信息论与编码
信息论与编码实验报告
实验一: 唯一可译码的判断
一、 实验目的
1.理解和掌握唯一可译码判断的基本原理和方法
2.通过c编程实现对编码的唯一可译性进行判断
二、 实验内容
1.已知:信源符号个数q、码字集合C;
2.输入:任意的一个码字集合C。码字个数和每一个具体的码字在运行时从键盘输入;
3.输出:判决(是惟一可译码/不是惟一可译码)。
三、 实验原理
1.根据p(源码)内的码组,通过判断码A是否是码B的子码,生成s[1]的码组
2.用类似方法,再根据s[i-1]与p的比较,生成s[i]的码组。
3.判断s[0]~s[n]内的码组是否与p内码组有重复,有重复则可以判断该p码组不是唯一可译码。否则则是唯一可译码。
四、 实验环境及实验文件存档名
实验环境:实验在VC++6.0软件环境下运行测试
实验文件存档名:weiyikeyima.cpp
五、 实验结果
数据一:码组:000, 001, 010, 011, 100, 101
数据二:码组:0 ,10 ,1101 ,1100 ,1001 ,1111
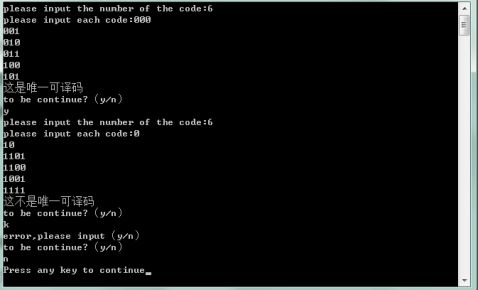
测试结果与实际分析相同
六、 实验分析
1.在实验中,对于唯一可译码码的判断方法有了更深刻的了解。
2.实验中需要注意的是针对一些特殊情况的处理,如输入本身有重复可直接判断码的不唯一性、输入本身可以使用克劳夫特不等式进行判断以减少运算量(此源码并没使用此功能)。
3.实验中并没有使用复杂算法,更多的是对字符串的操作。因此源代码的编写并没有多大难度。
实验二: Huffman编码
一、 实验目的
1.进一步熟悉Huffman编码过程
2. 掌握C语言递归程序的设计和调试技术
二、 实验内容
1.输入: 信源符号个数r,信源的概率分布P
2.输出: 每个信源符号对应Huffman编码的码字
三、 实验原理
哈夫曼编码算法(利用哈夫曼树)如下:
1. 存储结构:构造由信息元素与对应的权值组成的信息元素结构体来存储已给 定的字母与其权重信息;构造由信息元素、权值、当前结点的父结点、左结点、右结点组成的哈夫曼树结点结构体来存储树结点的信息,还会很方便地帮助创建哈夫曼树;构造由信息元素与对应的哈夫曼编码结构体来存储哈夫曼编码信息;方便进行对数据的编码。
2).结构体数组处理:哈夫曼树没有度为 1 的结点,若一个哈夫曼树由 n 个叶 子结点,则该哈夫曼树共有2n-1个结点。应用以上的原理,根据用户输入的信息元素的个数n开辟大小为2n-1的哈夫曼树数组来满足创建哈夫曼树的需要,并对此数组进行初始化,叶子结点的信息元素与权值即给定的的信息元素与权值;非叶子结点的信息元素与权值设置为空值;所有哈夫曼树结点的父结点、左
结点、右结点设置为 0 。
3.选择权值最小与次小:在进行比较的过程中循环取出权值进行比较,设置两 个s1,s2分别记录本次循环最小与次小的权值,进行下一次的比较选择。返回权值最小与次小的哈夫曼树结点信息。或可反之。
4. 生成小树:应用3)中想法,在用户输入的信息元素中选择权值中最小与次小 的元素分别赋值给右叶子结点与左叶子结点,并把这两个权值之和赋值给这两个结点的父结点,记录父结点位置。
5).生成哈夫曼树:再应用3) 4)把这些小树的父结点的权值进行比较选择,选 择权值比较大的设置为新的右结点的权值,权值比较小的设置为左结点,把这两个权值的和赋值给新的父结点;以此重复进行,最终生成哈夫曼树。
四、 实验环境及实验文件存档名
实验环境:实验在VC++6.0软件环境下运行测试
实验文件存档名:Huffman.cpp
五、 实验结果
5个码字:a,0.4 b,0.1 c,0.2 d,0.2 e,0.1
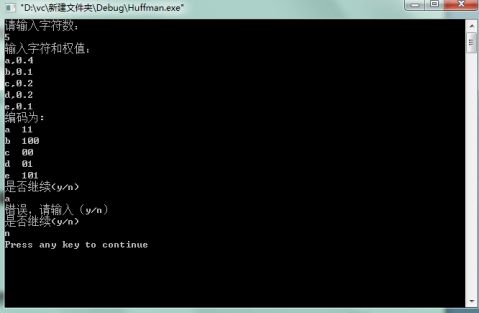
六、 实验分析
1.在实验中,对于Huffman编码有了更深刻的了解。
2.简要总结Huffman 编码的基本原理及特点:哈夫曼码是用概率匹配方法进行信源编码。它有两个明显的特点:一是哈夫曼的编码方法保证了概率大的符号对应于短码,概率小的符号对应于长码,充分利用了短码;二是缩减信源的最后两个码字总是最后一位不同,从而保证了哈夫曼码是即时码。
第二篇:信息论与编码试卷答案
一、概念简答题(每题5分,共40分)
1.什么是平均自信息量与平均互信息,比较一下这两个概念的异同?
2.简述最大离散熵定理。对于一个有m个符号的离散信源,其最大熵是多少?
3.解释信息传输率、信道容量、最佳输入分布的概念,说明平均互信息与信源的概率分布、信道的传递概率间分别是什么关系?
4.对于一个一般的通信系统,试给出其系统模型框图,并结合此图,解释数据处理定理。
5.写出香农公式,并说明其物理意义。当信道带宽为5000Hz,信噪比为30dB时求信道容量。
6.解释无失真变长信源编码定理。
7.解释有噪信道编码定理。
8.什么是保真度准则?对二元信源 ,其失真矩阵
,其失真矩阵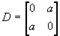 ,求a>0时率失真函数的
,求a>0时率失真函数的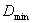 和
和 ?
?
二、综合题(每题10分,共60分)
1.黑白气象传真图的消息只有黑色和白色两种,求:
1) 黑色出现的概率为0.3,白色出现的概率为0.7。给出这个只有两个符号的信源X的数学模型。假设图上黑白消息出现前后没有关联,求熵 ;
;
2) 假设黑白消息出现前后有关联,其依赖关系为: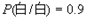 ,
, ,
, ,
, ,求其熵
,求其熵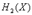 ;
;
2.二元对称信道如图。  ;
;
1)若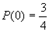 ,
, ,求
,求 和
和 ;
;
2)求该信道的信道容量和最佳输入分布。
3.信源空间为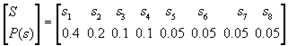 ,试分别构造二元和三元霍夫曼码,计算其平均码长和编码效率。
,试分别构造二元和三元霍夫曼码,计算其平均码长和编码效率。
4.设有一离散信道,其信道传递矩阵为 ,并设
,并设 ,试分别按最小错误概率准则与最大似然译码准则确定译码规则,并计算相应的平均错误概率。
,试分别按最小错误概率准则与最大似然译码准则确定译码规则,并计算相应的平均错误概率。
5.已知一(8,5)线性分组码的生成矩阵为 。
。
求:1)输入为全00011和10100时该码的码字;2)最小码距。
6.设某一信号的信息传输率为5.6kbit/s,在带宽为4kHz的高斯信道中传输,噪声功率谱NO=5×10-6mw/Hz。试求:
(1)无差错传输需要的最小输入功率是多少?
(2)此时输入信号的最大连续熵是多少?写出对应的输入概率密度函数的形式。
一、 概念简答题(每题5分,共40分)
1.答:平均自信息为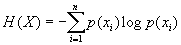
表示信源的平均不确定度,也表示平均每个信源消息所提供的信息量。
平均互信息
表示从Y获得的关于每个X的平均信息量,也表示发X前后Y的平均不确定性减少的量,还表示通信前后整个系统不确定性减少的量。
2.答:最大离散熵定理为:离散无记忆信源,等概率分布时熵最大。
最大熵值为 。
。
3.答:信息传输率R指信道中平均每个符号所能传送的信息量。信道容量是一个信道所能达到的最大信息传输率。信息传输率达到信道容量时所对应的输入概率分布称为最佳输入概率分布。
平均互信息是信源概率分布的∩型凸函数,是信道传递概率的U型凸函数。
4.答:通信系统模型如下:
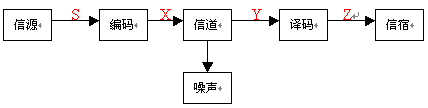
数据处理定理为:串联信道的输入输出X、Y、Z组成一个马尔可夫链,且有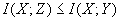 ,
, 。说明经数据处理后,一般只会增加信息的损失。
。说明经数据处理后,一般只会增加信息的损失。
5.答:香农公式为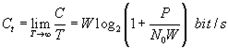 ,它是高斯加性白噪声信道在单位时间内的信道容量,其值取决于信噪比和带宽。
,它是高斯加性白噪声信道在单位时间内的信道容量,其值取决于信噪比和带宽。
由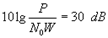 得
得 ,则
,则
6.答:只要 ,当N足够长时,一定存在一种无失真编码。
,当N足够长时,一定存在一种无失真编码。
7.答:当R<C时,只要码长足够长,一定能找到一种编码方法和译码规则,使译码错误概率无穷小。
8.答:1)保真度准则为:平均失真度不大于允许的失真度。
2)因为失真矩阵中每行都有一个0,所以有 ,而
,而 。
。
二、综合题(每题10分,共60分)
1.答:1)信源模型为

2)由 得
得
则
2.答:1)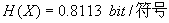

2) ,最佳输入概率分布为等概率分布。
,最佳输入概率分布为等概率分布。
3.答:1)二元码的码字依序为:10,11,010,011,1010,1011,1000,1001。
平均码长 ,编码效率
,编码效率
2)三元码的码字依序为:1,00,02,20,21,22,010,011。
平均码长 ,编码效率
,编码效率
4.答:1)最小似然译码准则下,有 ,
,
2)最大错误概率准则下,有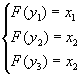 ,
,
5.答:1)输入为00011时,码字为00011110;输入为10100时,码字为10100101。
2)
6.答:1)无错传输时,有
即 则
则
2)在 时,最大熵
时,最大熵
对应的输入概率密度函数为
- 信息论与编码心得体会
-
信息论与编码课程总结
信息论与编码课程总结08信息1班0807011039赵传来信息论是人们在长期通信工程的实践中由通信技术与概率论随机过程和数理统计相…
-
信息论与编码 课程总结
信息论与编码课程总结本学期我选修了信息论与编码这门课程信息论是应用近代概率统计方法来研究信息传输交换存储和处理的一门学科也是源于通…
-
信息论与编码课程总结
信息论与编码《信息论与编码》这门课程给我带了很深刻的感受。信息论是人类在通信工程实践之中总结发展而来的,它主要由通信技术、概率论、…
-
《信息论与编码》课程小结
《信息论与编码》课程小结《信息论与编码》课程小结信息论是应用概率论、随机过程和数理统计和近代代数等方法,来研究信息的存储、传输和处…
-
信息论与编码课程总结
信息论与编码《信息论与编码》这门课程给我带了很深刻的感受。信息论是人类在通信工程实践之中总结发展而来的,它主要由通信技术、概率论、…
-
《信息论与编码》课程小结
《信息论与编码》课程小结《信息论与编码》课程小结信息论是应用概率论、随机过程和数理统计和近代代数等方法,来研究信息的存储、传输和处…
- 信息论与编码心得体会
-
信息论与编码课程总结
信息论与编码课程总结08信息1班0807011039赵传来信息论是人们在长期通信工程的实践中由通信技术与概率论随机过程和数理统计相…
-
信息论与编码 课程总结
信息论与编码课程总结本学期我选修了信息论与编码这门课程信息论是应用近代概率统计方法来研究信息传输交换存储和处理的一门学科也是源于通…