模式识别上机实验报告
实验一、二维随机数的产生
1、实验目的
(1) 学习采用Matlab程序产生正态分布的二维随机数
(2) 掌握估计类均值向量和协方差矩阵的方法
(3) 掌握类间离散度矩阵、类内离散度矩阵的计算方法
(4) 熟悉matlab中运用mvnrnd函数产生二维随机数等matlab语言
2、实验原理
多元正态分布概率密度函数:

其中: 是d维均值向量:
是d维均值向量:
Σ是d×d维协方差矩阵:
(1)估计类均值向量和协方差矩阵的估计
各类均值向量
各类协方差矩阵
(2)类间离散度矩阵、类内离散度矩阵的计算
类内离散度矩阵: , i=1,2
, i=1,2
总的类内离散度矩阵:
类间离散度矩阵:
3、实验内容及要求
产生两类均值向量、协方差矩阵如下的样本数据,每类样本各50个。
 ,
, ,
, ,
,
(1) 画出样本的分布图;
(2) 编写程序,估计类均值向量和协方差矩阵;
(3) 编写程序,计算类间离散度矩阵、类内离散度矩阵;
(4) 每类样本数增加到500个,重复(1)-(3)
4、实验结果
(1)、样本的分布图


(2)、类均值向量、类协方差矩阵
根据matlab程序得出的类均值向量为:
N=50 : m1=[-1.7160 -2.0374] m2=[2.1485 1.7678]
N=500: m1=[-2.0379 -2.0352] m2=[2.0428 2.1270]
根据matlab程序得出的类协方差矩阵为:
N=50: 

N=500: 

(3)、类间离散度矩阵、类内离散度矩阵
根据matlab程序得出的类间离散度矩阵为:
N=50: 
N=500: 
根据matlab程序得出的类内离散度矩阵为:
N=50:


N=500: 

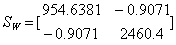
5、结论
由mvnrnd函数产生的结果是一个N*D的一个矩阵,在本实验中D是2,N是50和500.
根据实验数据可以看出,当样本容量变多的时候,两个变量的总体误差变小,观测变量各个取值之间的差异程度减小。
6、实验程序
clc;close all;clear all;
%parameter
N = 50;
N_1 = 500;
mu_1 = [-2,-2];
Sigma_1 = [1,0;0,1];
r_1 = mvnrnd(mu_1,Sigma_1,N);
r_11 = mvnrnd(mu_1,Sigma_1,N_1);
mu_2 = [2,2];
Sigma_2 = [1,0;0,4];
r_2 = mvnrnd(mu_2,Sigma_2,N);
r_22 = mvnrnd(mu_2,Sigma_2,N_1);
%figures
figure(1);
plot(r_1(:,1),r_1(:,2),'.');%将矩阵r_1的第一列当成横坐标,第二列当作纵坐标。
title('样本数为50时的第一类样本分布图');
figure(2);
plot(r_2(:,1),r_2(:,2),'.');
title('样本数为50时的第二类样本分布图');
figure(3);
plot(r_11(:,1),r_11(:,2),'.');
title('样本数为500时的第一类样本分布图');
figure(4);
plot(r_22(:,1),r_22(:,2),'.');
title('样本数为500时的第二类样本分布图');
%类均值向量和类协方差矩阵
m_1 = mean(r_1);%样本数为50时第一类 类均值向量
m_2 = mean(r_2);%样本数为50时第二类 类均值向量
m_11 = mean(r_11);%样本数为500时第一类 类均值向量
m_22 = mean(r_22);%样本数为500时第二类 类均值向量
sum1 = [0,0;0,0];
for n = 1:N
sum1 =sum1 + (r_1(n,:)-mu_1)'*(r_1(n,:)-mu_1);
end
E_1 = sum1/N;%样本数为50时,第一类 类协方差矩阵
sum2 = [0,0;0,0];
for n = 1:N
sum2 =sum2 + (r_2(n,:)-mu_2)'*(r_2(n,:)-mu_2);
end
E_2 = sum2/N;%样本数为50时,第二类 类协方差矩阵
sum3 = [0,0;0,0];
for n = 1:N_1
sum3 =sum3 + (r_11(n,:)-mu_1)'*(r_11(n,:)-mu_1);
end
E_11 = sum3/N_1;%样本数为500时,第一类 类协方差矩阵
sum4 = [0,0;0,0];
for n = 1:N_1
sum4 =sum4 + (r_22(n,:)-mu_2)'*(r_22(n,:)-mu_2);
end
E_22 = sum4/N_1;%样本数为500时,第二类 类协方差矩阵
%计算类间离散度和类内离散度
Sb_1 = (m_1 - m_2)'*(m_1 - m_2);%样本数为50时的,类间离散度矩阵
Sb_2 = (m_11 - m_22)'*(m_11 - m_22);%样本数为500时的,类间离散度矩阵
S_1 = [0,0;0,0];
S_2 = [0,0;0,0];
for n = 1:N
S_1 = S_1 + (r_1(n,:) - m_1)'*(r_1(n,:) - m_1);
S_2 = S_2 + (r_2(n,:) - m_2)'*(r_2(n,:) - m_2);
end
SW1 = S_1 + S_2;%样本数为50时的,总的类内离散度矩阵
S_11 = [0,0;0,0];
S_22 = [0,0;0,0];
for n = 1:N_1
S_11 = S_11 + (r_11(n,:) - m_11)'*(r_11(n,:) - m_11);
S_22 = S_22 + (r_22(n,:) - m_22)'*(r_22(n,:) - m_22);
end
SW2 = S_11 + S_22;%样本数为500时的,总的类内离散度矩阵
实验二、Fisher线性分类器的设计
1、实验目的
(1) 掌握Fisher线性判别方法
(2) 掌握Bayes决策的错误率的计算
(3) 掌握分类器错误率的估算方法
(4) 对模式识别有一个初步的理解
2、实验原理
Fisher准则基本原理:
如果在二维空间中一条直线能将两类样本分开,或者错分类很少,则同一类别样本数据在该直线的单位法向量上的投影的绝大多数都应该超过某一值。而另一类数据的投影都应该小于(或绝大多数都小于)该值,则这条直线就有可能将两类分开。
准则:向量W的方向选择应能使两类样本投影的均值之差尽可能大些,而使类内样本的离散程度尽可能小。这就是Fisher准则函数的基本思路。 y=WTX+W0
评价投影方向W的函数 :
最佳W值的确定:求取使JF达极大值时的 w*:
向量 就是使Fisher准则函数
就是使Fisher准则函数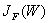 达极大值的解,也就是按Fisher准则将d维X空间投影到一维Y空间的最佳投影方向,该向量的各分量值是对原d维特征向量求加权和的权值。
达极大值的解,也就是按Fisher准则将d维X空间投影到一维Y空间的最佳投影方向,该向量的各分量值是对原d维特征向量求加权和的权值。
w0确定 :
当W0确定之后,则可按以下规则分类,

使用Fisher准则方法确定最佳线性分界面的方法是一个著名的方法,尽管提出该方法的时间比较早,仍见有人使用。
3、实验内容及要求
考虑Fisher线性判别方法,利用实验1中程序产生的数据(分别在各类样本数均为50及500时),计算:
1) 求解最优投影方向W;
2) 画出表示最优投影方向的直线,并且标记出投影后的点在直线上的位置;
3) 计算投影后的阈值权;
4) 计算分类器的各类错误率及总的平均错误率;
5) 计算按最小错误率Bayes决策的错误率(各类先验概率相同)
4、实验结果

上图可以看出在N=50时的情况下绿色的点是第一类样本点,蓝色的*给出了第二类样本点,红色的直线是最优投影方向的直线,+标出的点是W0点,直线上不同颜色代表了不同类样本点所投影的点的位置。
N=50时,类一的错误概率为0
类二的错误概率为 8%
平均错误概率为 1%
Bayes决策错误率为0%
最佳投影方向
5、结论
通过对实验结果的探究,可以得出当样本数比较大的时候类错误概率会上升。 的比例因子对于Fisher判别函数没有影响的原因:
的比例因子对于Fisher判别函数没有影响的原因:
在本实验中,最重要的是W的方向,或者说是在此方向上数据的投影,所以W的比例因子,即它是单位向量的多少倍长就没那么重要了,不管比例因子大小是多少,在最后求投影时都会被消掉。
6、实验程序
N = 50;%样本数为50时
mu_1 = [-2,-2];
Sigma_1 = [1,0;0,1];
r_1 = mvnrnd(mu_1,Sigma_1,N);
mu_2 = [2,2];
Sigma_2 = [1,0;0,4];
r_2 = mvnrnd(mu_2,Sigma_2,N);
m_1 = mean(r_1);
m_2 = mean(r_2);
S_1 = [0,0;0,0];
S_2 = [0,0;0,0];
for n = 1:N
S_1 = S_1 + (r_1(n,:) - m_1)'*(r_1(n,:) - m_1);
S_2 = S_2 + (r_2(n,:) - m_2)'*(r_2(n,:) - m_2);
end
SW1 = S_1 + S_2;
W_0 = -(m_1+m_2)/2;
w = (m_1-m_2)*inv(SW1);%投影向量S
k = w(:,2)/w(:,1);%最优投影方向直线的斜率。
x=[-7:0.01:7];
y = k*(x-W_0(:,1)) + W_0(:,2);%最优投影方向直线
figure(3);
plot(r_1(:,1),r_1(:,2),'g.');
title('样本数为50时的样本分布图');
hold on;
plot(r_2(:,1),r_2(:,2),'*');
plot(W_0(1),W_0(2),'+');
plot(x,y,'r');%画出最优投影方向直线
A0=[k -1;1 k];
X0=zeros(2,N);
for n=1:N
b=[k*W_0(:,1)-W_0(:,2) r_1(n,1)+k*r_1(n,2)]';
X0(:,n)=inv(A0)*b;
end
A1=[k -1;1 k];
X1=zeros(2,N);
for n=1:N
b1=[k*W_0(:,1)-W_0(:,2) r_2(n,1)+k*r_2(n,2)]';
X1(:,n)=inv(A1)*b1;
end
plot(X0(1,:),X0(2,:),'g');
plot(X1(1,:),X1(2,:),'b');
hold off;
en1=0;en2=0;
for m=1:N
if X0(1,m) > W_0(:,1)
en1=en1+1;
end
if X1(1,m) < W_0(:,1)
en2=en2+1;
end
end
p1=en1/N; % 类一错误率
p2=en2/N; % 类二错误率
p0=(en1+en2)/(2*N); % 平均错误率
Pw1=0.5;Pw2=0.5;
Pbayes1=Pw1*p1+Pw2*p2; %Bayes决策错误率
实验三、最近邻分类器的设计
1、 实验目的
(1) 掌握最近邻分类算法
(2) 掌握k近邻分类算法
(3) 掌握分类器错误率的估算方法
2、实验原理
(1)近邻法原理及其决策规则
最小距离分类器:将各类训练样本划分成若干子类,并在每个子类中确定代表点。测试样本的类别则以其与这些代表点距离最近作决策。该法的缺点:所选择的代表点并不一定能很好地代表各类,其后果将使错误率增加。
以全部训练样本作为“代表点”,计算测试样本与这些“代表点”,即所有样本的距离,并以最近邻者的类别作为决策。
最近邻法决策规则:将与测试样本最近邻样本的类别作为决策的方法称为最近邻法。
对一个C类别问题,每类有Ni个样本,i=1,…,C,则第i类ωi的判别函数

判别函数的决策规则:
若: ;则:X∈ωj
;则:X∈ωj
 表示是ωi类的第k个样本
表示是ωi类的第k个样本
(2)k-近邻法决策规则
在所有N个样本中找到与测试样本的k个最近邻者,其中各类别所占个数表示成ki,i=1,…,c。
则决策规划是:
如果:
则:X∈ωj
3验内容及要求
还是利用实验1的程序,计算
(1) 每类产生50个样本作为训练样本;每类产生100个样本作为考试样本;
(2) 按最近邻法用训练样本对考试样本分类,计算平均错误率;
(3) 按最k近邻法(k=10)用训练样本对考试样本分类,计算平均错误率;
4、实验结果


最近邻分类法错误率 =0.0150; K紧邻分类法错误率=0.0050
5、结论
最近邻分类方法相对于K近邻分类方法来说,错误率高,其分类错误率受样本个数的影响小,K值越大,错分率应该越低,当K趋向于样本总个数时 错误率应该最低,但此时计算量大。在计算量方面,K近邻分类的计算量比最近邻分类法大。
6、实验程序
N1=100;
N2=50;
miu1=[-2;-2];
miu2=[2;2];
x1=random('normal',-2,1,1,N1);
x2=random('normal',-2,1,1,N1);
x3=random('normal',2,1,1,N1);
x4=random('normal',2,2,1,N1);
y1=random('normal',-2,1,1,N2);
y2=random('normal',-2,1,1,N2);
y3=random('normal',2,1,1,N2);
y4=random('normal',2,2,1,N2);
X1=[x1;x2]; %测试样本1
X2=[x3;x4]; %测试样本2
Y1=[y1;y2]; %训练样本1
Y2=[y3;y4]; %训练样本2
figure
plot(X1(1,:),X1(2,:),'*'); %测试样本1
hold on
plot(X2(1,:),X2(2,:),'*r'); %测试样本2
title('测试样本分布图')
figure
plot(Y1(1,:),Y1(2,:),'*'); %训练样本1
hold on
plot(Y2(1,:),Y2(2,:),'*r'); %训练样本2
title('训练样本分布图')
distance1=zeros(N1,2*N2);
distance2=zeros(N1,2*N2);
%%最近邻
erro1=0;
erro2=0;
for i=1:N1
for j=1:N2
distance1(i,j)=sqrt((X1(1,i)-Y1(1,j))^2+(X1(2,i)-Y1(2,j))^2);
distance1(i,j+N2)=sqrt((X1(1,i)-Y2(1,j))^2+(X1(2,i)-Y2(2,j))^2);
end
zuixiao=min(distance1(i,:));
for j=1:2*N2
if distance1(i,j)==zuixiao
if j>N2
erro1=erro1+1;
end
end
end
end
for i=1:N1
for j=1:N2
distance2(i,j)=sqrt((X2(1,i)-Y1(1,j))^2+(X2(2,i)-Y1(2,j))^2);
distance2(i,j+N2)=sqrt((X2(1,i)-Y2(1,j))^2+(X2(2,i)-Y2(2,j))^2);
end
zuixiao=min(distance2(i,:));
for j=1:2*N2
if distance2(i,j)==zuixiao
if j<N2
erro2=erro2+1;
end
end
end
end
erro_pingjun=(erro1+erro2)/(2*N1)
%%k近邻
k=10;
number11=zeros(N1,1);number12=zeros(N1,1);
MAX=1e5;
k_erro1=0;
for ii=1:N1
for i=1:k
zuixiao=min(distance1(ii,:));
for j=1:2*N2
if distance1(ii,j)==zuixiao
if j<=N2
number11(ii)=number11(ii)+1;
else
number12(ii)=number12(ii)+1;
end
distance1(ii,j)=MAX;
end
end
end
if number11(ii)<number12(ii)
k_erro1=k_erro1+1;
end
end
number21=zeros(N1,1);number22=zeros(N1,1);
k_erro2=0;
for ii=1:N1
for i=1:k
zuixiao=min(distance2(ii,:));
for j=1:2*N2
if distance2(ii,j)==zuixiao
if j<=N2
number21(ii)=number21(ii)+1;
else
number22(ii)=number22(ii)+1;
end
distance2(ii,j)=MAX;
end
end
end
if number21(ii)>number22(ii)
k_erro2=k_erro2+1;
end
end
k_erro_pingjun=(k_erro1+k_erro2)/(2*N1)
-
上机实验报告格式
网页设计实验报告院部热能学院专业热能与动力工程班级112姓名范金仓学号20xx031388一实验目的及要求1确定网站主题和网站的用…
-
计算机上机实验报告模板
交通与汽车工程学院实验报告课程名称课程代码学院直属系交通与汽车工程学院年级专业班学生姓名学号实验总成绩任课教师开课学院交通与汽车工…
-
上机实验报告格式要求
VB上机实验报告要求1预习报告课程名称姓名实验名称班级学号实验日期指导教师一实验目的及要求本次上机实验所涉及并要求掌握的知识点二实…
-
C语言集中上机实验报告
重庆邮电大学移通学院C语言集中上机实验报告学生学号班级专业重庆邮电大学移通学院20xx年5月重庆邮电大学移通学院目录第一章循环31…
-
上机实验报告
编译原理报告编译原理报告正规式转化为NFA班级19xx31班学号20xx1002284姓名李豪强指导老师刘远兴日期20xx1020…
-
ERP上机实验心得体会
工商101320xx610083林冰冰首先感谢王家聚老师再这一学期中对我们的ERP知识传授,你教会我们的绝不仅仅是ERP课程上的知…
-
erp上机实验心得
ERP上机实验心得通过该实验,对所学的知识有了进一步的了解。在实验的过程中,出现了一些问题,不过最后都得以解决。然而通过这些错误,…
-
C语言上机实验心得
在科技高度发展的今天,计算机在人们之中的作用越来越突出。而C语言作为一种计算机的语言,学习它将有助于我们更好的了解计算机,与计算机…
-
电子商务实验心得体会
完成电子商务实验课的心得体会通过这段时间的电子商务实验,我了解到很多关于电子商务的实践知识。伴随着商品经济和网络技术的不断发展,网…
-
java上机实验心得体会报告
北京联合大学信息学院“面向对象程序设计”课程上机实验报告题目:JAVA上机实验心得体会姓名(学号):专业:计算机科学与技术编制时间…