Oracle中查看已执行sql的执行计划
Oracle中查看已执行sql的执行计划
上一篇 / 下一篇 2008-09-12 10:54:07 / 个人分类:原创笔记
查看( 771 ) / 评论( 8 ) / 评分( 15 / 0 )
有时候我们可能会希望查看一条已经执行过的sql的执行计划,常用的方式有两种:a,set autotrace后再重新执行一遍,不过重新执行可能会浪费时间,而且有些语句也不允许(例如修改操作的语句),或者查询v$sql_plan视图,但v$视图的可读性又不是那么好,这里提供一个新方式,通过dbms_xplan.display_cursor来获取执行过的sql的执行计划。
首先看看该函数的语法:
DBMS_XPLAN.DISPLAY_CURSOR(
sql_id IN VARCHAR2 DEFAULT NULL,
child_number IN NUMBER DEFAULT NULL,
format IN VARCHAR2 DEFAULT 'TYPICAL');
由上可知,我们至少需要找到执行过sql的sql_id,该参数可以从v$sql视图中找到。
下面,举个例子吧,执行一个简单查询:
SQL> select count(0) from cat_product cp,cat_drug cd where cp.medical_id=cd.id;
COUNT(0)
----------
118908
如果我们想获取该语句的实际执行计划,通过下列步骤:
1、查询v$sql视图,找到该语句的sql_id(注意哟,必须要确保你要查询的sql语句还在shared pool): SQL> select sql_id from v$sql where sql_text=
2 'select count(0) from cat_product cp,cat_drug cd where cp.medical_id=cd.id';
SQL_ID
-------------
c9cxqvr3q4tjd
2、调用dbms_xplan包,查看该语句执行时的实现执行计划:
SQL> select * from table(dbms_xplan.display_cursor('c9cxqvr3q4tjd'));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID c9cxqvr3q4tjd, child number 0
-------------------------------------
select count(0) from cat_product cp,cat_drug cd where cp.medical_id=cd.id
Plan hash value: 2559475106
-----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | -----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | 750 (100)| |
| 1 | SORT AGGREGATE | | 1 | 50 | | | |
|* 2 | HASH JOIN | | 118K| 5804K| 4096K| 750 (1)| 00:00:11 | | 3 | INDEX FAST FULL SCAN| PK_CAT_DRUG | 112K| 2758K| | 186 (1)| 00:00:03 |
| 4 | INDEX FAST FULL SCAN| TU_CAT_PRODUCT_MED_CHECK
| 118K| 2902K| | 212 (1)| 00:00:03 |
-----------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("CP"."MEDICAL_ID"="CD"."ID")
事实上dbms_xplan.display_cursor也非常灵活,如果执行的统计信息也被收集的话,还可以显示出每一步实际的花费时间等信息,例如:
SQL> select /*+gather_plan_statistics*/ count(0) from cat_product cp,cat_drug cd where
cp.medical_id=cd.id;
COUNT(0)
----------
118908
SQL> select sql_id from v$sql where sql_text=
2 'select /*+gather_plan_statistics*/ count(0) from cat_product cp,cat_drug cd where
cp.medical_id=cd.id';
SQL_ID
-------------
91w1ug6vc9pxh
SQL> select * from table(dbms_xplan.display_cursor('91w1ug6vc9pxh',null,'all iostats last'));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 91w1ug6vc9pxh, child number 0
-------------------------------------
select /*+gather_plan_statistics*/ count(0) from cat_product cp,cat_drug cd where cp.medical_id=cd.id Plan hash value: 2559475106
-----------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes|E-Temp | Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 50 | | | | 1 |00:00:00.18 | 595 |
|* 2 | HASH JOIN | | 1 | 118K| 5804K| 4096K| 750 (1)| 00:00:11 | 118K|00:00:00.33 | 595 |
| 3 | INDEX FAST FULL SCAN| PK_CAT_DRUG | 1 | 112K| 2758K| | 186 (1)| 00:00:03 | 112K|00:00:00.01 | 278 |
| 4 | INDEX FAST FULL SCAN| TU_CAT_PRODUCT_MED_CHECK | 1
| 118K| 2902K| | 212 (1)| 00:00:03 | 118K|00:00:00.01 | 317 |
-----------------------------------------------------------------------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id): -------------------------------------------------------------
1 - SEL$1
3 - SEL$1 /CD@SEL$1
4 - SEL$1 /
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("CP"."MEDICAL_ID"="CD"."ID")
Column Projection Information (identified by operation id): -----------------------------------------------------------
1 - (#keys=0) COUNT(*)[22]
2 - (#keys=1)
3 - "CD"."ID"[CHARACTER,24]
4 - "CP"."MEDICAL_ID"[CHARACTER,24]
35 rows selected.
第二篇:oracle中查找执行效率低下的SQL
oracle中查找执行效率低下的SQL
v$sqltext:存储的是完整的SQL,SQL被分割
v$sqlarea:存储的SQL 和一些相关的信息,比如累计的执行次数,逻辑读,物理读等统计信息(统计)
v$sql:内存共享SQL区域中已经解析的SQL语句。(即时)
根据sid查找完整sql语句:
select sql_text from v$sqltext a where a.hash_value = (select sql_hash_value from v$session b where b.sid = '&sid' )
order by piece asc
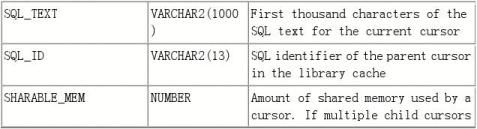
select a.CPU_TIME,--CPU时间 百万分之一(微秒)
a.OPTIMIZER_MODE,--优化方式
a.EXECUTIONS,--执行次数
a.DISK_READS,--读盘次数
a.SHARABLE_MEM,--占用shared pool的内存多少
a.BUFFER_GETS,--读取缓冲区的次数
a.COMMAND_TYPE,--命令类型(3:select,2:insert;6:update;7delete;47:pl/sql程序单元)
a.SQL_TEXT,--Sql语句
a.SHARABLE_MEM,
a.PERSISTENT_MEM,
a.RUNTIME_MEM,
a.PARSE_CALLS,
a.DISK_READS,
a.DIRECT_WRITES,
a.CONCURRENCY_WAIT_TIME,
a.USER_IO_WAIT_TIME
from SYS.V_$SQLAREA a
WHERE PARSING_SCHEMA_NAME = 'CHEA_FILL'--表空间
order by a.CPU_TIME desc
引用:/blog/700985
从V$SQLAREA中查询最占用资源的查询
select b.username username,a.disk_reads reads,
a.executions exec,a.disk_reads/decode(a.executions,0,1,a.executions) rds_exec_ratio,
a.sql_text Statement
from v$sqlarea a,dba_users b
where a.parsing_user_id=b.user_id
and a.disk_reads > 100000
order by a.disk_reads desc;
用buffer_gets列来替换disk_reads列可以得到占用最多内存的sql语句的相关信息。
v$sql:内存共享SQL区域中已经解析的SQL语句。(即时)
列出使用频率最高的5个查询:
select sql_text,executions
from (select sql_text,executions,
rank() over
(order by executions desc) exec_rank
from v$sql)
where exec_rank <=5;
消耗磁盘读取最多的sql top5:
select disk_reads,sql_text
from (select sql_text,disk_reads,
dense_rank() over
(order by disk_reads desc) disk_reads_rank
from v$sql)
where disk_reads_rank <=5;
找出需要大量缓冲读取(逻辑读)操作的查询:
select buffer_gets,sql_text
from (select sql_text,buffer_gets,
dense_rank() over
(order by buffer_gets desc) buffer_gets_rank
from v$sql)
where buffer_gets_rank<=5;

-
半小时看懂Oracle的执行计划
一什么是执行计划Anexplainplanisarepresentationoftheaccesspaththatistakenw…
-
Oracle如何分析执行计划
执行计划首先在分析的用户下执行rdbmsadminutlxplansql用sys用户登录sqlplusadminplustrace…
-
oracle执行计划
0SELECTSTATEMENT864200000011TABLEACCESSFULLDAVE86420000001统计信息0re…
-
Oracle执行计划 SQL语句执行效率问题查找与解决方法
Oracle的SQL语句执行效率问题查找与解决方法一识别占用资源较多的语句的方法4种方法1测试组和最终用户反馈的与反应缓慢有关的问…
-
Oracle执行计划详解
Oracle执行计划详解目录一相关的概念Rowid的概念RecursiveSql概念Predicate谓词DRivingTable…
-
Oracle SQL执行计划基线总结(SQL Plan Baseline)
OracleSQL执行计划基线总结(SQLPlanBaseline)一、基础概念Oracle11g开始,提供了一种新的固定执行计划…