数据挖掘报告(模板)
第一章:数据挖掘基本理论
数据挖掘的产生:
随着计算机硬件和软件的飞速发展,尤其是数据库技术与应用的日益普及,人们面临着快速扩张的数据海洋, 如何有效利用这一丰富数据海洋的宝藏为人类服务业已成为广大信息技术工作者的所重点关注的焦点之一。与日趋成熟的数据管理技术与软件工具相比,人们所依赖的数据分析工具功能,却无法有效地为决策者提供其决策支持所需要的相关知识,从而形成了一种独特的现象“丰富的数据,贫乏的知识” 。
为有效解决这一问题,自二十世纪90年代开始,数据挖掘技术逐步发展起来,数据挖掘技术的迅速发展,得益于目前全世界所拥有的巨大数据资源以及对将这些数据资源转换为信息和知识资源的巨大需求,对信息和知识的需求来自各行各业,从商业管理、生产控制、市场分析到工程设计、科学探索等。数据挖掘可以视为是数据管理与分析技术的自然进化产物。自六十年代开始,数据库及信息技术就逐步从基本的文件处理系统发展为更复杂功能更强大的数据库系统;七十年代的数据库系统的研究与发展,最终导致了关系数据库系统、数据建模工具、索引与数据组织技术的迅速发展,这时用户获得了更方便灵活的数据存取语言和界面;此外在线事务处理手段的出现也极大地推动了关系数据库技术的应用普及,尤其是在大数据量存储、检索和管理的实际应用领域。
自八十年代中期开始,关系数据库技术被普遍采用,新一轮研究与开发新型与强大的数据库系统悄然兴起,并提出了许多先进的数据模型:扩展关系模型、面向对象模型、演绎模型等;以及应用数据库系统:空间数据库、时序数据库、多媒体数据库等;日前异构数据库系统和基于互联网的全球信息系统也已开始出现并在信息工业中开始扮演重要角色。

被收集并存储在众多数据库中且正在快速增长的庞大数据,已远远超过人类的处理和分析理解能力 (在不借助功能强大的工具情况下) , 这样存储在数据库中的数据就成为“数据坟墓” ,即这些数据极少被访问,结果许多重要的决策不是基于这些基础数据而是依赖决策者的直觉而制定的,其中的原因很简单,这些决策的制定者没有合适的工具帮助其从数据中抽取出所需的信息知识。而数据挖掘工具可以帮助从大量数据中发现所存在的特定模式规律,从而可以为商业活动、科学探索和医学研究等诸多领域提供所必需的信息知识。数据与信息知识之间的巨大差距迫切需要系统地开发数据挖掘工具,来帮助实现将“数据坟墓”中的数据转化为知识财富。
数据挖掘的概念:
数据挖掘,在人工智能领域,习惯上又称为数据库中知识发现(Knowledge Discovery in Database, KDD), 也有人把数据挖掘视为数据库中知识发现过程的一个基本步骤。知识发现过程以下三个阶段组成:(1)数据准备,(2)数据挖掘,(3)结果表达和解释。数据挖掘可以与用户或知识库交互。
并非所有的信息发现任务都被视为数据挖掘。例如,使用数据库管理系统查找个别的记录,或通过因特网的搜索引擎查找特定的Web页面,则是信息检索(information retrieval)领域的任务。虽然这些任务是重要的,可能涉及使用复杂的算法和数据结构,但是它们主要依赖传统的计算机科学技术和数据的明显特征来创建索引结构,从而有效地组织和检索信息。尽管如此,数据挖掘技术也已用来增强信息检索系统的能力。
数据挖掘的步骤:
1.确定挖掘对象:定义清晰的挖掘对象,认清数据挖掘的目标是数据挖掘的第一步。数据挖掘的最后结果往往是不可预测的,但是要解决的问题应该是有预见性的、有目标的。在数据挖掘的第一步中,有时还需要用户提供一些先验知识。这些先验知识可能是用户的业务领域知识或是以前数据挖掘所得到的初步成果。这就意味着数据挖掘是一个过程,在挖掘过程中可能会提出新的问题;可能会尝试用其他的方法来检验数据,在数据的子集上展开研究。
2.数据收集:数据是挖掘知识最原始的资料。“垃圾进,垃圾出”,只有从正确的数据中才能挖掘到有用的知识。为特定问题选择数据需要领域专家参加。因此,领域问题的数据收集好之后,和目标信息相关的属性也选择好了。
3.数据预处理:数据选择好以后,就需要对数据进行预处理。数据预处理包括:去除错误数据和数据转换。错误数据,在统计学中称为异常值,应该在此阶段发现并且删除。否则,它们将导致产生错误的挖掘结果。同时,需要将数据转换成合适的形式。例如,在某些情况下,将数据转换成向量形式。另外,为了寻找更多重要的特征和减少数据挖掘步骤的负担,我们可以将数据从一个高维空间转换到一个低维空间。
4.数据挖掘:数据挖掘步骤主要是根据数据建立模型。我们可以在这个步骤使用各种数据挖掘算法和技术。然而,对于特定的任务,需要选择正确合适的算法,来解决相应的问题。
5.信息解释:首先,通过数据挖掘技术发现的知识需要专家对其进行解释,帮助解决实际问题。然后,根据可用性、正确性、可理解性等评价指标对解释的结果进行评估。只有经过这一步骤的过滤,数据挖掘的结果才能够被应用于实践。
6.可视化:可视化技术主要用来通过图形化的方式显示数据和数据挖掘的结果,从而帮助用户更好的发现隐藏在数据之后的知识。它可以被应用在数据挖掘的整个过程,包括数据预处理、数据挖掘和信息解释。数据和信息的可视化显示对用户来说非常重要,因为它能够增强可理解性和可用性。
第二章:系统分析
系统用户分析:
系统功能分析:
系统算法分析:
第三章:数据管理
数据管理的方法:
数据管理的具体实现:
第四章:数据采集
数据采集的方法
数据收集:数据是挖掘知识最原始的资料。“垃圾进,垃圾出”,只有从正确的数据中才能挖掘到有用的知识。为特定问题选择数据需要领域专家参加。因此,领域问题的数据收集好之后,和目标信息相关的属性也选择好了。
数据采集的具体实现过程
第五章:数据预处理
数据预处理的方法:
数据预处理:数据选择好以后,就需要对数据进行预处理。数据预处理包括:去除错误数据和数据转换。错误数据,在统计学中称为异常值,应该在此阶段发现并且删除。否则,它们将导致产生错误的挖掘结果。同时,需要将数据转换成合适的形式。例如,在某些情况下,将数据转换成向量形式。另外,为了寻找更多重要的特征和减少数据挖掘步骤的负担,我们可以将数据从一个高维空间转换到一个低维空间。
数据预处理的具体实现过程:
第六章:数据挖掘
算法描述与流程图
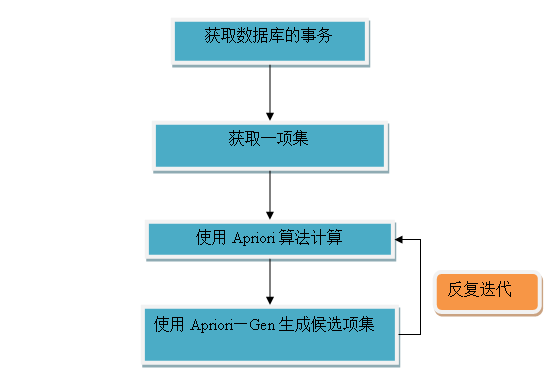
数据结构的设计
算法的具体实现
Apriori算法:
static List<ItemSet> Apriori(ArrayList D, ArrayList I, float sup)//传进的参数D为事务数据集,I为频繁一项集,sup为支持度阈值
{
List<ItemSet> L = new List<ItemSet>();//所有频繁项集
if (I.Count == 0) return L;
else
{
int[] Icount = new int[I.Count];//初始项集计数器,初始化为0
ArrayList Ifrequent = new ArrayList();//初始项集中的频繁项集
//遍历事务数据集,对项集进行计数
Regex r = new Regex(",");//正则表达式
for (int i = 0; i < D.Count; i++)
{
string[] subD = r.Split(D[i].ToString());
for (int j = 0; j < I.Count; j++)
{
string[] subI = r.Split(I[j].ToString());
bool subIInsubD = true;
for (int m = 0; m < subI.Length; m++)//频繁项集
{
bool subImInsubD = false;
for (int n = 0; n < subD.Length; n++)//事物数据集
if (subI[m] == subD[n])
{
subImInsubD = true;
continue;
}
if (subImInsubD == false) subIInsubD = false;
}
if (subIInsubD == true)
{
//int s = Icount[j];
Icount[j]++;//支持频度+1
//int t = Icount[j];
//float confi = s / t;
//ItemSet.confi = confi;
}
}
}
//从初始项集中将支持度大于给定值的项转到L中
for (int i = 0; i < Icount.Length; i++)
{
if (Icount[i] >= sup * D.Count)//判断支持度是否大于给定值,并且置信度大于给定值&&ItemSet.confi>=ItemSet.confidence*0.01
{
Ifrequent.Add(I[i]);
ItemSet iSet = new ItemSet();
iSet.Items = I[i].ToString();
iSet.Sup = Icount[i];
L.Add(iSet);
}
}
I.Clear();
I = AprioriGen(Ifrequent);//将频繁项集作为参数传给AprioriGen生成新的候选项集
L.AddRange(Apriori(D, I, sup));
return L;
}
}
Apriori—Gen方法:
static ArrayList AprioriGen(ArrayList L)
{
ArrayList Lk = new ArrayList();
Regex r = new Regex(",");
for (int i = 0; i < L.Count; i++)
{
string[] subL1 = r.Split(L[i].ToString());
for (int j = i + 1; j < L.Count; j++)
{
string[] subL2 = r.Split(L[j].ToString());
//比较L中的两个项集将它们的并集暂存于temp中
string temp = L[j].ToString();//存储两个项集的并集
for (int m = 0; m < subL1.Length; m++)
{
bool subL1mInsubL2 = false;
for (int n = 0; n < subL2.Length; n++)
{
if (subL1[m] == subL2[n]) subL1mInsubL2 = true;
}
if (subL1mInsubL2 == false) temp = temp + "," + subL1[m];
}
//当temp包含的项为(L中项集的大小)+1并且所求候选项集中没有与temp一样的项集
string[] subTemp = r.Split(temp);
if (subTemp.Length == subL1.Length + 1)
{
bool isExists = false;
for (int m = 0; m < Lk.Count; m++)
{
bool isContained = true;
for (int n = 0; n < subTemp.Length; n++)
{
if (!Lk[m].ToString().Contains(subTemp[n])) isContained = false;
}
if (isContained == true) isExists = true;
}
if (isExists == false) Lk.Add(temp);
}
}
}
return Lk;
}
第七章:结果显示与解释评估
参数设置:
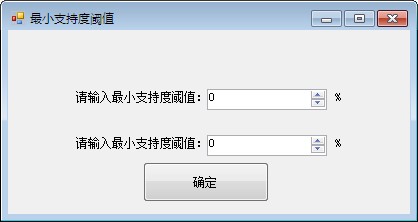
在程序开始计算之前,需要输入两个参数:最小支持度阈值与最小置信度阈值。
结果显示界面的具体实现
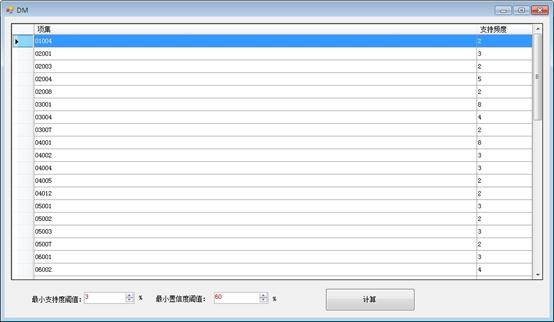
程序用一个C#里边的DataGridView显示,一个有两栏,左边的项集是生成的项集,右边的支持频度指的是该项集的出现的次数。
解释评估
学习体会
通过两周的软件开发综合训练,做了这个数据挖掘的题目,对数据挖掘有了生加深了的认识,因此认识到了数据挖掘的重要性,它很大程度的帮助人们把从大量的无序的数据中获得知识,指导人们做出决策。在这次数据挖掘的过程中,我做的是用Apriori算法对超市的销售记录进行数据挖掘。从而找出符合置信度阈值与支持度阈值的商品的项集。在编程的过程中,我也遇到过一些问题,通过对这些问题的解决,我发现自己的编程能力也有了一定的提高。
参考文献
[1].数据挖掘概念与技术,范明,孟小峰 译/20##年03月/机械工业出版社.
[2].数据挖掘原理与算法(第二版)毛国君等编著/20##年12月/清华大学出版社.
致谢
在这次课程设计中,得到了 孙士保、白秀玲、魏汪洋、赵海霞四位老师的耐心指导,帮助我解决了知识上的难题,教会我了很多的东西,再次,诚挚的感谢诸位老师,谢谢你们!
第二篇:《数据仓库与数据挖掘》课程设计报告模板
江西理工大学应用科学学院
《数据仓库与数据挖掘》课程设计报告
题 目:某超市数据集的OLAP分析及数据挖掘
系 别:
班 级:
姓 名:
二〇##年六月
目 录
一、建立数据仓库数据库结构和设置数据源............................................................... 1
1. 任务描述..................................................................................................................... 2
2. 建立数据仓库数据库...................................................................................................
3. 设置数据源.................................................................................................................
二、销售数据OLAP分析..............................................................................................
1. 任务描述.....................................................................................................................
2. 设计星型架构多维数据集(Sales)..................................................................................
3. 设计存储和数据集处理................................................................................................
4. OLAP分析..................................................................................................................
三、人力资源数据OLAP分析......................................................................................
1. 任务描述....................................................................................................................
2. 设计父子维度的多维数据集(HR).................................................................................
3. 修改多维数据集(HR)的结构........................................................................................
4. 设计存储和数据集处理...............................................................................................
5. OLAP分析..................................................................................................................
四、数据仓库及多维数据集其它操作...........................................................................
1. 任务描述....................................................................................................................
2. 设置数据仓库及多维数据集角色及权限.......................................................................
3. 查看元数据.................................................................................................................
4. 创建对策....................................................................................................................
5. 钻取...........................................................................................................................
6. 建立远程 Internet 连接...............................................................................................
五、数据仓库高级操作...................................................................................................
1. 任务描述.....................................................................................................................
2. 创建分区.....................................................................................................................
3. 创建虚拟多维数据集...................................................................................................
4. DTS调度多维数据集处理............................................................................................
5. 备份/还原数据仓库 ....................................................................................................
六、数据挖掘...................................................................................................................
1. 任务描述.....................................................................................................................
2. 创建揭示客户模式的决策树挖掘模型...........................................................................
3. 决策树挖掘结果分析...................................................................................................
4. 创建聚类挖掘模型.......................................................................................................
5. 聚类挖掘结果分析.......................................................................................................
6. 创建基于关系数据表的决策树挖掘模型.......................................................................
7. 浏览“相关性网络”视图............................................................................................
一、建立数据仓库数据库结构和设置数据源
1、任务描述
数据仓库数据库是将要在其中存放多维数据集、角色、数据源、共享维度和挖掘模型的一种结构。然后跟预先设置好的ODBC数据源建立连接。
2、建立数据仓库数据库
(1) 展开树视图的Analysis Servers;
(2) 单击服务器名或右击选择连接,与Analysis Servers建立连接;
(3) 右击服务器名,然后单击“新建数据库”命令;
(4) 在“数据库”对话框中输入数据库名“教程DW”,单击<确定>;
3、设置数据源
(5) 展开刚创建的“教程DW”数据库,可看到如下项目:数据源、多维数据集、共享维度、挖掘模型、数据库角色
(6) 右击“教程DW”数据库下的“数据源”文件夹,然后单击“新数据源”命令;
(7) 在“数据链接属性”对话框中,单击“提供程序”选项卡,选择“Microsoft OLE DB Provider for ODBC Drivers”;
(8) 单击“连接”选项卡,选择建好的ODBC数据源“FoodMart 2000”;
(9) 单击<确定>按钮关闭“数据链接属性”对话框
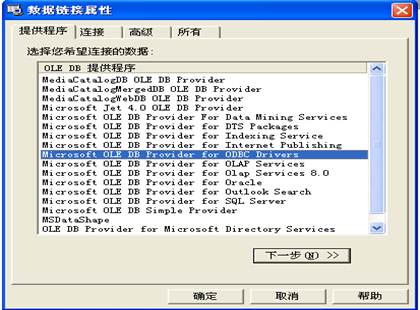

图表 1 连接数据源
二、销售数据OLAP分析
1. 任务描述
以多维方式建立数据模型可简化联机业务分析,提高查询性能。通过创建多维数据集,Analysis Manager 可将存储在关系数据库中的数据转换为具有实际含义并且易于查询的业务信息。
2. 设计星型架构多维数据集(Sales)
星型架构的多维数据集由一个事实数据表和链接到该事实数据表的多个维度表组成。
下面针对FoodMart超市1998年的销售业务数据,建立一个多维数据集,以便按产品和顾客2个主题展开分析。具体操作如下:
(1)展开树窗格的“教程DW”,右击“多维数据集”,选择“新建多维数据集”→“向导…”菜单命令,打开如下“多维数据集向导”对话框。
(2)向多维数据集添加度量值(事实) :
(3)单击<下一步>,在“从数据源中选择事实数据表”步骤中,展开“FoodMart”数据源,然后单击“sales_fact_1998”;
(4)单击<下一步>,设置多维数据集的度量值列: store_sales、store_cost、unit_sales;
(5)单击<下一步>,建立维度表。单击<新建维度>,打开“维度向导”对话框;
1) 向多维数据集添加时间维:
(1)选择维度类型为“星型架构:单个维度表”;
(2)单击<下一步>,选择维度表“time_by_day”;
(3)单击<下一步>,选择维度类型为“时间维度”;
(4)单击<下一步>,选择时间级别为“年、季度、月”;
(5)单击<下一步>,单击<下一步>,输入时间维名称: Time,并设为“共享”方式,单击<完成>,OK!
2) 向多维数据集添加产品维:
(1)再次单击<新建维度>,打开“维度向导”对话框;
(2)选择创建维度的方式为“雪花架构:多个相关维度表”;
(3)单击<下一步>,选择维度表“Product”和“product_class”;
(4)单击<下一步>,查看连接方式,在这里可删除不要的连接,添加需要的连接;
(5)单击<下一步>,依次选择product_category、product_subcategory和brand_name三个维度级别;
(6)单击<下一步>,指定成员键列步骤中,不需改变主键列;
(7)单击<下一步>,在“高级选项”步骤中,根据需要选择;
(8)单击<下一步>,输入产品维名称: Product,并设为“共享”方式,单击<完成>,OK!
3) 向多维数据集添加客户维度:
(1)再次单击<新建维度>,打开“维度向导”对话框;
(2)选择创建维度的方式为“星型架构:单个维度表”;
(3)单击<下一步>,选择维度表“Customer”;
(4)单击<下一步>,选择维度类型为“标准维度”;
(5)单击<下一步>,依次选择Country、State_Province、City和lname四个维度级别;
(6)单击<下一步>,指定成员键列步骤中,不需改变主键列;
(7)单击<下一步>,在“高级选项”步骤中,根据需要选择;
(8)单击<下一步>,输入客户维名称: Customer,并设为“共享”方式,单击<完成>,OK!
4) 生成多维数据集:
(1)回到多维数据集向导对话框,这里已 到了新建的4个维度;
(2)单击<下一步>,在“是否计算事实数据表行数提问时,单击<是>,开始计算。
(3)计算完成后,命名多维数据集为:Sales,单击<完成>,OK!
(4)关闭向导,随之启动多维数据集编辑器,其中可看到刚刚创建的多维数据集。单击蓝色或黄色的标题栏,对表进行排列,使其符合下图所示的样子
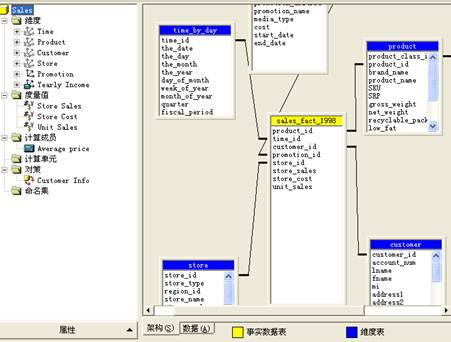
图表 2 “Sales多维数据集编辑器”窗口
3. 设计存储和数据集处理:
设计好 Sales 多维数据集的结构之后,需要选择数据的存储模式(MOLAP、ROLAP或HOLAP),并指定要存储的预先计算好的值的数量,然后用数据填充多维数据集。
本例选择MOLAP作为存储模式,创建Sales多维数据集的聚合设计,然后从ODBC源中装载数据并按照聚合设计中的定义计算汇总值。
(1)展开树窗格,右击“Sales”多维数据集,选择“设计存储…”菜单命令,弹出“存储设计向导”对话框;也可在多维数据集编辑窗口中选择“工具|设计存储…”菜单命令,打开“存储设计向导”对话框;
(2)单击<下一步>,然后选择“MOLAP”作为数据存储类型 ;
(3)单击<下一步>,设置聚合选项为“性能提升达到”,并输入“40”作为指定百分比,以此优化能力平衡查询性能和存储空间大小。
(4)单击<开始>,完成后可看到“性能与大小”图,从中可看出增加性能提升对使用额外磁盘空间的需求。
(5)单击<下一步>,选择“立即处理”,并单击<完成>,系统开始进行数据处理,处理聚合一般要花费较长一些时间。
(6)处理完成后点击<关闭>,回到Analysis Manager窗口。
(7)接下来就可浏览多维数据集的数据了。
4. OLAP分析:
联机分析处理(OLAP)是使用多维数据表达式(称为多维数据集)提供对数据仓库数据进行快速访问的常用方法。多维数据集为维度表中的数据和数据仓库中的事实数据表建立模型,并为客户端应用程序提供完善的查询和分析功能。
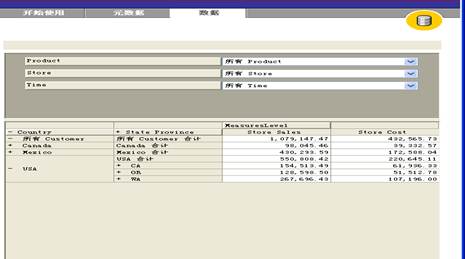
图表 3 OLAP分析图
三、人力资源数据OLAP分析
1. 任务描述:
建立一个人力资源(HR)多维数据集,以进行雇员工资分析。先把Employee维度创建为父子维度,然后使用该维度以及常规维度来生成HR多维数据集
2. 设计父子维度的多维数据集(HR):
(1)展开“教程DW”,右击“共享维度”,选择“新建维度|向导”菜单命令,打开“新建维度向导”对话框。
(2)单击<下一步>,选择维度结构为“父子:单个维度表中相关的两列”;
(3)单击<下一步>,选择维度表 employee;
(4)单击<下一步>,选择employee_id为成员键,选择supervisor_id为父键列,选择full_name为成员名。
(5)单击<下一步>,直到最后一步,输入维度名称: employee;
(6) 单击<完成>,回到维度编辑器。OK!
3. 修改多维数据集(HR)的结构
(1) 展开“教程DW”,右击“多维数据集”,选择“新建多维数据集|向导”菜单命令,打开多维数据集向导对话框。
(2) 点击<下一步>,选择salary(工资)作事实数据表;
(3) 点击<下一步>,选择salary_paid、vacation_used为度量值列;
(4) 点击<下一步>,选择Employee(雇员)、Store(商店)、Time(时间)作维度;
(5) 点击<下一步>,在提示是否计算事实数据表行数时选“是”。最后输入人力资源多维数据集的名称NR,点击<完成>,OK!
(6) 回到编辑器窗口,手工建立time_by_day表到salary表的联接,再建立 store表到employee表中的联接,删除多余的联接。最后如下图所示。
4. 设计存储和数据集处理
设计好 Sales 多维数据集的结构之后,需要选择数据的存储模式(MOLAP、ROLAP或HOLAP),并指定要存储的预先计算好的值的数量,然后用数据填充多维数据集。
本例选择MOLAP作为存储模式,创建Sales多维数据集的聚合设计,然后从ODBC源中装载数据并按照聚合设计中的定义计算汇总值。
(1)展开树窗格,右击“Sales”多维数据集,选择“设计存储…”菜单命令,弹出“存储设计向导”对话框;也可在多维数据集编辑窗口中选择“工具|设计存储…”菜单命令,打开“存储设计向导”对话框;
(2)单击<下一步>,然后选择“MOLAP”作为数据存储类型 ;
(3)单击<下一步>,设置聚合选项为“性能提升达到”,并输入“40”作为指定百分比,以此优化能力平衡查询性能和存储空间大小。
(4)单击<开始>,完成后可看到“性能与大小”图,从中可看出增加性能提升对使用额外磁盘空间的需求。
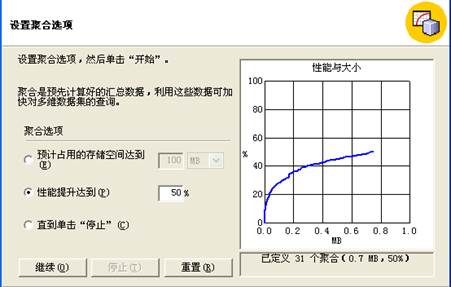
图表 4 性能与大小
(5)单击<下一步>,选择“立即处理”,并单击<完成>,系统开始进行数据处理,处理聚合一般要花费较长一些时间。
(6)处理完成后点击<关闭>,回到Analysis Manager窗口。
(7)接下来就可浏览多维数据集的数据了。
5. OLAP分析
联机分析处理(OLAP)是使用多维数据表达式(称为多维数据集)提供对数据仓库数据进行快速访问的常用方法。多维数据集为维度表中的数据和数据仓库中的事实数据表建立模型,并为客户端应用程序提供完善的查询和分析功能。
四、数据仓库及多维数据集其它操作
1 任务描述
多维数据集角色用于定义可以访问和查询多维数据集的用户或组,指出其可以访问的对象,以及对这些对象的访问类型。
角色是保护多维数据集内对象和数据安全的主要方法,可以在多维数据集的不同粒度级别上设置安全性。要定义安全性必须先创建角色,然后向这些角色授予权限。
我们要创建Sales和HR角色分别用于访问多维数据集Sales和HR。Management角色用于管理整个数据仓库。
2 设置数据仓库及多维数据集角色及权限
多维数据集角色用于定义可以访问和查询多维数据集的用户或组,指出其可以访问的对象,以及对这些对象的访问类型。
角色是保护多维数据集内对象和数据安全的主要方法,可以在多维数据集的不同粒度级别上设置安全性。要定义安全性必须先创建角色,然后向这些角色授予权限。
本例中,我们要创建Sales和HR角色分别用于访问多维数据集Sales和HR。Management角色用于管理整个数据仓库。
具体操作如下:
2.1 创建多维数据集角色:
(1) 展开“多维数据集”文件夹,右击“Sales”多维数据集,并选择“管理角色”命令,打开“多维数据集角色管理器”;
(2) 目前还没角色显示在角色列表中。点击<新建…>,打开新建角色对话框,并输入角色名:Marketing,表示市场部;
(3) 在“成员资格”选项卡中单击<添加>按钮,接着在“添加用户和组”对话框中,添加该角色的网络用户名(如hzm),单击<确定>回到新建对话框框框;
(4) 其它选项可暂不设定,直接点<确定>,回到角色管理器窗口,角色Marketing就已在列表中了。在这里可以看到各个角色的权限,也可修改它们的权限。
(5) <关闭>角色管理器。然后用同样的方法创建多维数据集HR的角色HR。
2.2 创建数据库角色:
数据库角色是可在数据库范围内使用的角色,可指派给该数据库的一个或多个多维数据集。本例中我们可以为经理创建一个数据库角色,然后将其指派到Sales和HR两个多维数据集。具体操作如下:
(1) 在“教程DW”数据库下右击“数据库角色”,然后选择“管理角色”命令,打开“数据库角色管理器”窗口;
(2) 这里显示了“教程DW”数据库中现有角色的列表(包括刚建的Marketing和HR多维数据集角色);
(3) 单击<新建>,在弹出的对话框中输入角色名:Management,然后为该角色添加用户或组(如admin),并勾选多维数据集Sales和HR。最后点击<关闭>退出
3 查看元数据
(1) 元数据是关于数据属性和数据结构的信息,此信息显示在 Analysis Manager 右窗格中。
(2) 查看多维数据集的元数据:展开“多维数据集”文件夹,单击某多维数据集,再单击右窗格的“元数据”;
(3) 查看维度的元数据:展开“共享维度”文件夹,单击一个维度,再单击右窗格的“元数据”。
4 创建对策
对策是指由最终用户启动的、在所选多维数据集或其某部分上执行的操作。
Analysis Services管理员可以定义以下几种类型的对策:命令行、URL、OLE DB语句或多维表达式 (MDX) 语句。
本例假设市场部想要针对上一节中创建的Sales多维数据集,能在分析过程的某一点跳转到Internet,以便能够搜索并找到关于某个特定客户的信息。
操作步骤如下:
(1)展开“教程DW”数据库,右击“Sales”多维数据集,然后选择“编辑”命令,打开多维数据集编辑器;
(2)右击“对策”文件夹,然后选择“新建对策”命令,启动对策向导,点击<下一步>;
(3)在“目标”框中选择“此多维数据集中的某一维度”,并单击“Customer”,点击<下一步> ;
(4)保持“对策类型”列表不变,继续单击<下一步>;
(5)在“定义对策语法”步骤中键入:“http://search.msn.com/ results.asp?q=” + [Customer].currentmember.name,意思是“通过浏览器调用MSN 搜索引擎搜索Customer维度中的当前客户的信息。

图表 5 对策语法图
(6)继续单击<下一步>,输入对策名称:Customer Info,点击完成。OK!
5 钻取
本例假设市场部希望对商店和客户按从上到下进行分析,最终深化到关系数据库中的事务级别。为此,我们要在 Sales 多维数据集内启用钻取,然后浏览数据并深化到事务。
具体操作如下:
(1)展开“教程DW”数据库,右击“Sales”多维数据集并选择“编辑”命令,打开多维数据集编辑器;
(2)单击“工具|钻取选项…”菜单命令,打开“钻取选项”对话框;
(3)选择“启用钻取”复选框,并单击<全选>以选中所有列,然后单击<确定>,关闭对话框;
(4)接下来为不同的角色分配钻取权限。
(5)右击“Sales”多维数据集,并选择“管理角色…”命令,打开角色管理器;
(6)单击前面创建的“Management”角色,然后在“钻取”列中单击 <...> 按钮,打开角色权限设置对话框;
(7)选中“允许钻取”复选框,然后单击<确定>返回角色管理器;
这时可看到“Management”角色已获得钻取权。
(8)关闭角色管理器,回到分析管理器,右击“Sales”多维数据集,并选择“浏览数据…”命令,打开数据浏览器;
(9)双击展开统计列以显示不同级别的聚集数据。右击某数据(如USA→CA→Berkeley的销售额)并选择“钻取”命令,稍等将打开明细数据查看窗口,显示原始数据源中的明细数据。

图表 6 钻取
6 建立远程 Internet 连接
SQL Server Analysis Services 能让用户借助客户端工具,通过Internet连接访问分析服务器数据库和多维数据集。
本示例介绍通过 HTTP 从 Excel 连接到分析服务器并访问多维数据集的操作。
具体步骤如下:
(1)准备:在分析服务器上安装Web服务(如IIS),从分析服务器的bin文件夹中复制Msolap.asp文件到默认站点文件夹(C:\Inetpub\wwwroot)中;
(2)启动客户端 Excel,选择“数据|数据透视表和数据透视图报表…”菜单命令;
(3)在向导第1步中选择“外部数据源”,然后单击<下一步>;
(4)在向导的第2步,单击<获取数据>,打开“选择数据源”对话框,然后选择“OLAP多维数据集”选项卡,并选中“<新数据源>”,然后单击<确定>;
(5)在接下来的对话框中,输入数据源名称:RemoteSales,在驱动程序列表中选择“Microsoft OLE DB Provider for OLAP Services 8.0”,然后单击<连接>;
(6)在接下来的对话框中,选中“分析服务器”并输入URL(如 http://Localhost,然后单击<下一步>;
(7)从连接到的远程分析服务器上选择数据库列表(如教程DW),然后单击<完成>,回到上级对话框;
(8)选定包含所需数据的多维数据集(如Sales),然后单击<确定>,最后一步点击<完成>,回到Excel工作表;
(9)接下来就可以在客户端电子表格中执行OLAP了。
五、数据仓库高级操作
1. 任务描述
多维数据集的数据可以存储在一个或多个分区上,在创建多维数据集时系统会自动为其分配一个默认分区。合理地将一个逻辑多维数据集划分为多个单独的物理分区,常常可以改进查询的性能,但不正确地分区也可能导致错误。
2. 创建分区
多维数据集的数据可以存储在一个或多个分区上,在创建多维数据集时系统会自动为其分配一个默认分区。合理地将一个逻辑多维数据集划分为多个单独的物理分区,常常可以改进查询的性能,但不正确地分区也可能导致错误。
为多维数据集创建分区的步骤如下:
(1)展开“Sales”多维数据集,右击“分区”文件夹,然后选择“新建分区”命令,打开分区向导,单击<下一步>;
(2)在“指定数据源和事实数据表”步骤中,单击<更改>,然后选择“FoodMard”数据源的sales_fact_1997表,然后单击<确定>;
(3)继续单击<下一步>,在“选择数据切片(可选)”步骤中,选择“Time”维度,展(4)开“所有Time”级别并选择1997,继续单击<下一步>;
(5)在“指定分区类型”步骤中,选择“本地”并单击<下一步>;
(6)输入分区名称:Sales 97,并选择“从现有的分区(Sales)中复制聚合设计”和“完成时处理分区”,最后单击<完成>;

图表 7 分区
(7)处理完成后单击<关闭>,97年多维数据集将位于另一个名为Sales 97的分区上了。将来99、20##、…的数据也可分别存储在不同的分区上,这样既便于管理,也可提高查询的效率,特别对大型数据集,效果更加明显。
3. 创建虚拟多维数据集
虚拟维度是基于物理维度内容的逻辑维度。这些内容可以是物理维度中的现有成员属性,也可以是物理维度的表中的列。
使用虚拟维度可基于成员属性对多维数据集数据进行分析。其优点是不占用磁盘空间或处理时间。下面创建一个带有Yearly Income(年收入)成员属性的虚拟维度,然后将这个新创建的维度添加到Sales多维数据集中。操作步骤如下:
(1) 右击“共享维度”文件夹,选择“新建维度|向导”菜单命令;
(2) 单击<下一步>,选择“虚拟维度:另一个维度的成员属性”,再单击<下一步>;
(3) 在“选择带有成员属性的维度”步骤中,单击“Customer”维度,再单击 <下一步>;在“选择虚拟维度的级别”步骤中,添加“Lname.Yearly Income”成员属性后再单击<下一步>,在“高级选项”步骤中直接单击<下一步>;
(4) 在“完成”步骤中,输入维度名称 “Yearly Income”;
(5) 单击<完成>。关闭向导。新建的虚拟维度“Yearly Income”已在共享维度列表中了。接下来就可向现有多维数据集添加虚拟维度了。
4. DTS调度多维数据集处理
本例为Sales、HR和Expense Budget三多维数据集创建自动化过程,确保在每天早上3点钟从OLTP和 ERP导入前一天的新增业务数据。处理完成后再给管理员和关键用户发送电子邮件通知他们处理任务已顺利完成。
具体操作如下:
(1)选择“开始|程序|Microsoft SQL Server|企业管理器”菜单命令,启动SQL Server企业管理器;
(2)逐级展开,直到看到“数据转换服务”文件夹下的“本地包”,右击“本地包”并选择“新建包”命令,打开DTS包窗口,接下来为2个多维数据集定义处理任务;
(3)点击DTS包窗口的左窗格中的“Analysis Services处理任务”图标,并将其拖动到空白窗格中,弹出“Analysis Services 处理任务”对话框;
(4)在对话框中,给第1个任务输入名称为Sales,并输入相应的描述,如Sales任务;
展开树窗格的“教程DW”数据仓库,单击“Sales”多维数据集,然后在右窗格选择处(5)理选项,选择“完整处理”;
(6)同样的方法为“HR”多维数据集创建另1个处理任务:HR任务;
(7)接下来指定任务执行的顺序:按住<Ctrl>键,依次选择Sales任务和HR任务,然后选择“工作流|完成时”菜单命令;
(8)将左窗格中的“发送电子邮件”图标拖至右窗格中,弹出“发送邮件任务属性”对话框,设置好相关参数后点<确定>,然后设置其处理顺序。最后以“Cubes处理”为名保存该包。
(9)回到企业管理器窗口,刚创建的包位于“本地包”文件夹中,接下来要为该包设置执行时间;
(10)右击“Cube处理”包,选择“调度包…”命令,弹出“作业调度”对话框;
在“每月”频率下,设置“第末一天,每1个月”,在“每日频率”下设置:“一次发生于:3:00:00AM”,单击<确定>;
(11)至此,多维数据集定期处理任务已定制完成,可以退出企业管理器了。OK!
5. 备份/还原数据仓库
5.1 以下3种情况可能需要对数据仓库进行存档:
5.1.1创建数据仓库的压缩备份;
(1)数据仓库不再用于日常分析了,先存档后删除,以后需要时还可还原;
(2)将数据仓库从一台服务器复制到另一台服务器。
5.1.2具体操作如下:
(1)在Analysis Manager树窗格中右击“教程DW”,然后单击“将数据库存档”命令,打开存档对话框;
(2)输入存档文件(.cab)保存位置及文件名,如d:\Program Files\Microsoft Analysis Services\Samples\教程.cab,最后点击<存档>。OK!
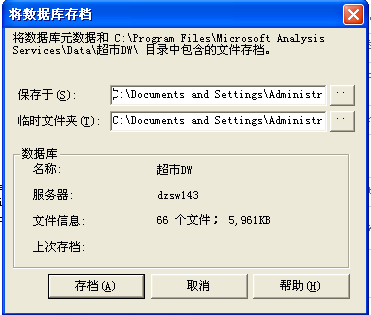
图表 8 备份
5.2删除/还原数据仓库
(1)在要删除的数据仓库(如“教程DW”)上右击,然后选择“删除”命令,提示确认时点击<是>,该数据仓库将被删除。删除数据仓库之前最好先存档!
(2)利用数据仓库的存档CAB文件可将其还原到任一台分析服务器上。具体操作如下:右击Analysis Manager 的服务器名,然后选择“还原数据库…”,在接下来的对话框中选择存档文件,最后点击<还原>,稍等,存档的数据仓库就会被还原。
六、数据挖掘
1. 任务描述
将通过实例介绍如何创建用于揭示客户模式的数据挖掘模型。
这里将创建一个数据挖掘模型以训练销售数据,并使用“Microsoft决策树”算法在客户群中找出会员卡选择模式。
将需要挖掘的维度设置为客户,将Member_Card属性设置为挖掘算法识别模式的参考信息。然后从人口统计特征列表中确定模式:婚姻状况、年收入、在家子女数和教育程度。下一步需要训练模型,以便能够浏览树视图并从中读取模式。市场部将根据这些模式设计新的会员卡,实际上就是对会员卡重新分类
2. 创建揭示客户模式的决策树挖掘模型
(1)展开“多维数据集”文件夹,右击“Sales”多维数据集,然后选择“新建挖掘模型”命令,打开挖掘模型向导;
(2)在“选择数据挖掘技术”步骤中,选择“Microsoft决策树”,然后单击<下一步>;
(3)在“选择事例”步骤中,选择维度为Customer, 级别选择Lname,然后单击<下一步>;
(4)在“选择被预测实体”步骤中,选择“事例级别的成员属性”,并选择“Member Card”,继续单击<下一步>;
(5)在“选择训练数据”步骤中,取消Customer维度的Country、State Province和City聚集成员前的勾√,继续单击<下一步>;

图表 9 勾选成员
(6)接下来输入新维度名“Customer Patterns”, “虚拟多维数据集名“Trained Cube”,继续单击<下一步>;
(7)在最后的步骤输入模型名“Customer patterns discovery”,并选择“保存并开始处理”,然后单击<完成>;

图表 10 模型向导
(8)处理完成后,单击<关闭>,然后“OLAP挖掘模型编辑器”将打开,最大化 编辑器窗口,右窗格中就能看到生成的决策树。右窗格分为4个区域,分别以不同的方式显示挖掘结果。
3. 决策树挖掘结果分析
(1)在“内容详情”窗格的决策树区域中,颜色深浅代表“事例”的密度点击某节点能从“特性”框查看其出现的事例数,从这里还看到不同类型客户选择金、银、铜及普通卡的比例(偏好)情况。
(2)树的第一个级别“yearly income”,说明该属性的重要性最高(信息增益率最大),其中年收入为3~5万的人最多。
(3)在右下角设置“树颜色基于:Golden”,则可方便地看出偏好选择金卡的客户群为:年收入15万以上的已婚簇。从特性框中可以看出其购买金卡的概率达到45.09%,另外还有47.4%购买了银卡。再往下展开决策树可以看到,购买金卡的主要为已婚簇,未婚簇则购买银卡为主。
(4)同样也可以查看其它卡的客户类型及分布情况。
市场部可以根据上述决策树挖掘结果来确定最可能选择某种类型卡的客户的特征。根据这些特征(年收入、子女数、婚姻状况等),可以重新定义会员卡服务和方案,以便更好地针对其客户。
4. 创建聚类挖掘模型
目标:通过创建聚类挖掘模型将客户群划分为不同的逻辑簇。
操作步骤如下:
(1)右击“Sales”多维数据集,然后选择“新建挖掘模型”命令,打开新建挖掘模型向导;
(2)在“选择数据挖掘技术”步骤中,选择“Microsoft聚集”,单击<下一步>;
在“选择事例”步骤中,选择维度“Customer”,级别为“Lname”,单击<下一步>;
(3)在“选择训练数据”步聚中,清除“Customer”维度的Country、State Province和City复选框(因为没有必要使用汇总级别划分客户群),然后在“度量值”维度中选择“Store Sales”,单击<下一步>;
(4)输入挖掘模型的名称“Customer segmentation”,选中“保存,但现在不处理”,然后单击<完成>。
5. 聚类挖掘结果分析
通过分析,市场部可以知道:Cluster1主要由中等收入的客户构成,而且全部为单身,每年在FoodMart商店平均花费72.42美元,由此可进一步采取有针对的营销策略。同样可找出Cluster2和Cluster3中的客户特征。
6. 创建基于关系数据表的决策树挖掘模型
通过建立基于关系数据表的挖掘模型,可以挖掘出更详细的信息。
具体操作如下:
(1)右击“挖掘模型”文件夹,然后选择“新建挖掘模型”命令,打开挖掘模型向导;
(2)单击<下一步>,在“选择源类型”步骤中,单击“关系数据”,继续单击<下一步>;
(3)在“选择事例表”步骤中,单击“单个表包含数据”并选择“Customer”,然后单击<下一步>;
(4)选择挖掘技术为“Microsoft 决策树”,继续<下一步>;
(5)选择“事例键列”为“customer_id”,继续<下一步>;
7. 浏览“相关性网络”视图
相关性网络是Microsoft决策树另一视图模型,是对树浏览器的补充。树浏览器可以使观察者的注意力集中在单个特性的详细关系上,而相关性网络则显示所有特性的高级关系,给出数据中相关性的俯视图。
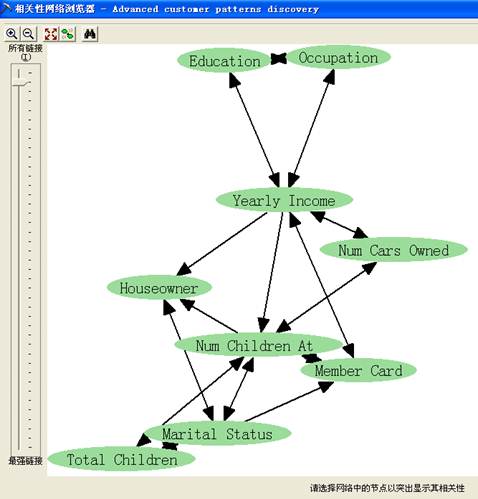
图表 11 相关性浏览视图
江西理工大学应用科学学院经管系
《数据仓库与数据挖掘》课程设计(论文)指导教师评分表
班级: 姓名: 学号:
课程设计题目: 基于Foodmart超市数据集的OLAP分析及数据挖掘
指导老师签名:
年 月 日
-
数据分析报告格式
数据分析报告格式分析报告的输出是是你整个分析过程的成果,是评定一个产品、一个运营事件的定性结论,很可能是产品决策的参考依据,既然这…
-
数据分析报告怎么写
数据分析报告怎么写数据分析报告其实是对整个数据分析过程的一个总结与呈现,通过报告,把数据分析的起因、过程、结果及建议完整地呈现出来…
-
XX公司数据分析报告
数据分析报告QREK840120xx上海一开电气集团有限公司管理体系小组20xx年8月装订数据分析报告总记录表格页码第64页VER…
-
总结报告模板20xx版-数据
1.项目的研究成果。特别要说明科学发展或技术创新之处,并有具体的内容和必要的数据(必须注明体现主要研发结果和必要数据的论文名称或测…
-
数据库检查报告模版
数据库系统远程性能监测报告模版文档控制修改记录审阅分发ii目录文档控制概述数据库配置非缺省的数据库参数Sga占用情况数据文件使用情…
-
数据挖掘读书报告
读书报告数据挖掘可以看成是信息技术自然化的结果。数据挖掘(Datamining),又译为资料探勘、数据采矿。它是数据库知识发现(K…
-
数据挖掘实验报告 超市商品销售分析及数据挖掘
通信与信息工程学院课程设计说明书课程名称数据仓库与数据挖掘课程设计题目超市商品销售分析及数据挖掘专业班级电子商务理组长学号组员学号…
-
数据挖掘大作业结果分析报告
数据仓库期末作业数据挖掘分析报告某药店常用药品信息数据挖掘解决方案作者刘金龙学院计算机信息管理学院专业计算机科学与技术年级20xx…
-
数据挖掘报告
研究方向前沿读书报告数据挖掘技术的算法与应用目录第一章数据仓库511概论512数据仓库体系结构613数据仓库规划设计与开发7131…
-
数据挖掘实验报告4
甘肃政法学院本科生实验报告四姓名贾燚学院计算机科学学院专业信息管理与信息系统班级10级信管班实验课程名称数据仓库与数据挖掘实验日期…
-
数据挖掘与分析心得体会
正如柏拉图所说:需要是发明之母。随着信息时代的步伐不断迈进,大量数据日积月累。我们迫切需要一种工具来满足从数据中发现知识的需求!而…