计量经济学报告
多元线性回归模型实验分析
实验步骤
一、变量之间相关性分析
Correlation Matrix
Y X1 X2 X3 X4
Y 1.000000 -0.232829 -0.003101 -0.833077 -0.826184
X1 -0.232829 1.000000 -0.158706 0.290057 0.037925
X2 -0.003101 -0.158706 1.000000 0.140559 0.334241
X3 -0.833077 0.290057 0.140559 1.000000 0.933534
X4 -0.826184 0.037925 0.334241 0.933534 1.000000
首先,可以由表中数据得出,x3、x4与y的负相关系数较大,说明他们之间的线性相关程度大;而x1、x2与y的相关系数较小,x2近乎于0,说明x2与y的相关程度比较小。由此猜测x1、x2与y可能不相关。
还可以发现,x3与x4之间相关系数快要趋于1,然而变量之间关系应该是不相关的,由此猜测x3、x4两者中有一个并不是y的相关因素。
二、散点图分析
根据自变量x1、x2、x3、x4与因变量y的各个散点图来分析
X1、X2的散点较分散,表示与Y的线性关系并不显著。特别是x2与y之间的线性线趋近于直线,因此,可以假设x1、x2与变量y不相关。
X3、X4的散点较集中,与Y的线性关系比较显著,且图形较相同,因此,可以假设自变量x3、x4之中有一个不是变量y的相关因素。
三、假设检验
先用普通最小二乘法检验
1.Y与x1 x2 x3 x4 建立总体模型
Dependent Variable: Y Method: Least Squares Date: 11/19/12 Time: 18:09 Sample: 1991 2010 X1 X2 X3 X4 R-squared
Adjusted R-squared S.E. of regression Sum squared resid Log likelihood -0.152177 0.928911 3.259844 -11.85109 0.091600 0.379247 3.144016 4.398585 -1.661322 2.449356 1.036841 -2.694297 0.1174 0.0271 0.3162 0.0166 2.540220 0.265758 -0.990990 -0.742056 15.33666 0.803528 Mean dependent var 0.751135 S.D. dependent var 0.132577 Akaike info criterion 0.263650 Schwarz criterion 14.90990 F-statistic
分析: 拟合程度:图中可知R-squared=0.803528, Adjusted R-squared=0.751135,数据较大,说明拟合程度较高。
显著性:Prob(F-statistic)<0.05,线性关系显著。
结论:变量x1与x3两者的Prob>0.05,,说明x1、x3变量的显著性不强。因此,应该考虑是否剔除x1与x3这两个变量。
2.Y与X1、X2、X4建立模型 Dependent Variable: Y Method: Least Squares
Date: 11/16/12 Time: 23:35 Sample: 1991 2010
X1 X2 X4 R-squared
Adjusted R-squared S.E. of regression Sum squared resid Log likelihood -0.082845 0.713914 -7.407430 0.789447 0.749968 0.132887 0.282545 14.21772 0.062750 0.318283 0.992114 -1.320245 2.243018 -7.466312 0.2053 0.0394 0.0000 2.540220 0.265758 -1.021772 -0.822626 19.99675 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic
拟合程度:R-squared=0.789447,Adjusted R-squared=0.749968,可以说明拟合程度高。 显著性:Prob(F-statistic)<0.05,线性关系显著。
结论:除去x3的模型中AIC=-1.021772、SC=-0.822626,比较总体模型,可知除去x3后模型中的SC、AIC值更小。因此,说明变量x3对模型没有影响,可以剔除。
3.Y与X1、X4建立模型 Dependent Variable: Y Method: Least Squares Date: 11/16/12 Time: 23:51 Sample: 1991 2010 Included observations: 20 X4 -6.639969 1.035789 -6.410543 0.0000
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
0.723239 Mean dependent var 0.690679 S.D. dependent var 0.147806 Akaike info criterion 0.371390 Schwarz criterion 11.48357 F-statistic
0.267668 Prob(F-statistic)
2.540220 0.265758 -0.848357 -0.698997 22.21243 0.000018
分析:
拟合程度: R-squared=0.723239,Adjusted R-squared=0.690679,但是本身数值较大,拟合程度还是较高。
显著性:Prob(F-statistic)<0.05,线性关系显著。
结论:模型中AIC=-0.848357、SC=-0.698997,两者与之前的Y与X1、X2、X4的模型中的AIC和SC有所加大,因此,可以说明变量X2不可剔除。
4.Y与X2、X4建立模型 Dependent Variable: Y Method: Least Squares Date: 11/16/12 Time: 23:53 Sample: 1991 2010
Included observations: 20 X2 X4 C
R-squared
Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
0.790381 -7.535481 3.198975
0.319736 1.008709 0.106689
2.471982 -7.470422 29.98407
0.0243 0.0000 0.0000 2.540220 0.265758 -1.018367 -0.869007 27.90396 0.000004
0.766509 Mean dependent var 0.739039 S.D. dependent var 0.135761 Akaike info criterion 0.313326 Schwarz criterion 13.18367 F-statistic 0.537862 Prob(F-statistic)
拟合程度:R-squared=0.766509、Adjusted R-squared=0.739039,拟合程度好。 显著性:Prob(F-statistic)<0.05,线性关系显著。
结论:该模型中AIC=-1.018367、SC=-0.869007,两者与之前的Y与X1、X2、X4的模型中的AIC和SC有所加大。因此,可以说明变量x1对模型没有影响,可以剔除。
多元线性回归方程:Y=3.198975+0.790381*X2-7.535481*X4 再使用最大似然估计和矩估计法来分析变量x2、x4对变量y的线性影响。
最大似然估计法建立Y与X2、X4之间关系的模型
Dependent Variable: Y
Method: ML - Censored Normal (TOBIT) Date: 11/19/12 Time: 20:50 Sample: 1991 2010 Included observations: 20 Left censoring (value) at zero
Convergence achieved after 4 iterations
Covariance matrix computed using second derivatives
X2 X4 C SCALE:C(4)
R-squared
Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Avg. log likelihood
0.790381 -7.535481 3.198975
0.294781 0.929981 0.098362
2.681248 -8.102831 32.52237
0.0073 0.0000 0.0000
0.125165
0.019790
6.324595
0.0000 2.540220 0.265758 -0.918367 -0.719221 -0.879492
0.766509 Mean dependent var 0.722729 S.D. dependent var 0.139939 Akaike info criterion 0.313326 Schwarz criterion 13.18367 Hannan-Quinn criter. 0.659184
矩估计法建立Y与X2、X4之间关系的模型 Dependent Variable: Y
Method: Generalized Method of Moments Date: 11/19/12 Time: 21:18 Sample: 1991 2010
Included observations: 20 No prewhitening Bandwidth: Fixed (2) Kernel: Bartlett
Convergence achieved after: 1 weight matrix, 2 total coef iterations X2 X4 R-squared
Adjusted R-squared S.E. of regression Durbin-Watson stat
0.790381 -7.535481 0.766509 0.739039 0.135761 0.537862
0.352758 1.527347 2.240577 -4.933704 0.0387 0.0001 2.540220 0.265758 0.313326 1.45E-28
Mean dependent var S.D. dependent var Sum squared resid J-statistic
可以看出,矩估计的结果以及最大似然估计法与普通最小二乘法的结果一致。
数据处理
Y=3.198975+0.790381*X2-7.535481*X4
从方程可以得出,
1.人均GDP增长率(x2)与城乡收入比(y)成正相关关系,当人均GDP增长率增加一个百分比,城乡收入比增加0.790381个百分比。
2.产业比(x4)与城乡收入比(y)成负相关关系,当产业比减少一个百分比,城乡收入比增加7.535481个百分比。
3.除此之外,城乡收入还可能由其他经济因素改变,由系数C=3. 198975表示,可以说,它对城乡收入比的影响是固定不变的。
实验总结
报告的经济意义在于,证实城乡二元结构系数与财政支农比率不是造成城乡居民收入比拉大的原因。真正造成城乡居民收入比拉大的原因是人均GDP增长率与产业比。
因而,首先要促进经济的大发展,不断深化产业化改革,扩大产业规模,优化结构,从而加强经济实力,加大人均GDP的增长率。
产业比例中,农业比例应该随着当今时代的变迁不断减小,但是应该加大对于农村的建设,解决对于农村教育、医疗、就业等问题, 使得城乡平衡发展战略,缩小城乡差距。
第二篇:计量经济学试验报告
实验报告
实验1:单方程线性计量经济学模型的最小二乘估计和统计检验
1实验目的
掌握计量经济学专用软件(Eviews)使用方法,理解和正确解释输出结果。在学习计量经济学的基本理论和方法的基础上,掌握建立计量经济模型对实际经济问题进行实证分析的方法。运用Eviews软件完成对线形回归模型的最小二乘估计、统计检验、计量经济学检验以及进一步进行经济结构分析、经济预测和政策评价,培养发现问题、分析问题、解决问题的能力。
2实验软件
Eviews5.0
3实验数据
甲商品从1988—20xx年的销售量Y/千个,价格X1 /(元/个),售后服务支出X2 /万元
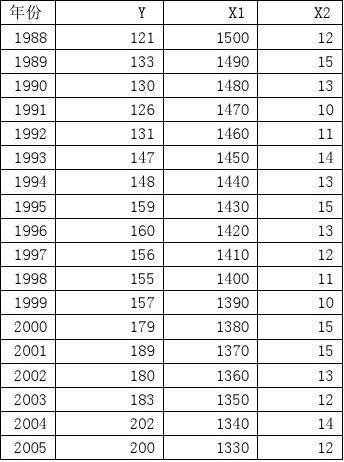
1
4实验内容及其步骤 实验内容:
研究甲商品1988—20xx年价格和售后服务支出对销售量的影响。 其中,销售量Y、价格X1、售后服务支出X2的数据如上所示。 建立多元线性计量经济学回归模型为:
Yi = β0 + β1X1i + β2X2i + μi
实验步骤:
1、建立工作文件:双击Eviews,进入Eviews主界面在主菜单上依次点击 File → New → Workfile,出现Workfile对话框,在workfile frequency中选择Annual,在Start里输入起始日期1988,在End里输入结束日期2009。点击OK。 2、输入数据:在Eviews命令框中输入“data Y X1 X2”,按enter键,出现Group数据编辑窗口,在对应的“Y”、“X1”、“X2”下输入相应数据。
3、估计参数:在Eviews主窗口界面点击Quick菜单,点击“Estimate Equation”,弹出“Equation Specification”对话框,选择“LS-Least Squares”,输入“Y C X1 X2”,点击OK按钮,出现回归分析结果如下:
Dependent Variable: Y Method: Least Squares Date: 05/25/10 Time: 16:21 Sample: 1988 2009 Included observations: 22
Variable C X1 X2
R-squared Adjusted R-squared S.E. of regression
Std. Error 41.55143 0.028701 1.075251
t-Statistic 20.53784 -18.54467 4.390998
Coefficient 853.3767 -0.532253 4.721426
Prob. 0.0000 0.0000 0.0003 170.5455 35.96920 7.250172
2
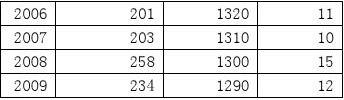
0.949168 Mean dependent var 0.943818 S.D. dependent var 8.525703 Akaike info criterion
Sum squared resid
Log likelihood
Durbin-Watson stat
1381.065 Schwarz criterion -76.75189 F-statistic 0.881956 Prob(F-statistic) 7.398950 177.3919 0.000000
5实验结果分析
由上表回归分析结果,模型估计结果为:
Y i = 853.3767 - 0.532253X1i + 4.721426X2i
2=0.943818 F=177.3919 df=19
1、经济意义检验
根据回归结果,参数β1的估计量为—0.532253,说明在其他变量不变的条件下,甲商品的价格每下降1元,就会使销售量增加0.532253千个,与理论模型中描述的价格与销售量之间存在负相关关系是一致的。参数β2的估计量为4.721426,说明在其他变量不变的条件下,对甲商品的售后服务支出每增加1万元,就会使销售量增加
4.721426千个,与理论模型中描述的销售量与售后服务支出之间存在正相关关系是一致的。
2、统计推断检验
1) 拟合优度检验:
由表中数据可以看出,本例中的可决系数R2=0.949168,调整的可决系数
2=0.943818,说明模型对样本的拟合优度很好,解释变量能对被解释变量94%的离差作出解释。
2) 方程显著性检验------F检验:
给定显著性水平α=0.05,针对原假设H0:β1=β2=0,备择假设H1:β1、β2不全为零,进行检验。由表知,F=177.3919,F分布表自由度分别为k=2,n-k-1=19,F0.05(2,
19)=3.52,由于F>F0.05(2,19),所以拒绝原假设H0,接受备择假设H1,在5%的显著水平下,Y对X1、X2有显著的线性关系,回归方程是显著的,即解释变量“价格”和“售后服务支出”联合起来对被解释变量 “销售量”有显著影响。
3) 变量显著性检验----t检验:
给定显著性水平α=0.05,分别针对假设H0:β1=0,H1:β1≠0和H0:β2=0,H1:β2≠0进行检验。由表可知,参数β1和β2估计量的t值分别为:
t(β1) = —18.54467 t(β2) = 4.390998
查t分布表得: t0.025(19)=2.093 可见:
∣t(β1)∣> t0.025(19) ∣t(β2)∣> t0.025(19)
所以拒绝H0,接受H1。这表明解释变量“价格”和“售后服务支出”在95%的 3
置信水平下都对被解释变量 “销售量”有显著影响,都通过了显著性检验。
6心得体会
通过这次实验,我明白了eviews的使用方法,运用Eviews对数据进行分析,快速的建立回归模型,通过对实验结果的分析可清晰地了解各项统计检验结果。在这过程中,图形分析与各项指标相结合更清楚的了解数据的特性。比如散点图与可决系数相比较,可知道回归模型对数据的拟合程度。通过这次试验,我进一步了解了计量经济学线性回归模型的最小二乘估计,理论与实践结合,理解了各项统计检验指标的内涵。
-----朱莉莉 2008092121
通过此次实验,我学会了Eviews在单方程经济模型的一些应用。了解到了利用Eviews来对线性回归模型的估计:创建工作文件、输入和编辑数据、进行图形分析和OLS估计参数。其间,我还认识到了怎样用Eviews来对模型进行统计检验、预测和实际的操作。在估计线性模型时,运用并熟悉了普通最小二乘法(OLS),还了解了制作散点图的方法。在统计检验时,充分认识到拟合优度检验、显著性检验和方程显著性的F检验的具体步骤和原理。
-----赵 悦 2008092127
在实验之前,我对Eviews软件了解甚少。通过这次试验,让我有机会接触并亲身实践。通过利用Eviews软件将所学到的计量经济学知识进行实践,让我加深了对理论知识的额理解,更体会到了单方程计量经济学模型的精髓之所在。其中涉及的大量公式,以及大量的运算,曾令我觉得很吃力。通过这次试验,使我对最小二乘法有了进一步的了解,通过软件应用,免除了大量的繁琐计算,使分析更加方便快捷,同时也给了我更多的对于所掌握知识的启示。
-----白 双 2008092114
在实验之前,老师的演示还有一点没有明白。后来经过反复的熟悉Eviews软件,我了解到怎样运用Eviews来对单方程计量经济模型估计和统计的检验。我熟悉了普通最小二乘法的实际运用,并在找来统计数据之后,了解到对模型的预测和显著性检验。实践与理论并行。
-----吴庄友 2008092129
计量经济学是一门以经济理论为前提,借助数学、统计学方法,以经济计量软件为工具,根据实际观测资料来研究经济现象、分析经济过程,通过建立经济计量模型来探讨经济规律的学科。计量经济学建模的程序为:模型设定、模型估计、模型检验和模型应用。模型的构成要素为:被解释变量、解释变量、参数、随机项和方程式。 4
建模需要高质量的数据资料。数据可归为四类:横断面数据、时间序列数据、虚拟变量数据、平行数据。数据的质量与数据的完整性、准确性、可比性一致相关性。收集数据时要注意样本容量要大、数据结构要稳定等问题。模型估计的方法从大类来说分为极大似然估计法、最小二乘法系列。我们主要应用后者。模型的检验包括经济合理性检验、古典统计检验和经济计量检验。经济计量模型主要应用于经济预测、经济结构分析、政策评价方面。
------许孝孔 2008092117
5
实验2:联立方程模型的估计
1实验目的
理解线性联立方程计量经济学模型的基本概念和有关模型识别、检验的理论与方法;掌握常用的估计、检验方法:联立方程的两阶段最小二乘法估计方法、系统估计方法和预测;运用Eviews软件建立并应用简单的计量经济学模型,对现实经济现象中的数量关系进行实际分析。
2实验软件
Eviews5.0
3实验数据
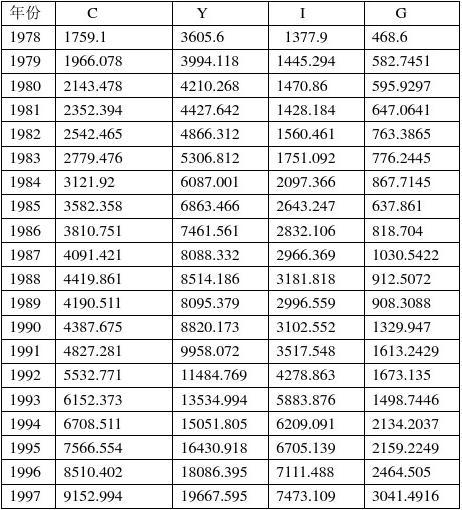
1978—20xx年全国居民消费Ct、国民生产总值Yt 、投资It、政府消费支出Gt
单位:亿元
6
4实验内容及其步骤 实验内容:
1978—20xx年全国居民消费Ct、国民生产总值Yt 、投资It、政府消费支出Gt数据(单位:亿元),如上表所示: 建立联立方程模型:
消费方程:Ct = ?0 + ?1Yt + ?2 Ct-1+ u1t 投资方程:It = ?0 + ?1 Yt-1 + u2t 收入方程;Yt = Ct + It + Gt
对方程的识别性进行判断,可知消费方程恰好识别,投资方程过度识别,收入方程为平衡方程,不存在可识别性,因此,整个联立方程组过度识别,可用两阶段最小二乘法进行参数估计。
实验步骤:
1、建立工作文件:双击Eviews,进入Eviews主界面在主菜单上依次点击 File → New → Workfile,出现Workfile对话框,在workfile frequency中选择Annual,在Start里输入起始日期1978,在End里输入结束日期2003。点击OK。 2、输入数据:在主功能菜单上点击Object,点击Objects中的New Objects,选择Group,并定义文件名,点击Ok,出现数据编辑框,输入样本数据。 3、估计参数:在主页上选择Quick菜单,点击Equation项,出现估计对话框,在Estimate Settings中选择TSLS估计,Estimate Speclication中分别键入:CU C Y CU(-1)和C G CU(-1) I(-1),点击Ok,出现回归分析结果如下:
消费函数:
Dependent Variable: CU
Method: Two-Stage Least Squares Date: 05/25/10 Time: 17:09 Sample (adjusted): 1979 2003
Included observations: 25 after adjustments Instrument list: C G CU(-1) I(-1)
Variable
Coefficient
Std. Error
t-Statistic
Prob.
7
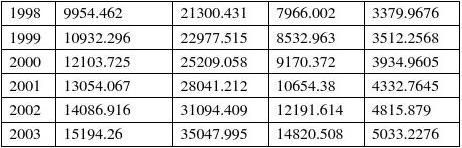
C 139.4559 89.28587 1.561904 0.1326 Y 0.122725 0.068805 1.783655 0.0883 CU(-1) 0.783980 0.169392 4.628189 0.0001 R-squared 0.998561 Mean dependent var 6526.600
Adjusted R-squared 0.998431 S.D. dependent var 4023.411 S.E. of regression 159.3868 Sum squared resid 558891.4 F-statistic 7631.907 Durbin-Watson stat 1.391460 Prob(F-statistic) 0.000000 投资函数:
Dependent Variable: I Method: Two-Stage Least Squares Date: 05/25/10 Time: 17:10 Sample (adjusted): 1979 2003 Included observations: 25 after adjustments Instrument list: C G CU(-1) I(-1) Variable Coefficient Std. Error t-Statistic Prob.
C -336.3689 171.9259 -1.956476 0.0627
Y(-1) 0.448308 0.011556 38.79458 0.0000 R-squared 0.984978 Mean dependent var 5279.634
Adjusted R-squared 0.984324 S.D. dependent var 3703.951 S.E. of regression 463.7430 Sum squared resid 4946325. F-statistic 1505.019 Durbin-Watson stat 0.779184 Prob(F-statistic) 0.000000 5实验结果分析
由上表回归分析结果,模型估计结果为:
消费模型: Ct = 139.4559 + 0.122725Yt + 0.783980Ct-1
2=0.998431 F=7631.907 D·W =1.391460
投资模型: It = —336.3689 + 0.448308Yt-1
2 =0.984324 F=1505.019 D·W =0.779184
收入模型: Yt = —224.4598 + 0.511023Yt-1 + 0.893654Ct-1 + Gt 8
1、拟合优度检验
消费模型:由表中数据看出,可决系数R2=0.998561,调整的可决系数2 =0.998431,
说明模型对样本的拟合优度很好,解释变量能对被解释变量99.8%的离差
作出解释。
投资模型:可决系数R2=0.984978,调整的可决系数 2=0.984324,说明模型对样本
的拟合优度很好,解释变量能对被解释变量98.4%的离差作出解释。
2、方程显著性检验-------F检验:
给定显著性水平α=0.05,假设H0:β1=β2=0,H1:β1、β2不全为零,进行检验。 消费模型:F=7631.907,查F分布表,F0.05(2,23)=3.42,由于F>F0.05(2,19),所以拒
绝假设H0,接受H1,在5%的显著水平下,C对Yt、Ct-1有显著的线性关
系,回归方程是显著的,即解释变量“国民收入”和“居民前期消费”联
合起来对被解释变量 “消费支出”有显著影响。
投资模型:F=1505.019,查F分布表,F0.05(1,24)=4.26,由于F>F0.05(2,19),所以拒
绝假设H0,接受H1,在5%的显著水平下, I对Yt-1有显著的线性关系,
回归方程是显著的,即解释变量“前期国民收入”被解释变量“投资支出”有显著影响
3、异方差性---- D·W检验 给定显著性水平α=0.05
消费模型:由表得,D·W =1.391460,当n=26,k=2时,dL=1.224 du=1.553,
dL<D·W<du,不能确定是否存在一阶自相关
投资模型:D·W =0.779184,当n=26,k=1时,dL=1.302 du=1.461, 0<D·W< dL ,
存在正自序列相关
6心得体会
通过这次试验,我了解经济数量分析在经济学科的发展和实际经济工作中的作用,理解了单方程估计方法和系统估计方法的异同,掌握了联立方程的两阶段最小二乘法估计方法、系统估计方法和预测。与线性回归模型相比,联立方程计量计学模型的检验要复杂得多。在2SLS过程中,要分别检验每个方程和单个变量的显著性以及每一个方程的拟合优度。利用eviews软件,可以很方便的确定模型中方程的识别特性,快捷地对方程及变量的显著性进行检验。
---朱莉莉 2008092121
联立方程模型是由两个或两个以上相互联系的单一方程结合在一起描述某一经济系统的联立方程组。构成联立方程模型的变量类型有内生变量、外生变量、前定变量。联立方程组模型可以表达为结构式模型、简化式模型和递归系统模型。模型识别的目的在于选择估计模型的适宜方法。估计联立方程模型的方法有:OLS法、ILS法、IV法、2SLS法及3SLS法。OLS法适合于估计递归联立方程模型。ILS和IV适合于估计恰好识别的结构式方程,求得的模型参数估计量对于小样本是有偏,对于大样本 9
是一致的。2SLS法实质上也是一种工具变量法,适合于估计恰好识别及过度识别的结构方程,具有与工具变量法估计量相同的性质。3SLS法是一种系统估计法,实质上等价于2SLS+GLS法。3SLS估计量比2SLS估计量更有效,因为3SLS在估计过程中应用的信息比2SLS更多。
---许孝孔 2008092117
在这联立方程经济模型试验中,我熟悉怎样建立一个联立方程系统、利用两阶段最小二乘法(2SLS)对模型进行估计、利用RMS来判断模型的总体拟合优度。同时还深入了解方程识别的原理和步骤方法。将理论知识与实践相结合,巩固了我所学的计量经济学在理论是应用方面的知识。
-------赵悦 2008092127
通过此次联立方程的实验,我深刻体会到了Eviews在实际经济领域的应用以及计量经济学的有效预测。在试验中,我熟悉了两阶段最小二乘法的原理和应用方法,进一步知道了如何对模型进行总体的拟合优度计算。将课堂所学应用于实际生活中是必要的。
------吴庄友 2008092129
计量经济学,作为方法论科学,是进行经济学实证研究的基本工具。其中,联立方程计量经济学模型在实际生活中的应用是十分广泛的。联立方程比单方程计量经济学模型更为复杂,不仅要考虑模型如何建立,还要对其进行可识别性的判断。在实验之前,我并没有意识到这一点,所以起初时,我产生了一些错误,后来在其他同学的帮助下,问题得到了解决。通过一系列的操作,对方程进行识别,应用Eviews软件进行分析,有了更熟练的掌握。我想计量经济学的研究方法以及给我的启示,对我未来的学习,都有很大的帮助。
-----白双 2008092114
10
-
计量经济学实验报告格式
时间:20XX年9月11日小组成员:XXX实验题目:多元线性回归分析一、实验目的与要求:要求目的:熟练运用eviews软件操作,建…
-
计量经济学实验报告模版
计量经济学实验报告姓名:XX班级:B100906学号:XX《计量经济学》课程实验报告1一、实验目的1.学会Eviews工作文件的建…
-
计量经济学实验报告范文
计量经济学实验报告范文一各地区农村居民家庭人均纯收入与家庭人均消费支出的数据单位元地区北京天津河北山西内蒙古辽宁吉林黑龙江上海江苏…
- 计量经济学实验报告(范例)
- 计量经济学实验报告模板加实例
-
计量经济学实验报告1_心得体会
计量经济学实验心得本次比赛的收获、体会、经验、问题和教训:通过利用Eviews软件将所学到的计量知识进行实践,让我加深了对理论的理…
- 计量经济学实验报告1 心得体会
-
计量经济学实验报告
实验1一元线性回归分析实验目的学习利用Eviews进行一元线性回归分析一实验内容利用一元线性回归模型研究改革开放以来中国居民消费状…
-
计量经济学实验报告
学生实验报告经管类专业用一实验目的及要求1目的利用实验软件使学生在实验过程中全面了解和熟悉计量经济学的基本概念熟悉一元线性回归模型…
- 计量经济学实验报告(范例)