编译原理实验报告

课程实验报告
课程名称:《编译原理》
专业班级:计算机科学与技术11级10班
学 号: XXXXXXX
姓 名: X X
指导教师: 刘 铭
报告日期: 2014年6月16日
计算机科学与技术学院
目录
目录... 2
1 实验一 词法分析... 3
1.1 实验目的... 3
1.2 实验要求... 3
1.3 算法思想... 4
1.4 实验程序设计说明... 5
1.5 词法分析实现... 6
1.6 词法实验结果及结果分析... 12
2 实验二 语法分析... 13
2.1 实验目的... 13
2.2 实验要求... 13
2.3 算法思想... 13
2.4 实验程序设计说明... 15
2.5 语法分析实现... 15
4 实验中遇到的问题及解决... 22
参考资料... 23
1 实验一 词法分析
1.1 实验目的
设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
1.2 实验要求
1、待分析的简单的词法
(1)关键字:
begin if then while do end
所有的关键字都是小写。
(2)运算符和界符
: = + - * / < <= <> > >= = ; ( ) #
(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:
ID = letter (letter | digit)*
NUM = digit digit*
(4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
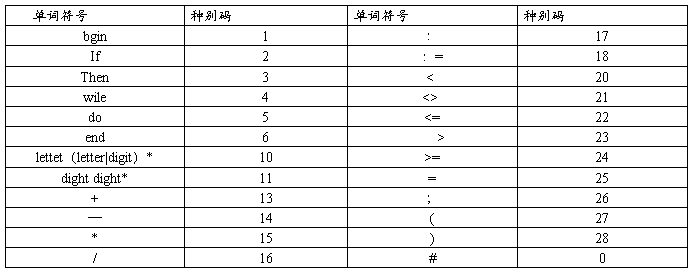
2、 各种单词符号对应的种别码:
表1 各种单词符号对应的种别码
3、 词法分析程序的功能:
输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;
token为存放的单词自身字符串;
sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:
(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……
1.3 算法思想
算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
1、 主程序示意图:
主程序示意图如图1所示。其中初始包括以下两个方面:
⑴ 关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下:
Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};
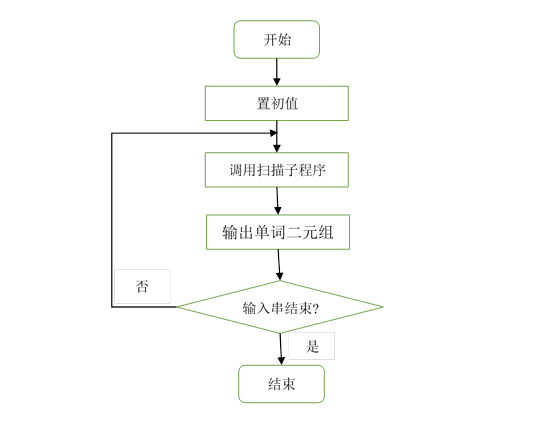
图1 主程序示意图
(2)程序中需要用到的主要变量为syn,token和sum
2、 扫描子程序的算法思想:
首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。扫描子程序主要部分流程如图2所示。
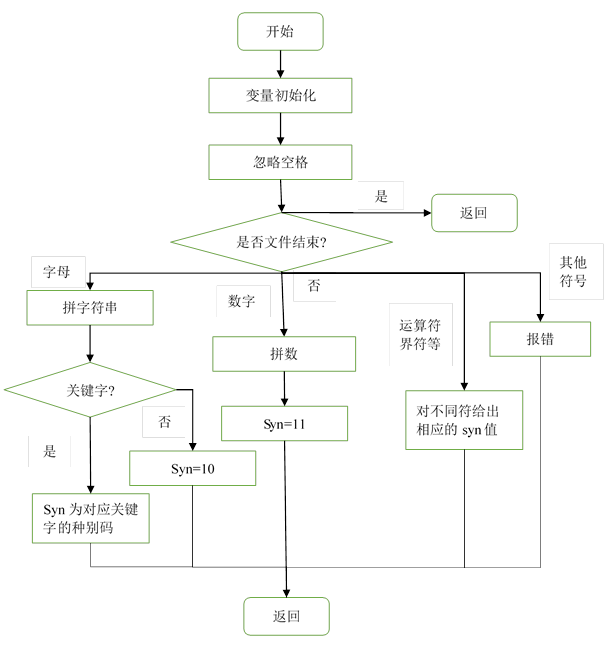
图2 扫描子程序流程图
1.4 实验程序设计说明
1、数据结构的设计
先来看看WORD结构的设计:
typedef struct {
int typenum; //用于存储该字符串的种别码;
char *word; //用于存储字符串;
}
这个词法分析中,我们要将我们识别到的字符串输出他们,而且还要将他们的相应的种别码输出,因此我们得用一个结构体来将这两个属性放在一个结构体中。
2、算法的设计
首先将输入端的字符串读入然后进行前期的处理,如去掉空白符号。之后在一个字符一个字符的进行处理,判断下一个字符串所属类型,然后给出相应类型的种别码,返回给主函数进行输出。其中主要部分就是分类属性的判断以及判断之后不同属性种别码的赋值,这就是整个程序中的主要部分。
1.5 词法分析实现
【使用C语言实现:】
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <windows.h>
#define _KEY_WORD_END "waiting for your expanding" /*定义关键字结束标志*/
HANDLE gh_std_out; //标准输出设备句柄
typedef struct /*单词二元组的结构,可以根据需要继续扩充*/
{
int typenum;
char * word;
} WORDS;
char input[255]; /*输入缓冲区*/
char token[255]="";/*单词缓冲区*/
int p_input;/*输入缓冲区指针*/
int p_token;/*单词缓冲区指针*/
char ch; /*当前读入字符*/
char* KEY_WORDS[]={"begin","if","then","while","do","end",_KEY_WORD_END};/*可扩充的关键字数组*/
WORDS* scaner();/*词法扫描函数,获得一个单词*/
void WriteKeyWord(char *str);/*高亮输出文字*/
int main()
{
int over=1;
WORDS* oneword=new WORDS;
printf("Enter Your words(end with #):\n");
scanf("%[^#]s",input);/*读入源程序字符串到缓冲区,以#结束,允许多行输入*/
getchar();
p_input=0;
printf("Your words:\n%s\n",input);
printf("The sequence as follow:\n( 字符\t, 种别码 )\n");
while(over<1000&&over!=-1){/*对源程序进行分析,直至结束符#*/
oneword=scaner();/*获得一个新单词*/
if(oneword->typenum<1000){
printf("( ");
WriteKeyWord(oneword->word);
printf("\t,%5d )\n",oneword->typenum);/*打印种别码和单词自身的值*/
}
over=oneword->typenum;
}
return 0;
}
/**************
*需要用到的自编函数参考实现
*从输入缓冲区读取一个字符到ch中
**************************/
char m_getch(){
ch=input[p_input];
p_input=p_input+1;
return (ch);
}
/**************
*去掉空白符
**************/
void getbc(){
while(ch==' '||ch==10){
ch=input[p_input];
p_input=p_input+1;
}
}
/**************
*拼接单词
**************/
void concat(){
token[p_token]=ch;
p_token=p_token+1;
token[p_token]='\0';
}
/**************
*判断是否为字母
**************/
int letter(){
if(ch>='a'&&ch<='z'||ch>='A'&&ch<='Z')return 1;
else return 0;
}
/**************
*判断是否为数字
**************/
int digit(){
if(ch>='0'&&ch<='9')return 1;
else return 0;
}
/**************
*检索关键字表格
**************/
int reserve(){
int i=0;
while(strcmp(KEY_WORDS[i],_KEY_WORD_END)){
if(!strcmp(KEY_WORDS[i],token)){
return i+1;
}
i=i+1;
}
return 10;
}
/**************
*回退一个字符
**************/
void retract(){
p_input=p_input-1;
}
/****************
*数字转换成二进制
****************/
char* dtb(){
/*Enter Your Code!*/
return NULL;
}
/**************
*词法扫描函数
**************/
WORDS* scaner(){
WORDS* myword=new WORDS;
myword->typenum=10;
myword->word="";
p_token=0;
m_getch();
getbc();
if(letter()){
while(letter()||digit()){
concat();
m_getch();
}
retract();
myword->typenum=reserve();
myword->word=token;
return(myword);
}
else if(digit()){
while(digit()){
concat();
m_getch();
}
retract();
myword->typenum=11;
myword->word=token;
return(myword);
}
else switch(ch){
case '=': m_getch();
if (ch=='='){
myword->typenum=39;
myword->word="==";
return(myword);
}
retract();
myword->typenum=21;
myword->word="=";
return(myword);
break;
case '+': myword->typenum=13;
myword->word="+";
return(myword);
break;
case '-': myword->typenum=14;
myword->word="-";
return(myword);
break;
case '*': myword->typenum=15;
myword->word="*";
return(myword);
break;
case '/': myword->typenum=16;
myword->word="/";
return(myword);
break;
case '(': myword->typenum=27;
myword->word="(";
return(myword);
break;
case ')': myword->typenum=28;
myword->word=")";
return(myword);
break;
case '[': myword->typenum=29;
myword->word="[";
return(myword);
break;
case ']': myword->typenum=30;
myword->word="]";
return(myword);
break;
case '{': myword->typenum=31;
myword->word="{";
return(myword);
break;
case '}': myword->typenum=32;
myword->word="}";
return(myword);
break;
case ',': myword->typenum=33;
myword->word=",";
return(myword);
break;
case ':': m_getch();
if (ch=='='){
myword->typenum=18;
myword->word=":=";
return(myword);
}
retract();
myword->typenum=17;
myword->word=":";
return(myword);
break;
case ';': myword->typenum=26;
myword->word=";";
return(myword);
break;
case '>': m_getch();
if (ch=='='){
myword->typenum=24;
myword->word=">=";
return(myword);
}
retract();
myword->typenum=23;
myword->word=">";
return(myword);
break;
case '<': m_getch();
if (ch=='='){
myword->typenum=22;
myword->word="<=";
return(myword);
}
retract();
myword->typenum=20;
myword->word="<";
return(myword);
break;
case '!': m_getch();
if (ch=='='){
myword->typenum=21;
myword->word="!=";
return(myword);
}
retract();
myword->typenum=-1;
myword->word="ERROR";
return(myword);
break;
case '\0': myword->typenum=1000;
myword->word="OVER";
return(myword);
break;
default: myword->typenum=-1;
myword->word="ERROR";
return(myword);
}
}
/* 函数功能: 高亮显示指定字符串 */
void WriteKeyWord(char *str)
{
COORD pos;
CONSOLE_SCREEN_BUFFER_INFO csbi;
DWORD len; //指向变量的指针,用来存放字符的实际数目
WORD att=FOREGROUND_GREEN | FOREGROUND_INTENSITY;
gh_std_out = GetStdHandle(STD_OUTPUT_HANDLE); //获取标准输出设备句柄
if (GetConsoleScreenBufferInfo(gh_std_out, &csbi))
{
pos.Y=csbi.dwCursorPosition.Y;
pos.X=csbi.dwCursorPosition.X;
}
SetConsoleCursorPosition(gh_std_out,pos);
printf("%s ",str);
FillConsoleOutputAttribute(gh_std_out,att,strlen(str),pos,&len);
}
1.6 词法实验结果及结果分析
输入begin x:=9: if x>9 then x:=2*x+1/3; end #
程序输出序列的结果如下图3所示:
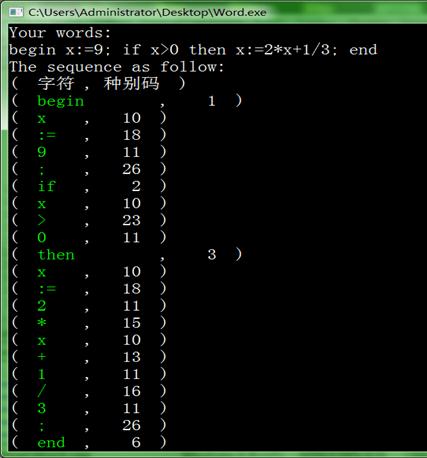
图3 程序运行结果
2 实验二 语法分析
2.1 实验目的
编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
2.2 实验要求
利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
1、 待分析的简单语言的语法
用扩充的BNF表示如下:
⑴<程序>::=begin<语句串>end
⑵<语句串>::=<语句>{;<语句>}
⑶<语句>::=<赋值语句>
⑷<赋值语句>::=ID:=<表达式>
⑸<表达式>::=<项>{+<项> | -<项>}
⑹<项>::=<因子>{*<因子> | /<因子>
⑺<因子>::=ID | NUM | (<表达式>)
2、 实验要求说明
输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。例如:
输入 begin a:=9; x:=2*3; b:=a+x end # 输出 success!
输入 x:=a+b*c end # 输出 error
2.3 算法思想
(1)主程序示意图如图4所示。
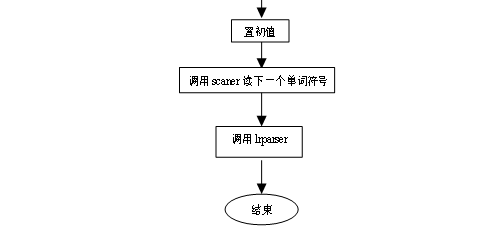
图4 语法分析主程序示意图
(2)递归下降分析程序示意图如图5所示。
(3)语句串分析过程示意图如图6所示。
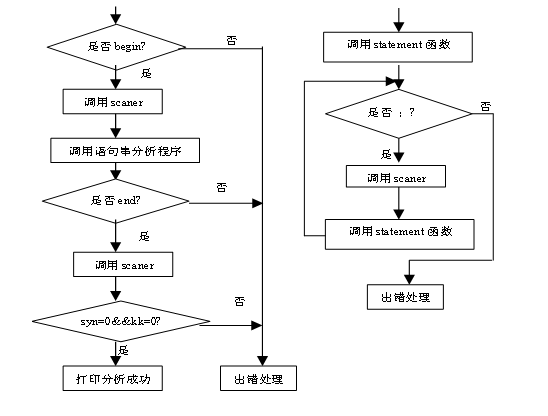
图5 递归下降分析程序示意图 图6语句串分析示意图
(4)statement语句分析程序流程如图7,8,9,10所示。
 图7 statement语句分析函数示意图 图8 expression表达分析函数示意图
图7 statement语句分析函数示意图 图8 expression表达分析函数示意图
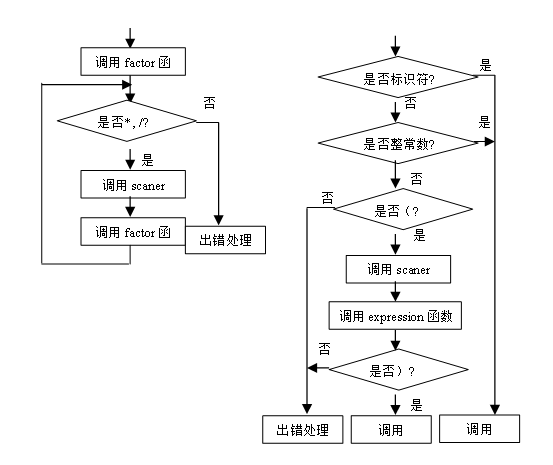
图9 term分析函数示意图 图10 factor分析过程示意图
2.4 实验程序设计说明
1、数据结构的设计
本程序中主要功能是完成文法正确性的判断,因此没有特别的需要使用到结构体等数据结构。本程序中主要使用了一个数组rwtab用于存放语法关键字{begin,if,then,while,do,end}。
2、算法设计
首先程序读入用户输入的文法语句,然后使用scaner函数进行字符串的分离处理,即读出一个一个单独的字符串,然后使用递归下降的分析方式进行语法分析。
2.5 语法分析实现
【使用C语言实现】
#include <stdio.h>
#include <string.h>
char prog[100],token[8],ch;
char *rwtab[6]={"begin","if","then","while","do","end"};
int syn,p,m,n,sum;
int kk;
int factor();
int expression();
int yucu();
int term();
int statement();
int lrparser();
int scaner();
int main()
{
p=kk=0;
printf("Please input your sentence (end with '#'): \n");
do
{
scanf("%c",&ch);
prog[p++]=ch;
}while(ch!='#');
p=0;
scaner();
lrparser();
return 0;
}
int lrparser()
{
if(syn==1)
{
scaner(); /*读下一个单词符号*/
yucu(); /*调用yucu()函数;*/
if (syn==6)
{
scaner();
if ((syn==0)&&(kk==0))
printf("Success!\n");
}
else
{
if(kk!=1) printf("The sentence haven't got a 'end'!\n");
kk=1;
}
}
else
{
printf("The sentence haven't got a 'begin'!\n");
kk=1;
}
return 0;
}
int yucu()
{
statement(); /*调用函数statement();*/
while(syn==26)
{
scaner(); /*读下一个单词符号*/
if(syn!=6)
statement(); /*调用函数statement();*/
}
return 0;
}
int statement()
{
if(syn==10)
{
scaner(); /*读下一个单词符号*/
if(syn==18)
{
scaner(); /*读下一个单词符号*/
expression(); /*调用函数statement();*/
}
else
{
printf("the letter ':=' is wrong!\n");
kk=1;
}
}
else
{
printf("wrong sentence!\n");
kk=1;
}
return 0;
}
int expression()
{
term();
while((syn==13)||(syn==14))
{
scaner(); /*读下一个单词符号*/
term(); /*调用函数term();*/
}
return 0;
}
int term()
{
factor();
while((syn==15)||(syn==16))
{
scaner(); /*读下一个单词符号*/
factor(); /*调用函数factor(); */
}
return 0;
}
int factor()
{
if((syn==10)||(syn==11)) scaner();
else if(syn==27)
{
scaner(); /*读下一个单词符号*/
expression(); /*调用函数statement();*/
if(syn==28)
scaner(); /*读下一个单词符号*/
else
{
printf("the error on '('\n");
kk=1;
}
}
else
{
printf("the expression error!\n");
kk=1;
}
return 0;
}
int scaner()
{
sum=0;
for(m=0;m<8;m++) token[m++]=NULL;
m=0;
ch=prog[p++];
while(ch==' ')ch=prog[p++];
if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A')))
{
while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9')))
{
token[m++]=ch;
ch=prog[p++];
}
p--;
syn=10;
token[m++]='\0';
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{ syn=n+1;
break;
}
}
else if((ch>='0')&&(ch<='9'))
{
while((ch>='0')&&(ch<='9'))
{
sum=sum*10+ch-'0';
ch=prog[p++];
}
p--;
syn=11;
}
else
switch(ch)
{
case '<': m=0;
ch=prog[p++];
if(ch=='>')
{
syn=21;
}
else if(ch=='=')
{
syn=22;
}
else
{
syn=20;
p--;
}
break;
case '>': m=0;
ch=prog[p++];
if(ch=='=')
{
syn=24;
}
else
{
syn=23;
p--;
}
break;
case ':': m=0;
ch=prog[p++];
if(ch=='=')
{
syn=18;
}
else
{
syn=17;
p--;
}
break;
case '+': syn=13; break;
case '-': syn=14; break;
case '*': syn=15;break;
case '/': syn=16;break;
case '(': syn=27;break;
case ')': syn=28;break;
case '=': syn=25;break;
case ';': syn=26;break;
case '#': syn=0;break;
default: syn=-1;break;
}
return 0;
}
2.6 词法实验结果及结果分析
1、输入 begin a:=9; x:=2*3; b:=a+x end # 后输出Success!如下图11所示:
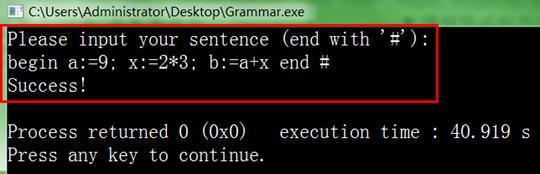
图11 语法分析成功
2、输入 x:=a+b*c end # 后输出错误信息如下图12所示:
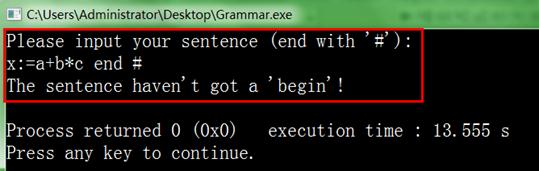
图12 语法分析失败
4 实验中遇到的问题及解决
实验一过程中参考课本中的实验说明以及样例代码,基本上实现起来没多大的问题。
不过实验二过程中按照课本上的思路来写的话还是遇到一些问题:比如一开始测试的时候结果老是不对,后来调试的时候我才发现是忘记对运算符“:=”进行定义了,导致程序识别不出而报错,基本上实验二就是在实验一的基础上稍微改动一下。
当然这两次实验还有许多待改进的地方,比如实验二中报错部分的改进,可以进一步分析得出具体错误原因,以及错误发生在那个位置等。总之这两次实验还有许多加强的地方。
参考资料
[1]刘铭、徐兰芳、骆婷 . 编译原理 . 北京:电子工业出版社,2011
[2] 参考网址http://www.ibm.com/developerworks/cn/linux/sdk/lex/
课程实验的评分:

指导老师签字:
时间: 年 月 日
-
编译原理实验报告
ltlt编译原理gtgt上机实验报告编译原理上机实验报告一实验目的与要求目的在分析理解一个教学型编译程序如PL0的基础上对其词法分…
-
《编译原理》课程实验报告(词法分析)完整版
编译原理课程实验报告题目专业计算机指导教师签名华东理工大学信息学院计算机系20xx年4月10日一实验序号编译原理第一次实验二实验题…
-
编译原理-词法语法分析实验报告
编译原理词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。二、实验要求2.1待分析的简单的词法(1)…
-
编译原理 实验报告
编译原理实验报告指导教师1一实验目的基本掌握计算机语言的词法分析程序的开发方法以及掌握计算机语言的语法分析程序设计与属性文法应用的…
-
编译原理实验报告完整版(河北工业)
编译原理实验报告班级姓名学号自我评定75实验一词法分析程序实现一实验目的与要求通过编写和调试一个词法分析程序掌握在对程序设计语言的…
-
编译原理上机实验报告
编译技术上机实验题目实验一一题目编制C语言子集的词法分析程序二目的通过设计编制调试一个具体的词法分析程序加深对词法分析原理的理解并…
-
编译原理-语法分析实验报告
课程实验报告课程名称:编译原理(语法分析)专业班级:信息安全1001班学号:姓名:指导教师:报告日期:20XX/11/8计算机科学…
-
编译原理 语法分析 实验报告
编译原理实验报告编译原理实验报告1编译原理实验报告一实验内容设计编制并调式一个语法分析程序加深对语法分析原理的理解二实验目的及要求…
-
武汉理工大学编译原理实验报告
武汉理工大学学生实验报告书实验课程名称编译原理开课学院计算机科学与技术学院指导老师姓名饶文碧学生姓名学生专业班级软件20xx20x…
-
编译原理实验报告
编译原理实验报告姓名余同庆班级软件1005班学号3902100509日期20xx67中南大学软件学院20xx年06月第一部分词法分…
-
编译原理上机实验报告
编译原理课内实验报告学院计算机学院专业计算机科学与技术年级班别20xx级6班学号31120xx028学生姓名曾主赐辅导教师刘添添成…