信息论与编码实验报告
中南大学
信息论与编码实验报告2
实验名称: 关于编码的实验
班 级: 电子信息xxxx班
学 号: xxxxxxxx
姓 名: xxxx
指导老师: xxxx
实验一 关于编码的实验
一、 实验目的
1. 掌握香农码和 Huffman 编码原理和过程。
2. 熟悉matlab软件的基本操作,练习使用matlab实现香农码和 Huffman 编码。
3. 熟悉 C/C++语言,练习使用 C/C++实现香农码和 Huffman 编码。
4. 应用 Huffman 编码实现文件的压缩和解压缩。
二、实验原理
香农码:
(1)将信源发出的N个消息符号按其概率的递减次序排列
(2)按下式计算第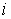 个消息的二进制代码组的码长
个消息的二进制代码组的码长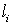 ,并取整
,并取整
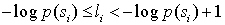
(3)计算第个消息的累加概率 (为小数)
(为小数)
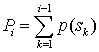
(4)将累加概率变换成二进制数
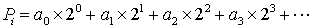
(5)去掉小数点,并根据取小数点后的前几位为对应的代码组。
霍夫曼(Huffman)编码:
属于码词长度可变的编码类,是霍夫曼在1952年提出的一种编码方法,即从下到上的编码方法。同其他码词长度可变的编码一样,可区别的不同码词的生成是基于不同符号出现的不同概率。生成霍夫曼编码算法基于一种称为“编码树”(coding tree)的技术。算法步骤如下:
(1)初始化,根据符号概率的大小按由大到小顺序对符号进行排序。
(2)把概率最小的两个符号组成一个新符号(节点),即新符号的概率等于这两个符号概率之和。
(3)重复第2步,直到形成一个符号为止(树),其概率最后等于1。
(4)从编码树的根开始回溯到原始的符号,并将每一下分枝赋值为1,上分枝赋值为0。
三、 实验内容
1、 使用matlab实现香农码和Huffman编码,并自己设计测试案例。
2、 使用C\C++实现香农码和Huffman编码,并自己设计测试案例。
3、 可以用任何开发工具和开发语言,尝试实现Huffman编码应用在数据文件的压缩和解压过程中,并自己设计测试方案。
四、 程序设计与算法描述
(1)香农码matlab程序:
clear all;
N=input('N='); %输入信源符号的个数
s=0;
l=0;
H=0;
for i=1:N
p(i)=input('p=');
%输入信源符号概率分布矢量,p(i)<1
s=s+p(i)
H=H+(-p(i)*log2(p(i)));
%计算信源信息熵
end
if abs(s-1)>0,
error('不符合概率分布')
end
for i=1:N-1
for j=i+1:N
if p(i)<p(j)
m=p(j);
p(j)=p(i);
p(i)=m;
end
end
end
%按概率分布大小对信源排序
for i=1:N
a=-log2(p(i));
if mod(a,1)==0
w=a;
else
w=fix(a+1);
end
%计算各信源符号的码长
l=l+p(i)*w; %计算平均码长
end
l=l;
n=H/l; %计算编码效率
P(1)=0
for i=2:N
P(i)=0;
for j=1:i-1
P(i)=P(i)+p(j);
end
end %计算累加概率
for i=1:N
for j=1:w
W(i,j)=fix(P(i)*2);
P(i)=P(i)*2-fix(P(i)*2);
end
end
%将累加概率转化为L(i)位二进制码字
disp(W) %显示码字
disp(l)% 显示平均码长
disp(n) %显示编码效率
运行结果:


(2)Huffman编码matlab程序:
clear all;
I=input('please input a string:'); %提示输入界面
len=length(I);
t=2;
biaozhi=0;
b(1)=I(1);
for i=2:len
for j=1:i-1
if I(j)==I(i)
biaozhi=1;
break;
end
end
if biaozhi==0
b(t)=I(i);
t=t+1;
end
biaozhi=0;
end
fprintf('信源总长度:\n');
disp(len); %信源总长度
fprintf('字符:\n');
disp(b );
L=length(b);
for i=1:L
a=0;
for j=1:len
if b(i)==I(j)
a=a+1;
count(i)=a;
end
end
end
count=count/len;%各字符概率
fprintf('各字符概率:\n');
disp(count);
p=count;
%%%%%%%%%%%%%%%%%%%%%%%%%%%
s=0;
l=0;
H=0;
N=length(p);
for i=1:N
H=H+(- p(i)*log2(p(i)));%计算信源信息熵
end
fprintf('信源信息熵:\n');
disp(H);
tic;
for i=1:N-1 %按概率分布大小对信源排序
for j=i+1:N
if p(i)<p(j)
m=p(j);
p(j)=p(i);
p(i)=m;
end
end
end
Q=p;
m=zeros(N-1,N);
for i=1:N-1 %循环缩减对概率值排序,画出由每个信源符号概率到1.0 处的路径,
[Q,l]=sort(Q);
m(i,:)=[l(1:N-i+1),zeros(1,i-1)];
Q=[Q(1)+Q(2),Q(3:N),1];
end
for i=1:N-1
c(i,:)=blanks(N*N);
end
c(N-1,N)='0';
c(N-1,2*N)='1';
for i=2:N-1 %对字符数组c码字赋值过程,记下沿路径的“1”和“0”;
c(N-i,1:N-1)=c(N-i+1,N*(find(m(N-i+1,:)==1))-(N-2):N*(find(m(N-i+1,:)==1)));
c(N-i,N)='0';
c(N-i,N+1:2*N-1)=c(N-i,1:N-1);
c(N-i,2*N)='1';
for j=1:i-1
c(N-i,(j+1)*N+1:(j+2)*N)=c(N-i+1,N*(find(m(N-i+1,:)==j+1)-1)+1:N*find(m(N-i+1,:)==j+1));
end
end
for i=1:N
h(i,1:N)=c(1,N*(find(m(1,:)==i)-1)+1:find(m(1,:)==i)*N);%码字赋值
ll(i)=length(find(abs(h(i,:))~=32)); %各码字码长
end
l=sum(p.*ll); %计算平均码长
n=H/l; %计算编码效率
fprintf('编码的码字:\n');
disp(h) %按照输入顺序排列的码字
fprintf('平均码长:\n');
disp(l) %输出平均码长
fprintf('编码效率:\n');
disp(n) %输出编码效率
fprintf('计算耗时time= %f\n',toc);
实验结果:

(3)香农码C语言程序:
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
#define max_CL 10 /*maxsize of length of code*/
#define max_PN 6 /*输入序列的个数*/
typedef float datatype;
typedef struct SHNODE {
datatype pb; /*第i个消息符号出现的概率*/
datatype p_sum; /*第i个消息符号累加概率*/
int kl; /*第i个消息符号对应的码长*/
int code[max_CL]; /*第i个消息符号的码字*/
struct SHNODE *next;
}shnolist;
datatype sym_arry[max_PN]; /*序列的概率*/
void pb_scan(); /*得到序列概率*/
void pb_sort(); /*序列概率排序*/
void valuelist(shnolist *L); /*计算累加概率,码长,码字*/
void codedisp(shnolist *L);
void pb_scan()
{
int i;
datatype sum=0;
printf("input %d possible!\n",max_PN);
for(i=0;i<max_PN;i++)
{ printf(">>");
scanf("%f",&sym_arry[i]);
sum=sum+sym_arry[i];
}
/*判断序列的概率之和是否等于1,在实现这块模块时,scanf()对float数的缺陷,故只要满足0.99<sum<1.0001出现的误差是允许的*/
if(sum>1.0001||sum<0.99)
{ printf("sum=%f,sum must (<0.999<sum<1.0001)",sum);
pb_scan();
}
}
/*选择法排序*/
void pb_sort()
{
int i,j,pos;
datatype max;
for(i=0;i<max_PN-1;i++)
{
max=sym_arry[i];
pos=i;
for(j=i+1;j<max_PN;j++)
if(sym_arry[j]>max)
{
max=sym_arry[j];
pos=j;
}
sym_arry[pos]=sym_arry[i];
sym_arry[i]=max;
}
}
void codedisp(shnolist *L)
{
int i,j;
shnolist *p;
datatype hx=0,KL=0; /*hx存放序列的熵的结果,KL存放序列编码后的平均码字的结果*/
p=L->next;
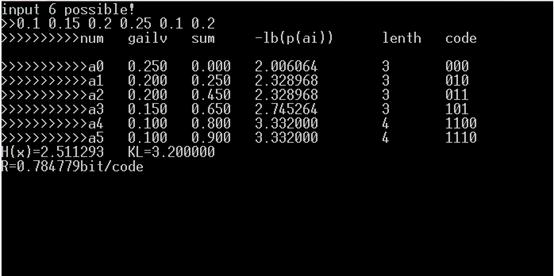
printf("num\tgailv\tsum\t-lb(p(ai))\tlenth\tcode\n");
printf("\n");
for(i=0;i<max_PN;i++)
{
printf("a%d\t%1.3f\t%1.3f\t%f\t%d\t",i,p->pb,p->p_sum,-3.332*log10(p->pb),p->kl);
j=0;
for(j=0;j<p->kl;j++)
printf("%d",p->code[j]);
printf("\n");
hx=hx-p->pb*3.332*log10(p->pb); /*计算消息序列的熵*/
KL=KL+p->kl*p->pb; /*计算平均码字*/
p=p->next;
}
printf("H(x)=%f\tKL=%f\nR=%fbit/code",hx,KL,hx/KL); /*计算编码效率*/
}
shnolist *setnull()
{ shnolist *head;
head=(shnolist *)malloc(sizeof(shnolist));
head->next=NULL;
return(head);
}
shnolist *my_creat(datatype a[],int n)
{
shnolist *head,*p,*r;
int i;
head=setnull();
r=head;
for(i=0;i<n;i++)
{ p=(shnolist *)malloc(sizeof(shnolist));
p->pb=a[i];
p->next=NULL;
r->next=p;
r=p;
}
return(head);
}
void valuelist(shnolist *L)
{
shnolist *head,*p;
int j=0;
int i;
datatype temp,s;
head=L;
p=head->next;
temp=0;
while(j<max_PN)
{
p->p_sum=temp;
temp=temp+p->pb;
p->kl=-3.322*log10(p->pb)+1;
/*编码,*/
{
s=p->p_sum;
for(i=0;i<p->kl;i++)
p->code[i]=0;
for(i=0;i<p->kl;i++)
{
p->code[i]=2*s;
if(2*s>=1)
s=2*s-1;
else if(2*s==0)
break;
else s=2*s;
}
}
j++;
p=p->next;
}
}
int main(void)
{
shnolist *head;
pb_scan();
pb_sort();
head=my_creat(sym_arry,max_PN);
valuelist(head);
codedisp(head);
}
运行结果:
(4)Huffman编码C语言程序:
#include<stdio.h>
#include<conio.h>
#include<iostream.h>
#include<string.h>
#include<stdlib.h>
#define MAXVALUE 10000 /*权值最大值*/
#define MAXLEAF 30 /*叶子最多个数*/
#define MAXNODE MAXLEAF*2-1 /* 结点数的个数*/
#define MAXBIT 50 /*编码的最大位数*/
typedef struct node /*结点类型定义*/
{
char letter;
int weight;
int parent;
int lchild;
int rchild;
}HNodeType;
typedef struct /*编码类型定义*/
{
char letter;
int bit[MAXBIT];
int start;
}HCodeType;
typedef struct /*输入符号的类型*/
{
char s;
int num;
}lable;
void HuffmanTree(HNodeType HuffNode[],int n,lable a[])
{
int i,j,m1,m2,x1,x2,temp1;
char temp2;
for (i=0;i<2*n-1;i++) /*结点初始化*/
{
HuffNode[i].letter=0;
HuffNode[i].weight=0;
HuffNode[i].parent=-1;
HuffNode[i].lchild=-1;
HuffNode[i].rchild=-1;
}
for (i=0;i<n-1;i++)
for (j=i+1;j<n-1;j++) /*对输入字符按权值大小进行排序*/
if (a[j].num>a[i].num)
{
temp1=a[i].num;
a[i].num=a[j].num;
a[j].num=temp1;
temp2=a[i].s;
a[i].s=a[j].s;
a[j].s=temp2;
}
for (i=0;i<n;i++)
{
HuffNode[i].weight=a[i].num;
HuffNode[i].letter=a[i].s;
}
for (i=0;i<n-1;i++) /*构造huffman树*/
{
m1=m2=MAXVALUE;
x1=x2=0;
for (j=0;j<n+i;j++)/*寻找权值最小与次小的结点*/
{
if (HuffNode[j].parent==-1&&HuffNode[j].weight<m1)
{
m2=m1;
x2=x1;
m1=HuffNode[j].weight;
x1=j;
}
else if (HuffNode[j].parent==-1&&HuffNode[j].weight<m2)
{
m2=HuffNode[j].weight;
x2=j;
}
}
HuffNode[x1].parent=n+i;
HuffNode[x2].parent=n+i; /*权值最小与次小的结点进行组合*/
HuffNode[n+i].weight=HuffNode[x1].weight+HuffNode[x2].weight;
HuffNode[n+i].lchild=x1;
HuffNode[n+i].rchild=x2;
}
}
void HuffmanCode(int n,lable a[])
{
HNodeType HuffNode[MAXNODE];
HCodeType HuffCode[MAXLEAF],cd;
int i,j,c,p;
HuffmanTree(HuffNode,n,a);
for (i=0;i<n;i++) /*按结点位置进行编码*/
{
cd.start=n-1;
c=i;
p=HuffNode[c].parent;
while (p!=-1)
{
if (HuffNode[p].lchild==c)
cd.bit[cd.start]=0;
else cd.bit[cd.start]=1;
cd.start--;
c=p;
p=HuffNode[c].parent;
}
for (j=cd.start+1;j<n;j++) /*储存编码*/
HuffCode[i].bit[j]=cd.bit[j];
HuffCode[i].start=cd.start;
}
for (i=0;i<n;i++)
{
HuffCode[i].letter=HuffNode[i].letter;
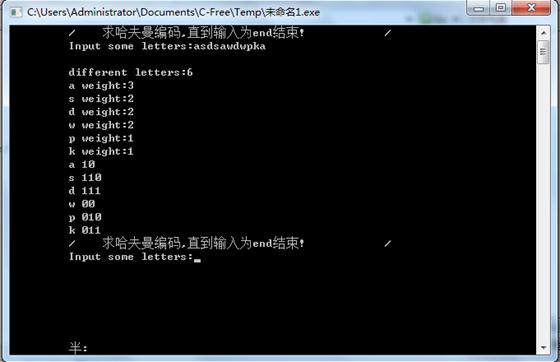
printf(" %c ",HuffCode[i].letter);
for (j=HuffCode[i].start+1;j<n;j++)
printf("%d",HuffCode[i].bit[j]);
printf("\n");
}
}
int main()
{
lable data[30];
char s[100],*p;
int i,count=0;
for (;;)
{
cout<<" / 求哈夫曼编码,直到输入为end结束! /"<<endl;
printf(" Input some letters:");
scanf("%s",s);
if (!strcmp(s,"end"))
exit(0);
for (i=0;i<30;i++)
{
data[i].s=0;
data[i].num=0;
}
p=s;
while (*p) /*计算字符个数与出现次数(即权值)*/
{
for (i=0;i<=count+1;i++)
{
if (data[i].s==0)
{
data[i].s=*p;
data[i].num++;
count++;
break;
}
else if (data[i].s==*p)
{
data[i].num++;
break;
}
}
p++;
}
printf("\n");
printf(" different letters:%d\n",count);
for (i=0;i<count;i++)
{
printf(" %c ",data[i].s);
printf("weight:%d\n",data[i].num);
}
HuffmanCode(count,data);
count=0;
}
getch();
}
运行结果:
五、 实验心得
通过本次试验,熟悉了matlab和excel的使用方法以及在信息论中的使用方法,加强了课程框架的理解。在这次实验中,再次对信息论与编码有了更深层的理解,以前只是通过书上的理论推导,对相关的计算不是特别理解,通过这次的上机实际操作,以及函数图形的绘制,让我对熵函数有了更多的感性认识。
六 、附录
参考书籍:
《matlab数字图像处理》 20## 机械工业出版社
《数字信号处理》 20## 机械工业出版社
《信息论与编码(第二版)》姜丹编著中国科学技术大学出版社
-
大三下-信息论实验报告
实验1绘制二进熵函数曲线串联信道容量曲线一实验内容用Excel或Matlab软件制作二进熵函数曲线串联信道容量曲线二实验环境1计算…
-
信息论实验报告
信息论实验实验一哈夫曼编码HuffmanCoding是一种编码方式哈夫曼编码是可变字长编码VLC的一种Huffman于19xx年提…
-
信息论实验报告
信息论与编码上机实验报告实验名称信息论与编码学院计算机与通信工程学院专业班级计算机1004姓名李春醒学号4105034920xx年…
-
信息论实验报告
实验一唯一可译码的判决准则实验目的1进一步熟悉唯一可译码的判决准则2掌握程序字符处理程序的设计和调试技术实验要求已知信源个数r码字…
-
信息论与编码实验报告
中南大学信息论与编码实验报告姓名xxxxx学号xxxxxxxx专业电子信息工程班级电子信息xxxx班指导老师xx实验一关于信源熵的…
-
信息论与编码实验报告
课程名称姓名系专业年级学号指导教师职称实验报告信息论与编码年月日目录实验一信源熵值的计算1实验二Huffman信源编码5实验三Sh…
-
信息论与编码实验报告-Shannon编码
课程名称姓名系专业年级学号指导教师职称实验报告信息论与编码年月日1实验三Shannon编码一实验目的1熟悉离散信源的特点2学习仿真…
-
信息论与编码实验2-实验报告
中南大学信息论与编码题目关于编码的实验学生姓名杨家骏指导教师赵颖学院信息科学与工程学院学号0909101123专业班级电子信息10…
-
中南大学信息论与编码编码部分实验报告
信息论与编码编码部分实验报告课程名称信息论与编码实验名称关于香农码费诺码Huffman码的实验学院信息科学与工程学院班级电子信息工…
-
二元霍夫曼编码 - 信息论与编码实验报告
计算机与信息工程学院综合性实验报告一实验目的根据霍夫曼编码的原理用MATLAB设计进行霍夫曼编码的程序并得出正确的结果二实验仪器或…