数据挖掘课程设计 (规范化) 081002102 陈浩
数据变换
一.设计题目
数据变换:
1.最小-最大规范化
2.Z-score规范化
3.小数定标规范化
二.主要内容
1.平滑:去除数据中的噪声
2.聚集:数据汇总,数据立方体的构建,数据立方体的计算/物化(一个数据立方体在方体的最底层叫基本方体,基本方体就是已知存在的数据,对现有的数据按照不同维度进行汇总就可以得到不同层次的方体,所有的方体联合起来叫做一个方体的格,也叫数据立方体。数据立方体中所涉及到的计算就是汇总)
3.数据概化:沿概念分层向上汇总,数据立方体的不同的维之间可能存在着一个概念分层的关系
4.规范化:将数据按比例缩放,使这些数据落入到一个较小的特定的区间之内。方法有:
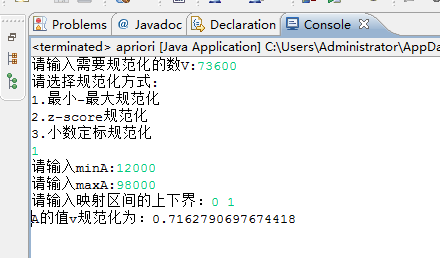
a.最小----最大规范化
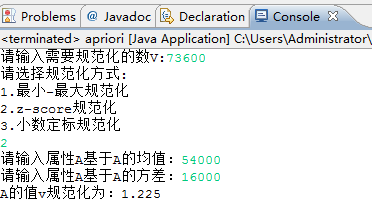
b.Z-score规范化
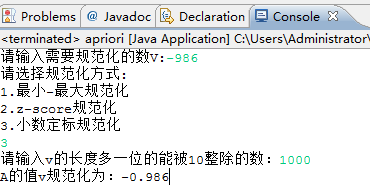
c.小数定标规范化
5.属性的构造:通过现有属性构造新的属性,并添加到属性集中
三.基本思想
1.数据变换的基本思想:
通过将属性值按比例缩放,使之落入一个小的特定区间,对属性规范化。
四.算法的代码
import java.util.*;
publicclass apriori{
publicstaticvoid main(String[] args){
Scanner Scanner= new Scanner(System.in);
System.out.print("请输入需要规范化的数V:");
double v=Scanner.nextInt();
System.out.println("请选择规范化方式:\n1.最小-最大规范化\n2.z-score规范化\n3.小数定标规范化");
int pin=Scanner.nextInt();
switch(pin){
case 1:
System.out.print("请输入minA:");
double minA=Scanner.nextInt();
System.out.print("请输入maxA:");
double maxA=Scanner.nextInt();
System.out.print("请输入映射区间的上下界:");
double[]s;
s=newdouble[2];
for(int i=0;i<2;i++){
s[i]=Scanner.nextInt();
}
double v1=((v-minA)/(maxA-minA)*(s[1]-s[0])+s[0]);
System.out.print("A的值v规范化为:"+v1);
break;
case 2:
System.out.print("请输入属性A基于A的均值:");
double meanA=Scanner.nextInt();
System.out.print("请输入属性A基于A的方差:");
double varianceA=Scanner.nextInt();
double v2=(v-meanA)/varianceA;
System.out.print("A的值v规范化为:"+v2);
break;
case 3:
System.out.print("请输入v的长度多一位的能被10整除的数:");
double L=Scanner.nextInt();
double v3=v/L;
System.out.print("A的值v规范化为:"+v3);
break;
}
}
}
五.运行结果
1.最小--最大规范化
2.z-score规范化
3.小数定标规范化
第二篇:数据挖掘课程设计
本科课程设计及实验
期末成绩评估系统的数据仓库和数据挖掘设计
课 程 名 称: 数据挖掘
课 程 编 号: 08060116
学 生 姓 名: cwl
学 号: 2008052251
学 院: 信息科学技术学院
系: 计算机科学系
专 业: 软件工程
指 导 教 师: lb
教 师 单 位: 信息学院计算机系
开 课 时 间: 20## ~ 20## 学年度第 二 学期
20##年 06月20日
第1章 概述
1.1应用背景和问题的提出
在大学生活中,我们大学生在某种程度上还是比较重视自己的课程成绩的。而有一个期末最终成绩的评估系统,无疑对同学们而言是很有用的。在这个系统中,只需输入你估计的平时成绩以及表现和期末考试的得分,就可以预测出最终的成绩。而这个课程成绩的组成以及得出是怎么样的呢。这个最终的得分是受到什么影响呢?本论文就以上问题进行了探讨和挖掘。
1.2设计内容的介绍
本课程设计主要是探讨和研究在老师给定成绩时考虑的因素,以及这些因素所占的比例。数据仓库为一份记录着600个同学的得分情况的数据,数据挖掘则采用决策树探究出影响结婚年龄的因素。
第2章 数据仓库设计
2.1概念模型设计
数据仓库里面有一个实体,也就是成绩score。成绩的决定因素有performance也就平时表现情况,即根据其在课堂上的活跃程度以及认真听课的情况来给的分,还有averscore就是同学平时的作业得分以及平时测试或者期中测试的平均成绩,以及期末考试的成绩lasttest。

2.2逻辑模型设计
本数据仓库只有一个表,逻辑模型设计如下:

2.3物理模型设计
在数据仓库的物理设计中,主要解决数据的存储结构、数据的索引策略、数据的存储策略、存储分配优化等问题。物理设计的主要目的有两个,一是提高性能,二是更好地管理存储的数据。访问的频率、数据容量、选择的RDBMS支持的特性和存储介质的配置都会影响物理设计的最终结果。在本数据挖掘中,数据的索引策略采取的并不是位图索引而是按列索引
2.4 OLAP模型设计
在本设计中由于案例考虑的并不复杂,所以OLAP模型设计也就比较的简单。
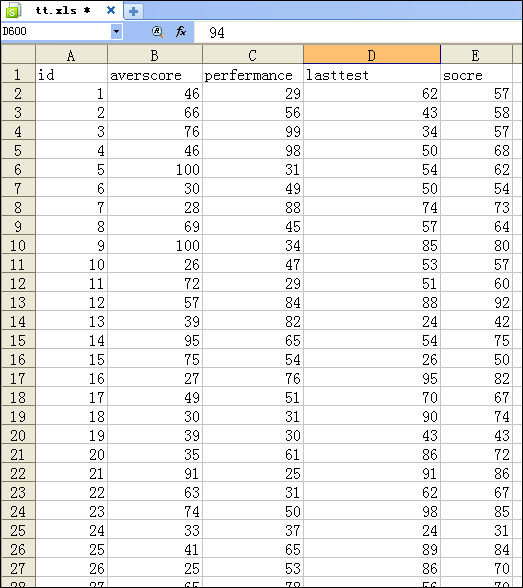 下面的数据是保存在Excel中的。大概的模型设计也就如下图所示。
下面的数据是保存在Excel中的。大概的模型设计也就如下图所示。
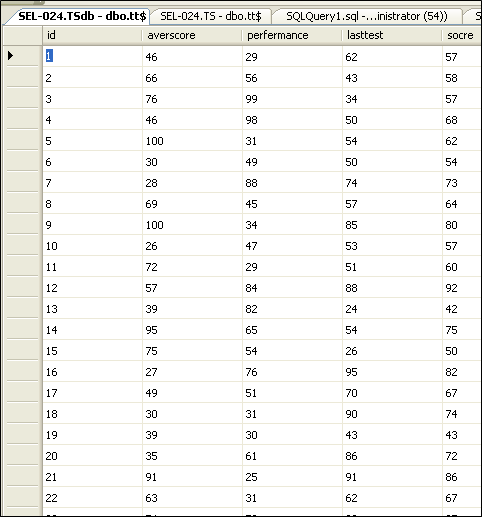 2.5 OLAP前端展示设计
2.5 OLAP前端展示设计
第3章 数据挖掘分析
3.1 期末成绩评估系统应用挖掘概述
在本系统中,数据仓库采用一个二维表来存储和表示同学们的平时成绩,平时表现得分,以及期末成绩等属性。数据挖掘则采用关联分析来将二维表中的实例分开,并探究这些数据所蕴含的规律。
3.2数据挖掘实验
3.2.1实验环境
Windows XP
Microsoft SQL Server 2008
Microsoft Visual Studio 2008
Microsoft Office 20## Excel Access
3.2.2数据准备及预处理
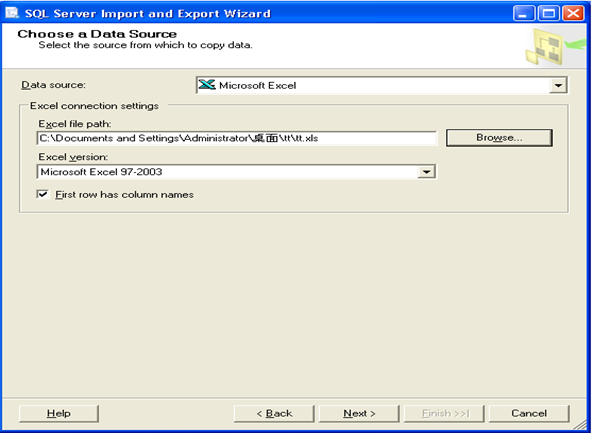 首先选择数据源,以下几个截图是在做实验时的几个步骤。
首先选择数据源,以下几个截图是在做实验时的几个步骤。

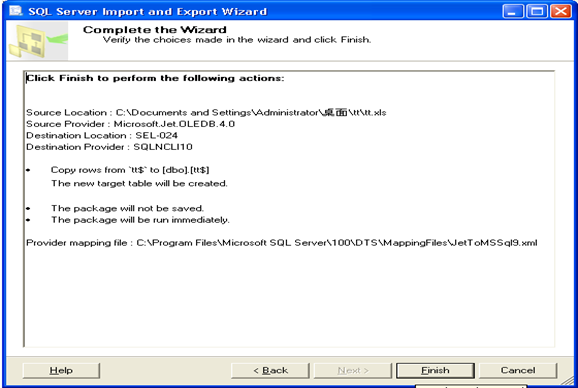

3.2.3实验内容 (输入数据集,选择算法,输出结果,比较分析)
(1)建立一个Analysis Services Project的项目,在数据源中输入数据集:

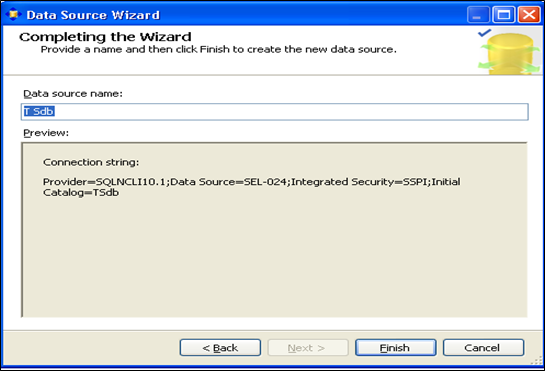
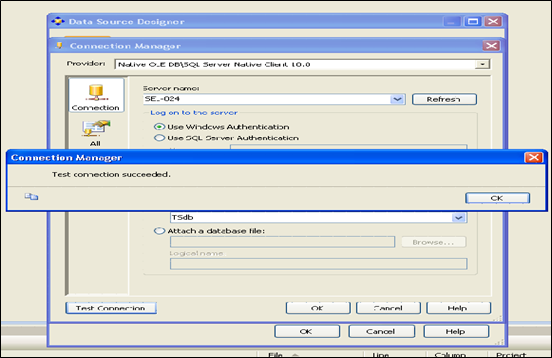
说明: 以上实验室在实验室做的,由于时间不够,回到宿舍自己安装了中文版的SQL SERVER工具,并完成接下来的实验步骤。
3.2.4算法选择
分类的任务是通过分析由已知类别数据对象组成的训练数据集,建立描述并区分数据对象类别的分类函数或分类模型(也常常称作分类器)。
分类算法有多种,例如,决策树分类算法、神经网络分类算法、贝叶斯分类算法等。这里需要用的是决策树分类算法。
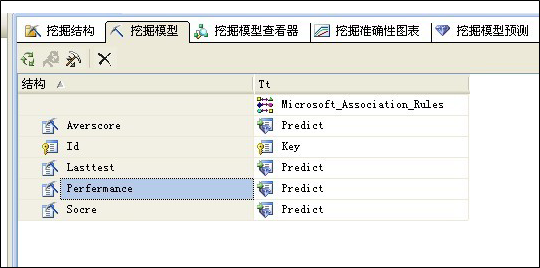
在本挖掘中选择是关联分析,分析过程和结果如以下图所示:
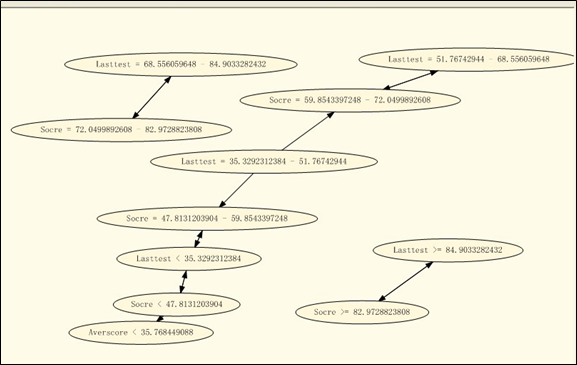
下面是挖掘模型:
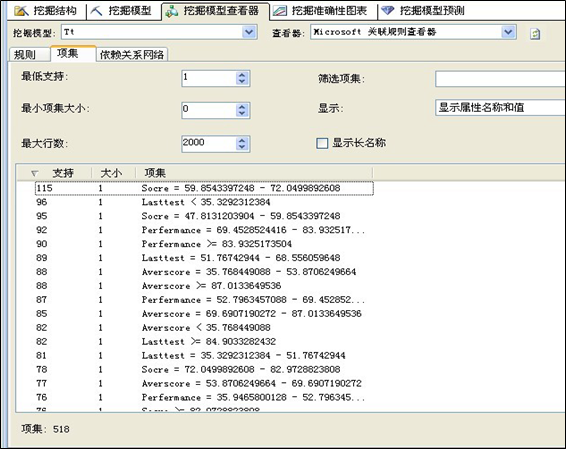
项集:
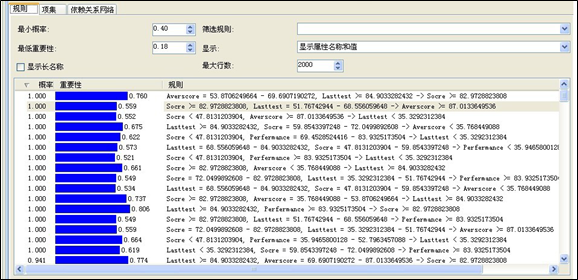
关联规则:
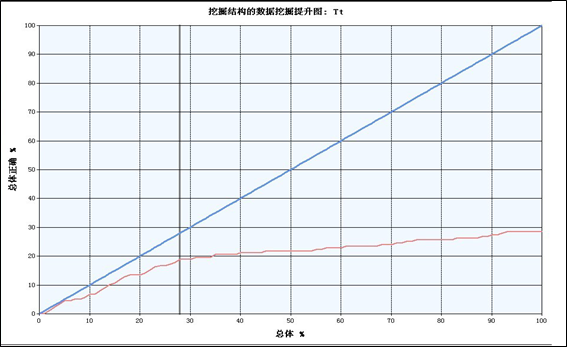
提升图:
分类矩阵:
依赖关系网络图:

后来我用回归预测法,得到了一个散点图,说明预测值和实际值是有一定的关联的: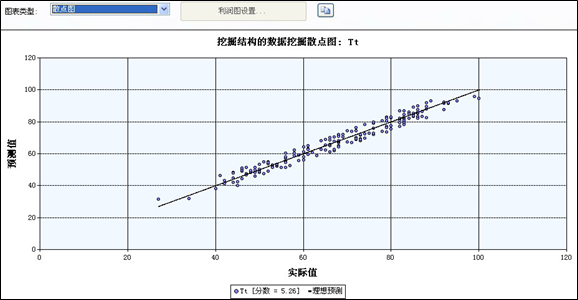
通过以上的分析,我们得出一个结论,就是期末成绩在最终得分中所占的比例最大,平时成绩和平时表现的权重差不多,在这个结论中,期末考试的成绩的重要性,不言而喻,增加期末考试的成绩,最能提高最终成绩,平时成绩和表现的得分也很重要,但相对权重没有期末成绩大。一个分数高的学生,他的所有成绩都应该是很高的。
参考文献:
[1] Jamie MacLennan,ZhaoHui Tang,Bogdan Crivat 著.数据挖掘原理与应用(第2版)——SQL Server 2008数据库.北京:清华大学出版社.
[2]、王丽珍、周丽华、陈红梅、肖清,数据仓库与数据挖掘原来及应用,北京:科学出版社
[3]、陈立潮、张淼、南志红,数据库技术及应用(SQL Server)实践教程,北京:高等教育出版社
-
数据挖掘课程设计报告
ID3算法的改进摘要本文基于ID3算法的原有思路再把属性的重要性程度值纳入了属性选择的度量标准中以期获得更适合实际应用的分类划分结…
-
数据挖掘课程设计报告正文
目录第1章数据挖掘基本理论211数据挖掘的产生212数据挖掘的概念313数据挖掘的步骤3第2章系统分析421系统用户分析422系统…
-
数据挖掘课程设计报告
数据挖掘课程设计报告题目姓名班级学号关联规则挖掘系统xxxxxx计算机0901xxxxxxxxxxx20xx年6月19日1一设计目…
-
数据挖掘聚类算法课程设计报告
数据挖掘聚类问题PlantsDataSet实验报告1数据源描述11数据特征本实验用到的是关于植物信息的数据集其中包含了每一种植物种…
-
《数据仓库与数据挖掘》课程设计报告模板
江西理工大学应用科学学院数据仓库与数据挖掘课程设计报告题目某超市数据集的OLAP分析及数据挖掘系别班级姓名二一二年六月目录一建立数…
-
数据挖掘课程设计报告正文
目录第1章数据挖掘基本理论211数据挖掘的产生212数据挖掘的概念313数据挖掘的步骤3第2章系统分析421系统用户分析422系统…
-
数据挖掘课程设计报告
ID3算法的改进摘要本文基于ID3算法的原有思路再把属性的重要性程度值纳入了属性选择的度量标准中以期获得更适合实际应用的分类划分结…
-
数据挖掘课程设计
本科课程设计及实验期末成绩评估系统的数据仓库和数据挖掘设计课程名称数据挖掘课程编号08060116学生姓名cwl学号20xx052…
-
数据挖掘课程设计报告
数据挖掘课程设计报告题目姓名班级学号关联规则挖掘系统xxxxxx计算机0901xxxxxxxxxxx20xx年6月19日1一设计目…
-
数据挖掘课程设计报告
一设计目的1更深的了解关联规则挖掘的原理和算法2能将数据挖掘知识与计算机编程相结合编写出合理的程序3深入了解Apriori算法二设…