二叉树的应用实验报告
实 验 报 告
课程名称 ____数据结构上机实验__________ 实验项目 ______二叉树的应用 ____________ 实验仪器 ________PC机___________________
系 别____________________________ 专 业_____________________________ 班级/学号____________________________ 学生姓名 _____________________________ 实验日期 _______________________ 成 绩 _______________________ 指导教师 _______________________
实验三.二叉树的应用
1. 实验目的:掌握二叉树的链式存储结构和常用算法。利用哈夫曼树设计最优压缩编码。
2. 实验内容:
1) 编写函数,实现建立哈夫曼树和显示哈夫曼树的功能。
2) 编写函数,实现生成哈夫曼编码的功能。
3) 编写主函数,从终端输入一段英文文本;统计各个字符出现的频率,然后构建哈夫曼树并求出对应的哈夫曼编码;显示哈夫曼树和哈夫曼编码。
选做内容:修改程序,选择实现以下功能:
4) 编码:用哈夫曼编码对一段英文文本进行压缩编码,显示编码后的文本编码序列;
5) 统计:计算并显示文本的压缩比例;
6) 解码:将采用哈夫曼编码压缩的文本还原为英文文本。
3. 算法说明:
1) 二叉树和哈夫曼树的相关算法见讲义。
2) 编码的方法是:从头开始逐个读取文本字符串中的每个字符,查编码表得到它的编码并输出。重复处理直至文本结束。
3) 解码的方法是:将指针指向哈夫曼树的树根,从头开始逐个读取编码序列中的每位,若该位为1则向右子树走,为
0则向左子树走。当走到叶子节点时,取出节点中的字符并输出。重新将指针放到树根,继续以上过程直至编码序列处理完毕。
4) 压缩比例的计算:编码后的文本长度为编码序列中的0和1,的个数,原文本长度为字符数*8。两者之比即为压缩比。
4. 实验步骤:
实现哈夫曼树的编码序列操作:
int i=0,j=0;
huffnode p;
p=tree[2*n-2];//序号2*n-2节点就是树根节点
while(hfmstr[i]!='\0')//从头开始扫描每个字符,直到结束 {while(p.lchild!=-1&&p.rchild!=-1)
if(hfmstr[i]=='0')//为0则向左子树走
{
p=tree[p.lchild];//取出叶子节点中的字符
}
else if(hfmstr[i]=='1')//为1则向右子树走
{
p=tree[p.rchild];//取出叶子节点中的字符
}
i++;
}
decodestr[j]=p.data;j++;//对字符进行译码,结果放在decodestr字符串中
p=tree[2*n-2];//返回根节点
}
}
程序修改后完整源代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <limits.h>//专门用于检测整型数据数据类型的表达值范围
#define N 96 //ASCII字符集包含至多N个可见字符 typedef struct //Huffman树节点定义
{ char data; //字符值
int weight; //权重
int lchild; //左子结点
int rchild; //右子结点
} huffnode; //huffman节点类型
struct charcode
{ int count; //字符出现的次数(频率)
char code[N]; //字符的Huffman编码
} codeset[N]; //编码表,长为N,每项对应一个ascii码字符,下标
i的项对应ascii编码为i+32的字符
huffnode * CreateHufftree(char data[], int weight[], int n) //建立Huffman树的算法
{
int i,k;
int min1,min2,min_i1,min_i2;
huffnode *tree;
tree=(huffnode *)malloc((2*n-1)*sizeof(huffnode)); //为Huffman树分配2n-1个节点空间
for (i=0;i<2*n-1;i++) //初始化,将各字符和其频率填入Huffman树,作为叶子结点
{
tree[i].lchild=tree[i].rchild=-1;
if (i<n) {
tree[i].data=data[i];
tree[i].weight=weight[i];
}
else tree[i].data=' ';
}
for (i=n;i<2*n-1;i++) ////合并两棵树,作n-1遍
{
min1=min2=INT_MAX; //INT_MAX为最大值
min_i1=min_i2=-1;
for (k=0;k<i;k++) ////查找定位两个最小权重节点 if (tree[k].weight>=0) //仅在根节点中找 if (tree[k].weight<min1)
{
min2=min1;
min_i2=min_i1;
min1=tree[k].weight;
min_i1=k;
}
else
if (tree[k].weight<min2) {
min2=tree[k].weight;
min_i2=k;
}
tree[i].weight=min1+min2;
tree[min_i1].weight *= -1;
tree[min_i2].weight *= -1;
tree[i].lchild=min_i1;
tree[i].rchild=min_i2;
}
return tree; // 合并
}
void CreateHuffcode(huffnode tree[], int i, char s[])//已知tree[i]节点的编码序列为s,求该节点下所有叶子节点的编码序列。 { char s1[N],c;
if(i!=-1)
if (tree[i].lchild==-1 && tree[i].rchild==-1) {
c=tree[i].data;
strcpy(codeset[c-32].code, s);
}
else {
strcpy(s1, s); strcat(s1, "0");
CreateHuffcode(tree, tree[i].lchild, s1);
strcpy(s1, s); strcat(s1, "1");
CreateHuffcode(tree, tree[i].rchild, s1);
}
return;
}
void PrintHufftree(huffnode tree[], int n)
Huffman树
{
int i;
printf("Huffman tree :\n"); //输出tree中的
printf("i\tValue\tLchild\tRchild\tWeight\n");
for(i=2*n-2;i>=0;i--)
{
printf("%d\t",i);
printf("%c\t",tree[i].data);
printf("%d\t",tree[i].lchild);
printf("%d\t",tree[i].rchild);
printf("%d\t",tree[i].weight);
printf("\n");
}
}
void EnCoding(char str[], char hfmstr[])
{//根据codeset编码表,逐个将str字符串中的字符转化为它的huffman编码,结果编码串放在hfmstr字符串中
int i, j;
hfmstr[0]='\0';//把hfmstr串赋空
i=0;
while(str[i]!='\0')//从第头开始扫描str的每个字符,一直到该字符的结束
{
j=str[i]-32;//执行字符到huffman的转换
strcat(hfmstr, codeset[j].code);//把codest编码串添加到hfmstr
结尾处
i++;//每次循环完i的值加1
}
}
void DeCoding(huffnode tree[], int n, char hfmstr[], char decodestr[])
//根据tree数组中的huffman树,逐个对hfmstr字符串中的字符进行译码,结果放在decodestr字符串中
{
int i=0,j=0;
huffnode p;
p=tree[2*n-2];//序号2*n-2节点就是树根节点
while(hfmstr[i]!='\0')//从头开始扫描每个字符,直到结束
{while(p.lchild!=-1&&p.rchild!=-1)//指针为空,儿子的值取完了
{
if(hfmstr[i]=='0')//为0则向左子树走
{
p=tree[p.lchild];//取出叶子节点中的字符
}
else if(hfmstr[i]=='1')//为1则向右子树走
{
p=tree[p.rchild];//取出叶子节点中的字符
}
i++;
}
decodestr[j]=p.data;j++;//对字符进行译码,结果放在decodestr字符串中
p=tree[2*n-2];//返回根节点
}
}
void main()
{
int i,j;
huffnode * ht; //Huffman树
char data[N]; //要编码的字符集合
int weight[N]; //字符集合中各字符的权重(频率) int n=0; //字符集合中字符的个数
char str[1000]; //需输入的原始字符串 char hfm_str[1000]=""; //编码后的字符串
char decode_str[1000]="";//解码后的字符串
printf("请输入要转换的字符串\n");
gets(str);
for(i=0;i<N;i++) { //初始化编码表,频率为0,编码串为空串
codeset[i].count=0;
codeset[i].code[0]='\0';
}
i=0;
while(str[i]!='\0') { //统计原始字符串中各字符出现的频率,存入编码表
j=str[i]-32;
codeset[j].count++; //codeset[0]~[95]对应ascii码32~127的字符
i++;
}
for(i=0;i<N;i++) //统计原始字符串中出现的字符个数 if(codeset[i].count!=0) n++;
printf("字符频率统计:\n"); //显示统计结果
for(i=0;i<N;i++)
if(codeset[i].count!=0)
codeset[i].count);
printf("\n");
j=0;
for(i=0;i<N;i++) //生成要编码的字符集合,以及权重 if (codeset[i].count!=0) {
data[j]=i+32; printf("%c:%d, ", i+32,
weight[j]=codeset[i].count;
j++;
}
ht=CreateHufftree(data,weight,n); //建立Huffman树,根节点是ht[2*n-2]
PrintHufftree(ht,n); //显示Huffman树的存储结果
CreateHuffcode(ht, 2*n-2, ""); //以ht[2*n-2]为根,以空字符串为起始编码字符串,求出各叶子节点的编码字符串
//显示codeset中的Huffman编码,参见"显示频率统计结果"的代码.
printf("haffman编码为:\n");
for(i=0;i<N;i++){
if(codeset[i].count!=0)
printf("%c:%s\n",i+32,codeset[i].code );
}
EnCoding(str, hfm_str); //对str字符串进行编码,放在hfm_str字符串
printf("编码序列: %s\n",hfm_str);
DeCoding(ht, n, hfm_str, decode_str); //对hfm_str字符串进行译码,放在decode_str字符串中
printf("解码后的字符串: %s\n",decode_str);
free(ht); //释放Huffman树
}
实验总结:
第二篇:二叉树的遍历实验报告
二叉树的遍历实验报告
一、需求分析
在二叉树的应用中,常常要求在树中查找具有某种特征的结点,或者对树中全部结点逐一进行某种处理,这就是二叉树的遍历问题。
对二叉树的数据结构进行定义,建立一棵二叉树,然后进行各种实验操作。
二叉树是一个非线性结构,遍历时要先明确遍历的规则,先访问根结点还时先访问子树,然后先访问左子树还是先访问有右子树,这些要事先定好,因为采用不同的遍历规则会产生不同的结果。本次实验要实现先序、中序、后序三种遍历。
基于二叉树的递归定义,以及遍历规则,本次实验也采用的是先序遍历的规则进行建树的以及用递归的方式进行二叉树的遍历。
二、系统总框图
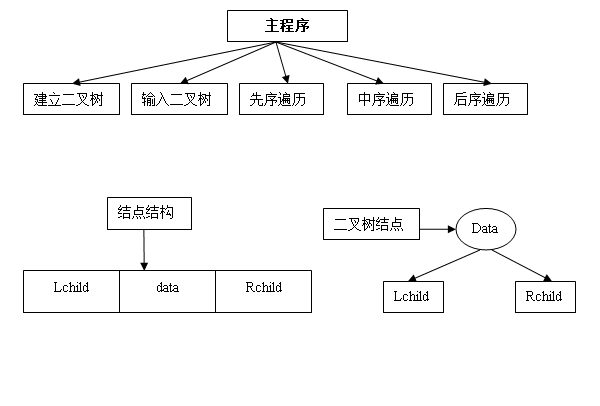
三、各模块设计分析
(1)建立二叉树结构
建立二叉树时,要先明确是按哪一种遍历规则输入,该二叉树是按你所输入的遍历规则来建立的。本实验用的是先序遍历的规则进行建树。
二叉树用链表存储来实现,因此要先定义一个二叉树链表存储结构。因此要先定义一个结构体。此结构体的每个结点都是由数据域data、左指针域Lchild、右指针域Rchild组成,两个指针域分别指向该结点的左、右孩子,若某结点没有左孩子或者右孩子时,对应的指针域就为空。最后,还需要一个链表的头指针指向根结点。
要注意的是,第一步的时候一定要先定义一个结束标志符号,例如空格键、#等。当它遇到该标志时,就指向为空。
建立左右子树时,仍然是调用create()函数,依此递归进行下去,直到遇到结束标志时停止操作。
(2)输入二叉树元素
输入二叉树时,是按上面所确定的遍历规则输入的。最后,用一个返回值来表示所需要的结果。
(3)先序遍历二叉树
当二叉树为非空时,执行以下三个操作:访问根结点、先序遍历左子树、先序遍历右子树。
(4)中序遍历二叉树
当二叉树为非空时,程序执行以下三个操作:访问根结点、先序遍历左子树、先序遍历右子树。
(5)后序遍历二叉树
当二叉树为非空时,程序执行以下三个操作:访问根结点、先序遍历左子树、先序遍历右子树。
(6)主程序
需列出各个函数,然后进行函数调用。
四、各函数定义及说明
因为此二叉树是用链式存储结构存储的,所以定义一个结构体用以存储。
typedef struct BiTNode
{ char data;
struct BiTNode *Lchild;
struct BiTNode *Rchild;
}BiTNode,*BiTree;
(1)主函数main()
主程序要包括:定义的二叉树T、建树函数create()、先序遍历函数Preorder()、中序遍历函数Inorder()、后序遍历函数Postorder()。
(2)建树函数Create()
定义一个输入的数是字符型的,当ch为空时,T就为空值,否则的话就分配空间给T,T就指向它的结点,然后左指针域指向左孩子,右指针指向右孩子,若还有,继续调用Create(),依次循环下去,直到ch遇到空时,结束。
最后要返回建立的二叉树T。
(3)先序遍历函数Preorder()
根据先序遍历规则,当T为非空时,先输出结点处的数据,指针指向左、右孩子,依次进行下去。
(4) 中序遍历函数Inorder()
根据中序遍历规则,当T为非空时,先左指针指向左孩子数据,然后输出结点处的数据,再右指针指向右孩子,依次进行下去。
(5)后序遍历函数Postorder()
根据后序遍历规则,当T为非空时,先右指针指向右孩子,然后左指针指向左孩子,最后输出结点处的数据,依次进行下去。
五、使用说明
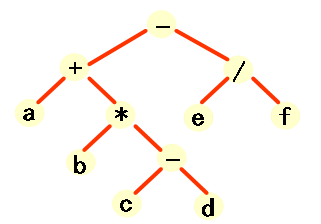
在Turbo C的环境下,先按Ctrl+F9运行程序,此时就是建立二叉树的过程,例如输入序列-+a *b -c d /e f 输入过程中不要加回车,因为回车也有对应的ASCII码,是要算字符的,输入完之后再按回车,用户界面上就能够看到结果了。
另外你必须会手动建立一棵二叉树,保证你输入的序列能构成一棵二叉树,否则你怎么输入,按最后按多少回车程序也不会结束!
六、源程序
#include "stdio.h"
#include "string.h"
#include "alloc.h"
#define NULL 0
typedef struct BiTNode
{
char data;
struct BiTNode *Lchild;
struct BiTNode *Rchild;
}BiTNode,*BiTree;
BiTree Create()
{
char ch;
BiTree T;
scanf("%c",&ch);
if(ch==' ')
T=NULL;
else
{ T=(BiTNode *)malloc(sizeof(BiTNode));
T->data=ch;
T->Lchild=Create();
T->Rchild=Create();
}
return T;
}
void Preorder(BiTree T)
{
if(T)
{
printf("%c",T->data);
Preorder(T->Lchild);
Preorder(T->Rchild);
}
}
void Inorder(BiTree T)
{
if(T)
{
Inorder(T->Lchild);
printf("%c",T->data);
Inorder(T->Rchild);
}
}
void Postorder(BiTree T)
{
if(T)
{
Postorder(T->Lchild);
Postorder(T->Rchild);
printf("%c",T->data);
}
}
main()
{
BiTree T;
clrscr();
printf("The elements is : ");
T=Create();
printf("\n");
printf("The Preorder's result is : ");
Preorder(T);
printf(" \n\n");
printf("The Inorder's result is : ");
Inorder(T);
printf("\n\n");
printf("The Postorder's result is : ");
Postorder(T);
getch();
}
七、测试数据
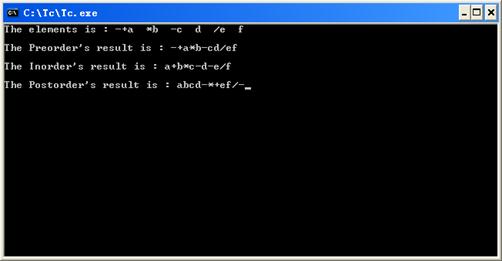
八、测试结果
先序遍历序列:-,+,a,*,b,-,c,d,/,e,f ;
中序遍历序列:a,+,b,*,c,-,d,-,e,/,f ;
后序遍历序列:a,b,c,d,-,*,+,e,f,/,- ;
-
实验六 二叉树实验报告(1)
实验四二叉树的操作班级:计算机1002班姓名:**学号:**完成日期:20XX.6.14题目:对于给定的一二叉树,实现各种约定的遍…
-
二叉树实验报告
实验六树和二叉树的操作一实验目的1进一步掌握树的结构及非线性特点递归特点和动态性2进一步巩固对指针的使用和二叉树的三种遍历方法建立…
-
树和二叉树实验报告
树和二叉树一实验目的1掌握二叉树的结构特征以及各种存储结构的特点及适用范围2掌握用指针类型描述访问和处理二叉树的运算二实验要求1认…
-
二叉树基本操作--实验报告
宁波工程学院电信学院计算机教研室实验报告一实验目的1熟悉二叉树树的基本操作2掌握二叉树的实现以及实际应用3加深二叉树的理解逐步培养…
-
二叉树实验报告
二叉树实验报告问题描述1问题描述用先序递归过程建立二叉树存储结构二叉链表输入数据按先序遍历所得序列输入当某结点左子树或右子树为空时…
-
二叉树实验报告
算法与数据结构实验报告——二叉树课程名称:算法与数据结构实验项目名称:满二叉树的建立与遍历实验时间:20xx年x月x日班级:电科1…
-
树和二叉树实验报告
树和二叉树一实验目的1掌握二叉树的结构特征以及各种存储结构的特点及适用范围2掌握用指针类型描述访问和处理二叉树的运算二实验要求1认…
-
二叉树实验报告
数据结构课程设计报告专业计算机科学与技术班级3班姓名学号指导教师起止时间20xx1220xx1课程设计二叉树一任务描述二叉树的中序…
-
实验六 二叉树实验报告(1)
实验四二叉树的操作班级:计算机1002班姓名:**学号:**完成日期:20XX.6.14题目:对于给定的一二叉树,实现各种约定的遍…
-
二叉树基本操作--实验报告
宁波工程学院电信学院计算机教研室实验报告一实验目的1熟悉二叉树树的基本操作2掌握二叉树的实现以及实际应用3加深二叉树的理解逐步培养…
-
二叉树实验报告
实验六树和二叉树的操作一实验目的1进一步掌握树的结构及非线性特点递归特点和动态性2进一步巩固对指针的使用和二叉树的三种遍历方法建立…