�˹������ܽ�---����
��ֻ�в��ָ�������ⲻ������
��һ��
���˹����ܵĶ��塿
���˹�������Ҫ�о��������ܻ�Ĺ��ɣ��������һ�����ܵ��˹�ϵͳ���о�����ü����ȥ���������Ҫ������������ʤ�εĹ�����
�˹����ܵķ�չ����Ϊ��
�����ڣ�1956��ǰ��
�γ��ڣ�1956��-1969�꣩-����é˹����
��չ��-����֪ʶ��ϵͳ
ʵ����-������ĸ���
�������������
�������壺��AI�о��Ĵ�ͳ�۵㣩ǿ����������ϵͳ��˼ά�����Ǹ�����ģʽ�Ĵ������̡�
�������壺�ֳƷ���ѧ�ɣ�ǿ����Ԫ��������
��Ϊ���壺������Ϊ�Ļ����ǡ���֪-�ж����������뻷���Ľ��������б��ֳ����ġ�
�˹����ܵ���Ҫ�о�����
ר��ϵͳ �����ھ� ����web ��Ȼ�������� ������ ģʽʶ�� ���ܿ��� ���� �Զ�֤������
�ڶ��£�
֪ʶ��ʾ֪ʶ��ʾ�����ݽṹ���䴦�����Ƶ��ۺ�
֪ʶ��ʾ=���ţ��ṹ��+��������
������֪ʶ��ʾ��ʽ
ν������ʾ�� ����ʽ��ʾ�� ���������ʾ�� ��ܱ�ʾ��
�ű� ״̬�ռ��ʾ�� ��������֪ʶ��ʾ
����ʽ����
ͨ�����ڱ�ʾ�����������ϵ��
��������ʽ��
IF P then Q �� P ��> Q������
P��ʾ��������������ǰ�ᣩ��
Q��ʾ����ʱӦ��ִ�еĶ�������õ��Ľ��ۣ���
��������ࡿ
��ǰ��-������
������-������
����ʽϵͳ�����
��һ�����ʽ����һ�������ǻ�����ϣ�Эͬ���ã�һ������ʽ���ɵĽ��ۿ��Թ���һ������ʽ��Ϊ��֪��ʵʹ�ã����������Ľ����������ϵͳ��Ϊ����ʽϵͳ��һ��˵����һ������ʽϵͳ���������������������
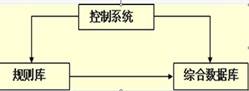
����ʽϵͳ��������������ʽ����������������������˫���������֡�
��������
 1. ������ϵ
1. ������ϵ
AKO(A-Kind-of):��ʾһ����������һ�������һ�����͡�
AMO(A-Member-of):��ʾһ����������һ������ij�Ա��
ISA(Is-a):��ʾһ����������һ�������ʵ����
2. ������ϵ
Part-of,Member-of
3.���Թ�ϵ
Have����ʾһ����������һ����������������ԡ�
Can����ʾһ�����������һ���������顣
4.ʱ���ϵ
Before����ʾһ���¼���һ���¼�֮ǰ������
 After����ʾһ���¼���һ���¼�֮������
After����ʾһ���¼���һ���¼�֮������
5. λ�ù�ϵ
Located-on:��ʾһ��������һ����֮�ϡ�
Located-at: ��ʾһ������ijһλ�á�
Located-under: ��ʾһ��������һ����֮�¡�
Located-inside: ��ʾһ��������һ����֮�С�
Located-outside: ��ʾһ��������һ����֮�⡣
6. �����ϵ
Similar-to:��ʾһ��������һ�������ơ�
Near-to: ��ʾһ��������һ����ӽ���
7. �����ϵ
If-then
8. ��ɹ�ϵ
Compsoed-of
ÿ��ѧ����ѧϰ��һ�������
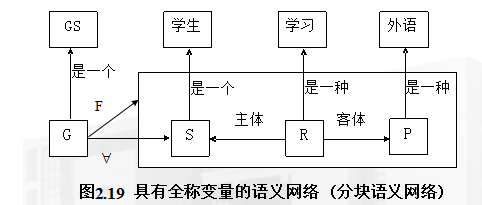
������ܵ�һ���ʾ�ṹ
�����������������������ԵIJۣ�slot�����
��ܸ�ǿ����ʾ������ڲ��ṹ��
��������ڵ��ǿ����ʾ�����Ĺ�ϵ��
��1��ISA��
ISA������ָ��������������ϵ�������ϵ����ֱ�������ǡ���һ����������һ�֡�������һֻ����������һ������£���ISA��ָ������ϵ�����м̳��ԡ�
��2��AKO��
AKO�����ھ����ָ��������������ϵ����ֱ�������ǡ���һ�֡�����������Ϊij�²��ܵIJ�ʱ������ȷ��ָ���˸��²��������������������ϲ��������������е�һ�֣��²��ܿɼ̳��ϲ�����ֵ�����ԡ�
��3��Instance��
Instance��������ʾAKO�۵����ϵ����������Ϊij�ϲ��ܵIJ�ʱ�����ڸò���ָ��������ϵ���²��ܡ���Instance��ָ������ϵ�����м̳��ԣ����²��ܿɼ̳��ϲ����������������Ի�ֵ��
��4��Part-of��
Part-of������ָ�����ֺ�ȫ��Ĺ�ϵ����������Ϊij��ܵ�һ����ʱ�����������ֵ��Ϊ�ÿ�ܵ��ϲ��������ÿ���������Ķ���ֻ�����ϲ��������������һ���֡�
������
����˵����
s-��ʼ״̬�ڵ�
G-����ͼ
OPEN-��Ŵ�չ���ڵ�ı�
CLOSE-����ѱ���չ�Ľڵ�ı�
MOVE-FIRST(OPEN)-ȡOPEN���Ľڵ���Ϊ��ǰҪ����չ�Ľڵ�n��ͬʱ���ڵ�n����CLOSE��
äĿ�������õļ�ʽ��
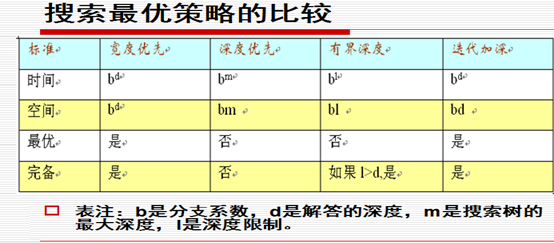
?�������ȣ�����˼�룩������չ��ǰ�ڵ�����ɵ��ӽڵ���������OPEN���ĺ�ˣ���OPEN����Ϊ����ʹ�ã��Ƚ��ȳ���ʹ�����������㷽��չ��
?������ȣ�����˼�룩������չ��ǰ�ڵ�����ɵ��ӽڵ���������OPEN����ǰ�ˣ���OPEN����Ϊջʹ�ã�����ȳ���ʹ���������������չ��
������ȡ��������� �Ƚϣ�
����
������ȡ�����һ�������ж������������·������ֻ���ҵ�����һ��ʱ������Ӧ��������ȼ������ơ�
�������ȡ���ȷ����������̵Ľ��·����
��ͬ��ȱ�㣺
?��ֱ��Ӧ��һ��ͼ�����㷨ʵ�֣�����Ҫ����ر�Ľڵ��������Ӷ������У��ʺ������ิ�ӶȲ��ߵ������������
?�ڵ������äĿ�ԣ����ڲ���������ר��֪ʶȥָ�������������ڰװ������˴����ص�״̬�ڵ��������������Ҳ��ΪäĿ������
����ʽ����
����1.A�㷨�����գ�
������˼�롿
�����������ʽ֪ʶ�����ۺ���f(n)��
ָ��һ��ͼ������OPEN������չ�ڵ������
�����ۺ���f(n)=g(n)+h(n) �����գ� ��
n-����ͼG�еĽڵ㣻
f(n)- G�д�s��n��ng�����Ƶ���С·�����ۣ�
g(n)- G�д�s��n��Ŀǰʵ�ʵ�·�����ۣ�
h(n)-��n��ng�����Ƶ���С·�����ۣ�
h(n)ֵ-����������ʽ֪ʶ���Լ��㣻
h(n)��Ϊ����ʽ�������������壡����
��������ۺ�����ʵ��A�㷨? �� ���գ���
A�㷨�������һ��ͼ������ͬ������Ϊ�����Σ�
1����ʼ��
����ֻ������ʼ״̬�ڵ�s������ͼG:={s}
OPEN:={s}
CLOSE:={}
2������ѭ��
MOVE-FIRST(OPEN)-ȡ��OPEN���Ľڵ�n
����չ��n���ӽڵ�,��������ͼG��OPEN�� ��ÿ���ӽڵ�ni,����f(n,ni)=g(n,ni)+h(ni)
 ���ʵ��ı�Ǻ���ָ�루�ӽڵ�?���ڵ㣩
���ʵ��ı�Ǻ���ָ�루�ӽڵ�?���ڵ㣩
������OPEN�������ۺ���f(n)��ֵ����
ͨ��ѭ����ִ�и��㷨������ͼ�������½ڵ���������ֱ��������Ŀ��ڵ�
A�㷨�Ŀɲ����ԡ�������f*(n)=g*(n)+h*(n)
n-����ͼG����̽��·���Ľڵ㣻
f*(n)- s���ڵ�n��ng����̽��·����·�����ۣ�
g*(n)-��·��ǰ�Σ���s��n����·�����ۣ�
h*(n)-��·����Σ���n��ng����·�����ۣ�
A*�㷨���壺
1����A�㷨�У��涨h(n)��h*(n);
2������������Ժ��A�㷨����A*�㷨��
A*�㷨�ǿɲ��ɵģ���������������̽��·��
����ʽ������ǿ������Ӱ��
���������ͬһ���������A*�㷨A1��A2��
��h1(n) �� h2(n) �� h*(n)��g1(n)=g2(n)
��t(A1) �� t(A2)
���У�h1��h2�ֱ����㷨A1��A2������ʽ������tָʾ��Ӧ�㷨����Ŀ��״̬ʱ����ͼ���Ľڵ�������
h(n)�ӽ�h*(n)�ij̶ȡ�����������ʽ������ǿ��
A*�㷨����������Ĺؼ�
h(n)������h(n) �� h*(n)�������£�Խ��Խ�ã�
�����Լ�����ɳ�ʼ������������ò������Ӳ���һЩ�����⣬�������������ò������Ӳ���������������⣬����һֱ���е������������Ϊ��ԭ���⣬������ý⡣
����ʽ������ǿ������Ӱ��
���������ͬһ���������A*�㷨A1��A2��
��h1(n) �� h2(n) �� h*(n)��g1(n)=g2(n)
��t(A1) �� t(A2)
���У�h1��h2�ֱ����㷨A1��A2������ʽ������tָʾ��Ӧ�㷨����Ŀ��״̬ʱ����ͼ���Ľڵ�������
�㷨AO*��A*�ıȽϡ�
��ͼ�������·��
���ƴ�����С�ľֲ���ͼ����������չ����OPEN����f(n)��С�Ľڵ㣻
ֻ�������ۺ���f(n)=h(n)����ͬʱ�������g(n)��h(n)��
Ӧ��LGS��Ŵ���չ�ֲ���ͼ��������fi(n0)ֵ����Ӧ��OPEN����CLOSE���ֱ��Ŵ���չ�ڵ������չ�ڵ㣬������f(n)ֵ����OPEN����
MINMAX����˼�룺
(1)���ֵ�MIN�߲��Ľڵ�ʱ��ȡ��ʱ����MAXӦ��������������f(p)ȡ��Сֵ����
(2)���ֵ�MAX�߲��Ľڵ�ʱ��ȡ��ʱ����MAXӦ������õ��������f(p)ȡ����ֵ����
(3)�������ص���ʱ����Ӧ����λ���ֵĶԿ����ԣ�����ʹ�ã�1���ͣ�2�����ַ������ݵ���ֵ��
�������ַ�����Ϊ����С���̡�
��-�¹��̾��ǰ����ɺ�̺͵���ֵ���ƽ����������ʱ����һЩ���÷�֧���Դ�������㷨��Ч�ʡ�
������
ν�ʹ�ʽ�����ԺͿ������Ը��
�������٣����ν�ʹ�ʽP���Ը�����D�ϵ��κ�һ�����Ͷ�ȡ������ֵ����ֵ�������P��D��������ģ����ٵģ��������ʽP��ÿ���ǿո������Ͼ�Ϊ���棨���٣������P���棨���ٵģ���
�����㣺����ν�ʹ�ʽP��������ٴ���һ������ʹ�ù�ʽP�ڴ˽����µ���ֵΪ�棬��ƹ�ʽP�ǿ�����ġ�
�������ȼ�����?�ǣ��ġ��ţ��̺����ȼۣ�����ͨ�����Ÿı����ȼ���

���Ӿ�
��C1=L�� C2=?L������ʽCΪ�գ�
�ԡ���ʾΪ�յĹ��ʽC������C=��Ϊ���Ӿ䣻
��ΪC1��C2��һ��ì���Ӿ䣬����ͬʱ���㣬���ԡ��Dz���������Ӿ䣻
ͨ����S�м��������������չ�Ӿ伯S���������㣻
���Ӿ�����ù��ԭ���ж��Ӿ伯S��������ijɹ���־��
���Ӿ��Dz������㣨�����٣����Ӿ�
��ᷴ�ݵĻ���˼·��
Ҫ����Ϊ��ʵ�Ĺ�ʽ��F֤��Ŀ�깫ʽWΪ�棻
���Ƚ�Wȡ��~W �����빫ʽ��F��
�ڱ���F��~WΪ�Ӿ伯S��
��ͨ���������֤��S�������㣬�ó�WΪ��Ľ��ۡ�
������
Ҫʵ�ֶԲ�ȷ����֪ʶ�Ĵ�����Ҫ���
��ȷ��֪ʶ�ı�ʾ����
��ȷ����Ϣ�ļ�������
��ȷ���Ա�ʾ
����������������
3�ֲ�ȷ��������������ͬ��ȷ���Գ̶ȶ��壩��
����Bayes����
���Ŷȷ���
֤������
LS�������������
=1:O(Q/P)=O(Q)��P��Q��Ӱ�죻
>1:O(Q/P)>O(Q)��P֧��Q��
<1:O(Q/P)<O(Q)��P��֧��Q��
LN������Ҫ������
=1:O(Q/��P)=O(Q)����P��Q��Ӱ�죻
>1:O(Q/��P)>O(Q)����P֧��Q��
<1:O(Q/��P)<O(Q)���� P��֧��Q��

����Bayes:
�ֶ����Բ�ֵ��
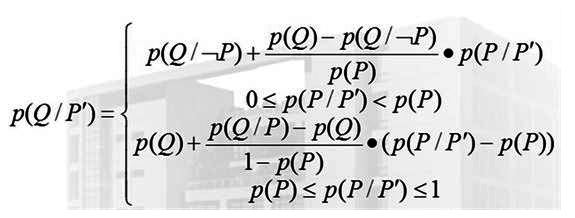
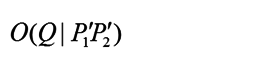
���Ŷȶ��壺
�Ź���IJ�ȷ����
MYCIN����Ŀ��Ŷȷ����У����������ʾΪ��
IF E THEN H��CF(H,E)������
֤��E��������ĺ�ȡ�ĺ���ȡ����ϣ�
����H������һ���⣻
CF(H,E)����ȷ�������ӣ����Ϊ���Ŷȣ�֤��EΪ�������£�����FΪ��Ŀ��̶ܳȣ�
CF(H,E)=MB(H,E)-MD(H,E)
��MB(H,E)=a���������
֤��E����ʹ����H�Ŀ��Ŷ�����������a��
��MD(H,E)=b �����������
֤��E����ʹ����H�IJ����Ŷ�����������b��
�����Bel
Bel(A)=A�������Ӽ�B�Ļ�������m(B)֮�ͣ�
Bel(A)��ʾ��ǰ֤���£����輯A���ۺ����ζȣ�
����Ȼ���棩����Pl
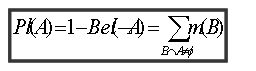
Pl(A)=������A�ཻ���Ӽ�B�Ļ�������m(B)֮��
Pl(A)��ʾA�Ǽٵ����γ̶�
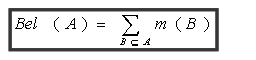

��ʾ��A��֪�������Ǽٵij̶ȣ�
[Bel(A),Pl(A)]���ۺ�����A�IJ�ȷ���ԣ�
3���������䣺
[1��1]������AΪ�棻
[0��0]������AΪ�٣�
[0��1]����A�����Ǽ�һ����֪;
[1��0]������
���輯A������ʺ���f(A)
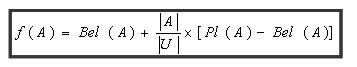
���У�|A|�����輯A����Ԫ�صĸ�����
|U|������U����Ԫ�صĸ�����
������
ѧϰϵͳ�Ļ����ṹ��ͼ��ʾ

����ѧϰ�����õIJ��Կɷ�Ϊ�� ��еѧϰ ʾ��ѧϰ ���ѧϰ ʾ��ѧϰ
����ѧϰ(induction learning)��Ӧ�ù�����������ѧϰ��һ�ַ��������ݹ���ѧϰ����ʦָ�����ɰ�����Ϊʾ��ѧϰ�۲��뷢��ѧϰ��ǰ��������ʦѧϰ������������ʦѧϰ��
����ѧϰ��˫�ռ�ģ��
���ػ�����
������ļ��裨����������������
ÿ��ȡ��һ���µ����ӣ�����һЩ�ػ���������
ֱ���������㹻�ػ��Ľ�������
�ڷ�������
�����ػ��ļ��裨���ӿռ��е�һ����������ʼ��
ÿ��ȡ��һ���µ����ӣ�����һЩ������������
ֱ���������㹻�����Ľ�������
���������ԡ���
���ÿ������ȡ��Ե����ϵ�������ʽ��
���ػ����ԡ���
���ÿ������ȡ��Զ����µ�������ʽ��
����ͬ�㡿
�����ӵļ���ᵼ���¼�������Ӻ��Ѵ��ڼ����ɾ�� ��
�����������ù����ػ��ļ��衣
������������һЩ�ػ�����
ID3�㷨��ȱ�㣺
�ŵ㣺����Ͳ����ٶȿ죬�ر��ʺ��ڴ����ݿ�ķ������⡣
ȱ�㣺��������֪ʶ��ʾ������������������⣻���ž��������бȽϣ����ж������Ƿ�ȼ۵���������ͼƥ�����⣬��NP��ȫ�ģ����ܴ���δ֪����ֵ�����������������û�кõĴ���������
�ڶ�ƪ���˹�������ҵ��(�й����)
1�����º��ʹ�ʽ����Ϊ��ȡ��ʽ���Ӿ伯��
����1��Ø (" x)($ y)($ z){P(x) Þ (" x)[Q(x, y) Þ R(z)]}
�� ��2�� ( " x)( $ y){{P(x) Ù [Q(x) Ú R(y)]} Þ (" y)[P(f(y)) Þ Q(g(x))]}
�� (3) ("x)( $y){P(x) Ù [Q(x)Ú R(y)]}Þ (" y){[P(f(y))Þ Q(g(y))]Þ (" x)R(x)}
(1) · Ø("x)( $y)( $z){P(x) Þ ("x)[Q(x,y) Þ R(z)]}
��· Ø("x)( $y)( $z){ ØP(x) Ú ( "x)[ØQ(x,y) Ú R(z)]}
��· ($x)( "y)( "z){ P(x) Ù ($ x)[Q(x,y) Ù ØR(z)]}
��· P(A) Ù [Q(f(y,z), y) Ù ØR(z)]
��· {P(A), Q(f(y,z),y), Ù ØR(w)}
��2)��· ("x)($y){{P(x) Ù [Q(x) Ú R(y)]} Þ ("y)[P(f(y)) Þ Q(g(x))]}
��· ("x)($y){Ø{P(x) Ù [Q(x) Ú R(y)]} Ú("y)[ØP(f(y)) Ú Q(g(x))]}
��· ("x)($y){ØP(x) Ú [ØQ(x) Ù ØR(y)] Ú
("w)[ØP(f(w)) Ú Q(g(x))]}
��· ("x){ØP(x) Ú [ØQ(x) Ù ØR(h(x))] Ú
("w)[ØP(f(w)) Ú Q(g(x))]}
��· [ØP(x) Ú ØQ(x) Ú ØP(f(w)) Ú Q(g(x))] Ù
[ØP(x) Ú ØR(h(x)) Ú ØP(f(w)) Ú Q(g(x))]
��· {ØP(x1) Ú ØQ(x1) Ú ØP(f(w1) Ú Q(g(x1)),
ØP(x2) Ú ØR(h(w2)) Ú ØP(f(w2)) Ú Q(g(x2))}
(3) · ("x)($y){P(x) Ù [Q(x) Ú R(y)]} Þ
("y){[P(f(y)) Þ Q(g(y))]Þ("x)R(x)}
· Ø("x)($y){P(x) Ù [Q(x) Ú R(y)]} Ú
( "y){Ø[ØP(f(y)) Ú Q(g(y))] Ú ("x)R(x)}
· ($x)("y){ ØP(x) Ú [ØQ(x) Ù ØR(y)]} Ú
("w){Ø[ØP(f(w)) Ú Q(g(w))] Ú ("v)R(v)}
· {ØP(A) Ú[ØQ(A) Ù ØR(y)]} Ú
{[P(f(w)) Ù ØQ(g(w))] Ú R(v)}
· ØP(A) Ú {[ØQ(A) Ú P(f(w))] Ù [ØQ(A) Ú ØQ(g(w))] Ù
[ØR(y) Ú P(f(w))] Ù [ØR(y) Ú ØQ(g(w))]} Ú R(v)
· {ØP(A) Ú ØQ(A) Ú P(f(w1)) Ú R(v1),
ØP(A) Ú ØQ(A) Ú Q(g(w2)) Ú R(v2),
ØP(A) Ú ØR(y3) Ú P(f(w3)) Ú R(v3),
ØP(A) Ú ØR(y4) Ú Q(g(w4)) Ú R v4)}
2������֪������ʵ��
��������1�� С�Li��ϲ�����ģ�Easy���γ̣�Course����
��������2�� С�ϲ���ѵģ�Difficult���γ̡�
��������3�� �����ࣨEng���γ̶����ѵġ�
��������4�� �����ࣨPhy���γ̶������ġ�
��������5�� С�⣨Wu��ϲ������С�ϲ���Ŀγ̡�
��������6�� Phy200��������γ̡�
��������7�� Eng300�ǹ�����γ̡�
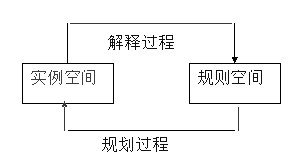
���ù�ᷴ�ݷ��ش��������⣺
��������1�� С��ϲ��ʲô�γ̣�
��������2�� ֤��С��ϲ��Eng300�γ�
����֪��ʵ��ʽ����ʾΪ���ʹ�ʽ:
������(1) ("x)[Course(x) Ù Easy(x) Þ Like(Li,x)]��
(2) ("x)[Course(x) Ù ØEasy(x) Þ ØLike(Li,x)]��
(3) ("x)[Course(x) Ù Eng(x) Þ ØEasy(x)]��
(4) ("x)[Course(x) Ù Phg(x) Þ Easy(x)]��
(5) ("x)[Course(x) Ù ØLike(x) Þ Like(Wu,x)]��
(6) Course(Phy200) ٠Phy(Phy200)��
(7) Course(Eng300) ٠Eng(Eng300)��
����· �����ʾΪ���º��ʹ�ʽ(Ŀ�깫ʽ):
������
(1)( $x)[Coure(x) ٠Like(Li,x)]��
(2)Like(Wu),Eng300)��
����· ��������ʵ�Ͷ�Ӧ�������Ŀ�깫ʽȡ�����Ի���,������Ϊ��ȡ��ʽ�Ӿ伯:
������
(1) ØCourse(x1) Ú ØEasy(x1) Ú Like(Li,x1);
(2) ØCourse(x2) Ú Easy(x2) Ú ØLike(Li,x2);
(3) ØCourse(x3) Ú ØEny(x) Ú ØEasy(x3);
(4) ØCourse(x4) Ú ØPhy(x4) Ú Easy(x4);
(5) ØCourse(x5) Ú Like(Li,x5) Ú Like(Wu,x5);
(6) Course(Phy200);
(7) Phy(Phy200);
(8) Course(Eng300);
(9) Eng(Eng300);
(10) Ŀ�깫ʽ(1)��ȡ��: (1) ØCourse(x6) Ú ØLike(Li,x6);
(11) Ŀ�깫ʽ(2)��ȡ��: (1) ØLike(Wu,Eng300);
����· �������(1)
��������(10)��ȡ��Ϊ:Ask(x6)=Course(x6) Ù Like(Li,x6)
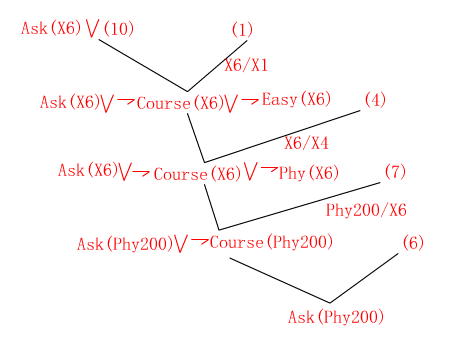
��ȡ������ش�Ϊ: Course(Phy200) ÙLike(Li,Phy200)
��������С��ϲ��Phy200�γ�.
����· �������(2)

3.���ڹ���P Þ Q����֪p(Q)=0.04,LS=100,LN=0.4,��������Bayes�������P(Q/P)��p(Q/ØP)��
��O(θ/P)=LS*O(θ)=100*0.04/(1-0.04)=4.2
����P(θ/P)=O(θ/P))/(1+O(θ/P))=4.2/5.2=0.81
����O(θ/¬P)=LN*O(θ)=0.4*0.04/(1-0.04)=0.017
����P(θ/¬P)=O(θ/¬P)/(1+O(θ/¬P))=0.017/1.017=0.017
4.�������У���P������ȷ��������P’,����p(P)=0.05,����P’Þ P��LS=120,LN=0.3���ù�Bayes�������P(θ/P')����
��1��.��P(P/P')
����O(P/P')=LS*O(P)=120*0.05/(1-0.05)=6.4
����P(P/P')=O(P/P')/(1+O(P/P'))=6.4/7.4=0.87
����(2).��P(θ/P')
������ΪP(P/P')=0.87�� p(P),����
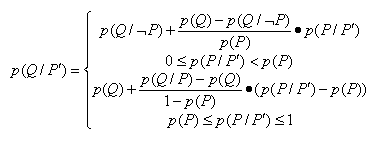
P(θ/P')=0.04+��0.81-0.04��*��0.87-0.05��/(1-0.05)=0.04+0.66=0.70
5. ��MYCIN�У��������¹���
R1: IF E1 THEN H (0.8)
R2: IF E2 THEN H (0.6)
R3: IF E3 THEN H (-0.5)
R4: IF E4 AND (E5 OR E6) THEN E1 (0.7)
R5: IF E7 AND E8 THEN E3 (0.9)
��ϵͳ�������Ѵ��û�����CF(E2)=0.8, CF(E4)=0.5, CF(E5)=0.6, CF(E6)=0.7, CF(E7)=0.6, CF(E8)=0.9, ��H���ۺϿ��Ŷ�CF(H)��
�� (1)��֤��E4,E5,E6����ϵĿ��Ŷ�

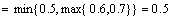
(2)���ݹ���R4,��CF(E1)

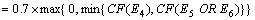
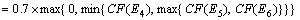

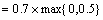

(3)��֤��E7,E8����ϵĿ��Ŷ�

(4)���ݹ���R5, ��CF(E3)

(5)���ݹ���R1, ��CF1(H)

(6)���ݹ���R2, ��CF2(H)
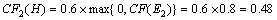
(7)���ݹ���R3, ��CF3(H)

(8)����ɶ���֤�ݵ����ļ���H�Ŀ��Ŷ�CF1(H),CF2(H)��CF3(H),�õ�H���ۺϿ��Ŷ�:



6.��ѧ�����Գɼ�������Ϊ{A��B��C��D��E}��С���ɼ���A����B����A��B�Ļ������ʷֱ���䵽0.2��0.1��0.3��Bel({C, D, E})Ϊ0.2�������Bel({A, B})��Pl({A, B})��f({A, B})��
��Bel({A, B}) = m({A}) + m({B}) + m({A, B}) = 0.2 + 0.1 + 0.3 = 0.6
���� Pl({A, B})= 1 - Bel({C, D, E}) = 1 - 0.2 = 0.8
���� f({A, B}) = Bel({A, B}) + |{A, B}| / |U| · [Pl({A, B}) -Bel({A, B})] = 0.6 + 2/5 ·(0.8 - 0.6) =0.6 + 0.08 = 0.68
-
�˹������ĵ����
�˹�����ѧϰ�ĵý�������ѧϰ�˹����ܵĵ�һ�ÿ�Ҳ�����ϴ�ѧ������һ�νӴ��˹��������ſ�ͨ����ʦ�Ľ����Ҷ��˹���������һЩ�ĸ��ԡ�
-
�˹������ܽ�(������)
1PROLOG����һ����һ����ʵ��������������ʵһ���ʾ��������ʻ��ϵ����һ���ʾ�����������ϵ�̺���ϵ���Ӧ��ϵ�����ʾ�á�
- �˹�������ĩ�ܽ�
- �˹������ܽ�
-
�˹������ܽ�
11ʲô���˹������˹�����ArtificialIntelligence�������豸��������˹��ķ��������Ե�˼ά����̽���ģ�ʹ��
-
�˹�����ʮ���㷨�ܽ�
51��������ѧϰʮ���㷨��ÿ���㷨�ĺ���˼�빤��ԭ�������������ȱ���1C45�㷨ID3�㷨������Ϣ��Ϊ��������Ϣ�غ���Ϣ�����Ϊ��
- �˹������ܽ�
-
�˹�������ĩ�ܽ�
1�˹������Ǻ�ʱ�ε�����������19xx���ļ�������һЩ������ѧ����ѧ�������ѧ��Ϣ�ۺ���ѧ�о�������ѧ�����Dartmouth��
-
���˹����ܡ�ѧϰ����
���ڴ�ѧ˶ʿ�о����γ���ҵ�˹������˹�����ѧϰ�������ڴ�ѧ��������ƹ���ѧԺ������ѧ��09430102101�����˹�����Artif��
- �˹����ܼ���Ӧ�ÿγ��ܽ�