农作物田间试验设计
田间试验设计
内容要点提示:
试验设计属于科学试验方法论的范畴,学习时①要注意将试验误差和前一章作为随机变量介绍的误差联系起来,进一步区分田间试验研究和抽样分析的不同点;②了解试验研究的程序和试验方案的内容,重点掌握试验误差的控制办法,特别是试验地土壤差异的控制技术;③要在充分认识随机区组设计和拉丁方设计的田间排列、优势及其缺陷的基础上,理解其它各种试验设计与它们的联系和区别;④对于正交设计,要熟悉正交表的类与型,熟练正交表的使用方法(因素上列,处理成行)以及由正交拉丁方构造部分正交表的原理。
第一节 试验概述
一、 试验研究的基本知识
1、试验研究在科研中的地位。
(1) 科学研究的基本过程。
科研活动是人类认识世界,能动地改造世界的过程,任何一个领域的科研活动都不可能一下子全部完结,但对一个具体的研究课题而言,都是一个有始有终的过程,这个过程对于自然科学来讲,大体上包括以下四个阶段:
调查研究 试验研究 解释或表达
 选题 假说形成 假说验证 科技写作
选题 假说形成 假说验证 科技写作
什么叫“假说”?
用已有的事实材料和科学原理为依据,对未知事物的猜测或假定性解释。
假说及其形成作为科研活动的阶段之一,标志着科研方法的进步和完善,其价值在于研究工作可以它为基点,把研究方向朝四面八方铺开,尽可能地将它应用于各种具体情况而引伸出许多预期结果,来和客观实际结果作比较,从而提出试验或观察方法,恩格斯在《自然辩证法》中有过这样一句名言:
“只要自然科学还在思维着,它的发展形式就是假说”。
哥伦布发现美州大陆就是为验证“地球是球体”这样一个假说而得到的意外发现。
狭义相对论的提出,就是迈克尔逊等人为验证,光的传播介质是“以太”这样一个假说而导出了洛仑兹变换,这一变换经爱因斯坦的头脑就成了新的发现线索。
所以科研工作就以“假说形成”为时间界限分为前后两个阶段。假说形成前是科研工作的准备阶段,其方法主要调查研究。假说形成后的阶段是试验或观测阶段,这一阶段主要是试验研究,因此,实践检验真理在科研工作中就表现为试验验证假说。
(2)什么叫试验研究?
在尽可能排除外界影响,突出主要因素,并能细腻地观察到各种现象之间相互关系的条件下,使某种过程重演,以观察未知事实,验证假说。
农业和生物学领域的试验研究方法有两类。
田间试验——
以差异对比法为基础,在田间自然条件下,突出试验因素,排除次要因素,以观察比较不同试验处理的反应和效果。
试验室或温室试验——
与田间试验相比,能够严格地控制一些在田间条件下难以控制的试验条件,如光照、温湿度、土壤环境等,因而有助于深入研究作物的生长发育规律。
2、试验研究与统计学
统计学最主要的应用领域有两个:工农业生产和社会经济领域。田间试验的适当的设计与统计分析,是统计方法在农业中应用的直接形式。由于农业试验周期长,环境因素变异大,如不对试验的设计安排作精心考虑,并使用有力的统计分析方法,则得不出什么有用的结论,所以试验设计及其统计分析的发展,始自农业和生物方面的应用。尤其是试验设计的基本思想和方法,最初都是从田间试验开始发展起来的。
如在Australia的一些较大的科研单位和试验站所进行的农业试验研究,大多较为庞杂,且耗时多年、试验设计与数据分析工作做得非常严肃、认真。程序是:
交计划任务 定研究方案

 课题主持人 生统局统计专家 工人或试验员
课题主持人 生统局统计专家 工人或试验员
报告分析结果 按时邮寄数据
这样严格的分工使研究人员集中精力从事自己的课题研究:熟悉自己研究范围内的基础知识及其更新和发展情况。统计学家则专门从事生物统计方面的学习和研究,并在各州农业厅设专门机构——生物统计局,订有世界各国出版的与生物统计有关的杂志,每年还派人参加世界性的生统会议,也常有外国专家和学者去他们那里讲课或交流经验。
我国统计学管理机构尚处于学会团体性质的阶段,如中国现场统计学会,定期开展学术活动,主办刊物《数理统计与管理》。
3、农业试验研究的一般程序
选题————→计划————→实施————→总结
(1)选定研究课题
① 当前生产提出的实际问题; ② 生产进一步发展需要解决的理论和技术问题;
③ 推广国内外先进经验; ④ 科学发展上需要解决的理论问题。
要求:第一,要深入生产实际,抓主要矛盾(找瓶颈);第二,要广泛搜集国内外有关资料。
(2)拟订试验计划
按统计学原理,设计和确定完成试验任务的方法和步骤。具体包括:
① 设计试验方案;② 确定试验设计种类;③ 制订管理措施;
④ 拟订观察项目、记载方法及标准。
要求:第一,符合试验任务要求的精确度;第二,照顾需要和可能,做到多、快、好、省。
(3)实施试验计划
也就获取试验数据的过程。
① 根据方案做好准备工作; ② 科学布置田间试验;
③ 有始有终地做好管理工作; ④ 完成计划规定的观察记载任务。
要求:贯彻单一差异原则,减少误差,杜绝差错。
(4)对试验数据进行统计分析,作出科学结论。
首先是对所有数据进行整理,发现错误设法更正,无法更正又证明确是错误的观察值应剔除,其次是对所有数据按统计学原理进行分析,找出规律并确定可靠程度,最后作出总结,写出试验研究报告,如果学术价值较高还须进一步撰写学术论文,这就是“科技写作”。
二、 试验方案
1、试验方案的内容:
试验方案指试验中进行比较的一组试验处理的总称。试验方案是全部试验工作的核心,它是围绕研究课题,根据试验的目的和要求制订的,其内容包括试验因素、试验水平、试验指标和试验处理。分别介绍如下:
试验因素——
在控制影响试验结果的其它条件的情况下,人为变动的一个或几个试验条件。如品比试验、密度试验中的品种、密度即是。
试验指标——
衡量试验因素效应的指示性状,如比较两个品种优劣的试验,试验指标就可以是产量或者是收获物中某一种经济性状。
试验指标对试验(处理)因素效应的定量表达就是试验数据。
试验水平——
试验因素从质或量的方面分成不同的等级,其中的每一个等级就是一个水平,如品比试验中的每一个品种就是从质的方面来策划分水平的,密度试验中的密度就是从量的方面来划分水平的。
试验处理——
如试验中仅一个因素,则该因素的每一个水平就是一个试验处理;如果试验中包括两个或两个以上的因素,则试验处理就是这些因素各个水平的组合,简称组合或水平组合。
例如有一特早熟扁豆栽培试验方案 ,A因素为追肥,分花前追肥与对照(不追肥)两个水平,B因素为品种,分红花一号,白花二号,C因素为密度,设四种株距(行距为1.5M)即45cm、70cm、95cm、120cm,重复2次,则水平组合数为2×2×4=16个。
2、因素效应及交互作用
简单效应(其平均值就是主效应):
试验因素的相对独立作用,即因素对性状的数量指标所起的增加减少的作用,简称主效。
以某水稻品种施肥量为例,若亩施N肥由10kg增至15kg时,产量由350kg增加到450kg,则效应就是施N肥单因素的不同水平引起的产量差异为+100kg,这就是简单效应。
交互作用(互作效应,简称互作)
上例中,假定在增施5kg的同时,再增施5kg复合肥,事先已知单纯增施5kg复合肥时,产量可望由350kg增加到400kg,现这两个措施同时采用后,其结果无非是下列三种情况之一:
①等于150kg:称两个因素无交互作用,称“零互作”。
②大于150kg,两个因素有类似正反馈的交互作用,称“正互作”。
③小于150kg:两个因素有类似负反馈的交互作用,称“负互作”。
3、确定试验方案的要点。
①抓主要矛盾,力求试验因素简单明确;
因素过多时先选一、两个关键性因素进行试验,然后再作比较复杂的试验,这样先简后繁,结论明确;或者先做预备试验,再做能完成多元统计分析的模式试验。
②同一因素各水平间的差别要拉开档次;
从量的方面划个水平时,等比级数比等差级数好(旋转组合设计二者兼顾)
③每个因素所设水平数要适当;
水平数太少了容易漏掉有用的信息,多了增加工作量。
④方案中要明确中心水平(处理);
中心水平即预计结果可能最优的水平,其余水平都是围绕该水平展开设置(如回归设计)。
⑤尽量排除非试验因素的限制,使其处于比较良好的状态,有助于因素效应的充分发挥;
⑥差异比较法必须建立在单一差异原则的基础上,以保证试验具有严密的可比性,这就要求:
第一, 试验因素以外的其它条件相对一致,谨防干扰;
第二, 试验处理中应设置作为比较标准的处理,也就是要有对照(CK)。
三、田间试验的种类和要求
按任务不同的划分为两类:
1、小区试验:即科研性试验,处理数目多,小区面积小,准确度要求较高,研究多因素最好的水平组合。
2、生产试验:即示范性试验,处理数少,小区面积大,准确度要求很高,验证小区试验结果的推广价值。
按试验因素的多少,分为三类:
1、单因素试验:只研究一个因素效应的试验。
优点:设计简单明了,结果很直观;
缺点:影响试验指标的因素很多时,结果有片面性。
2、复因素试验:研究两个或两个以上因素效应的试验,其特点是说明问题较全面,可以研究各因素的主效应,也可以研究因素间的协同效应(或互作),试验效率比单因素试验高。
3、综合试验:研究一定条件下各因素最优(或较优)组合的综合效应,并比较其实用价值的试验。
特点是大多属生产试验,确定规范化栽培模式。
田间试验的要求有三个:
1、试验条件的代表性(典型性)
指试验条件应能代表拟推广试验结果的地区的自然条件和农业条件,既要有先进性,又要有实用性。
2、试验数据的可靠性(正确性)
包括数据的准确度和精确度两个方面,准确度指观察值Y与其相应真值μ接近的程度,指标是σ? / ? (%),其值越小,准确度越大。
但由于一般试验中,真值μ为未知数,只能根据的样本标准误算得另一个指标,即S? / ?(%),
这就是精确度,它反映观察值彼此接近的程度。
3、试验结果的重演性(规律性)
指在相同或相似条件下,再重复做类似试验时,应该能获得相同或相似的结果。
由于田间试验的自然条件难以人为控制,即使重复同一试验,试验结果也会因为不同地区或不同年份而有出入,完全相同不可能,但类似是完全应该的。
第二节 试验设计原理
一、试验误差的分类
由于试验因素既有主效应,又有互作效应,因此,同一试验中各试验处理因其所含水平(组合)不同而出现不同的效应值,这种反映各试验处理真实效应的数值叫处理真值。
而对于田间试验来讲,试验数据的各观察值由于受到许多非试验因素的干扰和影响,即包含了处理真值,又包含了使之偏离处理真值的试验因素效应,就叫做试验误差,也简称误差。
按性质的不同,试验误差分两类。
1、系统误差(片面误差)
试验因素以外的其它条件明显不一致所产生的误差,其特点是:
①干扰因素始终朝一个方向影响试验结果,使观察值总是比处理真值偏大(或偏小),直接影响试验结果的准确度σ? / ? (%);
② 可人为控制,即通过合理的试验设计消除掉(如设保护行或计产面积消除边际效应), 使之不带进数据内,或者虽带进数据中(区组效应,如田间试验中的土壤肥力梯度——趋向性差异或试验材料的顺序差异),但可以和试验因素效应一样能定量分析出来,故又可称之为系统因素效应。
以两因素各二水平的RCBD实例展开讲……………………

Ⅰ Ⅱ Ⅲ Ⅳ
 肥力梯度
肥力梯度
 可控因素 系统因素
可控因素 系统因素
试验因素
边际效应是指靠试验边缘生长的作物因占据较大的生长空间,其生长势或产量与行中作物出现较大的差异,有的产量相差可达到一倍以上。
2、偶然误差(随机误差)
在严格控制试验条件相对一致后,仍不能消除的偶发性误差,简称机误,其特点是:
①干扰因素使观察值大于处理真值或小于处理真值的机会均等,即误差的符号可正可负,其取值是一个服从正态分布的随机变量,即可以定量估计y-μ任一取值范围的概率(如果μ、σ已知的话),直接影响的是试验结果的精确度S? / ?(%);
②不管怎样控制条件,这种误差均为只能减小而不可能彻底消除。
一个成功的试验设计一方面要降低偶然误差,另一方面又要消除系统误差(如边际效应),或者使之能够明确、定量地分析出来,转化成区组效应,所以实际研究中所讲的“试验误差”仅剩下偶然误差(因此,又称其为剩余误差),而把系统误差纳入到可控因素效应中去了。即:

 试验误差 系统误差 系统因素效应 ——→转化成区组效应 (可控因素效应)
试验误差 系统误差 系统因素效应 ——→转化成区组效应 (可控因素效应)
边际效应——→设保护行或计产面积消除掉
偶然误差 ————→“剩余误差”
以实习指导中特早熟扁豆栽培试验的田间布置为例:

Ⅰ (前作为蔬菜) Ⅱ(前作为苗木)
这样一来,准确度和精确度就成了一回事,对试验误差的研究也就单纯指对偶然误差的概率分布进行研究了,并且和第二章所讲的关于随机变量的误差统一起来。只是对试验误差的概率分布研究不象第二章那样能够在总体参数已知条件下进行,而只能以数据的特征数?、S代替μ、σ来进行,即相当于以样本(一份或一组试验数据)去推断总体结果,比抽样研究复杂得多。
二、试验设计三原则
试验设计有广义、狭义之分
广义的试验设计是指实施整个试验计划的方法,包括方案的确定,试验地、试验材料的选择,小区排列技术,数据的搜集整理和统计分析方法等等,它针对的是整个研究课题,如本章标题就要广义地理解。
狭义的试验设计仅指实施试验方案的方法、即各重复区和试验小区的田间排列方法、针对的只是小区排列技术。如本节的标题就要狭义地理解。
1、重复
试验中同一处理种植的小区数即重复次数。如每一处理只种一个小区,叫一次重复;种2个小区,叫两次重复,依次类推。其作用有二:
第一,估计试验误差(抽样误差)
试验任一个处理的小区观察值都是一个随机变量的取值,其真值μ和σ是未知数(或者说是待研究的),如果只有一个观察值y,不仅无法估计y-μ的绝对数。就是y-μ取值范围的概率分布也无法计算,但如果有了重复观多值,虽然抽样误差?-μ的绝对数还是无法计算,但?-μ取值范围的概率分布却可以计算出来,这是因为σ值虽然未知,但各处理样本标准差S可以算出,用它代替σ计算就可以把?-μ转化为标准化随机变量t ,从而运用t分布计算任一取值区间的概率。概括地讲,重复是估计抽样误差?-μ的必要条件。
由于田间试验是以不同处理间的差异比较为基础,用任意两个处理的样本标准差代替总体标准差算得差数的样本标准误,就可以将差数的抽样误差转换为标准化变量t来进行研究与分析。
第二、降低试验误差(偶然误差)
同名小区由于分散在试验地的不同位置,占据不同的试验材料和外界条件,因此,对于各试验小区之间出现的偶然误差就可以通过计算同名小区观察值的平均数?相互抵消一部分,且重复次数越多,误差正负相抵的机会也就越多。从数量上讲,因为抽样误差?-μ的变异幅度S? 与重复次数n的平方根成反比(教材称“误差的大小与重复次数的平方根成反比”容易误导!应改为“概率尺(或标准误)的大小与重复次数的平方根成反比”, (抽样)误差是随机变量, 只能描述其概率分布,而不能用表述常量的方式来对待它!),所以,重复次数n越多,算术平均数?的精确度S? / ?(%)越高(数值越小!)。
2、随机排列
重复只是估计试验误差的必要条件,还要加上随机排列才够得上充分,因为要使估计的各处理平均数?的误差没有偏性的话,试验中的每一个处理都必须有同等的机会被安排在任意一个试验小区内,即随机排列是估计抽样误差?-μ的充分条件。
随机不仅仅是一种要求,更是一种信仰。
由于试验的每一个处理均有相同的重复次数,故随机的方法就是在每一个重复区所含的试验小区上随机排列各试验处理,方法可以抽签,按计算器或使用随机数字表。
3、局部控制。
单用重复也不是降低试验误差(系统误差)的充分条件,还必须实施局部控制,即分范围、分地段控制非试验因素,使之对重复区内各试验处理的影响趋于最大限度的一致。
即重复只是降低试验误差(转化系统误差)的必要条件,局部控制是降低试验误差(转化系统误差)的充分条件。
按大范围的差异将试验地(或试验材料)划分成不同的等级叫做区组,一个区组安排一个重复,各区组内的试验小区再安排各处理,也就成了重复区组。
由于区组比试验区小得多,只是其重复次数n的1/n倍,试验地或试验材料等条件容易一致,故同一区组所有处理间的差异符合单一差异原则,而不同区组间的差异则可利用统计分析方法从数据中定量分析出来,排除了系统误差对数据的影响,因此大幅度地控制土壤差异或试验材料差异往往靠局部控制。
实施局部控制后能影响试验数据的就只有区组内的偶然误差了,与因增加重复而扩大试验规模(如增加试验地或试验材料)可能导致的系统因素效应无关。
综合重复、随机排列、局部控制三者的关系,图示如下:


 重复
重复




随机排列 局部控制



估计抽样误差 转化系统误差
降低偶然误差 只剩偶然误差
第三节 经典试验设计
一、完全随机设计
1、小区排列方法
试验的每一个处理(包括同名处理)安排在整个试验地各试验小区的机会均等。
例如要检验三种剂量的生长素对小麦苗高的效果,包括对照(用水)在内,共4个处理,若用盆栽试验每盆小麦为一个单元(即试验小区),每处理重复4次,要16个盆
① 将全部16个盆拟出一个摆放顺序,臂如将其排成两行,编号为:
1 2 3 4 5 6 7 8
16 15 14 13 12 11 10 9
② 使用随机数字表(附表1)将16个编号查出一个随机顺序,例如:
14、13、9、8;12、11、6、5;2、7、1,15;3、4、10、6
③ 再将A、B、C、D四个处理依上述连续的4个随机数字安排列各个盆栽小区,得:
1C 2C 3D 4D 5B 6B 7C 8A
16D 15C 14A 13A 12B 11B 10D 9A
2、优势与缺陷:
⑴处理数、重复数可以极其灵活(弹性大),尤其重复次数各处理可以不相同,便于充分列用试验材料,如上述16个盆安排3个处理或5个处理也可以,分别设5、5、6次重复或3、3、3、3、4次重复就是了;
⑵统计分析很简单,即使缺区也不受影响;
⑶试验误差自由度大,有利于估计处理效应显着性;
⑷未实施局部控制,不能分析区组效应,只能应用于试验环境相当一致,试验条件可人为控制的温室、网室实验室的盆钵试验,田间试验一般不能应用。
配对数据差数相当于没有重复的完全随机设计试验结果,故不能做AOV。
产生于19世纪80年代的半条式对比法,属于安排仅一个处理和一个对照相比较试验方案,重复10-20次,排列狭长小区(相邻的土肥条件最相似)的方式:AB BA AB BA……同上一章介绍的配对(试验材料和试验小区各一个实例)设计基于同样的原理,具有分析精度高,统计方法和完全随机设计一样简单,但设计原理又和随机区组法相似。
二、随机区组设计
1、田间小区排列
每个区组安排一个重复,同一重复的所有处理(含CK)在一个区组内必须出现而且仅仅出现一次,各处理在同一区组内的排列绝对随机。
如一8品种,4个重复的随机区组法排列如下(小区排列示意图不是田间种植图!):

Ⅰ Ⅱ Ⅲ Ⅳ
肥力梯度
注:区组集中排列时,同名小区尽可能不在一条横线上,本例只有品种1在第二行小区位于一条线,随机排列数果尚好。还有就是小区长边与肥力梯度线平行。
2、特点:
能将试验地或试验材料之任意一个方向的差异引起的系统因素效应转化为区组效应(谓之与区组效应混杂),再通过ANOVA从数据中定量分析出来,这就是单向控制作用。
3、优势:
①弹性(伸缩性)大,处理数、重复数不受严格限制,单因素、复因素试验、综合试验都可采用;
②对试验地(材料)只要求区组内一致,不同区组也可以分散排列,甚至多地点排列或分年度进行,试验安排灵活性大;
③试验结果的准确度高 ,主要是单向控制作用带来的效果 ,其次是重复次数根据需要设置,使 S? / ?(%) 符合精度要求;
④统计分析不复杂。
4、缺陷
当有局部控制效果的区组不能容纳一个重复的全部处理时,就只好改用不完全区组设计。
因同一重复的所有处理必须排列在一起,故安排试验时,设置处理数目仍受到区组大小(容量)的限制 ,一般为3—15个。
三、 拉丁方设计
1、田间小区排列:
将一个重复的所有处理(含CK)从两个方向排列成区组,各处理在横行区组和直行区组内都必须出现而且仅出现一次,所有处理在横、直行区组内都随机排列,方法是:
①选择标准方:统计上将第一横行,第一直行(列)的字母都按拉丁字母顺序排列的拉丁方。
教材列出4×4至8×8共5种阶数的标准方,供选用(n = k);
②列随机:按顺序编排的列号使用随机数字表进行随机排序;
③行随机:在列随机的基础上,对整行(横行)进行随机排序;
④处理随机:将处理编号随机排序后依次代换拉丁字母。
以n = k = 5所用5×5拉丁方为例,排列过程及其结果(也不等于田间种植图!)如下:
1 2 3 4 5 1 4 5 3 2

 1、2、3、4、5 D、A、E、C、B
1、2、3、4、5 D、A、E、C、B
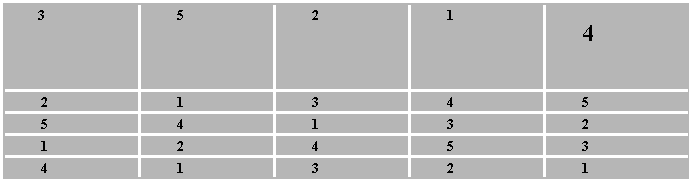
 2、特点:
2、特点:
把两个方向的试验地顺序差异转化为两个区组效应,再借助ANOVA从数据中分析出来,这就是双向控制作用。
3、优势:
可分析出两个方向的系统误差,比随机区组设计还多一个方向的局部控制,因此 ,试验具有较高的精确度。
4、缺陷:
①缺乏灵活性 ,因为各区组必须集中排列,不能分散,所以,要求选整块平坦的试验地,但并不要求试验地为正方形,恰恰因为小区长方形居多而要求长方形试验地;
②区组之间界线不能象随机区组法那样设走道,中部试验小区不容易接近,观察记载都不方便;
③缺乏弹性(伸缩性),即处理次数与重复次数必须相等。处理数增加,试验规模不必要的硬性扩大,因此,一般只适宜于处理数为5——8个的试验方案,少于5个,用单个拉丁方试验嫌误差自由度dfe太小,以4×4为例;
用于4个处理的试验方案,dfe =15-3-3-3 = 6<10或12,试验结果有可能因为dfe较小时,需要的F0.05偏大使得处理效应本来应该有的显著性测验不出来。
只有采用两个4×4标准方分别进行随机排列后再随机代换同一组处理编号1、2、3、4(内容相同),之后再进行田间布置,就可以既保留双向控制的优势,又增加了误差自由度,这就是复拉丁方设计,此时: dfe =(32-2)-(8-2)-(8-2)-(4-1)= 15
1 2 3 4 2 4 1 3

1 2 3 4 1 3 2 4

四、裂区设计
1、田间小区排列
必定用于复因素试验,先将重复区按第一个因素分设的各个水平(主水平)划分小区,叫主区(main plot)或整区。
再按第二个因素分设的各个水平(副水平),把主区划分成更小的小区,叫副区(sub plot)或称裂区。
重复区内各主水平(亦称主处理)的排列及主区内各副水平(亦称副处理)的排列都是随机进行的,对第二个因素而言,主区就是一个区组,但从试验的所有水平组合来看,主区仅是一个不完全区组。所以,裂区设计被教材归为不完全区组设计类型。
但决不是说裂区设计只能用于两因素试验,三因素试验就一定要用再裂区设计,以前述特早熟扁豆栽培的三因素试验2×2×4方案为例,用2×8式裂区设计方案照样可以实施(图示稍后)。
其中,追肥A1、A2被视为主处理,品种B与密度C两因素的8个水平组合B1C1、B1C2、B1C3、B1C4、B2C1、B2C2、B2C3、B2C4被视为副处理,依次编号为1、2、3、4、5、6、7、8。

2、特点:
由于副区之间比主区之间更为接近,占据的试验条件为一级,加之副处理的重复次数是主处理的若干倍(倍数即主水平数),因此,副水平之间的差异比较比主水平之间的差异比较更为精确,特别适宜于下列几种情况不下采用:
①、一个因素的各个水平比另一个因素各个水平需要更大的面积时将要求面积大者作为主水平,如施肥、灌溉、耕作方式等;
②、一个因素的主效应比另一个因素的主效应更为重要,要求精度高时,或者两因素的交互作用研究比其主效更为重要时,将精度要求高的因素安排成副水平;
③、根据以往研究,知某因素的效应比另一些因素效应更大时,将可能表现更大差异的因素安排成主水平。
鉴于此,裂区设计的主副水平的田间排列往往不局限于随机区组法,尤其是主水平数超过4个时(象7×2 、7×3式;6×2、6×3式、5×2、5×3式等),采用拉丁方排列更能提高其精确度。
如施肥量与品种二因素重复3次的3×6式裂区设计,主处理就可排列成拉丁方。

Ⅰ Ⅱ Ⅲ
3、优势:
只要两因素的效应不是同等重要,要求的精确度不是一样高的话,裂区设计比随机区组设计(就同一试验方案而言)的试验规模要小得多。
如有一柑桔的灌溉与修剪二因素试验,定3次重复,灌溉为第一个因素分a1、a 2、a 3三个主水平,需要主区面积至少为4株树;修剪为第二因素,分B1、B2、B3、B44个副水平,需要副区面积为1株树。
若采用随机区组法设计,因受灌溉因素的限制,试验小区面积必须定为4株树,所有3×4=12个处理(水平组合)各安排一次就需48株树,重复3次,试验规模48×3=144株树。
而采用裂区设计,所有12个水平组合(仅12株树)重复3次,试验规模12×3=36株树。
两相比较,裂区设计的规模仅为前者的1/4,即副水平数的倒数倍。
4、缺陷:
统计分析方法比随机区组法和拉丁方设计都要复杂(尤其是三因素以上的再裂区设计更麻烦)只适宜安排两个或三个因素的试验。
第四节 正交试验设计
一、正交试验产生的必然性
多因素多验随着因素数及其水平数的增加,处理数(水平组合数)呈几何级数的规律增加,例如:

这里所列还只是一个重复的处理数目,采用经典试验设计实施局部控制将遇到空前的困难,因为成百上千乃至成千上万的处理数目,全部付诸实施的话,试验规模实在太大了。
唯一可行的办法是从众多的水平组合中挑选一部分组合来进行试验,这就是部分重复试验。被选来做试验(即部分实施)的那一部分水平组合叫不完全组合。
第四章第一节讲到的综合试验的各个处理也只是方案中的一部分组合,但这部分组合是根据以往小区试验得出的预计试验结果较优的组合,其目的是进行示范,即检验小区试验结果大面积推广的可行性。
而通常的多因素小区试验主要带科研性质,事先并没有多少附加知识,对各因素的主效应及其互作情况并不了解,所以,不完全组合的挑选就只有借助于正交表来进行。
于是,我们将“正交试验”界定为:采用一种由数学领域的组合理论推导而成的正交阵列表来安排的部分重复试验(即挑选不完全组合),并进而对其部分实施的试验结果进行统计分析的一种多因素试验方法。
可见,正交试验的产生不是偶然的,它是经典试验设计发展到一定阶段后的必然产物 ,从随机区组法到拉丁方试验就已经孕育着正交试验的思想,再进一步发展成为正交试验自然是水到渠成的事情。
教材对“正交试验”提法不很明确,笼统地称之为“部分重复试验”,以强调它和完全实施的混杂设计或部分混杂设计的联系,由于是从挑选组合开始,正交试验设计应从广义的角度来理解,不妨称“不完全重复设计”。
二、正交表
1、正交拉丁方
将两个同阶拉丁方重叠起来后,如果其中一个拉丁方的每一个字母与另一个拉丁方的各个字母必相遇一次,而且只相遇一次,则称如此重叠起来的两个拉丁方互为正交拉丁方。
如果3个或3个以上的同阶拉丁方重叠起来后,任意两个拉丁方均互为正交关系,则称它们为“两两正交”。
现已知道,k×k阶拉丁方(k≠6,k≥3)最多可以有k-1个两两正交的拉丁方(公理!),由这样的k-1个两两正交的拉丁方重叠起来就构成正交拉丁方完全系(OLSCS)。
下面写出3×3、4×4、5×5的OLSCS:
k-1=2 k-1=3 k-1= 4

2、正交表的构造和性质
用OLSCS可构造出通式为L m2 (m m+1) 的正交表,如由3×3的OLSCS经过适当变换就可以得到正交表L 32 (m 3+1) 即L9(34),其构造过程如下:

L m2 (m m+1) 型正交表——L9(34)的构造过程
所得正交表记为L9(34),其中L为正交表的代号,源自Latin square的第一个字母,9为正交表的行数,一般用k表示,4为正交表的列数,一般不j表示,3指正交表各列水平数,一般用m表示,所以正交的通式为L k ( mj ),由OLSCS构造的L m2 (m m+1) 只是其中的一部分。
类似地,我们可根据m =2、4、5、7、8的各阶OLSCS构造出相应的正交表(见教材附表13P380):
L4(23)、L16(45)、L25(56)、L49(78)、L64(89)
但没有m=6的相同水平正交表,因为其OLSCS不存在!
正交表所具备的两个性质被称为“正交性”:
第一, 任意一列各水平出现次数相等;
第二, 任意一列的每一水平与其它任何一列的各水平相遇在同一行(水平组合)中的次数相等。
按照正交表的这个特点,我们用它挑选的“不完全组合”,可以保证任意两因素的水平对子出现在同一水平组合(处理)中的次数相等,所以,也就叫做正交组合,其包含的处理数目就是挑选组合所用正交表的行数k。
三、正交表的种类:
1、相同水平的正交表:
以上由OLSCS是构造的正交表是L k ( mj ) 型中的一部分。
另有一些相同水平的正交表如L8(27)、L16(215)、L27(313)、L64(421) 等,其构造必须用组合数学中的有限域理论来定义水平运算规则后进行,该理论用于构造所有L k ( mj )型正交表只要求m为素数或素数幂,其通式不能写为L m2 (m m+1),而只能以L k ( mj )来表示。
2、混合水平的正交表。
由相同水平的正交表经过由水平对换取新的水平编号所得, 其通式为L m2 (mj1×mj2)等等。
以L8(27)——→L 8(41×24)为例:
 1——1、1——2、2——1、2——2 1、2、3、4
1——1、1——2、2——1、2——2 1、2、3、4

四、正交表的表头设计
指按试验预期的目的和要求确定各试验因素安排到正交表中的列位,从而决定正交组合内容的过程(属于构造不完全组合),也叫因素上列。
以L8(27)的部分表头设计方案为例,用该表安排四因素试验的话,可以有两种典型的表头设计方案,即按A、B、C、D的顺序把它们依次安排到1、2、4、7列或1、2、4、6列,这样得到两种不完全组合的构造方案,内容虽不完全一样,但都是正交组合。只是前者有利于分析A、B、C、D四个因素的主效应(表头中主效应列名没有被混杂),后者有利于分析A因素的主效应和有A因素参与的三个一级互作效应(表头中A、A×B、A×C、A×D效应列名没有被混杂)。

这种因表头设计不同,对试验结果进行分析时侧重点不一样的现象是由正交表的结构决定的。因此,有关文献在提供正交表的同时,一般都附有相应的表头设计方案表或者是表头设计说明,供正交试验设计时使用。
表头设计的三种情形:
⑴完全混杂 如以L8(27)安排5个因素(或者更多)时,每一列都至少有两个以上的列名,这就意味着分析试验结果时按正交表算出的各列效应值SS都是几个效应混杂在一块,“看不清”某一个主效应或一级互作效应究竟有多大。优点是试验效率高,本例部分实施程度为:8÷25=1/4,能用有限的试验规模考察尽可能多的试验因素,从正交组合中优选出虽不一定是最优但却是较优的组合(“矮个子里头选将军”)。
⑵不允许混杂 如用L16(215)安排5 因素试验,每一列就只有一个列名,或者是主效应,或者是一级互作效应;意味着分析试验结果时按正交表算出的各列效应值SS都没有被混杂,有利于深入分析各因素间的相互关系,包括各因素的主效应和因素间的一级互作,并很容易找到或者是预测最优的水平组合。缺点是试验效率低,本例部分实施程度仅为16÷25=1/2。
⑶部分混杂 此为传统的正交试验法所采用的表头设计,前面介绍“表头设计”这一术语时以L8(27)安排四因素的两种上列方法就属于这种情况。其特点是既可有限度的提高试验效率,又可部分地分析各因素的主效应或者是因素间的一级互作,有较大希望获得或者预测最优组合。
五、正交设计的田间排列
表头设计只是完成从多因素试验方案中挑选正交组合的任务,田间实施时还要设置重复并进行随机排列,一般的作法是将正交组合视为单因素的不同处理实施局部控制,即按随机区组法落实田间布置。如果将正交组合全部纳入实施局部控制的范围有困难的话,可考虑继续用正交表进行混杂或部分混杂设计。
如果不愿设重复而倾向于多安排组合做试验的话,则可考虑继续用正交表进行旋转组合设计。
第四章内容小结
第一,以试验研究在科研中的地位——验证假说为出发点,介绍了农业及生物领域试验研究的基本知识;
第二,试验数据虽然是处理真值的反映,但因为受自然条件的制约,误差不可避免。而试验误差能不能视为服从常态分布(包括正态分布及t分布等)的随机变量来进行研究,关键在于试验研究方法是否符合试验设计原理;
第三,由于试验条件的特殊性,农业及生物类试验研究过程中试验误差必须结合其产生来源实施控制,但从统计角度讲,可归纳为重复、随机排列、局部控制;
第四,在所介绍的四种经典试验设计类型中,完全随机设计虽只限于温室或试验室应用,但其试验数据可作为最简单的方差分析模型,由此衍生出其它各种试验设计种类的数据整理和ANOVA方法;
第五,随机区组设计是试验设计方法的重大进步,裂区设计也还是随机区组或拉丁方设计的某种“综合”。即由随机区组法发展到拉丁方设计已经意味着新的突破,因为拉丁方蕴含着正交试验设计的思想;
第六,正交设计的高明之处就在于它摆脱了经典试验设计只在小区排列上做文章的做法,而是把眼光放到试验方案付诸实施之前如何挑选正交组合上,因此,正交试验设计的含义必须从广义的试验设计角度去理解;
第七,正交设计的最大优势是能够在对众多的因素效应没有任何附加知识的情况下提供一个筛选较优水平组合并搜索最优组合的捷径,所以正交试验曾一度被普及成为“优选法”。对探索性的小区试验来讲,往往能获得事半功倍的效果;
第八,正交设计使用正交表的决窍就在表头设计上,因素上列的方法不同,不光是所得正交组合内容不同,还会牵涉到数据分析时哪些效应能明确考察,哪些效应不明确(即被混杂);
第九,决不是只有正交试验才使用正交表,《正交表在经典试验统计中的功用》和旋转组合设计中使用正交表一样,同样值得重视。
-
田间试验计划书
田间试验与统计分析课程试验计划书品种种植密度两因素对棉花产量的影响田间试验计划书姓名林廷烜学号0801020xx年级专业08级农村…
-
玉米田间试验计划书
玉米田间试验计划书一试验时间和地点1试验时间20xx年5月20xx年10月2试验地点福建农林大学作物科学学院试验田二试验示范目的探…
-
马铃薯田间试验计划书
马铃薯田间试验计划书农业与食品科学学院园艺103班王亚锋一试验名称马铃薯3414肥效田间试验二试验目的及其依据肥料是作物的粮食有收…
-
农业试验计划书的制定
第三章田间试验的实施31试验计划书的制定方法一确定试验课题进行农业科学试验首先要选择试验课题试验课题确定得是否恰当决定着试验的成果…
-
田间试验计划书_周以帖
一物候期1播种期播种的日期以月日表示下同2出苗期50以上出苗的日期3分蘖期50以上植株第一叶腋出现分蘖的日期4拔节期50以上植株主…
-
农业试验计划书的制定
第三章田间试验的实施31试验计划书的制定方法一确定试验课题进行农业科学试验首先要选择试验课题试验课题确定得是否恰当决定着试验的成果…
-
玉米田间试验计划书
玉米田间试验计划书一试验时间和地点1试验时间20xx年5月20xx年10月2试验地点福建农林大学作物科学学院试验田二试验示范目的探…
-
田间试验计划书
田间试验与统计分析课程试验计划书品种种植密度两因素对棉花产量的影响田间试验计划书姓名林廷烜学号0801020xx年级专业08级农村…
-
试验方案与试验计划书
第三章试验方案与试验计划书知识目标学会田间试验方案的制订方法掌握田间试验计划书的书写格式技能目标学会制订田间试验方案的技能学会制订…
-
试验方案与试验计划书的制定方法
第三章试验方案与试验计划书知识目标学会田间试验方案的制订方法掌握田间试验计划书的书写格式技能目标学会制订田间试验方案的技能学会制订…
-
肥料试验报告格式
肥料试验报告格式页面设置页边距左右30上下25文字行距28磅表格行距16磅封页肥肥效鉴定田间试验报告字体隶书字号小初试验承担人试验…