对客户信用风险值的回归分析
对客户EMMA分值的回归分析
背景和目标
为了减少商业风险,我们往往需要对客户当前的信用度进行评估。通常,我们会通过向第三方机构购买的客户信用评估报告来判断和该客户合作的商业风险,比如:D&B 或 Sinotrust。而这类评估报告存在以下问题:
Ø 有些你关心的客户,第三方机构不一定有他们的信用评估信息
Ø 这类评估报告并没有和我们的生意动态联系起来,比如:我们对客户的应收账款
Ø 生意的动态的,每年我们都需要知道客户的信用状况,所以每年我们都会为此支付一笔很大的费用
因此,我们希望建立起一套能自己评估客户信用度的方法,使得我们能够:
Ø 在我们需要的时候,随时获得客户的信用值,而且我们不再为此向第三方支付任何费用
Ø 基于我们在客户那里的应收账款,动态的监控客户的信用风险,并据此及时的采取应对措施
实现上述目标的挑战如下:
Ø 缺少完成信用评估的专业知识,如何在没有这些专业知识的情况下,依然能对客户信用风险进行较为准确的评估
Ø 如何实现一个监控平台,使得客户信用风险的变化能与SAP中的应收信息同步变化,并能自动给出警告
解决问题的基本途径
为准确的评估中国企业的信用风险,D&B开发了一套评估模型,称为EMMA ( Emerging Market Mediation Alert )。EMMA的分值能有效的预测一个公司在未来12个月内存在不稳定或不可靠的危险,分值从 1 到 10,分值越高越危险。由于和D&B的长期合作,我们手上有很多公司的评估报告,所以我们想,是否可以从以往的评估报告中总结出评估客户信用风险的所用到的参数,通过对这些参数的回归分析,是否可以找到一个较为准确的预测模型,今后,我们可以用这个模型来完成对客户信息风险的分析。基本思路如下图所示:

数据获取
来源: Business Information Report of D&B
样本量: 112 Enterprises
时间范围: 20## 年 ~ 20## 年
D&B 的信用风险评估报告提供了各种各样的数据,大致可分为:基本信息、股东结构、公司历史、购销策略、以及现金流状况等几个方面。基于实际工作中的经验,我们认为对客户信用风险影响比较大的参数有如下几个:
Type of Business 也就是企业性质,国企、外企、还是有限公司
Year Started 公司什么时候成立的,我们的常识是,新成立的公司往往信用风险较高
History 在经营过程中有无发生过法律纠纷,有纠纷自然信用风险较高
Employee 员工数量,我们还不太确定员工少的公司,风险是高还是低
Reg. Capital 注册资金,注册资金越多,也许意味着风险越低
Line of Business 所从事的行业,我们发现 D&B 对不同行业进行了编码,这可能是他们度量行业风险的一个重要参数
Net Profit 净利润,毫无疑问,净利润越高风险越低,但真的是这样吗
Total Cur. Assets 当前资产总值,越高越好
Total Cur. Liability 当前负债总值,越低越好
对数据的整理
在前面提及的参数中, Type of Business 和 History 是用文字描述的,需要对其进行编码,编码结果如下表所示:

初步分析
做Matrix Plot,排除异常点后,得下图:

可以看出,Liability 和 Assets 之间有线性关系,History、Net Profit 与 EMMA 有一定的线性关系,为进一步确认,对所有参数做Regression,结论如下所述。

分析结果显示:Year Started, History, Net Profit 等参数与EMMA的相关性是显著的,这符合我们的常识。 而 Net Profit, Assets 和 Liability 与EMMA 的相关性不显著,和我们的常识是相悖的,我们猜想,是不是这几个参数以某种交互关系来影响EMMA。 因此,我们打算引入新的参数,做进一步的分析。
引入新参数:净盈利比例(Profit %)
基于财务常识和样本中的数据,我们发现,不能简单的从 Net Profit 的绝对值来判断一个公司的信用风险是高还是低,一个盈利的盈利能力,应该看它是基于多大的资产总值来创造的,故而,我们引入一个新参数:
净盈利比例(Profit %)= Net Profit / Total Cur. Assets * 100%
用这个参数来重新进行 EMMA 的回归分析。这次我们得到如下信息:
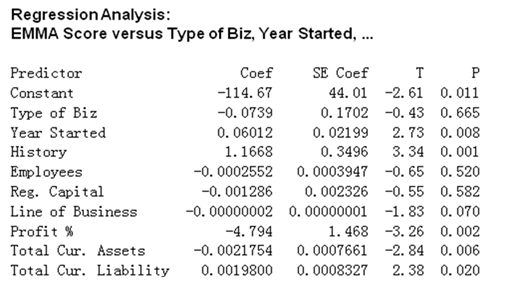
我们发现, Profit % 和 EMMA 的相关性是显著的。而且,引入 Profit % 后,我们看见,Assets 和 Liability 的相关性也是得显著的。
与此同时,Line of Business 的相关性也接近显著的边缘,基于我们前面的猜想,这个参数可能是 D&B 对行业风险的一个经验评价值,它接近显著,说明 D&B 对行业风险的评价还是有一定的合理性,而统计学上的不显著,告诉我们,在我们建立的评价模型中,可以忽略这个参数对 EMMA 的影响。这对我们是好事,因为,即使不能准确的评估行业风险,我们仍然能从其它参数准确的评估一个公司的信用风险。
确定最终模型
排除不显著的项,做回归分析,得:

以拟合出的公式对样本中的 EMMA 进行计算,得到的结果称为 Predict EMMA,与样本值对比,得下图:
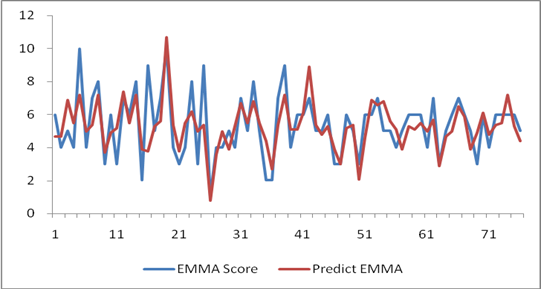
可以看出,用该公式来预测,得到的预测值具备一定的准确性,但仍有改进的空间。
模型的后续改进
为提高模型的准确性,可从以下几个方面加强工作:
p 增加样本量,再次进行回归分析
p 对 Line of Business 做进一步的了解,把该参数融入到模型中
当然,预测总是存在一定的误差,所以,也没有必要苛求预测模型的精确性。
能实现我们最初定义的目的,并且容易操作的方法,才是好方法。
第二篇:Logistic回归模型在信用风险分析中的应用
第36卷第9期数学的实践与认识v01.36No.92006年9月MATHEMATICSINPRACTICEANDTHEORYSep.,2006
Logistic回归模型在信用风险分析中的应用
庞素琳
(暨南大学数学系,广州广东51063z)
摘要:通过运行sPss,建立Logistic回归信用评价模型(creditevaluationmodel),用来对中国2000年106
家上市公司进行两类模式分类,这两类模式是指按照公司的经营状况分为“差”和“正常”两个小组.对每一家
上市公司.考虑其经营状况的4个主要财务指标:每股收益、每股净资产、净资产收益率和每傲现金流量.仿
真结果表明.Logistie回归信用评价模型对总体106个样本,判别准确率达到99.06%.此外.本文的研究结果
还发现.当利用sPSS的Discriminant给出的模型系数建立的线性判别分析模型和利用sPSs的Multinomial
Logistic给出的模型参数建立的Logistic回归模型.Logistic回归模型的判别结果不如线性判别模型.但如果
剔除不合格的样本.或是将样本数据规格化.则可以提高Logistic回归模型的分类准确率.
关键词:信用风险分析;信用评价模型;Logistic回归模型;线性判别分析
l引言
I。ogistic模型最早是由Martin[1](1977)用来预测公司的破产及违约概率.他从1970一1977年间大约5700家美联储成员银行中界定出58家困境银行,并从25个财务指标中选取总资产净利润率等8个财务比率,用来预测公司的破产及违约概率,建立了I。ogistic回归模型(Logisticregressionmodel),根据银行、投资者的风险偏好设定风险警界线,以此对分析对象进行风险定位和决策.他还将Z—Score模型,ZETA模型和I。ogistic模型的预测能力进行了比较,结果发现I,ogistic回归模型优于Z—Score模型和ZETA模型.0hlson[2](1980)也将I。ogistic模型应用于信用风险分析.Madalla[3](1983)则采用I。ogistic模型区别违约与非违约贷款申请人.其研究结果表明,当违约概率p≥o.551时是风险贷款,当户<o.551时是非风险贷款.
Davidwest[4](2000)建立了5种神经网络模型:多层感到知器(multilayerperceptron)、专家杂合系统(mixture—of—experts)、径向基函数网络(radialbasisfunctionnetwork)、学习向量化子(1earningvectorquantization)和模糊自适应共振(fuzzyadaptiveresonance)与5种统计分类模型:线性判别分析法(1ineardiscriminantanalysis)、I。ogistic回归模型(Logisticregressionmodel)、K最邻近法(Knearestneighbor)、核密度分类方法(Kerneldensity)、分类树法(Classmcationtrees),分别对德国和澳大利亚两组财务数据进行两类模式分类.研究结果表明,I。ogistic模型在这10种模型中的判别准确率都最高,分别为76.3%和87.25%.
在我们国家,齐治平,余妙志[5](2002)从我国沪、深两交易所选取164家上市公司,然后随机分成两组:第一组99家用来作为估计的样本,其中含58家非ST公司,41家ST公司;第二组65家用来作为检验样本,其中含35家非ST公司,30家ST公司.然后运用线性判别模型、I。ogistic回归模型以及含有二次项和交叉项的Logistic模型对数据样本提前两年进行预
收稿日期:2006—06—20基金项目:国家自然科学基金(60574069)i广东省软科学研究项目(2005870lOl044)
万 方数据
130数学的实践与认识36卷测.结果发现,含有二次项和交叉项的I。ogistic模型对前一年数据的预测准确率最高,达到83.3%,而I。ogistic回归模型的预测准确率为66.67%,线性判别模型的预测准确率为56.67%.在对前两年数据进行预测时,这三个模型预测的准确率分别为60%、53.33%、53.33%.姜秀华[6](2002)和唐有瑜[7](2002)也利用I。ogistic模型对我国上市公司进行信用风险分析.吴世农[8](2003)采用我国1998—2000年A股市场全部的ST公司(已排除非正常的ST公司)共70家,样本数据的收集时间延至公司发生ST前5年,同时选取70家非ST公司作为匹配样本,因此总体样本共140个,使用了剖面分析、单变量分析、线性概率模型(LPM),Fisher二类线性判定,I。ogit模型等统计方法对财务困境公司进行预测研究,其中I。ogit模型对前一年数据的预测准确率达到93.53%,Fisher判别分析法和I。PM的准确率都为89.93%.庞素琳,王燕鸣[11’12](2003)利用多层感知器分别对我国2000年106家上市公司和2000年96家上市公司进行两类模式分类,分类准确率分别达到98.11%和79.17%.
本文再运用I。ogistic回归模型建立信用评价模型,用来对我国2000年106家上市公司进行两类模式分类.
到目前为止,众多的研究已经表明,I。ogistic回归模型不要求数据满足正态分布,其模型采用I。ogistic函数.因此,在满足正态分布条件下,I。ogistic回归模型与判别分析模型具有相同的判别准确率;而在不满足正态分布条件下,Logistic回归模型判别准确率高于多元判别分析法的判别结果[1^引.但在本文的研究中将看到,通过运行SPSS软件建立Logistic回归信用评价模型,用来对中国2000年106家上市公司进行两类模式分类时,总误判样本的个数为1,判别准确率为99.06%.而在文献[9]告诉我们,通过运行SPsS软件建立线性判别分析信用评价模型,用来对同样的106个数据样本集进行两类模式分类,总误判样本的个数为o,判别准确率达到100%.这就告诉我们,当I,ogistic回归模型和判别分析模型都通过运行SPSS软件来估计模型参数并建立相应模型时,线性判别分析模型优于I。ogistic回归模型.2Logistic回归模型
I。ogistic回归模型可表述为:户一南1
‘1)
一f。+∑懈t
其中z。(是=1,2,…,研)为信用风险评定中的影响变量(或表示企业的特征指标变量),c,(歹=o,1,2,…,m)技术系数,通过回归或极大似然估计获得,Logistic回归值户∈(o,1)为信用风险分析的判别结果.
I。ogistic回归模型的函数图像具有s型分布,如图1所示.
由I。ogistic函数图像知,户是s的连续增函数,5∈(一o。,+oo).并且坚户2坚南2j¨?o1c1
,旦曼户。当矍南2J一一o。卜。一。o1uo
对于某一公司i(j=l,2,…,咒)来说,如果其I。ogistic回归值户,接近于o(或户r≈o),则被判定为一类经营“差”的企业;若其I。ogistic回归值户一接近于1(或户i≈1),则被判定为一万方数据
万方数据
132数学的实践与认识36卷联立(4)及(5)中,咒+1个方程,从中解出各参数c,(歹=o,1,2,…,扰)的值己,己即为所估计的参数值.
3样本数据及实验结果分析
本文利用I。ogistic回归模型建立信用评价模型,用来对我国2000年106家上市公司进行两类模式分类,其中训练集含有63个样本;测试集含有43个样本,考虑企业如下4个主要财务指标;
z一=每股收益,zz=每股净资产,铂=净资产收益率,毛=每股现金流量
于是,具有4个指标变量的I,ogistic回归模型可表示为:
’由:——————————————————————三——————————————————一1+exp(一(fo+‘121+c222+f323+c424))
其中户取值。或1,代表模式中的两类.对第i(i一1,2,?..'106)个公司的4个指标值z。、z。、Ir。、z。,假设其相应的I。ogistic回归值为户,,则p,被定义如下:
fo,公司i被判定为陷入财务困境公司
一11,公司i被判定为非财务困境公司
在户j的定义中,如果某公司i被判定为陷入财务困境公司,是指该公司被判定为一类经营“差”的公司;如果某公司i被判定为非财务困境公司,是指该公司被判定为一类经营“正常”的公司.
定义的第l类错误为:将经营“差”的公司误判为经营“正常”的公司;定义的第2类错误为:将经营“正常”的公司误判为经营“差”的公司.
以下通过运行SPSS软件来对系数c,(-f=o,1,2,3,4)进行估计.表1表明观测数据共有63个(是63个训练样本),其中一类有32个样本(是32家ST及PT公司),另一类有31个样本(是31家不亏损公司),缺失值为o.
表l观测数量表
CaseProcessingSummary
NMarginalPercentage
X13149.2%
23250.8%
Valid63100.0%
Missing0
Total63
Subpopulation63“
a.ThedependentvariablehasonlyonevaIueobservedin
63(100.0%)subpopulations.
经16步迭代后,对数似然值接近于o.表2给出了每一步迭代4个指标变量戤(志=1,2,3,4)的系数值c,(J=o,1,2,3,4),在迭代过程中,系数‘』不断发生变化.
f,的初始值为:f50’=一o.0317487,ff∞=o,f{∞=o,f{∞=o,f{∞=o
万 方数据
9期
庞素琳:Logistic回归模型在信用风险分析中的应用
表2
2
133
Log
LikeIihood迭代过程及其相应的参数估计值
IteratiOnHistOry
N
Iteration
Step—halving
Ol2345678910111213141516
OOOO0O0
O
一2Log
l
Likelihood
Intercept
87.32l38.86021_18412.0137.0994.3082.7281.8041.054.437.159.0580.21.008.003.001.000“
一.0317487一.1798955一.4356482一.6696054一.8009164一.7921845一.6525316一.5703814一.7875620一.831495l一.2578548.72197631.9693133.2564994.5409885.8230357.104049
X1.00000001.2860592.7164844.5948927.08152510.5887315.6477522.7459934.9334359.3332388.50199117.2757145.8507174.2583202.5829230.8754259.1562
X2.0000000.1514243.3054981.4823626.6579229.8136052.8960125.915595l1.0560791.2593581.3399601.3947531.4369741.4789141.5219991.5655521.609295
X3.0000000.0012821.00ZZ010.0038268.0068468.0113056.01701lO.0234507.0290409.0102152一.016016l一.0311365一.0432147一.0546558一.0659834一.0772834一.0885757
X4.OOOOOOO.23144lO.0958787一.2586024一.6508927—1.08196—1.57475—2.04378—3.03939—6.10989一11.2798—18.872l一28.2186—37.842l一47.4561—57.0572—66.6528
X
0O0OOOO
O0
a.
T11elog—likelihoodvaluesThema“mum
are
approaching
zero.
Theremaybeacompleteseparationinthedata.
likeIihoodestimatesdomotexist.Latabsolutechangein一2LogLikelihoodis.001,
abs01utec11angeinparametersis28.2807714
andlastmaximum
此时,2
I。og
l。ikelmood的值为87.321.经第1次迭代后,‘』的值为:
I,ikelihood的值为38.86.可以看出,对数似然算法在下降.经第2次迭代后,c,
f51’一一o.1798955,c{¨一1.286059,c;1’=0.1514243,f;"=O.0012821,fj¨=O.231441此时,2的值为:
f:2’=一o.4356482,ci∞=2.716484,f{鼬=o.3054981,c5鼬=o.002201,c{肋=o.0958787此时,2值为:
f516’=7.104019,c{16’=259.1562,c516’=1.609295,f51∞一一o.0885757,c{16’=一66.6528此时,2
I,ogI.ogI。og
I。ikelihood的值为21.184,对数似然算法继续下降.一直迭代到第16步时,f,的
I。ikelihood的值已下降到o,迭代终止.c,的估计值f,分别为:
己=f∥,;。=f…,;。=f{16),;。=fil6),蠢一f{16)
所以,I。ogistic回归信用评价模型可建立如下:
一
,2
r正面下可F而—乏瓦可丽—1习瓦ii孤溺i=丽百丽
1
¨’
…
表3进一步给出了参数c,的估计(见B列)和各统计量的检验.
表4给出了I。ogistics回归模型(2)对63个训练样本的分类结果.它表明,两类样本的分类准确率都为100%,因此对63个训练样本的分类准确率为100%.
万方数据
万方数据
9期庞素琳:Logistic回归模型在信用风险分析中的应用135需要的只是户(s)接近于。或1的值,并不需要计算出户(5)的实际值.所以,除了尸(27.71718)和尸(一10.7988)需要计算之外,我们将采用如下判别方法来估计户(s)的其它的值:
1)计算户(s)在27.71718的值,得:户(27.71718)=Fr蒜=9.1744E一13≈o1
1o
因为27.71718是在s的所有大于零的值中的最小值,所以将s的其它大于零的值代入(8)后得到户(s)的值都比户(27.71718)=9.1744E一13小且大于o.换句话来说,对s中任意一个大于27.71718的值n(即以>27.71718),有
o<户(“)=矗々<r—册1=户(27.71718)≈O(9)
所以户(以)一r}i≈o.
这表明对s所有大于零的值,p(s)的值都约为o,且误差精度达到P=9.1744E一13.2)计算户(5)在一10.7988的值,得:
1
P(一10.7988)=Fr去丽丽=o.999979576≈1
因为一10.7988是在s的所有小于零的值中的最大值,所以将5的其它小于零的值代入(8)后得到户(s)的值都比P(一10.7988)=o.999979576大且小于1.换句话来说,对5中任意一个小于一10.7988的值6(即6<一10.7988),有
1≈尸(一10.7988)一r了■‰<南=尸(6)<111
l十e……”l十e。(1G)
1
所以P(6)=_÷];≈1.1TC
这表明对s所有小于零的值,p(s)的值都约为1,且误差精度达到
P=1一O.999979576=0.000020434.
根据以上分析及对夕(一)值的估计,可得到I。ogistic回归模型(6)对43个测试样本的判别结果,其中误判样本的个数为1,误判率为2.33%,因而判别准确率达到97.67%.从而对总体106个样本,I。ogistic回归模型(6)的总误判个数为1,总误判率为o.94%,总体判别准确率达到99.06%.
在文献[9]的研究中看到,I。DA~SPSS方法(通过运行SPsS软件建立线性判别信用评价模型)对总体106个样本的判别准确率达到100%.由此说明了:I。ogistjc回归模型的判别结果不如线性判别模型.这与经典的研究结果是不相符的.经典的结论是[
万 方数据
136数学的实践与认识36卷从表6的财务指标值看出,该公司(ST海洋)的净资产收益率为一36666.09,其负值的绝对值非常大,因为其s值为一2914.084,而一2914.084<一10.7988,所以由(10)的判别式有:
所以P(一2914.084)=F工:翻≈1,从而将sT海洋这一严重陷入财务困境的sT公司误判为一类经营“好”的公司.1≈尸(一10?7988)=订南<订≤赢=P(一2914?084)<111
再来看测试样本中的另一个ST公司(ST恒泰),其信息如下:
表7ST恒泰的主要财务数据
其净资产收益率为一574.15,是43个测试样本中净资产收益率为负值的绝对值第2大的公司,因为其s值为80.26302,而80.26302>27.7171,所以由(9)的判别式有:
o<户(80?26302)2
1所以户(80.26302)=r工知≈o.所以sT恒泰被正常判定为一类经营“差”的公司.
由此得知,造成I。ogistic回归模型(6)判别不准确的主要原因是由于某一公司的某个财务指标值的绝对值太大.我们还做了一个很有趣的实验,经过反复试验知,在误差精度为P’=o.o001下,如果其它三个财务指标的值都不变,净资产收益率的最小值可达到一3823.3,Fi刍丽<F乏匆丽2户(27.71718)≈o11此时相应的s值为8.92452,户(8.92452)=FF知≈o.o00133≈o.I。ogistic回归模型1
(6)可正常判断这一陷入ST的公司为一类经营“差”的公司.当然,如果在判别之前,对这一不合格的样本进行剔除处理,或是先将数据规格化,那么I。ogistic回归模型的判别准确率是可以达到100%的.
4结论
本文采用我国2000年106家上市公司的财务数据,考虑上市公司经营状况的4个主要财务指标:每股收益、每股净资产、净资产收益率、每股现金流量,通过运行sPSS软件,利用其中63家公司的数据建立I。ogistic回归信用评价模型,用来对余下43个公司的数据进行判别分析.研究结果表明,利用SPSS对模型参数进行估计,所建立的I。ogistic回归模型对63个训练样本的判别准确率达到100%,对43个测试样本误判了1个,因而对总体106个样本,I。ogistic回归模型的判别准确率达到99.06%.
除此之外,本文还得到结论:当将训练样本输入SPSS,利用SPSS的Discriminant给出的模型系数建立的线性判别分析模型和利用SPSS的MultinomialI。ogistic给出的模型参数建立的I。ogistic回归模型,I,ogistic回归模型的判别结果不如线性判别模型.但如果剔除不合格的样本,或是将样本数据规格化,则可以提高I。ogistic回归模型的分类准确率.
万方数据
9期庞素琳:Logistic回归模型在信用风险分析中的应用137参考文献:
[1]MartinD.Earlywarningofbankfailurelalogitregressionapproach[J].JournalofBankingandFinance,1977.
249—276.
[2]0hIsonJ.FinancialrationsandtheprobabiIisticpredictionofbankruptcy[J].JAccountingResearch.1980.1:
109一一130.
[3]MadallaGs.Limited-DependentandQualitativeVariablesinEconometrics[M].cambridgelcambridge
UniversityPress,1983.
4westD.Neuralnetworkcred“scoringmodels[J].Computer&0perationsRe8earch.2000.27:1131一1152.5齐治平.余妙志.Logjstjc模型在上市公司财务状况评价中的应用口].东北财经大学学报.2002,l:62—63.6姜秀华.任强.孙铮.上市公司财务危机预警模型研究[J].预测,2002.2l(3)t56—61.7唐有瑜.财务危机预警模型在信贷风险管理中的应用[J].上海金融,2002.2:36—38.8吴世农.中国股票市场风险研究[M].北京:中国人民大学出版社,2003.
庞素琳,王燕鸣.判别分析模型在信用评价中的应用[J].南方经济,2006.3.
9“庞素琳.《信用评价及股市预测模型研究及应用一统计学、神经网络及支持向量机方法》[M].北京t科学出版社.
2005.
[11]庞素琳,王燕呜.罗育中.多层感知器信用评价模型及预警研究口].数学的实践与认识,2003.33(9)t55—62.[12]庞素琳.王燕呜.多层感知器信用评价模型研究[J].中山大学学报,2003,42(4):118—122.
AnApplicationofLogisticRegressionModeI
inCreditRiskAnalysis
PANGSu—juan
(DepartmentofMathematics,JinanUniversity,GuangzhouGuangdong510632,China)Abstract:ThepaperestablishesaLogisticregressioncreditevaIuationmodelbyrunningSPSSsoftware.Itisusedtoclassifythe106listedcompaniesofChinaiin2000intotwopatterns.Thetwopatternsmeanthatthelistedcompaniesaredividedintotwogroupsaccordingtotheirbusinessconditions:oneisa%ad”groupandtheotherisa,『normal”group.Toeach“stedcompany,the4mainfinancialindexesareconsidered:earningpershare,netassetpershare,returnone(1uity,cashflowpershare.Thesimulatingresutlsshowedthat,tothe106samples,thediscriminantaccuracyrateis99.06%byusingtheLogisticregressioncreditevaluationmodel-Inaddition,theresearchstillfoundthat.whenweusethemodelcoefficientsgivenbyDiscriminaninSPSStoestablishthemodelofIineardiscriminantanalysisandusethemodelparametersgivenbyMultinomialLogisticinSPSStoestablishthemodelofLogisticregressionmodel,thediscriminantresultsoftheLogisticregressionmodelisnotasgoodasthatofthelineardiscriminantanalysis.
Kevwords:creditrjskanalyses;creditevaluaitonmodel}logisticregressionmodel;lineardisc“minantanalysis
万 方数据


Logistic回归模型在信用风险分析中的应用
作者:
作者单位:
刊名:
英文刊名:
年,卷(期):
被引用次数:庞素琳, PANG Su-juan暨南大学数学系,广州,广东,510632数学的实践与认识MATHEMATICS IN PRACTICE AND THEORY2006,36(9)4次
参考文献(12条)
1.Martin D Early warning of bank failure:a logit regression approach 1977
2.Ohlson J Financial rations and the probabilistic prediction of bankruptcy 1980
3.Madalla G S Limited-Dependent and Qualitative Variables in Econometrics 1983
4.West D Neural network credit scoring models[外文期刊] 2000
5.齐治平.余妙志 Logistic模型在上市公司财务状况评价中的应用[期刊论文]-东北财经大学学报 2002(01)
6.姜秀华.任强.孙铮 上市公司财务危机预警模型研究[期刊论文]-预测 2002(03)
7.唐有瑜 财务危机预警模型在信贷风险管理中的应用[期刊论文]-上海金融 2002(02)
8.吴世农 中国股票市场风险研究 2003
9.庞素琳.王燕鸣 判别分析模型在信用评价中的应用[期刊论文]-南方经济 2006(03)
10.庞素琳 信用评价及股市预测模型研究及应用-统计学、神经网络及支持向量机方法 2005
11.庞素琳.王燕鸣.罗育中 多层感知器信用评价模型及预警研究[期刊论文]-数学的实践与认识 2003(09)
12.庞素琳.王燕鸣 多层感知器信用评价模型研究[期刊论文]-中山大学学报(自然科学版) 2003(04)
引证文献(4条)
1.肖冰.李春红 基于Logistic模型的房地产行业信用风险研究[期刊论文]-技术经济 2010(3)
2.张勇.应超 审计委员会制度能有效防止上市公司信息披露违规吗——来自2003-20xx年沪深两市A股的经验证据
[期刊论文]-宏观经济研究 2009(5)
3.白少布 基于有序logistic模型的企业供应链融资风险预警研究[期刊论文]-经济经纬 2010(6)
4.刘迎春 基于Logistic回归的中国上市公司信用风险度量研究[期刊论文]-黑龙江对外经贸 2010(11)
本文链接:http://d..cn/Periodical_sxdsjyrs200609021.aspx
-
信贷信用风险分析报告
20xx年上半年信用风险分析报告风险状况分析一总体情况XX支行作为新设分支机构信贷资产规模比较小信贷资产结构也较单一不良信贷资产没…
-
银行风险分析报告
参考模式XX分、支行20xx年XX(季度/上半年/年度)风险分析报告概述(简要概括辖内整体风险状况)第一部分风险状况分析一、总体情…
-
信贷资产风险分析报告
信贷资产风险分析报告截止6月末我社各项贷款余额为万元较年初增加万元增速为不良贷款余额为万元较年初增加万元不良贷款增幅为不良率为较年…
-
xx支行信用风险报告
-1-二、信用风险状况及趋势分析(一)辖内信用风险环境分析我行坚持以服务“三农”为宗旨,以农村为主要阵地,服务广大农民、农村经济组…
-
XX银行年度经营风险分析报告
XX银行年度经营风险分析报告中国银行业监督管理委员会XX监管分局现将XX银行下称我行年度风险经营分析报告如下一业务经营基本情况分析…
-
信用社经营及风险分析报告
信用社经营及风险分析报告银监分局(组):上半年,在市银监局、市社党委、理事会的正确领导下,我们认真贯彻落实“十六大”精神,努力实践…
-
xx支行信用风险报告
-1-二、信用风险状况及趋势分析(一)辖内信用风险环境分析我行坚持以服务“三农”为宗旨,以农村为主要阵地,服务广大农民、农村经济组…
-
信贷资产风险分析报告
信贷资产风险分析报告截止6月末我社各项贷款余额为万元较年初增加万元增速为不良贷款余额为万元较年初增加万元不良贷款增幅为不良率为较年…
-
银行季度风险分析报告模板
参考模式银行支行季度上半年年度风险分析报告概述简要概括辖内整体风险状况第一部分风险状况分析一总体情况XX月末全行资产总额XX万元比…
-
信用卡、电子银行业务风险案例分析报告
信用卡电子银行业务风险案例分析报告年初以来信用卡中心紧紧围绕防范风险合规经营主题开展工作在努力完成各项任务指标的同时着重加强业务管…
-
内控风险排查报告
××县农村信用合作社内控风险排查情况的报告市办:根据省银监局《关于转发内控风险提示及开展内控检查工作的通知》(赣银监办发[20xx…