[转]Oracle10g数据库优化实用心得小结
[转]Oracle10g数据库优化实用心得小结
很 多的时侯,做Oracle DBA的我们,当应用管理员向我们通告现在应用很慢、数据库很慢的时侯,我们到数据库时做几个示例的Select也发现同样的问题时,有些时侯我们会无从 下手,因为我们认为数据库的各种命种率都是满足Oracle文档的建议。实际上如今的优化己经向优化等待(waits)转型了,实际中性能优化最根本的出 现点也都集中在IO,这是影响性能最主要的方面,由系统中的等待去发现Oracle库中的不足、操作系统某些资源利用的不合理是一个比较好的办法,下面把 我的一点实践经验与大家分享一下,本文测重于Unix环境。
一、通过操作系统的一些工具 检查系统的状态,比如CPU、内存、交换、磁盘的利用率,根据经验或与系统正常时的状态相比对,有时系统表面上看起 来看空闲这也可能不是一个正常的状态,因为cpu可能正等待IO的完成。除此之外我们还应观注那些占用系统资源(cpu、内存)的进程。
1、如何检查操作系统是否存在IO的问题?使用的工具有sar,这是一个比较通用的工具。

即每隔2秒检察一次,共执行20次,当然这些都由你决定了。
示例返回:

注:我在redhat下查看是这种结果,不知%system就是所谓的%wio
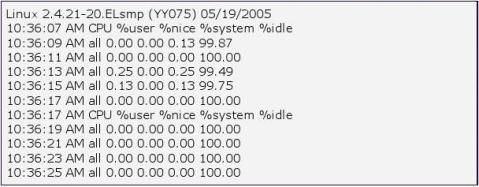
其中的%usr指的是用户进程使用的cpu资源的百分比,%sys指的是系统资源使用cpu资源的百分比,%wio指的是等待io完成的百分 比,这是值得我们观注的一项,%idle即空闲的百分比。如果wio列的值很大,如在35%以上,说明你的系统的IO存在瓶颈,你的CPU花费了很大的时 间去等待IO的完成。Idle很小说明系统CPU很忙。像我的这个示例,可以看到wio平均值为11说明io没什么特别的问题,而我的idle值为零,说 明我的cpu已经满负荷运行了。 当你的系统存在IO的问题,可以从以下几个方面解决
*联系相应的操作系统的技术支持对这方面进行优化,比如hp-ux在划定卷组时的条带化等方面。
*查找Oracle中不合理的sql语句,对其进行优化。
*对Oracle中访问量频繁的表除合理建索引外,再就是把这些表分表空间存放以免访问上产生热点,再有就是对表合理分区。
2、关注一下内存
常用的工具便是vmstat,对于hp-unix来说可以用glance,Aix来说可以用topas,当你发现vmstat中pi列非零, memory中的free列的值很小,glance,topas中内存的利用率多于80%时,这时说明你的内存方面应该调节一下了,方法大体有以下几项。
*划给Oracle使用的内存不要超过系统内存的1/2,一般保在系统内存的40%为益。 为系统增加内存
*如果你的连接特别多,可以使用MTS的方式
*打全补丁,防止内存漏洞。
3、如何找到点用系用资源特别大的Oracle的session及其执行的语句。
Hp-unix可以用glance,top
IBM AIX可以用topas
此外可以使用ps的命令。
通过这些程序我们可以找到点用系统资源特别大的这些进程的进程号,我们就可以通过以下的sql语句发现这个pid正在执行哪个sql,这个 sql最好在pl/sql developer,toad等软件中执行, 把<>中的spid换成你的spid就可以了。

我们就可以把得到的这个sql分析一下,看一下它的执行计划是否走索引,对其优化避免全表扫描,以减少IO等待,从而加快语句的执行速度。
提示:我在做优化sql时,经常碰到使用in的语句,这时我们一定要用exists把它给换掉,因为Oracle在处理In时是按Or的方式做的,即使使用了索引也会很慢。
比如:

可以换成:

4、另一个有用的脚本:查找前十条性能差的sql.

二、迅速发现Oracle Server的性能问题的成因,我们可以求助于v$session_wait这个视图,看系统的这些session在等什么,使用了多少的IO。以下是我提供的参考脚本:
脚本说明:查看占io较大的正在运行的session
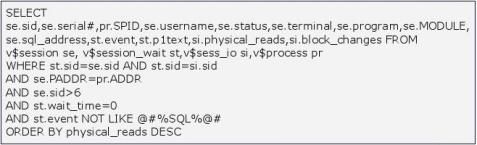
对检索出的结果的几点说明:

1、我是按每个正在等待的session已经发生的物理读排的序,因为它与实际的IO相关。
2、你可以看一下这些等待的进程都在忙什么,语句是否合理?
执行以上两个语句便可以得到这个session的语句。
你也以用alter system kill session @#sid,serial#@#;把这个session杀掉。
3、应观注一下event这列,这是我们调优的关键一列,下面对常出现的event做以简要的说明:
a、buffer busy waits,free buffer waits这两个参数所标识是dbwr是否够用的问题,与IO很大相关的,当v$session_wait中的free buffer wait的条目很小或没有的时侯,说明你的系统的dbwr进程决对够用,不用调整;free buffer wait的条目很多,你的系统感觉起来一定很慢,这时说明你的dbwr已经不够用了,它产生的wio已经成为你的数据库性能的瓶颈,
这时的解决办法如下:
a.1增加写进程,同时要调整db_block_lru_latches参数
示例:修改或添加如下两个参数

a、2开异步IO,IBM这方面简单得多,hp则麻烦一些,可以与Hp工程师联系。
b、db file sequential read,指的是顺序读,即全表扫描,这也是我们应该尽量减少的部分,解决方法就是使用索引、sql调优,同时可以增大db_file_multiblock_read_count这个参数。
c、db file scattered read,这个参数指的是通过索引来读取,同样可以通过增加db_file_multiblock_read_count这个参数来提高性能。
d、latch free,与栓相关的了,需要专门调节。
e、其他参数可以不特别观注。
结篇:匆忙之中写下了这篇文章,希望能抛砖引玉,能为你的Oracle调优实践带来帮助。 如何查询全表扫表:SQL> select name,value from v$sysstat where name like '%table scan%';
第二篇:Oracle10g优化
Oracle10g性能调整与优化 主要内容:收集性能数据、优化SQL语句和应用程序、调整共享池(Shared Pool)的性能、调整缓冲区高速缓存(Buffer Cache)的性能、调整重做有关的性能、共享(多线程)服务器(MTS)、调整磁盘I/O的性能、调整闩(latch)和锁定(lock)、调整操作系统。
第一章 收集性能数据
1. 报警(Alert)日志文件
报警(Alert)日志文件在c:\oracle\product\10.2.0\admin\erp\bdump目录下:文件名为alert_erp.log。
注意报警(Alert)日志文件中的错误信息:
ORA-01652:在临时表空间中没有足够的空闲空间来进行排序操作。 ORA-01653:在表空间中没有足够的空闲空间来存放表。
ORA-01650:在回退段所在的表空间中没有足够的空闲空间来使回退段增长。
ORA-01631:表所占用的空间超过允许的最大值。
Checkpoint Not Complete。
Snapshot too old。
后台进程跟踪文件:也在c:\oracle\product\10.2.0\admin\erp\bdump目录下。文件名类似于erp_lgwr_2548.trc、erp_arc0_2620.trc、erp_dbw0_3012.trc。
用户跟踪文件:
udump目录下:erp_ora_788.trc文件。其中788为该会话所对应的Server Process的编号,可以通过V$process查得。
设置用户跟踪
实例级跟踪:init.ora参数SQL_TRACE=TRUE。这种方法会产生大量的系统开销。
用户级跟踪:
SQl>alter session set sql_trace=true;
SQl>alter session set sql_trace=false;
DBA跟踪:
SQL>exec sys.dbms_system.set_sql_trace_in_session(10,87,true); SQL>exec sys.dbms_system.set_sql_trace_in_session(10,87,false); 10为会话编号,87为会话序列号。
限制用户跟踪文件的大小:init.ora参数 MAX_DUMP_FILE_SIZE。
2. 性能优化视图 v$sysstat:数据库启动以来的统计数据。 v$system_event:系统中所有会话发生过的等待事件。 v$sesstat:所有当前会话的统计数据。 v$session: 所有当前的会话。 V$session_event:已经发生过的等待事件。 V$session_wait:正在发生的等待事件。 V$sgastat:SGA内存的统计数据。 V$waitstat:对自由列表的争用。
3. 收集性能数据的程序:STATSPACK。
STATSPACK工具的使用
创建一个单独的表空间存放性能数据。大小300M左右。
注意:STATSPACK收集的是默认数据库的数据。
用管理员SYS用户登录。
SQL> @ c:\oracle\product\10.2.0\db_1\rdbms\admin\spcreate.sql
用PERFSTAT用户登录。
SQL>execute STATSPACK.SNAP;
至少要有两个快照。
用PERFSTAT用户登录,生成报告文件:
SQL> @ c:\oracle\product\10.2.0\db_1\rdbms\admin\spreport.sql
4. 图形性能工具(WEB方式)
第二章 优化SQL语句和应用程序
1. 测量SQL语句的性能
Tkprof(Trace Kernel Profile)工具的使用
功能:测量SQL语句的性能。
c:\> tkprof
c:\oracle\product\10.2.0\admin\ERP\udump\erp_ora_1436.trc c:\bao.txt sys=no
sys=no的含义:不包含递归SQL语句(即访问数据字典的隐含语句)
SQL语句的处理要经过三个阶段:Parse、Execute、Fetch。 需要优化的SQL语句:
占用过多的CPU时间。
Parse、Execute、Fetch阶段的时间太长。
从磁盘读太多的数据块,而从内存中读很少的数据块。
访问许多数据块,但只返回几条数据。
Top SQL 的使用(WEB方式)
Top SQL用来代替Tkprof。
Top SQL可以找出哪些SQL语句的性能差,需要优化。
Top SQL 中的数据来源于V$SQL。
Top Sessions的使用(WEB方式)
Top Sessions可以找出哪些会话占用较多的资源。
2. SQL语句的解释计划(EXPLAIN PLAN)
通过解释计划,可以找出SQL语句性能低的原因。
用SQL ScratchPad来生成SQL语句的解释计划:
用命令来生成SQL语句的解释计划:
先检查sys用户下是否有plan_table表(9i中已经有了这个表),如果没有,执行
SQL〉@C:\oracle\product\10.2.0\db_1\rdbms\admin\utlxplan.sql脚本。
SQL>explain plan for SELECT e.empno, e.ename, d.deptno, d.loc FROM scott.emp e, scott.dept d WHERE e.deptno = d.deptno; 注意要commit。
查询执行计划:
SQL>select lpad(' ',4*(level-2)) || operation || ' ' || options || ' ' || object_name "EXECUTION_PLAN" from plan_table start with id =0 connect by prior id = parent_id;
3. STATSPACK报告中的SQL语句性能
SQL ordered by Gets(按Gets排序的SQL语句)
SQL ordered by Reads(按Reads排序的SQL语句)
SQL ordered by Executions(按Executions排序的SQL语句) SQL ordered by Parse Calls(按Parse Calls排序的SQL语句
4. Oracle优化方式
优化方式:基于rule和cost.
基于rule时的优化等级:根据语法和表结构优化
1 Single row by rowid
2 Single row by cluster join
3 Single row by hash cluster key with unique or primary key 4 Single row by unique or primary key
5 Cluster join
6 Hash cluster key
7 Indexed cluster key
8 Composite key
9 Single-column indexes
10 Bounded range search on indexed columns
11 Unbounded range search on indexed columns
12 Sort-merge join
13 MAX or MIN of indexed column
14 ORDER BY on indexed columns
15 Full table scan
以 SELECT empno FROM emp WHERE ename = 'CHUNG' AND sal > 2000;语句为例说明访问路径 。分析应在哪个字段上创建索引?
缺点:小表的全表扫描比索引效率高,索引字段值的差异性小。
基于cost时的优化根据表和索引的统计信息优化,优先采用。
根据表和索引的统计信息包括:
每个表或索引的大小。
每个表或索引所包括的数据行数。
每个表或索引所使用的数据块数量。
每个表行的字节数。
索引字段值的差异性(基数)。
5. 统计信息的创建
SQL> ANALYZE TABLE employee COMPUTE STATISTICS;
SQL> ANALYZE INDEX employee_last_name_idx COMPUTE STATISTICS;
查询统计信息,可用图形界面或DBA_TABLES。
SQL> ANALYZE TABLE employee DELETE STATISTICS;
如果表或索引的数据量很大时,可以使用样本来创建统计信息: SQL> ANALYZE TABLE employee ESTIMATE STATISTICS;
默认的样本大小为1064行。
SQL> ANALYZE TABLE employee ESTIMATE STATISTICS
SAMPLE 500 ROWS;
SQL> ANALYZE TABLE employee ESTIMATE STATISTICS
SAMPLE 35 PERCENT;
创建字段的统计信息:
SQL> ANALYZE TABLE employee ESTIMATE STATISTICS
FOR COLUMNS employee_id SIZE 200;
SIZE的默认值是75。可以是1到254。
字段上的数据假设是正态分布。
直方图:SQL> ANALYZE TABLE finaid COMPUTE STATISTICS FOR COLUMN award SIZE 100;
用图形界面创建统计信息。
优化提示:SQL> SELECT /*+ FIRST_ROWS */ * FROM hr.employees;
其它优化提示有:RULE、FULL SALES(访问SALES表)、 INDEX SALES_ID_PK、PARALLEL。
6. 设置优化模式
init.ora参数OPTIMIZER_MODE:
CHOOSE、RULE、FIRST_ROWS(提高响应时间)、ALL_ROWS(提高吞吐量)。
7. 索引
B-树索引: 适合建在重复值少的字段。
索引的统计信息,索引B-树的高度(建议<4)。
SQL> ANALYZE INDEX employee_last_name_idx VALIDATE STRUCTURE;
SQL> SELECT (DEL_LF_ROWS_LEN/ LF_ROWS_LEN) * 100 “Wasted Space” FROM index_stats WHERE NAME= “EMPLOYEE_LAST_NAME_IDX” ;
建议:索引的空闲空间(<20)。
重组索引:
SQL> alter index scott.pk_dept rebuild online;
SQL> alter index scott.pk_dept coalesce;
压缩B树索引:适合于索引字段重复值多的情况
SQL>ALTER INDEX employee_last_name_idx REBUILD COMPRESS;
位图(bitmap)索引:适合建在于重复值多的字段。
位图索引不适合于建在频繁进行insert、update和delete的表上。这些操作的性能代价太高。位图索引适合于数据仓库和DSS。
优化位图索引的init.ora参数:SORT_AREA_SIZE、PGA_AGGREGATE_TARGET。
淘汰的init.ora参数:CREATE_BITMAP_AREA_SIZE、BITMAP_MERGE_AREA_SIZE。
函数索引
必须要把init.ora参数QUERY_REWRITE_ENABLE设成TRUE,才能创建函数索引。
SQL>SELECT last_name,first_name FROM employees
WHERE UPPER(first_name)=?SMITH?;
SQL> CREATE INDEX hr.employee_first_name_upper_idx ON hr.employees(UPPER(first_name));
SQL> SELECT * FROM sales where (price * units) > 10000; SQL> CREATE INDEX sales_total_sale_idx
ON sales (price * units) TABLESPACE INDX;
反键索引:适用于序列字段。
反键索引只适用于=和!=查询。使用Between、>、< 查询不会使用反键索引优化。
8. 优化应用程序
索引组织表(IOT)
分区表
簇:索引簇和散列簇。
9. 使用 SQL Analyze(对9i适用)
例子:SELECT department_name, department_id
FROM hr.departments WHERE department_id NOT IN (SELECT department_id FROM hr.employees)
使用Index Tuning Wizard。
10. 并行查询
并行查询可以优化:表扫描、join语句、sort、not in、group by、select distinct、union and union all 、aggregation、PL/SQL functions 、order by 、create table as select 、create index 、rebuild index 、insert ... select、enable constraint、cube、rollup。
用在多CPU和磁盘阵列。
表和索引的并行度。
ALTER TABLE emp PARALLEL 4;
ALTER INDEX iemp PARALLEL;
SELECT /*+ PARALLEL(emp,4) */ COUNT(*) FROM emp ;
调整开发系统和生产系统。
应用程序、SQL、内存、I/O、锁定、OS。
第三章 调整共享池(Shared Pool)的性能
1. 监视共享池的性能
共享池由library cache和dictionary cache组成。采用LRU(Least Recently Used)算法管理。library cache用于缓存执行的SQL语句和PL/SQL程序。dictionary cache用于缓存数据字典。
共享池有关的数据字典:V$SQL、V$SQLAREA、V$SQLTEXT、V$SQL_PLAN。(V$session)。
测量library cache的命中率:V$librarycache
SQL>select namespace,gethitratio,pinhitratio,reloads,invalidations from v$librarycache where namespace in (?SQL AREA?,?TABLE/PROCEDURE?,?BODY?,?TRIGGER?);
SQL AREA部分的gethitratio 、pinhitratio要 > 90%。
GETS(语法分析)。
PINS(执行)。
RELOADS(SQL语句需要重新语法分析)、
INVALIDATIONS(SQL语句所引用的表结构发生变化,或视图重新编译)。
select SUM(reloads)/SUM(pins) “Reload Ratio” from V$librarycache;
重新装载率Reload Ratio要 < 1%。
使用STATSPACK来监视library cache。
使用REPORT.TXT来监视library cache。
使用Performance Manager(内存、数据库例程、SQL)来监视library cache。
SGA内存的经验公式。
SGA= 55% 物理内存
Shared Pool = 45% SGA
Buffer cache = 45% SGA
Redo Log Cache = 10% SGA
测量dictionary cache的命中率:V$rowcache
select 1- (SUM(getmisses)/SUM(gets)) “Data Dictionary Hit Ratio” from V$rowcache;
“Data Dictionary Hit Ratio”的值要 > 85%。
使用STATSPACK来监视dictionary cache。
使用REPORT.TXT来监视dictionary cache。
2. 提高共享池性能的方法
加大共享池的大小:init.ora参数shared_pool_size(动态参数)。注意参数sga_max_size。
为大型PL/SQL程序设置保留内存:防止其它SQL语句从内存中移走。 init.ora参数SHARED_POOL_RESERVED_SIZE(建议值:10% shared_pool_size)。
销定(Pin)程序:DBMS_SHARED_POOL.KEEP(‘deposit’)。 鼓励代码重用:在SQL语句中使用变量。
例如:SELECT * FROM EMP WHERE ename = ?Smith?; SELECT * FROM EMP WHERE ename= ?John?; 改写为:
v_ename = ?Smith?;
Select * from emp where ename =v_ename;
v_ename = ?John?;
Select * from emp where ename =v_ename;
调整共享池有关的init.ora参数
OPEN_CURSORS:建议值500。
CURSOR_SPACE_FOR_TIME:建议值TRUE。
SESSION_CACHED_CURSORS:建议值TRUE。
CURSOR_SHARING:默认值为EXACT。建议设成SIMILAR或FORCE。
第四章 调整缓冲区高速缓存(Buffer Cache)的性能
1. Buffer Cache的工作原理
Buffer Cache由数据块组成。
LRU列表:MRU ??????. LRU。(全表扫描FTS放在LRU端。) 缓冲区块的状态:Free、Pinned、Clean、Dirty。
Dirty List或Write List(写列表)。
数据库写进程DBW0将缓冲区高速缓存中的数据写到数据文件中。
2. 测量Buffer Cache的性能
测量Buffer Cache的命中率:
SQL> select 1-((physical.value – direct.value – lobs.value)/logical.value) “Buffer Cache Hit Ratio” from V$SYSSTAT physical, V$SYSSTAT direct,V$SYSSTAT lobs, V$SYSSTAT logical where physical.name = ?physical reads?
And direct.name = ?physical reads direct? and
lobs.name = ?physical reads direct (lob)?
And logical.name = ?session logical reads?;
“Buffer Cache Hit Ratio”的值要 > 90%。
使用STATSPACK来监视Buffer Cache。
使用REPORT.TXT来监视Buffer cache。
非命中率指标:Free Buffer Inspected。(V$sysstat)
Free Buffer Waits、Buffer Busy Waits。(V$system_event)
3. 提高缓冲区高速缓存性能的方法
加大Buffer Cache的大小:init.ora参数DB_CACHE_SIZE(动态参数)。
使用Buffer Cache Advisory功能决定Buffer Cache的大小:
首先将init.ora参数DB_CACHE_ADVICE设成ON,然后查询V$DB_CACHE_ADVICE。
使用多个缓冲区池:
Keep Pool: DB_KEEP_CACHE_SIZE
Recycle Pool:DB_RECYCLE_CACHE_SIZE
Default Pool: DB_CACHE_SIZE
在内存中缓存表: 表的CACHE选项,对优化小表的全表扫描。
正确创建索引。
4. 调整Large Pool和JAVA POOL
Large Pool用于共享服务器、RMAN、并行查询、DBWR的从属进程。 Large Pool的大小通过init.ora参数Large_pool_size设置。默认为8M。 从V$sgastat中监视free memory的值:
SQL>SELECT name,bytes FROM V$sgastat WHERE pool = ?large pool?;
JAVA_POOL池的默认大小为32M。对于大型Java应用程序,JAVA_POOL池的大小应大于50M。
init.ora参数java_pool_size
从V$sgastat中监视free memory的值。
SQL>SELECT name,bytes FROM V$sgastat WHERE pool = ?java pool?;
第五章 调整重做有关的性能
Oracle重做有关的组件包括:Redo Log Buffer、Online Redo Log、LGWR、
Archive Log、Checkpoint、Arch0。
1. 监视Redo Log Buffer的性能
Redo Log Buffer不采用LRU(Least Recently Used)算法管理。 当下列事件发生时,Redo Log Buffer的内容存盘:
Commit时、每3秒、空间使用1/3、达到1M、检查点。
如果写入Redo Log Buffer的速度超过LGWR存盘的速度,就会因等待而降低性能。
监视Redo Log Buffer的重试率(<1%)。
Select retries.value/entries.value “Redo Log Buffer Retry Ratio” From V$sysstat retries, V$sysstat entries
Where retries.name = ?redo buffer allocation retries?
And entries.name = ?redo entries?;
“Redo Log Buffer Retry Ratio”的值要 < 1%。
Select name,value from V$sysstat where name=?redo log space requests?;
如果该值大,需要增加Redo Log Buffer。
2. 提高Redo Log Buffer的性能
增加Redo Log Buffer的大小:init.ora参数log_buffer。
减小重做日志的生成量。(如果设置表的NOLOGGING属性,下列操作不记录在Online Redo Log中:用SQL* Loader的直接路径加载。 NOLOGGING属性还可用于下列SQL语句:CREATE TABLE AS SELECT、CREATE INDEX、ALTER INDEX REBUILD、CREATE TABELSPACE)。
3. 调整检查点进程的性能
两个事件:checkpoint completed、log file switch(checkpoint incomplete)。
Select * from V$sysstat。
background checkpoints started和background checkpoints completed。
使用Alert日志来记录检查点进程 :init.ora参数log_checkpoint_to_alert。
使用Performance Manager来测量检查点进程的性能:I/O中的平均灰数据队列长度(如果为0,说明检查点太频繁)。
建议调整online redo log的大小,使检查点进程每20-30分钟执行一次。
4. 调整联机重做日志文件
使用V$system_event来监视联机重做日志文件的性能:
log file parallel write、log file switch completed。
调整联机重做日志文件的方法:与数据文件、控制文件、归档日志文件分开,放在原始设备上。
5. 调整归档性能
检查归档进程的性能:通过V$system_event中的log file switch(archiving needed)事件。
检查每个归档进程的状态:V$archive_processes。
创建多个归档进程:init.ora参数LOG_ARCHIVE_MAX_PROCESSES(默认为2)。
第六章 调整磁盘I/O的性能
哪些操作会导致磁盘I/O:
将Buffer cache中的内容写到数据文件。
写回退段。
将数据文件的内容读到Buffer cache中。
将Redo log Buffer中的内容写到online redo log中。
将online Redo log中的内容归档到 archive log中。
1. 调整表空间和数据文件
测量数据文件I/O:使用V$filestat。
使用STATSPACK来测量数据文件I/O。
使用REPORT.TXT来测量数据文件I/O。
使用Performance Manager(I/O)来测量数据文件I/O。
建议:
不要在SYSTEM表空间存放用户数据。
将 I/O操作均分到几个数据文件上。(监视数据文件的I/O操作数。) 使用本地管理的表空间。
将数据库文件与其它程序的文件分开。
使用分区表和分区索引。
将大表放在单独的表空间。
创建单独的回退表空间。
创建一个或多个临时表空间。
不要将联机重做日志文件和归档联机重做日志文件放在同一个设备上。 至少将一个控制文件放在一个单独的设备上。
检查V$sysstat中的’table scans(long tables)’。
使用init.ora参数DB_FILE_MULTIBLOCK_READ_COUNT(默认为16)
来优化表扫描。
2. 调整DBW0性能
监视DBWR0性能。
使用V$system_event监视下列事件:buffer busy waits、free buffer waits、
db file parallel write、write complete waits、
使用init.ora参数DBWR_IO_SLAVES(优化磁盘I/O)、
DB_WRITER_PROCESSES(默认为1,优化Buffer Cache的内部管理)。 如果DBWR_IO_SLAVES设为非0值,DB_WRITER_PROCESSES的值无效。
3. 调整段I/O
避免动态空间分配。
表的有关存储特性
空闲百分比(PCTFREE):每个对象数据块中为今后更新该对象而保留的空间的百分比。可以输入0到99之间的值。默认值为10%。
已用百分比(PCTUSED):Oracle数据库为该对象的每个数据块保留的已用空间的最小百分比。当一个块的已用空间低于“已用百分比”的值时,则该块将成为插入行的目标。可以输入1到99之间的值。默认值为40%。
最小数量:创建段时已分配的总区数。默认值为1。可以输入1或大于1的值。
SQL> alter table emp allocate extent ;
事务处理数量
初始值:在分配给该对象的每个数据块内分配给事务处理条目的初始数量。可以输入1或2(对于簇和索引)到255之间的值。
最大值:可同时更新分配给对象的数据块的并行事务处理的最大数量。可以输入1到255之间的值。
自由表
列表:表、簇或索引的每个自由表组的自由表数量。可以输入1或大于1的值。默认值为1。
组:表、簇或索引的自由表组的数量。可以输入1或大于1的值。默认值为1。
缓冲池。
行转移(更新行时超过块的可用空间)和行链接(行的大小超过块的大小)的概念。
使用V$sysstat来监视行转移和行链接:table fetch continued row。
SQL>analyze table emp compute statistics;
使用DBA_TABLES来查询统计信息。
SQL> alter table emp deallocate unused;
SQL> alter table scott.emp move tablespace users;
表的高水位标志High Water Mark(HWM)。
1M 10M 100M
4. 调整排序IO
哪些SQL语句需要排序操作:order by、group by、select distinct、union、 intersect、minus、analyze、create index、联接。
V$sysstat。内存排序和磁盘排序(临时表空间中)。
监视排序性能(内存排序比例>95%)。
使用init.ora参数SORT_AREA_SIZE(512K)、SORT_AREA_RETAINED_SIZE、
pga_aggregate_target、WORKAREA_SIZE_POLOCY。
如何避免排序:SQL语法、正确索引、创建索引、ANALYZE。 v$sort_segment、v$sort_usage。
5. 优化回退段
一个回退段的区间可以分配给多个事务,回退段的一个数据块只能分配给一个事务。
测量回退段事务表的争用
select * from V$system_event where event like ?%undo%?;
回退段事务表的等待时间应接近于0。
select * from V$waitstat;
V$rollstat
回退段事务表访问的成功率应>95%。
回退段区间争用
V$waitstat、V$sysstat。
回退段事务环绕(Wrap):一个事务占用的回退段从一个区间扩展到另一个区间。
回退段的动态区间分配
V$system_event。
使用V$rollstat来监视回退段的使用情况。
使用Performance Manager(后台进程)来测量回退段。
提高回退段的性能
Oracle10g中的撤消表空间。
建议:每四个事务使用一个回退段,最多不超过20个回退段。 会退段的区间大小512k,最小区间数20。
明确分配回退段给事务。
SQL> set transaction use rollback segment rbs01;
最小化回退段活动:EXPORT、IMPORT、SQL* Loader时加commit=y参数。
Oracle10g中的撤消表空间。
第七章 共享(多线程)服务器(MTS)
1. 共享服务器(用户数>200)
SP1 SP2 SP3 SP10
Dispatcher1 2 …….
UP1 UP2 UP3 ……………….. UP100
dispatchers、max_dispatchers(5)、shared_server(1)、
max_shared_server(20)。Sessions(170)、circuits(170)。mts开始的参数已被淘汰。
共享服务器的联接不能关闭和启动数据库。
客户端的联接方式。(SERVER=DEDICATED)
SQL>alter system set MTS_SERVERS=5;
测量共享服务器的性能
V$shared_server、V$queue 是否需要生成更多的Shared Server进程。
V$dispatcher 是否需要增加更多的 Dispatcher进程。
Net8的高级配置
多路复用:此功能允许通过单个传输协议连接以集中方式多路传送多个客户网络会话。
连接共享(连结池):(释放物理连接,保持逻辑连接)。
入网连接超时(以 秒 记)
超时(以 秒记),用于入网网络连接。如果指定超时的数值为0,则使用缺省值(10 秒)。
第八章 调整闩(latch)和锁定(lock)
1. 调整闩(latch)
闩可以作为内存性能的另一个指标。
1.闩:等待闩和立即闩(V$lacth。共239个)。
数据库中是否存在闩争用V$system_event("latch free")。
几个重要的闩:shared pool、library cache、cache buffers lru chain、 cache buffers chains、redo allocation、redo copy。
select * from V$latch where misses!=0;
2.自由列表:V$system_event("buffer busy waits")。
V$waitstat。
测量哪些段存在自由列表争用:dba_segments、V$session_wait。 alter table scott.emp storage (freelists 5);
自动段空间管理的表空间。
2. 调整锁定
DML锁(TM)和DDL锁(TX)
事务。
其它。
自动。
1.update t1 2. drop table t1
2.update t1 2. select t1
3.update t1 2. update t1
锁定模式:
RX:对表UPDATE、INSERT、DELETE时获得。
RS:对表SELECT ? FOR UPDATE时获得。
S: LOCK TABLE EMP IN SHARE MODE; 可以是多个用户获得。 SRX: LOCK TABLE EMP IN SHARE ROW EXCLUSIVE MODE; 只能是一个用户获得。V$LOCK;
外键约束时的锁定。死锁。
第九章 调整操作系统
1. 调整操作系统
观察内存和CPU利用率(<90%)。
2. 使用Resource Manager
资源使用者组。一个用户可以是多个资源使用者组的成员,但一次只有一个组是活动的。
确定用户的CPU利用率。(v$sesstat和v$sysstat)
资源计划:由资源计划指令组成。一次只能有一个资源计划是活动的(V$rsrc_plan)。
alter system set resource_manager_plan=system_plan;
select username,RESOURCE_CONSUMER_GROUP from V$session;
子计划。
资源计划调度。
-
Oracle数据库心得体会
学习Oracle数据库的心得体会对于学习Oracle数据库,应该先要了解Oracle的框架。它有物理结构(由控制文件、数据文件、重…
-
达内学习心得:oracle数据库笔记
达内学员oracle数据库笔记获奖学员王梓祺所获奖项三等奖内容前言这份资料是结合老师笔记课堂案例TTS60课件以及个人的理解整理时…
-
Oracle数据库学习总结
Oracle数据库学习总结1setlinesizexx设置行间距常用数值有1002003002setpagesizexx设置每页显…
-
oracle数据库个人小结
OracleSQL4GL第四代语言struncturedquerylanguage结构化的查询语言将数据放入Database数据库…
-
oracle数据库学习笔记心得
select字段表名from表名where布尔表达式条件externalcandidate职员相关信息contractrecrui…
-
Oracle数据库心得体会
学习Oracle数据库的心得体会对于学习Oracle数据库,应该先要了解Oracle的框架。它有物理结构(由控制文件、数据文件、重…
-
Oracle单机数据库安装学习总结
单机数据库学习总结一、Linux安装1、设置光盘启动,启动Linux的安装系统,根据提示一步步安装,创建分区时选择ext3和swa…
-
Oracle数据库管理系统实习总结
Oracle数据库管理系统实习总结学习完oracle数据库后,我们进行了一次大实习,实习是分组进行的,我们组根据老师的安排,采用O…
-
学习Oracle数据库-Linux操作系统心得体会 腾科 杭州
最初开始接触Oracle数据库是在20xx年刚上大一的时候,因为当时所学的专业偏向于数据库方向。学的第一门课是数据建模,接着是SQ…
-
oracle数据库学习总结(一)
oracle数据库学习总结基础一ORACLE中字段的数据类型1字符型1char范围最大20xx个字节定长char1039张三39后…
-
数据库实验心得体会
有关于数据库实验的心得体会,总的来说,受益匪浅。在这些天中,我们学到了很多东西,包括建表,导入数据,查询,插入。最重要的是我们有机…