单道脉冲分析器验证实验报告
单道脉冲幅度分析器验证
实验目的:
1.进一步掌握单道脉冲幅度分析器电路的工作原理;
2.对单道脉冲分析器模拟仿真的电路图进行实物焊接。
3.对焊接完成的成品进行验证。
实验原理:
(1)单道脉冲幅度分析器:单道脉冲幅度分析器包括两个甄别器,一个叫上甄别器,甄别阀用V上表示;另一个叫下甄别器 ,甄别阀用V下表示;上、下甄别阀之差称为道宽,用ΔV表示,即:ΔV = V上 – V下 ;除了两个甄别器外,还有一个反符合电路。当信号Vin<V下时分析器无脉冲输出,Vin> V上时分析器无脉冲输出,V下<Vin<V上分析器有脉冲输出(如图2所示)。


单道脉冲幅度分析器结构框图 单道脉冲幅度分析器工作原理图
(2)反符合电路 其工作过程为:
1.当VI < VL 时,L和H都是低电平,显然与门输出为零。
2.当VL < VI < VH 时,H为低电平,H非为高电平,即双稳态清零端为高电平,V3 维持高电平不变,与门开放;而L的下降沿触发单稳输出正脉冲,经与门输出。
3.当VI > VH 时,H、L都有正脉冲输出,如果直接将上、下甄别电路输入脉冲进行反符合处理,由于脉冲上升时间和下降时间存在,将会发生甄别错误。此电路用非H的前沿将双稳态电路清零,保证在单稳态电路输出脉冲之前将与门关闭,而用单稳态电路输出正脉冲VI 的后沿将双稳态电路触发翻转,使V3 回到高电平状态,与门重新开放。


反符合电路原理图 信号关系图
(3)电压运放跟随器:电压跟随器具有很高的输入阻抗和很低的输出阻抗,是最常用的阻抗变换和匹配电路。电压跟随器常用作电路的输入缓冲级和输出缓冲级,它实际上就是Rf=0,R1=∞,反馈系数F=l时的同相输入放大器。

电压运放跟随器
实验步骤:
(1) 根据仿真电路图焊接电路板。
(2) 将完成电路板接入电源设置上下阈值分别约为1v,0.5v。
(3) 将焊接的电路板连接信号发生器与示波器进行验证。
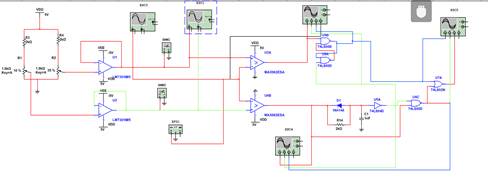
单道脉冲分析器仿真电路图
实验验证结果:
1)焊接完成的电路板

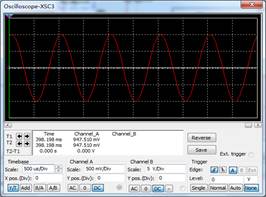
(1)输入信号(XCS3信号截图)与电路板对比:

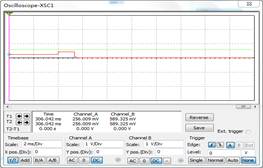
(2)上下阈值(由XCS1显示)

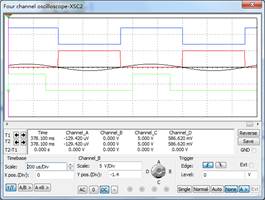
(3)反符合电路甄别过程与结果(由XCS2显示):



(4)XCS5结果:
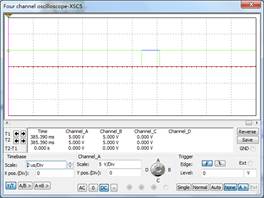

(5)XCS4结果:
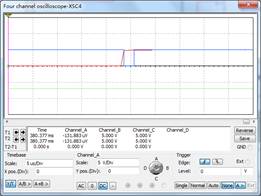


经过验证,实际电路板与仿真结果一致,电路板焊接成功。
第二篇:词法分析器实验报告
词法分析器实验报告
姓名: 学号: 时间:
实验内容:
用flex工具生成一个PL/0语言的词法分析程序,对PL/0语言的源程序进行扫描,识别出单词符号的类别,统计输出各种符号的信息
实验目的:
a) 理解编译器的工作机制
b) 掌握编译器的构造方法
c) 掌握词法分析器的生成工具LEX的用法
d) 掌握语法分析器的生成工具YACC的用法
实验环境:
Window XP
Visual C++ 6.0
Flex.exe
实验要求:
1.实现预处理功能。
源程序中可能包含有对程序执行无意义的符号,要求将其剔除。
2.实现词法分析功能。
输入:预处理过的源程序。
输出:把单词符号分为下面五类,然后统计PL0源程序中各单词符号出现的次数。
1) K类(关键字)
2) I类(标识符)
3) C类(常量)
4) P类(算符及界符)
5) O类(其他)
3.规则
? 语句类型:
– 赋值语句,if...then..., while...do..., read, write, call, 复合语句begin... end, 说明语句: const..., var..., procedure…
? 13个关键字:
– if, then, while, do, read, write, call, begin, end, const, var, procedure, odd
? 标识符定义为identifier,在程序中由范式定义:
– identifier {letter}({letter}|{digit})*
? 常量定义为Constant,在程序中由范式定义:
– number {digit}+
? 界符作为boundary-operator,在程序中通过列举定义:
– "("|")"|","|";"|"."
? 算符作为Operator,在程序中通过列举定义:
– "+"|"-"|"*"|"/"|
? 关系符号作为arithmetic-operator,在程序中通过列举定义
– "<>"|">="|"<="|":="|"="|"#"|"<"|">"|"++"|"--"|"+="|"-="
? 此外在程序中实现了错误字符,以及未知字符的定义:
– wrongid ({digit}+){letter}({letter}|{digit})*
? 空格、回车、换行符跳过。
代码调试:
根据lex的源程序的语法规则,源程序分为4个部分。
声明:
%{
#include<stdio.h>
#include<stdlib.h>
#define maxname 20
#define maxnum 1000
void print(); //输出token序列;
void main(int argc,char*argv[]); //主函数;
struct token{ //二元组;
char*idproperty; //token属性值;
char*idname; //识别的token名字;
}entity[maxnum]; //定义1000个这样的token,大小可改变;
char filename[maxname]; //源程序文件名;
int errnum=0; //错误token的数目;
int value; //属性值int型;
int linenum=1; //行数;
int count=0; //token的个数;
FILE*fpin; //测试文件指针;
FILE*fpout; //结果文件指针;
%}
辅助定义:
digit [0-9]
letter [a-zA-Z]
number {digit}+
identifier {letter}({letter}|{digit})*
wrongid ({digit}+){letter}({letter}|{digit})*
newline [\n]
whitespace [\t]+
识别规则:
"procedure"|"call"|"begin"|"end"|"var"|"const"|"if"|"then"|"while"|"do"|"read"|"write"|"odd" {value=0;print();}
{identifier} {value=1;print();}
{number} {value=2;print();}
"+"|"-"|"*"|"/" {value=3;print();}
"<>"|">="|"<="|":="|"="|"#"|"<"|">" {value=4;print();}
"("|")"|","|";"|"." {value=5;print();}
{wrongid} {value=6;print();}
{newline} {linenum+=1;}
{whitespace} {;}
" " {;}
. {value=7;print();}
%%
用户子程序:
void print()
{
count++;
if((fpout=fopen("My.txt","a"))==NULL){
printf("cannot write the file /n");
exit(0);
}
if(value<=5){ //正常情况下处理方式
switch(value){
case 0:entity[count-1].idproperty="BasicKey";break;
case 1:entity[count-1].idproperty="identifier";break;
case 2:entity[count-1].idproperty="number";break;
case 3:entity[count-1].idproperty="arithmetic-op";break;
case 4:entity[count-1].idproperty="relation-op";break;
case 5:entity[count-1].idproperty="boundary-op";break;
}
entity[count-1].idname=yytext;
fprintf(fpout,"%d <符号: \"%s\" , 类型:%s > \n",count,entity[count-1].idname,entity[count-1].idproperty);
}else{ //wrongid时处理方式
errnum+=1;
switch(value){
case 6:entity[count-1].idproperty="Mixed number and letter:";break;
case 7:entity[count-1].idproperty="Unkown operator:";break;
}
entity[count-1].idname=yytext;
fprintf(fpout,"%d [line:%d]: \"%s\" %s \n",count,linenum,entity[count-1].idname,entity[count-1].idproperty);
}
fclose(fpout);
}
void main()
{
printf("please input the PL//0 program file: ");
scanf("%s",&filename);
if((fpin=fopen(filename,"r"))==NULL){ //打开文件
printf("can't open the file: %s",filename);
exit(0);
}
yyin=fpin;
yylex(); /* yyin是个FILE类型的指针, 指向词法分析器要接收的待分析程序的指针。每调用一次,yylex 的返回值为当前分析的Word类型值。当文件结束时,yylex 的返回值为0。*/
if((fpout=fopen("My.txt","a"))==NULL){
printf("cannot write the file /n");
exit(0);
}
fprintf(fpout,"\n");
fprintf(fpout,"%d symbol(s) found. \n %d error(s) found.\n",count,errnum);
fprintf(fpout,"=======================================================================\n");
fclose(fpout);
yywrap();
}
操作过程:
Windows下用felx进行编译:

生成文件:

VC中编译:

生成文件记录结果My.txt:

测试结果如下(局部截图):


添加错误代码于第二行:

然后得到测试结果为:


- 验证性试验报告样式
-
实验验证报告
电子汽车衡衡器载荷测量仪法检定规程试验验证报告电子汽车衡衡器载荷测量仪法检定规程起草小组20xx年3月电子汽车衡衡器载荷测量仪法检…
-
验证性实验报告格式-更新20xx1105
深圳大学实验报告课程名称学报告学提交时间注1报告内的项目或内容设置可根据实际情况加以调整和补充学号附原始数据以上各页如不够可另附页…
-
戴维南定理的实验验证报告
戴维南定理学号姓名成绩一实验原理及思路一个含独立源线性电阻和受控源的二端网络其对外作用可以用一个电压源串联电阻的等效电源代替其等效…
-
实验分析用测试方法验证报告
方法验证报告方法名称验证单位通讯地址报告编写人报告日期1原始测试数据11实验室基本情况表11参加验证的人员情况登记表表12使用仪器…
- 比对和验证试验分析总结报告
-
实验室间比对和能力验证结果的分析报告
实验室间比对和能力验证结果的分析报告质管办为了通过适时开展比对试验和能力验证等质量控制活动对检测质量及其过程的有效性进行监控保证检…
-
能力验证和实验室间比对结果的分析报告
资料5能力验证和实验室比对结果的分析报告120xx年参见项目伤残程度鉴定结果满意20xx年本所首次参加能力验证活动接到能力验证计划…
-
实验室间比对和能力验证结果的分析报告
湖北华源包装有限公司实验室间比对和能力验证结果的分析报告为了通过适时开展比对试验和能力验证等质量控制活动对检测质量及其过程的有效性…
-
机动车检测站-比对,能力验证分析报告
机动车检测站比对能力验证分析报告按照实验室资质认定评审准则的要求及国家质量监督检验检疫机动车安全技术检验机构监督管理办法20xx总…