中国矿业大学密码学课程设计报告
中国矿业大学
密码学课程设计报告
院系: 计算机学院
专业: 信息安全
班级:
姓名:
学号:
指导老师:
20##年6月
摘要
近些年来,由于许多私密信息的泄漏,信息安全成为全社会的需求,所以也成为了整个社会的关注热点。对于信息安全来说,密码学是信息安全的核心,应用密码学技术是实现安全系统的核心技术。随着信息系统及网络系统的爆炸性增长,形形色色的安全威胁严重阻碍了当前的信息化进程。由于对信息的机密性、完整性、不可否认性的需要,密码学变得炙手可热。
经过学习《应用密码学》这门课程,我们对密码学有了初步的认识和了解,对于一些理论和算法都有了初步掌握。此次密码学课程设计,主要设计的是维吉尼亚密码算法、实现HASH算法SHA1、AES算法的实现以及实现椭圆曲线密码算法。这些经典的密码算法是我们学习密码学课程设计所必须掌握的,也是学习信息安全的基础。通过这次的密码学课程设计,对密码技术有了更深入的了解和掌握。
关键词:信息安全;密码学;密码技术。
目录
1 古典密码 Vignere........................................................................................................ 1
1.1 古典密码 Vignere概述...................................................................................... 1
1.2 算法原理与设计思路.......................................................................................... 1
1.3 密码安全性分析................................................................................................. 1
1.4 实验代码............................................................................................................ 2
1.5 实验结果展示..................................................................................................... 5
2 HASH算法SHA1的实现................................................................................................... 5
2.1 算法原理与设计思想.......................................................................................... 5
2.1.1 安全哈希算法概述................................................................................... 5
2.1.2 SHA1的分组过程...................................................................................... 5
2.1.3 SHA1的4轮运算...................................................................................... 6
2.2 实验设计............................................................................................................ 7
2.3 实验代码..................................................................................................... 8
2.4 实验结果展示................................................................................................... 13
3.1 算法原理.......................................................................................................... 14
3.1.1 字节替换SubByte................................................................................... 14
3.1.2 行移位ShiftRow.................................................................................... 14
3.1.3 列混合MixColumn................................................................................... 15
3.1.4 轮密钥加AddRoundKey............................................................................ 15
3.1.5 逆字节替换InvByteSub.......................................................................... 15
3.1.6 逆行移位InvShiftRow............................................................................ 16
3.1.7 逆列混淆InvMixColumn.......................................................................... 16
3.1.8 加密流程图............................................................................................ 17
3.1.9 解密流程图............................................................................................ 18
3.2 系统程序设计................................................................................................... 18
3.2.1 字节替换................................................................................................ 18
3.2.2 行位移................................................................................................... 19
3.2.3 列混合................................................................................................... 20
3.2.4 密钥加................................................................................................... 21
3.2.5 密钥扩展................................................................................................ 22
3.2.6 获取RoundKey........................................................................................ 23
3.2.7 逆字节替换............................................................................................ 23
3.2.8 逆行位移................................................................................................ 24
3.2.9 逆列混合................................................................................................ 25
3.2.10 加密..................................................................................................... 27
3.2.11 解密..................................................................................................... 29
3.3 实验结果展示................................................................................................... 31
4 实现椭圆曲线密码算法................................................................................................ 31
4.1 算法原理与设计思想......................................................................................... 31
4.1.1 椭圆曲线概述......................................................................................... 31
4.1.2 加密通信的过程..................................................................................... 32
4.1.3 过程分析................................................................................................ 32
4.2 实验代码.......................................................................................................... 32
4.3 实验结果展示................................................................................................... 37
5 实验心得体会.............................................................................................................. 37
1 古典密码 Vignere
1.1 古典密码 Vignere概述
1858年法国密码学家维吉尼亚提出一种以移位替换为基础的周期替换密码。这种密码是多表替换密码的一种。是一系列(两个以上)替换表依次对明文消息的字母进行替换的加密方法。
1.2 算法原理与设计思路
1.首先使用维吉尼亚方阵,它的基本方阵是26列26行。方阵的第一行是a到z按正常顺序排列的字母表,第二行是第一行左移循环一位得到得,其他各行依次类推。
2.加密时,按照密钥字的指示,决定采用哪一个单表。例如密钥字是bupt,加密时,明文的第一个字母用与附加列上字母b相对应的密码表进行加密,明文的第二个字母用与附加列的字母u相对应的密码表进行加密,依次类推。
3.令英文字母a,b,…,z对应于从0到25的整数。设明文是n个字母组成的字符串,即 m=m1m2m3m4…mn
密钥字周期性地延伸就给出了明文加密所需的工作密钥
K=k1k2…kn,E(m)=C=c1c2…cn
加密:Ci=mi+kimod26
解密:mi=ci-kimod26,i=1,2,3,…,n
加密算法的关键是给出初始密钥,例如第一个密钥字母是e,对第一个明文字母p进行加密时,选用左边附加列上的字母e对应的那一行作为代替密码表,查处与p相对应的密文字母是T,依次类推即可得出明文。上述代码中的生成密钥部分为核心代码,只有密钥更长,才能保证密码算法的可靠性。解密算法和加密算法只需要减去密钥继续模26即可得到。
1.3 密码安全性分析
首先,破译的第一步就是寻找密文中出现超过一次的字母。有两种情况可能导致这样的重复发生。最有可能的是明文中同样的字母序列使用密钥中同样的字母加了密;另外还有一种较小的可能性是明文中两个不同的字母序列通过密钥中不同部分加了密,碰巧都变成了密文中完全一样的序列。假如我们限制在长序列的范围内,那么第二种可能性可以很大程序地被排除,这种情况下,我们多数考虑到4个字母或4个以上的重复序列。
其次,破译的第二步是确定密钥的长度,又看看这一段先: 密钥 F O R E S T F O R E S T F O R E S T F O R E S T F O R 明 文 b e t t e r t o d o w e l l t h a n t o s a y w e l l 密 文 G S K X W K Y C U S O X Q Z K L S G Y C J E Q P J Z C 第一个YC出现后到第二个YC的结尾一共有12个字母(U S O X Q Z K L S G Y C) 那么密钥的长度应是12的约数---1,2,3,4,6,12之中的一个(其中,1可排除)。
第三, 破译的时候,可以从一下几个方面进行考虑。1.A-E段,U-Z段以及O-T段的特征比较显著,可先从这些方面着手; 2.如果一些字符串出现的频率较多,不妨猜猜,特别要注意THE,-ING等的出现;3.要留意那些图表中没有出现的字母,很多时候也会是突破点,如X与Z的空缺;4.图表最好还是做一下,毕竟比较直观,好看 。
因此,利用单纯的数学统计方法就可以攻破维吉尼亚密码,所以在使用这种密码的过程中,我们尽量增加密钥的长度,只有密钥长度的足够长时,密码的使用才会越安全。
1.4 实验代码
#include <iostream>
#include <string>
using namespace std;
const int N=26;
char v[N][N]={{'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'}};
int number(char x)//把行号字母对应到数字
{
char y='a';
for(int i=0;i<N;i++)
{
if(x==(y+i)) return i;
}
}
void encryption(string m,string k)//加密
{
cout<<"明文:";
cin>>m;
cout<<"密钥:";
cin>>k;
int mlen,klen;
mlen=m.length();
klen=k.length();
char *p,*q,*t;//明文,初始密钥,密钥串。把string换成char
p=new char[m.length()+1];
strcpy(p,m.c_str());
q=new char[k.length()+1];
strcpy(q,k.c_str());
t=new char[m.length()+1];
int j=0;
for(int i=0;i<mlen;i++)
{
t[i]=q[j];
j++;
j=j%klen;
}//生成密钥
cout<<"密文:";
for(i=0;i<mlen;i++)
cout<<v[number(t[i])][number(p[i])];
cout<<endl;
}
void disencryption(string c,string k)//解密
{
cout<<"密文:";
cin>>c;
cout<<"密钥:";
cin>>k;
int clen,klen;
clen=c.length();
klen=k.length();
char *p,*q,*t;//密文,初始密钥,密钥串。把string换成char
p=new char[c.length()+1];
strcpy(p,c.c_str());
q=new char[k.length()+1];
strcpy(q,k.c_str());
t=new char[c.length()+1];
int j=0;
for(int i=0;i<clen;i++)
{
t[i]=q[j];
j++;
j=j%klen;
}//生成密钥
cout<<"明文:";
for(i=0;i<clen;i++)
for(int j=0;j<N;j++)
if(v[number(t[i])][j]==p[i]) {cout<<char(j+97);break;}
cout<<endl;
}
int main()
{
for(int i=1;i<N;i++)
{
for(int j=0;j<N;j++)
{
v[i][j]=v[i-1][(j+1)%N];
}//方阵初始化
}
cout<<"欢迎使用维吉尼亚加密!"<<endl<<endl;
cout<<"请选择要进行的操作"<<endl;
int flag;
do{
cout<<"1.加密2.解密3.结束:"<<endl;
cin>>flag;
string m,k;
if(flag==1)encryption(m,k);
else if(flag==2) disencryption(m,k);
else if(flag!=1&&flag!=2&&flag!=3) cout<<"输入错误,请重新输入!";
}while(flag!=3);
return 0;
}
1.5 实验结果展示

2 HASH算法SHA1的实现
2.1 算法原理与设计思想
2.1.1 安全哈希算法概述
安全哈希算法(Secure Hash Algorithm)主要适用于数字签名标准(Digital Signature Standard DSS)里面定义的数字签名算法(Digital Signature Algorithm DSA)。对于长度小于2^64位的消息,SHA1会产生一个160位的消息摘要。当接收到消息的时候,这个消息摘要可以用来验证数据的完整性。在传输的过程中,数据很可能会发生变化,那么这时候就会产生不同的消息摘要。 SHA1有如下特性:不可以从消息摘要中复原信息;两个不同的消息不会产生同样的消息摘要。
2.1.2 SHA1的分组过程
对于任意长度的明文,SHA1的明文分组过程与MD5相类似,首先需要对明文添加位数,使明文总长度为448(mod512)位。在明文后添加位的方法是第一个添加位是l,其余都是0。然后将真正明文的长度(没有添加位以前的明文长度)以64位表示,附加于前面已添加过位的明文后,此时的明文长度正好是512位的倍数。与MD5不同的是SHA1的原始报文长度不能超过2的64次方,另外SHA1的明文长度从低位开始填充。
经过添加位数处理的明文,其长度正好为512位的整数倍,然后按512位的长度进行分组(block),可以划分成L份明文分组,我们用Y0,Y1,……YL-1表示这些明文分组。对于每一个明文分组,都要重复反复的处理,这些与MD5是相同的。
对于512位的明文分组,SHA1将其再分成16份子明文分组(sub-block),每份子明文分组为32位,我们使用M[k](k= 0, 1,……15)来表示这16份子明文分组。之后还要将这16份子明文分组扩充到80份子明文分组,我们记为W[k](k= 0, 1,……79),扩充的方法如下。
W t = M t , 当0≤t≤15
W t = ( W t-3 ? W t-8? W t-14? W t-16 ) <<< 1, 当16≤t≤79
SHA1有4轮运算,每一轮包括20个步骤(一共80步),最后产生160位摘要,这160位摘要存放在5个32位的链接变量中,分别标记为A、B、C、D、E。这5个链接变量的初始值以16进制位表示如下。
A=0x67452301
B=0xEFCDAB89
C=0x98BADCFE
D=0x10325476
E=0xC3D2E1F0
2.1.3 SHA1的4轮运算
SHA1有4轮运算,每一轮包括20个步骤,一共80步,当第1轮运算中的第1步骤开始处理时,A、B、C、D、E五个链接变量中的值先赋值到另外5个记录单元A′,B′,C′,D′,E′中。这5个值将保留,用于在第4轮的最后一个步骤完成之后与链接变量A,B,C,D,E进行求和操作。
SHA1的4轮运算,共80个步骤使用同一个操作程序,如下:
A,B,C,D,E←[(A<<<5)+ (B,C,D)+E+Wt+Kt],A,(B<<<30),C,D
其中 (B,C,D)为逻辑函数,Wt为子明文分组W[t],Kt为固定常数。这个操作程序的意义为:
1) 将[(A<<<5)+ (B,C,D)+E+Wt+Kt]的结果赋值给链接变量A;
2) 将链接变量A初始值赋值给链接变量B;
3) 将链接变量B初始值循环左移30位赋值给链接变量C;
4) 将链接变量C初始值赋值给链接变量D;
5) 将链接变量D初始值赋值给链接变量E。
2.2 实验设计
首先,找出三个数,p,q,r,其中 p,q 是两个相异的质数,r 是与 (p-1)(q-1) 互质的数。 p,q,r 这三个数便是 private key。接著,找出m,使得 rm == 1 mod (p-1)(q-1)。 这个 m 一定存在,因为 r 与 (p-1)(q-1) 互质,用辗转相除法就可以得到了,再来,计算 n = pq。. m,n 这两个数便是 public key。
编码过程是:若资料为 a,将其看成是一个大整数,假设 a < n。 如果 a >= n 的话,就将 a 表成 s 进位 (s <= n,通常取 s = 2^t),则每一位数均小于 n,然后分段编码。接下来,计算 b == a^m mod n,(0 <= b < n),b 就是编码后的资料。解码的过程是,计算 c == b^r mod pq (0 <= c < pq),于是乎,解码完毕。 等会会证明 c 和 a 其实是相等的 : 如果第三者进行窃听时,他会得到几个数: m,n(=pq),b 如果要解码的话,必须想办法得到 r。 所以,他必须先对 n 作质因数分解。 要防止他分解,最有效的方法是找两个非常的大质数 p,q,使第三者作因数分解时发生困难。
<定理> 若 p,q 是相异质数,rm == 1 mod (p-1)(q-1),a 是任意一个正整数,b == a^m mod pq,c == b^r mod pq,则 c == a mod pq 证明的过程,会用到费马小定理,叙述如下: m 是任一质数,n 是任一整数,则 n^m == n mod m (换另一句话说,如果 n 和 m 互质,则 n^(m-1) == 1 mod m) 运用一些基本的群论的知识,就可以很容易地证出费马小定理的。.. <证明> 因为 rm == 1 mod (p-1)(q-1),所以 rm = k(p-1)(q-1) + 1,其中 k 是整数 因为在 modulo 中是 preserve 乘法的 (x == y mod z and u == v mod z => xu == yv mod z),所以,c == b^r == (a^m)^r == a^(rm) == a^(k(p-1)(q-1)+1) mod pq 1. 如果 a 不是 p 的倍数,也不是 q 的倍数时,则 a^(p-1) == 1 mod p (费马小定理) => a^(k(p-1)(q-1)) == 1 mod p a^(q-1) == 1 mod q (费马小定理) => a^(k(p-1)(q-1)) == 1 mod q 所以 p,q 均能整除 a^(k(p-1)(q-1)) - 1 => pq | a^(k(p-1)(q-1)) - 1 即 a^(k(p-1)(q-1)) == 1 mod pq => c == a^(k(p-1)(q-1)+1) == a mod pq 2. 如果 a 是 p 的倍数,但不是 q 的倍数时,则 a^(q-1) == 1 mod q (费马小定理) => a^(k(p-1)(q-1)) == 1 mod q => c == a^(k(p-1)(q-1)+1) == a mod q => q | c - a 因 p | a => c == a^(k(p-1)(q-1)+1) == 0 mod p => p | c - a 所以,pq | c - a => c == a mod pq 3. 如果 a 是 q 的倍数,但不是 p 的倍数时,证明同上 4. 如果 a 同时是 p 和 q 的倍数时,则 pq | a => c == a^(k(p-1)(q-1)+1) == 0 mod pq => pq | c - a => c == a mod pq Q.E.D. 这个定理说明 a 经过编码为 b 再经过解码为 c 时,a == c mod n (n = pq).... 但我们在做编码解码时,限制 0 <= a < n,0 <= c < n,所以这就是说 a 等于c,所以这个过程确实能做到编码解码的功能。
2.3 实验代码
typedef struct {
unsigned long state[5];
unsigned long count[2];
unsigned char buffer[64];
}SHA1_CTX;
void SHA1Transform(unsigned long state[5], unsigned char buffer[64]);
void SHA1Init(SHA1_CTX* context);
void SHA1Update(SHA1_CTX* context, unsigned char* data, unsigned int len);
void SHA1Final(unsigned char digest[20], SHA1_CTX* context);
#include "sha1.h"
#include <memory.h>
#define rol(value, bits) (((value) << (bits)) | ((value) >> (32 - (bits))))
/* blk0() and blk() perform the initial expand. */
/* I got the idea of expanding during the round function from SSLeay */
#ifdef LITTLE_ENDIAN
#define blk0(i) (block->l[i] = (rol(block->l[i],24)&0xFF00FF00) \
|(rol(block->l[i],8)&0x00FF00FF))
#else
#define blk0(i) block->l[i]
#endif
#define blk(i) (block->l[i&15] = rol(block->l[(i+13)&15]^block->l[(i+8)&15] \
^block->l[(i+2)&15]^block->l[i&15],1))
/* (R0+R1), R2, R3, R4 are the different operations used in SHA1 */
#define R0(v,w,x,y,z,i) z+=((w&(x^y))^y)+blk0(i)+0x5A827999+rol(v,5);w=rol(w,30);
#define R1(v,w,x,y,z,i) z+=((w&(x^y))^y)+blk(i)+0x5A827999+rol(v,5);w=rol(w,30);
#define R2(v,w,x,y,z,i) z+=(w^x^y)+blk(i)+0x6ED9EBA1+rol(v,5);w=rol(w,30);
#define R3(v,w,x,y,z,i) z+=(((w|x)&y)|(w&x))+blk(i)+0x8F1BBCDC+rol(v,5);w=rol(w,30);
#define R4(v,w,x,y,z,i) z+=(w^x^y)+blk(i)+0xCA62C1D6+rol(v,5);w=rol(w,30);
/* Hash a single 512-bit block. This is the core of the algorithm. */
void SHA1Transform(unsigned long state[5], unsigned char buffer[64])
{
unsigned long a, b, c, d, e;
typedef union {
unsigned char c[64];
unsigned long l[16];
} CHAR64LONG16;
CHAR64LONG16* block;
#ifdef SHA1HANDSOFF
static unsigned char workspace[64];
block = (CHAR64LONG16*)workspace;
memcpy(block, buffer, 64);
#else
block = (CHAR64LONG16*)buffer;
#endif
/* Copy context->state[] to working vars */
a = state[0];
b = state[1];
c = state[2];
d = state[3];
e = state[4];
/* 4 rounds of 20 operations each. Loop unrolled. */
R0(a,b,c,d,e, 0); R0(e,a,b,c,d, 1); R0(d,e,a,b,c, 2); R0(c,d,e,a,b, 3);
R0(b,c,d,e,a, 4); R0(a,b,c,d,e, 5); R0(e,a,b,c,d, 6); R0(d,e,a,b,c, 7);
R0(c,d,e,a,b, 8); R0(b,c,d,e,a, 9); R0(a,b,c,d,e,10); R0(e,a,b,c,d,11);
R0(d,e,a,b,c,12); R0(c,d,e,a,b,13); R0(b,c,d,e,a,14); R0(a,b,c,d,e,15);
R1(e,a,b,c,d,16); R1(d,e,a,b,c,17); R1(c,d,e,a,b,18); R1(b,c,d,e,a,19);
R2(a,b,c,d,e,20); R2(e,a,b,c,d,21); R2(d,e,a,b,c,22); R2(c,d,e,a,b,23);
R2(b,c,d,e,a,24); R2(a,b,c,d,e,25); R2(e,a,b,c,d,26); R2(d,e,a,b,c,27);
R2(c,d,e,a,b,28); R2(b,c,d,e,a,29); R2(a,b,c,d,e,30); R2(e,a,b,c,d,31);
R2(d,e,a,b,c,32); R2(c,d,e,a,b,33); R2(b,c,d,e,a,34); R2(a,b,c,d,e,35);
R2(e,a,b,c,d,36); R2(d,e,a,b,c,37); R2(c,d,e,a,b,38); R2(b,c,d,e,a,39);
R3(a,b,c,d,e,40); R3(e,a,b,c,d,41); R3(d,e,a,b,c,42); R3(c,d,e,a,b,43);
R3(b,c,d,e,a,44); R3(a,b,c,d,e,45); R3(e,a,b,c,d,46); R3(d,e,a,b,c,47);
R3(c,d,e,a,b,48); R3(b,c,d,e,a,49); R3(a,b,c,d,e,50); R3(e,a,b,c,d,51);
R3(d,e,a,b,c,52); R3(c,d,e,a,b,53); R3(b,c,d,e,a,54); R3(a,b,c,d,e,55);
R3(e,a,b,c,d,56); R3(d,e,a,b,c,57); R3(c,d,e,a,b,58); R3(b,c,d,e,a,59);
R4(a,b,c,d,e,60); R4(e,a,b,c,d,61); R4(d,e,a,b,c,62); R4(c,d,e,a,b,63);
R4(b,c,d,e,a,64); R4(a,b,c,d,e,65); R4(e,a,b,c,d,66); R4(d,e,a,b,c,67);
R4(c,d,e,a,b,68); R4(b,c,d,e,a,69); R4(a,b,c,d,e,70); R4(e,a,b,c,d,71);
R4(d,e,a,b,c,72); R4(c,d,e,a,b,73); R4(b,c,d,e,a,74); R4(a,b,c,d,e,75);
R4(e,a,b,c,d,76); R4(d,e,a,b,c,77); R4(c,d,e,a,b,78); R4(b,c,d,e,a,79);
/* Add the working vars back into context.state[] */
state[0] += a;
state[1] += b;
state[2] += c;
state[3] += d;
state[4] += e;
/* Wipe variables */
a = b = c = d = e = 0;
}
/* SHA1Init - Initialize new context */
void SHA1Init(SHA1_CTX* context)
{
/* SHA1 initialization constants */
context->state[0] = 0x67452301;
context->state[1] = 0xEFCDAB89;
context->state[2] = 0x98BADCFE;
context->state[3] = 0x10325476;
context->state[4] = 0xC3D2E1F0;
context->count[0] = context->count[1] = 0;
}
void SHA1Update(SHA1_CTX* context, unsigned char* data, unsigned int len)
{
unsigned int i, j;
j = (context->count[0] >> 3) & 63;
if ((context->count[0] += len << 3) < (len << 3)) context->count[1]++;
context->count[1] += (len >> 29);
if ((j + len) > 63) {
memcpy(&context->buffer[j], data, (i = 64-j));
SHA1Transform(context->state, context->buffer);
for ( ; i + 63 < len; i += 64) {
SHA1Transform(context->state, &data[i]);
}
j = 0;
}
else i = 0;
memcpy(&context->buffer[j], &data[i], len - i);
}
/* Add padding and return the message digest. */
void SHA1Final(unsigned char digest[20], SHA1_CTX* context)
{
unsigned long i, j;
unsigned char finalcount[8];
for (i = 0; i < 8; i++) {
finalcount[i] = (unsigned char)((context->count[(i >= 4 ? 0 : 1)]
>> ((3-(i & 3)) * 8) ) & 255); /* Endian independent */
}
SHA1Update(context, (unsigned char *)"\200", 1);
while ((context->count[0] & 504) != 448) {
SHA1Update(context, (unsigned char *)"\0", 1);
}
SHA1Update(context, finalcount, 8); /* Should cause a SHA1Transform() */
for (i = 0; i < 20; i++) {
digest[i] = (unsigned char)
((context->state[i>>2] >> ((3-(i & 3)) * 8) ) & 255);
}
/* Wipe variables */
i = j = 0;
memset(context->buffer, 0, 64);
memset(context->state, 0, 20);
memset(context->count, 0, 8);
memset(&finalcount, 0, 8);
#ifdef SHA1HANDSOFF /* make SHA1Transform overwrite it's own static vars */
SHA1Transform(context->state, context->buffer);
#endif
}
2.4 实验结果展示

3 AES算法的实现
3.1 算法原理
1.
2.
3.
1.
2.
3.
3.1.1 字节替换SubByte
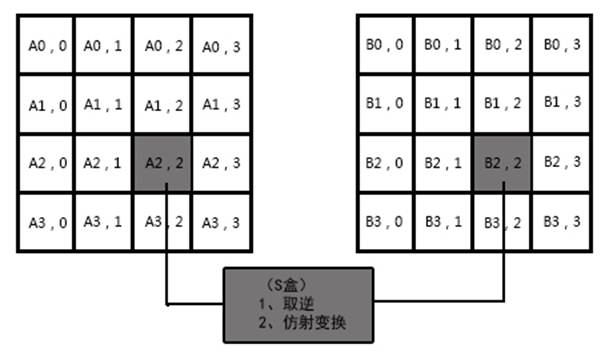
图3-1 字节替代图
3.1.2 行移位ShiftRow

图3-2 行移位图
3.1.3 列混合MixColumn
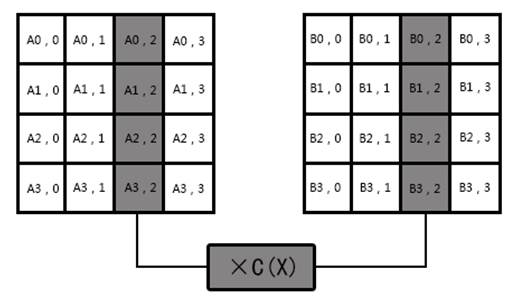
图3-3 列混合图
3.1.4 轮密钥加AddRoundKey
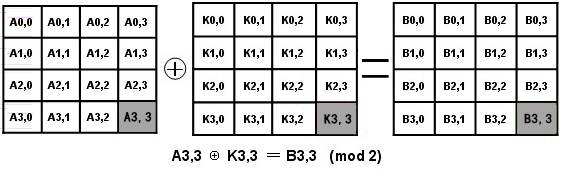
图3-4 轮密钥加图
3.1.5 逆字节替换InvByteSub
通过逆S盒的映射变换得到。
3.1.6 逆行移位InvShiftRow
图3-5 逆行移位图
3.1.7 逆列混淆InvMixColumn
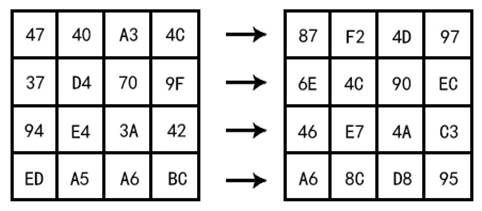
图3-6 逆列混淆图
3.1.8 加密流程图
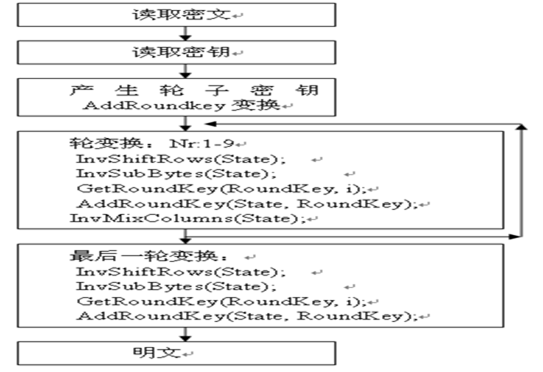
图3-7 加密流程图
3.1.9 解密流程图

图3-8 解密流程图
3.2 系统程序设计
3.2.1 字节替换
字节代换是非线性变换,独立地对状态的每个字节进行查表代换。代换表(S盒)是可逆的,由以下两个变换合成得到:
首先,将字节看作GF(28)上的元素,映射到自己的乘法逆元。
b(x)=a(x) mod m(x)
其中m(x)=x8+x4+x3+x+1,当a(x)=0时,其逆元素也为0,即’00’映射到自己。
其次,对字节作如下的(GF(2)上的,可逆的)仿射变换,如图所示。

图3-9 S盒仿射变换
将从00到FF的十六进制数经过上述运算就可以得到一个16*16的字节代换表,也就是用于加密的S盒。其代码为:
void SubBytes(int a[4][4],int s_box[256])/*s_box[256]是s盒*/
{
int i,j;
for (i = 0; i < 4; i++)
for (j = 0; j < 4; j++)
a[i][j] =s_box[a[i][j]];
}
3.2.2 行位移
行移位是根据不同的分组长度将状态矩阵中的各行进行相应循环移位。在加密过程中,状态矩阵的后三行要按字节进行左移位。在解密过程中则要进行逆行移位,即将状态矩阵中的后三行按字节进行右移位。表3给出了在分组不同的情况下移位量,即在后三行的第1行要移位c1个字节,第2行要移位c2个字节,第3行要移位c3个字节。其代码为:
void ShiftRows(int a[4][4],int decrypt)
{
int i,j,b;
if(decrypt==0)
{ /* 此时实现加密行移位功能 */
for(i=1;i<4;i++)
{
if(i==1)
{
j=a[i][0];
a[i][0]=a[i][1];
a[i][1]=a[i][2];
a[i][2]=a[i][3];
a[i][3]=j;}
if(i==2)
{
j=a[i][0];
b=a[i][1];
a[i][0]=a[i][2];
a[i][1]=a[i][3];
a[i][2]=j;
a[i][3]=b;}
if(i==3)
{
j= a[i][3];
a[i][3]=a[i][2];
a[i][2]=a[i][1];
a[i][1]=a[i][0];
a[i][0]=j;}
}
}
3.2.3 列混合
在列混合变换中,将状态矩阵中的一列看作在GF(28)上的多项式,与一个常数多项式c(x)相乘并模x4+1。其中,
c(x)=’03’x3+’01’x2+’01’x+’02’(系数用十六进制表示)
c(x)是与x4+1互素的,因此模x4+1是可逆的。列混合预算也可写为矩阵乘法。设b(x)=c(x)?a(x),则

图3-10 矩阵乘法图
这个运算需要做GF(28)上的乘法,代码实现如下:
int mul(int a, int b)
{
return (a != 0 && b != 0)? alog[(log[a & 0xFF] + log[b & 0xFF]) % 255]:0;
}
采用查对数表和反对数表的方法,可以简单方便的找到元素的逆元。其代码为:
void MixColumns(int a[4][4],int b[4][4]) /*b[4][4]为列混合时的固定矩阵*/
{
int temp[4][4]={0};
int d[3]={0x80,0x1B,0x02};
int i,j,m,k;
for(m=0;m<4;m++)
for (i = 0; i<4;i++)
for (j = 0;j<4;j++)
{
if(b[i][j]==1)
temp[i][m]=a[j][m]^temp[i][m];
else
if(b[i][j]==2)
if(a[j][m]<d[0])
temp[i][m]=(b[i][j]*a[j][m])^temp[i][m];
else
{
k=a[j][m]^d[0];
temp[i][m]=((b[i][j]*k)^d[1])^temp[i][m];}
else
{ if(a[j][m]<d[0])
temp[i][m]=((a[j][m]*d[2])^a[j][m])^temp[i][m];
else
{
k=a[j][m]^d[0];
temp[i][m]=(((k*d[2])^d[1])^a[j][m])^temp[i][m];}}}
for(i=0;i<4;i++)
for(j=0;j<4;j++)
a[i][j]=temp[i][j];
}
3.2.4 密钥加
密钥加是将轮密钥简单地与状态进行逐比特异或。轮密钥由种子密钥通过密钥编排算法得到,轮密钥长度等于分组长度Nb。其代码为:
void AddRoundKey(int a[4][4],int roundKey[4][4])
{
int i,j;
for (i = 0;i < 4; i++)
for (j = 0; j < 4; j++)
a[i][j] = a[i][j] ^ roundKey[i][j];
}
3.2.5 密钥扩展
扩展密钥用数组w(Nb*(Nr+1))表示,前Nk个字是种子密钥,其它的密钥字通过递归定义生成。SubByte(w)是一个返回4个字节的函数,每个字节都是它输入字中相应位置字节通过S盒作用后的结果;而函数RobByte(w)返回的是这4个字节经循环置换后的字,即将该字循环左移一个字节。扩展密钥的前Nk个字由种子密钥构成,随后的字w[i]等于字w[i-1]经一些变换后得到的字temp和字w[i-Nk]异或而成;而且对位置为Nk倍数的字变换中不仅运用了循环左移变换RotByte和子字节变换SubByte,还运用了轮常数Rcon对变换后的字temp进行异或。
对轮常数的定义为:Rocn[i]=(Rc[i],’00’,’00’,’00’);
而Rc[i]便是在有限域GF(28)中的xi-1的值,即:
Rc[1]=1(即’01’)
Rc[i]=x?(Rc[i-1])= xi-1 (即’02’?(Rc[i-1]))。
其代码为:
void KeyExpansion(int roundkey[4][4],int s_box[256], int temp[4][44])
{
int i,j,n,m,a,b,x,y;
int w[4],r[4],q[4];
for(i=0;i<4;i++)
for(j=0;j<4;j++)
{
temp[i][j]= roundkey[i][j];}
for(i=4;i<44;i++)
{
a=i-4;b=i-1;
if(i%4!=0)/*i不是4的倍数*/
{
for(j=0;j<4;j++)
q[j]=temp[j][a]^temp[j][b];
for(y=0;y<4;y++)
temp[y][i]=q[y];}
else
{
for(x=0;x<4;x++)
w[x]=temp[x][b];
n=w[0]; /*左移一位*/
w[0]= w[1];
w[1]= w[2];
w[2]= w[3];
w[3]=n;
for(j=0;j<4;j++)
w[j]=s_box[w[j]];/*字节替代*/
w[0]= rcon[(i-4)/4]^w[0];
for(m=0;m<4;m++)
r[m]=temp[m][a]^w[m];
for(y=0;y<4;y++)
temp[y][i]=r[y];
}
}
}
3.2.6 获取RoundKey
轮密钥i(即第i个轮密钥)由轮密钥缓冲字W[Nb*i]到W[Nb*(i+1)-1]给出,如图所示。

图3-11 轮密钥图
Nb=6且Nk=4时的密钥扩展与轮密钥选取。
其代码为:
void GetRoundKey(int roundKey[4][4], int temp[4][44],int n)
{
int i,j;
for(i=0;i<4;i++)
for(j=0;j<4;j++)
roundKey[i][j]=temp[i][j+4*n];
}
3.2.7 逆字节替换
与字节代替类似,逆字节代替基于逆S盒实现。其代码为:
void InvSubBytes(int a[4][4],int InverS_box[256])/* InverS_box[256]是逆S盒*/
{
int i,j;
for (i = 0; i < 4; i++)
for (j = 0; j < 4; j++)
a[i][j] = InverS_box [a[i][j]];
}
3.2.8 逆行位移
与行移位相反,逆行移位将态state的后三行按相反的方向进行移位操作,即第0行保持不变,第1行循环向右移一个字节,第2行循环向右移动两个字节,第3行循环向右移动三个字节。其代码为:
if(decrypt==1)
{ /* 此时实现解密行移位功能 */
for(i=1;i<4;i++)
{
if(i==1)
{
j=a[i][3];
a[i][3]=a[i][2];
a[i][2]=a[i][1];
a[i][1]=a[i][0];
a[i][0]=j;}
if(i==2)
{
j=a[i][0];
b=a[i][1];
a[i][0]=a[i][2];
a[i][1]=a[i][3];
a[i][2]=j;
a[i][3]=b;}
if(i==3)
{
j=a[i][0];
a[i][0]=a[i][1];
a[i][1]=a[i][2];
a[i][2]=a[i][3];
a[i][3]=j;}
}
}
}
3.2.9 逆列混合
逆列混淆的处理办法与MixColumns()类似,每一列都通过与一个固定的多项式d(x)相乘进行交换。其代码为:
void InvMixColumns(int a[4][4],int c[4][4]) /*c[4][4]为逆列混合时的固定矩阵*/
{
int temp[4][4]={0};
int d[7]={0x80,0x1B,0x02,0x0e,0x0b,0x0d,0x09};
int i,j,m,n,e,k,p,q,x,y;
for(m=0;m<4;m++)
for (i = 0; i<4;i++)
for (j = 0;j<4;j++)
{
e=a[j][m];y=a[j][m];
if(c[i][j]==d[3])
{
for(n=0;n<3;n++)
{
if(y<d[0])
y=y*d[2];
else
{
k=y^d[0];
y=(k*d[2])^d[1];}
if(n==0)
{
p=y;}
else
if(n==1)
{ q=y;}
else
{ x=y;}}
temp[i][m]=p^q^x^temp[i][m];}
if(c[i][j]==d[4])
{
for(n=0;n<3;n++)
{
if(y<d[0])
y=y*d[2];
else
{
k=y^d[0];
y=(k*d[2])^d[1];}
if(n==0)
q=y;
if(n==2)
x=y;}
temp[i][m]=e^q^x^temp[i][m];}
if(c[i][j]==d[5])
{
for(n=0;n<3;n++)
{
if(y<d[0])
y=y*d[2];
else
{
k=y^d[0];
y=(k*d[2])^d[1];}
if(n==1) {q=y;}
if(n==2) {x=y;}}
temp[i][m]=e^q^x^temp[i][m];}
if(c[i][j]==d[6])
{
for(n=0;n<3;n++)
{
if(y<d[0])
y=y*d[2];
else
{
k=y^d[0];
y=(k*d[2])^d[1];}
}
temp[i][m]=e^y^temp[i][m];}
}
for(i=0;i<4;i++)
for(j=0;j<4;j++)
a[i][j]=temp[i][j];
}
3.2.10 加密
AES加密算法由初始轮密钥加和Nr轮的轮变换组成,它的输入为初始状态矩阵和轮密钥,执行加密算法后产生一个输出状态矩阵,输入明文和输出密文均为128比特。
其代码为:
void Encrypt(int a[4][4],int roundKey[4][4],int temp[4][44])
{
int i,j,n;
int decrypt = 0;
AddRoundKey(a,roundKey);/* 轮密钥加*/
for(n=1;n<=10;n++)
{
if(n==10)
{
SubBytes(a,s_box); /* 字节替代*/
ShiftRows(a,decrypt); /*行移位*/
GetRoundKey(roundKey,temp,n); /* 获取轮密钥*/
printf("\n");
printf("第%d轮加密密钥为:\n",n);
for(i=0;i<4;i++)
{
for(j=0;j<4;j++)
{
if(roundKey[i][j]<16)
printf("0%x ", roundKey[i][j]);
else
printf("%x ", roundKey[i][j]);}
printf("\n");}
printf("\n\n");
AddRoundKey(a,roundKey); /* 轮密钥加*/
printf("\n");
printf("第10轮加密结果为: \n");
for(i=0;i<4;i++)
{
for(j=0;j<4;j++)
{
if(a[i][j]<16)
printf("0%x ",a[i][j]);
else
printf("%x ",a[i][j]);}
printf("\n");}
printf("第10轮加密结束 \n");
printf("\n\n");
}
else
{
SubBytes(a,s_box); /* 字节替代*/
ShiftRows(a,decrypt); /*行移位*/
MixColumns(a,b); /* 列混合*/
GetRoundKey(roundKey,temp,n); /* 获取轮密钥*/
printf("\n");
printf("第%d轮加密密钥为:\n",n);
for(i=0;i<4;i++)
{
for(j=0;j<4;j++)
{
if(roundKey[i][j]<16)
printf("0%x ", roundKey[i][j]);
else
printf("%x ", roundKey[i][j]);}
printf("\n");}
printf("\n\n");
AddRoundKey(a,roundKey); /* 轮密钥加*/
printf("\n");
printf("第%d轮加密结果为: \n",n);
for(i=0;i<4;i++)
{
for(j=0;j<4;j++)
{
if(a[i][j]<16)
printf("0%x ",a[i][j]);
else
printf("%x ",a[i][j]);}
printf("\n");}
printf("第%d轮加密结束 \n",n);
printf("\n\n");
}
}
}
3.2.11 解密
解密算法和加密算法类似,只是在解密算法中使用的变换为加密时相应变换的逆变换,并且在第一轮到地Nr-1轮之间逆字节替代与逆行移位,逆列混合和逆轮密钥加交换了位置。
其代码为:
void Decrypt(int a[4][4],int roundKey[4][4],int temp[4][44])
{
int i,j,n,m;
int decrypt = 1;
int r[10]={0,9,8,7,6,5,4,3,2,1};
m=10;
GetRoundKey(roundKey, temp,m);
AddRoundKey(a,roundKey);
for(n=1;n<=10;n++)
{
if(n==10)
{
ShiftRows(a,decrypt);
InvSubBytes(a,Invers_box);
m=0;
GetRoundKey(roundKey, temp,m);
printf("\n");
printf("第10轮解密密钥为:\n");
for(i=0;i<4;i++)
{
for(j=0;j<4;j++)
{
if(roundKey[i][j]<16)
printf("0%x ",roundKey[i][j]);
else
printf("%x ",roundKey[i][j]);}
printf("\n");}
printf("\n\n");
AddRoundKey(a,roundKey);
printf("\n");
printf("第10轮解密结果为: \n");
for(i=0;i<4;i++)
{
for(j=0;j<4;j++)
{
if(a[i][j]<16)
printf("0%x ",a[i][j]);
else
printf("%x ",a[i][j]);}
printf("\n");}
printf("第10轮解密结束\n");
printf("\n\n");}
else
{ ShiftRows(a,decrypt);
InvSubBytes(a,Invers_box);
m=r[n];
GetRoundKey(roundKey, temp,m);
printf("\n");
printf("第%d轮解密密钥为:\n",n);
for(i=0;i<4;i++)
{
for(j=0;j<4;j++)
{
if(roundKey[i][j]<16)
printf("0%x ",roundKey[i][j]);
else
printf(" %x ",roundKey[i][j]);}
printf("\n");}
printf("\n\n");
AddRoundKey(a,roundKey);
InvMixColumns(a,c);
printf("\n");
printf("第%d轮解密结果为: \n",n);
for(i=0;i<4;i++)
{
for(j=0;j<4;j++)
{
if(a[i][j]<16)
printf("0%x ",a[i][j]);
else
printf("%x ",a[i][j]);}
printf("\n");}
printf("第%d轮解密结束 \n",n);
printf("\n\n");
}
}
}
3.3 实验结果展示
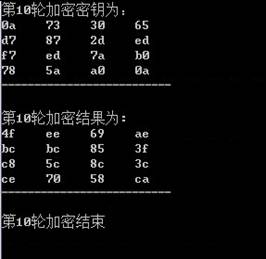
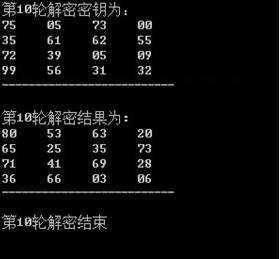
4 实现椭圆曲线密码算法
4.1 算法原理与设计思想
4.1.1 椭圆曲线概述
在椭圆曲线加密中,利用了某种特殊形式的椭圆曲线,即定义在有限域上的椭圆曲线。其方程如下:
y2=x3+ax+b(mod p)
这里p是素数,a和b为两个小于p的非负整数,它们满足:
4a3+27b2(mod p)≠0 其中,x,y,a,b ∈Fp,则满足式(2)的点(x,y)和一个无穷点O就组成了椭圆曲线E。
椭圆曲线离散对数问题ECDLP定义如下:给定素数p和椭圆曲线E,对 Q=kP,在已知P,Q的情况下求出小于p的正整数k。
4.1.2 加密通信的过程
1、用户A选定一条椭圆曲线Ep(a,b),并取椭圆曲线上一点,作为基点G。
2、用户A选择一个私有密钥k,并生成公开密钥K=kG。
3、用户A将Ep(a,b)和点K,G传给用户B。
4、用户B接到信息后 ,将待传输的明文编码到Ep(a,b)上一点M(将M转化为十进制整数m,然后令椭圆曲线中点的横坐标为m,根据曲线方程计算出纵坐标,便得到了一个点。),并产生一个随机整数r(r<n)。
5、用户B计算点C1=M+rK;C2=rG。
6、用户B将C1、C2传给用户A。
7、用户A接到信息后,计算C1-kC2,结果就是点M。因为
C1-kC2=M+rK-k(rG)=M+rK-r(kG)=M
再对点M进行解码就可以得到明文。
4.1.3 过程分析
1、 将给出的椭圆上的两点G,K相加求得第三点M。P跟Q有两种情况。分P=Q和P不等于Q时。
2、 求M的过程中进行求模运算。第一,将分数利用最小公倍数求模。第二,负数求模,先将负号拿出来,求完再将负号加上。根据公式将λ解出。
3、 将X3Y3求出。循环算出nG,求出C1C2(密文)。C1=rG,C2=M+rK。M为明文,公开密钥K=kG
4.2 实验代码
#include <iostream>
using namespace std;
//求两数的最小公倍数
int f1(int a, int b)
{
int c=a;
while( c%a!=0 || c%b!=0)
c++;
return c;
}
//求mod
int mod (int a, int b)
{
int c;
if(a>0)
c=a%b;
else
{
while(a<b)
a=a+b;
c=a%b;
}
return c;
}
//求λ
int f2(int x1,int y1,int x2,int y2,int a,int p)
{
int b,b1,b2,q;//b1为分子,b2为分母
if( x1==x2 && y1==y2)//如果λ两点相等
{
b1=3*x1*x1+a;
b2=2*y1;
if(b1<0)
b1=-mod(-b1,p);
else
b1=mod(b1,p);
if(b2<0)
{
b2=mod(-b2,p);
q=-f1(b2,p+1)/b2;
}
else
{
b2=mod(b2,p);
q=f1(b2,p+1)/b2;
}
b2=f1(b2,p+1)/b2;
b=b1*b2;
b=mod(b,p);
}
else
{
b1=y2-y1;
b2=x2-x1;
if(b1<0)
b1=-mod(-b1,p);
else
b1=mod(b1,p);
if(b2<0)
{
b2=mod(-b2,p);
q=-f1(b2,p+1)/b2;
}
else
{
b2=mod(b2,p);
q=f1(b2,p+1)/b2;
}
b=b1*q;
b=mod(b,p);
}
return b;
}
//求两点横坐标的和
int sumx(int x1,int y1,int x2,int y2,int k,int a,int p)
{
int x3,y3,i;
if(k==1)
{
x3=(f2(x1,y1,x2,y2,a,p))*(f2(x1,y1,x2,y2,a,p))-x1-x2;
x3=mod(x3,p);
}
else
{
for(i=1;i<=k-1;i++)
{
x3=(f2(x1,y1,x2,y2,a,p))*(f2(x1,y1,x2,y2,a,p))-x1-x2;
x3=mod(x3,p);
y3=(f2(x1,y1,x2,y2,a,p)*(x1-x3))-y1;
y3=mod(y3,p);
x2=x1;
x1=x3;
y2=y1;
y1=y3;
}
}
return x3;
}
//求两点纵坐标的和
int sumy(int x1,int y1,int x2,int y2,int k,int a,int p)
{
int x3,y3,i,u=x1,v=y1,m=x2,n=y2;
if(k==1)
{
x3=f2(u,v,m,n,a,p)*f2(u,v,m,n,a,p)-u-m;
x3=mod(x3,p);
y3=f2(u,v,m,n,a,p)*(u-x3)-v;
y3=mod(y3,p);
}
else
{
for(i=1;i<=k-1;i++)
{
x3=f2(u,v,m,n,a,p)*f2(u,v,m,n,a,p)-u-m;
x3=mod(x3,p);
y3=f2(u,v,m,n,a,p)*(u-x3)-v;
y3=mod(y3,p);
m=x1;
u=x3;
n=y1;
v=y3;
}
}
return y3;
}
//加密过程
void encry(int x1,int y1,int x2,int y2,int k, int a, int p,int r)
{
int c1x,c1y,bx,by,bx1,by1,mbx,mby;
c1x=sumx(x1,y1,x1,y1,r,a,p);
c1y=sumy(x1,y1,x1,y1,r,a,p);
bx1=sumx(x1,y1,x1,y1,k,a,p);
by1=sumy(x1,y1,x1,y1,k,a,p);
bx=sumx(sumx(x1,y1,x1,y1,k,a,p),sumy(x1,y1,x1,y1,k,a,p),sumx(x1,y1,x1,y1,k,a,p),sumy(x1,y1,x1,y1,k,a,p),r,a,p);
by=sumy(sumx(x1,y1,x1,y1,k,a,p),sumy(x1,y1,x1,y1,k,a,p),sumx(x1,y1,x1,y1,k,a,p),sumy(x1,y1,x1,y1,k,a,p),r,a,p);
mbx=sumx(x2,y2,bx,by,1,a,p);
mby=sumy(x2,y2,bx,by,1,a,p);
cout<<"(C1,C2)="<<"(("<<c1x<<","<<c1y<<"),("<<mbx<<","<<mby<<"))";
}
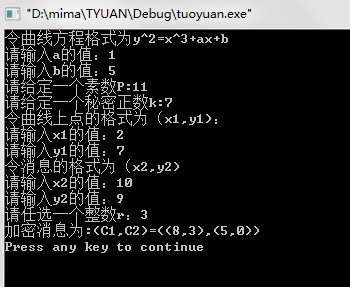
void main()
{
cout<<"令曲线方程格式为y^2=x^3+ax+b"<<endl;
int a,b,c,d,m,n,x,y,r;
cout<<"请输入a的值:";
cin>>a;
cout<<"请输入b的值:";
cin>>b;
cout<<"请给定一个素数P:";
cin>>c;
cout<<"请给定一个秘密正数k:";
cin>>d;
cout<<"令曲线上点的格式为(x1,y1):"<<endl;
cout<<"请输入x1的值:";
cin>>m;
cout<<"请输入y1的值:";
cin>>n;
cout<<"令消息的格式为(x2,y2)"<<endl;
cout<<"请输入x2的值:";
cin>>x;
cout<<"请输入y2的值:";
cin>>y;
cout<<"请任选一个整数r:";
cin>>r;
cout<<"加密消息为:";
encry(m,n,x,y,d,a,c,r);
cout<<endl;
}
4.3 实验结果展示
5 实验心得体会
经过前一段时间对密码学课程的学习,我对密码学技术有了初步的了解,经过此次密码学课程设计,将已知知识灵活结合应用起来,我再次加深了对密码知识的了解和认识。
这四个密码算法,都具有一定的难度,对于编程知识不扎实的我来说,具有很强的挑战性。在此次课程设计中,在编程的过程中遇到了很多的问题,发现了自己编程能力的不足以及课堂学习的局限性,知道了只有通过动手实践才能真正掌握所学的知识。通过询问同学和参考网上的资料,最终完成了此次课程设计,锻炼了自己分析问题和解决问题的能力。同时通过实际编写密码分析程序,也极大的激发了我对密码学的兴趣,我会在以后的学习中不断地积累和丰富密码学技术知识。
-
密码学课程设计报告
沈阳工程学院课程设计设计题目院系信息学院班级信安本111学生姓名学号指导教师祝世东王素芬职称工程师副教授起止日期20xx年1月6日…
-
密码学课程设计报告
密码学课程设计报告班级:信安10-1班姓名:学号:指导老师:一、Hash算法的实现MD5算法1.1算法概述MD5算法是一种消息摘要…
-
密码学-RSA加密解密算法的实现课程设计报告
密码学课程报告《RSA加密解密算法》专业:信息工程(信息安全)班级:1132102学号:****姓名:***时间:20××年1月1…
-
密码学课程设计报告
XX大学密码学课程设计姓名学号学院指导老师完成日期20xx0106一实验任务及要求任务使用IDEA算法实现加解密过程要求1输入至少…
-
密码学课程设计报告要求及模板
计算机与信息工程学院《密码学课程设计》报告(20××/20学年第二学期)题目:Diffie-Hellman密钥交换协议系别:计算机…
-
密码学:AES的实现与分析-课程设计
课程设计课程名称密码学题目名称AES的实现与分析学生学院应用数学学院专业班级11信息安全1班学号学生姓名指导教师李锋20xx年12…
-
现代密码学课程设计实验报告 -
西安科技大学《现代密码学》课程设计报告题目:密码学计算器学院:计算机科学与技术学院班级:姓名:学号:日期:20XX.1.8一.课程…
-
密码学课程设计报告
沈阳工程学院课程设计设计题目院系信息学院班级信安本111学生姓名学号指导教师祝世东王素芬职称工程师副教授起止日期20xx年1月6日…
-
密码学课程设计报告
密码学课程设计班级成员姓名指导教师20xx7中国矿业大学计算机学院密码学课程设计目录密码学课程设计11实验一实现一个多表古典加密和…
-
密码学-RSA加密解密算法的实现课程设计报告
密码学课程报告《RSA加密解密算法》专业:信息工程(信息安全)班级:1132102学号:****姓名:***时间:20××年1月1…