折半查找数据结构实验报告
数据结构实验报告三
题目:
试编写利用折半查找确定记录所在块的分块查找算法。
提示:
1) 读入各记录建立主表;
2) 按L个记录/块建立索引表;
3) 对给定关键字k进行查找;
测试实例:设主表关键字序列:{12 22 13 8 28 33 38 42 87 76 50 63 99 101 97 96},L=4 ,依次查找K=13, K=86,K=88
算法思路
题意要求对输入的关键字序列先进行分块,得到分块序列。由于序列不一定有序,故对分块序列进行折半查找,找到关键字所在的块,然后对关键字所在的块进行顺序查找,从而找到关键字的位置。
故需要折半查找和顺序查找两个函数,考虑用C++中的类函数实现。因为序列一般是用数组进行存储的,这样可以调用不同类型的数组,程序的可适用性更大一些。
折半查找函数:
int s,d,ss,dd;//声明一些全局变量,方便函数与主函数之间的变量调用。
template <class T>
int BinSearch(T A[],int low,int high,T key)//递归实现折半查找
{
int mid;// 初始化中间值的位置
T midvalue;// 初始化中间值
if (low>high)
{
s=A[high];
d=A[low];
ss=high;
dd=low;
return -1;}// 如果low的值大于high的值,输出-1,并且将此时的low与high的值存储。
else
{
mid=(low+high)/2;// 中间位置为低位与高位和的一半取整。
midvalue=A[mid];
if (midvalue==key)
return mid;
else if (midvalue < key) //如果关键字的值大于中间值
return BinSearch(A,mid+1,high,key);// 递归调用函数,搜索下半部分
else
return BinSearch(A,low,mid-1,key);// 否则递归调用哦个函数,搜索上半部分
}
}
以上为通用的折半查找的函数代码,这里引入了几个全局变量,主要是方便在搜索关键字在哪一个分块中时,作为判断条件。
顺寻查找函数:
template <class T>
int shuxuSearch(T A[],int high,T key)// 顺序查找
{
int i=0; A[high]=key;// 初始化i,使 A的最高位为key值
while(A[i]!=key)
i++;
return i;// 如果A中有key值,则在i不到n+1时就会输出,否则,返回high值,说明搜索失败。
}
主函数中,首先对所需要的参数变量进行初始化,由键盘输入关键字,分块的多少,每一块有多少个关键字。为了用户的人性化考虑,这里由用户自己决定分块的多少和数目。为了实现这一功能,引入了一个动态存储的二维数组:
int **p2 ;
p2 = new int*[row] ;//声明一个二维数组
for( i = 0 ; i < row ; i ++ )
p2[i] = new int[col] ;
for( i = 0 ; i < row ; i ++ )
{for( j = 0 ; j < B[i] ; j ++ )
{p2[i][j]=A[k];
k=k+1;}
}//将所有关键字,按块的不同存入二维数组中
cout<<"分块情况为"<<endl;
for( i = 0 ; i < row ; i ++ )
{
for( j = 0 ;j <B[i] ; j ++ )
{cout<<p2[i][j]<<' ' ;
if(p2[i][j]>=M[i])
M[i]=p2[i][j];
}
cout<<endl;
}//输出二维数组,检验分块是否为预期
将各种信息用各种数组加以存储,在需要时不断调用。
另外,由于题目中需要多次查找,为了避免每次查找的反复输入,引入了一个while循环,保证可以多次查找并输出结果。
在关键字等信息输入完毕后,进行查找,可以得到该关键字所在块的序号,以及该关键字在整个关键字序列中的位置。
程序结构
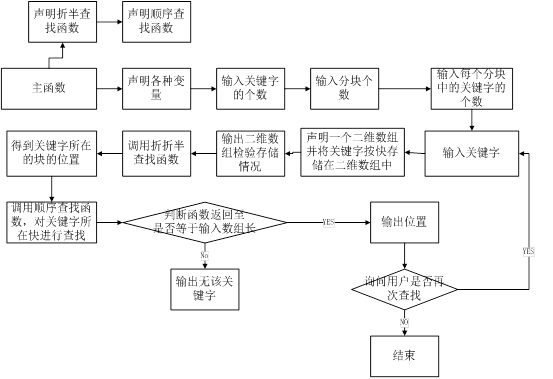
源代码:
#include <iostream>
using namespace std;
int s,d,ss,dd;//声明一些全局变量,方便函数与主函数之间的变量调用。
template <class T>
int BinSearch(T A[],int low,int high,T key)//递归实现折半查找
{
int mid;// 初始化中间值的位置
T midvalue;// 初始化中间值
if (low>high)
{
s=A[high];
d=A[low];
ss=high;
dd=low;
return -1;}// 如果low的值大于high的值,输出-1,并且将此时的low与high的值存储。
else
{
mid=(low+high)/2;// 中间位置为低位与高位和的一半取整。
midvalue=A[mid];
if (midvalue==key)
return mid;
else if (midvalue < key) //如果关键字的值大于中间值
return BinSearch(A,mid+1,high,key);// 递归调用函数,搜索下半部分
else
return BinSearch(A,low,mid-1,key);// 否则递归调用哦个函数,搜索上半部分
}
}
template <class T>
int shuxuSearch(T A[],int high,T key)// 顺序查找
{
int i=0; A[high]=key;// 初始化i,使 A的最高位为key值
while(A[i]!=key)
i++;
return i;// 如果A中有key值,则在i不到n+1时就会输出,否则,返回high值,说明搜索失败。
}
int main()
{
int i,key,pos,length,fen,k,j,a,kuai,e;// 定义一些变量
a=0;
k=0;
cout<<"请输入关键字的个数"<<endl;
cin>>length;
int A[length-1]; // 根据输入关键字的个数初始化一个数组进行存储
cout<<"请输入要分块的个数"<<endl;
cin>>fen;
int B[fen-1];
int M[fen-1];
for(i=0;i<fen;i++)
{M[i]=0;}// 初始化两个数组,一个用来存储每一块元素的大小,另一个用来存储每一块的中元素的最大值
cout<<"请输入每个分块关键字的个数"<<endl;
for(i=0;i<fen;i++)
{cin>>B[i];}//使数组B中表示每块中关键字的个数
cout<<"请输入关键字"<<endl;
for(i=0;i<length;i++)
{cin>>A[i];}//输入所有的关键字,存在数组A中
int row,col;
row=fen;
col=length;
int **p2 ;
p2 = new int*[row] ;//声明一个二维数组
for( i = 0 ; i < row ; i ++ )
p2[i] = new int[col] ;
for( i = 0 ; i < row ; i ++ )
{for( j = 0 ; j < B[i] ; j ++ )
{p2[i][j]=A[k];
k=k+1;}
}//将所有关键字,按块的不同存入二维数组中
cout<<"分块情况为"<<endl;
for( i = 0 ; i < row ; i ++ )
{
for( j = 0 ;j <B[i] ; j ++ )
{cout<<p2[i][j]<<' ' ;
if(p2[i][j]>=M[i])
M[i]=p2[i][j];
}
cout<<endl;
}//输出二维数组,检验分块是否为预期
cout<<"每个块最大元素为"<<endl;
for(i=0;i<fen;i++)
{cout<<M[i]<<endl;}//将每一组的最大元素存入数组M中
cout<<endl<<"请输入要查找的元素";
cin>>key;//将要查找的关键字赋值给key
pos=BinSearch(M,0,length-1,key);//调用折半查找函数,查找关键字处于哪个块中
cout<<"该元素所处的块是"<<endl;
if (pos!=-1)
{kuai=pos;
cout<<kuai<<endl;
}
else
{kuai=dd;
cout<<kuai<<endl;}//将关键字所在的块输出。
int *S;
S = new int[kuai] ;
for(i=0;i<B[kuai];i++)
{S[i]=p2[kuai][i];
}//初始化一个一维数组,将 关键字所在快的元素重新定义为一个数组S
pos=shuxuSearch(S,B[kuai],key);//在S中顺序查找关键字
int q=0;
for(i=0;i<kuai;i++)
{q=q+B[i];}
if (pos!=B[kuai])
cout<<"该元素的位置为"<<pos+q<<endl;//如果关键字存在,输出其位置
else
cout<<"不存在该元素"<<endl;//若不存在,输出“不存在该元素”
cout<<"还要继续查找吗?是的话,输入1,不是的话输入0"<<endl;
cin>>e; //引入判断条件,以便多次查找
while ((e!=1)&&(e!=0))
{cout<<"输入不合法,请重新输入e"<<endl;
cin>>e;}//保证输入合法
while (e==1)
{
cout<<endl<<"请输入要查找的元素";
cin>>key;
pos=BinSearch(M,0,length-1,key);
cout<<"该元素所处的块是"<<endl;
if (pos!=-1)
{kuai=pos;
cout<<kuai<<endl;
}
else
{kuai=dd;
cout<<kuai<<endl;}
for(i=0;i<B[kuai];i++)
{S[i]=p2[kuai][i];}
pos=shuxuSearch(S,B[kuai],key);
int q=0;
for(i=0;i<kuai;i++)
{q=q+B[i];}
if (pos!=B[kuai])
cout<<"该元素的位置为"<<pos+q<<endl;
else
cout<<"不存在该元素"<<endl;
cout<<"还要继续查找吗?是的话,输入1,不是的话输入0"<<endl;
cin>>e; //与上面程序一致,通过循环条件保证可以多次进行查找
}
system("pause");
return 0;
}
输出结果:
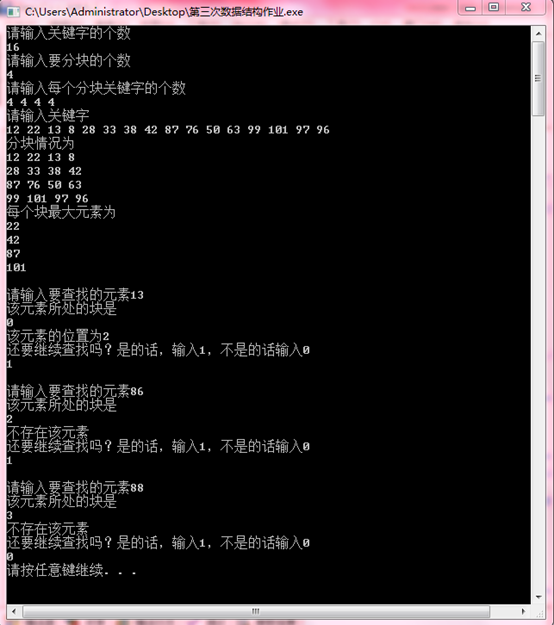
说明:可见,按照16=4*4分块的选择方式,13元素在第0块,处于关键字序列中的第2位。86和88元素都不在关键字序列中。
另外,由于程序中引入了可以由用户自己选择分块数目和大小的功能,因此,选择16=7+5+4(同样保证了分块有序)的分块方法可以得到一样的结果:
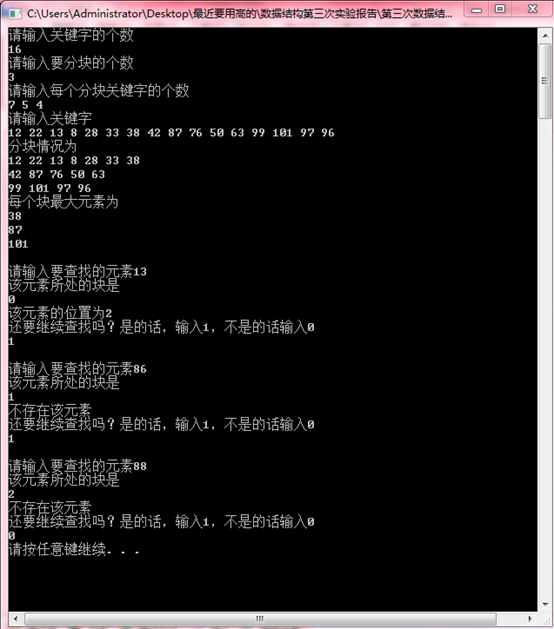
发现结果完全一致。
心得体会:
1) 本次实验程序结构比较简单,无需复杂的函数调用。但是由于本人编程基础不够扎实,在面对需要很多数组声明和调用的时候,经常弄错,在编译的过程中出现了很多次内存调用出错的情况。后来发现是二维数组的定义上没有做好,引入了动态定义的方法解决了这一问题。
2) 用户的需求是编程的主要目的,这道题如果输入以及分块由编程者自己定义,虽然可以大大简化编程的繁琐度,但是并没有太大的实际意义。
3) 引入while循环使程序可以多次查找,语句并不复杂,但是实现的功能却比较理想。
第二篇:数据结构实验报告-静态查找表中的查找
数据结构实验
实验一 静态查找表中的查找
一、实验目的:
1、理解静态查找表的概念
2、掌握顺序查找和折半查找算法及其实现方法
3、理解顺序查找和折半查找的特点,学会分析算法的性能
二、实验内容:
1、按关键字从小到大顺序输入一组记录构造查找表,并且输出该查找表;
2、给定一个关键字值,对所构造的查找表分别进行顺序查找和折半查找,输出查找的结果以及查找过程中“比较”操作的执行次数。
三、实验要求:
1、查找表的长度、查找表中的记录和待查找的关键字值要从终端输入; 2、具体的输入和输出格式不限;
3、算法要具有较好的健壮性,对错误操作要做适当处理; 4、输出信息中要标明所采用的查找方法类型。
实验二 基于二叉排序树的查找
一、实验目的:
1、理解动态查找表和二叉排序树的概念 2、掌握二叉排序树的构造算法及其实现方法 3、掌握二叉排序树的查找算法及其实现方法
二、实验内容:
1、输入一组记录构造一颗二叉排序树,并且输出这棵二叉排序树的中序序列; 2、给定一个关键字值,对所构造的二叉排序树进行查找,并输出查找的结果。
三、实验要求:
1、二叉排序树中的记录和待查找的关键字值要从终端输入;
2、输入的记录格式为(整数,序号),例如(3, 2)表示关键字值为3,输入序号为2的记录; 3、算法要具有较好的健壮性,对错误操作要做适当处理。
四、程序实现:
(1)实现顺序查找表和折半查找表:
#include<stdio.h>
#define MAX_LENGTH 100 typedef struct {
int key[MAX_LENGTH]; int length; }stable;
int seqserch(stable ST,int key,int &count) {
int i;
for(i=ST.length;i>0;i--) {
count++;
if(ST.key[i]==key) return i; }
return 0; }
int binserch(stable ST,int key,int &count) {
int low=1,high=ST.length,mid; while(low<=high) {
count++;
mid=(low+high)/2; if(ST.key[mid]==key) return mid;
else if(key<ST.key[mid]) high=mid-1; else
low=mid+1; }
return 0; }
main() {
stable ST1; int
a,b,k,x,count1=0,count2=0,temp=0; ST1.length=0;
printf("请按从小到大的顺序输入查找表数据:(-1代表结束!)\n"); for(a=0;a<MAX_LENGTH;a++) {
scanf("%d",&temp); if(temp!=-1) {
ST1.key[a]=temp; ST1.length++; } else break; }
printf("输入数据为:\n"); for(b=0;b<ST1.length;b++) {
printf("%d ",ST1.key[b]); }
printf("\n请输入要查找的数据:"); scanf("%d",&k);
a=seqserch(ST1,k,count1)+1;
printf("\n顺序查找: 该数据的位置在第:%d个\n",a); printf("查找次数为:%d\n\n",count1-1);
a=binserch(ST1,k,count2)+1;
printf("折半查找: 该数据的位置在第:%d个\n",a); printf("查找次数为:%d\n",count2-1); }
(2)二叉排序树的查找:
#include<stdio.h> #include<malloc.h>
typedef struct node {
int data; int key;
struct node *left,*right; }bitnode,*bittree;
void serchbst(bittree T,bittree *F,bittree *C,int data) {
while(T!=NULL) {
if(T->data==data) {
*C=T; break; }
else if(data<T->data) {
*F=T; T=T->left; } else {
*F=T;
T=T->right; } }
return 0; }
int insertbst(bittree *T,int key,int data) {
bittree F=NULL,C=NULL,s; serchbst(*T,&F,&C,data); if(C!=NULL) return 0;
s=(bittree)malloc(sizeof(bitnode)); s->data=data; s->key=key;
s->left=s->right=NULL; if(F==NULL) *T=s; else if(data<F->data) F->left=s; else
F->right=s; return 1; }
void creatbst(bittree *T) {
int key,data;*T=NULL;
printf("请输入数据以构造二叉排序树:(数据格式为:m n (-1000,-1000)代表结束)\n");
scanf("%d%d",&key,&data); while(key!=-1000 || data!=-1000) {
insertbst(T,key,data);
scanf("%d%d",&key,&data); } }
void midTraverse(bittree T) {
if(T!=NULL) {
midTraverse(T->left); printf("(%d,%d) ",T->key,T->data);
midTraverse(T->right); } }
main() {
bittree
T=NULL,C=NULL,F=NULL; int key,data,temp; creatbst(&T);
printf("此二叉树的中序序列为:");
midTraverse(T);
printf("\n请输入要查找的关键字:");
scanf("%d",&data); serchbst(T,&F,&C,data);
printf("此关键字的数据为:%d\n",C->key); }
五、实现结果:
(1)顺序查找和折半查找:
(2)二叉树排序树查找:
六、实验之心得体会:
(1)在这次实验中,我基本上掌握了顺序查找、折半查找和二叉排序树查找的基本思想和实现方法,让我体会到了写程序时,不仅要考虑是否能够调试出结果,还要考虑程序实现的效率,这是一个编程人员必须要具备的一项总要的素质。
(2)通过这次实验,让我体会到同样的数据在不同的查询方法下有着不同的查询效率,就拿实验一来说,用顺序查找法在12个数据中查找一个关键字需要的查找的次数为8次,但是,如果折半查找法却只要两次,由此可以看出,我们在查找时不仅要考虑查找的实现,还要考虑查找的效率和查找所用的时间。
(3)用二叉排序树查找效率也比较高,只要你输入相应的关键字,就可已找到所需要的数据,就我个人看来,用二叉排序树的效率要比顺序查找和折半查找的效率更高,查询的速度更快。
-
数据结构查找实验报告
实验题91设计一个程序exp91cpp输出在顺序表36210185749中采用顺序方法找关键字5的过程程序如下文件名exp91cp…
-
数据结构实验报告 实验五 查找算法
昆明理工大学信息工程与自动化学院学生实验报告201201学年第一学期课程名称数据结构开课实验室年月日一实验内容查找算法其中线性表的…
-
数据结构查找实验报告
实验报告课程名称实验项目数据结构查找姓名xx专业班级学号网络工程网络132130402xxxx计算机科学与技术学院实验教学中心20…
-
数据结构查找算法实验报告
100410528孙晨添数据结构实验报告实验第四章实验简单查找算法一需求和规格说明查找算法这里主要使用了顺序查找折半查找二叉排序树…
-
《数据结构》实验报告查找
实验四查找一实验目的1掌握顺序表的查找方法尤其是折半查找方法2掌握二叉排序树的查找算法二实验内容1234建立一个顺序表用顺序查找的…
-
数据结构实验报告-静态查找表中的查找
数据结构实验实验一静态查找表中的查找一、实验目的:1、理解静态查找表的概念2、掌握顺序查找和折半查找算法及其实现方法3、理解顺序查…
-
数据结构上机实验报告
实验一线性表的基本操作实验目的学习掌握线性表的顺序存储结构链式存储结构的设计与操作对顺序表建立插入删除的基本操作对单链表建立插入删…
-
数据结构-实验8查找的算法
81实现顺序查找的算法一实验目的1熟悉掌握各种查找方法深刻理解各种查找算法及其执行的过程2学会分析各种查找算法的性能二实验内容81…
- 数据结构图实验报告
-
焦作数据结构实验报告
河南省高等教育自学考试实验报告册计算机及应用专业本科段数据结构姓名李威威准考证号所属地市焦作市实验地点焦作大学实验实训中心实验日期…