编译原理实验报告
编译原理实验报告
语义分析
实验:
班级:
姓名:
学号:
一、 实验目的:
通过上机实习,加深对语法制导翻译原理的理解,掌握将语法分析所识别的语法成分变换为中间代码的语义翻译方法。
二、 实验要求:
采用递归下降语法制导翻译法,对算术表达式、赋值语句进行语义分析并生成四元式序列。
三、 算法思想:
1、设置语义过程。
(1)emit(char *result,char *ag1,char *op,char *ag2)
该函数的功能是生成一个三地址语句送到四元式表中。
四元式表的结构如下:
struct
{ char result[8];
char ag1[8];
char op[8];
char ag2[8];
}quad[20];
(2) char *newtemp()
该函数回送一个新的临时变量名,临时变量名产生的顺序为T1,T2,…
char *newtemp(void)
{ char *p;
char m[8];
p=(char *)malloc(8);
k++;
itoa(k,m,10);
strcpy(p+1,m);
p[0]=’t’;
return(p);
}
2、函数lrparser 在原来语法分析的基础上插入相应的语义动作:将输入串翻译成四元式序列。在实验中我们只对表达式、赋值语句进行翻译。
四、 源程序代码:
#include<stdio.h>
#include<string.h>
#include<iostream.h>
#include<stdlib.h>
struct
{
char result[12];
char ag1[12];
char op[12];
char ag2[12];
}quad;
char prog[80],token[12];
char ch;
int syn,p,m=0,n,sum=0,kk; //p是缓冲区prog的指针,m是token的指针
char *rwtab[6]={"begin","if","then","while","do","end"};
void scaner();
char *factor(void);
char *term(void);
char *expression(void);
int yucu();
void emit(char *result,char *ag1,char *op,char *ag2);
char *newtemp();
int statement();
int k=0;
void emit(char *result,char *ag1,char *op,char *ag2)
{
strcpy(quad.result,result);
strcpy(quad.ag1,ag1);
strcpy(quad.op,op);
strcpy(quad.ag2,ag2);
cout<<quad.result<<"="<<quad.ag1<<quad.op<<quad.ag2<<endl;
}
char *newtemp()
{
char *p;
char m[12];
p=(char *)malloc(12);
k++;
itoa(k,m,10);
strcpy(p+1,m);
p[0]='t';
return (p);
}
void scaner()
{
for(n=0;n<8;n++) token[n]=NULL;
ch=prog[p++];
while(ch==' ')
{
ch=prog[p];
p++;
}
if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))
{
m=0;
while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))
{
token[m++]=ch;
ch=prog[p++];
}
token[m++]='\0';
p--;
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{
syn=n+1;
break;
}
}
else if((ch>='0'&&ch<='9'))
{
{
sum=0;
while((ch>='0'&&ch<='9'))
{
sum=sum*10+ch-'0';
ch=prog[p++];
}
}
p--;
syn=11;
if(sum>32767)
syn=-1;
}
else switch(ch)
{
case'<':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='>')
{
syn=21;
token[m++]=ch;
}
else if(ch=='=')
{
syn=22;
token[m++]=ch;
}
else
{
syn=23;
p--;
}
break;
case'>':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=24;
token[m++]=ch;
}
else
{
syn=20;
p--;
}
break;
case':':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=18;
token[m++]=ch;
}
else
{
syn=17;
p--;
}
break;
case'*':syn=13;token[0]=ch;break;
case'/':syn=14;token[0]=ch;break;
case'+':syn=15;token[0]=ch;break;
case'-':syn=16;token[0]=ch;break;
case'=':syn=25;token[0]=ch;break;
case';':syn=26;token[0]=ch;break;
case'(':syn=27;token[0]=ch;break;
case')':syn=28;token[0]=ch;break;
case'#':syn=0;token[0]=ch;break;
default: syn=-1;break;
}
}
int lrparser()
{//cout<<"调用lrparser"<<endl;
int schain=0;
kk=0;
if(syn==1)
{
scaner();
schain=yucu();
if(syn==6)
{
scaner();
if(syn==0 && (kk==0))
cout<<"success!"<<endl;
}
else
{
if(kk!=1)
cout<<"缺end!"<<endl;
kk=1;
}
}
else
{cout<<"缺begin!"<<endl;kk=1;}
return(schain);
}
int yucu()
{// cout<<"调用yucu"<<endl;
int schain=0;
schain=statement();
while(syn==26)
{
scaner();
schain=statement();
}
return(schain);
}
int statement()
{//cout<<"调用statement"<<endl;
char *eplace,*tt;
eplace=(char *)malloc(12);
tt=(char *)malloc(12);
int schain=0;
switch(syn)
{
case 10:
strcpy(tt,token);
scaner();
if(syn==18)
{
scaner();
strcpy(eplace,expression());
emit(tt,eplace,"","");
schain=0;
}
else
{
cout<<"缺少赋值符!"<<endl;
kk=1;
}
return(schain);
break;
}
return(schain);
}
char *expression(void)
{
char *tp,*ep2,*eplace,*tt;
tp=(char *)malloc(12);
ep2=(char *)malloc(12);
eplace=(char *)malloc(12);
tt =(char *)malloc(12);
strcpy(eplace,term ()); //调用term分析产生表达式计算的第一项eplace
while((syn==15)||(syn==16))
{
if(syn==15)strcpy(tt,"+");
else strcpy(tt,"-");
scaner();
strcpy(ep2,term()); //调用term分析产生表达式计算的第二项ep2
strcpy(tp,newtemp()); //调用newtemp产生临时变量tp存储计算结果
emit(tp,eplace,tt,ep2); //生成四元式送入四元式表
strcpy(eplace,tp);
}
return(eplace);
}
char *term(void)
{// cout<<"调用term"<<endl;
char *tp,*ep2,*eplace,*tt;
tp=(char *)malloc(12);
ep2=(char *)malloc(12);
eplace=(char *)malloc(12);
tt=(char *)malloc(12);
strcpy(eplace,factor());
while((syn==13)||(syn==14))
{
if(syn==13)strcpy(tt,"*");
else strcpy(tt,"/");
scaner();
strcpy(ep2,factor()); //调用factor分析产生表达式计算的第二项ep2
strcpy(tp,newtemp()); //调用newtemp产生临时变量tp存储计算结果
emit(tp,eplace,tt,ep2); //生成四元式送入四元式表
strcpy(eplace,tp);
}
return(eplace);
}
char *factor(void)
{
char *fplace;
fplace=(char *)malloc(12);
strcpy(fplace,"");
if(syn==10)
{
strcpy(fplace,token); //将标识符token的值赋给fplace
scaner();
}
else if(syn==11)
{
itoa(sum,fplace,10);
scaner();
}
else if(syn==27)
{
scaner();
fplace=expression(); //调用expression分析返回表达式的值
if(syn==28)
scaner();
else
{
cout<<"缺)错误!"<<endl;
kk=1;
}
}
else
{
cout<<"缺(错误!"<<endl;
kk=1;
}
return(fplace);
}
void main()
{
p=0;
cout<<"**********语义分析程序**********"<<endl;
cout<<"Please input string:"<<endl;
do
{
cin.get(ch);
prog[p++]=ch;
}
while(ch!='#');
p=0;
scaner();
lrparser();
}
五、 结果验证:
1、给定源程序
begin a:=2+3*4; x:=(a+b)/c end#
 输出结果
输出结果
2、 源程序
begin a:=9; x:=2*3-1; b:=(a+x)/2 end#

输出结果
六、 收获(体会)与建议:
通过此次实验,让我了解到如何设计、编制并调试语义分析程序,加深了对语法制导翻译原理的理解,掌握了将语法分析所识别的语法成分变换为中间代码的语义翻译方法。
第二篇:编译原理实验报告1
03091337 李璐 03091339 宗婷婷
一、 上机题目:实现一个简单语言(CPL)的编译器(解释器)
二、功能要求:接收以CPL编写的程序,对其进行词法分析、语法分析、语法制导翻译等,然后能够正确的执行程序。
三、 试验目的
1. 加深编译原理基础知识的理解:词法分析、语法分析、语法制导翻译等
2. 加深相关基础知识的理解:数据结构、操作系统等
3. 提高编程能力
4. 锻炼独立思考和解决问题的能力
四、 题目说明
1. 数据类型:整型变量(常量),布尔变量(常量)
取值范围{…, -2, -1, 0, 1, 2, …}, {true, false}
2、运算表达式:简单的代数运算,布尔运算

3、程序语句:赋值表达式,顺序语句,if-else语句,while语句
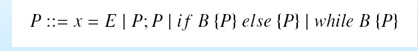
五、 环境配置
1. 安装Parser Generator、Visual C++;
2. 分别配置Parser Generator、Visual C++;
3. 使用Parser Generator创建一个工程
编写l文件mylexer.l;
编译mylexer.l,生成mylexer.h与mylexer.c;
4. 使用VC++创建Win32 Console Application工程并
配置该项目;
加入mylexer.h与mylexer.c,编译工程;
执行标识符数字识别器;
注意:每次修改l文件后,需要重新编译l文件,再重新编译VC工程
六、 设计思路及过程
l 设计流程:

l 词法分析
LEX的此法分析部分主要利用有限状态机进行单词的识别,在分析该部分之前,首先应该对YACC的预定义文法进行解释。在YACC中用%union扩充了yystype的内容,使其可以处理char型,int型,node型,其中Node即为定义的树形结点,其定义如下:
typedef enum { TYPE_CONTENT, TYPE_INDEX, TYPE_OP } NodeEnum;
/* 操作符 */
typedef struct {
int name; /* 操作符名称 */
int num; /* 操作元个数 */
struct NodeTag * node[1]; /* 操作元地址 可扩展 */
} OpNode;
typedef struct NodeTag {
NodeEnum type; /* 树结点类型 */
/* Union 必须是最后一个成员 */
union {
int content; /* 内容 */
int index; /* 索引 */
OpNode op; /* 操作符对象 */
};
} Node;
extern int Var[26];
结点可以是三种类型(CONTENT,INDEX,OP)。结点如果是操作符对象(OpNode)的话,结点可继续递归结点。操作符结点包括了名称,个数和子结点三个要素,其中子结点可以为多个。
在YACC定义的文法中将<iValue>与INTEGER,<sIndex>与VARIABLE绑定,表示对lex返回的值自动进行类型转换。
l YACC的语法分析和语义制导
在YACC中首先定义了与函数相关的文法和与运算相关的文法,其中函数定义的文法中可以处理if-else,if,while,print,x=exp;类型,在与运算相关的文法中可以处理+,-,*,/,>,<,>=,<=,!==,&&,||运算。在语义制导翻译部分主要目的是在内存建立一颗语法树来实现刚才所说的函数。扩展了set_index,set_value两个赋值语句,其操作实质是在内存空间分配index和value的两种树结点。opr这个扩展函数很重要,而且使用了动态参数,主要考虑操作符的操作元个数是可变的,这个也与头文件“struct NodeTag * node[1];”的定义思想一致。opr主要在内存空间中分配操作符相关的树结点。Set_index,set_value,opr从概念上是完全一致的,目的就是在内存中构造一颗可以递归的语法树。
程序代码
mylexer.l文件如下:
%{
#include <stdlib.h>
#include "node.h"
#include "myparser.h"
void yyerror(char *);
%}
%%
"/*"([^\*]|(\*)*[^\*/])*(\*)*"*/" ;
"while" {return WHILE;}
"if" {return IF;}
"else" {return ELSE;}
"print" {return PRINT;}
"false" {yylval.iValue = 0;
return INTEGER;
}
"true" {yylval.iValue = 1;
return INTEGER;
}
[a-z] {yylval.sIndex = *yytext - 'a';
return VARIABLE;
}
[0-9]+ {yylval.iValue = atoi(yytext);
return INTEGER;
}
[-()<>=+*/%;{}.] {return *yytext;}
">=" {return GE;}
"<=" {return LE;}
"==" {return EQ;}
"!=" {return NE;}
"<>" {return NE;}
"&&" {return AND;}
"||" {return OR;}
"!" {return NOT;}
[ \t\n]+ ; /* 去除空格,回车 */
. printf("unknow symbol:[%s]\n",yytext);
%%
int yywrap(void)
{
return 1;
}
myparser.y文件如下:
%{
#include <stdio.h>
#include <stdlib.h>
#include <stdarg.h>
#include "node.h"
/* 属性操作类型 */
Node *opr(int name, int num, ...);
Node *set_index(int value);
Node *set_content(int value);
void freeNode(Node *p);
int exeNode(Node *p);
int yylexeNode(void);
void yyerror(char *s);
int Var[26]; /* 变量数组 */
%}
%union {
int iValue; /* 变量值 */
char sIndex; /* 变量数组索引 */
Node *nPtr; /* 结点地址 */
}
%token <iValue> VARIABLE
%token <sIndex> INTEGER
%token WHILE IF PRINT
%nonassoc IFX
%nonassoc ELSE
%left AND OR GE LE EQ NE '>' '<'
%right NOT
%left '+' '-'
%left '*' '/' '%'
%nonassoc UMINUS
%type <nPtr> stmt expr stmt_list
%%
program:
function { exit(0); }
;
function:
function stmt { exeNode($2); freeNode($2); }
| /* NULL */
;
stmt:
';' { $$ = opr(';', 2, NULL, NULL); }
| expr ';' { $$ = $1; }
| PRINT expr ';' { $$ = opr(PRINT, 1, $2); }
| VARIABLE '=' expr ';' { $$ = opr('=', 2, set_index($1), $3); }
| WHILE '(' expr ')' stmt { $$ = opr(WHILE, 2, $3, $5); }
| IF '(' expr ')' stmt %prec IFX { $$ = opr(IF, 2, $3, $5); }
| IF '(' expr ')' stmt ELSE stmt %prec ELSE { $$ = opr(IF, 3, $3, $5, $7); }
| '{' stmt_list '}' { $$ = $2; }
;
stmt_list:
stmt { $$ = $1; }
| stmt_list stmt { $$ = opr(';', 2, $2, $1); }
;
expr:
INTEGER { $$ = set_content($1); }
| VARIABLE { $$ = set_index($1); }
| expr '+' expr { $$ = opr('+', 2, $1, $3); }
| expr '-' expr { $$ = opr('-', 2, $1, $3); }
| expr '*' expr { $$ = opr('*', 2, $1, $3); }
| expr '/' expr { $$ = opr('/', 2, $1, $3); }
| expr '%' expr { $$ = opr('%', 2, $1, $3); }
| expr '<' expr { $$ = opr('<', 2, $1, $3); }
| expr '>' expr { $$ = opr('>', 2, $1, $3); }
| expr GE expr { $$ = opr(GE, 2, $1, $3); }
| expr LE expr { $$ = opr(LE, 2, $1, $3); }
| expr NE expr { $$ = opr(NE, 2, $1, $3); }
| expr EQ expr { $$ = opr(EQ, 2, $1, $3); }
| expr AND expr { $$ = opr(AND, 2, $1, $3); }
| expr OR expr { $$ = opr(OR, 2, $1, $3); }
| NOT expr { $$ = opr(NOT, 1, $2); }
| '-' expr %prec UMINUS { $$ = opr(UMINUS, 1, $2); }
| '(' expr ')' { $$ = $2; }
;
%%
#define SIZE_OF_NODE ((char *)&p->content - (char *)p)
Node *set_content(int value)
{
Node *p;
size_t sizeNode;
/* 分配结点空间 */
sizeNode = SIZE_OF_NODE + sizeof(int);
if ((p = malloc(sizeNode)) == NULL)
yyerror("out of memory");
/* 复制内容 */
p->type = TYPE_CONTENT;
p->content = value;
return p;
}
Node *set_index(int value)
{
Node *p;
size_t sizeNode;
/* 分配结点空间 */
sizeNode = SIZE_OF_NODE + sizeof(int);
if ((p = malloc(sizeNode)) == NULL)
yyerror("out of memory");
/* 复制内容 */
p->type = TYPE_INDEX;
p->index = value;
return p;
}
Node *opr(int name, int num, ...)
{
va_list valist;
Node *p;
size_t sizeNode;
int i;
/* 分配结点空间 */
sizeNode = SIZE_OF_NODE + sizeof(OpNode) + (num - 1) * sizeof(Node*);
if ((p = malloc(sizeNode)) == NULL)
yyerror("out of memory");
/* 复制内容 */
p->type = TYPE_OP;
p->op.name = name;
p->op.num = num;
va_start(valist, num);
for (i = 0; i < num; i++)
p->op.node[i] = va_arg(valist, Node*);
va_end(valist);
return p;
}
void freeNode(Node *p)
{
int i;
if (!p) return;
if (p->type == TYPE_OP)
{
for (i = 0; i < p->op.num; i++)
freeNode(p->op.node[i]);
}
free (p);
}
void yyerror(char *s)
{
fprintf(stdout, "%s\n", s);
}
int main(void)
{
yyparse();
return 0;
}
定义结点如下:
union tagYYSTYPE {
int iValue; /* 变量值 */
char sIndex; /* 变量数组索引 */
Node *nPtr; /* 结点地址 */
};
extern YYSTYPE YYNEAR yylval;
在本程序中,还有自定义的头文件node.h如下:
typedef enum { TYPE_CONTENT, TYPE_INDEX, TYPE_OP } NodeEnum;
/* 操作符 */
typedef struct {
int name; /* 操作符名称 */
int num; /* 操作元个数 */
struct NodeTag * node[1]; /* 操作元地址 可扩展 */
} OpNode;
typedef struct NodeTag {
NodeEnum type; /* 树结点类型 */
/* Union 必须是最后一个成员 */
union {
int content; /* 内容 */
int index; /* 索引 */
OpNode op; /* 操作符对象 */
};
} Node;
extern int Var[26];
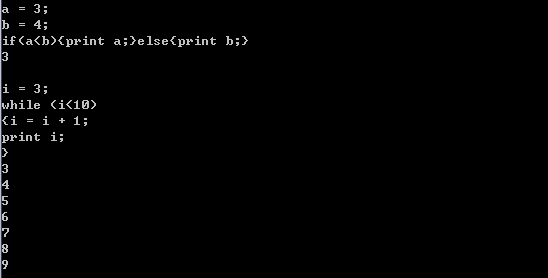
七、 运行结果及测试程序


-
编译原理实验报告
ltlt编译原理gtgt上机实验报告编译原理上机实验报告一实验目的与要求目的在分析理解一个教学型编译程序如PL0的基础上对其词法分…
-
《编译原理》课程实验报告(词法分析)完整版
编译原理课程实验报告题目专业计算机指导教师签名华东理工大学信息学院计算机系20xx年4月10日一实验序号编译原理第一次实验二实验题…
-
编译原理-词法语法分析实验报告
编译原理词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。二、实验要求2.1待分析的简单的词法(1)…
-
编译原理 实验报告
编译原理实验报告指导教师1一实验目的基本掌握计算机语言的词法分析程序的开发方法以及掌握计算机语言的语法分析程序设计与属性文法应用的…
-
编译原理实验报告完整版(河北工业)
编译原理实验报告班级姓名学号自我评定75实验一词法分析程序实现一实验目的与要求通过编写和调试一个词法分析程序掌握在对程序设计语言的…
-
会计实验报告
会计实验报告一、实验目的通过本实验,使学生能够掌握各种会计核算方法,真正领会各种方法在反映经济业务至报出会计信息这一过程中的内在联…
-
实验报告模板
编号20xx20xx学年第二学期实验报告实验课程名称会计学专业班级学号学生姓名实验指导教师浙江大学城市学院实验报告纸实验名称指导老…
-
综合化学实验实验一_华南师范大学实验报告
华南师范大学实验报告姓名组员课件密码30620学号实验题目二茂铁的绿色合成组别第四组实验时间20xx0320前言1实验目的了解一些…
-
中南大学近代物理实验报告-光泵磁共振实验报告
近代物理实验报告实验名称光泵磁共振实验指导老师黄迪辉班级物理升华1301学号0801130117姓名黄佳清1实验目的1观察铷原子光…
-
开放式电子电路实验报告
西安邮电大学开放式电子电路实验报告班级姓名学号班内序号实验名称放大器电路设计一实验目的1进一步理解三极管的放大特性2掌握三极管放大…