模式识别方PCA实验报告
模式识别作业
《模式识别》大作业人脸识别方法一
---- 基于PCA和欧几里得距离判据的模板匹配分类器
一、 理论知识
1、主成分分析
主成分分析是把多个特征映射为少数几个综合特征的一种统计分析方法。在多特征的研究中,往往由于特征个数太多,且彼此之间存在着一定的相关性,因而使得所观测的数据在一定程度上有信息的重叠。当特征较多时,在高维空间中研究样本的分布规律就更麻烦。主成分分析采取一种降维的方法,找出几个综合因子来代表原来众多的特征,使这些综合因子尽可能地反映原来变量的信息,而且彼此之间互不相关,从而达到简化的目的。主成分的表示相当于把原来的特征进行坐标变换(乘以一个变换矩阵),得到相关性较小(严格来说是零)的综合因子。
1.1 问题的提出
一般来说,如果N个样品中的每个样品有n个特征 ,经过主成分分析,将它们综合成n综合变量,即
,经过主成分分析,将它们综合成n综合变量,即
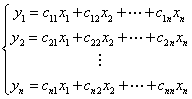
 由下列原则决定:
由下列原则决定:
1、 和
和 (
( ,i,j = 1,2,...n)相互独立;
,i,j = 1,2,...n)相互独立;
2、y的排序原则是方差从大到小。这样的综合指标因子分别是原变量的第1、第2、……、第n个主分量,它们的方差依次递减。
1.2 主成分的导出
我们观察上述方程组,用我们熟知的矩阵表示,设 是一个n维随机向量,
是一个n维随机向量, 是满足上式的新变量所构成的向量。于是我们可以写成Y=CX,C是一个正交矩阵,满足CC’=I。
是满足上式的新变量所构成的向量。于是我们可以写成Y=CX,C是一个正交矩阵,满足CC’=I。
坐标旋转是指新坐标轴相互正交,仍构成一个直角坐标系。变换后的N个点在 轴上有最大方差,而在
轴上有最大方差,而在 轴上有最小方差。同时,注意上面第一条原则,由此我们要求轴和轴的协方差为零,那么要求
轴上有最小方差。同时,注意上面第一条原则,由此我们要求轴和轴的协方差为零,那么要求


令 ,则
,则
经过上面式子的变换,我们得到以下n个方程

1.3 主成分分析的结果
我们要求解出C,即解出上述齐次方程的非零解,要求的系数行列式为0。最后得出结论 是
是 的根,的方差为。然后选取前面p个贡献率大的分量,这样就实现了降维。也就是主成分分析的目标。
的根,的方差为。然后选取前面p个贡献率大的分量,这样就实现了降维。也就是主成分分析的目标。
二、 实现方法
1、 获取数据。在编程时具体是把一幅二维的图像转换成一维的;
2、 减去均值。要使PCA正常工作,必须减去数据的均值。减去的均值为每一维的平均,所有的x值都要减去,同样所有的y值都要减去,这样处理后的数据都具有0均值;
3、 计算协方差矩阵;
4、 计算协方差矩阵的特征矢量和特征值。因为协方差矩阵为方阵,我们可以计算它的特征矢量和特征值,它可以告诉我们数据的有用信息;
5、选择成分组成模式矢量
现在可以进行数据压缩降低维数了。如果你观察上一节中的特征矢量和特征值,会注意到那些特征值是十分不同的。事实上,可以证明对应最大特征值的特征矢量就是数据的主成分。
对应大特征值的特征矢量就是那条穿过数据中间的矢量,它是数据维数之间最大的关联。
一般地,从协方差矩阵找到特征矢量以后,下一步就是按照特征值由大到小进行排列,这将给出成分的重要性级别。现在,如果你喜欢,可以忽略那些重要性很小的成分,当然这会丢失一些信息,但是如果对应的特征值很小,你不会丢失很多信息。如果你已经忽略了一些成分,那么最后的数据集将有更少的维数,精确地说,如果你的原始数据是n维的,你选择了前p个主要成分,那么你现在的数据将仅有p维。
现在要做的是你需要组成一个模式矢量,这只是几个矢量组成的矩阵的一个有意思的名字而已,它由你保持的所有特征矢量构成,每一个特征矢量是这个矩阵的一列。
6、获得新数据
这是PCA最后一步,也是最容易的一步。一旦你选择了须要保留的成分(特征矢量)并组成了模式矢量,我们简单地对其进行转置,并将其左乘原始数据的转置:
其中rowFeatureVector是由特征矢量作为列组成的矩阵的转置,因此它的行就是原来的特征矢量,而且对应最大特征值的特征矢量在该矩阵的最上一行。rowdataAdjust是减去均值后的数据,即数据项目在每一列中,每一行就是一维。FinalData是最后得到的数据,数据项目在它的列中,维数沿着行。
FinalData = rowFeatureVector * rowdataAdjust
这将仅仅给出我们选择的数据。我们的原始数据有两个轴(x和y),所以我们的原始数据按这两个轴分布。我们可以按任何两个我们喜欢的轴表示我们的数据。如果这些轴是正交的,这种表达将是最有效的,这就是特征矢量总是正交的重要性。我们已经将我们的数据从原来的xy轴表达变换为现在的单个特征矢量表达。如果我们已经忽略了一些特征矢量,则新数据将会用我们保留的矢量表达。
三、 matlab编程
matlab程序分为三部分。程序框图如下图所示。

四、 总结
从书里看我觉得最让人明白模板匹配分类器的一段话,就是“譬如A类有10个训练样品,就有10个模板,B类有8个训练样品,就有8个模板。任何一个待测样品在分类时与这18个模板都算一算相似度,找出最相似的模板,如果该模板是B类中的一个,就确定待测样品为B类,否则为A类。”意思很简单吧,算相似度就是算距离。就是说,模板匹配就要用你想识别的样品与各类中每个样品的各个模板用距离公式计算距离,距离最短的那个就是最相似的。实验结果表明识别率达90%。
这样的匹配方法明显的缺点就是在计算量大,存储量大,每个测试样品要对每个模板计算一次相似度,如果模板量大的时候,计算量就十分的大。
五、 参考文献
【1】 边肇其,张学工.模式识别【M】.第2版.北京.:清华大学出版社,2000
【2】 周杰,卢春雨,张长水,李衍达,人脸自动识别方法综述【J】.电子学报,2000,5(4):102-106
《模式识别》大作业人脸识别方法二
---- 基于PCA和FLD的人脸识别的线性分类器
一、理论知识
1、fisher概念引出
在应用统计方法解决模式识别问题时,为了解决“维数灾难”的问题,压缩特征空间的维数非常必要。fisher方法实际上涉及到维数压缩的问题。fisher分类器是一种几何分类器, 包括线性分类器和非线性分类器。线性分类器有:感知器算法、增量校正算法、LMSE分类算法、Fisher分类。
若把多维特征空间的点投影到一条直线上,就能把特征空间压缩成一维。那么关键就是找到这条直线的方向,找得好,分得好,找不好,就混在一起。因此fisher方法目标就是找到这个最好的直线方向以及如何实现向最好方向投影的变换。这个投影变换恰是我们所寻求的解向量 ,这是fisher算法的基本问题。
,这是fisher算法的基本问题。
样品训练集以及待测样品的特征数目为n。为了找到最佳投影方向,需要计算出各类均值、样品类内离散度矩阵 和总类间离散度矩阵
和总类间离散度矩阵 、样品类间离散度矩阵
、样品类间离散度矩阵 ,根据Fisher准则,找到最佳投影准则,将训练集内所有样品进行投影,投影到一维Y空间,由于Y空间是一维的,则需要求出Y空间的划分边界点,找到边界点后,就可以对待测样品进行进行一维Y空间的投影,判断它的投影点与分界点的关系,将其归类。
,根据Fisher准则,找到最佳投影准则,将训练集内所有样品进行投影,投影到一维Y空间,由于Y空间是一维的,则需要求出Y空间的划分边界点,找到边界点后,就可以对待测样品进行进行一维Y空间的投影,判断它的投影点与分界点的关系,将其归类。
Fisher法的核心为二字:投影。
二、 实现方法
(1) 计算给类样品均值向量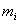 ,是各个类的均值,
,是各个类的均值, 是
是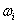 类的样品个数。
类的样品个数。

(2) 计算样品类内离散度矩阵和总类间离散度矩阵

(3) 计算样品类间离散度矩阵

我们希望投影后,在一维Y空间各类样品尽可能地分开,也就是说我们希望两类样品均值之差( )越大越好,同时希望各类样品内部尽量密集,即希望类内离散度越小越好,因此,我们可以定义Fisher准则函数:
)越大越好,同时希望各类样品内部尽量密集,即希望类内离散度越小越好,因此,我们可以定义Fisher准则函数:
使得 取得最大值的为
取得最大值的为 
(5) 将训练集内所有样品进行投影

如果是非奇异的,则要获得类间离散度与类内离散度的比值最大的投影方向的满足下式:

其中 是满足下式的和对应的m个最大特征值所对应的特征向量。注意到该矩阵最多只有C-1个非零特征值,C是类别数。
是满足下式的和对应的m个最大特征值所对应的特征向量。注意到该矩阵最多只有C-1个非零特征值,C是类别数。
2、程序中算法的应用
Fisher线性判别方法(FLD)是在Fisher鉴别准则函数取极值的情况下,求得一个最佳判别方向,然后从高位特征向量投影到该最佳鉴别方向,构成一个一维的判别特征空间。
将Fisher线性判别推广到C-1个判决函数下,即从N维空间向C-1维空间作相应的投影。利用这个m维的投影矩阵M将训练样本n维向量空间转化为m维的MEF空间并且获得在MEF空间上的最佳描述特征,即

由这N个MEF空间上的最佳描述特征可以求出 的样品类内离散度矩阵
的样品类内离散度矩阵 和总类间离散度矩阵,取
和总类间离散度矩阵,取 的K个最大的特征可以构成FLD投影矩阵W。将MEF空间上的最佳描述特征在FLD投影矩阵W上进行投影,将MEF空间降维到MDF空间,并获得对应的MDF空间上的最佳分类特征,即
的K个最大的特征可以构成FLD投影矩阵W。将MEF空间上的最佳描述特征在FLD投影矩阵W上进行投影,将MEF空间降维到MDF空间,并获得对应的MDF空间上的最佳分类特征,即

通过计算 的欧氏距离,可以将训练样本分为C(C等于的秩),完成对训练样本集的分类
的欧氏距离,可以将训练样本分为C(C等于的秩),完成对训练样本集的分类
1、 matlab编程
1、fisher判别法人脸检测与识别流程图

2、matlab程序分为三部分。程序框图如下图所示。

2、 总结
从计算成本来看,PCA+LDA方法的好处在于对高维空间的降维,避免了类内离散度矩阵不可逆的情况。然而,从识别性能来看,由于主成分只是代表图像的灰度特征,是从能量的角度衡量主成分大小的,应用PCA之后,舍弃的对应较小特征值的次要成分有可能对LDA来说重要的分类信息,有可能降低分类识别性能。
而且,在实际应用中,特别是在人脸图像识别中,由于“维数灾难”的存在,FLD通常会遇到两个方面的困难:
(1) 类内离散度矩阵总是奇异的。这是由于的秩最多为N-C,(N是用于训练样本的图像数目,C是人脸的类别数)。而一般情况下,用于训练的图像数目N是远小于每幅图像的像素数目,即“小样本问题“经常出现。
(2) 计算的复杂度。在高维空间中,要得出一个分类向量的复杂度远远高于计算一个低维空间中的分类向量。
3、 参考文献
【1】边肇其,张学工.模式识别【M】.第2版.北京.:清华大学出版社,2000
【2】周杰,卢春雨,张长水,李衍达,人脸自动识别方法综述【J】.电子学报,2000,5(4):102-106
-
上机实验报告格式
网页设计实验报告院部热能学院专业热能与动力工程班级112姓名范金仓学号20xx031388一实验目的及要求1确定网站主题和网站的用…
-
计算机上机实验报告模板
交通与汽车工程学院实验报告课程名称课程代码学院直属系交通与汽车工程学院年级专业班学生姓名学号实验总成绩任课教师开课学院交通与汽车工…
-
上机实验报告格式要求
VB上机实验报告要求1预习报告课程名称姓名实验名称班级学号实验日期指导教师一实验目的及要求本次上机实验所涉及并要求掌握的知识点二实…
-
C语言集中上机实验报告
重庆邮电大学移通学院C语言集中上机实验报告学生学号班级专业重庆邮电大学移通学院20xx年5月重庆邮电大学移通学院目录第一章循环31…
-
上机实验报告
编译原理报告编译原理报告正规式转化为NFA班级19xx31班学号20xx1002284姓名李豪强指导老师刘远兴日期20xx1020…
-
大一C语言上机实验实验报告
指导教师纪良浩学院通信与信息工程专业通信类班级0101022学号20xx210722姓名曾小兵实验室S319实验题目实验一用选择法…
-
汇编上机实验报告心得体会
汇编语言程序设计第一次上机作业1.从键盘上接受一个字符,找出他的前导字符和后继字符,按顺序显示这三个字符。寄存器分配:AL:存输入…
-
CATIA-上机实验报告
重庆交通大学学生实验报告实验课程名称计算机辅助制造开课实验室重庆交通大学计算机中心学院国际学院20xx级专业机械设计制造及其自动化…
-
编译原理上机实验报告
编译技术上机实验题目实验一一题目编制C语言子集的词法分析程序二目的通过设计编制调试一个具体的词法分析程序加深对词法分析原理的理解并…
-
计算机网络上机实验报告
计算机网络课程设计论文设计论文题目计算机网络综合实习课程设计学院名称信息科学与技术学院专业名称通信工程学生姓名杜立华学生学号20x…
-
erp上机实验心得
ERP上机实验心得通过该实验,对所学的知识有了进一步的了解。在实验的过程中,出现了一些问题,不过最后都得以解决。然而通过这些错误,…