Spss总结
Spss总结
一、Spss的简要介绍
1菜单(了解,掌握几个常用的)
File:文件管理菜单。有关文件的调入,存储,显示和打印等。 Edit:编辑菜单。有关文本内容的选择,拷贝,剪贴,寻找和替换等。 View:
Data:数据管理菜单。有关数据变量变义,数据格式选定,观察对象的选择,排序,加权,数据文件的转换,连接,汇总等。
Transform:数据转换处理菜单。有关数据的计算,重新赋值,缺失值替代等。 Analyze:分析数据菜单。几乎所有的常用统计分析过程都可以在这个菜单里找到,除了分析前的预处理,如整理数据,筛选数据,以及少数需要Syntax来完成的统计过程。 Graphs:作图菜单。有关统计图的制作,自定义表格,均值比较,概括描述等。 Utilities:用户选项菜单。有关命令解释,字体选择,文件信息,定义输出标题,窗口设计等。
Add-ons:程序加载项目,程序应用,服务及编程延迟等。
Windows:窗口管理菜单。有关窗口的排列,选择,显示等。
Help:求助菜单。有关帮助文件的调用,查询,显示等。
2 Spss的窗口:
2.1在spss左下方有两个窗口,一个是“Data View”为输入数据窗口,默认为激活状态;另一个是”Variable View”是定义变量的窗口。
2.1.1在“Data View”为输入数据窗口中:
? 列:
一列对应一个变量,即每一列代表一个变量或一道题目或个人的资料特征,如:性别、是否独生子女,年级,问卷上的第一题,第二题........。
? 行:
每一行代表一个个体,即一个被试的所有信息均在同一行呈现,spss中称为Case。
2.1.2在”Variable View”是定义变量的窗口中:
定义变量时注意以下事项:
? 只填写数字不行,需要在数字前加汉字,如“第一题”;或加字母如“A1”; ? 为保证题号与问卷题号一致,可以直接在数据编辑窗口从第一题开始输入,直至输完所有题目。(仅输一个被试的数据)。这样就不用定义数据名称了。
? 如果需要输入汉字,如姓名,学校等,需要把变量属性,改为“String”,(默认的是N),注意问卷各题输入的数据类型应该是N型,否则不能进行加减运算。 ? 为了输入数据时比较方便快捷,可以将文字资料,如男女,定义为数字符号,如男为1,女为2.Values一栏,Value 1,label 男,点Add
? 可以利用Insert插入变量或数据
3 spss的结果输出窗口OUTPUT
每次在SPSS窗口中的操作都会在结果窗口中告知。
结果输出窗口分为左右两个部分,左边为索引输出区,用于显示已有的分析结果标题和内容索引;右边为各个分析的具体结果,称之为详解输出区。
二、spss数据的基本操作
(一)导入数据——把excel数据导入spss
注意:
? 一定要给问卷编号,以便做善后工作;
? 先将题目导过去:顶格将题目数据导入,选取数据复制粘贴;然后再用insert插入个人资料,如性别、年级等。
? 如果原来的数据是汉字,要在variable view中type栏修改为string字符型。 ? 检查所有题目的数据类型是N数值型。
(二)检查数据——analyze——Descriptives Statistics——(1.123Frequencies(频率统计) 把所有变量选入;
从结果看变量是否有异常。
选中所有变量:选中第一个变量,加Shift,加最后一个变量。
(三)反向计分
Transform中第三个X——X打开,将需要反向计分的项目导入,在old and new栏中导入反向计分题目的计分对比,点击add添加。
(四)计算变量
Transform中的第一个打开COMPUTE
第一种方法:在target variable输入维度名称(因子),function group选择all;下面的框中选择mean,导入该维度下的题目,点ok,结果的解释是该维度的得分,会在spss表中的后面出现。
第二种方法:直接用加号加在一起,然后除以题目数。
注意:输入逗号时,一定要用英文状态下输入。
(五)高低分组
1. 排序:菜单栏→Date→Sort cases→选中总分→点击总分到Sort by→OK
2. 分组:Transform→X,Y→偶数题→Name 下输入高低分组→Change→Old and New Values→在Range lowest through values输入低分组的最高分→value里输入1→add→再输入高分组的最低分→value输入2→add→continute→OK
(其中最高分和最低分都要计算27%)
三、项目分析法
1.求方差法
Analyze ——Descriptive statistics→Descriptives→选入所有题目—— 右边窗口→Options→选中Variance→continue→OK
2.相关法
Analyze ——Correlation——Brivate,选入各维度包括的题目与所在维度(情绪疲惫)分数,计算每道题目与所属维度的相关。或者选入每题与总分,计算每题与总分的相关。 结果举例:
3.临界比率法
①利用倦怠总分分为高低两组组27%,(方法见上)
②对高低两组在每一道题上做独立样本T检验;
③若高低两组在题目上差异显著,则说明该题符合要求,若差异不显著,则删除。 注意:Sig<0.05 表示显著,<0.01非常显著,<0.001极其显著(三个星号); Output结果中只显示两个星号,实际论文写作中要写三个星号。
结果示例:
采用求每个题项“临界比率”(CriticalRatio,简称CR值)的方法,将未达到显著水平的题项予以删除。即将总分按从高到低的顺序排列,得分前27%者为高分组,得分后27%者为低分组,求出高低两组被试在每题得分平均数差异的显著性检验,如果CR值没有达到显著标准即表示这个题目不能鉴别不同被试的反应程度,这个题目应当删除。统计结果显示,西医版问卷各题均达.000的显著水平,即各题项的区分度良好。
四、因素分析(以教师倦怠数据为例)
4.1是否适合进行因素分析
输入数据(文件→open中添加所需的数据)→Analyze tsrDate Redution→Factor→选题目(a1,a2…)→Descriptive(描述性数据)→KMO and Bartlett’s test of sphericity→continue→OK
Output:KMO and Bartlett’s test 表格,看是否显著再决定是否进行因素分析→1.看Sig 的值是否显著 2.KMO>0.5
4.2 抽取因子
Analyze Date Redution→Factor→选所需的题目(a1~a15)→Extraction→Scree plot→continue→OK
Output:1.Scree plot 碎石图
2.Total Variance Explained表中total(特征值)显示大于1的表示有几个因子
3.Component Matrix表显示每道题与每个因子的相关系数。从这里可以看出每个因子所包含的题目(选相关系数较大的)
注:如上步骤→scree plot中的Number of factor 填入数字3→continue→OK
则Output:Component Matrix中就会出现3个因子
注:因素负荷:指特定题目与有关因子的相关系数
特征值:Total Variance Explained表中第一个Total栏所对应的值
共同度:一道题目与每个因子相关系数的平方和
4.3因子旋转:
Analyze Date Redution→Factor→选题目(如a1~a15)→Rotation Variances →Continue→OK
Output:Rotated component Matrix表是每道题与因子的相关程度。旋转后的各题与某个因子的相关系数更大,与其他因子的相关更小,便于我们更方便地确定每道题属于哪个因子。
注:可以在结果显示中去掉小于0.1的值,这样更方便找出题目与因子的相关系数(取大值)。具体操作:
Analyze Date Reduction Factor→选题→Opeions→suppress obsolete values less than 0.1→continue→OK
结果示例:
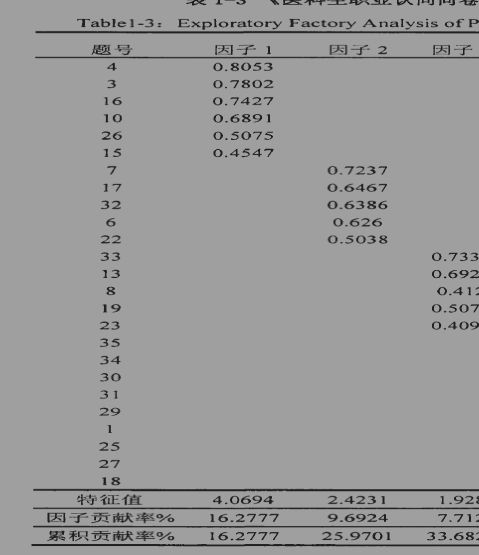
首先对医科生职业认同问卷(中医版)进行了KMO与Bartlett球形检验。求出KMO系数为.898(>0.50),说明样本量充足,Bartlett球形检验值为2897.2389,卡方值显著,说明变量内部有共享因素的可能性,也满足进行因素分析的先决条件。
医科生职业认同问卷(中医版)同样使用主成分分析法和正交极大方差旋转法进行因素分析,结果发现6个因子的累积贡献率达54.73%。因子1中6个题项共同体现的是“情感认同”;因子2体现的是“能力认同”;因子命名为“职业意志”;因子5有3个题项,也命名为“职业价值观”;因子4的题项共同构成“职业认知”。
五、结构效度(维度与维度,维度与总分)
Analyze→correlate→Bivariate→选几个维度与总分)→OK
结果举例:
表12 各因素之间以及各因素与问卷总分的相关
变量 F1 F1 1.000
F2
F3
F4
F5
F6
F7
F8
F9
F10
F11
F12 总分
F2 0.404 1.000
F3 0.288 0.122 1.000
F4 0.377 0.287 0.176 1.000
F5 0.294 0.339 0.204 0.167 1.000
F6 0.408 0.365 0.218 0.179 0.171 1.000
F7 0.342 0.516 0.124 0.154 0.364 0.299 1.000
F8 0.274 0.231 0.259 0.150 0.263 0.279 0.316 1.000
F9 0.241 0.144 0.274 0.163 0.242 0.194 0.160 0.158 1.000
F10 0.227 0.208 0.243 0.111 0.294 0.219 0.255 0.225 0.291 1.000
F11 0.325 0.129 0.283 0.131 0.253 0.098 0.187 0.240 0.250 0.222 1.000
F12 0.201 0.167 0.090 -0.034 0.236 0.209 0.217 0.168 0.175 0.318 0.105 1.000
总分 0.694 0.637 0.545 0.447 0.569 0.587 0.610 0.558 0.416 0.474 0.432 0.386 1.000
上表是根据相关分析检验各个因素之间的结构效度。根据相关分析原理,各个因素应该与问卷总分具有较高的相关,以体现问卷整体的同质性;各个因素的相关应该适当,相关过低说明社会自我构念上同质性太低,相关过高则说明因素之间有重复成分。
从表中可以看出,各个因素之间的相关在-0.034—0.516之间,较低的相关主要来自角色体验因子,这一因素具有相对独立性,其他绝大多数因素之间的相关适中。这说明问卷具有较好的结构效度。
六、信度分析
Analyze→scale→Reliability analyze→选入各个维度的题目或所有题目→OK
选入所有题目:问卷总的Cronbach’s Alpha系数;若选入某维度的题目,则求的是某维度的Cronbach’s Alpha系数。
Output:Reliability Statistics表中Cronbach’s Alpha 结果举例:
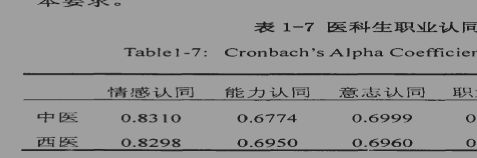
在本研究中,采用内部一致性系数作为检验信度的指标。两版问卷各维度以及总分的Cronbach系数。系数见表1一7。由表可见,中医和西医版问卷总的内部一致性系数均高于各因素,这说明问卷各因素测得的心理特质既有较高的同质性又有一定的区别,而各维
度的同质信度又均大于0.6,达到了问卷信度的基本要求。 七、T检验(必考)
(一)独立样本T检验 7.1 Eg:性别差异检验
Analyze—— Compare means(均数比较)→Independent sample T test——Test Variable:选各维度及总分,组别选入:性别→Define Groups(定义组与性别的输入数据相同) Output:
T检验之前检查方差是否齐性:看第一个Sig值(若大于0.05则齐性,看第一行的T值,若小于0.05则不齐性,选第二行的T值;再看第2个Sig值,若大于0.05则无差异,若小于0.05则有显著的差异) 结果示例:
表1 不同地区小学教师职业倦怠的差异检验
因素 情绪疲惫 少成就感 去个人化 职业倦怠总分
城镇(n=152)
3.53±0.71 4.00±0.68 4.54±0.60 4.02±0.50
农村(n=119) 3.63±0.61
4.30±0.54 4.72±0.42 4.22±0.40
t
-1.25
-4.15*** -2.96** -3.62***
P
.213 .000 .003 .000
注:**P<0.01,***P<0.001 进行独立样本t检验发现,城乡小学教师在情绪疲惫上不存在显著差异,而农村小学教师的成就感水平极其显著地低于城镇教师,倦怠总分和去个人化水平非常显著地高于城镇教师(见表1)。
(二)单一样本T检验 输入数据(Scl-90)
Analyze—— Compare Means→One sample T Test→选维度→在Test value输入常模或某一标准 Output:
One-sample Statistics表,可以看出平均值(Mean),标准差(Std Deviation),标准误(Std Error)。是否显著直接看Sig,若大于0.05则差异不显著,若小于0.05则差异显著。
结果示例:
表2 我校大学新生心理健康状况与全国大学生常模的比较
项目 躯体化 强迫 人际敏感 抑郁 焦虑 敌对 恐怖 偏执 精神病性
我校大学新生 1.35±0.35 1.76±0.48 1.63±0.48 1.47±0.51 1.50±0.41 1.38±0.41 1.36±0.39 1.58±0.49 1.46±0.38
全国大学生常模1.5±0.54 2.09±0.63 2.08±0.84 1.87±0.48 1.68±0.57 1.92±0.68 1.45±0.45 1.96±0.73 1.71±0.54
t值及显著性
-15.68*** -25.86*** -34.74*** -29.19*** -16.46*** -48.35*** -8.67*** -3.11** -24.86***
注:*:p<0.05,**:p<0.01,***:p<0.001
表2是对我校大学新生心理健康自测问卷SCL-90结果与全国大学生常模的比较。结果发现:我校大学新生在偏执的维度上非常显著地低于全国常模,在躯体化、强迫、人际敏感、抑郁、焦虑、敌对、恐怖和精神病性的维度上极其显著地低于全国常模。结果表明我校新生的心理健康状况高于全国大学生心理健康的常模水平。
(三)相依(配对)样本T检验
Analyze—— Compare Means→ paired samples T Test→选中要配对检验的项目 Output:
paired samples statistics表:选中项目各自的平均数,标准差,标准误
paired samples correlations:correlation一下数据表示选中项目间的项目系数的高低表示两者的差异性,结果中一般不用呈现,Paired Samples Test:两者差的平均值,标准差,标准误;看Sig,若小于0.05,则有显著差异。
结果示例:
表4 实验组前后测得分比较
前测(N=15) 后测(N=15) t值 M SD M SD SDS 65.00 5.59 47.33 4.48 12.03*** 人际 26.73 3.01 44.00 2.33 15.80*** (注: *代表p<0.05,**p<0.01,***p<0.00l;检验方法为配对样本T检验)
如表4所示,从总体上看,实验组在SDS和人际交往能力问卷上的前后测得分有显著性差异,实验后好于实验前。说明实验结束后,患者的抑郁症状得到了良好的缓解,人际交往能力得到了明显改善。从平均数上也可以直观地发现,实验后实验组SDS和人际交往能力量表总分均好于实验前。
八、方差分析(F检验) (必考)
输入数据(以教师倦怠数据为例)
Analyze—— Compare Means→ One-way ANOVA→在Dependent list下选入各维度及总分,在Factor中选中自变量(如年级、学历等);
Post HOC→选中LSD或Scheffe→ continue
Options→选中Descriptive→ OK
Output:以职称为例
①首先看F值(ANOVA表),看Sig值来检查F值是否显著。
②若F值显著则继续看事后比较表,若不显著则不用看。
③看Multiple Comparison(事后比较)表,从表中看出每一职称与另一职称在少成就感方面的差异,看Sig值,找出小于0.05的值,对于第二行2与1,4显著。在事后检验中回到Descriptive表,在少成就感这一维度平均值一栏中2>1,4>2,因此在事后检验中写上2>1,4>2,若能综合在一起,则应写在一起。
注:若考察不同年龄、教龄等组别较多时,为了研究结果更概括,更有意义,需要进行分组。
以教师倦怠为例:Analyze Descriptive statistics→123Frequencies→选中教龄→OK,观察教龄的具体分布情况,便于分组人数更均匀。
Output:教龄,根据cumulative Percent(累计频率)来决定所需分组的组表。
结果示例:表2 不同教龄小学教师职业倦怠的差异检验
因素 情绪疲惫 少成就感 去个人化 职业倦怠总分
教龄段1 (n=55) 3.60±0.67 3.92±0.67 4.30±0.67 3.96±0.53
教龄段2
(n=86) 3.50±0.77 4.03±0.71 4.67±0.51 4.07±0.53
教龄段3
(n=86) 3.65±0.61 4.23±0.57 4.71±0.45 4.20±0.38
教龄段4
(n=44) 3.56±0.58 4.41±0.44 4.75±0.36 4.24±0.33
F
0.736
6.61*** 9.48*** 5.07**
事后检验 3,4>1,2 2,3,4>1 3,4>1 *P<0.05,**P<0.01,***P<0.001 以职业倦怠为因变量,教龄为自变量进行单因素方差分析,结果发现小学教师在职业倦怠总分、少成就感和去个人化维度上均存在极其显著的教龄差异,有统计学意义。事后检验表明,20年以上教龄的小学教师成就感极其显著地低于20年以下教龄的教师,职业倦怠总分显著高于10以下教龄教师。10年以下教龄的小学教师在去个人化水平上极其显著地低于其他教龄段教师。不同教龄的小学教师在情绪疲惫和上不存在显著差异(见表2)。 -
-
Spss实验总结
Spss总结本学期一共学习了七项spss使用方法分别是数据整理数据的转换t检验方差分析卡方检验相关分析与回归方程图表的制作与编辑我…
-
spss实验报告
湖北汽车工业学院SPSS实习报告学号20xx0530501姓名杨文弟指导教师彭娟娟曾智实验一描述性统计分析一实验目的利用SPSS进…
-
spss实验报告1
统计分析与SPSS的应用实验报告一一数据来源及说明本次试验报告数据来源于19xx年美国社会变迁普查19xxUSGeneralSoc…
- spss实验报告
-
spss实验报告模板
实验报告实验三连续变量的统计描述与参数估计实验目的1了解连续变量的统计描述指标体系和参数估计指标体系2掌握具体案例的统计描述和分析…
-
spss学习心得
学院:传播学院专业:10级广播电视新闻学学号:1290120xx023姓名:许咪咪学习SPSS有感——与EXCEL之比较在学习SP…
-
spss课程实习报告
安康学院经济与管理系课程实习报告课程名称统计分析软件实习实习时间实习地点信息管理与电子商务实验室班级专业11级信息管理与信息系统1…
-
Spss总结
Spss总结二描述性统计分析在调查时一般很难得到对象的整体只能从整体中抽取样本统计学就是通过样本数据来研究整体数据的一门科学它分为…
-
spss学期笔记总结
学期笔记总结一基本掌握1研究要注意的问题2题目的输入编码各种题型的输入方法3数据的筛选DataselectcasesAsimple…
-
spss心得体会
学习SPSS在教育统计中的应用心得体会一什么是SPSS为什么要学习SPSS新学期开始时在信息化教育测量与评价的课程中第一次接触到S…