人工智能读书及实验报告
人工智能导论
--读书及实验报告
计算机 XX
目录:
一、 读书报告……………………………………………………………………2.
二、 实验一………………………………………………………………………15.
1. 实验题目……………………………………………………………..15.
2. 问题分析和实验原理……………………….………………...15.
3. 程序设计和流程图………………………………………………17
4. 程序运行结果………………………………………………………19.
三、 实验二……………………………………………………………………...20.
1.实验题目………………………………………………………………..20.
2.问题分析和实验原理…………………………………………….20.
3.程序设计和流程图…………………………………………..……22.
4.程序运行结果…………………………………………..……………31.
四、 实验总结…………………………………………………………………..32.
一、读书报告
人工智能与神经网络读书报告
摘要:人工智能与神经网络技术在近二十年中飞速发展,取得了大量成果,本文介绍了神经网络的发展现状,并对神经网络的的未来发展进行了展望。
关键词:人工智能 神经网络
Abstract:The Artificial Intelligence and the neural network technique has gained high recognition in recent twenty years, and has acquired abundant accomplishment. This paper has made a prospect to the neural network’s future development based on viewing the state of development of neural network.
Keywords: Artificial Intelligence neural network
一、引言
神经网络[1](Neural Network:NN)是由具有适应性的简单单元组成的广泛并行互连的网络,也称为人工神经元网络、人工神经网络(ANN)、人工神经系统(ANS)、自适应系统(Adaptive System)、连接模型(Connectionism)、神经计算机(Neurocomputer)等。人工神经网络是生物神经网络的一种模拟和近似,它从结构、实现机理和功能上模拟生物神经网络。从系统观点看,人工神经元网络是由大量神经元通过极其丰富和完善的连接而构成的自适应非线性动态系统。
本文结构如下:首先介绍了神经网络技术的发展史;其次具体介绍了神经网络技术;最后对神经网络技术的发展进行了展望。
二、神经网络技术发展史[1]
神经网络最早的研究是1943年心理学家McCulloch和数学家Pitts合作提出的,他们提出的MP模型拉开了神经网络研究的序幕。神经网络的发展大致经历了三个发展阶段:1946-1969为初期,在此期间的主要工作包括Hebb(1949)《The Organization of Behavior》一书中提出的Hebb学习规则,他的基本思想是:大脑在器官接受不同的任务刺激时,大脑的突触在不断的进行变化,这些不停的变化导致了大脑的自组织形成细胞集合,循环的神经冲动会自我强化。Hebb在文中给出了突出调节模型,描述了分布记忆,即后来的关联论(connectionist);这个阶段另一个重要的工作为Rosenblatt基于MP模型,增加了学习机制,推广了MP模型研制了感知机。Rosenblatt感知机器的工作激发了许多的学者对神经网络研究的极大兴趣,美国上百家有影响的实验室纷纷投入到这个领域。1969年Minsky和Papert指出感知机的缺陷并表示出对该方法研究的悲观态度,同时由于专家系统方法展示出的强大活力,使得神经网络在很长时间内处于一个发展的低潮。第二阶段即为1970-1986期间的发展低潮阶段,在此期间科学家们做出了大量的工作,如Hopfield对网络引入能量函数的概念,给出了网络的稳定性判据,提出了用于联想记忆和优化计算的途径。1981-1984年Kohonen提出自组织映射网络模型。1986年Rumelhart等人提出误差反向传播神经网络,简称BP网络。目前BP网络已经得到广泛应用。1987年至今为发展期,在此期间,神经网络得到了国际重视,许多国家都展开研究,形成神经网络发展的另一个高潮。
三、神经网络技术
人工神经网络的定义[2]不是统一的,T.Koholen对人工神经网络的定义:“人工神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。”
人工神经网络(articles neural network,ANN)结构和工作机理基本上以人脑的组织结构(大脑神经元网络)和活动规律为背景的,它反映了人脑的某些基本特征,但并不是要对人脑部分的真实再现,可以说它是某种抽象、简化或模仿。
神经网络具有如下的特点:
(1) 由于信息分散存储于网络内的神经元中,因而神经网络具有很强的鲁棒性和容错性;
(2) 并行处理能力,人工神经元在结构上是并行的,从而使得相似问题的处理可以同时进行,具有快速的特点;
(3) 自学习、自组织、自适应性;
(4) 可以逼近任意复杂的非线性系统,同时可以处理定性与定量信息,适用于处理非线性和不确定性问题。上述特点使得神经网络具有很广泛的适用范围,主要包括图象处理、模式识别、机器人控制、信号处理、经济分析、数据挖掘、医学、农业、电力系统、交通、地理、气象等诸多领域。
1、人工神经元模型[3]
神经元是大脑处理信息的基本单元,人脑大约由1011个神经元组成,神经元互相连接成神经网络。神经元以细胞体为主体,由许多向周围延伸的不规则树枝状纤维构成的神经细胞,其形状很像一棵枯树的枝干。主要由细胞体、树突、轴突和突触(Synapse,又称神经键)组成 。
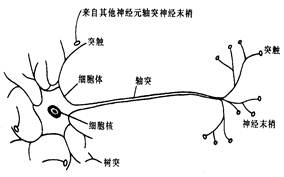
图1 生物神经元的示意图
生物神经元传递信息的过程为多输入、单输出,神经元各组成部分的功能来看,信息的处理与传递主要发生在突触附近,当神经元细胞体通过轴突传到突触前膜的脉冲幅度达到一定强度,即超过其阈值电位后,突触前膜将向突触间隙释放神经传递的化学物质,突触有两种类型,兴奋性突触和抑制性突触。前者产生正突触后电位,后者产生负突触后电位。
人工神经元是神经网络的基本处理单元。它是对生物神经元的简化和模拟。图2给出了一种简化的神经元结构。

图2 简化的神经元结构
从图中可见,它是一个多输入、单输出的非线性元件,其输入/输出关系可描述为
 (1-1)
(1-1)
其中 是从其它细胞传来的输入信号,
是从其它细胞传来的输入信号, 为阈值,权系数
为阈值,权系数 表示连接的强度,说明突触的负载。
表示连接的强度,说明突触的负载。 称为激发函数或作用函数,其非线性特征可用阈值型、分段线性型和连续激发函数近似。
称为激发函数或作用函数,其非线性特征可用阈值型、分段线性型和连续激发函数近似。
为了方便,有时将-看成是对应恒等于1的输入 的权值,这时公式(1)的和式变为:
的权值,这时公式(1)的和式变为:
 (1-2)
(1-2)
其中, ,
, 。
。
图3给出了神经网络中常用的激发函数,不同的激发函数决定了神经元的不同输出特性。

图3 常用激发函数
其中,(a)(b)为阈值型函数,(c)为饱和型函数,(d)(e)(f)均为连续性激发函数:(d)是双曲型函数或者称为对称的sigmoid函数;(e)是S型函数,又称为sigmoid函数;(f)是高斯函数。
2、神经网络的基本结构[4]
神经网络由大量的神经元广泛连接而成,根据连接方式的不同,神经网络可以分为两大类:无反馈的前向神经网络和相互连接型神经网络,分别如图4和图5 所示。

图4 前向神经网络
前向神经网络分为输入层、隐含层和输出层。隐含层可以有若干层,每一层的神经元只接受前一层神经元的输出。前向网络中各个神经元接受前一级的输入,并输出到下一级,网络中没有反馈,可以用一个有向无环路图表示。这种网络实现信号从输入空间到输出空间的变换,它的信息处理能力来自于简单非线性函数的多次复合。网络结构简单,易于实现。反传网络是一种典型的前向网络。

图5 反馈型神经网络
相互连接型网络的神经元相互之间都可能有连接,因此,输入信号要在神经元之间反复往返传递,从某一初始状态开始,经过若干次变化,渐渐趋于某一稳定状态或进入周期震荡等其他状态。网络内神经元间有反馈,可以用一个无向的完备图表示。这种神经网络的信息处理是状态的变换,可以用动力学系统理论处理。系统的稳定性与联想记忆功能有密切关系。Hopfield网络、波耳兹曼机均属于这种类型。
3、神经网络学习算法
3.1神经网络学习方法分类[4]
神经网络学习方法有多种。网络的学习规则可以分为三类:相关规则,即仅仅根据连接间的激活水平改变权值;纠错规则,即依赖关于输出节点的外部反馈来改变权系数;无教师学习规则,即学习表现为自适应于输入空间的检测规则。相应地,神经网络学习方法也可根据学习规则划分为不同的种类。
(1)相关规则
相关规则常用于自联想网络,执行特殊记忆状态的记忆式学习,也属于无教师的学习。Hopfield网络就采用这样的学习方法,称之为修正的Hebb规则:
 (3-1)
(3-1)
式中, 和
和 分别表示两个相连接的神经元i和神经元j的激活值。
分别表示两个相连接的神经元i和神经元j的激活值。
(2)纠错规则
纠错规则等效于梯度下降法,通过在局部最大改善的方向上逐步进行修正,力图达到表示函数功能的全局解。感知器使用纠错规则,其特点为:
若一节点的输出正确,一切不变;若输出本应为0而为1,则相应的权值减小;若输出应为1而为0,则相应的权值增加;
对于 学习规则,可分为一般学习规则和广义学习规则,常见的有以下3种。
学习规则,可分为一般学习规则和广义学习规则,常见的有以下3种。
①学习规则。
权值的 修正不是固定的量,而是和误差成正比,即
修正不是固定的量,而是和误差成正比,即
 (3-2)
(3-2)
这里, 是全局学习系数,而
是全局学习系数,而 ,即期望值和实际值之差;
,即期望值和实际值之差; 是神经元j的状态。学习规则和感知器学习规则一样,只适用于线性可分函数,无法用于多层网络。
是神经元j的状态。学习规则和感知器学习规则一样,只适用于线性可分函数,无法用于多层网络。
②广义学习规则。
它可在多层网络上有效地学习,可学习非线性可分函数。其关键是对隐节点的偏差如何定义和计算。具有误差反向传播的前向神经网路的BP算法,当j为神经网络隐层节点时,定义
 (3-3)
(3-3)
式中, 是节点j到下一层神经节点k的权值;
是节点j到下一层神经节点k的权值; 为隐层第j分神经节点的输入网络;
为隐层第j分神经节点的输入网络; 为隐层第j个神经节点的输出;
为隐层第j个神经节点的输出; 是连续的一次可微函数;
是连续的一次可微函数; 为隐层神经节点j的误差反向传播系数;
为隐层神经节点j的误差反向传播系数; 为下一层神经节点k的误差反向传播函数。
为下一层神经节点k的误差反向传播函数。
③Boltzmann机学习规则。
它用模拟退火的统计方法来替代广义的规则。它提供了隐节点的有效学习方法,能学习复杂的非线性可分函数。这种方法也属于梯度下降法,其主要缺点是学习速度太慢。
(3)无教师学习规则
在这种学习规则中,关键不在于实际节点的输出怎样与期望输出相一致,而在于调整参数以反映观测事件的分布。诸如Grossberg的自适应共振理论(ART),子组织特征映射和Klopf的享乐主义神经元都是无教师学习。
这类无教师学习的系统并不在于寻找一个特殊函数表示,而是将事件空间分类成输入活动区域,且有选择的对这些区域响应。它在应用于开发由多层竞争族组成的网络等方面有良好的前景。它的输入可以使连续值,对噪声有较强的抗干扰能力,但对较少的输入样本,结果可能依赖于输入顺序。
在人工神经网络中,学习规则是修正网络权值的一种算法,以获得适合的映射函数和其它的系统性能。Hebb学习规则的相关假设是许多规则的基础,尤其是相关规则;Hopfied网络和自组织特征映射展示了有效的模式识别能力;纠错规则采用梯度下降法,因而存在局部极小点问题。无教师学习提供了新的选择,它利用自适应学习方法,使节点有选择的接受输入空间上的不同特性,从而抛弃了普通神经网络学习映射函数的学习概念,并提供了基于检测特性空间的活动规律的性能描写。下面介绍几种常用的学习方法。
3.2 Hebb学习方法
Hebb学习是一类相关学习,它的基本思想是:如果有两个神经元同时兴奋,则它们之间的连接强度的增强与它们的激励的乘积成正比。用yi表示单元i的激活值(输出),yj表示单元j的激活值,wij表示单元j到单元i的连接加权系数,则Hebb学习规则可表示如下:
 (3-4)
(3-4)
式中η为学习速率。
①单层前向网
设有 个感知器,第
个感知器,第 个感知器的输出为
个感知器的输出为 ,输入
,输入 ,每个感知器有
,每个感知器有 个输入
个输入 ,得一个单层前向网可表示为
,得一个单层前向网可表示为
 (3-5)
(3-5)
单层前向网示意图:

记 为
为 ,表示第个神经元当权向量为
,表示第个神经元当权向量为 ,输入为时的输出,设网络的训练数据集为
,输入为时的输出,设网络的训练数据集为 ,
, 为输入,
为输入, 为输出,而
为输出,而 表示第个感知器的期望输出.训练数据集的误差函数定义为
表示第个感知器的期望输出.训练数据集的误差函数定义为
 (3-6)
(3-6)
学习的目标是求 使误差函数最小,即:
使误差函数最小,即:
 (3-7)
(3-7)
②双层前向网
不含反馈的人工神经网络.

分别有个输入神经元, 个隐层神经元和
个隐层神经元和 个输出神经元,输入
个输出神经元,输入 ,隐层神经元的激活函数为
,隐层神经元的激活函数为 ,第
,第 个隐层神经元的整合函数
个隐层神经元的整合函数 和输出值
和输出值 分别为
分别为
 (3-8)
(3-8)
 (3-9)
(3-9)
 是第一层权重矩阵
是第一层权重矩阵 中第
中第 个输入连接到个隐神经元的权重,
个输入连接到个隐神经元的权重, 是隐元的阀值
是隐元的阀值 ,同样,输出层的激活函数为
,同样,输出层的激活函数为 ,第个输出元以
,第个输出元以 输入,整合函数
输入,整合函数 和输出值分别为
和输出值分别为
 (3-10)
(3-10)
 (3-11)
(3-11)
得双层前向网的输出表达式
 (3-12)
(3-12)
 和
和 ,分别表示隐层元和输出元的阀值,二层前向网的一般模型可表示为
,分别表示隐层元和输出元的阀值,二层前向网的一般模型可表示为
 (3-13)
(3-13)
3.3 梯度下降法
梯度下降法是一种有教师的学习方法。假设下列准则函数
 (3-14)
(3-14)
其中 代表希望的输出,
代表希望的输出, 为期望的实际输出;
为期望的实际输出; 是所有权值组成的向量,
是所有权值组成的向量, 为对的偏差。现在的问题是如何调整W使准则函数最小。梯度下降法可用来解决此问题,其基本思想是沿着
为对的偏差。现在的问题是如何调整W使准则函数最小。梯度下降法可用来解决此问题,其基本思想是沿着 的负梯度方向不断修正W(k)值,直至达到最小。这种方法的数学表达式为
的负梯度方向不断修正W(k)值,直至达到最小。这种方法的数学表达式为
 (3-15)
(3-15)
其中, 是控制权值修正速度的变量;的梯度为:
是控制权值修正速度的变量;的梯度为:
 (3-16)
(3-16)
在上述问题中,把网络的输出看成是网络权值向量W的函数,因此网络的学习就是根据希望的输出和实际之间的误差平方最小原则来修正网络的权向量。根据不同形式的,可推导出相应的算法:规则和BP算法。
3.4 规则
在B.Windrow的自适应线性元件中个,自适应线性元件的输出表示为
 (3-17)
(3-17)
其中, 为权向量,
为权向量, 为k时刻的输入模式。
为k时刻的输入模式。
因此准则函数的梯度是

当 时,Windrow的规则为
时,Windrow的规则为
 (3-18)
(3-18)
这里 是控制算法和收缩性的常数,实际中往往取
是控制算法和收缩性的常数,实际中往往取 。
。
3.5 BP算法[5-6]
误差反向传播的BP算法(Back-Propagation Algorithm)最早由Webos提出。BP网络不仅有输入层节点、输出层节点,而且有隐层节点(可以使一层或多层)。其作用函数通常选用连续可导的Sigmoid函数。
反向传播是通过误差函数求导使误差沿网络向反传播,对误差函数求导以确定各层神经元误差的方法.前向传播是输入 进入网络,信息在网络中前进移动的方向,次计算
进入网络,信息在网络中前进移动的方向,次计算 直至输出的过程.
直至输出的过程.
学习样本集为,
分别为网络系统的输入和期望输出,而网络系统在输入 时的实际计算输出,误差函数为
时的实际计算输出,误差函数为
 (3-19)
(3-19)
 2 (3-20)
2 (3-20)
分析 与误差的关系,而利用上式得
与误差的关系,而利用上式得 与误差的关系.
与误差的关系.
分别称 和
和 为第个输出元和个隐元的误差率,计算可得
为第个输出元和个隐元的误差率,计算可得


同时又可得

 ,
,
在计算中,先计算输出层误差 ,再计算隐层误差
,再计算隐层误差 ,称误差反向传播.可设计求解
,称误差反向传播.可设计求解 的最小二乘法或梯度法
的最小二乘法或梯度法
得学习规则
 (3-21)
(3-21)
 (3-22)
(3-22)
四、神经网络的应用与展望
4.1 神经网络的应用现状[7]
神经网络的应用已经涉及各个领域,并且在智能控制、模式识别、信号处理、连续语音识别、图像处理、生物医学工程等方面均取得了实质性的进展。
(1)在智能控制方面的应用
已经应用于智能机器人、机械手、机器人传感系统的控制,从而可以实现自动躲避障碍物、自动监控生产环境以及机器人本身的智能导航。例如,机器人World Cup,其实质是提出一个充满活力的、嘈杂的复杂环境,这需要大规模的合作和协调。参赛队伍设计机器人共同使用的方法是将不同类型的神经网络和遗传算法(遗传算法)相结合。
(2)在连续语音、模式识别方面的应用
已经应用于连续语音说话人识别、类语言语音识别、手写字符识别、人脸识别、车牌号码识别等,还可以应用于目标自动检测和识别、自然灾害模式预报等。例如,自动speech reading是基于嘴唇图像分析的,该系统可以实现实时跟踪,还可以储存嘴唇区域并进行离线嘴唇模型匹配。神经网络分类器能检测牙齿边缘和其他属性。基于神经网络的输出,自动对封闭嘴唇边缘进行模式匹配识别。
(3)在生物医学图像、信号处理方面的应用
已经应用于图像分割、图像压缩和恢复,包括各种图像数据,比如心电图、脑电图等医学图像等,还可以对语音通信数据进行处理。例如,利用具有相关性的音频和视频来驱动人脸动画和语音合成;使人脸视频序列可以发出类似讲话的声音效果。许多先前的研究已采用这种音频到视觉的转换方案,目前,人们正在研究如何与隐马尔可夫模型(HMM)结合起来以更好地实现转换。
(4)在其他领域的应用
主要包括:财务分析,如股市的预测;特征分析,如美国银行采取神经网络来比对和验证客户签名;过程控制监督,如神经网络可用来提醒飞机飞行员可能的引擎故障。
4.2 神经网络的展望[7]
(1)VC维计算
VC维反映了函数集的学习能力,VC维越大则学习机器越复杂。目前尚没有通用的关于任意函数集VC维计算的理论,只对一些特殊的函数集知道其VC维。对于一些比较复杂的学习机器如神经网络,其VC维除了与函数集有关外,还受学习算法等因素的影响,其确定更加困难。在给定训练集的情况下,如果能求出合适的VC维,则可以帮助确定网络的结构;反之,在给定网络结构的情况下,如果能求出其VC维,则可以确定合适的训练集规模。
(2)神经网络集成
集成思想主要基于弱可学习理论,目的是通过充分利用训练样本来改善网络的泛化能力,因此,集成中网络的类型、结构与训练集规模有密切的关系。集成中虽然包含多个网络,但从更高的抽象级别来看,整个集成也可以看作一个学习系统。关于神经网络集成的研究目前基本上是针对分类和回归估计这2种情况分别进行的,而没有一个统一框架,理论上显得不够完备和深刻。神经网络的一大缺陷是其“黑箱性”,即网络学到的知识难以被人理解.而神经网络集成则加深了这一缺陷。
(3)基于神经网络的数据挖掘
神经网络规则抽取(数据挖掘)根据设计思想的不同,目前的方法大致可以分成2大类,即基于结构分析的方法和基于性能分析的方法。神经网络规则抽取的工作主要着重于提高抽取出的规则对网络的保真度,而在面向数据挖掘的应用中,规则的可理解性往往更加重要。另外,目前的神经网络模型大多不具备增量学习能力,在训练数据发生变动时,需要用整个训练集重新对网络进行训练。
参考文献:
[1]黄德双,关于21世纪人工智能与神经网络技术发展的展望,[会议记录],1999
[2]曹安照,田丽,陈俊,吕元峰,神经网络及其研究展望,自动化与仪器仪表,2006
[3]吴昌友,神经网络的研究及应用,[硕士学位论文],2007
[4]侯媛彬,神经网络,西安电子科技大学出版社,2007,28-33
[5]李炯城,黄汉雄,一种新的快速BP神经网络算法,华南理工大学学报:自然科学版,
2006,34(6):49—53
[6]赵立强,张晓华,高振波等,基于BP神经网络的主分量分析人脸识别算法,计算机
工程与应用,2007,43(36):226—229.
[7]陈俊,神经网络的应用于展望,佛山科学技术学院学报:自然科学版,vol.27 No.5
二、实验一
1. 实验题目
利用线性插值技术,绘制主观贝叶斯的EH公式图像。要求给出LS、LN、P(H)、P(E)四个参数。制作图形界面。
2. 问题分析和实验原理
2.1知识的不确定性
在主观贝叶斯方法中,知识是如下形式的产生式规则表示:
IF E THEN (LS,LN) H (P(H))。其中:
LS是充分性度量。其定义为:
LS=P(E|H)/P(E|¬H)。
LN是必要性度量,其定义为:
LN=P(¬E|H)/P(¬E|¬H)=(1-P(E|H))/(1-P(E|¬H))
2.2 LS和LN的意义
LS是充分性度量,当证据E越是支持H为真时,则应是使相应的LS值越大。而LN是必要性度量,反映了¬E对H的支持程度,¬E越是支持H,则LN越大。所以,不能出现LS>1且LN>1的取值。虽然LS、LN可以有若干种取值,但是,一般情况下,取LS>1, LN<1。这是符合人类的思维习惯的。另外,实验程序中不允许输入LS>1且LN>1或者LS<1且LN<1的输入。
2.3根据证据存在与否而确定的各种情况
主观贝叶斯方法的核心是用P(E|S)将P(H)更新为P(H|S)。
在证据确定的情况下,我们因该用杜达等人1976年证明了的公式来进一步讨论:
P(H/S)=P(H/E)*P(E/S)+P(H/-E)*P(-E/S)
分四种情况讨论这个公式:
(1)P(E/S)=1时

当P(E/S)=1时,P(-E/S)=0。此时公式变成(肯定存在的情况):
(2)P(E/S)=0时

当P(E/S)=0时,P(-E/S)=1.此时公式变成(肯定不存在的情况):
(3)P(E/S)=P(E)时

当P(E/S)=P(E)时,表示E与S无关。利用全概率公式就将公式变为:
(4)当P(E/S)为其它值时

通过分段线性插值就可得到计算P(H/S)的公式:
该公式称为EH公式或UED公式。
3. 程序设计和流程图
3.1流程图

3.2程序代码
代码语言为C语言,源码如下:
#include <iostream.h>
#include <graphics.h>
#include <conio.h>
int main()
#define fdbs 500 //设定坐标放大倍数
{
double PhNe,Ph,Phe,Pe,ls,ln;
cout<<"请输入:"<
cout<<"LS:";cin>>ls;
cout<<"LN:";cin>>ln;
cout<<"P(E):";cin>>Pe;
cout<<"P(H):";cin>>Ph;
Phe=ls*Ph/((ls-1)*Ph+1);
PhNe=ln*Ph/((ln-1)*Ph+1);
PhNe*=fdbs;Ph*=fdbs;Phe*=fdbs;Pe*=fdbs;
initgraph(800,600);
line(50,50,50,550);
line(50,550,650,550);
outtextxy(50,550,"0");
outtextxy(50,50,"P(H/S)");
outtextxy(650,550,"P(E/S)");
moveto(50,550-PhNe);
linerel(Pe,PhNe-Ph);
linerel(1*fdbs-Pe,Ph-Phe);
outtextxy(550,550,"1");
getch();
closegraph();
return 0;
}
4. 程序运行结果


三、实验二
1.实验题目
利用A*算法,实现重排九宫格问题。
2.问题分析和实验原理
2.1搜索的一般过程
(1)把初始节点S0放入OPEN表,并建立只含S0的图,记为G。
OPEN:=S0,G:=G0(G0=S0)
(2)检查OPEN表是否为空,若为空则问题无解,退出。
LOOP:IF(OPEN)=() THEN EXIT(FAIL)
(3)把OPEN表的第一个节点取出放入CLOSE表,记该节点为节点n。
N:=FIRST(OPEN), REMOVE(n,OPEN), ADD(n,CLOSE)
(4)观察节点n是否为目标节点,若是,则求得问题的解,退出。
IF GOAL(n) THEN EXIT(SUCCESS)
(5)扩展节点n,生成一组子节点。把其中不是节点n先辈的那些子节点记作集合M,并把这些节点作为节点n的子节点加入G中。
EXPAND(n)-->M(mi), G:=ADD(mi,G)
针对M中子节点的不同情况,分别进行如下处理:
对于那些未曾在G中出现过的M成员设置一个指向父节点(n)的指针,并把它放入OPEN表;
对于那些先前已在G中出现过的M成员,确定是否要修改指向父节点的指针;对于那些先前已在G中出现,并且已经扩展了的M成员,确定是否需要修改其后继结点指向父节点的指针。
(6)按某种搜索策略对OPEN表中的节点进行排序
(7)转第2步。
2.2 A*算法
A*算法可以描述为f(n)=h(n)+g(n)的形式。其中,h(n)被称作启发函数,是当前结点到目标结点的代价描述;而g(n)是代价函数,描述了起始结点到当前结点的代价;f(n)是估价函数。A*算法是不回溯的,每次都选择f 值最小的路径推进。
(1) 建立一个链表,计算初始结点的估价函数f,并将初始结点入表,设置链表头和尾指针。
(2) 取出头(头指针所指)结点,如果该结点是目标结点,则输出路径,程序结束。否则对结点进行扩展。
(3) 检查扩展出的新结点是否与链表中的结点重复,若与不能再扩展的结点重复(位于头指针之前),则将它抛弃;若新结点与待扩展的结点重复(位于头指针之后),则比较两个结点的估价函数中g的大小,保留较小g值的结点。跳至第五步。
(4) 如果扩展出的新结点与链表中的结点不重复,则按照它的估价函数f大小将它插入头结点后待扩展结点的适当位置,使它们按从小到大的顺序排列,最后更新尾指针。
(5) 如果头结点还可以扩展,直接返回第二步。否则将头指针指向下一结点,再返回第二步。
3.程序设计和流程图
3.1流程图

3.2程序代码
#include <iostream>
#include <vector>
#include<string>
#include<algorithm>
#include<stdlib.h>
using namespace std;
string target="123804765";
string start;
class Node
{
public:
string state;
int r;//1,2,3,4代表上下左右
int g,h;//代价;g代表执行的步数,h代表当前状态和目标状态不同数字的个数。
Node *family;//回溯用
int geth();
int getvalue();
Node()
{
family=NULL;
state="102345687";//如果初始化为NULL, if (*(pMatrix+i)!=*(target+i))会报错
r=0;
g=0;
h=0;
};
};
int Node::geth() //获得节点a的代价h
{
int k=0;
for(int i=0;i<9;++i)
{
for(int j=0;j<9;++j)
{
if(state[i]=='0')
continue;
if (state[i]==target[j])
{
k+=abs(j/3-i/3)+abs(j%3-i%3);
}
}
}
return k;
}
int Node::getvalue() //估计值
{
return g+h;
}
void sort(vector &list, Node* newone)//因为是顺序表,采用对半查找,提高效率
{
vector::iterator iter=list.begin();
int first=0;
int end=list.size();
if(end==0||list[end-1]->getvalue()>=newone->getvalue())
list.push_back(newone);
else if (list[0]->getvalue()<=newone->getvalue())
{
list.insert(iter,1,newone);
}
else
{
while (first<=end)
{
if (list[(end+first+1)/2]->getvalue()==newone->getvalue())
{
first=(end+first+1)/2;
break;
}
else
if ((list[(end+first+1)/2]->getvalue())>(newone->getvalue()))
{
first=(end+first+1)/2+1;
}
else
end=(end+first+1)/2-1;
}
list.insert(iter+first,1,newone);
}//得到first并插在他前面
}
/*求排列的奇偶性,输入8位数字串,输出0代表偶数,输出1代表奇数
当初始状态的逆序数和目标状态的逆序数的奇偶性相同时,问题有解;否则问题无解。
逆序数定义如下:丢弃数字 0 不计入其中,
所有的数之前比该数小的数字的个数之和是该状态的逆序数,
*/
bool CalNixu(string a)//求逆序数
{
int count(0);
for (int i=0;i<9;++i)
{
if(a[i]=='0')
continue;
for (int j=0;j
{
if (a[j]=='0')
continue;
if (a[i]-'0'>a[j]-'0')
{
++count;
}
}
}
return (count%2)?1:0;
}
bool CompareNixu(string a,string b)//比较a,b的奇偶性,相同1
{
return (CalNixu(a)==CalNixu(b))?1:0;
}
void PrintMatrix(string a)//按格式输出
{
for (int i=0;i<9;i++)
{
cout<
if((i+1)%3)
cout<<' ';
else
cout<
}
cout<
}
bool CompareRule(Node *a,Node *b)//排序规则
{
return (a->g+a->h)>(b->g+b->h)?1:0;
}
int FindZero(Node* a)//找节点a零位在什么位置
{
for(int i=0;i<9;++i)
{
if(a->state[i]=='0')
return i;
}
}
//看节点是否在open\closed存在,存在返回1
bool FindIfExist(Node* temp,vector open,vector close)
{
for (int i=0;i
if (temp->state==open[i]->state)
return 1;
for (int j=0;j
if (temp->state==close[j]->state)
return 1;
return 0;
}
bool CheckIfEqual(Node* a)//看节点和目标状态是否相等,是1,否则0
{
if (target==a->state)
return 1;
else
return 0;
}
bool CreateChildren(Node *a,vector &open,vector &close,vector &globle)//产生子节点,并在此处判断是否是目标节点
{
open.pop_back();
int ZPlace=FindZero(a);
Node* temp1=new Node;
if (ZPlace>2)//往上移
{
temp1->state=a->state;
char s=temp1->state[ZPlace-3];
temp1->state[ZPlace-3]=temp1->state[ZPlace];///指针相同如果temp1=a的话都会一起改变
temp1->state[ZPlace]=s;
if(!FindIfExist(temp1,open,close))
{
temp1->family=a;
temp1->g=a->g+1;
temp1->h=temp1->geth();
sort(open,temp1);
}
if(CheckIfEqual(temp1))
return 1;
}
Node* temp2=new Node;
if (ZPlace<6)//往下移
{
temp2->state=a->state;
char s=temp2->state[ZPlace+3];
temp2->state[ZPlace+3]=temp2->state[ZPlace];
temp2->state[ZPlace]=s;
if(!FindIfExist(temp2,open,close))
{
temp2->family=a;
temp2->g=a->g+1;
temp2->h=temp2->geth();
sort(open,temp2);
}
if(CheckIfEqual(temp2))
return 1;
}
Node* temp3=new Node;
if (!((ZPlace+1)%3==0))//往右移
{
temp3->state=a->state;
char s=temp3->state[ZPlace+1];
temp3->state[ZPlace+1]=temp3->state[ZPlace];
temp3->state[ZPlace]=s;
if(!FindIfExist(temp3,open,close))
{
temp3->family=a;
temp3->g=a->g+1;
temp3->h=temp3->geth();
sort(open,temp3);
}
if(CheckIfEqual(temp3))
return 1;
}
Node* temp4=new Node;
if (!((ZPlace)%3==0))//往左移
{
temp4->state=a->state;
char s=temp4->state[ZPlace-1];
temp4->state[ZPlace-1]=temp4->state[ZPlace];
temp4->state[ZPlace]=s;
if(!FindIfExist(temp4,open,close))
{
temp4->family=a;
temp4->g=a->g+1;
temp4->h=temp4->geth();
sort(open,temp4);
}
if(CheckIfEqual(temp4))
return 1;
}
close.push_back(a);//将a加入到close链表中
return 0;
}
void FindPath()
{
vectoropen,close,globle;
Node *head=new Node;
head->state=start;
// cin>>head->state;
head->g=0;
head->h=head->geth();
head->family=NULL;
open.push_back(head);
while (1)
{
if (open.size()==0)
break;
Node *temp=open[open.size()-1];
if(CreateChildren(temp,open,close,globle))
{
Node* temp1=open[open.size()-1];
while (temp1!=NULL)
{
globle.push_back(temp1);
temp1=temp1->family;
}
for (int i=globle.size()-1;i>=0;--i)
PrintMatrix(globle[i]->state);
// cout<<"总步数"<
// cout<<"开闭链表节点总数"<
break;
}
}
}
int main()
{
cout<<"*********************"<
cout<<" 重排九宫格"<
cout<<"TTTTTTTTTTTTTTTTTTTTT"<
cout<<" 本程序算法为 A*"<
cout<<"YYYYYYYYYYYYYYYYYYYYY"<
cout<<"按行列顺序输入数字串后回车:"<
cin>>start;
// start="283104765";
//检测输入是否正确
int input_correct=0;
while(1)//保证0-9存在且只出现一次
{
for(int i=0;i<9;i++)
for(int j=0;j<9;j++)
if(start[i]-48==j)
input_correct++;
if(input_correct==9)
break;
else
{
cout<<"错误!请重新输入:"<
cin>>start;
}
input_correct=0;
}
cout<<"正确,所输入九宫为:"<
PrintMatrix(start);
if (CompareNixu(start,target))
{
cout<<"可完成目的变换,变化步骤如下:"<
}
else
{
cout<<"不可完成目的变换"<
return 0;
}
FindPath();
return 0;
}
4.程序运行结果

四、实验总结
通过本次实验,我认识到了自己的一些不足,使自己的能力得到了一定程度的提升。实验一的图形化界面以前从未接触过,因为这个实验,我对c的图形化有了一些基础的了解,用“graphic”做出了非常简单的界面,但正因为此我对图形化的认识得以加深。对于实验二,则得到了更多的知识,如两个排列能否通过相邻交换达成一致可以通过逆序来判断,对状态搜索也有了相当程度的了解。自此,认真努力学习以丰富自身。
-
人工智能实验报告
人工智能九宫格重移搜索成员赵春杰20xx210665羊森20xx210653黄鑫20xx210周成兵20xx210664王素娟20…
-
人工智能试验报告汇总
人工智能课程实验指导书实验内容实验一产生式系统实验实验二移动机器人的路径规划与行为决策实验实验三梵塔问题实验实验四A算法实验实验五…
-
人工智能实验报告
华北电力大学实验报告实验名称课程名称人工智能及应用专业班级学生姓名号成绩指导教师李继荣实验日期20xx5学华北电力大学实验报告华北…
-
人工智能实验报告
人工智能第二次实验报告一实验题目遗传算法的设计与实现二实验目的通过人工智能课程的学习熟悉遗传算法的简单应用三实验内容用遗传算法求解…
-
人工智能实验报告
人工智能技术实验报告实验名称人工智能实验1姓名班级指导教师完成时间20xx04301读程序指出运行结果domainsssymbol…
-
C语言解八数码问题之人工智能实验报告
人工智能导论上机实验指导书基于人工智能的状态空间搜索策略研究八数码问题求解一实验软件TC20或VC60编程语言或其它编程语言二实验…
-
《人工智能》学习报告
深圳大学硕士研究生课程作业人工智能人工智能学习报告深圳大学机电与控制工程学院彭建柳学号09430102101引言人工智能Artif…
-
人工智能实验报告
人工智能第二次实验报告一实验题目遗传算法的设计与实现二实验目的通过人工智能课程的学习熟悉遗传算法的简单应用三实验内容用遗传算法求解…
- 人工智能实验报告
-
人工智能实验报告
人工智能实验报告ArtificialIntelligence老师刘丽珏班级物联网1201学号0909120xx5姓名钱晓雪日期20…
-
人工智能实验报告
人工智能九宫格重移搜索成员赵春杰20xx210665羊森20xx210653黄鑫20xx210周成兵20xx210664王素娟20…