“悦分享”读书感悟 赵倩
《体验的智慧》阅读感悟
“一切智慧皆来自于体验。”这是车建新用他真实传奇的一生想要告诉我们的。同样,《体验的智慧》这本书对每一个想要创业或者正在创业之路上努力奔跑的青年人来说,无疑是创业的启蒙书,智慧的升华。这本书它值得每个人用心去读,用心去体会。
说实话,一开始当我知道这本书的作者是车建新时,我是不太感兴趣的。车建新是何人物?乃是大名鼎鼎的红星美凯龙全球家居连锁集团的董事长。概括来说,无非是一位商人而已。商人所撰写的励志名著无非是为自己树碑立传,或是涂脂抹粉,归期还是一个做广告、赚钞票,搞些商业名堂。自古商人无不重利轻义,其中大部分还为富不仁。但当我真正开始用心读,用心体会这本书时,我的想法开始发生了转变。这就是它的魅力,亦是车建新的魅力。
车建新,一个木匠出身的商人。19xx年的企业家,16岁走出小山村,进城当了木匠。读他的书,你会发现你感悟的第一个道理便是认识自己,认清自己。“人是世界上最神秘和神奇的生灵”、“认识你自己始终是人类永恒的命题。”这是他写在第一章的重要内容。结合他的人生经历来讲,就像他一样,从不掩饰他自己的木匠出身,并且时刻都愿意向年轻人讲述他自己14岁时的一个黄昏。他说:“ 我帮母亲挑秧,走在窄窄的田埂上,迎面走来一位颤悠悠挑着秧苗担子的老人,那一刻,我仿佛一瞬间清晰地望见了60岁时的自己,于是下决心改变人生,走出一条创造新自我的道路。”他说;“当一个有用的人,不想依赖父母,为家庭赚钱,想把事情做好,有责任心,
有正义感,想超过别人……”实事求是地说,他当时的这些想法和时下我们很多大学生的想法是一致的。但是,虽然没有读过大学,起点那么低,16岁进城,连“靠右行走”都不懂的车建新,却深深明白:“人的生命只有一次。每个生命都是伟大的。既然是生命的存在了,来人世间走一遭了,起码应该活得明白:我是谁?这个世界是怎么回事?”因此,那时他就时时问自己:我是谁?答案是:“一个好木匠!”于是,他全力以赴去做一个好木匠,而且痴迷于各种木纹、各种工艺。这就是车建新人生的第一境界,亦是我们现在当代大学生所要认清的一个事实:你想要成长,想要成功,想要站在巨人的肩膀上,那你要做的第一步便是认清自己,认清自己所在的位置!人的生命只有一次。每个生命都是伟大的。既然是生命的存在,人世间走一回,起码得活得明白。在每天出门前,问下自己“我是谁”,便能使你的大脑变得清醒,你的分析变得到位。你可以清楚的知道自己的定位,认识了自己的优缺点,就可以避免很多无知与轻狂。
“人之为万物之灵,一个重要原因是人能思考和体验,并把知识、经验和感受通过文字等形式记录下来,传承下去,使后人总是能站在前人肩上继续探索。”这便是车建新的观点。没错,人类总是认为自己是全宇宙最高级的生物。如今的人们满足于高科技所带来的一切便利。但是,从另一个方面讲,我们是否保留了那份对大自然的敬畏之心呢?找一个假期,寻个空档,去郊外,去踏青,去郊游,去聆听风吹竹林打叶生,去领略一览众山小的万丈豪情,去欣赏自然的寂静之美,这一定也不失为另一种安然舒适的生活态度吧!当然,从
个人成就的方面来说,车建新的话也是给无数正在创业梦想之路上奔跑的人儿指明了一个方向:要想成功,光靠自己的力量是不够的,前人的许多事例都有我们借鉴的地方,借鉴前辈之经验,成就个人之辉煌,无疑是一种通往成功道路上的一种捷径。
“普通人的一生只是运用了10%的人生潜力,人完全可以通过改变其思想而改变其生活。”这无疑是车建新给予我们的第二个忠告。 人的潜力是没有局限的,更不是天生注定的。阿德勒的“个体心理学”理论意指每个人虽然都是独特的,但他们都是以内心的和谐和力求与所有同伴相合作为其特征的。同样,在我看来,人的一生除了那10%的潜力外,还需要一个“同伴”一个可以相互扶持,相互帮助的同伴。而这个“同伴”可以是朋友,可以是亲人,甚至可以是从未谋面的陌生人!但是他可以让你寄托一些情感,每每想起他,你都会会心一笑,内心涌出暖流。“他”可以激励你,会给予你一些好的影响。“他”可以是良友、是益师。毕竟,人不是独居动物,我们每个人都需要一个感情寄托,一个在你心中独一无二、举世无双的“同伴”!这便是车建新给予我们的第二个忠告:找到“同伴”一起挖掘自己全部的潜力!
车建新用他的人生经历告诉我们,奋斗的人生就是要不断地体验、不断的进取、不断的上升。正如他所说:“什么是生活?生活就是一门学科,更是一门艺术,未经思考和体验的生活是不得一过的,只能说是生存而已。”车建新他用30年的光阴酝酿了一部诗意盎然的哲学观念,慢慢读《体验的智慧》,你便可以听见骨骼成长的声音,
很原始,很直接。他以一种积极的情怀,给我们提供了一个善待生命、提升生命价值的哲学世界。它,值得我们每个人用心去感悟,去体会。 赵倩 中贸142
第二篇:读核感悟--内核阅读心得免费分享-下载-收藏
免费分享-下载-收藏
TableofContents
读核感悟.......................................................................2
读核感悟-Linux内核启动-内核的生成...........................................2读核感悟-Linux
读核感悟-Linux
读核感悟-Linux
读核感悟-Linux内核启动-从helloworld说起...................................3内核启动-BIOS.................................................5内核启动-setup辅助程序........................................6内核启动-内核解压缩...........................................8
读核感悟-Linux内核启动-开启页面映射.........................................9
读核感悟-Linux内核启动-链接脚本............................................11
读核感悟-伪装现场-系统调用参数.............................................13
读核感悟-伪装现场-fork()系统调用...........................................15
读核感悟-伪装现场-内核线程:...............................................17
读核感悟-伪装现场-信号通信.................................................19
读核感悟-kbuild系统-内核模块的编译.........................................22
读核感悟-kbuild系统-编译到内核和编译成模块的区别...........................24
读核感悟-kbuild系统-makebzImage的过程.....................................26
读核感悟-kbuild系统-makemenuconfig........................................31
读核感悟-文件系统-用C来实现面向对象........................................32
读核感悟-设计模式-用C来实现虚函数表和多态..................................32
读核感悟-设计模式-用C来实现继承和模板......................................33
读核感悟-设计模式-文件系统和设备的继承和接口...............................34
读核感悟-设计模式-文件系统与抽象工厂.......................................36
读核感悟-阅读源代码技巧-查找定义...........................................37
读核感悟-阅读源代码技巧-变量命名规则.......................................42
读核感悟-内存管理-内核中的页表映射总结.....................................43
读核感悟-健壮的代码-exceptiontable-内核中的刑事档案.......................44
读核感悟-定时器-巧妙的定时器算法...........................................45
读核感悟-内存管理-pagefault处理流程.......................................45
读核感悟-文件读写-select实现原理...........................................47
读核感悟-文件读写-poll的实现原理...........................................49
1功能介绍:.............................................................49
2关键的结构体:.........................................................49
3poll的实现.............................................................49
4性能分析:.............................................................50
读核感悟-文件读写-epoll的实现原理..........................................50
1功能介绍...............................................................50
2关键结构体:...........................................................51
3epoll_create的实现.....................................................53
4epoll_ctl的实现........................................................53
5epoll_wait的实现.......................................................54
6性能分析...............................................................54
读核感悟-同步问题-同步问题概述.............................................55
1同步问题的产生背景.....................................................55
2内核态与用户态的区别...................................................55
读核感悟-同步问题-内核态自旋锁的实现.......................................56
1自旋锁的总述............................................................56
2非抢占式的自旋锁........................................................56
3锁的释放...............................................................57
4与用户态的自旋锁的比较.................................................57
5总结...................................................................58
读核感悟-内存管理-free命令详解.............................................58
读核感悟-文件读写-2.6.9内核中的AIO.........................................59
1AIO概述................................................................59
2内核态AIO的使用.......................................................61
读核感悟-文件读写-内核态AIO相关结构体......................................61
1内核态AIO操作相关信息.................................................61
2AIO上下文:............................................................63
3AIOring...............................................................63
4异步I/O事件的返回信息.................................................64
读核感悟-文件读写-内核态AIO创建和提交操作..................................65
1AIO上下文的创建-io_setup().............................................65
2AIO请求的提交:io_submit实现机制......................................66
读核感悟-文件操作-AIO操作的执行............................................66
1.在提交时执行AIO........................................................66
2.在工作队列中执行AIO....................................................66
3.负责AIO执行的核心函数aio_run_iocb.....................................67
4AIO操作的完成..........................................................67
读核感悟-文件读写-内核态是否支持非directI/O方式的AIO.....................67
读核感悟
读核感悟-Linux内核启动-内核的生成
这段时间在看《Linux内核源代码情景分析》,顺便写了一些感悟。
。
读内核源代码是一件很有意思的事。它像一条线,把操作系统,编译原理,C语言,数据结构与算法,计算机体系结构等等计算机的基础课程串起来。
我看内核源代码是用lxr+glimpse(不一定要自己架,可以直接访问校内外的lxr网站)的。如果在windows下也可以用sourceinsight。以下的当前路径为内核源代码路径,通常为/usr/src/linux。内核版本为2.6.13,平台为x86
好,让我们开始Linux内核之旅。
我们的出发点是在CPU加电的一刹那,系统处于16位实地址模式下,终点是内核开始运行start_kernel(),系统处于32位页式寻址的保护模式下。那时内核映象bzImage已经解压完毕,运行于内核态。系统中已经有了一个叫swapper的0号进程,有自己的内核堆栈,情况就相对好理解得多。(尽管与用户态程序相比,还要多操心不少事,包括对硬件的直接操作,内核态各种数据结构的初始化,对页表的操作等等)。
不过,不妨先做些准备动作。
首先,什么是内核?
目前,只知道编译内核后,产生一个叫bzImage的压缩内核映象。它不同于任何普通的可执行程序。我们甚至不知道它从哪里开始执行。只知道把它往/boot/下一放,往bootloader的配置文件(例如grub的menu.lst)中写上相关信息,机子就顺利启动了。
因此,我对它的生成过程产生了浓厚兴趣。于是,我查看了相关资料,最直接的资料来自于arch/i386/boot/下的Makefile。从Makefile中可以知道。bzImage的产生过程是这样的:
不过我不满足于此。于是,我想到了去看arch/i386/boot/下的Makefile。从
arch/i386/boot/Makefile和arch/i386/boot/compressed/Makefile中可以看出(具体过程省略,)
1.先生成vmlinux.这是一个elf可执行文件
2.然后objcopy成arch/i386/boot/compressed/vmlinux.bin,去掉了原elf文件中的一些无用的section等信息。
3.gzip后压缩为arch/i386/boot/compressed/vmlinux.bin.gz
4.把压缩文件作为数据段链接成arch/i386/boot/compressed/piggy.o
5.链接:arch/i386/boot/compressed/vmlinux=head.o+misc.o+piggy.o
其中head.o和misc.o是用来解压缩的。
6.objcopy成arch/i386/boot/vmlinux.bin,去掉了原elf文件中的一些无用的section等信息。
7.用arch/i386/boot/tools/build.c工具拼接bzImage=bootsect+setup+vmlinux.bin
过程好复杂。
这里要介绍一下objcopy命令,它的作用是把一个object文件转化为另一种格式的文件。在这里,objcopy的作用就是去掉原来elf文件中的elfheader和一些无用的
section信息。为什么要这么做呢?因为elf文件中的elfheader和一些section的作用是告诉elfloader如何载入elf可执行文件。但是,linux内核作为一种特殊的elf文件,需要特殊折辅助程序去装载它。往往它的装载地址是固定的。这时,为了保证通用性而存在的elfheader和一些section对内核的装载就没有意义了。加上为了使内核尽可能小,所以干脆把这些信息去掉。
我们可以看一下vmlinux和arch/i386/boot/compressed/vmlinux。用file命令查
看,它们也是elf可执行文件。只是没有main函数而已
参考:
Documentation/kbuild/makefiles.txt
Documentation/kbuild/modules.txt
读核感悟-Linux内核启动-从helloworld说起
内核是从哪里开始执行的呢?几乎任何一本Linux内核源代码分析的书都会给出详细的答案。不过,我试图从一个不同的角度(一个初学者的角度)来叙述,而不是一上来就给出答案。从熟悉的事物入手,慢慢接近陌生的事物,这是比较常见的思路。既然都是二进制代码,那么不妨从最简单的用户态C程序,helloworld开始。说不定能找到共同点。恰好我是一个喜欢寻根究底的人。也许,理解了helloworld程序的启动过程,有助于更好地理解内核的启动。
好,开始寻根究底吧。从普通的C语言用户态程序开始写。先写一个简单的helloworld程序。
/*helloworld.c*/
#include<stdio.h>
intmain()
{
printf("helloworld\n");
return0;
}
然后gcchelloworld.c-ohelloworld,一个最简单的helloworld程序出现了。
它是从哪里开始执行的呢?这还不简单?main函数么。地球人都知道。
为什么一定要从main函数开始呢?于是,我开始琢磨这个helloworld程序。filehelloworld可知,它是一个elf可执行文件。
反汇编试试。
objdump-dhelloworld
反汇编的结果令人吃惊,因为出现了_start()等一堆函数。一定是gcc编译时默认链接了一些库函数。
其实,只要运行gcc-vhelloworld.c-ohelloworld就会显示gcc详细的编译链接过程。其中包括链接/usr/lib/下的crti.ocrt1.ocrtn.o等等文件。用objdump查
看,_start()函数就定义在crt1.o文件中。
那么helloworld的真正执行的入口在哪里呢?我们可以使用readelf来查看,看有没有有用信息。
readelf-ahelloworld
helloworld作为一个elf文件,有elf文件头,sectiontable和各个section等
等。有兴趣可以去看看elf文件格式的文档。
用readelf可知,在helloworld的elf文件头的信息中,有这么一项信息:
入口点地址:0x80482c0
可见,helloworld程序的入口地址在0x80482c0处,而由objdump得:
080482c0<_start>:
可见,_start()是helloworld程序首先执行的函数。_start()执行完一些初始化工
作后,经过层层调用,最终调用main().可以设想,如果_start()里最终调用的是foo(),那么C程序的主函数就不再是main(),而是foo()了。
再进一步:helloworld程序具体是如何执行的呢。我们只能猜测是由bash负责执行的。然而具体看bash代码就太复杂了。我们可以用strace跟踪helloworld的执行。
strace./helloworld
出来一大堆函数调用。其中第一个是execve().这是一个关键的系统调用,它负责载入helloworld可执行文件并运行。其中有很关键的一步,就是把用户态的eip寄存器(实际上是它在内存中对应的值)设置为elf文件中的入口点地址,也就是_start()。具体可见内核中的sys_execve()函数。
由此可见,程序从哪里开始执行,取决于在刚开始执行的那一刻的eip寄存器的值。
而这个eip是由其它程序设置的,在这里,eip是由Linux内核设置的。具体过程如下:
1.用户在shell里运行./helloworld。
2.shell(这里是bash)调用系统调用execve()。
3.execve陷入到内核里执行sys_execve(),把用户态的eip设置为_start()。
4.当系统调用执行完毕,helloworld进程开始运行时,就从_start()开始执行
5.helloworld进程最后才执行到main()。
参考:elf文件格式
/linux/references/ELF_Format.pdf
读核感悟-Linux内核启动-BIOS
“真罗嗦,直接告诉我Linux下用glibc库编译出来的C程序真正的入口地址是
_start()不就行了么?”臭鸡蛋扑面而来。
嗯,我说了我只是想用一种特别的方式来叙述问题。我更看重探索的过程中体现的思
考方式以及其中的乐趣。
回到我们的主题。Linux内核为什么不是从main函数开始执行?事实上,Linux内核
源代码里有许多main()函数,但仔细一看。他们都是运行在用户态的。其实,从上一节中可以看到,main()函数只是一个符号而已。很多书上提到start_kernel()。它类似于
main()。但正如调用main()的是_start()。在start_kernel之前仍然有很多代码。所以内
核的真正入口并不是start_kernel()。
真正决定程序执行入口的是载入程序。对普通的C程序helloworld来说,Linux内核
(严格的说应该是bash)负责设置helloworld的入口点,并且启动helloworld进程的执
行。
于是,问题出现了,Linux内核的载入程序是什么呢?难道是自己载入自己?
这类类似的问题在计算机史上出现过很多次,比如,C程序可以用C编译器来写,那
么,C编译器用什么来写呢?当然,解决的方案有很多种,比如,用汇编语言写。那么汇编器用什么写呢?可以用机器语言写。虽然是件痛苦的事,但是一想到能造福这么多人,(发散一下,C编译器可以编译出各种新的语言的编译器或者解释器如perl,然后程序员们再用perl来编出各种复杂的系统),简直太伟大了,那位用机器语言写汇编器的程序员一定会浑身干劲。
可以借鉴一下思路,这类问题的常见的解决方式是构造一个简单的系统来解决一个复
杂的系统的问题,如此往复,像滚雪球一下,最终把一个极为复杂的问题解决掉。
所以,很自然的想到,用一个简单的内核,(不,它仅仅是一段程序,甚至不能称之
为内核,因为它的功能很有限)来启动真正的内核。就像用一个小当量的原子弹来引爆氢弹一样。
本着KISS(keepitsimpleandstupid)的原则,你第一时间可能会想到BIOS。BIOS
通常存在ROM上。随着ROM容量的扩展(达1M甚至更多)PC上的BIOS功能已经很强大了,
包括了很多设备的驱动程序。不仅可以进行硬件的检测,还实现了基本的输入输出功能。
(basicinput/outputsystem,这也是它的本意)。开机时按del键出现的BIOS设置画
面就是BIOS的杰作。在BIOS上实现一个OS也不是不可能。事实上DOS就是在BIOS的基础上实现的。
然而,BIOS的一个致命的缺点是到目前为止它基本上只能在16位实地址模式下运
行,毕竟ROM的容量很有限。(当然也不绝对,BIOS也提供了在保护模式下扫描PCI设备的方法,大牛们yy一下实现一个保护模式下运行的BIOS的可行性。)而CPU刚加电时处在16位实地址模式下。它的另一个致命的缺点是太小。因为现代操作系统多种多样,BIOS再强大也无法把所有可能的情况都考虑进去。
不过即使这样,PC机刚启动时,x86CPU仍然会自动从BIOS开始启动,这是由硬件
决定的,因为加电时,寄存器CS里的值为0xffff,IP里的值为0。于是CPU从线性地址0xffff0处开始取指令。0xffff0处是什么地方呢?
运行cat/proc/iomem
前面5行
00000000-0009fbff:SystemRAM
0009fc00-0009ffff:reserved
000a0000-000bffff:VideoRAMarea
000c0000-000cc7ff:VideoROM
000f0000-000fffff:SystemROM
可以看到0xffff0处是SystemROM,也就是BIOS
注意这里的地址是16位实地址模式下的线性地址。
而BIOS能做的事,包括开机时对设备的检测,最后去读硬盘上的第一个扇区(即引导扇区MBR)的512个字节,把它们拷贝到地址为0x7c00处的内存中。到此为止,BIOS的引导使命已经完成。虽然以后Linux内核的引导还要用到BIOS的功能,但引导的使命已经落在其它程序上了。
读核感悟-Linux内核启动-setup辅助程序
我们发现,在起点与终点之间,还有几个中转站。最近的一站叫作MBR。BIOS,带你到MBR后,说:“对不起,只能送你到这里了。”
那其它几个中转站是什么呢?我们知道,在x86上,保护模式有两种,32位页式寻址的保护模式和32位段式寻址的保护模式。显然,32位页式寻址的保护模式要求系统中已经构造好页表。从16位实地址模式直接到32位页式寻址的保护模式是很有难度的,因为你要在16位实地址模式下构造页表。所以不妨三级跳,先从16位实地址模式跳到32位段式寻址的保护模式,再从32位段式寻址的保护模式跳到32位页式寻址的保护模式。
我们需要这样一个程序,负责从16位实地址模式跳到32位段式寻址的保护模式,然后设置eip,启动内核。这个程序的确存在,就是arch/i386/boot/setup.S。最后汇编成setup程序。
事实上,平时所见的压缩内核映象bzImage,其实由三部分组成。这可以从
arch/i386/boot/tools/build.c中看出来。build.c是用户态工具build的源代码,后者用来把bootsect(MBR),setup(辅助程序)和vmlinux.bin(压缩过的内核)拼接成bzImage。
setup有了,它可以启动内核,然而新的问题来了。谁来启动setup呢?第一个想到的是MBR。可惜,MBR只有512个字节,而且有64个字节来存放主分区表。这样看来,MBR的功能就很有限了。所以,最好在setup和MBR之间再架一座桥梁。引导程序,对,用它来引导setup再合适不过了。现有的引导程序如grub,lilo不仅功能强大,而且还提供了人机交互的功能。再合适不过了。
所以,我们理清了大概思路,查阅相关资料可知:
1.CPU加电,从0xffff0处,执行BIOS(可以理解为“硬件”引导BIOS)
2.BIOS执行扫描检测设备的操作,然后将MBR读到物理地址为0x7c00处。然后从MBR头部开始执行(可以理解为BIOS引导MBR)
3.MBR上的代码跳转到引导程序,开始执行引导程序的代码,例如grub(引以理解为BIOS引导bootloader)。
4.引导程序把内核映象(包括bootsect,setup,vmlinux)读到内存中,其中setup位于
0x90200处,如果是zImage,则vmlinux.bin位于0x10000(64K)处。如果是bzImage,则vmlinux.bin位于0x100000(1M)处。然后执行setup(可以理解为bootloader引导setup)
5.setup负责引导linux内核vmlinux.bin
现在,让我们看看setup做了些什么。
首先,运行一下filesetup
它报告说这是一个MSDOS的可执行程序。看来,file也有不正常工作的时候。不过有一点是肯定的。setup不是普通的elf可执行程序。事实上,gcc可以编译出各种格式的程序,具体可以运行objdump-i,查看ld(gcc的链接器)支持的输出格式。其中有一个是binary格式。
从start开始,setup做了很多操作,例如,如果是zImage,则把它从0x10000拷贝到0x1000,调用bios功能,查询硬件信息,然后放在内存中供将来的内核使用,然后建立临时的idt和gdt,负责把16位实地址模式转化为32位段式寻址的保护模式。前面这些我们不关心。我们关心的是后者:
_
832movw$1,%ax#protectedmode(PE)bit833lmsw%ax#Thisisit!
正是以下指令开启了保护模式的大门。
最后,再临门一脚
对bzImage来说:
jmpi0x100000,__BOOT_CS
对zImage来说:
jmpi0x1000,__BOOT_CS
就大功告成了。
不过,且慢,由于当时CS寄存器还没有设置为__BOOT_CS,所以,尽管在保护模式下,也仍然不能用通常的方式访问大于1M的内存。
不过,x86处理器提供了特殊的手段来访问大于1M的内存,那就是在指令前加前缀0x66。由于跳转地址与内核大小相关(zImage和bzImage不一样)所以用一个小技巧,即把该指令
当作数据处理。在计算机看来,指令和数据是没什么区别的,只要ip寄存器指向内存中某地址,计算机就把地址中的数据当作指令来看待。
854.byte0x66,0xea#prefix+jmpi-opcode855code32:.long0x1000#willbesetto0x100000
856#forbigkernels
857.word__BOOT_CS
我不仅发出感慨:看setup.S的代码真是一种痛苦的体验,并且有以下感悟:
1.为什么不用C写呢?
原因很简单,因为setup要尽量短小精悍,由于种种原因,它的大小不能超过63.5K.启动时内存分配如下:
0x00000~0x00400BIOS中断向量表
0x00400~0x01000
0x01000~0x10000
0x10000~0x8f000用来存放zImage所以最多508K
0x8f000~0x90000引导程序的命令行参数以及bios查询的信息
0x90000~0x90200MBR
0x90200~0xA0000setup
0xA0000~0x100000映射到BIOS和外设硬件等
0x100000~存放bzImage(如果大于508K)
2.如何引用变量?
在setup.S中,定义了不少全局变量。在编译生成setup文件时,链接参数
LDFLAGS_setup:=-Ttext0x0-s--oformatbinary-ebegtext
意为text段的地址为0,输出格式为binary(而不是默认的elf32-i386),入口地址begtext。
由于基本上处于16位实模式下,所以只要设置好CS等段寄存器就可以正确地寻址了。
现在我们跳到vmlinux.bin的开头(位于0x1000或者0x100000),也就是startup_32(),执行相应代码。
3.helloworld,vmlinux,arch/i386/boot/compressed/vmlinux,setup,bootsect
的区别与联系。
这几个可执行文件都是由gcc编译生成。只是格式不一样。
其中,helloworld,vmlinux,arch/i386/boot/compressed/vmlinux都是elf32_i386
格式的可执行文件。setup,bootsect是binary格式的可执行文件,它们的区别在于
1).helloworld是普通的elf32_i386可执行文件。它的入口是_start。运行在用户态空间。变量的地址都是32位页式寻址的保护模式的地址,在用户态空间。由shell负责装载。
2).vmlinux是未压缩的内核,它的入口是startup_32(0x100000,线性地址),运行在内核态空间,变量的地址是32位页式寻址的保护模式的地址,在内核态空间。由内核自解压后启动运行。
3).arch/i386/boot/compressed/vmlinux是压缩后的内核,它的入口地址是
startup_32(0x100000,线性地址).运行在32位段式寻址的保护模式下,变量的地址是32位段式寻址的保护模式的地址。由setup启动运行。
4).setup是装载内核的binary格式的辅助程序。它的入口地址是:begtext(偏移地址为
0。运行时需要把cs段寄存器设置为0x9020)。运行在16位实地址模式下。变量的地址等于相对于代码段起始地址的偏移地址。由bootloader启动运行。
5).bootsect是MBR上的引导程序,也为binary格式。它的入口地址是_start(),由于装载
到0x7c00处,运行时需要把cs段寄存器设置为0x7c0。运行在16位实地址模式下。变量地址等于相对于代码段起始地址的偏移地址。由BIOS启动运行。
问题出现了。startup_32有两个,分别在这两个文件中:
arch/i386/boot/compressed/head.S
arch/i386/kernel/head.S
那究竟执行的是哪一个呢?难道编译时不会报错么?
读核感悟-Linux内核启动-内核解压缩
这得从vmliux.bin的产生过程说起。
从内核的生成过程来看内核的链接主要有三步:
第一步是把内核的源代码编译成.o文件,然后链接,这一步,链接的是
arch/i386/kernel/head.S,生成的是vmlinux。注意的是这里的所有变量地址都是32位页寻址方式的保护模式下的虚拟地址。通常在3G以上。
第二步,将vmlinuxobjcopy成arch/i386/boot/compressed/vmlinux.bin,之后加
以压缩,最后作为数据编译成piggy.o。这时候,在编译器看来,piggy.o里根本不存在什么startup_32。
第三步,把head.o,misc.o和piggy.o链接生成
arch/i386/boot/compressed/vmlinux,这一步,链接的是
arch/i386/boot/compressed/head.S。这时arch/i386/kernel/head.S中的startup_32被
压缩,作为一段普通的数据,而被编译器忽视了。注意这里的地址都是32位段寻址方式的保护模式下的线性地址。
自然,在这过程中,不可能会出现startup_32重定义的问题。
你可能会说:太BT了,平时谁会采用这种方式编译程序?
是啊,然而在内核还没启动的情况下,要高效地实现自解压,还有更好的方式么?
所以前面的问题就迎刃而解。setup执行完毕,跳转到vmlinux.bin中的
startup_32()是arch/i386/boot/compressed/head.S中的startup_32()
这是一段自解压程序,过程和内核生成的过程正好相反。这时,CPU处在32位段寻址方式的保护模式下,寻址范围从1M扩大到4G。只是没有页表。
我们对具体的解压过程不感兴趣。
内核解压完毕。位于0x100000即1M处
最后,执行一条跳转指令,执行0x100000处的代码,即startup_32(),这回是arch/i386/kernel/head.S中的startup_32()代码
ljmp$(__BOOT_CS),$__PHYSICAL_START
读核感悟-Linux内核启动-开启页面映射
在setup的帮助下,我们顺利地从16位实地址模式过渡到32位段式寻址的保护模式。又在arch/i386/boot/compressed/head.S的帮助下实现了内核的自解压,并且从arch/
i386/kernel/head.S中的startup_32开始。现在在线性地址0x100000(1M)处开始就是我们的解压后的内核了。而startup_32()的地址恰好是0x100000。由于还没有开启页面映射,
所以必须引用变量的线性地址(即变量的虚拟地址-PAGE_OFFSET),带来了很多不便。所以下一步的任务,就是建立页表,开启页面映射了。我们不妨从arch/i386/kernel/head.S入手。
由于在Linux中,每个进程拥有一个页表,那么,第一个页表也应该有一个对应的进程。通常情况下,Linux下通过fork()系统调用,复制原有进程,来产生新进程。然而第一个进程该如何产生呢?既然不能复制,那就只能像女娲造人一样,以全局变量的方式捏造一个出来。它就是init_thread_union。传说中的0号进程,名叫swapper。只要swapper进程运行起来,调用start_kernel(),剩下的事就好办了。不过,现在离运行swapper进程还
差得很远。关键的一步,我们还没有为该进程设置页表。
为了保持可移植性,Linux采用了三级页表。不过x86处理器只使用两级页表。所
以,我们需要一个页目录和很多个页表(最多达1024个页表),页目录和页表的大小均为4k。swapper的页目录的创建与该进程的创建思维类似,也是捏造一个页表,叫
swapper_pg_dir.
417ENTRY(swapper_pg_dir)
418.fill1024,4,0
它的意思是从swapper_pg_dir开始,填充1024项,每项为4字节,值为0,正好是4K一个页面。
页目录有了,接下去看页表。一个问题产生了。该映射几个页表呢?尽管一个页目录最多能映射1024个页表,每个页表映射4M虚拟地址,所以总共可以映射4G虚拟地址空
间。但是,通常应用程序用不了这么多。最简单的想法是,够用就行。先映射用到的代码和数据。还有一个问题:如何映射呢?运行cat/proc/$pid/maps可以看到,用户态进程的地址映射是断断续续的,相当复杂。这是由于不同进程的用户空间相互独立。但是,由于所有
进程共享内核态代码和数据,所以映射关系可以大大简化。既然内核态虚拟地址从3G开始,而内核代码和数据事实上是从物理地址0x100000开始,那么本着KISS原则,一切从简,加上3G就作为对应的虚拟地址好了。由此可见,对内核态代码和数据来说:虚拟地址=物理地址+PAGE_OFFSET(3G)
内核中有变量pg0,表示对应的页表。建立页表的过程如下:
091page_pde_offset=(__PAGE_OFFSET>>20);
092
093movl$(pg0-__PAGE_OFFSET),%edi
094movl$(swapper_pg_dir-__PAGE_OFFSET),%edx
095movl$0x007,%eax/*0x007=PRESENT+RW+USER*/
09610:
097leal0x007(%edi),%ecx/*CreatePDEentry*/098movl%ecx,(%edx)/*StoreidentityPDEentry*/
099movl%ecx,page_pde_offset(%edx)/*StorekernelPDEentry*/100addl$4,%edx
101movl$1024,%ecx
10211:
103stosl
104addl$0x1000,%eax
105loop11b
106/*Endcondition:wemustmapuptoandincluding
INIT_MAP_BEYOND_END*/
107/*bytesbeyondtheendofourownpagetables;the+0x007istheattributebits*/
108leal(INIT_MAP_BEYOND_END+0x007)(%edi),%ebp
109cmpl%ebp,%eax
110jb10b
111movl%edi,(init_pg_tables_end-__PAGE_OFFSET)
用伪代码表示就是:
typedefunsignedintPTE;
PTE*pg=pg0;
PTEpte=0x007;
for(i=0;;i++){//把线性地址i*4MB~(i+1)*4MB-1(用户空间地址)和3G+i*4MB~3G+
(i+1)*4MB-1(内核空间地址)映射到物理地址i*4MB~(i+1)*4MB-1
swapper_pg_dir[i]=pg+0x007;
swapper_pg_dir[i+page_pde_offset]=pg+0x007;
for(j=0;j<1024;j++){
pte+=0x1000;
pg[i*1024+j]=pte;
}
if(pte>=((char*)pg+i*1024+j)*4+0x007+INIT_MAP_BEYOND_END)
{
init_pg_tables_end=pg+i*0x1000+j;
break;
}
}
大致意思是从0开始,把连续的线性地址映射到物理地址。这里的0x007是什么意思呢?由于每个页表项有32位,但其实只需保存物理地址的高20位就够了,所以剩下的低12位可以用来表示页的属性。0x007正好表示PRESENT+RW+USER(在内存中,可读写,用户页面,这样在用户态和内核态都可读写,从而实现平滑过渡)。
那么结束条件是什么呢?从代码中可知,当映射到当前所操作的页表项往下
INIT_MAP_BEYOND_END(128K)处映射结束。nmvmlinux|greppg0得c0595000。据此可以计算总共映射了多少页(小学计算题:P)
所以映射了2个页表,映射地址从0x0~0x2000-1,大小为8M。
最后,关键时刻到来了:
183/*
184*Enablepaging
185*/
186movl$swapper_pg_dir-__PAGE_OFFSET,%eax
187movl%eax,%cr3/*setthepagetablepointer..*/
188movl%cr0,%eax
189orl$0x80000000,%eax
190movl%eax,%cr0/*..andsetpaging(PG)bit*/
开启页面映射后,可以直接引用内核中的所有变量了。不过离start_kernel还有点
距离。要启动swapper进程,得首先设置内核堆栈。
193/*Setupthestackpointer*/
194lssstack_start,%esp
然后设置中断向量表,看到久违的"call"了
215callsetup_idt
检查CPU类型
载入gdt(原来的gdt是临时的)和ldt
302lgdtcpu_gdt_descr
303lidtidt_descr
最后,调用start_kernel
327callstart_kernel
到这一步,我们的目的地终于走到了。在摆脱了晦涩的汇编之后,接下去的代码,虽
然与用户态程序相比,还有中断,同步等等的干扰,但相比较而言就好懂很多了。
读核感悟-Linux内核启动-链接脚本
一般来说,用户是不需要关心section的具体位置的。在用户态,内核会解析elf可执行文件的各个section,然后把它映射到虚拟地址空间。然而,在内核启动时,一切得从
零开始。很多在用户态下应用程序不需要操心的东西,例如映射section的任务不得不由内核自己来完成。上一篇感悟揭示了内核如何建立页表,并且把自身的一部分映射到虚拟地址。内核还要负责对BSS段(所有在代码中未定义的全局变量)的初始化(设置为0),这就要求内核知道section的具体位置(否则如何知道该映射哪一部分呢?)
此外,在开启页面映射的过程中,我最为疑惑的是几个常量(页目录
swapper_pg_dir,页表pg0等等)是如何确定的。扩展一下。gcc链接可执行文件时,是如何确定变量的地址的?按理说应该有某种途径(命令行参数或者文件)告诉链接器ld如何定位这些变量。最普通如helloworld。为什么_start的地址是0x80482e0?于是想到,我们需要一个文件来指定各个section的虚拟地址。在内核源代码里,还看到这个文件arch/i386/kernel/vmlinux.lds.S。不像是普通的汇编文件。原来这就是linkerscripts
链接器脚本。
在链接器脚本中,.表示当前locationcounter地址计数器的值。默认为0。
017.=__KERNEL_START;
表示地址计数器从__KERNEL_START(0xc00100000)开始。
.text:{...}
表示.textsection包含了哪几个section
031.=ALIGN(16);
则表示对齐方式。
具体格式可以调用infold查看LinkerScripts一节。
链接器脚本指定了各个section的起始位置和结束位置。它还允许程序员在脚本中对变量进行赋值。这使内核可以通过__initcall_start和__initcall_end之类的变量获得段的起始地址和结束地址,从而对某些段进行操作。
根据链接器脚本,以及nmvmlinux的结果,内核中各个section的虚拟地址就很清楚了。以我的机子为例(粗略):
地址分配
textsection:
从_text:c0100000A_text
到_etext:c0436573A_etext
Exceptiontable
从__start___ex_table:c0436580A__start___ex_table
到__stop___ex_table:c04370b8A__stop___ex_table
RODATAreadonlysection
.datawritablesection
.data_nosavesection
从__nosave_begin:c050f000A__nosave_begin
到__nosave_end:c050f000A__nosave_end
.data.page_alignedsection
.data.cacheline_alignedsection
.data.read_mostlysection
.data.init_tasksection
initsection
从__init_beginc0514000A__init_begin
到__init_endc0540000A__init_end
其中.initcall.initsection:
从__initcall_start:c053b570A__initcall_start
到__initcall_end:c053b8c0A__initcall_end
BSSsection
从__bss_startc0540000A__bss_start
到__bss_endc0594c78A__bss_stop
其中swapper进程的页表
从c0540000Bswapper_pg_dir
到c0541000
共一页
empty_zero_page
从c0541000Bempty_zero_page
到c0542000
共一页
pg0页目录0
从c0595000Apg0
到init_pg_tables_end
.exitcall.exit
section
stabsection
几个比较重要的section:
bsssection,存放在代码里未初始化的全局变量,最后初始化为0。
initsections,所有只在初始化时调用的函数和变量,包括所有在内核启动时调用的函数,以及内核模块初始化时调用的函数。其中最特别的是.initcall.initsection。通过__initcall_start和__initcall_end,内核可以调用里面所有的函数。这些section在使用一次后就可以释放,从而节省内存。
读核感悟-伪装现场-系统调用参数
内核支配了整个计算机的硬件资源,好像一位独裁者,高高在上。他有时候必须像法官一样公正,有时候则必须像狐狸一样狡猾。伪装现场就是他的拿手好戏。
系统调用是很特别的函数,因为它里面实现了用户态到内核态的转换。应用程序要创建新进程,不可能在用户态直接调用sys_fork()。这就需要内核为sys_fork()伪装一下调用现场。
比如fork()系统调用,它有一个简洁得不能再简洁的接口。不过它在内核中的对应函数中的声明却是:
asmlinkageintsys_fork(structpt_regsregs)
如果有兴趣看早期的Linux源代码版本(0.95),它的声明是这样的:
intsys_fork(longebx,longecx,longedx,
longesi,longedi,longebp,longeax,longds,
longes,longfs,longgs,longorig_eax,
longeip,longcs,longeflags,longesp,longss)
这些参数是如何来的呢。为什么用户态参数与内核态参数不一致?
又如clone(),vfork()这几个系统调用在用户态的参数个数和类型都不一样。但在内核态都致。
asmlinkageintsys_clone(structpt_regsregs)
asmlinkageintsys_vfork(structpt_regsregs)
接下去,我们可以看到,内核是多么巧妙地设置堆栈,让内核的函数感觉就好像上层函数在调用它一样。
我们很容易得知,这些参数是在系统调用进入内核时由int0x80指令和SAVE_ALL宏把一些寄存器压入内核堆栈的。压入的寄存器数量和顺序是一致的,它们恰好与structpt_regs一一对应。从这个角度讲,所有的系统调用获得的参数是形式是一样的。026structpt_regs{
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041longebx;longecx;longedx;longesi;longedi;longebp;longeax;intintxds;xes;longorig_eax;longeip;intxcs;longeflags;longesp;intxss;
042};
其中xss到eip由int指令压入内核堆栈。orig_eax到ebx为ENTRY(system_call)压入堆
栈。orig_eax为系统调用号。eax作为返回值。ebp~ebx作为系统调用的参数。
linux的系统调用在内核中对应函数如sys_fork()的声明前都有一个asmlinage的宏。它被定义为:
#defineasmlinkageCPP_ASMLINKAGE__attribute__((regparm(0)))
也就是说,所有的参数都通过堆栈传递。注意,这里的堆栈传递已经在内核态了,与系统调用参数通过寄存器传递并不矛盾(那个是之前在用户态到内核态的切换过程中)。
这样就意味着我们只要巧妙地设置好堆栈,让sys_fork()产生一种错觉,好像是上层的一个函数直接调用sys_fork()一样。事实上sys_fork()也的确可以在内核态直接调用。
我们又观察到:内核中_syscall0,_syscall1,_syscall2,。。。这些宏用来封装系
统调用(只是内核自己用,glibc不用这些宏而已。)传递参数的方式是这样的:参数1~参数6正好放在ebxecxedxesiediebp中,这恰好与pt_regs中的顺序相对应。为什么采用这样的一种顺序呢?
1.这与编译器的编译规则有关。标准的C函数编译时,总是从右往左依次把参数压入堆栈。执行到函数内部时,就根据这样的规则依次从堆栈中取出参数。所以在内核中也不例外。当应用程序执行系统调用,进入到内核态中的ENTRY(system_call)调用
call*sys_call_table(,%eax,4)
时,所有的参数都在堆栈中准备就绪。
具体这些参数怎么理解,就取决于函数的定义了。
如果认为内核堆栈中放的是个结构体pt_regs,就可以定义为
asmlinkageintsys_fork(structpt_regsregs)
如果认为内核堆栈中放的是一个个整数,就可以定义为
asmlinkageintsys_fork(longebx,longecx,longedx,
longesi,longedi,longebp,longeax,longds,
longes,longfs,longgs,longorig_eax,
longeip,longcs,longeflags,longesp,longss)
其它的系统调用也类似。
通过巧妙的构造堆栈,达到调用内核函数的目的。
除了系统调用,还有其它函数如do_page_fault()等等,也是用类似的手段。
读核感悟-伪装现场-fork()系统调用
不仅进入系统调用时要伪装现场,fork系统调用时返回时也需要伪装现场。因为是“无中生有”。
例如在fork创建新进程时,系统要保证新进程与旧进程一样,从相同的代码开始执行。比如:
#include<stdio.h>
#include<unistd.h>
intmain()
{
pid_tpid;
if((pid=fork())>0)
{
printf("parent\n");
}
elseif(pid==0)
{
printf("child\n");
}
else
printf("error\n");
return0;
}
在fork()处,也就是执行call指令的过程中,产生了一个新进程。
80483f0:e8effeffffcall80482e4@>
执行完fork()后,新旧两个进程都执行相同的指令:
80483f5:8945fcmov%eax,0xfffffffc(%ebp)
80483f8:837dfc00cmpl$0x0,0xfffffffc(%ebp)
给人的感觉是新进程和旧进程一样,也是从main函数开始执行,只是执行到fork()处,返回值不一样而已。内核是如何做到的呢?当内核执行fork()系统调用时,内核堆栈里保存
有很多寄存器的值。其中包括了eax等几个通用寄存器。通过SAVE_ALL和RESTORE_ALL这两个宏,pt_regs结构体里的变量与对应的寄存器建立了一一对应关系。只要修改pt_regs结构体里的变量,就可以达到修改系统调用结束后,进程执行那一刹那的寄存器值。
这样就简单了,因为fork()时首先把PCB复制了一份(sys_fork()->do_fork()-
>copy_process->dup_task_struct)。所以内核堆栈pt_regs结构体里的值也跟着复制了一
份。之后,在copy_thread()中,把新进程的pt_regs的eax,也就是新进程的返回值设置
为0,eip不变。这样当新进程返回到用户态时,就仿佛刚执行完fork()返回0。
这是伪装用户态的现场。还有内核态的现场呢?
copy_thread()中有以下代码:
468childregs=(structpt_regs*)((unsignedlong)childregs-8);
469
470
471
472
473p->thread.esp=(unsignedlong)childregs;
当子进程被调度到时,子进程处于内核态。经过switch_to()进程切换,eip设置为thread.eip,esp设置为thread.esp。eip是ret_from_fork,esp是childregs。伪装成刚执行完系统调用fork准备从内核态返回到用户态。
474p->thread.esp0=(unsignedlong)(childregs+1);
thread.esp0在switch_to()->__switch_to()中,会通过load_esp0设置为
tss_struct中的esp0。这个字段是在CPU运行状态变化时(如系统调用从用户态进入内核态)保存0级也就是内核态的堆栈指针。这样的话不是有两个地方有内核态堆栈指针了么?不过他们不矛盾。thread.esp在进程切换时使用。thread.esp0在CPU运行状态变化时使用。当子进程返回到用户态后又发生中断或者系统调用。这时使用的是esp0,内核堆栈是空的。正好指向(unsignedlong)(childregs+1)。
如何同步,我也不清楚。
475
476p->thread.eip=(unsignedlong)ret_from_fork;
p->thread中保存了进程切换所需的很多信息。包括内核态的esp,eip
伪装的现场,给人的感觉是新进程在内核态正好快执行到ret_from_fork时由于中断等原因被抢占,所以在fork()完毕后可能进行的进程调度中,新进程可能被调度到,在执行完ret_from_fork中的一些代码,返回到用户态后,开始执行fork()之后的代码。*childregs=*regs;=0;=esp;childregs->eaxchildregs->esp读核感悟-伪装现场-内核线程:
众所周知,内核中创建一个内核线程是通过kernel_thread实现的。声明如下:
intkernel_thread(int(*fn)(void*),void*arg,unsignedlongflags);
我们知道,用户态创建线程调用clone(),如果要在内核态创建线程,首先想到的是在内核态调用clone()。这是可以的。比如在init内核线程中就直接在内核态调用
execve,参数为/sbin/init等等。但是还是要小心翼翼。因为系统调用里会有很多参数要求是用户态的(一般在声明前有__user),在调用一些内核函数时也会检查参数的界限,严格要求参数在用户态。一旦发现参数是在内核态,就立即返回出错。
所以kernel_thread采用了另外一种办法。
由于不是从用户态进入内核的,它需要制造一种现场,好像它是通过clone系统调用进入内核一样。方法是手动生成并设置一个structpt_regs,然后调用do_fork()。但是怎
样把线程的函数指针fn,参数arg传进去呢?和flags不同,flags可以作为do_fork()的参数。但是fn正常情况下应该是在clone()结束后才执行的。此外,线程总不能长生不老吧,所以执行完fn()还要执行exit()。
所以,我们希望内核线程在创建后,回到内核态(普通情况下是用户态)后,去调用fn(arg),最后调用exit()。而要去“遥控”内核线程在创建以后的事,只能通过设置
pt_regs来实现了。
看kernel_thread的实现:
355regs.ebx=(unsignedlong)fn;
356regs.edx=(unsignedlong)arg;
358
359
360
361这里设置了参数fn,arg,当内核线程在创建以后,ebx中放的是fn,edx中放的是argregs.xds=__USER_DS;regs.xes=__USER_DS;=-1;regs.orig_eaxregs.eip=(unsignedlong)kernel_thread_helper;
362当内核线程在创建以后,执行的是kernel_thread_helper函数regs.xcs=__KERNEL_CS;
当内核线程在创建以后,cs寄存器的值表明当前仍然处于内核态。
regs.eflags=X86_EFLAGS_IF|X86_EFLAGS_SF|
X86_EFLAGS_PF|0x2;363
364
365
366/*Ok,createthenewprocess..returndo_fork(flags*/|CLONE_UNTRACED,0,|CLONE_VM
®s,0,NULL,
NULL);
看来kernel_thread_helper就是我们想要的东西了。
336__asm__(".section.text\n"
337
338
339
340".align4\n""kernel_thread_helper:\n\t""movl%edx,%eax\n\t""pushl%edx\n\t"
341
342
343"call"pushl*%ebx\n\t"%eax\n\t""calldo_exit\n"
344".previous");
首先把edx保存到eax(不明白为什么这么做,因为调用fn后返回值就把eax覆盖掉了)把edx(其实就是参数arg)压入堆栈,然后调用ebx(也就是fn)。最后调用
do_exit。kernel_thread_helper是不返回的。
这里,内核通过巧妙设置pt_regs,在没有用户进程的情况下,在内核态创建了线程。
读核感悟-伪装现场-信号通信
信号是进程之间通信的一种方式。它包括3部分操作:
1.设置信号处理函数。系统调用signal。内核调用sys_signal(),设置当前进程对
某信号的处理函数。
2.发送信号.系统调用kill。内核调用sys_kill()。向目标进程发送信号。
3.接收并处理信号。目标进程调用do_signal()处理信号。
从用户态的角度看,目标进程在执行用户态的代码时突然“中断”,转而去执行对应的信号处理函数(同样在用户态)。等到信号处理函数执行完后,又从原来被中断的代码开始执行。
如何达到这样的效果呢?由前面的几种内核的伪装现场的手段,我们可以猜出它这次使用的手段。比如,要让目标进程执行信号处理函数,在内核态中当然不可能直接调用,但
是可以通过设置pt_regs中的eip来达到这种效果。但是,要使目标进程在执行完信号处理函数后,又恢复到被中断的现场继续执行,那得花些技巧。不过,不外乎设置堆栈。这一次
还包括了用户态堆栈。由于恢复的任务比较艰巨,系统干脆提供了一个系统调用sigreturn。
既然内核希望用户在执行完信号处理函数后,调用sigreturn。接下去的思路就比较简单了。就是先把用户态的eip设置为signal_handler(通过修改pt_regs中的eip来实现),然后把堆栈中的返回地址改成调用sigreturn的一段代码的入口(当然原来的返回地址也还是要保存的)并且把相关参数“压入”用户态堆栈。
这样,在源进程发送信号后不久,目标进程被调度到,然后执行到do_signal。对信号一一作处理。调用顺序:
do_signal()->handle_signal()->setup_rt_frame()
用来设置用户态堆栈。
我们看看这个函数做了些啥?
447frame=get_sigframe(ka,regs,sizeof(*frame));
structrt_sigframe__user*frame是内核在用户态的堆栈上新分配的一个数据结构。
011structrt_sigframe
012{
013
014
015
016
017
018
019
020
021};
图示:
高地址
--------------
--------------
frame->retcodechar*pretcode;intsig;structsiginfovoid*puc;structsiginfoinfo;structucontextuc;struct_fpstatefpstate;charretcode[8];*pinfo;用户进程原堆栈底部用户进程原堆栈顶部frame底部
frame->pretcode返回地址:从signalhandler返回后跳转的地址--------------frame顶部:用户进程新堆栈顶部
低地址
里面保存了大量用户态进程的上下文信息。尤其是pretcode,现在位于用户进程的新堆栈的顶部。
接下去开始设置frame
458err|=__put_user(usig,&frame->sig);
459
460
461
462
463
464err|=__put_user(&frame->info,err|=__put_user(&frame->uc,&frame->pinfo);&frame->puc);err|=copy_siginfo_to_user(&frame->info,info);if(err)gotogive_sigsegv;
465
466
467
468
469
470/*Createtheucontext.err|=__put_user(0,err|=__put_user(0,*/&frame->uc.uc_flags);&frame->uc.uc_link);&frame->uc.uc_stack.ss_sp);err|=__put_user(current->sas_ss_sp,err|=__put_user(sas_ss_flags(regs->esp),&frame->uc.uc_stack.ss_flags);
&frame-471err|=__put_user(current->sas_ss_size,
>uc.uc_stack.ss_size);
472
473
474err|=setup_sigcontext(&frame->uc.uc_mcontext,regs,set->sig[0]);&frame->fpstate,err|=__copy_to_user(&frame->uc.uc_sigmask,set,sizeof(*set));
当用户进程根据pt_regs中设置好的eip执行signalhandler。执行完毕后就会把frame->pretcode作为返回地址。(这一点2.6.13的内核与2.4的不同,后者是把指针指向retcode,其实仍然是调用sigreturn的代码。)
478
479
480
481
482/*Setuptoreturnfromuserspace.restorer*/=&__kernel_rt_sigreturn;&SA_RESTORER)=ka->sa.sa_restorer;&frame->pretcode);if(ka->sa.sa_flagsrestorererr|=__put_user(restorer,
这里的&__kernel_rt_sigreturn就是内核设置的负责信号处理“善后”工作的代码
入口。定义在arch/i386/kernel/vsyscall-sigreturn.S
nm/usr/src/linux/vmlinux|grep_kernel_rt_sigreturn
得,它的值是_kernel_rt_sigreturn
&__kernel_rt_sigreturn的值应该是内核态的。
问题来了。frame->pretcode是作为进程在用户态执行的代码(事实上,从执行
signalhandler开始,进程一直处于用户态)。它怎么能访问内核态的代码呢?这不是会
段错误么?
这里涉及到PIII中用sysenter来代替系统调用的int0x80的问题。大概就是内核允许一部分代码给用户态进程访问。
例如:
cat/proc/$pid/maps可以看到:
ffffe000-fffff000---p0000000000:000[vdso]
ldd一个应用程序也可以看到:
linux-gate.so.1=>(0xffffe000)
在arch/i386/kernel/中可以看到两个文件:
vsyscall-sysenter.so
vsyscall-int80.so
也就是说,__kernel_rt_sigreturn这段代码是链接在两个动态链接文件中。而不是vmlinux这个内核文件中。
具体是如何做到的,就不展开说了。
总之,在执行完signalhandler后,进程将跳转到__kernel_rt_sigreturn。
021__kernel_sigreturn:
022.LSTART_sigreturn:
023
*/
024
025popl%eax/*XXXdoesthismeanitneedsunwindinfo?movl$__NR_sigreturn,%eaxint$0x80
实际上调用的是sigreturn系统调用。该系统调用会根据frame里的信息,把堆栈恢复到处理信号之前的状态。所以这段代码是不返回的。然后,用户进程就像什么事也没发生,继续照常运行。
这里,内核通过设置用户态堆栈的手段,达到了打断用户态进程的运行,转而调用signalhandler的目的。手段不可谓不高明。
读核感悟-kbuild系统-内核模块的编译
Linux内核是一种单体内核,但是通过动态加载模块的方式,使它的开发非常灵活方便。那么,它是如何编译内核的呢?我们可以通过分析它的Makefile入手。以下是一个简单的hello内核模块的Makefile.
ifneq($(KERNELRELEASE),)
obj-m:=hello.o
else
KERNELDIR:=/lib/modules/$(shelluname-r)/build
PWD:=$(shellpwd)
default:
$(MAKE)-C$(KERNELDIR)M=$(PWD)modules
clean:
rm-rf
endif*.o*.mod.c*.mod.o*.ko
当我们写完一个hello模块,只要使用以上的makefile。然后make一下就行。
假设我们把hello模块的源代码放在/home/study/prog/mod/hello/下。
当我们在这个目录运行make时,make是怎么执行的呢?
LDD3第二章第四节“编译和装载”中只是简略地说到该Makefile被执行了两次,但是具体过程是如何的呢?
首先,由于make后面没有目标,所以make会在Makefile中的第一个不是以.开头的目标作为默认的目标执行。于是default成为make的目标。make会执行$(MAKE)-C$(KERNELDIR)M=$(PWD)modules
。
shell是make内部的函数,假设当前内核版本是2.6.13-study,所以$(shelluname-
r)的结果是2.6.13-study
这里,实际运行的是
make-C/lib/modules/2.6.13-study/buildM=/home/study/prog/mod/hello/
modules
/lib/modules/2.6.13-study/build是一个指向内核源代码/usr/src/linux的符号链
接。
可见,make执行了两次。第一次执行时是读hello模块的源代码所在目
录/home/study/prog/mod/hello/下的Makefile。第二次执行时是执行/usr/src/linux/下
的Makefile时.
但是还是有不少令人困惑的问题:
1.这个KERNELRELEASE也很令人困惑,它是什么呢?
在/home/study/prog/mod/hello/Makefile中是没有定义这个变量的,所以起作用的是else...endif这一段。不过,如果把hello模块移动到内核源代码中。例如放
到/usr/src/linux/driver/中,KERNELRELEASE就有定义了。
在/usr/src/linux/Makefile中有
162KERNELRELEASE=$(VERSION).$(PATCHLEVEL).$(SUBLEVEL)$(EXTRAVERSION)$(LOCALVERSION)
这时候,hello模块也不再是单独用make编译,而是在内核中用makemodules进行编译。
用这种方式,该Makefile在单独编译和作为内核一部分编译时都能正常工作。
2.这个obj-m:=hello.o什么时候会执行到呢?
在执行:
make-C/lib/modules/2.6.13-study/buildM=/home/study/prog/mod/hello/modules
时,make去/usr/src/linux/Makefile中寻找目标modules:
862.PHONY:modules
863modules:
864
865$(vmlinux-dirs)@echo$(if$(KBUILD_BUILTIN),vmlinux)'Buildingmodules,stage2.';$(srctree)/scripts/Makefile.modpost$(Q)$(MAKE)-rR-f
可以看出,分两个stage:
1.编译出hello.o文件。
2.生成hello.mod.ohello.ko
在这过程中,会调用
make-fscripts/Makefile.buildobj=/home/study/prog/mod/hello
而在scripts/Makefile.build会包含很多文件:
011-include.config
012
013include$(if$(wildcard$(obj)/Kbuild),$(obj)/Kbuild,$(obj)/Makefile)其中就有/home/study/prog/mod/hello/Makefile
这时KERNELRELEASE已经存在。
所以执行的是:
obj-m:=hello.o
关于makemodules的更详细的过程可以在scripts/Makefile.modpost文件的注释中找到。如果想查看make的整个执行过程,可以运行make-n。
由此可见,内核的Kbuild系统庞大而复杂。
读核感悟-kbuild系统-编译到内核和编译成模块的区别
代码编译到内核和编译成模块在代码中有什么区别呢?
从模块的代码中看是一样的。入口函数都是module_init(fun),但是代码中的条件编译会使宏module_init()在编译到内核和编译成模块的情况下替换成不同的代码。
include/linux/init.h中可知
#ifndef
...
#definemodule_init(x)__initcall(x);
...
#else/*
...
/*Eachmodulemustuseonemodule_init(),oroneno_module_init*/MODULEMODULE*/
#definemodule_init(initfn)
staticinlineinitcall_t__inittest(void)\\
{returninitfn;}\
intinit_module(void)__attribute__((alias(#initfn)));
...
#endif
当代码编译成模块时,会定义MODULE宏,否则不会。因为在/usr/src/linux/Makefile中可以看到
336MODFLAGS=-DMODULE
337CFLAGS_MODULE=$(MODFLAGS)
338AFLAGS_MODULE=$(MODFLAGS)
这两个变量又被export成为全局变量。所以可以知道,在编译成模块时,会有MODULE这个宏。
由以下代码可以知道
#define__initcall(fn)device_initcall(fn)
#definedevice_initcall(fn)__define_initcall("6",fn)
085#define__define_initcall(level,fn)
086
087\\".init")))=fnstaticinitcall_t__initcall_##fn__attribute_used____attribute__((__section__(".initcall"level
前者实际上是编译入内核中的.initcall6.init这个section
而在
arch/i386/kernel/vmlinux.lds.S中可以知道:
083__initcall_start=.;
084
085.initcall.init:AT(ADDR(.initcall.init)-LOAD_OFFSET){*(.initcall1.init)
086
087
088
089
090
091*(.initcall2.init)*(.initcall3.init)*(.initcall4.init)*(.initcall5.init)*(.initcall6.init)*(.initcall7.init)
092
093}__initcall_end=.;
arch/i386/kernel/vmlinux.lds.S
.initcall6.init是.initcall.init的一部分
执行顺序:
start_kernel->rest_init
系统启动后在rest_init中会创建init内核线程
init->do_basic_setup->do_initcalls
do_initcalls中会把.initcall.init中的函数依次执行一遍
for(call=__initcall_start;call<__initcall_end;call++)
...
(*call)();
...
}
于是执行了module_init(fn)函数
读核感悟-kbuild系统-makebzImage的过程{
从以上例子中可以看到,内核的编译系统kbuild是个很庞大的系统。但是,它所使用的make和我们平时用的make是一模一样的。kbuild只是通过预定义一些变量(obj-m,obj-y等等)和目标(bzImage,menuconfig等等),使内核的编译和扩展变得十分方便。我们不妨yy一下kbuild的一些功能:
1.考虑到Linux能够方便地移植到各个硬件平台,kbuild也必须很容易添加对某个新的平台的支持,同时上层的Makefile不需要做大的改动。
2.Linux下有众多驱动设备。它们的Makefile希望能够尽可能简洁。简洁到只要指定要编译的.o文件就行。(这方面kbuild定义了很多有用的变量如obj-mobj-y,<module>-
objs等等,用户只要为这些变量赋值,kbuild会自动把代码编译到内核或者编译成模块)
3.要有方便的可定制性。很多参数可以让用户指定。这方面kbuild也提供了大量的
变量如EXTRA_CFLAGS,用户如果想include自己的头文件或者加其它编译参数,只要设置一下EXTRA_CFLAGS就可以。
4.有能力递归地调用Makefile。因为内核是一个庞大的软件。它的源代码的目录层
次很深。要提供一种简洁的机制,使上层的Makefile能方便地调用下层的Makefile。在这过程中,面向对象的思想也许值得借鉴。
5.在配置内核时,要提供友好的用户界面。这方面kbuild也提供了不少工具,如常
用的makemenuconfig等等。
我们完全可以把kbuild想象成一个类库,它为普通的内核开发人员提供了接口
(obj-mobj-yEXTRA_CFLAGS等等),为用户提供了定制工具(makemenuconfig)
如果想了解kbuild的使用方法,可以参阅源代码自带的文档:
Documentation/kbuild/makefiles.txt
Documentation/kbuild/modules.txt
一般情况下是不需要知道具体的编译顺序的。除了在个别情况下,如
do_initcalls()中就和函数在.initcall.initsection中的顺序有关。不过喜欢寻根究底
的我,还是想理一下编译内核时几个常用的命令,如makebzImage,makemenuconfig等等,进而了解kbuild的架构。先看makebzImage吧。
它的大概脉络是怎样的呢?可以用以下命令查看。
make-nbzImage
如果嫌内容太多,可以过滤掉多余的信息:
make-nbzImage|grep“make-f”
可以猜到:
先作一些准备工作
make-fscripts/Makefile.buildobj=scripts/basic
然后依次递归地调用源代码中的Makefile
make-fscripts/Makefile.buildobj=init
make-fscripts/Makefile.buildobj=usr
make-fscripts/Makefile.buildobj=arch/i386/kernel
make-fscripts/Makefile.buildobj=arch/i386/kernel/acpi
make-fscripts/Makefile.buildobj=arch/i386/kernel/cpu
make-fscripts/Makefile.buildobj=arch/i386/kernel/cpu/cpufreq
make-fscripts/Makefile.buildobj=arch/i386/kernel/cpu/mcheck
make-fscripts/Makefile.buildobj=arch/i386/kernel/cpu/mtrr
make-fscripts/Makefile.buildobj=arch/i386/kernel/timers
。。。
最后压缩内核,生成bzImage
make-fscripts/Makefile.buildobj=arch/i386/bootarch/i386/boot/bzImage
make-fscripts/Makefile.buildobj=arch/i386/boot/compressed
IMAGE_OFFSET=0x100000arch/i386/boot/compressed/vmlinux
好,我们从头开始。找makebzImage的入口:
第一反应,自然是在/usr/src/linux/Makefile中找
bzImage:
...
可惜没找到。
不过没关系,用lxr搜索一下,可知bzImage定义在arch/i386/Makefile,所以可以猜测,该makefile一定是被include了。果然,在/usr/src/linux/Makefile中有:447include$(srctree)/arch/$(ARCH)/Makefile
又因为在arch/i386/Makefile中定义有
141zImagebzImage:vmlinux
142$(Q)$(MAKE)$(build)=$(boot)$(KBUILD_IMAGE)
其中这个$(build)定义在/usr/src/linux/Makefile中
1335build:=-f$(if$(KBUILD_SRC),$(srctree)/)scripts/Makefile.buildobj
我们在之前查看make-nbzImage信息和之后会经常看到。我们会发现kbuild通常不会直接去调用某个目录下的Makefile,而是让该目录作为scripts/Makefile.build的参数。scripts/Makefile.build会对该目录下的Makefile中的内容(主要是obj-m和obj-y等等)进行处理。由此看来scripts/Makefile.build这个文件很重要。看看它做了什么:
由于scripts/Makefile.build后面没跟目标,所以默认为第一个目标:
007.PHONY:__build
008__build:
009
010#Read.configifitexist,otherwiseignore
011-include.config
012
013include
014$(if$(wildcard$(obj)/Kbuild),$(obj)/Kbuild,$(obj)/Makefile)
015includescripts/Makefile.lib
这里可以看到,scripts/Makefile.build执行时会include.config文件。.config是makemenuconfig后生成的内核配置文件。
里面有如下语句:
CONFIG_ACPI_THERMAL=y
CONFIG_ACPI_ASUS=m
CONFIG_ACPI_IBM=m
。。。
以前我一直对它的格式表示奇怪,现在很清楚了,它们是作为makefile的一部分,通过读取CONFIG_XXX的值就可以知道他们是作为模块还是作为内核的一部分而编译的。此外,还包含了$(obj)/Makefile。这就是通过在make时传递目录名$(obj)间接调用Makefile的手法。对于内核普通代码所对应的Makefile而言,里面只是对obj-mobj-y,<module>-objs等变量进行赋值操作。
接下去是includescripts/Makefile.lib
。正如它的文件名所示,这类似于一个库文件。它负责对obj-mobj-y,<module>-objs等变量进行加工处理。从中提取出subdir-ym等变量,这是个很重要的变量,记录了需要递归调用的子目录。以后递归调用Makefile全靠它了。这里也充分体现了GNUmake对字符串进行操作的强大功能。
回到Makefile.build。这时,重要变量$(builtin-target),$(subdir-ym)等都已经
计算完毕。开始列依赖关系和具体操作了。
079__build:$(if$(KBUILD_BUILTIN),$(builtin-target)$(lib-target)$(extra-y))\
080
081
082$(if$(KBUILD_MODULES),$(obj-m))$(always)\$(subdir-ym)@:
$(builtin-target)是指当前目录下的目标文件,即$(obj)/built-in.o
如前文所说,$(subdir-ym)用来递归调用子目录的Makefile
306#Descending
307#
---------------------------------------------------------------------------
308
309.PHONY:$(subdir-ym)
310$(subdir-ym):
311$(Q)$(MAKE)$(build)=$@
通过这种方式,实现了对某个目录及其子目录的编译。
分析完Makefile.build,回过头来再看bzImage.从arch/i386/Makefile中可以看
到,bzImage是在vmlinux基础上加以压缩拼接而成。从vmlinux到bzImage的过程在《读核感悟-Linux内核启动-内核的生成》中已经有介绍。现在看看vmlinux是如何生成的。见/usr/src/linux/Makefile
728vmlinux:$(vmlinux-lds)$(vmlinux-init)$(vmlinux-main)$(kallsyms.o)FORCE729$(callif_changed_rule,vmlinux__)
611vmlinux-init:=$(head-y)$(init-y)
$(libs-y)$(drivers-y)$(net-y)612vmlinux-main:=$(core-y)
613vmlinux-all:=$(vmlinux-init)$(vmlinux-main)
614vmlinux-lds:=arch/$(ARCH)/kernel/vmlinux.lds
vmlinux所依赖的目标$(vmlinux-lds)是对arch/i386/kernel/vmlinux.lds.S进行预处理的结果:arch/i386/kernel/vmlinux.lds,其它的依赖关系也都可以
在/usr/src/linux/Makefile中查到。
所以,当用户在源代码目录下执行makebzImage。make会检查bzImage的依赖目标,然后不停地递归调用各个Makefile,最终生成一个bzImage文件。
如果我们换个角度,还可以归纳出不少有趣的东西。如果把make看成是一种脚本语言,那么Makefile就是代码。make就是解释器。make里也有函数,也有变量。通过定义目标,可以实现类似于函数的效果。而目标之间的依赖关系则类似于函数内部再调用其它函数。
如果我们考虑变量的作用域,还可以归纳出以下几点:
1.Makefile内部定义的变量作用域只限于那个Makefile中,如obj-m。
2.要使变量的作用域扩展到整个make命令的执行过程(包括递归调用的其它
Makefile),需要使用export命令。
调用Makefile的方式也有很多种:
1.一种是隐式调用,如运行make,它会自动在当前目录寻找Makefile等。
2.一种是显式调用,如用make-f指定。
3.一种是用include来调用。
读核感悟-kbuild系统-makemenuconfig
理解了makebzImage的过程,理解了整个kbuild的结构和运行机制,make
menuconfig的过程就很容易理解了。
先看/usr/src/linux/Makefile。可以找到:
452%config:scripts_basicoutputmakefileFORCE
453$(Q)$(MAKE)$(build)=scripts/kconfig$@
%config是通配符,所有以config结尾的目标(menuconfigxconfiggconfig)都采用这个规则。所以makemenuconfig在进行一些准备工作如makescripts_basic等操作后,最终会运行
$(Q)$(MAKE)$(build)=scripts/kconfigmenuconfig
其中$@指要生成的目标文件,这里指伪目标menuconfig。
接下去调用的是:scripts/kconfig/Makefile
013menuconfig:$(obj)/mconf
014
015$(Q)$(MAKE)$(build)=scripts/lxdialog$<arch/$(ARCH)/Kconfig
:=confmconf
:=conf.oqconfgconfkxgettext082hostprogs-y083conf-objs
084mconf-objszconf.tab.o:=mconf.ozconf.tab.o
085kxgettext-objs:=kxgettext.ozconf.tab.o
这里可以看到最终执行的是scripts/kconfig/mconfarch/i386/Kconfig其中$<代表“起因”,也就是scripts/kconfig/mconf
该程序并不属于内核,而是一个用户态程序。Linux源代码中这一类程序还有很多。如在scripts/kconfig/目录下就有mconf,gconf,qconf等等。它们用来执行内核的配置工作。
又如在arch/i386/boot/tools/中有个可执行程序叫build,它用来把bootsect(引导扇
区),setup(辅助程序)和vmlinux.bin(压缩内核)拼接成bzImage。
scripts/kconfig/mconf这个程序采用了ncurses类库。这是一个在文本界面下进行
画图操作类库。由于要适应不同平台,源代码中的mconf不是预编译好的elf可执行文件,而是在使用时才去编译生成。这使用户在运行makemenuconfig时要依赖ncurses的开发
包。
arch/i386/Kconfig,准确地说是各个Kconfig文件记录了各个内核配置的选项。我
们在makemenuconfig或者makexconfig时显示的菜单项和帮助信息,都是从这个文件中读出来的。
到此,我们对平时使用的makemenuconfig命令的执行流程应该有了一个大概的印象了吧。
读核感悟-文件系统-用C来实现面向对象
电脑用户跟文件系统打交道是非常频繁的。不过文件系统在结构上应该属于哪一层呢?它和设备驱动的关系如何?不同的系统有不同的理解。Linux把文件系统放在设备驱动之上,访问普通文件时,系统先执行文件系统的代码,把文件指针的偏移量映射为块设备的偏移量,然后调用驱动程序的代码。另一方面,Linux把设备也看作是一种特殊的文件。这有助于简化接口,对程序员来说是很方便的。
我们可以把接口的观点扩展开来。对于应用程序来说,类库是一种接口;对于用户态程序来说,系统调用是一种接口;而对内核的一些模块(如文件系统,驱动程序)来说,内核也提供了很多接口;对于底层的软件开发者来说,处理器的指令集可以看作是接口;对于一辆奔驰汽车来说,各个零部件的规格说明书也可以算是一种接口。。。接口的出现是社会分工的需要,这有力地提高了开发效率。这使一部分人能够专注于编写简洁,高效和功能强大的接口,而另一部分人则专注于具体的需求。当然,在提高开发效率的同时,也会使人局
限于某一个小领域。像BillJoy(前任Sun的首席科学家,当年在Berkeley时主持开发了最早版本的BSD。还主持设计了sparc处理器)这类软硬通吃的计算机牛人将会越来越少。这也可以算是社会分工带来的代价吧。
作为一个开放的系统。Linux也提供了文件系统的接口。这使它能够方便地支持
ext2,fat32,reiserfs等很多种文件系统。最理想的状况是选择一个wizard,然后选择和填
充若干属性,一路地Next下去,最后点OK,一个基本的文件系统就诞生了。接下去要做的只是实现一下里面的一些函数而已。当然,现在还没有这样的wizard,不过,基本思路是一致的,即把所有的文件系统中的公共接口抽象出来,让具体的文件系统去实现。这也是面
向对象的思想。关于具体的接口,这方面的书已经讲得非常详细了,这里讲一讲如何用C语言来实现面向对象。
对
不过问题也出来了:
1.根分区对应的设备是/dev/sda1,也就是说,要挂载根分区,就要读/dev/sda1,可
是,/dev/sda1是保存在根分区上的一个文件,也就是说,要读/dev/sda1,就要挂载根分区,这不是死锁了么?当然,解决办法是有的。关键在于/dev/sda1这个设备文件本身的信息不多,主要包括设备类型,主设备号与次设备号,这样,我们可以
windows则相反,是把设备驱动放在文件系统之上。
读核感悟-设计模式-用C来实现虚函数表和多态
内核作为一个庞大的系统,要保证扩展性和可维护性,里面用到了大量设计模式。说到设计模式就很容易联想到面向对象,联想到C++。那么,内核为什么不使用C++呢。我想是出于效率和平台可移植性的考虑。C++编译器实现起来比C复杂多了,想像一下很多编译器都不是100%地支持C++标准。所以在一些非主流的硬件上,不一定能找到对应的C++编译器。
虽然内核使用的是C,但是,内核仍然采用了面向对象的思想。尤其是在文件系统和设备驱动这一块。在这些地方,集中了大量的结构体如
file,dentry,inode,cdev,block_device,pci_dev,usb_device,file_operations等等以及
大量的函数和宏。我们的目标是理清它们之间的关系,最好能搞清楚为什么要这么设计。如果用面向对象的观点来阅读源代码,很多地方就显得清晰易懂了。好,让我们跟着问题走:
问题一:用C如何实现C++中常见的类,成员函数,虚函数表,多态,继承,封装等等特性呢?
稍加整理,我们可以发现,结构体主要可以分成两类。一类定义了很多数据成员,如structfile.一类定义了很多函数指针,如structfile_operations。并且这两者是一一
对应的。其中,file_operations可以看作是接口。file中可以看作是类,而里面的成员变
量f_op可以看作是虚函数表指针。只是没有C++的访问权限控制机制罢了。与此类似的还有dentry和dentry_operations,inode和inode_operations。这样,我们用C的结构体和函数指针模拟出了类,成员函数,虚函数表。你可能觉得这样很不直观。是的,很不直观,不过谁叫我们用的是C呢?还有更不直观的,下面要介绍的模板就是。
这里可以看出,类与接口的区别。类包括了数据和成员函数,也就是“实现”,而接
口只是一组操作的集合,类似于抽象类。接口的作用是屏蔽内部细节,方便上层的开发者开发一个通用的模型。对下层的开发者而言,只要实现接口的功能就行。在C++里是不区别类与接口的。而在Java里则在类之外还提供了接口的功能。扯远了,打住。
虚函数表有了,那么,要实现多态,就要实现动态绑定。我们知道,在C++中,编译器会根据类声明中的virtual关键字为每个类初始化一张虚函数表,然后,在每个对象构造的时候,把对象中的一个指针指向对应的虚函数表。现在C编译器宣布它撂担子不管这事了。所以这些辛苦活只能让我们自己来干喽~。以inode为例。假设文件系统是ext2。我们要读的是一个普通的ext2文件。
sys_open()->filp_open()->open_namei()->path_lookup()->link_path_walk()-
>__link_path_walk()->open_namei()->path_lookup()->do_lookup()->real_lookup()-
>ext2_lookup()->ext2_read_inode()
最后,在ext2_read_inode()中,它会根据inode类型把i_op设置成相应的
inode_operations。这一步相当于C++的构造函数中的动态绑定,即根据inode类型来决定对应的操作。通过这种方式实现了多态。
虽然多态很好地实现了抽象,方便了软件的扩展,但是我得说它给我的代码阅读带来了很大的不便。跟踪函数时经常到了有函数指针(类似于虚函数)时就中断了,很难知道它究竟调用的是哪个函数。
读核感悟-设计模式-用C来实现继承和模板
多态实现了,封装呢?基本上,C的结构体是不设防的,谁都可以访问。从这一点来看,C很难实现封装。尽管C中有static关键字,可以保证函数和变量的作用仅限于本文件,尽管内核可以通过控制导出符号表(EXPORT_SYMBOL)来控制提供给下层模块的函数和变量,但这些与C++中的封装相去甚远。好在内核的原则是“相信内核不会自己伤害自己”。所以就不苛求啦。
那么继承呢?这个也基本上很难。不过我们可以通过组合来模拟“继
承”。ext2_inode_info是ext2的inode在内存中的结构体(注意,不是ext2_inode,这个是在硬盘上),有个成员变量是structinode*,指向inode。使用时,用EXT2_I()宏来实现
类型的down_cast。这样很不直观。当然我们也可以理解为ext2_inode_info与inode是两
个完全不同的结构体,ext2_inode_info包含了inode。但是这样的理解显然更简单轻巧:ext2_inode_info继承了inode,并且加了自己的私有成员变量。
这是一种实现继承,ext2_inode_info实实在在地继承了inode的全部“财产”-成
员变量,还有一种接口继承,也使用得非常广泛。如ext2_dir_inode_operations(定义了对ext2的目录节点的操作)对inode_operations的继承。与通常理解的“继承”不同,在C中并没有生成新的结构体,而只是定义了一个inode_operations类型的变量。这种继承只是把里面的函数指针加以实现。这种继承很辛苦,因为接口除了声明,什么也没做。
有了父类子类,自然也少不了类型之间的转换,以及运行中的类型识别(RTTI)。由于内核中只是用组合来模拟继承关系,即用子类包含父类的方式,所以从子类转换到父类就很方便。如子类是structDerived里有个成员变量structBase*b,从子类转换到父类只要d->b就行,但是从父类downcast,向下类型转换到子类就比较麻烦了。然而这种情况非常常见,如设备驱动接口file_operations中
int(*ioctl)(structinode*,structfile*,unsignedint,unsignedlong);
如果我们开发一个叫scull的字符设备,通常要定义自己的结构体scull_dev,此外还要继承cdev(表现为组合).可是ioctl接口里没有scull_dev!幸好inode->i_cdev指向的就是cdev。那么如何通过cdev得到scull_dev呢?内核提供了container_of()宏。structscullc_dev*dev;
dev=container_of(inode->i_cdev,structscullc_dev,cdev);
这可比down_cast之类复杂多了。里面使用了黑客手段,有兴趣可以看看container_of的实现。
好像还忘记了什么。。。对了,模板呢?
说内核不需要模板是不可能的。光是链表一项,就有很多地方要用到,进程之
间,dentry之间。。。如果为每种情况写一套链表操作,那是很可怕的事。理论上,我们有两种选择,以循环链表,task_struct为例:1.把指针pprev,next放到task_struct中,然后写一套宏,把类型作为参数传进去,实现对循环链表的操作。这个是最自然的思路,最接近C++的模板。但是,问题来了,如果task_struct同时属于好几个链表怎么办(虽然听起来这个想法很怪,但task_struct的确有这样的需求)?
2.对第一种方法的改进:实现一个对最简单的结构体list_head的链表操作。然后把list_head等包含到task_struct结构体里。如果要对task_struct所在链表进行操作,只要操作对应的list_head就可以了。所以解决了1的问题。至于怎么通过list_head获得task_struct,可以参考container_of()宏的做法。
问题是解决了,但是与前面几种模拟办法相比,这种是最不直观的。因为当我在一个结构体里发现了list_head后,根本不知道它所在的链表究竟放的是什么结构体。事实上只要某个结构体有list_head这个成员,就可以放到链表里。有些类似于MFC的
CObjectList。这就有些恐怖了。
不过只要编程者清楚里面放了些什么,就没有问题。
“相信内核不会伤害自己”
不过我很好奇,如果换成C++,如何实现list_head的效果呢?能否实现一种新的multi_list模板,它与list的区别在于节点可以属于多个链表。
读核感悟-设计模式-文件系统和设备的继承和接口
接着,我们可以看一下文件系统几个关键的结构体之间的关系。显然,一个inode对应多个dentry,一个dentry对应多个file。任何一本介绍文件系统的书对此都有介绍。那
么inode和块设备block_device,字符设备cdev的关系如何呢。我们知道,inode是对很多事物的抽象。在2.4内核中。inode结构体中有一个union,记录了几十种类型,包括各种文件系统的inode,各种设备(块设备,字符设备,socket设备等等)的inode,我们可以把block_device和cdev理解为特殊的节点。他们除了普通节点的一些特性外,还有自己的接口。
如block_device有个成员gendisk,有自己的接口block_device_operations。而对于ide硬盘来说,它是一种特殊的gendisk,它有自己的结构体ide_driver_t。它还实现了block_device_operations接口,即idedisk_ops。
整体的继承关系:
block_device,gendisk(类)|block_device_operations(接口)
|is_a(继承)
ide_drive_t(类)|idedisk_ops(实现)
这种分析方法有助于理清内核中众多结构体之间的关系。
与此类似,我们也可以分析一下两种重要的设备PCI和USB设备:
内核中用来表示pci设备的结构体是pci_dev,此外,还有一个接口pci_driver,定义了一组PCI设备的操作。
内核中用来表示usb设备的结构体是usb_device,此外,还有一个接口
usb_driver,定义了一组USB设备的操作。
有趣的是,pci_dev和usb_device有一个共同的成员变量类型为
device,pci_driver和usb_driver有一个共同的成员变量类型为device_driver。
由此,我们可以猜出他们的关系。
pci_dev和usb_device可以看成对device的继承,pci_driver和usb_driver可以看作是从device_driver接口的继承。
在设备驱动中,各种层次显得非常分明。内核通过对usb和pci驱动通用框架的设计,减轻了驱动的开发人员的负担。实际上,内核为驱动开发人员提供的是一个框架(framework)。有些类似于MFC。开发人员只要实现一些接口就可以了。
此外,我们还可以总结出一些有趣的现象:
比如,接口该如何定义呢?
Linux把目录和设备看成文件,这使文件操作接口的定义有两种选择:
1.取普通文件,目录文件,设备文件接口的交集,为,把各种“文件”特有的接口放到各种“文件”自定义自己的接口。这样的好处是继承关系比较清楚。不过继承层次比较深。
2.取普通文件,目录文件,设备文件接口的并集,压缩继承层次。各种“文件”实现自己能实现的接口,把不能实现的函数指针置为NULL
事实上,file_operations就是这么做的。它里面有通用的操作(readwrite)。有针
对目录文件的操作(getdents)。有针对设备的操作(ioctl)。与之类似的还有
inode_operations,包括了普通文件节点(create),设备文件节点(mknod),目录文件节点(mkdir)等等。
通过这样的设计,大大简化了整个层次结构。
我们还可以归纳出更多东西:
1.为了保证扩展性,很多结构体提供一个private指针,如file::private_data
2.如果只是为了代码重用,就提供普通库函数和普通结构体。如果为了提供接口以便继承,就提供接口。在C中,接口和普通成员函数很容易区分,前者一般定义成函数指
针。
读核感悟-设计模式-文件系统与抽象工厂
抽象工厂的典型应用是在gui设计中。为了在运行时方便地替换不同风格的gui设计,我们需要在上层把每种不同风格的gui的实现细节隐藏起来。我们不再显式地调用gui中的某个组件的构造函数,因为这样暴露了组件的实现。相反,我们为每一个风格提供一个“工厂”来生产该风格的“产品”。
抽象工厂可以看作是面向对象设计中常用的多态思想的扩展。普通的多态只是针对一个“产品”,如shape抽象类。而抽象工厂是针对一组“产品”。所以显得整齐划一。
在设计文件系统时,我们希望抽象的文件系统VFS和具体的文件系统分离。即在VFS中不涉及任何具体的文件系统。如果要添加一个新的文件系统,则只要添加几个源文件,然后编译成模块,就万事大吉了。为了达到这一目标,VFS的代码本身不应该涉及具体的文件系统。VFS里需要构造dentry,inode,superblock对象时,也应该想方设法地避免显式地调用构造函数。但是由于文件系统可以抽象出一些共同的要素和接口,如
dentry,inode,super_block,这时我们想到了抽象工厂的设计模式。
每一类文件系统可以看作是“工厂”,而dentry,inode,superblock可以看作
是“产品”。那么,工厂在哪里呢?我们是在哪里创建”工厂”本身的呢?
我们知道文件访问的大概流程:
1.首先,我们得知道是哪个文件系统。然后,通过mount把文件系统安装到某个目录下。这个结构体就是:file_system_type。我们可以看一下ext2的file_system_type1167staticstructfile_system_typeext2_fs_type={
1168
1169
1170
1171
1172.owner.name.get_sb.kill_sb.fs_flags=THIS_MODULE,="ext2",=ext2_get_sb,=kill_block_super,=FS_REQUIRES_DEV,
1173};
我们可以在注册文件系统时把这个结构体放到内核的全局链表:file_systems中。然后通过文件系统的名称找到对应的file_system_type结构体。
2.其次,我们得获得superblock的信息,因为一个文件系统通常只有一个super
block,由于superblock的重要性,他会有很多个备份,但是从信息量的角度来讲仍然只有一份。文件系统的根目录也在superblock中。我们可以构造出根目录的inode对象和dentry对象
好在我们已经有了file_system_type。不出所料,我们可以发现里面有获得super
block的函数指针:get_sb。这里有一个有趣的现象:为什么ext2_fs_type,包括
ext2_get_sb要设置为static呢?因为这样做其它模块(包括VFS)就没有可能直接引用
ext2_fs_type了。“逼”着VFS引藏细节。这其实是C风格的一种封装。由此我们也可以总结出:设计为static,并不意味着其它模块不会调用到该变量或者函数,只是意味着无法直接调用到而已。那么VFS如何调用ext2_get_sb呢?在挂载文件系统时,在
do_kern_mount()中有如下代码:
sb=type->get_sb(type,flags,name,data);
由于我们在mount文件系统时会指定文件系统的名称。内核就会找到对应的
file_system_type。然后调用get_sb。
从面向对象的角度来说,super_block对象不仅包括superblock的数据成员,还包括对super_block的一组操作的实现。所以应该有个接口叫super_operations。果然,ext2文件系统有个super_operations变量叫ext2_sops,在ext2_get_sb赋给对应的superblock.
那么根结点如何找?不要急,根据之前的分析,super_operations应该提供读inode的操作,事实上,它是一个叫read_inode的函数指针。另一方面,super_block中有个dentry成员变量叫s_root,就是我们要找的根节点的dentry!此外,系统还悄悄地把一些函数指针也赋了值。如inode_operations。inode,dentry,file对象的构造通常伴随着inode_operations,dentry_operatons,file_operations的赋值。这在C++中是由编译器来负责实现的。在C中只能人肉实现了。
通过这种方法,引藏了具体文件系统的细节。
3.接着,有了根目录的inode,我们可以很方便地访问它的子节点。于是采用lazyalgorithm,只有当子节点被访问到,我们才去硬盘上访问它,并在内存中构造它。这一步是在sys_open中实现的。
sys_open()->filp_open()->open_namei()->path_lookup()->link_path_walk()-
>__link_path_walk()->do_lookup()->real_lookup()
在这里,当系统发现要访问的子节点不在内存中,,它不得不去硬盘上找。不过对应的lookup接口已经在父节点的“构造函数”中“人肉”赋值了。这里它只需要调用如下代码:
result=dir->i_op->lookup(dir,dentry,nd);
就实现了在磁盘上查找文件结点的操作。
由此我们可以总结出:
1.文件系统的“工厂”由很多组接口组成,包括file_system_type,
super_operatios,inode_operations,dentry_operations,file_operations.只要文件系统
类型确定,这些接口即“工厂”也确定了。在VFS中就可以根据ext2工厂生产出对应的产品即ext2的superblock,inode,dentry,file对象。只要我们在mount时换一下文件系统如reiserfs,ext2“工厂”就立即摇身一变,成了reiserfs的“工厂”。而VFS的代码不需要作任何改变。
2.为了在语法上保证松散耦合,除了需要通过EXPORT_SYMBOL导出的符号,我们可以把模块中的函数和变量尽量地声明为static,以实现一定程度的封装。
3.对象的构造总是伴随着成员变量和方法的赋值。尤其是后者,使VFS能够不用调用下层文件系统的具体代码。
读核感悟-阅读源代码技巧-查找定义
阅读内核源代码的工具有很多,例如lxr+swish-e,sourceinsight,
emacs+cscope,vim+ctags等等。这里以lxr+swish-e为例。
lxr+swish-e的安装是比较麻烦的,可以参考下面的教程:
.cn/viewtopic.php?
t=80527&sid=66446a9ff4783d61b05cd33a8023fe30
然后用浏览器打开对应的网址,就可以访问了。变量,函数的声明,定义和使用,都能找出来。
不过也有一些特殊情况:
1.只有声明,找不到定义。比如asmlinkageintsystem_call(void);
lxr只会从c的源代码中找定义。但是定义不一定在.h或者.c中,还可能在.S汇编代码或者.lds.S链接脚本中。
1)链接脚本:
比如,在时钟中断中经常出现的jiffies就定义在
arch/i386/kernel/vmlinux.lds.S。
jiffies=jiffies_64;
它的声明为:
externunsignedlongvolatile__jiffy_datajiffies;
而jiffies_64则是在arch/i386/kernel/time.c里正常定义的:
u64jiffies_64=INITIAL_JIFFIES;
这意味jiffies和jiffies_64的变量地址是一样的,或者说,他们根本就是同一个变量。为什么要这么写呢?我们注意到,jiffies被声明为一个32位无符号整
数,jiffies_64被定义为一个64位无符号整数,也许是为了保证向下兼容吧。因为在
2.4.33内核里jiffies还是32位的。但是在2.6.13里,内核已经不再使用jiffies而使用64位的jiffies_64了。但是,为了与2.4版本的兼容,使那些使用jiffies的驱动和其它模块仍然能正常使用jiffies。内核使用了这样一个小伎俩。
其它如__initcall_start,__initcall_end。也都在(事实上只能
在)vmlinux.lds.S中定义。
2)汇编文件:
还有定义在汇编文件中的变量。很多入口函数都定义在汇编文件中。其中
arch/i386/kernel/entry.S里面定义了大量的入口函数,包括系统调用入口system_call,页面异常page_fault,以及其它在trap_init()里设置的中断向量表中的入口。
这里不能不提一下普通中断interrupt数组。它的声明如下:
externvoid(*interrupt[NR_IRQS])(void);
是一个函数指针
在2.4.33的内核中,interrupt数组是由一组宏来定义的:
101#defineIRQ(x,y)
102
103\IRQ##x##y##_interrupt
104#defineIRQLIST_16(x)\
105
106
107IRQ(x,0),IRQ(x,1),IRQ(x,2),IRQ(x,3),IRQ(x,4),IRQ(x,5),IRQ(x,6),IRQ(x,7),IRQ(x,8),IRQ(x,9),IRQ(x,a),IRQ(x,b),\\\
108IRQ(x,c),IRQ(x,d),IRQ(x,e),IRQ(x,f)
={110void(*interrupt[NR_IRQS])(void)
111
112
113#ifdefCONFIG_X86_IO_APIC
114
115
116IRQLIST_16(0x0),IRQLIST_16(0x1),IRQLIST_16(0x2),IRQLIST_16(0x3),IRQLIST_16(0x4),IRQLIST_16(0x5),IRQLIST_16(0x6),IRQLIST_16(0x7),IRQLIST_16(0x8),IRQLIST_16(0x9),IRQLIST_16(0xa),IRQLIST_16(0xb),117
118#endif
119};IRQLIST_16(0xc),IRQLIST_16(0xd)
而IRQ##x##y##_interrupt
又是由BUILD_IRQ来定义。
175#defineBUILD_IRQ(nr)\
176asmlinkage
177__asm__(\
178"\n"__ALIGN_STR"\n"\
179SYMBOL_NAME_STR(IRQ)
180
181#nr\"_interrupt:\n\t"\voidIRQ_NAME(nr);\"pushl$"#nr"-256\n\t""jmpcommon_interrupt");
这种方式很清晰明了,不过有些罗嗦。
2.6.13中对interrupt的定义方式进行了改进,更简洁,但是也更不容易理解:
事实上它的定义也是放在entry.S。只是很不容易被发现。
396.data
397ENTRY(interrupt)
398.text
399
400vector=0
401ENTRY(irq_entries_start)
402.rept
403
4041:
405
406.data
407
408.text
409vector=vector+1
410.endr
411
412ALIGN
NR_IRQS
一般被定义为16。
这段代码利用了汇编的.rept功能,把代码展开为16段,每一段代码只是把vector加1,也就是irq号。每一段代码的功能就是把$vector-256
的值压入堆栈(因为irq号在0到255之间,所以要与系统调用号区别开来。),然后跳转到common_interrupt。
那么interrupt数组里的函数指针在哪里定义呢?.long1bNR_IRQSALIGNpushl$vector-256jmpcommon_interrupt
我们发现标签1处是每段小函数的入口。而
406.data
407.long1b
则把标签1的地址保存到数据段。是哪个数据段呢?
396.data
397ENTRY(interrupt)
我们可以看到。其实就相当于把这16个函数指针放在interrupt后面。相当于定义了一个interrupt数组。
3.函数以宏的方式批量定义。
例如对IO端口的操作:outb_p等等。
定义在include/asm-i386/io.h中
377BUILDIO(b,b,char)
378BUILDIO(w,w,short)
379BUILDIO(l,,int)
每个BUILDIO宏将生产很多个函数:
以BUILDIO(b,b,char)
为例:
能生成以下函数:
outb_local
inb_local
outb_local_p
inb_local_p
outb
inb
outb_p
inb_p
outsb
insb
如果把b,w,l三种情况都按常规方法定义一遍,无疑将产生大量雷同代码。遇到这种情况,我的第一反应就是模板。可惜C里没有模板。所以只能用宏来代替了。
那么,遇到这类情况,通用的解决办法是什么呢?
1.我们可以求助于lxr的freetextsearch。全文搜索包括了.S汇编文件。不过搜
索时量会很多。
2.可以去查查相关资料,如UnderstandingLinuxKernel,Linux内核源代码情景分析(虽然只是2.4内核的,但也可以以此为基础,猜测出2.6的定义方法,例如,可能在同一个头文件。)。
读核感悟-阅读源代码技巧-变量命名规则
在阅读源代码的时候,经常会发现在跟踪函数调用时跟踪不下去了,如
result=dir->i_op->lookup(parent_inode,child_dentry,nd);
这类似于C++中的多态。inode_operations中的lookup函数指针具体指向哪个函数,不是在编译时确定的,而是在运行期确定的。具体地说,就是在从磁盘上读入inode时才对对应inode的inode_operations结构体赋值。在ext2_read_inode()中
inode->i_fop=&ext2_file_operations;
也就是在inode对象创建的同时也对inode对应的操作进行了绑定。
但是为了确定函数指针具体指向的是哪一个函数,而去找函数指针的赋值的地方,未
免有些麻烦。而通过内核变量的命名规则猜测对应的函数倒不失为一个好办法。在这个例子中,我们使用的文件系统是ext2。于是猜测lookup对应的函数是ext2_lookup。很幸运,我们猜对了。为了保证扩展性,内核中使用了大量的函数指针,采用了大量的“动态绑定”。在这种情况下,总结一下内核变量的命名规则是很有必要的。
我个人认为变量的命名是很重要的,因为这关系到代码的可读性。通常每个公司都有自己的一套变量命名规范。比较有名的有微软的匈牙利命名法,以及Unix应用程序的命名方式。Linux内核采用的是Unix应用程序的命名方式,标志符通常采用“小写加下划线”的方式。
sys_+系统调用名:是系统调用在内核中的入口处理函数如sys_fork(),因为所有的
socket通信相关的系统调都通过sys_socketcall,所以他们的命名形式也像普通系统调用一样。如sys_socket,sys_bind等等,
do_+系统调用/中断操作名等等:具体的处理函数,如do_fork(被
sys_fork,sys_vfork,sys_clone调用),do_page_fault,do_mmap.
vfs_+VFS相关的系统调用名:第二层的处理函数,如
vfs_read,vfs_write,vfs_ioctrl。
文件系统函数方面:
文件系统名称_+操作名:该文件系统对应的操作。如ext2_lookup对应
inode_operations中的lookup操作。
文件系统名称_+接口名:该文件系统针对该接口实现的操作:如
ext2_file_operations。当然,实际情况比较复杂,如ext2中对inode的操作又分为普通文件的inode(ext2_file_inode_operations),目录文件的
inode(ext2_dir_inode_operations),特殊文件如设备文件的
inode(ext2_special_inode_operations)等等。
结构体名称缩写_+成员变量名:结构体成员变量的命名,如inode的成员变量前面都有i_,dentry的成员变量前面都有d_,super_block的为s,file的为f等等。
一些缩写,有助于理解变量的含义。
nr:number
bh:bottomhalf
ops:operations如f_ops,i_ops
在新版本的内核代码里,一些缩写开始用完整的单词来代替。这使代码的可读性进一步提高。
读核感悟-内存管理-内核中的页表映射总结
从线性地址到物理地址的转换,实际上是一种映射。所有进程的3~4G的线性地址实际上是映射到相同的物理地址的。这一点不多说了。为了方便起见,3~4G的线性地址与对应的物理地址基本上是呈线性关系的。即线性地址=物理地址+3G。但是如果把这1G的线性地
址都简单地处理为对应物理地址+3G,就会有新的问题产生。例如,如果物理地址大于4G,那么内核就没法访问这些地址了。所以,内核必须要从这1G的线
性空间中预留一部分,作其它用途,(例如,映射高端物理地址)。经过实践,发现128M线性地址够用了。所以,3~4G的线性地址中896M映射到物理地址中的0~896M,剩下的128M挪作它用,例如,内核空间的非线性映射(在vmalloc中使用)以及高于4G的物理地址的映射。
我曾经产生过的疑问:
1.如果物理内存小于896M,那不是所有的物理地址都被内核用完,没有内存留给用户空间了么?
事实上,小于896M时,同一块物理内存可能同时被映射到用户空间和内核空间,从数学的角度来讲,也就是所谓的“双箭一雕”。我们相信内核是没有bug的,所以不用担心因此产生的内核对用户空间数据破坏的可能性。
2.如果物理内存小于896M,所有物理内存地址都与内核线性地址相差3G,那vmalloc不是没有内存使用了么?
不使用vmalloc当然是不可能的,因为模块装载时就会用到vmalloc。原理与问题1一样,即使在内核空间,也可能多个线性地址映射到同一个物理地址,也就是“双箭一雕”。所以vmalloc仍然能获得相应的物理内存。
对以上两个问题的小结。系统在启动时会把前896M物理地址映射到3G以上的线性空间。但是映射不等于使用。事实上内核只使用了很小一部分(一般才几M)。只要有足够的未使用的物理内存,用户进程和vmalloc都不会有问题。
3.如果物理内存大于896M。那对内核而言不是无法在同一时刻访问所有的物理内存了么?
是的,虽然内核可以通过临时映射和永久映射来访问所有的物理内存,但是用到的线性地址很有限,即一次只能访问一小部分物理内存。当无法访问到更高地址物理内存时,只能通过修改内核页表来达到目的。但是,这对内核就足够了。因为上面说过,内核所需要的内存很少。内核只是偶尔会访问一下高端内内存。而对于用户进程而言,只要页表开启了PAE,就可以访问64G以内的物理内存(虽然只有4G的线性空间
,但是也足够了。)
4.内核页表是如何共享的呢?
我们知道所有的进程共享内核空间,所以共享内核页表是很自然的事。理论上内核只有一个页表,对应的内核全局页目录swapper_pg_dir,所有进程的页目录的最高256项与swapper_pg_dir相同。可惜的是,每个进程有自己的页目录,共1024项。其中最高的256项指向的是内核空间。尽管这些页目录项可以指向同样的内核页表,但是一旦内核页目录改变了,所有进程的页目录都需要同步。这种情况是存在的。比如
内核调用vmalloc时。
幸亏有了页错误,我们可以从容地处理页目录的同步。如果内核调用了vmalloc,内核只修改内核全局页目录。当其它进程访问vmalloc产生的线性空间时,会产生页错误。页错误处理程序可以判断当前的页错误是由于vmalloc产生的,于是修改对应的页目录,使它们与内核全局页目录保持一致。
读核感悟-健壮的代码-exceptiontable-内核中的刑事档案
如果系统调用的参数是错误的怎么办?如果参数仅仅是简单的整型,只要直接判断参数
范围就可以了,但是如果是指针呢?情况就复杂了。
如果指针为null,是很容易判断的。如果指针不为null,但是却指向非法的地址,该怎么办呢?如果在内核里段错误,内核就太冤了:明明是用户态程序的问题,却让我来背黑锅。。。
一种办法是在系统调用开始时就判断指针在不在用户空间里。进一步说,对指针指向的
buffer的每一个字节都要作判断。这样可以提前检查出错误的参数,返回一个错误码。
这样的缺点是太复杂,效率太低。因为出错的情况是少数。
针对这种情况,内核采用了exceptiontable。把所有可能出错的指令地址都放到
exceptiontable中,与之对应的是一个错误处理函数。
例如,系统调用从用户态拷贝参数到内核态,要通过copy_from_user()。这个函数是用汇编写的。除了效率因素,还有一个原因是可以精确地判定出错指令的地址(即其中的一个mov指令)。fixcode则是一小段代码,它返回0。于是,当copy_from_user()出错时,在pagefault处理函数里检查当前的eip是不是在exceptiontable中(即那条mov指令),如果是的话,就跳到对应的fixcode(即返回为0)。
这个方法兼顾了效率(不需要做额外的检查)和可靠性(保证用户程序的错误不会导致
内核崩溃)。我们可以把exceptiontable看作刑事档案,它告诉我们“某某某代码有前科,可能会有麻烦,请特别关照”。
这从另一个侧面告诉我们,内核中的代码对健壮性要求特别高。
读核感悟-定时器-巧妙的定时器算法
内核中经常要用到各种定时器。比如nanosleep()系统调用,让当前进程睡眠一段时间,再把它唤醒。即在expires时刻(以时钟滴答为单位),自动调用wake_up_process。
最直接的思路是定义一个定时器,里面有function(函数指针),data(函数参
数),expires(调用时刻)。然后排成一个链表。每次时钟中断发生时,扫描整个链表,发现有触发的定时器,就调用function(data)。寻找触发的定时器的时间复杂度O(N)。N是定时器数量。明显,这个算法效率太低。
改进:事实上我们只对最快触发的定时器感兴趣,所以在插入元素时就对元素进行排序。这样,每次时钟中断,只要检查链表中第一个定时器就行。寻找触发的定时器的时间复杂度O(1)。但是每次插入和删除操作的时间复杂度又变成O(N)了。这个算法还是不好。
继续改进:把数据结构改成优先队列(最小堆),这样插入删除操作的时间复杂度为O(logN)。寻找触发的定时器的时间复杂度O(1)。
有没有可能继续改进呢?墙上的挂钟给人以灵感。当秒针飞快走动时,分针走的很
慢,而时针几乎不动。这提醒我们要区别对待定时器。要把定时器划分成不同区间。对最早可能触发的定时器频繁扫描(就像秒针),而对很晚才触发的定时器隔一段时间再扫描(就像分针)。
基本思路:2^8-1个时钟滴答内触发的定时器放到第一组,2^8~2^14-1个时钟滴答内触发的定时器放到第二组,依次类推,最后分成五组。第一组每个时钟中断都要检查,第二组则每2^8=256个时钟中断检查一次,依次类推。每组中有256个队列。那么检查每一组是否意味着检查这256个队列?不是的。事实上,根据触发时间,我们可以把定时器放到对应的队列中(如在第一组中,把触发时间为expires的定时器放到第expires%256个队列中)。那么我们在检查每一组时,只要扫描其中一个队列就可以了。对于第一组,被检查到的定时器需要执行定时器函数。对于其它组,则意味着“升级”(跳到前一组,由于临近触发而受到更频繁的检查)。
可以看出,这个算法中,寻找触发的定时器的时间复杂度接近O(m)(m是第一组每个队列中定时器的个数,其它组的操作几乎可以忽略)。而这个m在绝大部分情况下接近1。插入和删除操作的时间复杂度也为O(1)。这是迄今为止最好的算法。
更详细的算法解释见ULK第六章timingmesuring。
从中也可以看出,把一个大队列分割成几个小队列,可以极大的降低算法的时间复杂度,提高效率。2.6内核中,调度算法也采用了类似的思想。
读核感悟-内存管理-pagefault处理流程
pagefault是Linux内存管理中比较关键的部分。理解了pagefault的处理流程,
有助于对Linux内核的内存管理机制的全面理解。因为要考虑到各种异常情况,并且为了使内核健壮高效,所以pagefault的处理流程是比较复杂的。我把这个繁琐的处理流程放在最后。在pagefault处理函数中使用了很多lazyalgorithm。它的核心思想是,由于磁盘IO非常耗时,所以把这些操作尽可能的延迟,从而省略不必要的操作。
以下是几种会导致pagefault的情景:
1.用户态按需调页:
为了提高效率,Linux实现了按需调页。应用程序在装载时,并不立即把所有内容读到内存里,而仅仅是设置一下mm_struct,直到产生pagefault时,才真正地分配物理内存。如果没有分配对应的页表,首先分配页表。这种情况下的缺页可能是匿名页(调用do_no_page),可能是映射到文件中的页(调用do_file_page),也可能是交换分区的页(调用do_swap_page)。此外,还可以判断是不是COW(写时复制)。
2.主内核页目录的同步:
内核页表信息保存在主内核页全局目录中,虚存段信息放在vm_struct中。进程页表
的内核部分要保持与主内核页全局目录的同步。当内核调用vmalloc等函数,对内核态虚拟
地址进行非线性映射时,修改主内核页全局目录,但是不修改进程页表的内核部分。这会引起pagefault。pagefault处理函数会执行vmalloc_fault里的代码,对进程的页表进行同步。
3.对exceptiontable中的异常操作的处理
内核函数通过系统调用等方式访问用户态的buffer,可能会在内核态导致page
fault。这一类pagefault是可以被fixup的,所有这些代码的地址都放在exceptiontable中。并且这些代码有异常处理函数,被称为fixupcode。pagefault处理函数查找对应的fixupcode,并且把返回时的rip设置为fixupcode。当pagefault处理完毕,内核会调用fixupcode,对异常进行处理。典型的例子是copy_from_user。
4.堆栈自动扩展
并不是所有的指针越界都会导致SEGV段错误。当指针越界的量很小,并且正好在当前堆栈的下方时,内核会认为这是正常的堆栈扩展,为堆栈分配更多物理内存。
5.对用户态指针越界的检查
如果指针越界,并且不是堆栈扩展,那么内核认为是应用程序的段错误,向应用程序强制发送SEGV信号。
6.oops
如果pagefault不是应用程序引起,并且不是内核中正常的缺页,那么内核认为是内核自己的错误。pagefault会调用__die()打印这时的内核状态,包括寄存器,堆栈等等。
Pagefault的处理流程如下:
1.对参数有效性的检查:
a)如果出错地址在内核态,并且不是vmallloc引起的,那么oops,内核bug
b)如果内核在执行内核线程或者进行不容打断的操作(中断处理程序,延迟函数,禁止抢占的代码),oops
c)如果出错地址在用户态,并且可以在exceptiontable中找到,那么执行
exception的处理函数,正常返回,否则,oops
2.如果在进程的地址空间vma找不到对应的vma,
a)判断是不是堆栈扩展,如果是,扩展堆栈。
b)如果错误在内核态发生,在exceptiontable寻找异常处理函数:fixup
c)如果在用户态,向当前进程发送一个SIGV的信号。
3.如果在进程的地址空间内
a)如果是写访问
i.如果没有写权限,非法访问
ii.如果vma有写权限,pte没有写权限,判断是不是COW,是的话调用
do_wp_page。
b)如果是读访问,没有读权限,非法访问
c)如果不是权限问题,是普通的缺页,调用handle_mm_fault来解决
i.handle_mm_fault,如有需要,分配pud,pmd,pte
ii.如果页不在内存中
1.如果还没有分配物理内存,调用do_no_page
2.如果映射到文件中,还没有读入内存,调用do_file_page
3.如果该页的内容在交换分区上,调用do_swap_page
4.如果在内核态缺页,并且是由于vmalloc引起
a)根据masterkernelpagetable同步
读核感悟-文件读写-select实现原理
1功能介绍
select系统调用的功能是对多个文件描述符进行监视,当有文件描述符的文件读写操作完成,发生异常或者超时,该调用会返回这些文件描述符。
intselect(intnfds,fd_set*readfds,fd_set*writefds,
fd_set*exceptfds,structtimeval*timeout);
2关键的结构体(内核版本2.6.9):
这里先介绍一些关键的结构体:
typedefstruct{
unsignedlong*in,*out,*ex;
unsignedlong*res_in,*res_out,*res_ex;
}fd_set_bits;
这个结构体负责保存select在用户态的参数。在select()中,每一个文件描述符用一个位表示,其中1表示这个文件是被监视的。in,out,ex指向的bit数组表示对应的读,写,异常文件的描述符。res_in,res_out,res_ex指向的bit数组表示对应的读,写,异常文件的描述符的检测结果。
structpoll_wqueues{
poll_tablept;
structpoll_table_page*table;
interror;
};
这是最主要的结构体,它保存了select过程中的重要信息。它包括了两个最重要的结构体poll_table和structpoll_table_page。接下去看看这两个结构体。
typedefvoid(*poll_queue_proc)(structfile*,wait_queue_head_t*,structpoll_table_struct*);
structpoll_table_struct{
poll_queue_procqproc;
}poll_table;
在执行select操作时,会用到回调函数,poll_table就是用来保存回调函数的。这个回调函数非常重要,因为当文件执行poll操作时,一般都会调用这个回调函数。所以,这个回调函数非常重要,通常负责把进程放入等待队列等关键操作。下面可以看到,在select中,这个回调函数是__pollwait(),在epoll中,这个回调函数是ep_ptable_queue_proc。structpoll_table_page{
structpoll_table_page*next;
structpoll_table_entry*entry;
structpoll_table_entryentries[0];
};
这个表记录了在select过程中生成的所有等待队列的结点。由于select要监视多个文件描述符,并且要把当前进程放入这些描述符的等待队列中,因此要分配等待队列的节点。这些节点可能如此之多,以至于不可能像通常做的那样,在堆栈中分配它们。所以,select以动态分配的方式把它保存在poll_table_page中。保存的方式是单向链表,每个节点以页为单位,分配多个poll_table_entry项。
现在看一下poll_table_entry:
polltable的表项
structpoll_table_entry{
structfile*filp;
wait_queue_twait;
wait_queue_head_t*wait_address;
};
其中filp是select要监视的structfile结构体,wait_address是文件操作的等待
队列的队首,wait是等待队列的节点。
3select的实现
接下去介绍select的实现
在进行一系列参数检查后,sys_select调用do_select()。该函数会遍历所有需要监
视的文件描述符,然后调用f_op->poll(),这个操作会做两件事:
1.查看文件操作的状态,如果这些文件操作完成或者有异常发生(下面统称为“用户感兴趣的事件”),在对应的fdset中标记这些文件描述符。
2.如果retval为0(在这一轮遍历中,迄今为止,文件没有发生感兴趣的事,这一点有些不明白,为什么不是通知所有监视的并且没有发生感兴趣事件的文件描述符,这样返回得更快)并且没有超时,那么,通知这些文件,让他们在文件操作完成时唤醒本进程。
如果发现文件具体通知的方式是:通过__pollwait()把自己挂到各个等待队列中。这
样,当有文件操作完成时,select所在进程会被唤醒。这里涉及到一个回调函数
__pollwait()。它是在什么时候被注册的呢?在进入for循环之前,有这样一行代码:
poll_initwait(&table);
它的作用就是把poll_table中的回调函数设置为__pollwait。
对文件描述符的遍历的循环会继续,直到发生以下事件:
如果有文件操作完成或者发生异常,或者超时,或者收到信号,select会返回相应
的值,否则,do_select会调用schedule_timeout()进入休眠,直到超时或者被再次唤醒
(这表明有用户感兴趣的事件产生),然后重新执行for循环,但是这一次一定能跳出循环体。
通知的过程如下(以管道的poll函数为例,在pipe中,f_op->poll对应的函数是pipe_poll:):
当do_select遍历所有需要监视的文件描述符时,假设有一个文件描述符对应的是一个管道,那么,它执行的f_op->poll实际上是pipe_poll。pipe_poll->poll_wait-
>__pollwait。最终__pollwait会把当前进程挂到对应文件的inode中的文件描述符中。当执行pipe_write对管道进行写操作时,操作完成后会唤醒等待队列中所有的进程。4性能分析
从中可以看出,select需要遍历所有的文件描述符,就遍历操作而言,复杂度是
O(N),N是最大文件描述符加1。此外,select参数包括了所有的文件描述符的信息,所以select在遍历文件描述符时,需要检查文件描述符是不是自己感兴趣的。
读核感悟-文件读写-poll的实现原理
1功能介绍:
poll与select实现了相同的功能,只是参数类型不同。它的原型是:
intpoll(structpollfd*fds,nfds_tnfds,inttimeout);
可以看到,poll的参数中,直接列出了要监视的文件描述符的信息,而不像select一样要列出从0开始到nfds-1的所有文件描述符。这样的好处是,poll不需要查询很多无关的文件描述符的信息,在一定场合下效率会有所提高。
2关键的结构体:
poll用到的很多结构体与select是一样的,如structpoll_wqueues。这是因为
poll的实现机制与select没有本质区别。
poll也用到了一些不同的结构体,这是因为poll的参数类型与select不同,用来保存参数的结构体也不同:
相关的数据结构:
structpoll_list{
structpoll_list*next;
intlen;
structpollfdentries[0];
};
这个结构体用来保存被监视的文件描述符的参数。其中structpollfdentries[0]
表示这是一个不定长数组。
structpollfd{
intfd;
shortevents;
shortrevents;
};
这个结构体记录被监视的文件描述符和它的状态。
3poll的实现
poll的实现与select也十分类似。一个区别是使用的数据结构。poll中采用了
poll_list结构体来记录要监视的文件描述符信息。poll_list中,每个pollfd代表一个要监视的文件描述符的信息。这些pollfd以数组的形式链接到poll_list链表中,每个数组
的元素个数不能超过POLLFD_PER_PAGE。在把参数拷贝到内核态之后,sys_poll会调用do_poll()。
在do_poll()中,函数遍历poll_list链表,然后调用do_pollfd()对每个poll_list
节点中的pollfd数组进行遍历。在do_pollfd()中,检查数组中的每个fd,检查的过程与select类似,调用fd对应的poll函数指针:
mask=file->f_op->poll(file,*pwait);
1.如果有必要,把当前进程挂到文件操作对应的等待列队中,同时也放到poll
table中。
2.检查文件操作状态,保存到mask变量中。
在遍历了所有文件描述符后,调用
timeout=schedule_timeout(timeout);
让当前进程进入休眠状态,直到超时或者有文件操作完成,唤醒当前进程才返回。那么,在f_op->poll中做了些什么呢?在sys_poll中有这样一行代码:
poll_initwait(&table);
可以发现,在这里,它注册了和select()相同的回调函数__pollwait(),内部的实现
机制也是一样的。在这里就不重复说了。
4性能分析:
poll的参数只包括了用户感兴趣的文件信息,所以poll在遍历文件描述符时不用像select一样检查文件描述符是否是自己感兴趣的。从这个意义上说,poll比select稍微要高效一些。前提是:要监视的文件描述符不连续,非常离散。
poll与select共同的问题是,他们都是遍历所有的文件描述符。当要监视的文件描述符很多,并且每次只返回很少的文件描述符时,select/poll每次都要反复地从用户态拷贝文件信息,每次都要重新遍历文件描述符,而且每次都要把当前进程挂到对应事件的等待队列和poll_table的等待队列中。这里事实上做了很多重复劳动。
读核感悟-文件读写-epoll的实现原理
1功能介绍
epoll与select/poll不同的一点是,它是由一组系统调用组成。
intepoll_create(intsize);
intepoll_ctl(intepfd,intop,intfd,structepoll_event*event);
intepoll_wait(intepfd,structepoll_event*events,
intmaxevents,inttimeout);
epoll相关系统调用是在Linux2.5.44开始引入的。该系统调用针对传统的select/poll系统调用的不足,设计上作了很大的改动。select/poll的缺点在于:
1.每次调用时要重复地从用户态读入参数。
2.每次调用时要重复地扫描文件描述符。
3.每次在调用开始时,要把当前进程放入各个文件描述符的等待队列。在调用结束后,又把进程从各个等待队列中删除。
在实际应用中,select/poll监视的文件描述符可能会非常多,如果每次只是返回一
小部分,那么,这种情况下select/poll显得不够高效。epoll的设计思路,是把
select/poll单个的操作拆分为1个epoll_create+多个epoll_ctrl+一个wait。此外,内核针对epoll操作添加了一个文件系统”eventpollfs”,每一个或者多个要监视的文件描
述符都有一个对应的eventpollfs文件系统的inode节点,主要信息保存在eventpoll结构体中。而被监视的文件的重要信息则保存在epitem结构体中。所以他们是一对多的关系。
由于在执行epoll_create和epoll_ctrl时,已经把用户态的信息保存到内核态了,所以之后即使反复地调用epoll_wait,也不会重复地拷贝参数,扫描文件描述符,反复地把当前进程放入/放出等待队列。这样就避免了以上的三个缺点。
接下去看看它们的实现:
2关键结构体:
/*Wrapperstructusedbypollqueueing*/
structep_pqueue{
poll_tablept;
structepitem*epi;
};
这个结构体类似于select/poll中的structpoll_wqueues。由于epoll需要在内核
态保存大量信息,所以光光一个回调函数指针已经不能满足要求,所以在这里引入了一个新的结构体structepitem。
/*
*Eachfiledescriptoraddedtotheeventpollinterfacewill
*haveanentryofthistypelinkedtothehash.
*/
structepitem{
/*RB-Treenodeusedtolinkthisstructuretotheeventpollrb-tree*/structrb_noderbn;
红黑树,用来保存eventpoll
/*Listheaderusedtolinkthisstructuretotheeventpollreadylist
*/
structlist_headrdllink;
双向链表,用来保存已经完成的eventpoll
/*Thefiledescriptorinformationthisitemrefersto*/
structepoll_filefdffd;
这个结构体对应的被监听的文件描述符信息
/*Numberofactivewaitqueueattachedtopolloperations*/
intnwait;
poll操作中事件的个数
/*Listcontainingpollwaitqueues*/
structlist_headpwqlist;
双向链表,保存着被监视文件的等待队列,功能类似于select/poll中的poll_table
/*The"container"ofthisitem*/
structeventpoll*ep;
指向eventpoll,多个epitem对应一个eventpoll
/*Thestructurethatdescribetheinterestedeventsandthesourcefd
*/
structepoll_eventevent;
记录发生的事件和对应的fd
/*
*Usedtokeeptrackoftheusagecountofthestructure.Thisavoids
*thatthestructurewilldesappearfromunderneathourprocessing.
*/
atomic_tusecnt;
引用计数
/*Listheaderusedtolinkthisitemtothe"structfile"itemslist*/structlist_headfllink;
双向链表,用来链接被监视的文件描述符对应的structfile。因为file里有f_ep_link,用来保存所有监视这个文件的epoll节点
/*Listheaderusedtolinktheitemtothetransferlist*/
structlist_headtxlink;
双向链表,用来保存传输队列
/*
*Thisisusedduringthecollection/transferofeventstouserspace
*topinitemsemptyeventsset.
*/
unsignedintrevents;
文件描述符的状态,在收集和传输时用来锁住空的事件集合
};
该结构体用来保存与epoll节点关联的多个文件描述符,保存的方式是使用红黑树实现的hash表。至于为什么要保存,下文有详细解释。它与被监听的文件描述符一一对应。structeventpoll{
/*Protectthethisstructureaccess*/
rwlock_tlock;
读写锁
/*
*Thissemaphoreisusedtoensurethatfilesarenotremoved
*whileepollisusingthem.Thisisread-heldduringtheevent
*collectionloopanditiswrite-heldduringthefilecleanup
*path,theepollfileexitcodeandthectloperations.
*/
structrw_semaphoresem;
读写信号量
/*Waitqueueusedbysys_epoll_wait()*/
wait_queue_head_twq;
/*Waitqueueusedbyfile->poll()*/
wait_queue_head_tpoll_wait;
/*Listofreadyfiledescriptors*/
structlist_headrdllist;
已经完成的操作事件的队列。
/*RB-Treerootusedtostoremonitoredfdstructs*/
structrb_rootrbr;
保存epoll监视的文件描述符
};
这个结构体保存了epoll文件描述符的扩展信息,它被保存在file结构体的
private_data中。它与epoll文件节点一一对应。通常一个epoll文件节点对应多个被监视的文件描述符。所以一个eventpoll结构体会对应多个epitem结构体。
那么,epoll中的等待事件放在哪里呢?见下面
/*Waitstructureusedbythepollhooks*/
structeppoll_entry{
/*Listheaderusedtolinkthisstructuretothe"structepitem"*/
structlist_headllink;
/*The"base"pointerissettothecontainer"structepitem"*/
void*base;
/*
*Waitqueueitemthatwillbelinkedtothetargetfilewait
*queuehead.
*/
wait_queue_twait;
/*Thewaitqueueheadthatlinkedthe"wait"waitqueueitem*/
wait_queue_head_t*whead;
};
与select/poll的structpoll_table_entry相比,epoll的表示等待队列节点的结
构体只是稍有不同,与structpoll_table_entry比较一下。
structpoll_table_entry{
structfile*filp;
wait_queue_twait;
wait_queue_head_t*wait_address;
};
由于epitem对应一个被监视的文件,所以通过base可以方便地得到被监视的文件信息。又因为一个文件可能有多个事件发生,所以用llink链接这些事件。
3epoll_create的实现
epoll_create()的功能是创建一个eventpollfs文件系统的inode节点。具体由
ep_getfd()完成。ep_getfd()先调用ep_eventpoll_inode()创建一个inode节点,然后调用d_alloc()为inode分配一个dentry。最后把file,dentry,inode三者关联起来。
在执行了ep_getfd()之后,它又调用了ep_file_init(),分配了eventpoll结构体,
并把eventpoll的指针赋给file结构体,这样eventpoll就与file结构体关联起来了。
需要注意的是epoll_create()的参数size实际上只是起参考作用,只要它不小于等于0,就并不限制这个epollinode关联的文件描述符数量。
4epoll_ctl的实现
epoll_ctl的功能是实现一系列操作,如把文件与eventpollfs文件系统的inode节
点关联起来。这里要介绍一下eventpoll结构体,它保存在file->f_private中,记录了eventpollfs文件系统的inode节点的重要信息,其中成员rbr保存了该epoll文件节点监视的所有文件描述符。组织的方式是一棵红黑树,这种结构体在查找节点时非常高效。
首先它调用ep_find()从eventpoll中的红黑树获得epitem结构体。然后根据op参数的不同而选择不同的操作。如果op为EPOLL_CTL_ADD,那么正常情况下epitem是不可能在eventpoll的红黑树中找到的,所以调用ep_insert创建一个epitem结构体并插入到对应的红黑树中。
ep_insert()首先分配一个epitem对象,对它初始化后,把它放入对应的红黑树。此外,这个函数还要作一个操作,就是把当前进程放入对应文件操作的等待队列。这一步是由下面的代码完成的。
init_poll_funcptr(&epq.pt,ep_ptable_queue_proc);
。。。
revents=tfile->f_op->poll(tfile,&epq.pt);
函数先调用init_poll_funcptr注册了一个回调函数ep_ptable_queue_proc,这个
函数会在调用f_op->poll时被执行。该函数分配一个epoll等待队列结点eppoll_entry:一方面把它挂到文件操作的等待队列中,另一方面把它挂到epitem的队列中。此外,它还注册了一个等待队列的回调函数ep_poll_callback。当文件操作完成,唤醒当前进程之前,会调用ep_poll_callback(),把eventpoll放到epitem的完成队列中,并唤醒等待进程。
如果在执行f_op->poll以后,发现被监视的文件操作已经完成了,那么把它放在完成队列中了,并立即把等待操作的那些进程唤醒。
5epoll_wait的实现
epoll_wait的工作是等待文件操作完成并返回。
它的主体是ep_poll(),该函数在for循环中检查epitem中有没有已经完成的事件,有的话就把结果返回。没有的话调用schedule_timeout()进入休眠,直到进程被再度唤醒或者超时。
6性能分析
epoll机制是针对select/poll的缺陷设计的。通过新引入的eventpollfs文件系统,epoll把参数拷贝到内核态,在每次轮询时不会重复拷贝。通过把操作拆分为
epoll_create,epoll_ctl,epoll_wait,避免了重复地遍历要监视的文件描述符。此外,由
于调用epoll的进程被唤醒后,只要直接从epitem的完成队列中找出完成的事件,找出完成事件的复杂度由O(N)降到了O(1)。
但是epoll的性能提高是有前提的,那就是监视的文件描述符非常多,而且每次完成操作的文件非常少。所以,epoll能否显著提高效率,取决于实际的应用场景。这方面需要进一步测试。
读核感悟-同步问题-同步问题概述
1同步问题的产生背景
在多线程应用程序中,线程同步是一个非常重要的环节,没有做好线程同步,应用程序不仅难以保证结果的正确性,也难以保证应用程序的稳定性。
另一方面,在应用程序调试中,线程同步的调试难度也比较大。线程同步引起的bug通常具有随机性。因为线程的调度具有随机性。很多情况下,只有当产生一个特定的执行序列时,bug才会产生。这使多线程的bug很难复现和追踪。
现有的调试工具中,针对多线程的工具很少。很多情况下只能使用打印日志的方式来调试多线程。这使我们在写多线程程序时必须分外小心。
pthread线程库提供了丰富的同步手段。如互斥锁(pthread_mutex_t),自旋锁
(pthread_spin_t),读/写自旋锁(pthread_rwlock_t)等等。
事实上,内核态同样有同步机制,而且比用户态更加丰富。了解内核态的同步机制,对了解和实现用户态的同步机制很有意义。
2内核态与用户态的区别
现代操作系统都建筑在保护模式基础上。与实模式不同,保护模式下程序运行在不同的级别下。普通的应用程序运行在用户态,操作系统内核则运行在内核态。
与用户态不同,内核态的程序可以使用很多特权指令(如用cli关中断,用lgdt设置全局描述符表,等等),可以响应外部设备的中断,也可以对各个进程进行调度。操作系统内核运行在内核态下,负责了对所有进程的调度,对文件系统的读写,对设备中断的响应和处理,对物理内存的分配等等。由于操作系统要统一分配计算机资源,它把关键的信息如
PCB(进程控制块),设备驱动,文件系统等等代码映射到相同的虚拟地址空间。在i386上,是3G-4G。
内核态可以执行普通的系统调用函数,中断处理程序等等,这些被统称为内核控制路径(kernelcontrolpath)。内核控制路径可以互相嵌套,如系统调用中可以嵌套中断处理函数,中断处理函数内部还可以嵌套执行。这样一来,内核态的代码的执行流程就显得非
常复杂。如果是在多CPU的环境下,同一时刻会有多个CPU访问同一块数据。如果把系统调用函数和中断处理程序比作线程,想象一下多个线程同时执行的复杂情况。所以内核需要自己实现同步。
为此,内核拥有丰富的同步原语,如信号量(类似于用户态的互斥锁),自旋锁(类似于用户态的自旋锁)等等。内核还拥有用户态没有的杀手锏--关中断。在单处理器上,只要关了中断,就没有其它内核代码来干扰当前代码的执行了。
在用户态,进程使用的指令是有限的,也不能响应外部设备。这大大简化了用户态程序的设计。对每个进程来说,它拥有自己独立的用户空间,并且大部分情况下不用考虑其它
进程的干涉。但是线程的出现给用户态带来了新的同步问题。pthread库提供了丰富的同步语,如pthread_mutex_t(用户态互斥锁)、pthread_spinlock_t(用户态自旋锁)、
pthread_rwlock_t(用户态读/写自旋锁)。
了解一下内核态同步原语的实现,有助于了解和设计用户态的同步原语
读核感悟-同步问题-内核态自旋锁的实现
1自旋锁的总述
在多处理器上,同一时间可能有多个CPU访问同一个数据。在多核处理器上,情况是类似的,因为对操作系统而言,一个核,甚至一个超线程(在一个核里同时执行多个代码流的技术,就好像有多个核)等价于一个“逻辑CPU”。这时候,关中断的能力就显得有限了,因为关中断只对本地的CPU起作用。x86-64处理器提供了锁总线的机制。由于多个CPU通过总线访问内存,Intel提供了在指令前加lock前缀的方法来强制性地锁住总线,使同一时刻只有一个CPU能访问内存。
但是,锁总线只对一条指令起作用,对于一个代码段,光锁总线也不够了。所以内核提供了自旋锁。
自旋锁(spinlock),顾名思义是“自己不停地旋转(循环)的锁”。它的基本思想
是通过不停地检测锁的状态,来获得锁。它有以下特点:
1.由于在这段时间CPU一直处于忙等状态(非抢占式内核中),所以除了响应中断,无法做其它事情。所以自旋锁针对的代码段一定要能够在短时间内执行完,不能休眠(即不能让出CPU)。
2.由于获得自旋锁的过程中不会引起进程切换,所以它的开销很小。自旋锁要比信号量快得多。
3.由于获得自旋锁的过程中不会引起进程切换,所以它不仅可以用在进程上下文(如系统调用,内核线程),也可以用在中断上下文(如中断处理函数,bottomhalf等等)。
4.自旋锁可以与其它同步手段相结合,如禁止中断(对应spin_lock_irq),禁止下半部(对应spin_lock_bh)
5.自旋锁有非阻塞版本,如spin_trylock()。
自旋锁有多个版本的实现
多CPU版本:定义了CONFIG_SMP
它又根据CONFIG_PREEMPT(抢占)宏定义为抢占和非抢占式。
单CPU版本:没有定义CONFIG_SMP
它根据CONFIG_PREEMPT(抢占)宏定义为抢占和非抢占式。
此外,它根据CONFIG_DEBUG_SPINLOCK定义了调试和非调试版本。
我们只对SMP非抢占版本感兴趣。
在抢占式和非抢占式内核中,spinlock的实现之所以不同,是因为在抢占式内核中,spinlock可以做一些优化,即在无法立即获得锁的情况下,spinlock会允许其它进程抢占当前进程,而不只是死循环来争夺锁。这使进程的实时性有了一定的提高。但是会牺牲性能。在非抢占式内核中,当前CPU只是不停循环来尝试获取锁。
2非抢占式的自旋锁
下面看一看自旋锁(spinlock)的非抢占式版本,也是服务器上经常使用的版本:
spinlock_t结构体中包含了一个lock的成员,当锁释放时,它的值为1,当有代码获得锁时,它的值小于等于0。
获得锁的函数spin_lock()它的关键部分的代码:
#definespin_lock_string\
"\n1:\t"\
"lock;decl%0\n\t"\
"js2f\n"\
LOCK_SECTION_START("")\
"2:\t"\
"rep;nop\n\t"\
"cmpl$0,%0\n\t"\
"jle2b\n\t"\
"jmp1b\n"\
LOCK_SECTION_END
它的伪代码如下:
for(;;){
lock--;
if(lock==0){
获得锁,执行下面的代码。
Break;
}
else{
for(;;){
if(lock==1){
锁已经被释放,跳转到trylock处尝试获得锁。
Break;
}else执行空操作
}
}
}
这段代码的流程是这样的:
1.首先把锁计数lock减一,如果不小于0,表示获得锁,跳出外部for循环,执行下面的代码。
2.否则,进入内部for循环。在内部的for循环中,不停地检测lock计数是否为1。为1表示锁已经释放,然后跑出内部for循环,在外部循环中再次尝试获得锁。
3.在这个过程中,关键的操作是对lock计数进行减1操作。这个操作必须锁总线,以保证减操作的正确性。
3锁的释放
锁的释放相对比较简单,只要把lock计数赋值成1就行了。
4与用户态的自旋锁的比较
用户态也有自旋锁。pthread库提供了pthread_spinlock_t。它的实现机制是与内核
态的自旋锁类似的。当其它CPU无法获得锁时,也会旋转空等。
不同的是,由于在用户态无法关中断,如果自旋锁保护的代码段执行时间过长,可能
会引发进程调度,导致自旋锁迟迟不能释放。其它CPU如果长时间得不到锁,就会因为时间片的耗尽而让出CPU。所以,自旋锁保护的代码段要简短,这一点是与内核态一致的。
一种改进的策略是:在尝试获得锁的次数超过一定次数(如100),就主动让出
CPU,这样的好处是,既保证了在其它CPU能够迅速释放锁的情况下能够不通过进程切换就
能获得锁,又保证了其它CPU不能够迅速释放锁的情况下,主动让出CPU,不会导致CPU资源的浪费。
与互斥锁相比,自旋锁适合保护执行时间比较快的代码段,因为在大部分情况下,等
待很短时间,不需要进行进程上下文切换就可以获得锁,会比互斥锁高效一些。
5总结
自旋锁的思路很简单,在实现中,只需要保证对lock计数的写操作是原子的就可以,这过程中需要锁住总线。
在内核中,开发人员可以通过关中断等方式,保证自旋锁对应的代码段不会引起调度。用户态应用程序中,由于无法通过关中断来禁止进程调度,所以照搬内核态的那种自旋锁的实现方式,在一定条件下可能会引起性能的下降。
读核感悟-内存管理-free命令详解
free命令可以用来显示内存使用状况。
运行free的结果显示如下:
totalusedfreesharedbufferscached
Mem:20673122015xxxxxxxxxxxx47252
-/+buffers/cache:1265204802108
Swap:9799240979924
但是关于这里的字段的具体含义,man手册语焉不详。尤其是buffer和cache究竟是指什么,”-/+buffers/cache”的意义,基本没有提及。不过我们可以通过源代码来获得
答案。
通过man手册可以知道,free命令的数据都来自于/proc/meminfo。在
proc_misc_init()中,meminfo文件节点被初始化。读取信息是meminfo_read_proc。在meminfo_read_proc()中,si_meminfo(i)获得内存信息。虽然有很多字段,但是我们重点关注的是/proc/meminfo中的MemBuffers和Cached字段,后面可以看到,free中的buffers和cached就是对应这两个字段。
先看一下MemBuffers对应的是什么,在meminfo_read_proc()这个函数中可以看到:
val->bufferram=nr_blockdev_pages();
在linux系统中,为了加快文件的读写,内核中提供了pagecache作为缓存。为了
加快对快设备的读写,内核中还提供了buffercache作为缓存。在2.4内核中,这两者是分开的。这样就造成了双缓冲,因为文件读写最后还是转化为对块设备的读写。在2.6中,buffercache合并到pagecache中,对应的页面叫作bufferpage。当进行文件读写时,如果文件在磁盘上的存储块是连续的,那么文件在pagecache中对应的页是普通的page,如果文件在磁盘上的存储块是不连续的,那么文件在pagecache中对应的页是buffer
page。bufferpage与普通的page相比,每个页多了几个buffer_head结构体(个数视块的大小而定)。此外,如果对单独的块(如超级块)直接进行读写,对应的pagecache中的页也是bufferpage。这两种页面虽然形式略有不同,但是最终他们的数据都会被封装成bio结构体,提交到通用块设备驱动层,统一进行IO调度。
此外,pagecache中还包含了swapcache。它里面包括了曾经被交换出内存,现在
又被换入内存,但是在交换设备(如交换分区)中仍然有对应的内容。之所以设置swap
cache是因为如果这些页面要被再度换出内存,不必执行真正的换出操作,因为交换设备中已经有了。这样做节省了不必要的I/O。
由上可知:/proc/meminfo中的MemBuffers对应块设备的缓存,即绕过文件系统直接对块设备读写时系统的缓存。
此外,在显示“Cached”的时候,使用的是这个表达式:
get_page_cache_size()-total_swapcache_pages-i.bufferram
其中get_page_cache_size()返回的是总的pagecache的大小,
total_swapcache_pages对应的是swapcache的大小,i.bufferram对应的是块设备的缓存。所以,“Cached”表示pagecache中除去块设备的缓存和swapcache后余下的部分。这部分主要保存在磁盘上的文件的页面,这些文件对应的物理存储块可能连续(普通的page)也可能不连续(bufferpage)。
可以看到,/proc/meminfo中的MemBuffers和Cached对应的内容都是内核中的缓存,对加快文件读写很有意义。
其它的/proc/meminfo参数详见:
/2008/02/know-about-procmeminfo.html
现在回过头来看一下free。它的源代码也很容易得到。
在debian/ubuntu下,运行
dpkg-Sfree
可以很容易找到free对应的软件包procps。运行
apt-getsourceprocps
可以方便地下载到procps的代码。
在proc/sysinfo.c中,可以知道free中的buffers和cached就对应/proc/meminfo
中的MemBuffers和Cached
在free.c中,可以看到,第一行中的used列表示系统已经使用的内存,free表示当前空余的内存。
-/+buffers/cache的意思是:
第二行used列对应的值=系统已经使用的内存-(buffers+cached)
第二行free列对应的值=系统空余的内存+(buffers+cached)
个人理解如下:
buffers和cached本质上是系统为加快文件读写所使用的缓存。没有这些buffers和cached,系统也能运行,只是IO性能会变得非常低下。当多个应用程序访问相同的文件时,很可能这些文件已经被放在pagecache里了,所以对这些应用程序来说buffers和cached对应的内存也是可用的,因为他们要访问的文件的数据放在buffers和cached里,而这些内存并不需要他们显式地分配。所以free命令输出的第一行是从系统的角度来看内存使用情况,第二行是从应用程序的角度来看内存使用情况。
读核感悟-文件读写-2.6.9内核中的AIO
1AIO概述
AIO(AsynchronousI/O,异步I/O)是比较普遍的一种IO处理方式,这种方式允许在I/O传输完成之前,执行其它的操作。与它相对应的IO处理方式是同步IO,要求在当前的I/O传输完成之后,再执行其它操作。它可以看到,在相同的时间,用异步IO的方式能
够提交更多的I/O请求。
AIO的实现形式有很多种,包括
1.轮询,通过反复检查IO状态来判断IO操作是否完成。
2.循环调用select/poll,这两个系统调用可以用来监视一组文件描述符的IO操作。3.信号,当IO操作完成后,应用程序会收到一个信号。应用程序只要注册相应的信号处理函数,就可以在IO操作完成时执行相应的操作。
Posix标准定义了一组异步I/O的接口(aio_read/aio_write等等),标准并没有规定这些接口的实现方式。在Linux下,这组接口是由glibc库函数实现的。它的实现机制如下:
异步I/O操作在用户态维护一个队列,叫做runlist,每个线程从runlist读取请求进行处理。同时还有个freelist作为请求结构的缓冲池。当上层应用程序的读写操作调用aio读写函数时,从freelist中获取一个请求结构填充数据与操作类型等,然后挂入request链表中;随即向上层返回,表示完成此次IO操作。
用户态AIO线程从runlist取请求进行处理,处理完毕后,从runlist和request队列中删除请求放入freelist,并通知应用程序操作已完成,用户可以读取数据或者继续写入数据。
POSIX标准库提供了很多异步IO的函数。库函数aio_readaio_erroraio_returnaio_writeaio_suspend
功能
请求异步读操作检查异步请求的状态获得完成的异步请求的返回状态
请求异步写操作
挂起调用进程,直到一个或多个异步请求已经完成(或失败)
取消异步I/O请求发起一系列I/O操作
原型
intaio_read(structaiocb*aiocbp);
intaio_error(conststructaiocb*aiocbp);ssize_taio_return(structaiocb*aiocbp);intaio_write(structaiocb*aiocbp);
intaio_suspend(conststructaiocb*constcblist[],intn,conststructtimespec*timeout);intaio_cancel(intfd,structaiocb*aiocbp);intlio_listio(intmode,structaiocb*restrictconstlist[restrict],intnent,structsigevent*restrictsig);
aio_cancellio_listio
这是一种通过用户态实现AIO的方法,但是效率与在内核态实现的AIO有很大的区别。
因为这种实现不仅需要额外的用户态线程创建,而且要执行多次系统调用。
在2.6内核中,Linux逐步在内核态实现了异步I/O。但是,到2.6.11为止,内核态异步I/O仍然只支持O_DIRECT标记。在2.6.9中,内核态实现了以下几个异步IO的系统调用:
系统调用
io_setup功能为当前进程初始化一
个异步IO上下文
提交一个或者多个异
步IO操作原型intio_setup(unsignednr_events,aio_context_t*ctxp);intio_submit(aio_context_tctx_id,longnr,structiocb**iocbpp);io_submit
io_getevents获得未完成的异步IOintio_getevents(aio_context_tctx_id,
操作的状态longmin_nr,longnr,structio_event
*events,structtimespec*timeout);
取消一个未完成的异
步IO操作
从当前进程删除一个
异步IO上下文intio_cancel(aio_context_tctx_id,structiocb*iocb,structio_event*result);intio_destroy(aio_context_tctx);io_cancelio_destroy
2内核态AIO的使用
用户态的AIO的使用很方便,只要在源代码里包含aio.h头文件,在链接时加上-lrt
就可以了。
内核态的AIO的使用,则首先要保证内核支持AIO,其次,要安装libaio库。在当前的2.6.9内核中,内核支持AIO,但是系统中并没有安装libaio。所以要下载libaio的源代码,然后在源代码目录下执行makeprefix=/usrinstall,libaio就会安装到系统
的/usr目录下。如果只是出于实验目的,可以把prefix参数改成普通用户自定义的目录,这样就不会影响其它应用程序的运行。在源代码里包含libaio.h,在链接时加上-laio就行。读核感悟-文件读写-内核态AIO相关结构体
1内核态AIO操作相关信息
内核态AIO的操作相关信息,是保存在对应异步I/O上下文中的,具体下文中会讲到。AIO的控制信息包括了执行一次AIO操作的所有必要信息。
结构体定义如下:
structkiocb{
structlist_head
结构体中的run_list队列中
long
intki_run_list;//这个字段会把kiocb挂载到对应kioctxki_flags;ki_users;//引用计数
unsigned
structfile
structkioctx
//对应的kioctx结构体
int
*);//取消AIO的操作
ssize_t
void
structlist_head
union{ki_key;/*idofthisrequest*/*ki_filp;//指向structfile结构体的指针*ki_ctx;/*maybeNULLforsyncops(*ki_cancel)(structkiocb*,structio_event*/(*ki_retry)(structkiocb*);//要执行的retry操作(*ki_dtor)(structkiocb*);//析构函数ki_list;/*theaiocoreusesthis*forcancellation*/
*user;//指向用户态的iocb结构体
*tsk;//指向PCB
*/void__userstructtask_struct}ki_obj;__u64ki_user_data;/*user'sdataforcompletion
loff_tki_pos;//文件指针的偏移量
/*Statethatweremembertobeabletorestart/retry*/
unsignedshortki_opcode;//文件操作
size_tki_nbytes;/*copyofiocb->aio_nbytes*///文件操作字节数
char__user*ki_buf;/*remainingiocb->aio_buf*///
异步IO的用户态缓冲区
size_tki_left;/*remainingbytes*///剩余操作
的字节数
wait_queue_tki_wait;//等待队列
longki_retried;/*justfortesting*/retry的次数
longki_kicked;/*justfortesting*/
longki_queued;/*justfortesting*/
void*private;
};
这个结构体是在内核中内部使用的,当执行io_submit时,该系统调用会把异步IO的请求挂载到异步IO上下文结构体kioctx的active_reqs队列中。
此外,在用户态,应用程序也需要把AIO操作相关信息传递给系统调用。
structiocb{
/*theseareinternaltothekernel/libc.*/
__u64aio_data;/*datatobereturnedinevent'sdata
回异步IO事件信息的空间。
__u32PADDED(aio_key,aio_reserved1);
/*thekernelsetsaio_keytothereq
/*commonfields*/
__u16aio_lio_opcode;/*seeIOCB_CMD_above*/
__s16aio_reqprio;//请求的优先级*/用来返#*/
__u32
__u64
__u64
__s64aio_fildes;//文件描述符aio_buf;//用户态缓冲区aio_nbytes;//文件操作的字节数aio_offset;//文件操作的偏移量
/*extraparameters*/
__u64aio_reserved2;/*TODO:usethisfora(structsigevent*)*/
__u64aio_reserved3;
};/*64bytes*/
用户态的iocb结构体在内核态最后会转化为kiocb结构体,挂到相应的kioctx结构体中。
2AIO上下文:
这个结构用来保存异步I/O上下文,一个进程可以有多个异步I/O上下文,他们都被保存在mm->ioctx_list链表中。一个异步I/O上下文可以保存多个异步I/O操作。每个异步I/O上下文都有用来标志的唯一的id号。此外,为了方便地与用户态应用程序交互,每个异步I/O上下文还拥有一个AIOring,用来保存对应异步I/O操作的结果。下面会具体介绍。
对应的结构体如下:
structkioctx{
atomic_tusers;//引用计数
intdead;
structmm_struct*mm;//进程虚拟内存管理信息
/*Thisneedsimproving*/
unsignedlonguser_id;//用来标记aio上下文的id,本质上是对应的
AIOring的起始地址
structkioctx*next;//指向下一个kioctx
wait_queue_head_twait;//等待队列
spinlock_tctx_lock;//用来保护kioctx的锁
intreqs_active;//活跃的请求数
structlist_headactive_reqs;/*usedforcancellation*/
structlist_headrun_list;/*usedforkickedreqs*/
unsignedmax_reqs;//最大请求数
structaio_ring_inforing_info;//AIOring
structwork_structwq;//workqueue中的“任务”
};
3AIOring
为了方便地把I/O操作的结果返回给用户态进程,内核态的异步I/O设计了AIOring。这是一段内核态与用户态都可以访问的内存,用来保存一组I/O操作的结果。每个I/O操作的结果用io_event结构体表示。
之所以叫作ring是因为它是一个循环数组。它在虚拟地址空间中的起始地址是
mmap_base,大小是mmap_size。ring_pages指向一个structpage指针数组。nr_pages是页面的数量。Nr,tail是来保存循环数组的大小和数组末尾。它由一个aioring缓冲区的头部(用aio_ring结构体表示)和一个io_event数组组成。
对应的内核态结构体如下:
structaio_ring_info{
unsignedlongmmap_base;//aioring的起始地址
unsignedlongmmap_size;//aioring的大小
structpage**ring_pages;
spinlock_tring_lock;//用来保护的锁
longnr_pages;//aioring使用的物理页面个数
unsignednr,tail;//用来记录aioring循环数组起始和结束信
息的下标
structpage*internal_pages[AIO_RING_PAGES];//指向aioring
对应物理页面的structpage结构体指针
};
此外,在用户态的aioring,还有一个头部信息。
结构体定义如下:
structaio_ring{
unsignedid;/*kernelinternalindexnumber*/aio上下文的id
unsignednr;/*numberofio_events*/ioevents的个数
unsignedhead;//aioring循环数组的起始下标
unsignedtail;//aioring循环数组的尾部下标
unsignedmagic;
unsignedcompat_features;
unsignedincompat_features;
unsignedheader_length;/*sizeofaio_ring*/aio_ring结构体的大小
structio_eventio_events[0];//接下去是io_event数组。
};/*128bytes+ringsize*/
这个是AIOring缓冲区的头部。与aio_ring_info结构体不同的是,它是保存在用户态的AIOring中,用来说明AIOring的基本信息,而aio_ring_info结构体是用来记录AIOring在用户空间的位置,以及对应的物理页面的信息。
4异步I/O事件的返回信息
异步I/O事件的结果保存在io_event结构体中:
/*read()from/dev/aioreturnsthesestructures.*/
structio_event{
__u64data;/*thedatafieldfromtheiocb
__u64obj;/*whatiocbthiseventcamefrom
应的用户态iocb结构体指针
__s64res;/*resultcodeforthisevent*/*///对*///操作的结果
__s64
};
这些结构体的关系如下图:res2;/*secondaryresult*/
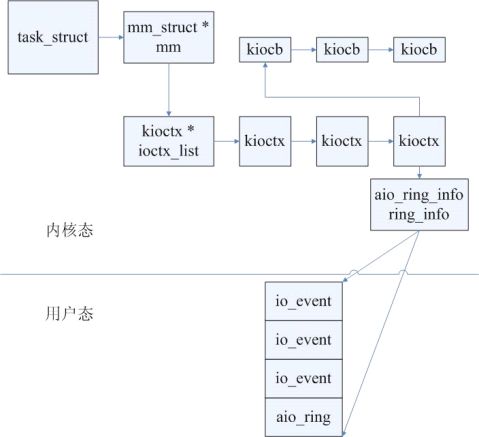
读核感悟-文件读写-内核态AIO创建和提交操作
1AIO上下文的创建-io_setup()
io_setup的功能是创建一个异步I/O的上下文,它的原型如下:
intio_setup(unsignednr_events,aio_context_t*ctxp);
其中,nr_events是AIO上下文中同一时刻能容纳的I/O事件的数量(已经操作完成的
不算)。Ctxp是指向AIO上下文id的指针。AIO上下文id的本质是指向AIO上下文的指针。
io_setup在内核态实际调用的是sys_io_setup。它主要分两步来创建异步I/O上下
文:
1.调用ioctx_alloc()创建一个新的kioctx结构体,并对它进行初始化。其中,对
kioctx中的work_struct(工作队列中的“任务”)进行初始化,把对应的执行函数设置为
aio_kick_handler。
2.调用aio_setup_ring()对kioctx中的AIOring信息进行初始化。
AIOring的开头几个字节是描述信息,接下去是一个io_event数组,数组元素的个
数为nr_events。计算所需的页面数量,分配这些页面,然后调用do_mmap()把这些页面映射到进程的用户态地址空间。这样的好处是应用程序不通过系统调用就能方便地访问到AIOring的信息。因为do_mmap()并不真正为AIOring分配物理页面,所以接下去还要调用get_user_pages()为它们分配物理页面。AIOring的物理页面数组信息存放在
aio_ring_info的internal_pages变量中。
初始化kioctx完毕后,把它挂到进程的内存管理结构体mm的ioctx_list中。
2AIO请求的提交:io_submit实现机制
io_submit的功能是提交异步IO的请求
intio_submit(aio_context_tctx_id,longnr,structiocb**iocbpp);
其中ctx_id是AIO上下文id,nr是请求个数,iocbpp是请求数组,里面包含着iocb信息。
该系统调用的内核函数是sys_io_submit(),该函数首先把用户态的异步IO请求iocb结构体拷贝到内核态,然后调用io_submit_one()把这些io请求一一提交到内核。
对kiocb结构体的初始化:
io_submit_one会为每个异步IO请求分配内核态的结构体kiocb,然后把用户态的iocb结构体的内容转化为内核态的kiocb结构体。
对AIO操作函数的初始化:
调用aio_setup_iocb对kiocb中的ki_retry作进一步的初始化操作:读操作实际上执行的是aio_pread函数,写操作实际上执行的是aio_pwrite操作,FDSYNC操作实际上执行的是aio_fdsync操作,FSYNC操作实际上执行的是aio_fsync操作。
对kiocb初始化完成后,如果kioctx中的run_list为空,则直接调用
aio_run_iocb()来执行真正的异步IO操作,否则,放入run_list队列,执行
__aio_run_iocbs(),执行队列中的AIO操作。
读核感悟-文件操作-AIO操作的执行
1.在提交时执行AIO
异步I/O操作通过io_submit()提交后,首先会在提交时尝试执行aio_run_iocb(),若不能立即执行完毕,返回,则放到AIO上下文kioctx的run_list中执行
__aio_run_iocbs()。但是,大部分的AIO操作是在工作队列中完成的。
2.在工作队列中执行AIO
这里,需要简单介绍一下工作队列。工作队列(workqueue)是内核中的一种机制,内核开发者可以通过create_workqueue()创建工作队列。开发者可以选择创建单个内核线程,也可以选择创建多个线程,每个CPU上绑定一个线程。开发者可以把任务封装到
work_struct结构体中(包括函数,参数和定时器等等),然后调用queue_work()把任务放到工作队列中。当工作队列的内核线程被内核调度到时,里面的任务会得到执行。
运行psaux可以看到aio/0、aio/1、aio/2等等,这些就是内核启动时创建的工作队列在每个CPU核上对应的内核线程。它是如何生成的呢?在系统启动时,内核会调用aio_setup(),该函数会创建一个名叫”aio”的工作队列。
该工作队列会在每个CPU核上创建一个内核线程。用户通过psaux命令可以看到,aio/0、aio/1、aio/2、aio/3等等。当内核在执行系统调用io_submit时不能立即把AIO操作处理完毕,就会把这些任务放到工作队列中,内核会在适当的时机执行它们。工作队列的对应的处理函数是aio_kick_handler()。它会调用__aio_run_iocbs()完成IO操作。
3.负责AIO执行的核心函数aio_run_iocb
__aio_run_iocbs()负责把每个kiocb结构体从kioctx中取出来,然后调用
aio_run_iocb()完成AIO操作。由此可见,最核心的函数是aio_run_iocb(),对异步I/O的操作最后都会落实到这个函数。
aio_run_iocb()的功能是调用每个AIO操作的retry方法,这个方法必须要尽可能的非阻塞,防止其它等待处理的AIO操作等待时间过长。
aio_run_iocb()在调用retry方法时,会判断返回值。
当返回值是EIOCBRETRY时,这意味着AIO操作只是部分完成,需要把kiocb的状态标记为Kicked,并且把该操作放入ki_run_list队列中。这样在工作队列中,aio内核线程会尝试着去再次执行它。
当返回值是EIOCBQUEUED时,这意味着AIO操作是以directIo的方式进行的。请求已经提交,但是还没有完成。
当返回值是其它值时,表示AIO操作结束,可能是正常结束,也可能是发生I/O错误。这时调用aio_complete完成I/O操作。
那么AIO操作的retry方法是什么呢?以读操作为例,retry方法实际上指向的是aio_pread函数。它走的流程与普通文件的读写并没有什么不同。
4AIO操作的完成
从前面的分析可以看到,当AIO操作结束时,会调用aio_complete来进行善后操作。这个函数的功能是把AIO操作的返回值写到AIOring中。前面提到,这是一块内核态与用户态都可以访问的缓冲区。它其实是一个循环数组,里面存放了io_event。当应用程序调用io_getevents系统调用时,就会从AIOring中读取AIO操作的状态和返回值。读核感悟-文件读写-内核态是否支持非directI/O方式的AIO
不止一篇文档指出:2.6.9的内核只支持directI/O方式的AIO。那么,这是否意味着无法用AIO的系统调用来执行非directI/O的文件操作呢?(即通过pagecache的操作?)
如果文件是以directI/O的方式打开的(即open时有O_DIRECT标志)代码执行流程如下:
aio_pread->generic_file_aio_read->__generic_file_aio_read-
>generic_file_direct_IO
可以看到,走的流程与同步的普通文件读写是类似的。区别在于,同步的文件读写中,kiocb的ki_key域的值是KIOCB_SYNC_KEY。而AIO的文件读写中,kiocb的ki_key的值是0(刚提交)或者KIOCB_C_CANCELLED(操作取消)或者KIOCB_C_COMPLETE(操作完成)。这样,内核在底层函数中就可以判断操作是由AIO还是其它方式发起的,从而执行不同的操作。当内核发现发起的操作是采用AIO的方式并且是directI/O的方式,那么,它会以异步的方式提交请求,即在请求提交之后立即返回。返回值为-EIOCBQUEUED。表示请求已经提交。而在同步的directI/O的方式下,进程提交请求后要等待请求完成,然后再返回完成读写的字节数。
从这里可以看到,在发起IO操作后,是立即返回,还是等待I/O操作完成后再返回,
是同步和异步两种I/O方式的重要区别。
如果文件是以非directI/O的方式打开的,事实证明,这种方式同样能够执行AIO
的系统调用。代码的执行流程如下:
aio_pread->generic_file_aio_read->__generic_file_aio_read-
>do_generic_file_read
可以看到,与普通的文件读写的流程没有什么区别。内核并不会因为发起操作的方式
是异步I/O而立即返回,而是与同步的I/O操作一样,等待I/O操作完成后才返回。从这个意义上说,内核对非directI/O方式发起的AIO的实现是虚假的。
所以说,在2.6.9中异步io只支持directI/O。如果以非directI/O的方式使用
AIO,也能够运行。但是,由于retry对应的方法是走普通的I/O操作的流程,即读写都经过pagecache,那么retry方法就会阻塞。如果一个文件重来没有被访问过,那么,当进程访问它时,必须等待I/O操作完成。这与AIO的本意是相悖的(AIO的本意是进程发起IO操作后能立即返回,执行后续操作。)。所以,2.6.9中也可以用非directI/O的方式使用AIO,但是并不是真正意义上的异步I/O。
读核感悟-文件读写-内核态AIO的相关测试
对异步IO的性能测试需要考虑多个方面,包括
1.是diretctI/O还是非directI/O
2.是同步I/O还是异步I/O
3.是用户态的异步I/O还是内核态的异步I/O
4.是连续提交多个AIO请求,最后等待操作完成,还是每提交一个I/O请求就立即等待。
根据这些情况,编写了相应的测试程序,用不同的方式完成多种读写请求。共完成
5000次读请求和5000次写请求,每次IO请求的数据大小为8K。采用随机的方式进行访问。共有10个测试程序:包括5种方式(每种方式采用diretctI/O和非diretctI/O两种方式)1-2普通的文件读写(使用系统调用readwrite而不用glibc的fread和fwrite)
3-4内核态的AIO,采用每提交一次,就等待AIO的返回值的方式(仅作参考)。
5-6用户态的AIO,采用每提交一次,就等待AIO的返回值的方式(仅作参考)。
7-8内核态的AIO,采用一次性提交大量IO,然后等待AIO的返回值的方式。
9-10用户态的AIO,采用一次性提交大量IO,然后等待AIO的返回值的方式。
1kio_testdio2kio_testnodio
3kaio_testdio4kaio_testnodio
5uaio_testdio6uaio_testnodio
7kaio_async_testdio8kaio_async_testnodio
9uaio_async_testdio10uaio_async_testnodio
注意到AIO的测试情况采用了两种方式:
1每提交一次,就等待AIO的返回值,这种方式其实本质上与同步I/O没有太大的差别。2一次性提交大量IO,然后等待AIO的返回值,这种方式才体现了异步I/O的优势:能够在相同时间内提交更多的I/O请求,并且当前进程不用返回。测试结果如下:
测试程
序是否异步是否direct
I/OAIO是AIO提总时间否基于交请求时间内核态后是否
等待内核时间I/O提交时间CPU利用率
从测试的结果来看(我们不考虑3-6的情况,因为不是常用的AIO的使用方式)1.在directI/O的情况下内核态AIO与用户态AIO的比较:
速度而言:内核态AIO快于同步I/O,同步I/O快于用户态AIO。
内核态的AIO在directI/O的情况下,采用一次性提交大量AIO操作的方式,效率要远远高于用户态的AIO,效率提高5倍(3.22/0.59=6)。而且这是在内核态AIO的CPU利用率比用户态低的情况下取得的(36%<62%)。因为用户态的AIO需要在用户态做大量的工作从而在用户态模拟异步I/O。它在用户态做了大量的工作,消耗了大量的用户态CPU时间
(2.48s),而内核态AIO在用户态要做的事情很少(usertime几乎为0s),几乎所有的操
作都是在内核态完成的。
2.在directI/O的情况下,内核态AIO与同步I/O的比较
采用一次性提交大量AIO操作的方式,效率略高于同步方式的directI/O,(0.59svs0.73s)但是注意到CPU利用率高于同步方式的directI/O(19%vs36%)。如果判断内核态时间的话,要慢于同步方式的directI/O(0.15vs0.26)。出现这种情况并不奇怪,因为异步IO的优势在于能够提高I/O吞吐量。
内核态的AIO在directI/O的情况下,花了较少的时间就提交了大量的I/O请求,而同步I/O则要花较多时间才能提交I/O请求(0.457svs0.77s)。
3.在非directI/O的情况下内核态AIO与用户态AIO的比较:
速度而言:同步I/O快于内核态AIO快于用户态AIO。内核态AIO与用户态
AIO(0.34svs2.82s)时间差别比较大,相差7倍。
4.在非directI/O的情况下,内核态AIO与同步I/O的比较
内核态AIO要慢于同步I/O(0.19和0.34)。即使只比较I/O提交的时间的话也要慢于同步的I/O(0.323svs0.19s)。之所以出现这种情况,是因为2.6.9内核不支持非direct
I/O方式的异步I/O,这种情况下它的异步I/O走的流程与同步I/O是类似的,在读pagecache时会阻塞。由于在提交AIO请求的时候会阻塞,所以导致提交请求与同步地执行IO没有本质区别,异步的优势体现不出来。
读核感悟-健壮的代码-让问题代码尽早暴露
-
读书的感悟
读书的感悟益都师范附小杨梦一开始老师问同学订不订主题阅读订不订依我们本来我不想订因为订了我又没时间看热爱书籍吧书籍是知识的源泉只有…
-
读书感悟之感悟 作者
读书感悟之感悟作者血压150血压150明天是第十四个世界读书日前几天读人民日报上的有关于丹的一篇采访题目是读书就是滋养自己文章写的…
-
读书分享活动有感
读书分享活动有感用真心对待学生用耐心等待学生成长今天周三会议上小明在读书分享活动中给大家介绍拥有阳光心态决定人生成败的66个细节一…
-
书香满溢,分享读书感悟
书香满溢分享读书感悟打造书香校园引领每个教师成为一个阅读者成为一个思想者在中青年教师中形成好读书读好书与书为友的读书氛围是我校提出…
-
读书分享会后感
读书分享会后感阅读是快乐的阅读的魅力是无穷的无处不在的当我还在名人传记的十字路口徘徊时借着这样一个读书分享会让我更欣赏肯尼迪的辉煌…
-
读书感悟
第56号教室的奇迹读书心得一博学爱生是本质语文数学科学美术音乐门门功课雷夫老师都能把他上的游刃有余精彩纷呈并且深受学生喜爱单就这一…
-
13 快乐阅读——“感受书香”读书分享会
第13周快乐阅读感受书香读书分享会主题班会一活动目标通过活动了解古今中外的名人的读书事例使学生明白读书的重要意义教育学生明辨是非有…
-
分享阅读 感受快乐
分享阅读感受快乐摘要亲子共读目前已被广泛接受广大师生和家长都已经满怀激情地参与进来取得了可喜的成果本文从亲子共读的益处原则和方式谈…
-
读书分享活动有感
读书分享活动有感用真心对待学生用耐心等待学生成长今天周三会议上小明在读书分享活动中给大家介绍拥有阳光心态决定人生成败的66个细节一…
-
读书明志、感悟人生
读书明志感悟人生彷徨不前时读书是一种动力失败灰心时读书是父辈最有力的鼓舞疲惫不堪时读书是最优的休憩方式读书感悟人生生活才会更精彩书…
-
个人读书感悟
个人读书感悟大杨树四中刘志云时光荏苒一转眼的功夫我跨入教师这个职业已经12年了回顾这12年的工作真是忙碌而又充实的这段时间里我与学…