对SPSS,AMOS的总结分析
对SPSS,AMOS的总结分析
作者:spssman 来源:【整理】 发布时间:20##-5-5 浏览: 121 访问者: 58.23.96.242

近段时间以来,我对SPSS11.0 SPSS16.0 AMOS16.0进行了较为系统的理论和技能的学习,可以说受益匪浅。咨将学习过程中的体会总结之,如下:
一. 对SPSS而言,可以说是一个十分强大的统计工具,里面的任何一个菜单都可以完成诸多任务。如果想掌握整个SPSS操作功能的话,可以说难度很大。当然都学下来也没有必要,我们只要掌握所需要用到的即可。对于心理学和社会学而言,主要学习下面的操作:(1)参数检验:单样本、两独立样本、配对样本(2)方差分析:单因素、多因素、协方差分析(3)非参数检验:X2 、二项式分布、K—S检验(4)相关分析和线性回归分析(5)聚类分析(6)因子分析(7)信度分析。以上的内容是我们经常用到的,尤其是相关分析和线性回归分析。
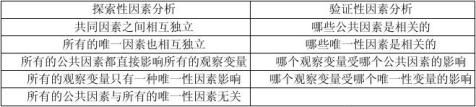
当然我主要学习的是SPSS中的探索性因素分析。所谓探索性因素分析其实就是尝试找出某事物中最能代表其本质的因素。因素可以是一个,两个或者多个。因素的个数可以人为规定也可以由系统自动生成,软件会自动将相似的题目数划到同一因素下。但是不管是人为决定因素的个数还是系统自动生成,其最大的目的就是为了尽可能找到特征根值大于1的因素数以及找到方差的最大贡献率,一般而言大于50%就认为不错了。(1)首先我要讲到的是探索性因素分析中对正交旋转和斜交旋转选择的问题。在这个问题上,各家的看法也不太一致。比较有代表性的是李茂能一般会采用斜交中的Promax法,其解释是为了简化结构,使项目与因素间达到较高的因素负荷;而张文彤则主张采用正交旋转法,其解释是斜交旋转的结果太容易受研究者主观意愿的左右,故一般采用正交旋转。我想正交相对斜交而言,前者能够最大的保持因子的不相关性,这点很重要。从我所看过的硕士论文中,用正交的相对来说比较多,所以建议还是采用正交旋转会更好一些。(2)其次,就是对正交旋转下最大变异法(Varimax)和极大相等法(Equanmax)的选择。前者的特点是能够导致第一个因素的负荷量过大,而后者则是平均分配几个因子的负荷量,当然这也要考虑你的研究目的了。不过从使用的频次和哈师大崔洪弟老师的建议还是采用Varimax法的居多。(3)最后一点我要提的就是在编制问卷过程中试题的删减标准,以下几点是我总结的,错误之处希望大家给予指正:①理论上的语义分析。②鉴别度和难度的判断,一般而言要大于0.3。③项目与总分的相关,应大于0.3.④项目的负荷量。视样本大小而定,一般大于0.4.⑤一般横跨两个因素或空白的项目也要删除,这一点我是在李茂能的书上看到的。
二、 对AMOS16.0的使用。初学AMOS给人耳目一新的感觉,尤其是相对LISREL枯燥的编程而言,AMOS的主动操作更是增大了使用者的便捷性和趣味性。AMOS是线性结构方程的一种,其操作方法也就是验证性因子分析,其涵义即为对理论模型和现实数据拟合程度的一种再分析。其版本经历了AMOS4.0 AMOS6.0 AMOS9.0和AMOS16.0,目前我使用的便是当前最新的版本。(1)首先做验证性因素分析重要的就是前期模型的假设,即构建显变量和潜变量之间的关系。将可能的关系罗列出来,并在模型中予以表示。(2)关于拟合指标的选择。结合李茂能、侯杰泰和所见到的论文,用到的比较多的拟合指标如下:X2/df、RMR RMSEA GFI AGFI AIC CAIC NFI TLI(NNFI)和CFI。其中X2/df一般在1~3左右波动,越小越好。RMR RMSEA均小于0.05,模型拟合的较好;GFI AGFI NFI TLI(NNFI)和CFI均大于0.9,模型拟合的比较好。(3)关于问卷编制中试题的删减标准,以下几点是我自己总结而得,错误之处希望大家给予指正:①在标准化下,看其因子中的负荷。若小于0.3则考虑删除,同时也要参考下MI值。②若MI值中两误差的指数很高的话,找到两误差对应的题目原题,看一下相关,若相关高,则删除其中一题,这是崔老师在课上讲到的,原文出处我没有找到。③以上过程不断的重复,修正和删除,直至模型拟合的的较好。注意一点就是理论上一定要通,不能仅仅根据数据数值而定。(4)最后我要提的就是在SEM中对中介变量和调节变量的检验。由于国内相关研究并不多,但是AMOS却是一个极好利用的工具。我想随着统计工具的普及,对三变量中介和调节关系的研究也会逐渐多起来。
以上只是简要叙述了SPSS,AMOS的使用后的感受,里面涉及的内容还有很多。下面介绍几本比较好的这方面的书籍。SPSS方面比较好的是张文彤的《SPSS统计分析高级教程》,张本的语言很幽默,特点就是操作性强,每步的操作都有详细的介绍,很适合上机演练。对每个菜单都有较为详细的叙述,当然缺点便造成了对每一个功能的介绍并不够深入。另外一本是薛薇的SPSS统计软件的应用,可以说是本SPSS的入门书,浅显易懂,最大的特点就是书后附了张数据光盘,可以在电脑上实时练习,是初学SPSS的不错选择。
对AMOS的书,容易买到的应该是侯杰泰的《结构方程模型及应用》是很好的一本书,可以作为SEM的入门书,不过书中的软件是以LISREL来运行的;如果想学AMOS的话,台湾李茂能的《结构方程模式软体AMOS之简介及其在测验编制上之应用:Graphics&Basic》,这本书编写的非常好,算是很详细的一本书了,可惜的是大陆这本书可能并不多。学习时主要参考以上两本书来进行的。
另外有对中介和调节变量感兴趣的同学可以参见近几年温忠麟和侯杰泰在《心理学报》上发表的相关文章。想这以后必将是心理学研究的一个热点。
问:
AMOS与SPSS到底有哪些区别
答:
如果你对统计知识一点都不懂的话还是最好看看基础的统计学,任何软件都只是一个工具,还要你自己有统计知识。
软件还是用SPSS比较简单,只要你会点就可以了至于AMOS他是一个做路径分析、结构方程比较常用的软件,建议用SPSS,一般的统计都能做。
SPSS是探索性统计分析软件,AMOS是验证性统计分析软件。
做探索性因素分析时用SPSS,探索性因素分析完成后,为了验证所得到的因子结构是否合理,就需要进行验证性因素分析。现在的论文如果涉及因子分析的话,大多要求进行验证性因素分析,以及路径分析等等。这时候,AMOS就派上用场了,AMOS可以进行验证性因素分析、路径分析、群组分析等等
第二篇:SPSS学习总结
SPSS学习总结
第一部分 数据处理
1.1数据输入
直接输入:spss
间接输入: excel 记事本 edit
1.2数据检查
简单检查:排序观察
极端值处理:两个标准差之外的剔除
缺失值处理:transform(T)替换缺失值(V)处理
1.3数据整理(不同年龄组在题项总分上的情况)
文件类的筛选
数据分组 splite file
数据选择处理 select case
新变量的生成 compute variable(函数的使用), add variable ,recode 行列转置 transpose
文件间的合并
Merge files
第二部分 描述性统计
2.1非连续变量的描述统计
直条图 Bar
馅饼图 Pie
2.2连续性变量的统计
频率菜单 Frequencies:Statistics ,Charts
描述菜单 Descriptive:Option ,标准分数
探索菜单 Explore:Statistics,Plots,Q-Q,Tests of Normality(P<0.05),Test of Homogenenity(P>0.05)
直方图 Histogram
峰度系数Kurtosis α=0 正太峰,α>0 高狭峰,α<0 低阔峰。 偏度系数Skewness Sk=0 对称,Sk>0 正偏态 ,Sk<0 负偏态。
2.3数据正态性检验
P-P 概率
Q-Q 概率单位
第三部分 数据分析
3.1信度分析
引入:(问卷)α系数 重测信度 分半信度
分类:外在信度 内在信度
标准:> 0.9表示信度良好 >0.7最小可以接受值 当然应结合具体实际 操作:Scale→Reliability :Model, Statistics (scale if item deleted)
3.2方差分析
引入:T检验的不足(一类错误增加)减少比较
逻辑:组间差异 组内差异 组间差异/组内差异判断各组差异的显著性 公式:
变异来源 组间(处理) 组内(误差)
全体
离均差平方和(SS) 自由度(df)
SSb SSw SSb
K-1 N-k N-1
均方(MS) MSb=SSb/(K-1) MSw=SSw/(N-k)
F值 MSb/MSw
基本假定:正态性(normality), 随机抽样(randomized),独立性(independnt),方差同质性(homogeneity)<P>0.05>。 事前比较:验证性数据分析 事后比较:探索性数据分析 操作:<P<0.05>
One-way ANOVA 单因子变异数分析法
Scheffe 各组人数不相等 控制总体a值控等于0.05 较为保守 Turkey 成对组比较 制总体a值等于0.05 监测个别差异较为敏感
GLM 一般因子分析法 (在样本量很大的情况下,更具有实际意义)
关联强度 W*W=SSb-(k-1)*MSw/SSt+MSw
解释变异量 <6%(微弱)6%~16%(中度)>16%(强度) Post Hoc Option 结果中(Eta Squared关联强度) 3.3项目分析
引入要实现区分度,或者整个项目的(分级)意义
临界比例的算法:CR值高分组(27%)/低分组(27%) T检验
操作:反向计分:Transform→Recode into Same Variables→Old and New values
重新计分,有现实表观意思
求量表的总分:Compute Variables →Sum 量表的总分排序:升序 降序
高低分组上下的27%:记录下数值
依临界分数将观察值在量表得分分成高低两组:T→Recode into Diff V→O and N V 以独立样本的T检验两组的题项差异:Compare Means→Independent-Samples T Test→Grouping Variables→观察t值
删除t值没有达到显著的题项: 第四部分 因素分析+实例 4.1简介
效度validity:内容效度(Content V)效标关联效度(Criterion-related V)结构效度(Construct V)
彼此相关变量降维彼此独立因素(作用)
探索性因素分析:探索量表的潜在结构,究竟有几个因素 验证性因素分析:验证量表的结构效度,符合理论的多少
4.2操作说明 准备:选取样本(样本:量表题项=5:1,并且样本不少于100)KMO<0.5不适合,KMO=0.6适合分析,KMO值越大越适合;Bartlett's的球形检定。 计算变量间相关矩阵
选择萃取方法:主成分分析法
决定转轴方法:正交转轴法Varimax(高相关采用) 斜交转轴法Obmilin(低相关0.1~0.3采用)
初次决定因素命名
删除题项再作因素分析:①没有显著性或低相关②共同性小于0.6③因子分数较小(<0.4或三个标准差之外)
检验因素分析的结构:信度
结束
4.3原理
理论模式:Zj=aj1F1+aj2F2+……+ajmFm+Uj(Zj第J个变量的标准化分数 Fi为共同因素m为所有变量共同因素的数目 Uj为唯一因素 aj1为因素负荷量)
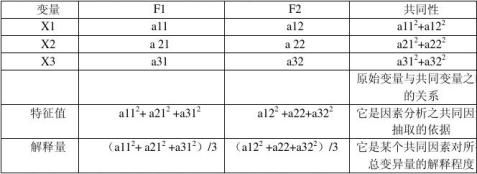
简化结构:一个变量与较少因素相关,但一个主相关;一个因素与一些变量存在密切相关(+/-);每个变量存在高相关。转轴 :直交转轴(因素间无相关,要求苛刻)与斜交转轴(因素间相关,应用广泛)
挑选:特征值大于1,陡坡检验
4.4实例
第五部分 回归分析
5.1回归分析相关概念
5.2回归模型的选择
5.3回归模型的诊断
5.4回归模型的应用-路径分析
第六部分 相关分析+实例
6.1相关系数与数据类型
6.2相关与回归
6.3相关散点图
6.4相关与因果
6.5相关实例演示
第七部分 专题解析
1.1正态性检验
7.1.2缺失值处理
7.2.1标注差与标准误
7.2.2卡方检验
7.3.1 t检验_方差分析_回归分析的综合比较
7.3.2 spss制图
7.4随机变量与固定变量
7.5.1重复测量
7.5.2自由度
7.6.1均数比较
7.6.2随机数生成
7.7.1七种常用交互式绘图
7.7.2四种重要抽样分布图
7.8.1集中量与频数分布的形态关系
7.8.2统计决断的两类错误及其控制
7.9.1因素负荷矩阵旋转
7.9.2原始分转化为标准分
7.10在SPSS中使用Syntax Editor语法编辑器
第八部分 综合案例演示
8现实案例教学
-
临床路径分析总结
4-6月份临床路径分析总结目前我科在医院指导下进一步开展临床路径工作,目前4-6月份纳入临床路径病种仅为LC术,目前第二季度共有4…
-
中段考试试卷分析总结
舞钢市第一小学20xx—20xx学年第一学期中段考试数学试卷分析总结11月x日下午,我校全体数学教师在会议室进行了中段考试试卷分析…
-
防汛应急疏散演练情况分析总结
防汛应急疏散演练总结为落实上级的文件精神,根据学校实际情况制订了“校园防汛应急疏散演练方案”,并进行了实际演练。为了确保演练活动落…
-
初二下学期数学期中考试试卷分析 总结计划
一、总体评价:本套试题本着“突出能力,注重基础,创新为魂的命题原则。按照《数学课程标准》的有关要求,突出了数学学科是基础的学科,八…
-
华威SWOT分析总结
市场部S:优势1.生产设备、原料、配件均为德国进口,一流品质。2.与北京嘉寓门窗幕墙股份有限公司(上市公司)强强联合3.集研发、生…
-
教师个人德育教育工作总结
教师个人德育教育工作总结本人拥护中国共 产 党的领导,热爱社会主义祖国,遵守国家法律和法规,热爱教育事业,热爱学生,认真贯彻党的教…
-
大学班干部生活委员年度工作总结
大学班干部生活委员年度工作总结时光飞逝,光阴荏苒,转眼间我已经做了一年的生活委员了,很感谢时老师和同学们给了我这么一个机会,让我如…
-
20xx护理质量总结
20xx年护理质量总结20xx年在护理部及科护士长的领导下及科主任的指导下,在全科护士的辛勤工作下,取得了各方面的进步与发展,现总…
-
社区20xx上半年综治工作总结
20xx年上半年度社区治安综合治理工作总结育才社区认真贯彻落实社会治安综合治理领导责任制和目标管理责任制,坚持“打防结合、预防为主…
-
生活委员年度总结
生活委员年度总结斗转星移,时间飞逝,不知不觉中一个学年已经结束。作为09物流一班的生活委员,我在老师的关怀和指导下,以及09物流一…