实践专周设计报告
电子科技大学成都学院云计算系
实践专周设计报告
课 程 名 称:基于Hadoop2.0并行数据处理应用 指导 教师 组: 邹倩颖 王小芳 组长学号姓名: 1341310131 屈太源 组员学号姓名: 1341310120 冯小丹 组员学号姓名: 1341310726 张 瑜
云计算科学与技术系制
20xx年12月
目 录
目 录
第1章 引 言 ................................................................................................................... 1
1.1 问题分析 ....................................................................................................................1
1.2 设计目标 ....................................................................................................................1
1.2.1 基本功能 .................................................................................................................1
1.2.2 扩展功能 .................................................................................................................2
1.3 设计思路 ....................................................................................................................2
1.4 功能描述 ....................................................................................................................2
1.5 设计过程 ....................................................................................................................3
第2章 相关技术简介 ..................................................................................................... 4
2.1 Hadoop平台介绍 .......................................................................................................4
2.2 MapReduce并行程序设计 .........................................................................................4
2.2.1 Map函数 ..................................................................................................................4
2.2.2 Reduce函数 .............................................................................................................5
2.2.3 MapReduce计算模型的优化 ..................................................................................5
2.3 HDFS简介 ..................................................................................................................6
2.3.1 HDFS节点 ...............................................................................................................6
2.3.2 关于NameNode ......................................................................................................6
2.3.3 关于DataNode及体系结构图 ...............................................................................7
第3章 环境搭建过程详述 ............................................................................................. 8
3.1 搭建hadoop伪分布的环境 ......................................................................................8
3.2 设置ssh免密码登本地 .............................................................................................8
3.2.1 创建一个wifi ..........................................................................................................8
3.2.2 配置jdk ...................................................................................................................9
3.2.3 配置hadoop ............................................................................................................9
3.2.4 测试hadoop是否搭建成功 .................................................................................12
第4章 MapReduce并行设计实现 ............................................................................... 13
4.1 第一案例要求 ..........................................................................................................13
4.2 核心代码1 ...............................................................................................................13
4.3 第二案例要求 ..........................................................................................................16
I
目 录
4.4 核心代码2 ...............................................................................................................16
第5章 测试和总结 ....................................................................................................... 20
5.1 集群测试和调试 ......................................................................................................20
5.2 集群系统存在的问题及解决方案 ..........................................................................20
5.3 收获及心得体会 ......................................................................................................21
参考文献 ......................................................................................................................... 22
致谢 ................................................................................................................................. 23
II
第1章 引 言
第1章 引 言
1.1 问题分析
Hadoop是Apache软件基金会旗下的一个开源分布式计算机平台。以Hadoop分布式文件系统HDFS和MapReduce为核心的Hadoop为用户提供了系统底层细节透明的分布式架构。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。
1.2 设计目标
1.2.1 基本功能
Hadoop集群环境具体搭建工作,需要调用jps命令,启动5个服务进程,完成Eclipse环境搭建。
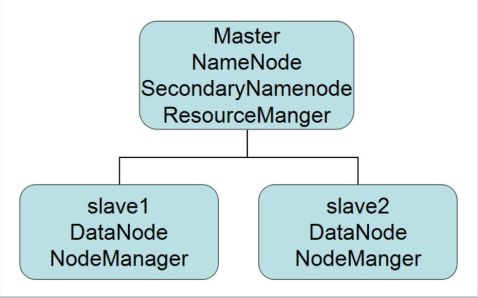
图1-1 集群搭建
1
电子科技大学成都学院实践专周设计报告
1.2.2 扩展功能
1.编写手机拨打电信、联通、移动特殊号码的统计应用。
2.倒排索引的实现。
3.Hadoop集群环境搭建,需调用jps命名启动5个服务进程。
1.3 设计思路
环境搭建
1、安装前的准备
完成分布式集群环境的搭建,一个master节点,两个slave节点,在hosts中添加主从节点的IP地址。在hostname中修改主机名,并使其生效。在主要点中添加相应从节点的IP。在yarn-env.sh中添加Java_home的路径。
2、安装JDK
JDK安装较为简单。
使用VMware Workstation 安装了3个RHEL 5.2系统。装好一个RHEL,并且安装好JDK,再利用VMware Workstation的克隆功能完成另外两个的安装。
3、更改主机名
IP设置:
Master:10.18.5.116
Slave1:10.18.6.77
Slave2:10.18.6.33
1.4 功能描述
步骤1:用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
2
第1章 引 言
步骤2:ResourceManager为该应用程序分配第一个Container(这里可以理解为一种资源比如内存),并与对应的Node-Manager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
步骤3:ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
步骤4:ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
步骤5:一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
步骤6:NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
步骤7:各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
步骤8:应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己)。
1.5 设计过程
在hosts中添加主从节点的IP地址。
在hostname中修改主机名,并使其生效。
在主节点中添加相应从节点的IP。
在yarn-env.sh中添加Java_home的路径。
在hadoop-env.sh中修改Java_home的路径。
3
电子科技大学成都学院实践专周设计报告
第2章 相关技术简介
2.1 Hadoop平台介绍
Hadoop自身包括以下内容:Hadoop Common: hadoop的基础,Hadoop Distributed File System (HDFS): 分布式文件系统,Hadoop YARN: 集群任务资源管理及任务调度的框架,Hadoop MapReduce: 基于YARN的分布式计算。
MRAppMaster是MapReduce的ApplicationMaster实现,它使得MapReduce应用程序可以直接运行于YARN之上。在YARN中, MRAppMaster负责管理MapReduce作业的生命周期,包括作业管理、资源申请与再分配、Container启动与释放、作业恢复等。
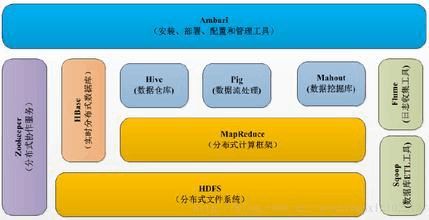
图2-1 Hadoop结构
2.2 MapReduce并行程序设计
2.2.1 Map函数
1.将小数据集进一步解析成一批<key,value>对,输入Map函数中进行处理;
2.每一个输入的<k1,v1>会输出一批<k2,v2>;<k2,v2>是计算的中间结果;
4
第2章 简介技术相关
2.2.2 Reduce函数
输入的中间结果<k2,List(v2)>中的List(v2)表示是一批属于同一个k2的value值。
2.2.3 MapReduce计算模型的优化
1.任务调度:
计算方面:Hadoop会优先将任务分配给空闲的机器,已达到公平分享系统资源的目的。
IO方面:Hadoop会尽量将Map任务分配给“输入分片(InputSplit)”所在机器,以减少IO的消耗。
2.数据预处理与输入分片的大小:
MapReduce任务擅长处理少量的大数据
若是大量的小数据,则选择先对数据进行一次预处理,将数据合并以提高MapReduce任务的执行效率。
或当一个Map任务运行只需几秒时,考虑多分配些数据,让其处理。
通常,一个Map任务运行60秒左右是比较合适的。
3.Map和Reduce任务的数量
Map/Reduce任务槽:这个集群能够同时运行的Map/Reduce任务的最大数量。 任务槽帮助对任务调度进行设置。
设置Map数量主要参考Map运行的时间,设置Reduce任务的数据量参考任务槽的设置,即Reduce任务数是任务槽的0.95或1.75倍。
4.Combine函数
用于本地合并数据的函数。
作用:某些数据在本地会产生很多相同重复的数据,若此时一个一个传递给Reduce任务是非常耗时的;因此,MapReduce框架运行Combine函数用于本地合并,这会大大减少IO操作的消耗。
合理设计该函数能有效减少网络传输的数据量,提高MapReduce的效率。
5.压缩
5
电子科技大学成都学院实践专周设计报告
对Map的中间结果输出和最终结果输出,进行压缩
作用:减少网络传输。
有副作用,请根据实际情况来选择。
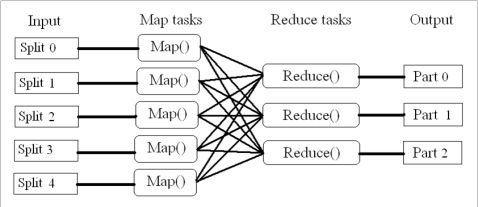
图2-2 MapReduce体系图
2.3 HDFS简介
HDFS是Hadoop项目的核心子项目,是Hadoop主要应用的一个分布式文件系统。HDFS非常适合用在商用硬件上作分布式存储和计算,因为它具有高容错性和可扩展性;HDFS可配置性极高;使用Java语言开发,支持所有主流平台;支持类shell命令,可直接和HDFS进行交互;NameNode和DataNode有内置的Web服务器。HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上。
2.3.1 HDFS节点
HDFS是一个主从结构,一个HDFS集群是由一个名字节点,它是一个管理文件命名空间和调度客户端访问文件的主服务器,当然还有一些数据节点,通常是一个节点一个机器,它来管理对应节点的存储。HDFS对外开放命名空间并允许用户以文件形式存储。
2.3.2 关于NameNode
管理文件系统的命名空间。
6
第2章 简介技术相关
记录每个文件数据块在各个DataNode上的位置和副本信息。
协调客户端对文件的访问 。
记录命名空间内的改动或空间本身属性的改动 。
使用事务日志记录HDFS元数据的变化。使用映像文件存储文件系统的命名空间,包括文件映射,文件属性等。
2.3.3 关于DataNode及体系结构图
负责所在物理节点的存储管理
一次写入,多次读取(不修改)
文件由数据块组成,典型的块大小是64MB
数
图2-3 HDFS结构图
7
电子科技大学成都学院实践专周设计报告
第3章 环境搭建过程详述
3.1 搭建hadoop伪分布的环境
配置jdk,进入在存放jdk文件夹的当前目录,将解压好的jdk1.7.0_10文件夹用最高权限复移动到/usr/lib/jvm目录里,此时即使没有jvm目录也可以执行如下命令,jvm文件夹将得到创建。
3.2 设置ssh免密码登本地
3.2.1 创建一个wifi
查看创建好wifi的IP :
ifconfig
安装SSH
sudo apt-get install openssh-server
将ip地址和主机映射写入hosts文件中
找到/etc/hosts,进行编辑
sudo vim /etc/hosts
生成公钥密钥,将公钥复制为authorized_keys,并且修改权限为600
执行如下命令
ssh-keygen -t rsa
一路回车,进入.ssh目录下
我们发现该目录下有如下两个文件,一个为公钥,一个为私钥
复制公钥为authorized_keys,修改其权限
cat id_rsa.pub >> authorized_keys
8
第3章 环境搭建过程详述
sudo chmod 600 authorized_keys
我们可以测试一下是否能够免密码登陆到本地
3.2.2 配置jdk
1.下载解压jdk
解压命令,-C指定解压路径
sudo tar -zxvf -C /usr/local/ jdk-7u25-linux-x64.tar.gz
2.配置环境变量
编辑/etc/profile文件
sudo vim /etc/profile
在文件末添加如下内容
export JAVA_HOME=/usr/local/jdk1.7 (这里的路径为jdk的所在路径) export PATH=.:$PATH:$JAVA_HOME/bin
:wq!保存退出后,需要更新一下配置文件
source /etc/profile
3.检查jdk是否配置完成
java -version
3.2.3 配置hadoop
1.下载
2.解压后,配置环境变量
在/etc/profile原有的基础上增加以下内容
export HADOOP_HOME=/usr/local/hadoop2.2
在PATH末尾增加
:$HADOOP_HOME/sbin
3.检查是否配置完成
9
电子科技大学成都学院实践专周设计报告
hadoop version
4.修改hadoop配置文件
进入/usr/local/hadoop2.2/etc/hadoop,修改该目录下的5个配置文件
修改hadoop-env.sh,将配置文件中的JAVA_HOME的路径修改为自己jdk所在的路径
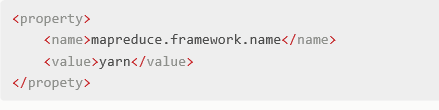
修改core-site.xml文件,在添加以下内容
图3-1 core-site.xml文件
修改hdfs-site.xml,在添加如下内容

10
第3章 环境搭建过程详述
图3-2 hdfs-site.xml文件
图3-3 hdfs-site.xml文件

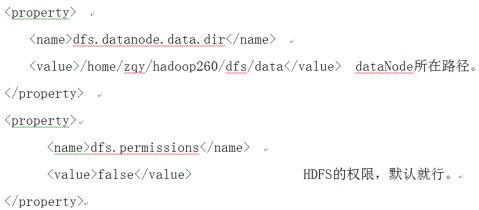
11
电子科技大学成都学院实践专周设计报告
修改yarn-site.xml,在添加以下内容
图3-4 yarn-site.xml文件
修改mapred.site.xml,在添加以下内容
图3-5 mapred.site.xml文件
3.2.4 测试hadoop是否搭建成功
1.启动hadoop ,第一次启动hadoop时需要格式化 : bin/hdfs namenode -format
2.进入sbin目录执行 :
./start-all.sh
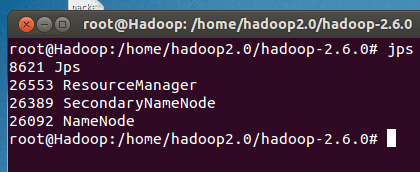
3.启动完成后查看hadoop的进程是否全部启动,执行命令jps

12
第4章 MapReduce并行设计实现
第4章 MapReduce并行设计实现
4.1 第一案例要求
倒排索引
案例1:现有一批电话通信清单,记录了用户A拨打某些特殊号码(如120,10086,138xxxxxxxx等)的记录。需要做一个统计结果,记录拨打给用户B的所有用户A。
添加原始数据

图4-1 添加数据
处理后的数据

图4-2 显示数据
4.2 核心代码1
计数器 Counter 是一个计数器 可以记录这个程序一些数据用于统计。
public class Test extends Configured implements Tool {
13
电子科技大学成都学院实践专周设计报告
enum Counter {
LINESKIP, // 出错的行
}
public static class Map extends Mapper<LongWritable, Text, Text, Text> { public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 读取源文件,line得到的就是输入文件的一行数据
String line = value.toString();
try {
// 数据处理
String[] lineSplit = line.split(" "); // 对源数据进行分割重组
String anum = lineSplit[0]; // 主叫
String bnum = lineSplit[1]; // 被叫
context.write(new Text(bnum), new Text(anum)); // 输出
} catch (ArrayIndexOutOfBoundsException e) {
context.getCounter(Counter.LINESKIP).increment(1); // 出错令计数器加1
2.Reduce函数
public static class Reduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String valueString;
String out = "";
// 每个value代表Map函数发送的一个value
14
第4章 MapReduce并行设计实现
// 在这里代表拨打了这个被叫号码的一个主叫
for (Text value : values) {
valueString = value.toString();
out += valueString + "|";
context.write(key, new Text(out));
3.运行
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = new Job(conf, "test_job"); // 任务名
job.setJarByClass(Test.class); // 执行class
FileInputFormat.addInputPath(job, new Path(args[0])); // 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); // 输出路径
job.setMapperClass(Map.class); // 指定上面Map类作为MAP任务代码
job.setReducerClass(Reduce.class); // 指定上面Reduce类作为REDUCE任务代码 job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class); // 指定输出KEY的格式
job.setOutputValueClass(Text.class); // 指定输出VALUE的格式等哈
job.waitForCompletion(true);
return job.isSuccessful() ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new Test(), args );
System.exit(res);
15
电子科技大学成都学院实践专周设计报告
4.3 第二案例要求
添加原始数据

图4-3 添加数据
显示原始数据
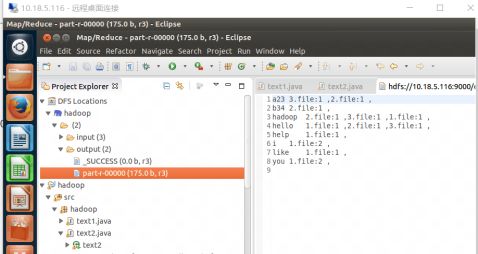
图4-4 结果图
4.4 核心代码2
private static Configuration conf = null; static {
16
第4章 MapReduce并行设计实现
conf = new Configuration(); conf.addResource(new Path("conf/core-site.xml")); conf.addResource(new Path("conf/yarn-site.xml")); conf.addResource(new Path("conf/mapred-site.xml")); conf.addResource(new Path("conf/hdfs-site.xml")); // conf.addResource(new Path("conf/hbase-site.xml")); public static class MyMapper extends Mapper<Object, Text, Text, Text> private Text valueInfo = new Text(); private Text keyInfo = new Text(); private FileSplit split; public void map(Object key, Text value, Context context)// throws IOException, InterruptedException { // 获取<key value>对所属的FileSplit对象 split = (FileSplit) context.getInputSplit(); StringTokenizer stk = new StringTokenizer(value.toString()); while (stk.hasMoreElements()) { // key值由(单词:URI)组成 keyInfo.set(stk.nextToken() + ":" + split.getPath().toString());
// 词频
17
电子科技大学成都学院实践专周设计报告
valueInfo.set("1"); context.write(keyInfo, valueInfo); public static class MyCombiner extends Reducer<Text, Text, Text, Text> Text info = new Text(); public void reduce(Text key, Iterable<Text> values, Context contex)//
//
throws IOException, InterruptedException { throws IOException, InterruptedException { int sum = 0; for (Text value : values) { sum += Integer.parseInt(value.toString()); int splitIndex = key.toString().indexOf(":"); // 重新设置value值由(URI+:词频组成) info.set(key.toString().substring(splitIndex + 1) + ":" + sum); key.set(key.toString().substring(0, splitIndex)); contex.write(key, info); public static class MyReducer extends Reducer<Text, Text, Text, Text> private Text result = new Text(); public void reduce(Text key, Iterable<Text> values, Context context)
18
第4章 MapReduce并行设计实现
//生成文档列表
String fileList = new String(); for (Text value : values) {
fileList += value.toString()+";"; result.set(fileList);
context.write(key, result);
19
电子科技大学成都学院实践专周设计报告
第5章 测试和总结
5.1 集群测试和调试
图5-1 主节点
图5-2 从节点
图5-3 从节点
5.2 集群系统存在的问题及解决方案
问题:1)在搭建集群环境将配置文件修改完之后,master主节点jps


后
20
第5章 测试和总结
SecondaryNmaeNode没有显示出来。
解决方案:主节点和两个重节点的yarn-env.sh文件修改不一致,修改一直之后金jps就能显示出来NameNode,ResourceMananger, SecondaryNmaeNod。
问题:2)在master主节点上安装好ecplise环境后,HDFS的数据传输不能够加载出来。
解决方案:两个slaver节点的core-site.xml的文件配置要成主节点master的IP,同时格式化与停止三个节点服务器,后将创建的临时文件夹彻底删除,再将三个服务器开启,HDFS的数据传输才能加载出来,也可以用命令hadoop fs –put 传文件。
解决办法:在/usr/java/hadoop/目录下,输入命令:chown -R hadoop:hadoop(用户名:用户组)tmp(文件夹)即可。
5.3 收获及心得体会
通过这次实践专周,我们小组在邹倩颖和王小芳老师的悉心指导下,很快的就完成了此次实验,在实验中我们小组遇到了很多的问题,并且及时通过老师的帮住解决了问题,虽然我们现在的知识结构体系很差,但是我们知道,只要肯学,肯付出,总有一天我们会收获到我们想要的一切。其次要感谢身边的同学给予我们小组的帮助,使我们共同进步!
21
电子科技大学成都学院实践专周设计报告
参考文献
[1]实战Hadoop-刘鹏-电子工业出版社
[2]Hadoop上运行WordCount以及本地调试
[3] 命令行运行Hadoop实例wordcount程序
[4]Hadoop的安装与配置及示例wordcount的运行
[5]MPI standard:/docs/mpi-11-html/mpi-report.html
22
致 谢
致 谢
光阴似箭,几天的时间很快就过去了。通过这次专周不仅让我们小组受益匪浅,而且更让我们懂得了发现问题,解决问题所收获的喜悦,在此也由衷的感谢邹倩颖老师与王小芳老师 ,在他们的悉心指导下,我们小组才得以完成此次学习任务。在一次向老师们表示忠心的感谢和最崇高的敬意。 同时感谢学校为我们提供实验室,他们给我们提供了必要的实验器材和资源。
更要感谢我们小组的其他成员,在实验期间,他们不仅在搭建过程上给予我有很大的帮助,而且我们还彼此探讨问题和解决问题。还在最后的实践专周设计报告上提供宝贵意见。这一周,虽然我们很辛苦,但我们彼此都收获颇多,真的很愉快!
23
电子科技大学成都学院实践专周设计报告
电子科技大学成都学院
-
综合实践周总结报告
05电本(1)班李雯35号对于实践周,我们往往抱以不予重视的态度,不把它当作一门重要的课程来对待,忽视其设立的必要性和意义,因此经…
-
社会实践周报告
ShanxiuniversityofFinanceandEconomics全日制普通本科实习报告学院管理科学与工程专业项目管理姓名…
-
大学生实践周报告总结
浙江传媒学院国际文化传播学院实习报告实习名称综合实践周实习外宣调研院系国际文化传播学院专业班级指导教师报告人时间浙江传媒学院实习情…
-
教学实践周报告 - 副本
实践记录1方法在厦门和大嶝岛实地调查走访大街小巷中山路文灶火车站大嶝岛等等电话采访问卷调查网上查找资料2步骤7月1112日查找在厦…
-
实践周报告
财务管理主要培养目标和主要课程比较实践目的:大学生社会实践的目的在于弥补学校实践知识的不足,大学生通过社会实践可以开阔学生眼界丰富…
-
《实践周报告》
20xx-20xx学年第二学期天津商务职业学院国际贸易系国际贸易实务专业实践周实习报告题目:LED商品出口业务流程班级:姓名:学号…
-
艺术实践周总结报告
艺术实践周总结报告金秋十月,中国音乐学院第二届艺术实践周活动于20xx年x月x日在国音堂音乐厅隆重开幕。上午9:00,大会一开始,…
-
综合实践周总结报告
05电本(1)班李雯35号对于实践周,我们往往抱以不予重视的态度,不把它当作一门重要的课程来对待,忽视其设立的必要性和意义,因此经…
-
实践报告周记第五周
毕业实践周记—第五周本周我们开始进行土方工程,我们对开始了对基坑的开挖。由于土石方工程是外包的所以我们只能负责进度管理工作。从外包…
-
富士康FOXCONN菁干班新人学习实习心得周报告四
1、本周实习内容:(340字刚好)本周主要协助固定资产信息核对、保税设备查验、申报员考试等工作。与采购部分开办公后,采购部与关务物…
-
实习报告周记录 范文
实习周记录实习单位:广州傲霆投资顾问有限公司实习时间:20xx年x月x日——20xx年x月x日第一周(20xx年x月x日—7月x日…