数据库系统设计期末考总结
数据库系统设计期末考总结
? 什么是数据库?
数据库是被一个系统所使用的所有数据的集合
数据库管理员(Database Administrator)
? 什么是数据库管理系统?(DBMS)
数据库管理系统就是帮助存储,管理和使用数据库的程序的集合,对数据库进行统一的管理和控制,以保证数据库的安全性和完整性
? DBMS(database management system)数据库管理系统
环境组成
硬件,软件,数据,程序(procedures),人
? 数据库系统开发生命周期(database system
development lifecycle)

? 数据库设计的三个主要步骤:
概念设计
逻辑设计
物理设计
? C/S vs B/S
C/S 即Client/Server (客户机/服务器) 结构,通过将任务合理分配到Client端和Server端,降低了系统的通讯开销,需要安装客户端才可进行管理操作。
客户端和服务器端的程序不同,用户的程序主要在客户端,服务器端主要提供数据管理、数据共享、数据及系统维护和并发控制等,客户端程序主要完成用户的具体的业务。
开发比较容易,操作简便,但应用程序的升级和客户端程序的维护较为困难。
三层C/S构架
在三层架构中,客户端接受用户的请求,客户端向应用服务提出请求,应用服务从数据库服务中获得数据,应用服务将数据进行计算并将结果提交给客户端,客户端将结果呈现给用户。
? 两层和三层的区别?
两层架构
Client side presented two problems preventing true scalability:
? ?Fat? client, requiring considerable resources on
client?s computer to run effectively.
? Significant client side administration overhead.
? By 1995, three layers proposed, each potentially
running on a different platform.
客户端提出的两个问题阻止真正的可伸缩性:
脂肪”客户端,需要相当大的客户端电脑上的资源有效地运行。
重大的客户端管理开销。
三层架构 Advantages:
? ‘Thin’ client, requiring less expensive hardware.
? Application maintenance centralized.
? Easier to modify or replace one tier without affecting
others.
? Separating business logic from database functions
makes it easier to implement load balancing.
? Maps quite naturally to Web environment.
优点:
瘦”客户机,需要更少的昂贵的硬件。
应用程序维护集中。
容易修改或替换一个层而不影响其他。
将业务逻辑与数据库函数分开使其容易实现负载平衡。
很自然地映射到Web环境。
Three main types of transactions(三种主要类型的事务):
retrieval transactions检索事务
update transactions更新交易处理
mixed transactions混合事项
B/S
即Browser/Server (浏览器/服务器) 结构,用户界面完全通过WWW浏览器实现。
客户端基本上没有专门的应用程序,应用程序基本上都在服务器端。由于客户端没有程序,应用程序的升级和维护都可以在服务器端完成,升级维护方便。由于客户端使用浏览器,使得用户界面“丰富多彩”,但数据的打印输出等功能受到了限制。
? SQL
SQL分类:
DDL—数据定义语言(CREATE,ALTER,DROP,DECLARE) DML—数据操纵语言(SELECT,DELETE,UPDATE,INSERT) DCL—数据控制语言(GRANT,REVOKE,COMMIT
? Query(查询)
? Security(安全)
? Index(索引)
? View(视图)
? ERD
A five-step process for ERD construction :
ERD构建五个步骤的过程:
? Step1: Represent Entities as Tables(将实体转换成表) ? Step2: Determine Relationships(确定关系)
? In most cases, a record in one table will
correspond to multiple records in another table.
在大多数情况下,一个表的记录将对应于另一个表中
的多条记录。
? For many-to-many relationships, a new
associative table must be created between two
tables. 多对多关系,必须创建一个新的关联表两个
表之间的关系。
? Step3:List Fields(确定表的属性)
? Step4: Identify Keys(确定键,主键和外键)
? Step5: Determining Data Types确定数据类型
? Primary and foreign keys must match in data type
and size. 主键和外键必须匹配的数据类型和大小。
2.主键
A primary key uniquely identifies each record in a table.
主键唯一标示表中的每一条记录。
? Unique
? Minimal
? Not Null
? Nonupdateable
3.外键
如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键。
4.完整性
实体完整性:每个表一定要有一个合法主键。(主键值唯一) 参照完整性规则(Referential Integrity):若属性组F是关系模式R1的主键,同时F也是关系模式R2的外键,则在R2的关系中,F的取值只允许两种可能:空值或等于R1关系中
某个主键值。(外键,的值在主键中没有出现)
5.范式
第一范式:(1NF)强调的是列的原子性,即列不能够再分成其他几列。 Definition: A table in which all fields contain a single value.
第二范式:(2NF)属性完全依赖于主键Definition: A table in which each non-key field is determined by the whole primary key and not part of the primary key by itself.
没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
第三范式:(3NF)属性不依赖于其它非主属性
首先是 2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
6.Normalization规范化
没有进行规范化的数据存在插入(表没有分开,插入数据是产生异常),更新(数据冗余,更新时产生异常),删除异常(表没有分开,数据间存在依赖关系)同一张表自身设计不合理导致异常
规范化的优缺点
优点:
? 消除更新异常
? 减少数据冗余
? 解决了数据完整性问题
? 节省存储空间
缺点:
? 涉及多表的子查询和表之间的联接,需要更复杂的SQL语
句
? DBMS的额外工作使应用程序变慢
7.关系型数据库优点
? 依赖逻辑,而不是物理、相关记录之间的联系
? 使用第四代语言(4 gl)
? 备抵高度的数据独立性
? Weak Entity(弱实体)
一个实体对于另一个实体具有很强的依赖关系,而且该实体主键的一部分或者全部都是从其他强实体中获得,则称该实体为弱实体
? Derived attribute(派生属性)
Attribute that represents a value that is derivable from value of a related attribute, or set of
attributes, not necessarily in the same entity. 属性代表了一个值从一个相关属性中派生出来的,或一组属性的值引出,,不一定在同一个实体。
? recursive relationship(递归关系)
添加一个外键,使得有一对多的关系,多对多关系
? complex relationship(复杂关系)
Multiplicity is the number (or range) of possible occurrences of an entity type in an n-ary relationship when other (n-1) values are fixed.
? problems in an ER model
Often due to a misinterpretation of the meaning of certain relationships.
通常由于特定的意义关系的误解。 connection traps. (连接陷阱)
俩个主要的连接陷进:扇形陷进和深坑陷进
扇形陷进:两个实体有一个一对多的关系,从而扇出第三个实体,两个实体键本该有一个直接关系提供必要信息 深坑陷进:一个模型显示实体之间的存在关系,但某些实体出现之间的路径不存在。
? Supertype/Subtype Hierarchies(超类和子类) 某个实体类型中所有实体同时也是另一个实体类型的实体.此时,我们称前一实体类型是后一实体类型的子类
(Subtype),后一实体类型称为超类(Supertype).
但是子类有一个很重要的性质:继承性。子类继承其超类上定义的所有属性,其本身还可以包含其他另外的属性.
第九章:
磁盘的性能指标:磁盘的容量,存取时间,数据传输速度,可靠性
磁盘的总容量
记录盘面数*每记录盘面的磁道数*每磁道的扇区数*每扇区的字节数
扇区:扇区是磁盘寻址的最小单位,其大小通常是512字节 数据在磁盘上的定位信息:柱面号,磁头号,扇区号
编址方法:柱面从外向内编址(如:0~199),磁道按柱面编号(如:0号柱面从上向下编号0~19,再给1号柱面磁道编号),盘块号(假设每个磁道有17个扇区,0号柱面0号磁道0号扇区的盘块号为0,0号柱面1号磁道0号扇区的盘块号为17)
Access time (存取时间)– the time it takes from when a read or write request is issued to when data transfer begins. (一个读或写请求发出到数据开始传输的时间) Consists of: Seek time (寻道时间)– time it takes to reposition the arm over the correct track.
? 将磁头移到柱面的时间:约2~30ms
Rotational latency (旋转等待时间)– time it takes for the sector to be accessed to appear under the head.
? 约10~20ms
? 总时间:10~40ms
Data-transfer rate – the rate at which data can be
retrieved from or stored to the disk. (从磁盘上读取数据或存储数据到磁盘的时间)
Mean time to failure (MTTF) (平均失效时间)– the average time the disk is expected to run continuously without any failure.(磁盘无故障连续运行的时间Typically 3 to 5 years)
Block – a contiguous sequence of sectors from a single track
data is transferred between disk and main memory in blocks sizes range from 512 bytes to several kilobytes
内存和外存的一次数据交换称为一次I/O操作,每次交换的数据量是一个Block
内存中开辟的缓冲区大小至少要等于一个block
Block的大小通常由DBMS厂商决定
廉价磁盘冗余阵列(RAID) Redundant Arrays of Independent Disks
通过冗余提高可靠性
是一种利用大量廉价磁盘进行磁盘组织的技术
价格上,大量廉价的磁盘比少量昂贵的大磁盘合算得多
性能上,使用大量磁盘可以提高数据的并行存取
可靠性上,冗余数据可以存放在多个磁盘上,因此一个磁盘的故障不会导致数据丢失
冗余(Redundancy)
存储额外的信息,以便当磁盘故障时能从中重建
磁盘还是内存?
? 5-minute rule:如果一个被随机访问的页面的使用频率
超过每5分钟一次,那么它应该被驻留在内存
? minute rule:如果被顺序访问的页面的使用频率超过每
1分钟一次,那么它应该被驻留在内存
文件存储:
The database is stored as a collection of files. Each file is a sequence of records. A record is a sequence of fields
数据库是存储为文件的集合。每个文件都是一个序列的记录。字段的记录是一个序列。
第十章:
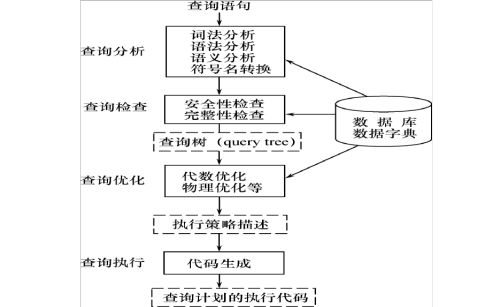
Basic Steps in Query Processing(查询处理的基本步骤):
1. Parsing and translation解析和翻译
2. Optimization最优化
3. Evaluation评估
RDBMS查询处理阶段 :
1. 查询分析
2. 查询检查
3. 查询优化
4. 查询执行
选择操作典型实现方法:
1. 简单的全表扫描方法
? 对查询的基本表顺序扫描,逐一检查每个元组是否满足选择
条件,把满足条件的元组作为结果输出
? 适合小表,不适合大表
2. 索引(或散列)扫描方法
? 适合选择条件中的属性上有索引(例如B+树索引或Hash索
引)
? 通过索引先找到满足条件的元组主码或元组指针,再通过元
组指针直接在查询的基本表中找到元组
排序
? 原因
? SQL查询可以指定对输出进行排序
? 关系运算的某些操作,如连接运算,排序后实现高效
? 对于可放进内存的关系,使用如快排序之类的技术。对不能放进内存的关系,
使用外排序
? 内排序
? 当数据集小于可用内存时,采用快速排序算法
? 快速排序的思想来源于分治策略。将数据块划分为两个
序列,第一个序列的值小于第二个序列,在两个序列中按照递归
排序的思想再次进行上述的划分,这样直到没有办法划分为止
? 外排序
? 创建有序段+N路归并
? 所有的输入数据最初分成许多有序的归并段文件,然后
不断归并成许多更大的归并段文件,直到剩下一个文件为止
? Join Operation
几种不同的连接算法
Nested-loop join(嵌套循环连接)
Block nested-loop join(块嵌套循环连接)
Indexed nested-loop join(索引嵌套循环连接)
Merge-join(合并连接)
Hash-join(哈希或散列连接)
Choice based on cost estimate(根据成本估算选择连接方式) 关系型数据库优点
? 依赖逻辑,而不是物理、相关记录之间的联系
? 使用第四代语言(4 gl)
? 备抵高度的数据独立性
? 关系数据库系统的查询优化
? 查询优化的优点不仅在于用户不必考虑如何最好地表达查询
以获得较好的效率,而且在于系统可以比用户程序的“优化”做得更好
(1) 优化器可以从数据字典中获取许多统计信息,而用户程序则难以获得这些信息
(2)如果数据库的物理统计信息改变了,系统可以自动对查询重新优化以选择相适应的执行计划。在非关系系统中必须重写程序,而重写程序在实际应用中往往是不太可能的
(3)优化器可以考虑数百种不同的执行计划,程序员一般只能考虑有限的几种可能性。
(4)优化器中包括了很多复杂的优化技术,这些优化技术往往只有最好的程序员才能掌握。系统的自动优化相当于使得所有人都拥有这些优化技术
? RDBMS关系型数据库管理系统(Relational Database Management
System)通过某种等价模型计算出各种查询执行策略的执行代价,然后选取代价最小的执行方案
? 集中式数据库
? 执行开销主要包括:
– 磁盘存取块数(I/O代价)
– 处理机时间(CPU代价)
– 查询的内存开销
? I/O代价是最主要的
? 分布式数据库
? 总代价=I/O代价+CPU代价+内存代价+通信代价
? 查询优化的总目标:
? 选择有效的策略
? 求得给定关系表达式的值
? 使得查询代价最小(实际上是较小)
? 实际系统的查询优化步骤:
1. 将查询转换成某种内部表示,通常是语法树
2. 根据一定的等价变换规则把语法树转换成标准(优化)形式
3. 选择低层的操作算法
对于语法树中的每一个操作
? 计算各种执行算法的执行代价
? 选择代价小的执行算法
4. 生成查询计划(查询执行方案) 查询计划是由一系列内部操作组成的。
2 代 数 优 化
? 代数优化策略:通过对关系代数表达式的等价变换来提高查询
效率
? 关系代数表达式的等价:指用相同的关系代替两个表达式中相
应的关系所得到的结果是相同的
? 两个关系表达式E1和E2是等价的,可记为E1≡E2
具体方法 笛卡尔积
? 查询树的启发式优化
? 典型的启发式规则:
1. 选择运算应尽可能先做。在优化策略中这是最重要、最基本的一条
2. 把投影运算和选择运算同时进行
如有若干投影和选择运算,并且它们都对同一个关系操作,则可以在扫描此关系的同时完成所有的这些运算以避免重复扫描关系
3. 把投影同其前或其后的双目运算结合起来
4. 把某些选择同在它前面要执行的笛卡尔积结合起来成为一个连接运算
5. 找出公共子表达式
如果这种重复出现的子表达式的结果不是很大的关系并且从外存中读入这个关系比计算该子表达式的时间少得多,则先计算一次公共子表达式并把结果写入中间文件是合算的
当查询的是视图时,定义视图的表达式就是公共子表达式的情况
6. 在执行连接操作前对关系适当进行预处理
? 按连接属性排序
? 在连接属性上建立索引
? 索引:
? Search Key(检索关键字) - attribute to set of attributes
used to look up records in a file.(设置属性用于查找在一个文件中的记录)
An index file consists of records (called index entries) of the form(一个索引文件包括记录表格即索引项表)
Index files are typically much smaller than the original file (索引文件比源文件小很多)
? Two basic kinds of indices(两种基本索引):
Ordered indices(指令索引): search keys are stored in sorted order(按照顺序搜索密钥存储)
Hash indices(哈希索引): search keys are distributed
uniformly across “buckets” using a “hash function”.(检索关键字均匀分布哈希函数的桶中)
? clustering index聚簇索引:
Primary index: in a sequentially ordered file, the index whose search key specifies the sequential order of the file.初级索引:在一个顺序文件、索引的搜索键指定文件的顺序。

Also called clustering index聚簇索引
The search key of a primary index is usually but not
necessarily the primary key.主索引的检索关键字通常但不一定是主键。
? non-clustering index.非聚簇索引
Secondary index: an index whose search key specifies an order different from the sequential order of the file. 索引的检索关键字指定一个顺序不同于文件中的顺序。 Also called
non-clustering index.非聚簇索引
? Dense Index Files(密集索引文件)指向行
Index record appears for every search-key value in the file. 索引记录对应每个检索关键字的值(一一对应) ? Sparse Index Files(稀疏索引文件)指向页
contains index records for only some search-key values. 只包含一些search-key值索引记录。
Applicable when records are sequentially ordered on
search-key适用于记录顺序记录检索关键字
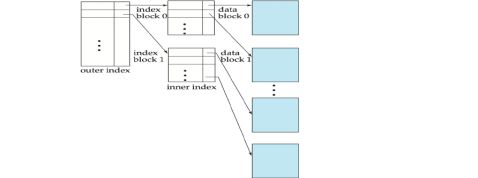
? Multilevel Index
? 冲突可串行化
? 冲突指令
当两条指令是不同事务在相同数据项上的操作,并且其中至少有一个是write指令时,则称这两条指令是冲突的 如在②、③、④情况下,Ii与Ij 是冲突的
非冲突指令交换次序不会影响调度的最终结果
? 冲突等价
如果调度S可以经过一系列非冲突指令交换转换成调度S',则称调度S与S'是冲突等价的
? B-tree
B+-tree indices are an alternative to indexed-sequential files(B+ 树索引是连续索引文件的替换)
? Disadvantage of indexed-sequential files(顺序索引文件的
缺点)
+
? performance degrades as file grows, since many overflow
blocks get created. (随着文件的增多,性能会有所下降,因为创建了许多溢出块)
? Periodic reorganization of entire file is required.(必
须定期重组整个文件)
? Advantage of B+-tree index files(B+-tree的优点): ? automatically reorganizes itself with small, local,
changes, in the face of insertions and deletions.(在进行插入和删除的时候,能自动对备份和更改进行整理)
? Reorganization of entire file is not required to maintain
performance.(对于性能的维护,不需要对整个文件进行重组) ? (Minor) disadvantage of B+-trees(缺点):
extra insertion and deletion overhead, space overhead. (额外的插入和删除开销,空间开销。)
Advantages of B+-trees outweigh disadvantages,B+-trees are used extensively(B+-trees优点大于缺点,被广泛使用)
? A B+-tree is a rooted tree satisfying the following
properties(B+-tree具备以下属性):
All paths from root to leaf are of the same length(所有树枝从根到叶的长度相同)
Each node that is not a root or a leaf has between n/2 and n children.(每个不是根节点也不是叶子节点的节点有n/2到n个孩子节点)
A leaf node has between ?(n–1)/2? and n–1 values
特殊情况: 如果根不是一片叶子,它至少有两个孩子。 如果根是叶(即没有其他节点树),它可以有0到(n - 1)之间的值。 B+-Tree Node Structure(节点结构)
P1是指针,指向子节点(非叶子结点)或指向记录内容(叶子结点) Ki are the search-key values
K1是关键字检索值
B+-Tree中的叶子结点
? ACID properties of a Transaction(事务的ACID属性)
? 原子性(Atomicity):一个事务中的所有操作要么
全部成功,要么全部失败。原子性由恢复机制实现。
? 一致性(Consistency):事务完成后,所有数据处
于应有的状态,所有内部结构正确,能够准确反映事务
所作的工作。基于隔离性实现。
? 隔离性(Isolation):一个事务不会干扰另一个事
务的进程,事务交叉调度执行的结果与串行调度执行的
结果是一致的。隔离性由并发控制机制实现。

? 持久性(Durability):事务提交后,对数据库的影
响是持久的,即不会因为系统故障影响事务的持久性。
持久性由恢复机制实现。
? 事务调度:
? 事务的执行顺序称为一个调度,表示事务的指令在系统中执行
的时间顺序
? 一组事务的调度必须保证
? 包含了所有事务的操作指令
? 一个事务中指令的顺序必须保持不变
? 串行调度
? 在串行调度中,属于同一事务的指令紧挨在一起
? 对于有n个事务的事务组,可以有n!个有效调度
? 并行调度
? 在并行调度中,来自不同事务的指令可以交叉执行
? 当并行调度等价于某个串行调度时,则称它是正确的
? 锁
? 锁的作用
? 一个事务对某个数据对象加锁,取得对它一定的控制,
限制其它事务对该数据对象的使用,由此提供事务需要的隔离性,
保证各个事务不会互相干扰,一个事务不会读取或修改另一个事
务正在使用的数据。
? 此外,锁提供的隔离性还保证事务的一致性。
? 为了使系统性能良好,应使事务尽量简短和不受干扰。
? 要访问一个数据项R,事务Ti必须先申请对R的封锁,
如果R已经被事务Tj加了不相容的锁,则Ti需要等待,直至Tj
释放它的封锁
? 锁的模式主要有六种:共享锁、更新锁、排他锁、结构锁、意向锁和块更新
锁。
? 共享锁(S锁,Share lock)
? 事务T对数据对象R加上S锁,则其它事务对R的X锁
请求不能成功,而对R的S锁请求可以成功;又称读锁
? 申请对R的共享锁: lock-S(R)
? 用于只读数据操作,它允许多个并发事务读取(Select)
锁定资源,但禁止其它事务对锁定的资源进行修改。一般读取数
据后就释放共享锁,除非要将锁升级。
? 排它锁(X锁,eXclusive lock)
? 事务T对数据对象R加上X锁,则其它事务对R的任何
封锁请求都不能成功,直至T释放R上的X锁;又称写锁
? 申请对R的排它锁:lock-X(R)
? 一般来说,SQL Server在事务结束时释放排他锁。
Two-Phase Locking Protocol
? 两阶段封锁协议内容
? 增长阶段(Growing Phase)
? 事务可以获得锁,但不能释放锁
? 缩减阶段(Shrinking Phase)
事务可以释放锁,但不能获得锁
? 封锁点:事务获得其最后封锁的时间
? 事务调度等价于和它们的封锁点顺序一致的串行调度
死锁:
两个事务都封锁了一些数据对象,并相互等待对方释放另一些数据对象以便对其封锁,结果两个事务都不能结束,则发生死锁
? 死锁发生的条件
①互斥条件:事务请求对资源的独占控制
②占有等待条件:事务已持有一定资源,又去申请并等待其它资源
③非抢占条件:直到资源被持有它的事务释放之前,不可能将该资源强制从持有它的事务夺去
④循环等待条件:存在事务相互等待的等待圈
? 预防死锁
?
预先占据所需的全部资源,要么一次全部封锁要么全不
封锁
缺点:难于预知需要封锁哪些数据并且数据使用率低
所有资源预先排序,事务按规定顺序封锁数据
使用抢占与事务回滚
? wait-die:如果T1等待T2,仅当T1的时间戳小于T2时,允许T1等待,否则回滚T1。
? wound-wait:如果T1等待T2,仅当T1的时间戳大于T2时,允许T1等待,否则回滚T2
? 死锁检测和恢复
? 超时法
如果等待封锁的时间超过限时,则撤消该事务
? 等待图法 ? ?
-
系统设计总结报告
一、团队分工合作及管理心得体会单片机课程是分小组进行的,这要求每个组员都要有明确的分工和积极的团队精神。我们小组由三个人组成,在单…
-
系统设计总结报告
*********一、所遇问题及解决方案问题1:不能正常打开ICCAVR软件。解决方案:由于用ICCAVR软件要进行破解,需要用到…
-
系统设计总结
系统设计总结报告许亚张自洋赵健赵斌一、关于选题在拿到实验题目后,进行了仔细的比较和研究,对各种类型题目特点及难易度有较深的理解,再…
-
学生管理系统 设计总结
概述随着计算机技术的发展,特别是计算机网络技术与数据库技术的发展,使用人们的生活与工作方式发生了很大的改变。现代化管理高效、简洁,…
-
体育馆智能化系统设计总结
南京奥体中心智能化系统设计总结南京奥林匹克体育中心(见下图)位于南京市的河西区,紧邻长江,是江苏省有史以来最大规模的社会公益事业项…
-
数据库系统设计报告及项目总结
我对数据库的制作是为了能够更方便更快捷的对学生基本信息、系部基本信息、课程信息、教职工信息以及学生成绩进行查询。数据库的最终效果是…
-
数据库设计报告范文1
图书管理系统的开发与实现摘要:图书管理系统是典型的信息管理系统(MIS),其开发主要包括后台数据库的建立和维护以及前端应用程序的开…
-
数据库课程设计总结报告
漳州师范学院数据库课程设计个人日程管理系统姓名某某学号系别计算机科学与工程专业计算机科学技术专业年级08级指导教师陈志翔王桃发20…
-
数据库系统设计上机实验报告
数据库系统设计上机实验报告院系人文经管学院专业信息管理和信息系统上机实习报告目录一上机实验报告简介21上机实验时间安排22上机实验…
-
SQLServer数据库课程设计报告
武汉工业学院数据库系统课程设计说明书设计题目选课管理系统姓名学院专业学号指导教师20xx年6月8日一读书笔记1SQL数据库的实际应…
-
系统设计总结报告
一、团队分工合作及管理心得体会单片机课程是分小组进行的,这要求每个组员都要有明确的分工和积极的团队精神。我们小组由三个人组成,在单…