学习日志总结_初级
1. 性能优化
a) SQL写法方面:在索引列上避免使用计算、改变类型和使用效率较高的操作符。例如:避免使用*号和NOT,查询表顺序先小后大表(FROM后从右至左处理,from表顺序从右往左表大小依次递增)链接,使用表的别名,减少对表的查询,WHERE后条件的顺序,用EXISTS代替IN,用大于或小于代替不等于,用>=代替>,用右模糊查询(LIKE ‘…%’)代替模糊查询,用UNION ALL代替UNION,union代替or,用truncate代替delete等
b) 设计方面:建立索引;用并行取代串行如数据迁移(并行是多个线程或进程同时处理,串行等待某个进程结束后再进行下一个进程,通过指定/*+parallel(a,并行数)*/,通过多个CPU和I/O处理一个数据库操作);使用临时表处理中间运算过程
c) 性能分析方面:通过查询v$session_wait视图,识别性能瓶颈,纠正存在的问题(动态视图列出造成会话session等待事件);看执行计划(set autotrace traceonly、explain plan for…select * from table(DBMS_XPLAN.display(null,null,’BASIC+PARALLEL’)))定位慢的位置进行优化;使用hints提示查看路径来改变执行计划;定期进行表分析;选用适合的ORACLE优化器:RULE(基于规则)、COST(基于成本)、CHOOSE(选择性),在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描,必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器
2. 索引
a) 数据量大的表,主键,字段唯一约束,查询条件约束字段,查询中与其它表关联字段(外键关系),查询中排序字段,查询中统计或分组的字段需建立索引。组合索引(多个字段)一定要用引导列(组合索引中的第一列),最好少用组合索引增加系统开销
b) 表的记录少,经常处理(插入、删除、修改)的表在查询允许的情况下,数据重复且分布平均的表字段不适合建立索引
3. 数据库设计
a) 三范式:一每一列不可再分,二每条记录唯一性(依赖主键),三表中不包含已在其他表中包含的非主关键字(不依赖于其它非主属性),例:存在一个部门信息表有字段部门编号、部门名称、部门简介,那么在员工信息表中列出部门编号后就不能再有部门名称和部门简介字段避免数据冗余。
b) 在设计大型数据库时把允许为NULL的列放在表的后面,养成写注释的习惯(comment),选择合适的数据类型和长度
c) 建数据库用到建模工具(power designer)建立E-R图,建立主键和外键关系,建立索引,产生建表语句建立数据库
4. 动态SQL
a) 静态SQL语句指在PL/SQL块中使用的SQL语句在编译时是明确的,执行确定的对象
b) 动态SQL语句在编择时SQL语句不确定,根据用户输入不同的参数执行不同的操作,编译程序对动态语句部分不进行处理,只在程序运行时动态的创建语句并对其进行语法分析和执行,本地动态SQL是使用execute immediate语句来实现,另可使用DBMS_SQL包实现如:先将要执行的SQL语句或块放到一个字符串变量中,用parse过程分析该字符串,用bind_variable过程绑定变量,最后用execute函数执行
5. 记录类型
a) RECORD把逻辑相关的资料作为一个单元存储,用%type和%rowtype动态指定,type type_name is record(name 表名.字段%type)
b) 自定义记录类型每个字段类型和表字段相同,且类型已指定,执行性能好。缺点:表字段类型修改后,需要修改记录类型字段。
c) 动态指定记录类型好处:表字段发生变化记录字段自动改变。但每次执行前遇到%type或%rowtype数据系统会去查看对应表字段类型会造成一定的开销。
6. 自治事务
a) 自治事务AT是相对于主事务MT的一个独立事务,当运行到AT块时,MT被挂起,必须等AT中显示的commit或rollback后才会恢复MT,常用于记录日志等
b) 在大型开发中,自治事务可以将代码更加模块化,失败或成功时不会影响调用者的其它操作,代价是调用者失去了对此模块的控制,且模块内部无法引用调用者未提交的数据
c) 自治事务是由父或主事务启动的,独立于其父事务进行操作。如果在自治事务或主事务中使用了回滚或提交,或者发生了错误不会影响其他事务
d) 使用pragma autonomous_transaction创建
7. 锁
a) 锁出现在数据共享场合,用来保证数据的一致性。多个会话同时对一个表或记录进行操作时需对数据锁定
b) 行锁select…for update [wait n] [skip locked],wait字句指定等待其它用户释放锁的秒数,防止无限期等待,优点:防止无期限等待被锁行;允许应用程序中对锁的等待时间控制;对交互式应用程序非常有用,用户不能等待不确定;若使用skip locked则可越过锁定行,不会报告有wait n引发的‘资源忙’的异常报告
c) 表锁Lock table 表名 in <mode>:有share mode共享;share update mode共享更新;exclusive mode排他
8. 游标
a) 显式游标:在PL/SQL程序中CURSOR…IS定义,它可以对查询语句返回的记录进行处理,用时需要定义、打开、使用和关闭,游标属性的前缀是游标名,有%FOUND、%NOTFOUND、%ROWCOUNT、%ISOPEN,可以处理多行数据,在程序中设置循环取出每一行数据
b) 隐式游标:非PL/SQL程序中定义,在PL/SQL中使用insert/update/delete语句时,oracle系统自动分配的游标,不需要打开和关闭,游标属性的前缀是SQL,%ISOPEN总是false,select…into语句,只处理一行数据
9. 包
a) 通常package有头和主体,需要被外部调用的程序及变量在包头中声明
b) 包需要定义一个常量记录包的名称,定义三个全局变量(一个存放函数名,另两个为异常变量),定义一个通用捕捉异常的程序,定义一个抛异常程序
c) 规范对程序功能、参数及编程人员信息时间等加注释说明
d) 异常处理传进的参数以pi开头命名,传出的参数以po开头命名,每个异常增加一个异常参数
e) 事务完整性:子程序不能有commit;锁表后不能进行commit否则锁表失败;通常在主程序的最后进行commit,也要看业务关联性;给form或java调用的包,commit写的form或java中,workflow同理;如果有写日志,在异常处理中先rollback然后更新日志再commit
f) 将相同业务逻辑功能块写在一个函数或过程中,如果在FORM中调用PACKAGE,最好在包中额外写一个子过程,供前台FORM调用
g) 存储过程细分到小功能比较好,功能独立容易维护
10. 异常
a) 异常分为内部和用户自定义异常pragma exception_init(name,-number)两种。内部异常由PL/SQL自动抛出,自定义异常通过raise抛出,RAISE_APPLICATION_ERROR(ERROR_NUMBER,ERROR_MESSAGE[,TRUE/FALSE])错误号范围是-20000到-20999,TRUE/FALSE是将错误添加(TRUE)进错误堆还是覆盖(FALSE),缺省情况下是FALSE
b) 常用异常有no_data_found,too_many_rows,values_error,others等
c) Others异常是不可少的
d) 异常处理:exception when … then
11. 视图
a) 物化视图是包括一个查询结果的数据库对象,它是远程数据的本地副本,或者用来生成基于数据表求和的汇总表。物化视图存储基于远程表的数据,也可以称为快照。
b) 物化视图提供了可伸缩的基于(with primary key|rowid)主键或ROWID的视图,指定了刷新模式ON DEMAND用户需要时进行刷新,ON COMMIT对基表的DML操作提交时刷新、刷新方法(refresh fast|complete|force)、自动刷新的时间(start with date)和间隔(next date)
c) 物化视图和普通视图的区别:物化视图用于预先计算并保存表连接或聚集等耗时较多的操作结果,普通视图查询时在嵌套子查询后去查询原表;物化视图对应用透明,增加和删除不会影响程序中的SQL语句,普通视图会影响原表数据;物化视图需占用存储空间,普通不用;当基表发生变化时,物化视图需刷新,普通不用。
12. 左右连接
a) +号放在等号右边为左连接,右连接相反
b) +号对面的表为主表,所在边为从表,以主表查询结果为主,没有与从表匹配的字段显示为NULL
13. 大小表查询顺序
a) ORACLE在解析sql语句的时候对FROM子句后面的表名是从右往左解析的,是先扫描最右边的表,然后在扫描左边的表,然后用左边的表匹配数据,匹配成功后就合并。 所以,在对多表查询中,一定要把小表写在最右边,为什么自己想想就明白了。例如下面的两个语句:
--No.1 tableA:100w条记录 tableB:1w条记录 执行速度十秒
select count(*) from tableA, tableB;
--No.2 执行速度百秒甚至更高
select count(*) from tableB, tableA;
b) 还有一种是三张表的查询,例如
select count(1) from tableA a,tableB b ,tableC c where a.id=b.id and a.id=c.id;
上面中tableA 为交叉表,根据oracle对From子句从右向左的扫描方式,应该把交叉表放在最末尾,然后才是最小表,所以上面的应该这样写
--tableA a 交叉表
--tabelB b 100w
--tableC c 1w
select count(1) from tableB b ,tableC c ,tableA a where a.id=b.id and a.id=c.id;
14. RETURN和EXIT
a) RETURN返回程序末尾,结束程序
b) EXIT退出循环,相当于java中的break
c) GOTO用于跳转,但会打乱程序逻辑,一般不使用,它可以实现RETURN、EXIT功能
d) 要实现java中continue功能使用自定义异常的方式
15. EXISTS和IN
a) EXISTS判断是否有记录,返回的是一个布尔类型,检索到满足条件退出
b) IN是遍历方式对结果进行比较
c) EXISTS比IN快
16. 表、视图、物化视图和包
a) 表是数据库中的主要结构,表示单个的、特定的集合
b) 视图是来自数据库中的一个或多个表字段组成的一个虚表,不存储数据
c) 物化视图也可称为快照,是包括一个查询结果的数据库对象,它是远程数据的本地副本,或者用来生成基于数据表求和的汇总表
d) 包是程序逻辑处理单位,封装过程(不返回值,不能作为表达式的一部分)和函数(返回单个值,可用变量或常量的表达式中)
17. 临时表
a) 语法create global temporary table test_temp(test_id number,test_desc varchar2(100)) on commit preserve rows会话指定,当中断会话时ORACLE将截断表;on commit delete rows事务指定,每次提交后ORACLE将截断表(删除全部行)
b) 临时表在数据库中保留表结构,但数据只在会话期内有效
c) 访问临时表的性能很高
d) 临时表分为基于事务和会话
e) 可用execute immediate动态创建
f) 应用:1、当某一个SQL语句关联的表在2张及以上,并且和一些小表关联。可以采用将大表进行分拆并且得到比较小的结果集合存放在临时表中;2、程序执行过程中可能需要存放一些临时的数据,这些数据在整个程序的会话过程中都需要用的等等
g) 注意:临时表的索引以及对表的修改、删除等和正常的表是一致的
h) 特性和性能(与普通表和视图的比较)临时表只在当前连接内有效不建立索引,所以如果数据量比较大或进行多次查询时,不推荐使用数据处理比较复杂时表快,反之视图快点在仅仅查询数据的时候建议用游标:open cursor for ‘sql clause’
18. 数据字典
a) ORACLE数据字典有表和视图组成,存储有关数据库结构信息的一些数据库对象。数据库字典描述了实际数据是如何组织的。比如一个表的创建者,创建时间,所属表空间,用户访问权限信息等。
b) 数据字典内容包括:1、数据库中所有模式对象的信息,如表、视图、簇及索引等;2、分配多少空间,当前使用了多少空间等;3、列的缺省值;4、约束信息的完整性;5、ORACLE用户的名字;6、用户及角色被授予的权限;7、用户访问或使用的审计信息;8、其它产生的数据库信息
c) User-用户示图
d) All-所有示图
e) Dba-数据库中所有示图
f) V$-动态性能示图
19. 集成
a) DBLink
b) 通过编程实现,如创建表去同步实际表,按一定的频率和采用增量或全量方式
c) 设计接口表,更新状态查看数据
20. 执行计划
a) 为了执行语句,oracle可能必须实现许多步骤,这些步骤中的每一步可能是从数据库中物理检索数据行,或者用某种方法去准备数据行,供发出语句的用户使用。Oracle用来执行语句的这些步骤的组合称之为执行计划
21. 数据库启动定期运行程序
a) 使用DBMS_JOB.SUBMIT
b) Declare
Job_no number;
Begin
DBMS_JOB.SUBMIT(job_no,’insert_Prod’,sysdate,’TRUNC(sysdate)+1+2/24’);
Commit;
End;
22. 数据初始化
a) 系统分析数据表,确定需要和不需要初始化的数据
b) 用excel收集表数据,确定格式和要素
c) 制定数据初始化方案
d) 编写初始化脚本
e) 建立临时表
f) 建立数据验证环境
g) 出数据验证结果
h) 初始化数据进入正式环境
23. ERP二次开发
a) 禁止修改系统自带的程序
b) 不直接修改系统对象,而是采用弹性域的方式,如一定要修改放在另外的栏位上
c) 采用接口表来访问数据表,尽量采用API栏位
d) 不允许对标准的FORM进行修改
e) 客制化定义的程序要统一放在一个专门的Schema下
f) 客制化的Form,Report要尽量与标准的命名方式以及风格保持一致
g) 能通过系统设置完成的就不要客制化(采用弹性域的方式)
24. FORM开发
a) 了解界面的样式和布局,了解数据来源(基于基础表或视图,基于视图需定义触发器操作基础表)
b) 基于模板开发form,后增加window,canvas,block以及Item(有数据据栏位和非数据库栏位)
c) 有些界面会用到控制按钮,需要把这些控制按钮放在一个统一的block(比如control),修改Item,Block等继承模板的属性
d) 写一些trigger来实现form的一些逻辑
e) 在oracle erp中注册
f) 上传form以及编译
25. REPORT开发
a) 创建数据模型,数据源基于SQL语句,根据业务需要对数据模型增加公式列或增加参数控制
b) 通过向导创建报表布局
c) 将设计好的报表存为RDF文件上传至服务器
d) 注册可执行,注册并发程序(注意输出格式为XML)
e) 分配给相应的请求组
26. XML PUBLISHER开发
a) 设计报表数据模型,不要在布局中建立对象
b) 为报表定义可执行,并发程序,并添加到相应的请组中(注意:要记住可执行的简称;定义并发程序时,输出格式选择XML,打印类型为A4)
c) 生成XML文件,在word中使用XML设计创建RTF模板(要以另存为的方式创建)
d) 在ERP中的Oracle XML Publisher管理员的职责中,使用模板管理器,定义数据源、注册模板;实现XML数据源和模板的关联关系
27. FORM触发器
a) 分为form级,block级和item级三种类型的触发器
b) 先执行form级,然后执行block级,再执行item级
c) 同一级的触发器先执pre(在XXX之前),再执行on(在XXX时),最后执行post(在XXX之后)
d) 可以通过修改trigger的执行层次属性来修改执行顺序(有默为,之前,之后)
28. FORM主从块
a) 可以通过关系向导建立主从块的关系
b) 删除主块记录时可以删除从块资料,设定主记录关系的删除属性为级联即可
29. XML和HTML报表开发
a) XML:准备XML数据源,设计RTF模板,关联数据源与模板
b) HTML:执行一个新的可执行程序,执行方式选择PL/SQL, package中采用fnd_file. put_line进行输出,然后用report builder完成格式的开发(格式为文本文件)
30. 开发注意
a) SQL的使用规范:不能对索引字段使用函数运算
b) 索引的使用规范:尽可能的使用索引字段作为查询条件,一个表中索引不要建立太多
c) 临时表的使用规范:尽量避免使用distinct,order by,group by,having,因为这些语句会加重临时表的负担,避免频繁创建和删除临时表,减少系统表资源的消耗
d) 合理的算法使用:采用多种算法进行比较,以获得消耗资源最少、效率最高的方法
31. 版本管理
a) 最常见的版本工具是cvs、vss,版本管理主要是管理开发过程中的程序和文档,提高多人合作开发的效率,避免程序文件版本过多带来的问题
b) 以vss (6.0和2005两个版本)为例管理流程:在项目立项后,从正式环境中将最新版本程序复制到vss服务器中,在管理员配置相应的访问权限后,开发人员直接从服务器中check out文件到本地,新建文件提交服务器需check in操作,原文件修改后需更新操作到服务器
32. 系统分析
a) 主要任务:系统分析人员与企业各部门管理人员一起,描述、分析对新的管理信息系统的要求,并把双方的理解用系统说明书表达出来
b) 原则是先整后局部
c) 步骤:系统调查(详细调查),业务流程分析,数据流程分析,数据建模,新系统逻辑模型提出,系统说明书
33. 业务系统开发设计
a) 有系统层,业务层,功能层,事务层
b) 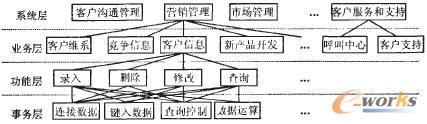
c) 面向业务的构件化设计核心思想是以事务层构件为基础,构建完成不同事务的功能,通过组装功能层构件,再封装为业务层构件,形成业务构件库,再动态组合复用这些构件,整个构件体系结构是一个层次型迭代递进的关系架构。在这个架中,通过组装自治功能的各个业务构件,实现构件的大粒度复用,使不同粒度的构件在应用管理与控制上更加安全可靠
34. 行转列怎么实现?
Case when 或者decode +groupby
35. 列转行怎么实现?
Union all
36. 游标是怎么用的?
游标(CURSOR)也叫光标,在关系数据库中经常使用,在PL/SQL程序中可以用CURSOR与SELECT一起对表或者视图中的数据进行查询并逐行读取。
Oracle游标分为显示游标和隐式游标。
显示游标(Explicit Cursor):在PL/SQL程序中定义的、用于查询的游标称作显示游标。
隐式游标(Implicit Cursor):是指非PL/SQL程序中定义的、而且是在PL/SQL中使用UPDATE/DELETE语句时,Oracle系统自动分配的游标。
一.显示游标
1.使用步骤 (1)定义 (2)打开 (3)使用 (4)关闭
2.使用演示 (1).使用WHILE循环处理游标
create or replace PROCEDURE PROC_STU1 AS
BEGIN --显示游标使用,使用while循环
declare --1.定义游标,名称为cur_stu
cursor cur_stu is
select stuno,stuname from student order by stuno; --定义变量,存放游标取出的数据
v_stuno varchar(4);v_stuname varchar(20);
begin --2.打开游标cur_stu
open cur_stu; --3.将游标的当前行取出存放到变量中
fetch cur_stu into v_stuno,v_stuname;
while cur_stu%found --游标所指还有数据行,则继续循环
loop --打印结果
dbms_output.PUT_LINE(v_stuno||'->'||v_stuname);
--继续将游标所指的当前行取出放到变量中
fetch cur_stu into v_stuno,v_stuname;
end loop;
close cur_stu; --4.关闭游标
end;
END PROC_STU1;
(2).使用IF..ELSE代替WHILE循环处理游标
create or replace PROCEDURE PROC_STU2 AS
BEGIN --显示游标使用,使用if判断
declare --1.定义游标,名称为cur_stu
cursor cur_stu is
select stuno,stuname from student order by stuno; --定义变量,存放游标取出的数据
v_stuno varchar(4);
v_stuname varchar(20);
begin --2.打开游标cur_stu
open cur_stu; --3.将游标的当前行取出存放到变量中
fetch cur_stu into v_stuno,v_stuname;
loop
if cur_stu%found then --如果游标cur_stu所指还有数据行 --打印结果
dbms_output.PUT_LINE(v_stuno||'->'||v_stuname);
--继续将游标所指的当前行取出放到变量中
fetch cur_stu into v_stuno,v_stuname;
else
exit;
end if;
end loop;
close cur_stu; --4.关闭游标
end;
END PROC_STU2;
(3).使用FOR循环处理游标
create or replace PROCEDURE PROC_STU3 AS
BEGIN --显示游标使用,使用for循环
declare --定义游标,名称为cur_stu
cursor cur_stu is
select stuno,stuname from student order by stuno;
begin
for stu in cur_stu
loop
dbms_output.PUT_LINE(stu.stuno||'->'||stu.stuname);
--循环做隐含检查 %notfound
end loop; --自动关闭游标
end;
END PROC_STU3;
(4).常用的使用EXIT WHEN处理游标
create or replace
PROCEDURE PROC_STU1_1 AS
BEGIN --显示游标使用,使用exit when循环
declare --1.定义游标,名称为cur_stu
cursor cur_stu is
select stuno,stuname from student order by stuno; --定义变量,存放游标取出的数据
v_stuno varchar(4);
v_stuname varchar(20);
begin --2.打开游标cur_stu
open cur_stu;
loop--3.将游标的当前行取出存放到变量中
fetch cur_stu into v_stuno,v_stuname;
exit when cur_stu%notfound; --游标所指还有数据行,则继续循环 --打印结果
dbms_output.PUT_LINE(v_stuno||'->'||v_stuname);
end loop;
close cur_stu; --4.关闭游标
end;
END PROC_STU1_1;
二.隐式游标 1.使用演示
create or replace PROCEDURE PROC_STU4 AS
BEGIN--隐式游标使用
update student set stuname='张燕广' where stuno='1104';
--如果更新没有匹配则插入一条新记录
if SQL%NOTFOUND then
insert into student(STUNO,STUNAME,AGE,GENDER)
values('1104','张燕广',18,'男');
end if;
END PROC_STU4;
2.说明
所有的SQL语句在上下文区内部都是可执行的,因为都有一个游标指向上下文区,此游标就是 SQL游标,与现实游标不同的是,SQL游标在PL/SQL中不需要打开和关闭,而是在执行UPDATE、 DELETE是自动打开和关闭。 上面例子中就是通过SQL%NOTFOUND游标属性判断UPDATE语句的执行结果决定是否需要插入新记录。
37. 你用过数据库锁吗?
DML锁(data locks,数据锁),用于保护数据的完整性;DDL锁(dictionary locks,字典锁),用于保护数据库对象的结构,如表、索引等的结构定义;内部锁和闩(internal locks and latches),保护数据库的内部结构。DML锁的目的在于保证并发情况下的数据完整性,在Oracle数据库中,DML锁主要包括TM锁和TX锁,其中TM锁称为表级锁,TX锁称为事务锁或行级锁。当Oracle执行DML语句时,系统自动在所要操作的表上申请TM类型的锁。当TM锁获得后,系统再自动申请TX类型的锁,并将实际锁定的数据行的锁标志位进行置位。这样在事务加锁前检查TX锁相容性时就不用再逐行检查锁标志,而只需检查TM锁模式的相容性即可,大大提高了系统的效率。TM锁包括了SS、SX、S、X等多种模式,在数据库中用0-6来表示。不同的SQL操作产生不同类型的TM锁。在数据行上只有X锁(排他锁)。在 Oracle数据库中,当一个事务首次发起一个DML语句时就获得一个TX锁,该锁保持到事务被提交或回滚。当两个或多个会话在表的同一条记录上执行DML语句时,第一个会话在该条记录上加锁,其他的会话处于等待状态。当第一个会话提交后,TX锁被释放,其他会话才可以加锁。 当Oracle数据库发生TX锁等待时,如果不及时处理常常会引起Oracle数据库挂起,或导致死锁的发生,产生ORA-60的错误。这些现象都会对实际应用产生极大的危害,如长时间未响应,大量事务失败等
锁表查询的代码有以下的形式:
select count(*) from v$locked_object; select * from v$locked_object;
38. 数据库优化你是怎么做的?
数据库逻辑设计的结果应当符合下面的准则:(1)把以同样方式使用的段类型存储在一起;(2)按照标准使用来设计系统;(3)存在用于例外的分离区域;(4)最小化表空间冲突;(5)将数据字典分离。
对这些内存缓冲区的合理设置,可以大大加快数据查询速度,一个足够大的内存区可以把绝大多数数据存储在内存中,只有那些不怎么频繁使用的数据,才从磁盘读取,这样就可以大大提高内存区的命中率。
数据库设计中的优化策略
数据应当按两种类别进行组织:频繁访问的数据和频繁修改的数据。对于频繁访问但是不频繁修改的数据,内部设计应当物理不规范化。对于频繁修改但并不频繁访问的数据,内部设计应当物理规范化。
合理设计和管理表1、利用表分区2、避免出现行连接和行迁移3、控制碎片 为了消除区间交叉将静态的或只有小增长的表放置在一个表空间中,而把动态增长的对象分别放在各自的表空间中。在create table、、create index、create tablespace、create cluster时,在storage子句中的参数的合理设置,可以减少碎片的产生。
4、别名的使用5、回滚段的交替使用 把回滚段定义为交替引用,这样就达到了循环分配事务对应的回滚段,可以使磁盘负荷很均匀地分布。
ORACLE要使用一个索引,有一些最基本的条件:1)、where子名中的这个字段,必须是复合索引的第一个字段;2)、where子名中的这个字段,不应该参与任何形式的计算。
39. 分析函数
一Oracle分析函数原理
1、分析函数通过将行分组后,再计算这些分组的值。它们与聚集函数不同之处在于能够对每一个分组返回多行值。分析函数根据analytic claues(分析子句)将行分组,一个分组称为:一个窗口(可通过Windowsing Clause子句进行控制),并通过分析语句定义,对于每一行都对应有一个在行上滑动的窗口。该窗口确定当前行的计算范围。窗口大小可以用多个物理行(例如:rowid实际编号)进行度量,也可以使用逻辑区间进行度量,比如时间。
2、分析函数是查询中除需要在最终处理的order by 子句之外最后执行的操作。所有连接、WHERE、GROUP BY、HAVING子句都是分析函数处理之前完成的。因此,分析函数只出现在SELECT LIST或ORDER BY(按…排序)语句中,而不能出现在where或having子句中
3、分析函数通常用于计算:数据累积值、数据移动值、数据中间值,和输出集合报表。
二、Oracle分析函数的语法

Analytic-Function(<Argument>,<Argument>,…)
over(
<Query-Partition-Clause>
<Order-by-Clause>
<Windowing-Clause>
)
例如:sum(sal) over(partition by deptno order by ename)new_alias
1)sum:就是函数名
2)(sal): 是分析函数的参数,每个函数有0~3个参数,参数可以是表达式,例如:sum(sal+comm)
3)over:是一个关键字,用于标识分析函数,否则查询分析器不能区别sum()聚集函数和sum()分析函数
4)partition by deptno:是可选的分区子句,如果不存在任何分区子句,则全部的结果集可看作一个单一的大区
5)order by ename:是可选的order by 子句,有些函数需要它,有些则不需要。依靠已排序数据的那些函数,例如:用于访问结果集中前一行和后一行的LAG和LEAD,它们就必须使用;其它 函数,例如:AVG,则不需要用到order by 子句。在使用了任何排序的开窗函数时,该子句是强制性的,它指定了在计算分析函数时一组内的数据是如何排序的.(即:如果要使用Windowing-Clause子句,那么一定要先使用Order by 子句)
1、Analytic-Function
ORACLE提供了28个分析函数(包括如下:
AVG *,CORR *,COVAR_POP *,COVAR_SAMP *,COUNT*,CUME_DIST,DENSE_RANK,FIRST,FIRST_VALUE *,LAG,LAST,LAST_VALUE *,LEAD,MAX *,
MIN *,NTILE,PERCENT_RANK,PERCENTILE_CONT,PERCENTILE_DISC,RANK,RATIO_TO_REPORT,REGR_(Linear Regression) Functions *,ROW_NUMBER,STDDEV *,STDDEV_POP *,STDDEV_SAMP*,SUM *,VAR_POP *,VAR_SAMP*,VARIANCE),按功能分5类
1)分析函数分类
(1)等级(ranking)函数:用于寻找前N种查询,如:RANK、DENSE_RANK等
(2)开窗(windowing)函数:用于计算不同的累计,如:SUM,COUNT,AVG,MIN,MAX等,作用于数据的一个窗口上
例如:如下函数
sum(t.sal) over (order by t.deptno,t.ename) running_total,
sum(t.sal) over (partition by t.deptno order by t.ename) department_total
(3)制表(reporting)函数:与开窗函数同名,作用于一个分区或一组上的所有列
例如:如下函数
sum(t.sal) over () running_total2,
sum(t.sal) over (partition by t.deptno ) department_total2
说明:制表函数与开窗函数的关键不同之处:在于OVER语句上缺少一个ORDER BY子句
(4)LAG,LEAD函数:这类函数允许在结果集中向前或向后检索值,为了避免数据的自连接,它们是非常用用的.
(5)VAR_POP,VAR_SAMP,STDEV_POPE及线性的衰减函数:计算任何未排序分区的统计值
2) 分析函数函数,及返回值
分析函数可取0-3个参数。参数可以是任何数字类型或是可以隐式转换为数字类型的数据类型。Oracle根据最高数字优先级别确定函数参数,并且隐式地将需要处理的参数转换为数字类型。函数的返回类型也为数字类型,除非此函数另有说明。
2、Analytic_Clause
[ query_partition_clause ] [ order_by_clause [ windows_clause ] ]
1)Over Analytic clause用以指明函数操作的是一个查询结果集。也就是说分析函数是在from,where,group by,和having子句之后才开始进行计算的。因此在选择列或order by子句中可以使用分析函数。为了过滤分析函数计算的查询结果,可以将它作为子查询嵌套在外部查询中,然后在外部查询中过滤其查询结果。
2)使用Analytic_Clause子名时,注意如下
(1)Analytic clause中不能包含其他任何分析函数。也就是说,分析函数不能嵌套。然而可以在一个子查询中应用分析函数,并且通过它计算另外的分析函数。
(2)用户自定义分析函数和内置函数分析函数,都可以使用OverAnalytic_Clause。
3、PARTITION子句
partition by { value_expr [,value_expr ]… | (value_expr [,value_expr ] …)}
说明:按照表达式分区(就是分组),如果省略了分区子句,则全部的结果集被看作是一个单一的组
1)Partition by子句根据一个或多个valueexpr将查询结果集分成若干组。若不使用该子句,那么函数将查询结果集的所有行当作一个组。
2) 在分析函数中使用query_partition_clause,应该使用语法图中上分支中的语法(不带圆括号)。model查询(位于model column clauses中)或被分隔的外部连接(位于outer_join_clause中)中使用该子句,应该使用语法图中下分支中的语法(带有圆括号)。
3) 在同一个查询中可以使用多个分析函数,它们可以有相同或不同的partition by键值
4) 若被查询的对象具有并行特性,并且分析函数中包含query_partition_clause,那么函数的计算也是并行的。
5) value expr的有效值:包括常量,表列,非分析函数,函数表达式,或者前面这些元素的任意组合表达式。
4、ORDER BY子句
分 析函数中ORDER BY的存在将添加一个默认的开窗子句(默认窗口为:RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW),这意味着计算中所使用的行的集合是当前分区中当前行和前面所有行,没有ORDER BY时,默认的窗口是全部的分区 在Order by 子句后可以添加nulls last,如:order by comm desc nullslast 表示排序时忽略comm列为空的行.
1)Order_by_clause 用以指定分组中数据的排序形式。除了percentile_cont和percentile_disc之外(它们只能取唯一的键值)外的分析函数,分组中 可以使用多个键值对值进行排序,每个键值在value expr中定义,并且被排序序列限定。
2)每个函数内可以指定多个排序表达式。当使用函数给值排名时,尤其显得意义非凡,因为第二个表达式能够解决按照第一个表达式排序后仍然存在相同排名的问题。
3)只要使用order_by_clause后,仍存在值相同的行,则每一行都会返回相同的结果。
4)使用Ordery_by_clause子句的限制:
(1) 分析函数中的order_by_clause必须是一个表达式(expr)。Sibling关键字在此处是非法的(它仅仅与层次查询有关)。位置 (position)和列别名(c_alias)也是非法的。除此之外,order_by_clause的用法与整个查询或者子查询中的相同。
(2)当分析函数使用range关键字限定窗口时,若使用的窗口是下列两个窗口之一,那么可以在分析函数的order_by_clause中使用多个排序健值。
① range between UNBOUNDEDPRECEDING and CURRENT ROW <=> range UNBOUNDED PRECEDING
② range between CURRENT ROWand UNBOUNDED FOLLOWING <=> range UNBOUNDED FOLLOWING
注意: 若窗口范围由range关键字指定的分析函数中指定的不是这两个窗口范围(即:range unbounded preceding与range unboundedfollowing),那么order_by子句中仅能使用一个排序键值。
(3)若分析函数的窗口范围由row关键字指定,order_by子句中排序键值的使用没有这个限制。
5)asc | desc:指定排序顺序(升序或降序),asc是默认值。
6)nulls first | nulls last:指定返回行包含空值,该值应该出现在排序序列的开始还是末尾。
7)升序排序的默认值为:nulls last,降序排序的默认值为:nulls first。
8)分析函数总是按order_by_clause对行排序。然而,分析函数中的order_by_clause只对各个分组进行排序,而不能保证查询结果有序。要保证最后的查询结果有序,可以使用查询的order_by_clause。
5、WINDOWING子句
1)有些分析函数允许使用windowing clause。在上述的分析函数列表中,带有星号(*)的函数都允许使用windowing_clause。
2) 用于定义分析函数将在其上操作的行的集合,Windowing子句给出了一个定义变化或固定的数据窗口的方法,分析函数将对这些数据进行操作默认的窗口是 一个固定的窗口,仅仅在一组的第一行开始,一直继续到当前行(即:range unbounded preceding),要使用窗口,必须使用ORDER BY子句。
3)row | range:这些关键字为每一行定义一个窗口,该窗口用于计算函数结果(物理或者逻辑的行的集合)。然后对窗口中的每一行应用分析函数。窗口在查询结果集或者分组中从上至下移动。
4)根据2个标准可以建立窗口:数据值的范围(逻辑偏移量--range)或与当前行的行偏移量(物理单位--rows)。
5)只有指定order_by_clause后才能指定windowing_clause。有些range子句定义的窗口范围只能在order_by_clause中指定一个排序表达式。
6)一个带逻辑偏移量的分析函数的返回值总是确定的。然而,除非排序表达式能产生唯一的排序,否则带有物理偏移量的分析函数的返回值可能会产生不确定的结果。为了解决此问题,你可能不得不在order by clause中指定多个列以获得唯一的排序。
(1)between…and:用来指定窗口的起点和终点。第一个表达式(位于and之前)定义起点,第二个表达式(位于and之后)定义终点。若不使用between而仅指定一个终点,那么oracle认为它是起点,终点默一认为当前行。
(2)unbounded preceding:指明窗口开始于分组的第一行。它只用于指定起点而不能用于指定终点
(3)unbounded following:指明窗口结束于分组的最后一行。它只用于指定终点而不能用于指定起点
(4)current row:
① 用作起点:指定窗口开始于当前行或者当前值(依赖于是否分别指定row或者range)。在这种情况下终点不能为value_expre preceding。
② 用作终点:指定窗口结束于当前行或者当前值(依赖于是否分别指定row或者range)。在这种情况下起点不能为value_expr following。
7)range或者row中的value_expr preceding或者value_expr following:
(1)若value_expr FOLLOWING是起点,那么终点必须为:value_exprFOLLOWING。
(2)若value_expr PRECEDING是终点,那么起点必须是:value_exprPRECEDING。
(3)若要定义一个数字格式的时间间隔的逻辑窗口,那么可能需要用到转换函数(numtoyminterval与numtodsinterval)
8)若windowing_clause由range指定:
(1)value_expr是一个逻辑偏移量。它必须是常量,或者值为正数值的表达式,或者时间间隔文字常量。
(2)只能在order_by_clause中指定一个表达式。
(3)若value_expr求值为一个数字值,那么order_by_expr必须为数字或者date类型。
(4)若value_expr求值为一个间隔值,那么order_by_expr必须是一个date类型。
(5)若完全忽略windowing_clause,那么默认值为: range between unbounded preceding and current row。
注意:range 5 preceding:将产生一个滑动窗口,它在组中拥有当前行以及前5行的集合;
RANGE窗口仅对NUMBERS和DATES起作用,因为不可能从VARCHAR2中增加或减去N个单元,另外的限制是ORDER BY中只能有一列,因而范围实际上是一维的,不能在N维空间中
例:avg(t.sal) over(order by t.hiredate asc range 100preceding) 统计前100天平均工资
8)若windowing_clause由rows指定:
(1)value_expr是一个物理偏移量,它必须是一个常量或者表达式,并且表达式的值必须是正数值
(2)若value_expr是起点的一部分,那么它必须在终点之前对行求值。
(3)利用ROW分区,就没有RANGE分区那样的限制了,数据可以是任何类型,且ORDER BY 可以包括很多列
9)常用的Specifying窗口
(1)UNBOUNDED PRECEDING:这个窗口从当前分区的每一行开始,并结束于正在处理的当前行
(2)CURRENT ROW:该窗口从当前行开始(并结束)
(3)Numeric Expression PRECEDING:对该窗口从当前行之前的数字表达式(Numeric Expression)的行开始,对RANGE来说,从从行序值小于数字表达式的当前行的值开始.
(4)Numeric Expression FOLLOWING:该窗口在当前行Numeric Expression行之后的行终止(或开始),且从行序值大于当前行NumericExpression行的范围开始(或终止)
例如:range between 100 preceding and 100 following:当前行100前,当前后100后
注意:分析函数允许你对一个数据集进排序和筛选,这是SQL从来不能实现的.除了最后的Order by子句之外,分析函数是在查询中执行的最后的操作集,这样的话,就不能直接在谓词中使用分析函数,即不能在上面使用where或having子句!!
40. 管道pipeline
答:是不是pipelined,对方说是。用过,这个关键字主要是函数返回一个集合时不等全部果结出来一起
返回,而是每出一个行就返回给调用方。
41. 如何存储blob?
答:前端程序实现,把文件读到内存流变量, Binary类型添加进去,再经过OracleCommand写到数据库二进制字段。
42. 执行计划提示你用过几个,怎么用的?
(接上一个问题)
parallel并发最大数是多少?
答:参数parallel_max_server决定的
-
新员工学习总结范文
20xx年x月x日进入**公司至今已近两周时间,通过这段时间的工作和学习,已经适应了新的工作环境,了解了公司的发展历史及企业文化、…
-
大学生个人学期学习总结范文
在短短的时间里一个学期很快就过去了,大学生活改变了我很多东西,包括我的生活方式和学习方式,当然相比以前是进步了很多。当然,作为新世…
-
20xx个人学习总结范文
20xx个人学习总结范文按照县委中心组学习计划的安排今年来我通过集中学与自学相结合的方式比较系统的学习了xxxx重要思想xxx同志…
-
国际工商管理个人学习总结范文
为提高自身的管理专业技能,培养创新经营和现代管理意识,促使在工作中进一步更新观念、理清思路。我从20xx年x月开始参加了杭州年代学…
-
工商管理个人学习总结范文
为提高自身的管理专业技能,培养创新经营和现代管理意识,促使在工作中进一步更新观念、理清思路。我从20xx年x月开始参加了杭州年代学…
-
上课技能远程培训学习总结(1)
上课技能远程培训学习总结(1)饮水思源保亭县20xx年中小学教师上课技能(远程)培训的学习已尾声。一个月以来,我所付出的辛勤劳动的…
-
远程培训学习日志
随着社会的进步和发展,人们生活、工作环境的变化越来越快,需要面对不断出现的新知识、新技术。一次性的学校教育,越来越不能满足个人终身…
-
远程培训学习日志
这次培训是一次难得的学习机会,我倍加珍惜这次学习机会,努力完成各项学习任务、认真学习研讨,认真观看每个学习的专题视频讲座,认真听好…
-
远程学习总结
知识的更新、时代的进步要求我们教师要不断地学习,不断地增长见识。最近在继续教育网上,看到众多老师们的总结、案例,端看专家老师的讲座…
-
国培学习日志与总结
国培学习日志与总结我通过这次“国培计划”远程项目的培训学习,提高了语文教学认识,理清了语文教学思路,学到了新的教学理念,找到了过去…