《数据结构课程设计》赫夫曼编码实验报告
目 录

一、概述.............................................. 1
二、系统分析.......................................... 1
三、概要设计.......................................... 2
四、详细设计.......................................... 4
4.1 赫夫曼树的建立................................. 4
4.1.1 选择选择parent 为0 且权值最小的两个根结点的算法 5
4.1.2 统计字符串中字符的种类以及各类字符的个数.... 7
4.1.3构造赫夫曼树............................... 8
4.2赫夫曼编码..................................... 10
4.2.1赫夫曼编码算法............................ 10
4.2.2建立正文的编码文件........................ 11
4.3代码文件的译码................................. 12
五、运行与测试....................................... 14
六、总结与心得....................................... 14
参考文献............................................. 15
附录................................................. 15
一、概述
本设计是对输入的一串电文字符实现赫夫曼编码,再对赫夫曼编码生产的代码串进行译码,输出 电文字符串。
在当今信息爆炸时代,如何采用有效的数据压缩技术节省数据文件的存储空间和计算机网络的传送时 间越来越引起人们的重视,赫夫曼编码正是一种应用广泛且非常有效的数据压缩技术。
二、系统分析
赫夫曼编码的应用很广泛,利用赫夫曼树求得的用于通信的二进制编码成为赫夫曼编码。树中从根到 每个叶子都有一条路径,对路径上的各分支约定:指向左子树的分支表示“0”码,指向右子树的分支表示 “1”码,取每条路径上的“0”或“1”的序列作为和每个叶子对应的字符的编码,这就是赫夫曼编码。
通常我们把数据压缩的过程称为编码,解压缩的过程称为解码。电报通信是传递文字的二进制码形式 的字符串,但在信息传递时,总希望总长度能尽可能短,即采用最短码。
假设每种字符在电文中出现的次数为W i ,编码长度为L i ,电文中有n 种字符,则电文编码总长为∑W i L i 。 若将此对应到二叉树上,W i 为叶节点的权 ,L i 为根节点到叶节点的路径长度。那么,∑W i L i 恰好为二叉 树上带权路径长度。
因此,设计电文总长最短的二进制前缀编码,就是以n 种子符出现的频率作权,构造一刻赫夫曼树, 此构造过程成为赫夫曼编码。
根据设计要求和分析,要实现设计,必须实现以下方面的功能:
(1) 赫夫曼树的建立;
(2) 赫夫曼编码的生成;
(3) 编码文件的译码;
三、概要设计
程序由哪些模块组成以及模块之间的层次结构、各模块的调用关系;每个模块的功能。
void main()
void HufffmanEncoding(HuffmanTree HT,HuffmanCode HC)//编码部分
char *decode(HuffmanCode Hc)//译码
void ChuffmanTree(HuffmanTree HT,HuffmanCode HC,int cnt[],char str[]) //生成Huffman树
void select(HufmanTree HT,int k,int &s1,int &s2) //找寻parent为0,权最小的两个节点
其流程图如下:
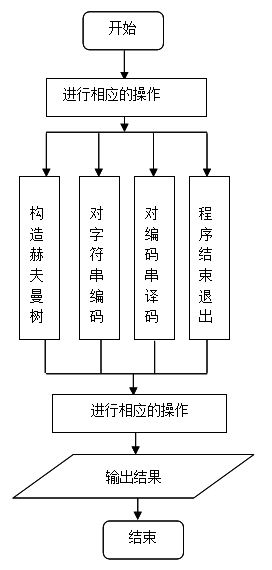
四、详细设计
4.1 赫夫曼树的建立
由赫夫曼算法的定义可知,初始森林中共有 n 棵只含根节点的二叉树。算法的第二步是:将当前森林 中的两颗根节点的二叉树,合并成一颗新的二叉树;每合并一次,森林中就减少一棵树,产生一个新 节点。显然要进行 n-1 次合并,所以共产生 n-1 个新节点,它们都是具有两个孩子分支结点。由此可 知,最新求得的赫夫曼树中一共有2n-1 个结点,其中n 个结点是初始森林的n 个孤立结点。并且赫夫 曼树中没有度数为1 的分支结点。我们可用一个大小为2n-1 的一维数组来存储赫夫曼树中的结点。因 此,赫夫曼树的存储结构描述为:
#define n 100
#define m 2*n-1
typedef struct{
int weight;
int lchild,rchild,parent;
}HTNode; T
typedef HTNode HuffmanTree[m+1];

4.1.1 选择选择parent 为0 且权值最小的两个根结点的算法
void select(HuffmanTree T,int k,int *s1,int *s2)
{//在HT[1……k]中选择parent为0且权值最小的两个根结点,其序号分别为S1和S2
int i,j;
int min1=100;
for(i=1;i<=k;i++)//查找s1
if(T[i].weight<min1 && T[i].parent==0)
{
j=i;min1=T[i].weight;
}
*s1=j;
min1=32767;
for(i=1;i<=k;i++)//查找s2,不和s1相同
if(T[i].weight<min1 && T[i].parent==0 && i!=(*s1))
{
j=i;
min1=T[i].weight;
}
*s2=j;
}
4.1.2 统计字符串中字符的种类以及各类字符的个数
假设电子文件字符串全是大写字母,那么该算法的实现思想是:先定义一个含有26个元素的临时整型数组,用来存储各种字母出现的次数。应为大写字母的ASCII码与整数1~26个元素之间相差64,因此在算法中使用字母减去64作为统计数组的下标对号入座,无须循环判断来实现,从而提高了效率;另外,要求出电文字符串中有多少种字符,并保存这些字符以供编码时使用。统计和保存都比较容易,用一个循环来判断先前统计好的各类字符个数的数组元素是否为零,若不为零,则将其值存入一个数组对应的元素中,同时将其对应的字符也存入另一个数组元素中。具体实现如下:
int jsq(char *s,int cnt[],char str[])
{
//统计各字符串中各种字母的个数以及字符的种类
char *p;
int i,j,k;
int temp[27];
for(i=1;i<=26;i++)
temp[i]=0;
for(p=s;*p!='\0';p++)
{//统计各种字符个数
if(*p>='A' && *p<='Z') {
k=*p-64;
temp[k]++;
}
}
j=0;
for(i=1,j=0;i<=26;i++)//统计有多少种字符
if(temp[i]!=0) {
j++;
str[j]=i+64;//将对应的数组送到数组中
cnt[j]=temp[i];//存入对应数组的权值
}
return j;
}
4.1.3构造赫夫曼树
void ChuffmanTree(HuffmanTree HT,HuffmanCode HC,int cnt[],char str[])
{//构造赫夫曼树HT
int i,s1,s2;
for(i=1;i<=2*num-1;i++)//初始化HT,左右孩子,双亲,权值都为0
{ HT[i].lchild=0; HT[i].rchild=0;
HT[i].parent=0; HT[i].weight=0;
}
for(i=1;i<=num;i++)//输入num个叶节点的权值
HT[i].weight=cnt[i];
for(i=num+1;i<=2*num-1;i++)//从numd后面开始新建结点存放新生成的父节点
{
select(HT,i-1,&s1,&s2);//在HT[1……i-1]中选择parent为0且权值最小的两个根结点,其序号分别为s1和s2
HT[s1].parent=i;HT[s2].parent=i;//将s1和s2的parent赋值
HT[i].lchild=s1; HT[i].rchild=s2;//新结点的左右孩子
HT[i].weight=HT[s1].weight+ HT[s2].weight;//新结点的权值
}
for(i=0;i<=num;i++)//输入字符集中的字符
HC[i].ch=str[i];
i=1;
while(i<=num)
printf("字符 %c,次数为: %d\n",HC[i].ch,cnt[i++]);
}
4.2赫夫曼编码
要求电文的赫夫曼编码,必须先定义赫夫曼编码类型,根据设计要求和实际需要定义的类型如下:
typedef struct{
char ch;
char bits[n+1];
int start ;
}CodeNode;
typedef CodeNode HuffmanCode[n];
4.2.1赫夫曼编码算法
void HuffmanEncoding(HuffmanTree HT,HuffmanCode HC)
{//根据赫夫曼树HT 求赫夫曼编码表HC
int c,p,i;
char cd[n];
int start; cd[num]='\0';
for(i=1;i<=num;i++)
{
start=num;
c=i;
while((p=HT[c].parent)>0)//直至上诉到ht[c]是树根为止
{//若HT[c]是HT[p]的孩子,则生成0;否则生成代码1
cd[--start]=(HT[p].lchild= =c)? '0':'1' :
c=p;
}//end of while
strcpy(HC[i].bits,&cd[start]);
HC[i].len=num-start;
}
}
4.2.2建立正文的编码文件
建立编码文件的基本思想是:将要编码的字符串中的字符逐一与预先生成赫夫曼树时保保存的 字符编码对照表进行比较,找到之后,对该字符的编码写入代码文件,直至所有字符处理完毕为止。
具体算法如下:
viod coding(huffmanCode HC,char *str)
{
int i,j;
FILE *fp;
fp =fopen(“codefile.tex”,”w”);
while(*str){//对电文中字符逐一生成编码并写入文件
for(i=1;i<=num;i++)
if(HC[i].ch= =*str){
for(j=0;j<=HC[i].len;j++) f
putc (HC[i].bits[j],fp);
break;
} str++;
}
fclose(fp);
}
4.3代码文件的译码
译码的基本思想是:读文件中编码,并与生成的赫夫曼编码表比较,遇到相等时,即取出其对应的 字符存入一个新串中。
Char * decode (HuffmanCode HC)
{//代码文件codefile.tex 译码
FILE *fp; char str[254];
char *p;
static char cd[n+1]
int i,j,k=0,cjs;
fp=fopen(“codefile.tex”,”r”);
while(!feof(fp))
{cjs=0;
for(i=0;i<=num&&cjs==0&&!feof(fp);i++)
{
cd[i]=‘ ’;
cd[i+1]='\0';
cd[i]=fgetc(fp);
for(j=1;j<=num;j++)
if(strcmp(HC[i].bits,cd)= =0)
{
str[k]=HC[j].ch;k++;
cjs=1;break;
}
}
str[k]='\0';
;p=str;
return p;
}
五、运行与测试
运行结果为
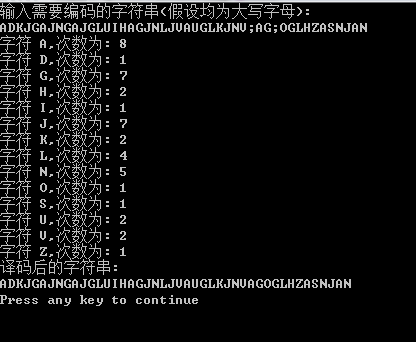
六、总结与心得
本次编写过程中出现了较多的问题,比如开始对赫夫曼树的理解不是很清楚,导致在编写过程中某些代码错误而没能及时修改,在最后进行修改时遇到了较多的麻烦。但是经过这次对赫夫曼树的学习后,我了解到赫夫曼编码(Huffman Coding)是一种编码方式,以赫夫曼树—即最优二叉树,带权路径长度最小的二叉树,经常应用于数据的无损耗压缩。总之受益匪浅。
参考文献
【1】《数据结构》严蔚敏.清华大学出版社.
【2】《数据结构课程设计》苏仕华.极械工业出版社.
【3】《程序设计》谭浩强 .清华大学出版社.
附录
#include <stdio.h>
#include <string.h>
#define n 100// 叶子结点数
#define m 2*n-1//赫夫曼树种的结点总数
typedef struct {
char ch;
char bits[9];//存放编码位串
int len;//编码长度
}CodeNode;
typedef CodeNode HuffmanCode[n+1];
typedef struct {
int weight;//权值
int lchild,rchild,parent;//左右孩子及双亲指针
}HTNode;//树中的结点类型
typedef HTNode HuffmanTree[m+1];//0号单元不可用
int num;//字母类型的个数
void select(HuffmanTree T,int k,int *s1,int *s2)
{//在HT[1……k]中选择parent为0且权值最小的两个根结点,其序号分别为S1和S2
int i,j;
int min1=100;
for(i=1;i<=k;i++)//查找s1
if(T[i].weight<min1 && T[i].parent==0)
{
j=i;min1=T[i].weight;
}
*s1=j;
min1=32767;
for(i=1;i<=k;i++)//查找s2,不和s1相同
if(T[i].weight<min1 && T[i].parent==0 && i!=(*s1))
{
j=i;
min1=T[i].weight;
}
*s2=j;
}
int jsq(char *s,int cnt[],char str[])
{
//统计各字符串中各种字母的个数以及字符的种类
char *p;
int i,j,k;
int temp[27];
for(i=1;i<=26;i++)
temp[i]=0;
for(p=s;*p!='\0';p++)
{//统计各种字符个数
if(*p>='A' && *p<='Z') {
k=*p-64;
temp[k]++;
}
}
j=0;
for(i=1,j=0;i<=26;i++)//统计有多少种字符
if(temp[i]!=0) {
j++;
str[j]=i+64;//将对应的数组送到数组中
cnt[j]=temp[i];//存入对应数组的权值
}
return j;
}
void ChuffmanTree(HuffmanTree HT,HuffmanCode HC,int cnt[],char str[])
{//构造赫夫曼树HT
int i,s1,s2;
for(i=1;i<=2*num-1;i++)//初始化HT,左右孩子,双亲,权值都为0
{ HT[i].lchild=0; HT[i].rchild=0;
HT[i].parent=0; HT[i].weight=0;
}
for(i=1;i<=num;i++)//输入num个叶节点的权值
HT[i].weight=cnt[i];
for(i=num+1;i<=2*num-1;i++)//从numd后面开始新建结点存放新生成的父节点
{
select(HT,i-1,&s1,&s2);//在HT[1……i-1]中选择parent为0且权值最小的两个根结点,其序号分别为s1和s2
HT[s1].parent=i;HT[s2].parent=i;//将s1和s2的parent赋值
HT[i].lchild=s1; HT[i].rchild=s2;//新结点的左右孩子
HT[i].weight=HT[s1].weight+ HT[s2].weight;//新结点的权值
}
for(i=0;i<=num;i++)//输入字符集中的字符
HC[i].ch=str[i];
i=1;
while(i<=num)
printf("字符 %c,次数为: %d\n",HC[i].ch,cnt[i++]);
}
void HuffmanEncoding(HuffmanTree HT, HuffmanCode HC)
{//根据赫夫曼树HT求赫夫曼编码表HC
int c,p,i,j;//c和p分别指示T中孩子和双亲的位置
char cd[n];//临时存放编码串
int start;//指示编码在cd中的起始位置
cd[num]='\0';//最后一位放上串结束符
for(i=1;i<=num;i++)
{
start=num;//初始位置
c=i;//从叶子节点T[i]开始上溯
while((p=HT[c].parent)>0)//直至上溯到HT[c]是树根为止
{//若T[c]是T[p]的做孩子,则生成0;否则生成代码1
cd[--start]=(HT[p].lchild==c) ? '0' : '1';//cd数组用来存放每一个字母对应的01编码,
c=p;
}//while 结束
strcpy(HC[i].bits,&cd[start]);//将cd数组中德01代码复制到i结点中
HC[i].len=num-start;
}//for 结束
}
void coding(HuffmanCode HC,char *str)
{
int i,j;
FILE *fp;
fp=fopen("codefile.txt","w");
while(*str) {
for(i=1;i<=num;i++)
if(HC[i].ch==*str){
for(j=0;j<HC[i].len;j++){
fputc(HC[i].bits[j],fp);
}
break;
}
str++;
}
fclose(fp);
}
char * decode(HuffmanCode HC)
{//代码文件coodfile.txt的译码*菡枫*
FILE *fp;
char str[254];//假设原文本文件不超过254个字符
char *p;
static char cd[n+1];
int i,j,k=0,cjs;
fp=fopen("codefile.txt","r");//读文件
while(!feof(fp))
{ cjs=0;
for(i=0;i<num && cjs==0 && !feof(fp);i++)
{
cd[i]=' ';
cd[i+1]='\0';
cd[i]=fgetc(fp);
for(j=1;j<=num;j++)
if(strcmp(HC[j].bits,cd)==0)//查找所有的字母的对应的编码,如果有相同的则将该字母放入str中
{
str[k]=HC[j].ch;
k++;
cjs=1;
break;
}
}
}
str[k]='\0';
p=str;
return p;
}
void main(){
char st[254],*s,str[27];
int cn[27];
HuffmanTree HT;
HuffmanCode HC;
printf("输入需要编码的字符串(假设均为大写字母): \n");
gets(st);
num=jsq(st,cn,str);//统计字符的种类及各类字符出现的频率
ChuffmanTree(HT,HC,cn,str);//建立赫夫曼树
HuffmanEncoding(HT,HC);//生成赫夫曼编码
coding(HC,st);//建立电文赫夫曼编码文件
s=decode(HC);//读编码文件译码
printf("译码后的字符串: \n");
printf("%s\n",s);
}
-
数据结构课程设计实验报告.doc
数据结构课程实验报告专业指导老师班级姓名学号完成日期一实验目的1掌握线性表的顺序存储结构和链式存储结构2熟练掌握顺序表和链表基本算…
-
数据结构课程设计实验报告
数据结构与算法课程设计报告姓名林小琼学号0907022118班级09网络工程设计时间20xx11020xx114审阅教师目录一课程…
-
数据结构课程设计实验报告格式
课程课程设计系电子信息与计算机科学系专业计算机科学与技术班级文计1111姓名毕萌玉张菁张帅学号20xx905141221011任课…
-
数据结构课程设计实验报告
软件111班18号赵庆珍数据结构课程设计任务书学期12131班级软件111一设计目的数据结构是一门实践性较强的软件基础课程为了学好…
-
数据结构课程设计实验报告-
仲恺农业工程学院课程设计报告课程名称院系专业班级学号姓名指导老师计算机科学与技术计算机102班20xx10214203成筠目录题目…
-
数据结构课程设计总结(模板)
《数据结构》课程设计报告题目:班级:计算机系1001班姓名:学号:4236指导教师:日期:20##年7月3日一、课程设计目标二、概…
-
数据结构课程设计报告
数据结构课程设计报告学生姓名学号班级地信10901长江大学20XX.6目录1.需求分析......................…
-
数据结构课程设计实验报告
软件111班18号赵庆珍数据结构课程设计任务书学期12131班级软件111一设计目的数据结构是一门实践性较强的软件基础课程为了学好…
-
数据结构课程设计报告范例1
课程设计报告课程名称数据结构课题名称迷宫问题姓名吴明华学号20xx16020xx9院系计算机学院通信与信息工程系专业班级通信112…
-
数据结构课程设计实验报告
数据结构与算法课程设计报告姓名林小琼学号0907022118班级09网络工程设计时间20xx11020xx114审阅教师目录一课程…
-
哈夫曼编码译码器实验报告
中北大学数据结构课程设计说明书20xx年12月20日目录1问题描述错误未定义书签2需求分析错误未定义书签3概要设计131抽象数据类…