什么优点?”STING有几个优点:(1)由于存储在每个单元中的统计信息描述了单元中数据的与查询无关的概要信息,所以基于网格的计算是独立于查询的;(2)网格结构有利于并行处理和增量更新;(3)该方法的效率很高:STING扫描数据库一次来计算单元的统计信息,因此产生聚类的时间复杂度是O(n),n是对象的数目。在层次结构建立后,查询处理时间是O(g),这里g是最底层网格单元的数目,通常远远小于n。
第一层
第(i-1)层
第i层
图8.14 STING聚类的层次结构 (p371 ?)
由于STING采用了一个多分辨率的方法来进行聚类分析,STING聚类的质量取决于网格结构的最底层的粒度。如果粒度比较细,处理的代价会显著增加;但是,如果网格结构最底层的粒度太粗,将会降低聚类分析的质量。而且,STING在构建一个父亲单元时没有考虑孩子单元和其相邻单元之间的关系。因此,结果簇的形状是(isothetic),即所有的聚类边界或者是水平的,或者是竖直的,没有斜的分界线。尽管该技术有快速的处理速度,但可能降低簇的质量和精确性,
8.7.2 WaveCluster:采用小波变换聚类
WaveCluster是一种多分辨率的聚类算法,它首先通过在数据空间上强加一个多维网格结构来汇总数据,然后采用一种小波变换来变换原始的特征空间,在变换后的空间中找到密集区域。
在该方法中,每个网格单元汇总了一组映射到该单元中的点的信息。这种汇总信息适合于在内存中进行多分辨率小波变换使用,以及随后的聚类分析。
“什么是小波变换?”小波变换是一种信号处理技术,它将一个信号分解为不同频率的子波段。通过应用一维小波变换n次,小波模型可以应用于n维信号。在进行小波变换时,数据被变换以在不同的分辨率层次保留对象间的相对距离。这使得数据的自然聚类变得更加容易区别。通过在新的空间中寻找高密度区域,可以确定聚类。小波变换在第三章中也进行了讨论,它们用于通过压缩来缩减数据。对该技术的参考文献在文献目录中列出。
“为什么小波变换对聚类是有用的?”它主要有如下的优点:
? 它提供了没有监控的聚类。它采用了hat-shape过滤,强调点密集的区域,而忽视在密
集区域外的较弱的信息。这样,在原始特征空间中的密集区域成为了附近点的吸引点(attractor), 距离较远的点成为抑制点(inhibitor)。这意味着数据的聚类自动地显示出来,并“清理”了周围的区域。这样,小波变换的的另一个优点是能够自动地排除孤立点。
? 小波变换的多分辨率特性对不同精确性层次的聚类探测是有帮助的。例如,图8.15显
示了一个二维特征空间的例子,图中的每个点代表了空间数据集中一个对象的属性或特征值。图8.16显示了不同分辨率的小波变换结果,从细的尺度到粗的尺度。在每一个层次,显示了原始数据分解得到的四个子波段。在左上像限中显示的子波段强调了每个数据点周围的平均邻域。右上像限内的子波段强调了数据的水平边。左下像限中的子波段强调了垂直边,而右下像限中的子波段强调了转角。
? 基于小波的聚类速度很快,计算复杂度是O(n),这里n是数据库中对象的数目。这个
算法的实现可以并行化。
图8.15 二维特征空间的例子 (p373 ?)
图8.16 图8.15中特征空间的多种分辨率的结果:(a)1级(高分辨率)(b)2级(中分辨率)(c)3级(低分辨率)。见[SCZ98]。 (p373 ?)
WaveCluster是一个基于网格和密度的算法。它符合一个好的聚类算法的许多要求:它能有效地处理大数据集合,发现任意形状的簇,成功地处理孤立点,对于输入的顺序不敏感,不要求诸如结果簇的数目,邻域的半径等输入参数的定义。在实验分析中,WaveCluster在效率和聚类质量上优于BIRCH,CLARANS,和DBSCAN。实验分析也发现WaveCluster能够处理最多20维的数据。
8.7.3 CLIQUE:聚类高维空间
CLIQUE(Clustering In QUEst)聚类算法综合了基于密度和基于网格的聚类方法。它对于大型数据库中的高维数据的聚类非常有效。CLIQUE的核心想法:
? 给定一个多维数据点的大集合,数据点在数据空间中通常不是均衡分布的。CLIQUE区
分空间中稀疏的和拥挤的区域,以发现数据集合的全局分布模式。
? 如果一个单元中的包含的数据点超过了某个输入参数,则该单元是密集的。在CLIQUE
中,相连的密集单元的最大集合定义为簇。
“CLIQUE如何工作?”CLIQUE分两步进行多维聚类:
第一步,CLIQUE将n维数据空间划分为互不相交的长方形单元,识别其中的密集单元。该工作对每一维进行。例如,图8.17显示了关于age和salary,vocation维的密集的长方形单元。代表这些密集单元的相交子空间形成了一个候选搜索空间,其中可能存在更高维度的密集单元。
图8.17关于age和salary,vocation维的密集单元,代表这些密集单元的相交子空间形成了一个候选搜索空间,其中可能存在更高维度的密集单元。
(p375 ?)
“为什么CLIQUE将更高维密集单元的搜索限制在子空间密集单元的交集中?”这种候选搜索空间的确定采用基于关联规则挖掘1中的先验特性(apriori property)。一般来说,该特性在搜索空间中利用数据项的先验知识以裁减空间。CLIQUE所采用的特性如下:如果一个k维单元是密集的,那么它在k-1维空间上的投影也是密集的。也就是说,给定一个k维的候选密集单元,如果我们检查它的k-1维投影单元,发现任何一个不是密集的,那么我们知道第k维的单元也不可能是密集的。因此,我们可以从(k-1)维空间中发现的密集单元来推断k维空间中潜在的或候选的密集单元。通常,最终的结果空间比初始空间要小很多。然后对检查密集单元决定聚类。
在第二步,CLIQUE为每个簇生成最小化的描述。对每个簇,它确定覆盖相连的密集单元的最大区域,然后确定最小的覆盖。
“CLIQUE的有效性如何?” 因为高密度的聚类存在于那些子空间中,CLIQUE自动地发现最高维的子空间,对元组的输入顺序不敏感,无需假设任何规范的数据分布。它随输入数据的大小线性地扩展,当数据的维数增加时具有良好的可扩展性。但是,由于方法大大简化,聚类结果的精确性可能会降低。
8.8 基于模型的聚类方法
基于模型的聚类方法试图优化给定的数据和某些数学模型之间的适应性。这样的方法经常是基于这样的假设:数据是根据潜在的概率分布生成的。基于模型的方法主要有两类:统计学方法和神经网络方法。在本节中对每种方法的例子都给出了描述。
8.8.1 统计学方法
概念聚类是机器学习中的一种聚类方法,给出一组未标记的对象,它产生一个分类模式。与传统的聚类不同,概念聚类除了确定相似对象的分组外,还向前走了一步,为每组对象发现了特征描述,即每组对象代表了一个概念或类。因此,概念聚类是一个两步的过程:首先,进行聚类,然后给出特征描述。在这里,聚类质量不再只是单个对象的函数,而且加入了如导出的概念描述的简单性和一般性等因素。
概念聚类的绝大多数方法采用了统计学的途径,在决定概念或聚类时使用概率度量。概率描述用于描述导出的概念。
图8.18 (p377 ?)
COBWEB是一种简单,流行的增量概念聚类算法。它的输入对象用(分类属性,值)来描述。COBWEB以一个分类树的形式创建层次聚类。
“但是,分类树是什么?它跟决策树一样吗?”图8.18显示了一棵对动物数据的分类树,它基于[Fis87]。分类树与决策树不同。分类树中的每个节点对应一个概念,包含该概念的一个概率描述,概述了被分在该节点下的对象。概率描述包括概念的概率和形如P(Ai= Vij| Ck)的条件概率,这里Ai=Vij是一对属性和值,Ck是概念类(计数被累计和存储在每个节点中,用于概率的计算)。这就与决策树不同,决策树标记分支,而非节点,而且采用逻辑1 关联规则讨论参见第6章。特别地,先验特性的描述见6.2.1节。
描述符,而不是概率描述符2。在分类树某个层次上的兄弟节点形成了一个划分。为了用分类树对一个对象进行分类,采用了一个部分匹配函数来沿着最佳匹配节点的路径在树中向下移动。
COBWEB采用了一个启发式估算值——分类效用(category utility)来指导树的构建。分类效用(Category Utility,CU)定义如下:
(8.27 p378 ?)
这里n是在树的某个层次上形成一个划分{C1,C2,…,Cn}的节点,概念,或“种类”的数目。尽管我们没有空间来显示这个推导过程,分类效用奖励类内相似性和类间相异性, ? 概率P(Ai=Vij|Ck)表示类内相似性。该值越大,共享该属性-值的类成员比例越大,该属
性-值对类成员的预见性就越大。
? 概率P(Ck|Ai=Vij)表示类间相异性。该值越大,共享该属性-值却在其它类中的对象
就越少,该属性-值对类的预见性就越大。
图8。18 分类树。参见[Fis87]
让我们看一下COBWEB怎样工作。COBWEB将对象增量地加入到分类树中。“给定一个新的对象,”你想知道,“COBWEB怎样决定将其加入分类树的位置?”COBWEB沿着一条适当的路径向下,修改计数,寻找可以分类该对象的最好节点。这个决策基于将对象临时置于每个节点,计算结果划分的分类效用。产生最高分类效用的方案应当是一个好的选择。 “但如果对象不属于树中现有的任何概念怎么办?如果为给出的对象新建一个节点更好怎么办?”这是一个很好的想法。事实上,COBWEB也计算为给定对象创建一个新的节点 所产生的分类效用。它与基于现存节点的计算相比较。根据产生最高分类效用的划分,对象被置于一个已存在的类,或者为它创建一个新类。要注意COBWEB可以自动修正划分中类的数目。它不需要用户提供这样的输入参数。
上面提到的两个操作符对于对象的输入顺序非常敏感。为了降低它对输入顺序的敏感度,COBWEB有两个额外的操作符:合并(merging)和分裂(splitting)。当一个对象被加入,两个最好的候选节点可以考虑合并为单个类。此外,COBWEB考虑在现有的分类中分裂最佳的候选节点的孩子。这些决定基于分类效用。合并和分裂操作符使得COBWEB执行一种双向的搜索,例如,一个合并可以抵消一个以前的分裂。
“COBWEB的局限性是什么?”COBWEB有若干局限性。首先,它基于这样一个假设:在每个属性上的概率分布是彼此独立的。由于属性间经常是相关的,这个假设并不总是成立。此外,聚类的概率分布描述使得更新和存储聚类相当昂贵。因为时间和空间复杂度不只依赖于属性的数目,而且取决于每个属性的值的数目,所以当属性有大量的取值时情况尤其严重。而且,分类树对于偏斜的输入数据不是高度平衡的,它可能导致时间和空间复杂性的剧烈变化。
CLASSIT是COBWEB的扩展,用以处理连续性数据的增量聚类。它在每个节点中为每个属性存储一个连续的正常的分布(即平均值和标准偏差),采用一个修正的分类效用函数,计算出在连续属性上的一个整数值。但是,它与COBWEB存在类似的问题,因此不适用于聚类大规模的数据。
在产业界,AutoClass是一个比较流行的聚类方法,它采用Bayesian统计分析来估算结果簇的数目。将概念聚类方法应用到数据挖掘中需要进行额外的研究。参考文献中给出了相关的参考书目。
2 决策树描述参见第7章。
8.8.2 神经网络方法
神经网络方法将每个簇描述为一个模型(exemplar)。模型作为聚类的“原型”,不一定对应一个特定的数据例子或对象。根据某些距离函数,新的对象可以被分配给模型与其最相似的簇。被分配给一个簇的对象的属性可以根据该簇的模型的属性来预测。
在本节中,我们讨论神经网络聚类的两个比较著名的方法。第一个是有竞争学习(competitive learning),第二个是自组织特征图,这两种方法都涉及有竞争的神经单元。 有竞争学习采用了若干个单元的层次结构(或者人造的“神经元”),它们以一种“winner-take-all”的方式对系统当前处理的对象进行竞争。图8.19显示了一个竞争学习系统的例子。每个圆圈代表一个单元。在一个簇中获胜的单元成为活动的(以填满的圆圈表示),而其它是不活动的(以空的圆圈表示)。各层之间的连接是激发(excitatory)——在某个给定层次中的单元可以接收来自低一层次所有单元的输入。在一层中活动单元的布局代表了高一层的输入模式。在某个给定层次中,一个簇中的单元彼此竞争,对低一层的输出模式做出反应。一个层次内的联系是抑制(inhibitory),以便在任何簇中只有一个单元是活动的。获胜的单元修正它与簇中其它单元连接上的权重,以便未来它能够对与当前对象相似或一样的对象做出较强的反应。如果我们将权重看作定义一个模型,那么新的对象被分配给有最近模型的簇。结果簇的数目和每个簇中单元的数目是输入参数。
层3 抑制簇
激发联接
层2 抑制簇
层1 输入单元
输入模式
图8.19有竞争学习的结构。其层数可以任意。见[RZ85] (p380 ?)
在聚类过程结束时,每个簇可以被看作一个新的“feather”,它发现了对象的一些规律性。这样,产生的结果簇可以被看作一个低层特征向高层特征的映射。
对于自组织特征图(self-organizing feature map,SOMs),聚类也是通过若干个单元竞争当前对象来进行的。权重向量最接近当前对象的单元成为获胜的或活动的单元。为了更接近输入对象,获胜单元及其最近的邻居的权重进行调整。SOMs假设在输入对象中存在一些拓扑结构或顺序,单元将最终在空间中呈现这种结构。单元的组织形成一个特征图。SOMs被认为类似于大脑的处理过程,对在二或三维空间中直观化高维数据是有用的。
神经网络聚类方法与实际的大脑处理有很强的理论联系。由于较长的处理时间和数据的复杂性,需要进行进一步的研究来使它适用于大规模的数据库。
8.9 孤立点(outlier)分析
“孤立点是什么?”经常存在一些数据对象,它们不符合数据的一般模型。这样的数据
对象被称为孤立点,它们与数据的其它部分不同或不一致。
孤立点可能是度量或执行错误所导致的。例如,一个人的年龄为-999可能是对未记录的年龄的缺省设置所产生的。另外,孤立点也可能是固有的数据可变性的结果。例如,一个公司的首席执行官的工资自然远远高于公司其他雇员的工资,成为一个孤立点。
许多数据挖掘算法试图使孤立点的影响最小化,或者排除它们。但是由于一个人的“噪音”可能是另一个人的信号,这可能导致重要的隐藏信息的丢失。换句话说,孤立点本身可能是非常重要的,例如在欺诈探测中,孤立点可能预示着欺诈行为。这样,孤立点探测和分析是一个有趣的数据挖掘任务,被称为孤立点挖掘。
孤立点挖掘有着广泛的应用。像上面所提到的,它能用于欺诈监测,例如探测不寻常的信用卡使用或电信服务。此外,它在市场分析中可用于确定极低或极高收入的客户的消费行为,或者在医疗分析中用于发现对多种治疗方式的不寻常的反应。
孤立点挖掘可以描述如下:给定一个n个数据点或对象的集合,及预期的孤立点的数目k,发现与剩余的数据相比是相异的,例外的,或不一致的头k个对象。孤立点挖掘问题可以被看作两个子问题:(1)定义在给定的数据集合中什么样的数据可以被认为是不一致的;
(2)找到一个有效的方法来挖掘这样的孤立点。
孤立点的定义非常重要。如果采用一个回归模型,剩余量的分析可以给出对数据“极端”的很好的估计。但是,当在时间序列数据中寻找孤立点时,它们可能隐藏在趋势的,周期性的,或者其他循环变化中,这项任务非常棘手。当分析多维数据时,不是任何特别的一个,而是维值的组合可能是极端的。对于非数值型的数据(如分类数据),孤立点的定义要求特殊的考虑。
“采用数据直观化方法来进行孤立点探测如何?”你可能想知道。既然人眼在发现数据的不一致上是非常迅速和有效的,可能看起来这是一个明显的选择。但是,这不适用于包含周期性曲线的数据,这时例外的值可能正好是现实中有效的值。数据直观化方法对于探测有很多分类属性的数据,或高维数据中的孤立点效率很低,这是因为人眼只擅长于处理两到三维的数值型数据。
在本节中,我们探讨基于计算机的孤立点探测方法。它们可以被分为三类:统计学方法,基于距离的方法,和基于偏移的方法,每类方法都会进行讨论。注意,当聚类算法将孤立点作为噪音剔除时,它们可以被修改,包括孤立点探测作为执行的副产品。一般说来,用户必须检查以确定发现的每个孤立点均是事实上的孤立点。
8.9.1 基于统计的孤立点探测
统计的方法对给定的数据集合假设了一个分布或概率模型(例如一个正态分布),然后根据模型采用不一致性检验(discordancy test)来确定孤立点。该检验要求数据集参数(例如假设的数据分布),分布参数(例如平均值和方差),和预期的孤立点的数目。
“不一致性检验如何进行?”一个统计学的不一致性检验检查两个假设:一个工作假设(working hypothesis)和一个替代假设(alternative hypothesis)。一个工作假设H是一个命题:n个对象的整个数据集合来自一个初始的分布模型F,即
H:Oi ∈F,I=1,2,…,n
如果没有显著的证据支持拒绝这个假设,它就被保留。不一致性检验验证一个对象Oi关于分布F是否显著地大(或者小)。依据可用的关于数据的知识,不同的统计量被提出来用作不一致性检验。假设某个统计量被选择用于不一致性检验,对象Oi的该统计量的值为Vi,然后分布T被构建。显著性概率SP(Vi)=Prob(T>Vi)被估算。如果某个SP(Vi)是足够的小,
那么Oi是不一致的,工作假设被拒绝。替代假设被采用,它声明Oi来自于另一个分布模型G。既然Oi可能在一个模型下是孤立点,在另一个模型下是非常有效的值,那么结果非常依赖于模型F的选择。
替代分布在决定检验的能力(即当Oi真的是孤立点时工作假设被拒绝的概率)上是非常重要的。有许多不同的替代分布:
? 固有的替代分布(inherent alternative distribution):在这种情况下,所有对象来自分布F
的工作假设被拒绝,而所有对象来自另一个分布G的替代假设被接受:
H’: Oi ∈G, I= 1,2,…,n (p383 ?)
F和G可能是不同的分布,或者是参数不同的相同分布。对G分布的形式存在约束以便它有产生孤立点的可能性。例如,它可能有不同的平均值或者离差,或者更长的尾部。 ? 混合替代分布(mixture alternative distribution):混合替代分布认为不一致的值不是F
分布中的孤立点,而是来自其他分布的污染物。在这种情况下,替代假设是:
H’: Oi∈(1-λ)F+λG,I=1,2,…,n (p383 ?)
? 滑动替代分布(slippage alternative distribution):这个替代分布声明所有的对象(除了少
量外)根据给定的参数独立地来自初始的模型F,而剩余的对象是来自修改过的F的独立的观察,这个F的参数已经变化了。
探测孤立点有两类基本的过程:
? block过程:或者所有被怀疑的对象都被作为孤立点对待,或者都被作为一致的而接受。 ? 连续的过程:该过程的一个例子是inside-out过程。它的主要思想是:最不可能是孤立
点的对象首先被检验。如果它被发现是孤立点,那么所有更极端的值都被认为是孤立点;否则,下一个极端的对象被检验,依次类推。这个过程往往比block过程更为有效。
“在孤立点探测上统计学方法的有效性如何?”一个主要的缺点是绝大多数检验是针对单个属性的,而许多数据挖掘问题要求在多维空间中发现孤立点。而且,统计学方法要求关于数据集合参数的知识,例如数据分布。但是在许多情况下,数据分布可能是未知的。当没有特定的检验时,统计学方法不能确保所有的孤立点被发现,或者观察到的分布不能恰当地被任何标准的分布来模拟。
8.9.2基于距离的孤立点探测
为了解决统计学方法带来的一些限制,引入了基于距离的孤立点的概念。
“什么是基于距离的孤立点?”如果至少数据集合S中对象的p部分与对象o的距离大于d,对象o是一个基于距离的带参数p和d的孤立点,即DB(p,d)。换句话说,不依赖于统计检验,我们可以将基于距离的孤立点看作是那些没有足够邻居的对象,这里的邻居是基于距给定对象的距离来定义的。与基于统计的方法相比,基于距离的孤立点探测归纳了多个标准分布的不一致性检验的思想。基于距离的孤立点探测避免了过多的计算,而大量的计算正是使观察到的分布适合某个标准分布,及选择不一致性检验所需要的。
对许多不一致性检验来说,如果一个对象 o根据给定的检验是一个孤立点,那么对恰当定义的p和d,o也是一个DB(p,d) 孤立点。例如,如果离平均值偏差3或更大的对象被认为是孤立点,假设一个正态分布,那么这个定义能够被一个DB(0.9988,0.13σ)孤立点所
概括3。
目前已经开发了若干个高效的挖掘基于距离的孤立点的算法,具体如下:
基于索引的算法: 给定一个数据集合,基于索引的算法采用多维索引结构,例如R树或k-d树,来查找每个对象o在半径d范围内的邻居。设M是一个孤立点的d邻域内的最大对象数目。因此,一旦对象o的M+1个邻居被发现,o就不是 孤立点。这个算法在最坏情况下的复杂度为O(k*n2),这里k是维数,n是数据集合中对象的数目。当k增加时,基于索引的算法具有良好的扩展性。但是,复杂度估算只考虑了搜索时间,即使建造索引的任务本身就是计算密集的。
嵌套-循环算法:嵌套-循环算法和基于索引的算法有相同的计算复杂度,但它避免了索引结构的构建,试图最小化I/O的次数。它把内存的缓冲空间分为两半,把数据集合分为若干个逻辑块。通过精心选择逻辑块装入每个缓冲区域的顺序,I/O效率能够改善。
基于单元(cell-based)的算法:为了避免O(n2)的计算复杂度,为驻留内存的数据集合开发了基于单元的算法。它的复杂度是O(ck+n),这里c是依赖于单元数目的常数,k是维数。在该方法中,数据空间被划分为边长等于d/2(?)的单元。每个单元有两层围绕着。第一层的厚度是一个单元,而第二层的厚度是(p385 ?)。该算法一个单元一个单元地对孤立点记数,而不是一个对象一个对象地进行。对一个给定的单元,它累计三个计数——单元中对象的数目,单元和第一层中对象的数目,及单元和两个层次中的对象的数目。让我们把这些计数分别称为cell_count,cell_+_1_layer_count,cell_+_2_layers_count。
“在该方法中怎样确定孤立点?”设M是一个孤立点的d邻域中可能存在的孤立点的最大数目。
? 在当前单元中的一个对象o被认为是孤立点,仅当cell_+_1_layer_count小于或等于M。
如果这个条件不成立,那么该单元中所有的对象可以从进一步的考察中移走,因为它们不可能是孤立点。
? 如果cell_+_2_layers_count 小于或等于M,那么单元中所有的对象被认为是孤立点。否
则,如果这个计数大于M,那么单元中的某些对象有可能是孤立点。为了探测这些孤立点,一个对象一个对象的处理被采用,对单元中的每个对象o,o的第二层中的对象被检查。对单元中的对象,只有那些d邻域内有不超过M个点的对象是孤立点。一个对象的d邻域由这个对象的单元,它的第一层的全部,和它的第二层的部分组成。
一个该算法的变形是关于n呈线性的,确保不会要求对数据集合进行超过三遍的扫描。它可以被用于大的磁盘驻留的数据集合,但对于高维数据不能很好地伸缩。
基于距离的孤立点探测要求用户设置参数p和d。寻找这些参数的合适设置可能涉及多次的试探和错误。
8.9.3 基于偏离的孤立点探测
基于偏离的孤立点探测(deviation-based outlier detection)不采用统计检验或基于距离3 参数p和d使用正态曲线概率函数加以计算,以满足概率条件(。。。),即(。。。)。(注意其解决方案不是唯一的。)半径为0.13的d邻域表示一个3σ+0.13单位(即,[2.87,3.13])的范围。有关偏离的完整的证明见[KN97]。
的度量值来确定异常对象。相反,它通过检查一组对象的主要特征来确定孤立点。与给出的描述偏离的对象被认为是孤立点。这样,该方法中的deviation典型地用于指孤立点。在本节中,我们研究基于偏离的孤立点探测的两种技术。第一种顺序地比较一个集合中的对象,而第二种采用了一个OLAP数据立方体方法。
序列异常技术
序列异常技术(sequential exception technique)(模仿了人类从一系列推测类似的对象中识别异常对象的方式。它利用了隐含的数据冗余。给定n个对象的集合S,它建立一个子集合的序列,{S1,S2,…,Sm},这里2≤m≤n,满足
Sj-1 Sj, Sj S (p386 ?)
序列中子集合间的相异度被估算。这个技术引入了下列的关键术语:
? 异常集(exception set):它是偏离或孤立点的集合,被定义为某类对象的最小子集,这些
对象的去除会产生剩余集合的相异度的最大减少。
? 相异度函数(dissimilarity function):该函数不要求对象之间的度量距离。它可以是满足
如下条件的任意函数:当给定一组对象时,如果对象间相似,返值就较小。对象间的相异度越大,函数返回的值就越大。一个子集的相异度是根据序列中先于它的子集增量计算的。给定一个n个对象的子集合{x1,…,xn},可能的一个相异度函数是集合中对象的方差:
(8.28 p386?)
这里(?)是集合中n个数的平均值。对于字符串,相异度函数可能是模式字符串的形式(例如,包含通配符),它可以用来覆盖目前所见的所有模式。当覆盖Sj-1中所有字符串的模式不能覆盖在Sj中,却不在 Sj-1中的任一字符串时,相异度增加。
? 基数函数(cardinality function):这一般是给定的集合中对象的数目。
? 平滑因子(smoothing factor):这是一个为序列中的每个子集计算的函数。它估算从原始
的数据集合中移走子集合可以带来的相异度的降低程度。该值由集合的势依比例决定。平滑因子值最大的子集是异常集。
一般的寻找异常集的任务可以是NP完全的(即,不可解的)。一个顺序的方法在计算上是可行的,能够用一个线性的算法实现。
“该方法如何工作?”不考虑其补集来估算当前子集的相异度,该算法从集合中选择了一个子集合的序列来分析。对每个子集合,它确定其与序列中前一个子集合的相异度差异。
“序列中子集合的顺序不影响结果吗?”为了减轻输入顺序对结果的任何可能的影响,以上的处理过程可以被重复若干次,每一次采用子集合的一个不同的随机顺序。在所有的迭代中有最大平滑因子值的子集合成为异常集。
OLAP 数据立方体技术
孤立点探测的OLAP方法在大规模的多维数据中采用数据立方体来确定反常区域。这种技术在第二章中有详细的描述。为了提高效率,孤立点的探测过程与立方体的计算是重叠的。这个方法是一种发现驱动的探索形式,预先计算的指示数据异常的值被用来在集合计算的所有层次上指导用户进行数据分析。如果一个立方体的单元值显著地不同与根据统计模型得到期望的值,该单元值被认为是一个例外,并采用可视化的提示来表示,例如背景颜色反映每个单元的异常程度。用户可以选择对那些标为异常的单元进行钻取。一个单元的度量值可能反映了发生在立方体更低层次上的异常,这些异常从当前的层次是不可见的。
这个模型考虑了涉及一个单元所属的所有维的度量值中的变化和模式。例如,假设你有一个销售数据的数据立方体,正在查看按月汇总的销售额。在可视化提示的帮助下,你注意到与其他月份相比,十二月的销售额有增长。这可能看起来是时间维上的一个异常。但是,通过向下查看十二月中每个项目的销售额,你发现每个项目的销售额都有相似的增长。因此,如果考虑项目维,十二月份总销售额的增长就不是一个异常。该模型考虑了隐藏在数据立方体集合分组操作后面的异常情况。对这样的异常,由于搜索空间很大,特别是当存在许多涉及多层概念层次的维的时候,人工探测是非常困难的。
8.10 总结
? 一个簇是一组数据对象的集合,在同一个簇中的对象彼此类似,而不同簇中的对象彼此
相异。将一组物理或抽象对象分组为类似对象组成的多个簇的过程被称为聚类。
? 聚类分析有很广泛的应用,包括市场或客户识别,模式识别,生物学研究,空间数据分
析,Web文档分类,及许多其他方面。聚类分析可以用作独立的数据挖掘工具,来获得对数据分布的了解,也可以作为其它数据挖掘算法的预处理步骤。
? 聚类的质量是基于对象相异度来评估的,相异度可以对多种类型的数据来计算,包括区
间标度变量,二元变量,标称变量,序数型变量,和比例标度型变量,或者这些变量类型的组合。
? 在数据挖掘中,聚类分析是一个活跃的研究领域。许多聚类算法已经被开发出来。具体
可以分为划分方法,层次方法,基于密度的方法,基于网格的方法,及基于模型的方法。 ? 划分方法首先得到初始的k个划分的集合,这里的参数k是要构建的划分的数目;然后
它采用迭代重定位技术,试图通过将对象从一个簇移到另一个来改进划分的质量。有代表性的划分方法包括k-means,k-medoids,CLARANS,和对它们的改进。
? 层次方法创建给定数据对象集合的一个层次性的分解。根据层次分解的形成过程,这类
方法可以被分为自底向上的,或自顶向下的。为了弥补合并或分裂的严格性,凝聚的层次方法的聚类质量可以通过分析每个层次划分中的对象链接(例如CURE和Chameleon),或集成其它的聚类技术(例如迭代重定位,BIRCH)来改进。
? 基于密度的方法基于密度的概念来聚类对象。它或者根据邻域对象的密度(例如
DBSCAN),或者根据某种密度函数(例如DENCLUE)来生成聚类结果。OPTICS是一个基于密度的方法,它生成数据聚类结构的一个扩充的顺序。
? 基于网格的方法首先将对象空间量化为有限数目的单元,形成网格结构,然后在网格结
构上进行聚类。STING是基于网格方法的一个有代表性的例子,它基于存储在网格单元中的统计信息聚类。CLIQUE和WaveCluster是两个既基于网格,又基于密度的聚类算法。
? 基于模型的方法为每个簇假设一个模型,发现数据对模型的最好匹配。有代表性的基于
模型的方法包括统计学方法(例如COBWEB,CLASSIT,和AutoClass),或神经网络方法(例如有竞争学习和自组织特征图)。
? 一个人的“噪音”可能是另一个人的信号。孤立点探测和分析对于欺诈探测,定制市场,
医疗分析,及许多其它的任务是非常有用的。基于计算机的孤立点分析方法包括基于统计学方法,基于距离的方法,和基于偏差的方法。
习题
8.1 简单地描述如何计算由如下类型的变量描述的对象间的相异度:
(a) 不对称的二元变量
(b) 标称变量
(c) 比例标度型(ratio-scaled)变量
(d) 数值型的变量
8.2 给定对如下的年龄变量的度量值:
18,22,25,42,28,43,33,35,56,28
通过如下的方法进行变量标准化:
(a) 计算年龄的平均绝对偏差
(b) 计算头四个值的z-score
8.3 给定两个对象,分别表示为(22,1,42,10),(20,0,36,8):
(a) 计算两个对象之间的欧几里得距离
(b) 计算两个对象之间的曼哈顿距离
(c) 计算两个对象之间的明考斯基距离,q=3
8.4 如下的表包含了属性name,gender,trait-1,trait-2,trait-3,及trait-4,这里的name是对象的id,gender是一个对称的属性,剩余的trait属性是不对称的,描述了希望找到笔友的人的个人特点。假设有一个服务是试图发现合适的笔友。
图(? 390)
对不对称的属性的值,值P被设为1,值N被设为0。
假设对象(潜在的笔友)间的距离是只基于不对称变量来计算的。
(a) 给定Kevan,Caroline,和Erk,给出对象之间的可能性矩阵。
(b) 计算对象间的简单匹配系数。
(c) 计算对象间的Jaccard系数。
(d) 你认为哪两个人将成为最佳笔友?哪两个会是最不能相容的?
(e) 假设我们将对称变量gender包含在我们的分析中。基于Jaccard系数,谁将是最
和谐的一对?为什么?
8.5 什么是聚类?简单描述如下的聚类方法:划分方法,层次方法,基于密度的方法,基于网格的方法,及基于模型的方法。为每类方法给出例子。
8.6 假设数据挖掘的任务是将如下的八个点(用(x,y)代表位置)聚类为三个类。 A1(2,10),A2(2,5),A3(8,4),B1(5,8),B2(7,5),B3(6,4),C1(1,2),C2(4,9)
距离函数是Euclidean函数。假设初始我们选择A1,B1,和C1为每个聚类的中心,用k-means算法来给出
(a) 在第一次循环执行后的三个聚类中心
(b) 最后的三个簇
8.7 用一个图表来描述当给定一个常数MinPts时,关于一个较高密度(即,邻域半径取一个较低的值)的基于密度的聚类结果如何被完全包含在根据较低的密度所获得的密度相连的集合中。
8.8 人眼在判断聚类方法对二维数据的聚类质量上是快速而有效的。你能设计一个数据可视化方法来使数据聚类可视化和帮助人们判断三维数据的聚类质量吗?对更高维数据又如
何?
8.9 给出一个特定的聚类方法如何被综合使用的例子,例如,什么情况下一个聚类算法被用作另一个算法的预处理步骤。
8.10 聚类被广泛地认为是一种重要的数据挖掘方法,有着广泛的应用。对如下的每种情况给出一个应用例子:
(a) 采用聚类作为主要的数据挖掘方法的应用
(b) 采用聚类作为预处理工具,为其它数据挖掘任务作数据准备的应用
8.11 数据立方体和多维数据库以层次的或聚集的形式包含分类的,序数型的,和数值型的数据。基于你已经学习的关于聚类方法的知识,设计一个可以有效和高效地在大数据立方体中发现簇的聚类方法。
8.12 假设你将在一个给定的区域分配一些自动取款机以满足需求。住宅区或工作区可以被聚类以便每个簇被分配一个ATM。但是,这个聚类可能被一些因素所约束,包括可能影响ATM可达性的桥梁,河流和公路的位置。其它的约束可能包括对形成一个区域的每个地域的ATM数目的限制。给定这些约束,怎样修改聚类算法来实现基于约束的聚类?
8.13 为什么孤立点挖掘是重要的?简单地描述基于统计的孤立点探测,基于距离的孤立点探测,和基于偏离的孤立点探测的方法。
文献注释
若干本教科书中都讨论了聚类方法,例如Hartigan[Har75],Jain和Dubes[JD88],及Kaufman和Rousseeuw[KR90]。Jain,Murty和Flynn关于聚类的一个最近的综述在[JMF99]中可以被找到。合并不同类型的变量到单个相异度矩阵中的方法在[KR90]中有介绍。
关于划分方法,k-means算法首先由MacQueen[Mac67]提出。K-medoids算法PAM和CLARA由Kaufman和Rousseeuw[KR90]提出。K-modes(k-模,聚类分类数据)和k-prototype(k-原型,聚类混合数据)算法由Huang[Hua98]提出,而EM(Expectation Maximization,最大期望)算法由Lauritzen[Lau95]提出。CLARANS算法由Ng和Han[NH94]提出。Ester,Kriegel,和Xu[EKX95]提出了采用高效的空间存取方法,例如R*树和调焦技术,来进一步改进CLARANS的性能。另一个基于k-means的可扩展的聚类算法由Bradley,Fayyad,和Reina[BFR98]提出。
凝聚的层次聚类(例如AGNES)和分裂的层次聚类(例如DIANA)由Kaufman和Rousseeuw[KR90]提出。改进层次聚类方法的聚类质量的一个引起关注的方向是综合层次聚类和基于距离的迭代重定位,或其它非层次的聚类方法。例如,由Zhang,Ramakrishnan,和Linvy[ZRL96]提出的BIRCH在采用其他技术之前首先用CF树进行层次聚类。层次聚类也能被成熟的连结分析,转换,或者最近邻居分析来执行,例如Guha,Rastogi,和Shim[GRS98]提出的CURE,Guha,Rastogi,和Shim[GRS99]提出的ROCK(聚类分类属性),及Karypis,Han,和Kumar[KHK99]提出的Chameleon。
关于基于密度的聚类方法,Ester,Kriegel,Sander,和Xu在[EKSX96]提出了DBSCAN。Ankerst,Breunig,Kriegel,和Sander[ABKS99]开发了一个聚类排序方法OPTICS,它方便了基于密度的聚类,而不用担心参数定义。基于一组密度分布函数的DENCLUE算法由Hinneburg和Keim[HK98]提出。
一个基于网格的多分辨率方法STING由Wang,Yang,和Muntz[WYM97]提出,它在网格单元中收集统计信息。WaveCluster由Sheikholeslami,Chatterjee,和Zhang[SCZ98]提
出,是一个多分辨率的聚类方法。它通过小波变换来转换原始的特征空间。Agrawal,Gehrke,Gunopulos,和Raghavan[AGGR98]提出的CLIQUE是一个综合了基于密度和基于网格方法的聚类算法,用于聚类高维数据。
关于基于模型的聚类方法,请参照Shavlik和Dietterich[SD90]。概念聚类首先由Michalski和Stepp[MS83]提出。统计的聚类方法的其它例子包括Fisher[Fis87]提出的COBWEB,Gennari,Langley,和Fisher[GLF89]提出的CLASSIT,及Cheeseman和Stutz[CS96a]提出的AutoClass。神经网络方法的研究包括Rumelhart和Zipser[RZ85]提出的竞争学习和Kohonen[Koh82]提出的SOM(self-organizing feature maps)。
聚类分类数据的可扩展方法被广泛研究,包括Gibson,Kleinberg,和Raghavan[GKR98],Guha,Rastogi,和Shim[GRS99],及Ganti,Gehrke,和Ramakrishnan[GGR99]。此外,也有许多其它的聚类范型。例如,模糊聚类方法在Kaufman和Rousseeuw[KR90],及Bezdek和Pal[BP92]中进行了讨论。
孤立点探测和分析可以分为三类方法:基于统计的方法,基于距离的方法,和基于偏离的方法。Barnett和Lewis[BL94]中描述了统计的方法和不一致性检验。基于距离的孤立点探测在Knorr和Ng[KN97,KN98]中有描述。基于偏离的孤立点探测的顺序方法在Arning,Agrawal,和Raghavan[AAR96]中提出。Sarawagi,Agrawal,和Megiddo[SAM98]提出了一个发现驱动的方法,在大规模的多维数据中采用OLAP数据立方体来确定异常情况。Jagadish,Koudas,和Muthukrishnan[JKM99]提出了一个高效的在时间序列数据库中挖掘异常的方法。
-
数据挖掘课程设计报告
ID3算法的改进摘要本文基于ID3算法的原有思路再把属性的重要性程度值纳入了属性选择的度量标准中以期获得更适合实际应用的分类划分结…
-
数据挖掘课程设计
本科课程设计及实验期末成绩评估系统的数据仓库和数据挖掘设计课程名称数据挖掘课程编号08060116学生姓名cwl学号20xx052…
-
数据挖掘课程设计报告正文
目录第1章数据挖掘基本理论211数据挖掘的产生212数据挖掘的概念313数据挖掘的步骤3第2章系统分析421系统用户分析422系统…
-
数据挖掘课程设计报告
数据挖掘课程设计报告题目姓名班级学号关联规则挖掘系统xxxxxx计算机0901xxxxxxxxxxx20xx年6月19日1一设计目…
-
数据挖掘聚类算法课程设计报告
数据挖掘聚类问题PlantsDataSet实验报告1数据源描述11数据特征本实验用到的是关于植物信息的数据集其中包含了每一种植物种…
-
数据挖掘课程设计报告正文
目录第1章数据挖掘基本理论211数据挖掘的产生212数据挖掘的概念313数据挖掘的步骤3第2章系统分析421系统用户分析422系统…
-
数据挖掘课程设计报告
ID3算法的改进摘要本文基于ID3算法的原有思路再把属性的重要性程度值纳入了属性选择的度量标准中以期获得更适合实际应用的分类划分结…
-
数据挖掘课程设计
本科课程设计及实验期末成绩评估系统的数据仓库和数据挖掘设计课程名称数据挖掘课程编号08060116学生姓名cwl学号20xx052…
-
数据挖掘课程设计报告
数据挖掘课程设计报告题目姓名班级学号关联规则挖掘系统xxxxxx计算机0901xxxxxxxxxxx20xx年6月19日1一设计目…
-
数据挖掘课程设计报告
一设计目的1更深的了解关联规则挖掘的原理和算法2能将数据挖掘知识与计算机编程相结合编写出合理的程序3深入了解Apriori算法二设…