Hadoop HBase 使用指南
第1章 集群的搭建
1.1 集群的结构
实验环境中共有6台服务器,搭建完全分布式HDFS与HBase环境,采用的Hadoop与HBase版本为hadoop0.20.2HBase0.92.0,其中一台节点做为NameNode和Master,另一台做为Master备份节点(可以不要备份Master节点),剩余四台则做为DataNode和RegionServer节点,并且在其上运行Zookeeper服务,整个实验环境结构如图 1-1所示。
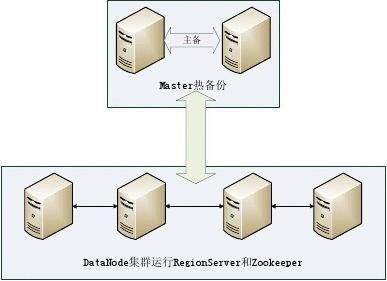
图 1-1 HBase 集群结构
1.2 基础环境
整个系统要能正常的运行,在各机器上安装需要的程序软件之前,也要正确的配置好网络连接、程序参数和系统设置等,主要包括:操作系统Ubuntu10.04、sun-java-6和OpenSSH。分别在每台服务器上安装上述的系统和程序,过程中要注意:
根据Hadoop和HBase的系统兼容性要求Linux系统的版本可以不一致,不影响HDFS和HBase的运行。
JDK的版本、安装位置和环境变量的设置都应保持一致。
OpenSSH要设置为无密码访问,确保各服务器之间能正常通信。 各服务器配置如表 1-1所示。
表 1-1服务器的配置信息
主机名
Master1
Master2
Slave1
Slave2
Slave3
Slave4 IP地址(在同一网段内) 192.168.1.100 192.168.1.99 192.168.1.101 192.168.1.102 192.168.1.103 192.168.1.104
备注 NameNode和Master节点 Master备份节点 DataNode和RegionServer DataNode和RegionServer DataNode和RegionServer DataNode和RegionServer
1.3 软件的安装
集群中Hadoop和HBase的版本要保持一致,并确保Hadoop和HBase版本相互之间兼容。
1.3.1 SSH设置
1.3.1.1 免密码SSH设置。
生成密钥对,执行如下命令:
$ ssh-keygen -t rsa
然后一直按<Enter>键,就会按照默认的选项将生成的密钥对保存在.ssh/id_rsa文件中,如图1-9所示。
图1-9 将密钥对保存在.ssh/id.rsa文件中
进入.ssh目录,执行如下命令:
$ cp id_rsa.pub authorized_keys
此后执行$ ssh localhost,可以实现用SSH 连接并且不需要输入密码。

1.3.1.2 SSH配置。
该配置主要是为了实现在机器之间执行指令时不需要输入密码。在所有机器上建立.ssh目录,执行:
$ mkdir .ssh
在ubuntunamenode上生成密钥对,执行:
$ ssh-keygen -t rsa
然后一直按<Enter>键,就会按照默认的选项将生成的密钥对保存在.ssh/id_rsa文件中。接着执行如下命令: $cd ~/.ssh
$cp id_rsa.pub authorized_keys
$scp authorized_keys ubuntudata1:/home/grid/.ssh
$scp authorized_keys ubuntudata2:/home/grid/.ssh
最后进入所有机器的.ssh目录,改变authorized_keys文件的许可权限: $chmod 644 authorized_keys
这时从ubuntunamenode向其他机器发起SSH连接,只有在第一次登录时需要输入密码,以后则不再需要。
1.3.2 JDK安装
实验使用jdk-6u24-linux-x86.bin,软件放在共享文件夹下。把Java安装到目录/usr/ java/jdk1.6.0_24,使用如下命令:
$ cd /usr/java/
$ /mnt/hgfs/share/jdk-6u24-linux-x86.bin
1.3.2.1 JDK设置
编辑系统文件/etc/profile ,在文件最后添加JDK的环境变量。 #set java environment
JAVA_HOME=/usr/ java/jdk1.6.0_24
CLASSPATH=.:$JAVA_HOME/bin:$PATH
PATH=$JAVA_HOME/bin:$PATH
Export JAVA_HOME CLASSPATH PATH
1.3.3 Hadoop的安装
实验使用的是Hadoop-0.20.2.tar.gz安装包,包括HDFS和MapReduce,安装过程如下:
首先把Hadoop-0.20.2.tar.gz安装包解压到Linux /home/UserName目录下,命令为:
$tar -zxvf /~/ Hadoop-0.20.2.tar.gz /home/UserName
解压文件之后需要对Hadoop进行配置,Hadoop的配置文件存放在/home/UserName/hadoop-0.20.2/conf目录之下,其中包括一个环境配置文件Hadoop-env.sh、核心配置文件core-site.xml、分布式文件系统HDFS配置文件hdfs-site.xml、MapReduce计算框架配置文件mapred-site.xml、主节点配置文件masters和从节点配置文件slaves,需要对各文件进行表 1-2所示配置。
表 1-2 Hadoop配置文件
文件名
Hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
masters
slaves 注释 配置Java环境变量:JAVA_HOME=/usr/java/jdk1.6.0_21 HDFS服务端口:fs.default.name=hdfs://localhost:9000 配置HDFS的参数:如数据副本数目等 MapReduce服务端口:mapred.job.tracker=localhost:9001 设置NameNode,添加NameNode主机名 设置Slaves,所有DataNode主机名
在一台服务器上安装完之后,可以把Hadoop目录下的所有文件Copy到集群中其它服务器上来完成整个集群的安装,其命令为:
$scp -rf /home/UserName/hadoop-0.20.2/ slave1://home/Username/
运行Hadoop前要对NameNode的命名空间进行初始化,在Hadoop目录下运行:
$bin/hadoop NameNode -format
然后启动Hadoop的守护进程:
$bin/start-all.sh
系统成功运行之后master之上将会运行NameNode、Secondary NameNode和JobTracker三个进程,slave节点之上会运行DataNode和TaskTracker二个进程。通过命令:
$bin/hadoop dfsadmin -report
可以查看整个系统的运行状态信息。
1.3.4 HBase的安装
HBase的安装包hbase-0.92.0.tar.gz包含分布式数据库HBase和Zookeeper,将其解压到目录/home/UserName/下。HBase的配置文件在conf目录下,包含环境配置文件hbase-env.sh、HBase数据库运行参数配置文件hbase-site.xml和Region服务器列表文件regionservers,需要对文件进行如表 1-3所示配置:
表 1-3 HBase配置文件
文件名
hbase-env.sh
hbase-site.xml
regionservers 注释 设置由HBase管理Zookeeper:HBASE_MANAGES=true 设置HBase的参数:hbase:rootdir=hdfs://UbuntuMaster:9000/hbase hbase.cluster.distributed=true Region服务器列表
HBase是运行在HDFS之上的,所以必须确保HDFS处于正常运行状态。同时因为存在版本兼容性问题,在启动HBase之前必须让HBase确定集群中所使用的Hadoop的版本,需要把Hadoop目录下的hadoop-0.20.2-core.jar替换掉HBase/lib目录下的hadoop-core-1.0.0.jar。最后确保集群中每台服务器的系统时间保持相对一致(误差小于30秒),进入HBase目录输入命令以启动HBase:
$bin/start-hbase.sh
接着启动HBase的外壳程序,命令如下:
$bin/hbase shell
在shell模式下可以对HBase进行创建表、添加数据、读取数据和删除表等操作。
第2章 实验中常见的问题和解决方法
2.1 问题1:节点不能正常启动
1.Datanode,RegionServer 进程可以启动但是系统不能正常使用-----节点系统时间不同步。
解决方法:修改集群各个节点的系统时间,把时间误差控制在30秒之内,命令为: $Sudo Date –s time
$hwclock –systohc
2.Datanode 进程启动后不久,自动结束----系统命名空间出错
解决方法:由于namenode和datanode空间版本不匹配,需要把所有Datanode节点存储的内容删除,然后重新formate命名空间,在重新启动Hadoop,可以解决这个问题
2.2 问题2:节点能够正常启动,但是某些datanode不能访问。
1.如果是在版本较新的桌面linux系统中,可能是IP配置出现问题,要把IPV6的配置清空,禁用IPV6服务。
2.长时间运行之后,也会出现个别节点不提供服务的情况,这是需要把该节点的服务关闭后重新启动。
$HBase regionserver start
2.3 问题3:HMaster不能启动错误 Address already in use
9000端口已经被占用,可以查看系统占用9000端口的服务,很有可能是多吃启动HBase并且没有正常结束的原因,可以重新启动计算机。如果9000端口被其他服务占用可以为HBase重新配置其他端口
2.4 问题4:数据备份和数据库切换问题
HBase数据库是在HDFS的文件系统上创建一个存储目录,所以要备份HBase数据只需要在HDFS的shell中,在HBase目录copy到本地即可。
如果要更换数据库,需要修改HBase的配置文件,改变HBase指向的文件目录即可。
2.5 问题5:Call to master:9000 failed on local exception 主要解决方法:关闭Master的防火墙
2.6 为题6:WebServer访问HBase数据连接问题
解决方法:在所有的集群节点上面运行zookeeper服务,特别是Master节点上。因为,访问HBase的第一步是通过Zookeeper访问.ROOT.表。
2.7 问题7 :WebServer访问HBase的DNS问题,不能解析所有的节点
解决方法,把Master节点上的HOSTS文件内容拷贝到访问PC上去。
第二篇:Hadoop、Hbase、zookeeper集群配置步骤
Hadoop、Hbase、Zookeeper集群配置步骤
一、规划拓扑
一台主服务器(masters):运行NameNode,JobTracker,Hbase master,zookeeper; 三台从服务器(slaves):运行DataNode,TaskTracker,Hbase regionserver; 在必要的时候这些复用的服务器可以拆分开来,zookeeper也可以用集群部署。
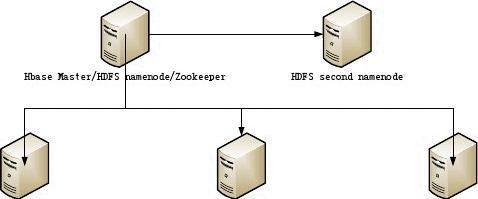
Hbase Regionserver/HDFS datanodeHbase Regionserver/HDFS datanodeHbase Regionserver/HDFS datanode
二、服务器环境准备
a) 安装JDK1.6.0以上,配置JAVA_HOME环境变量;
b) 创建hadoop用户,确保每台服务器相同
c) 安装配置SSH,使得主服务器通过SSH无用户名,无密码也可以登录到从服务器,具体过程如下:
i. 下载安装SSH;
ii. 用root修改 vi /etc/ssh/sshd_config,找到以下内容,并去掉注释符”#“ RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
iii. 用root重启sshd /sbin/service sshd restart
iv. 用hadoop用户登录服务器行执行
1. ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
2. cat ~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys
注意:在集群的每台服务器上执行以上命令生成rsa的公私钥对,把每台服务器的公钥文件id_rsa.pub的内容一起复制到authorized_keys,然后再将该文件复制到每台服务器的~/.ssh目录下
d) 修改/etc/hosts,给每个服务器指定别名并将这个配置复制到每台服务器
三、安装配置hadoop
a) 用hadoop用户登录到主服务器并下载安装包hadoop-1.0.4.tar.gz b) 在主服务器执行tar xfvz hadoop-1.0.4.tar.gz
c) 修改如下配置文件
i. /etc/profile
1. 在该文件后添加hadoop安装路径,示例如下:
HADOOP_HOME=/home/hadoop/hadoop-1.0.4
export PATH=$PATH:$HADOOP_HOME/bin
2. 执行source /etc/profile使得环境变量生效
ii. Hadoop-env.sh
1. 配置JAVA_HOME,如果linux设置了该系统变量则此处不需要单独设置。
iii. Core-site.xml
<configuration>
<property> <name>fs.default.name</name> <value>hdfs:///</value> <description>Common configure</description> </property>
</configuration>
使用服务器别名指定主服务器URL。
iv. Hdfs-site.xml
<configuration>
<property> <name>dfs.replication</name> <value>3</value> <description>HDFS configure</description> </property> <property> <name>dfs.name.dir</name> <value>/home/hadoop/HDFS/Namenode</value> <description>HDFS configure</description> </property> <property> <name>dfs.data.dir</name> <value>/home/hadoop/HDFS/Datanode</value> <description>HDFS configure</description> </property>
</configuration>
指定namenode和datanode对应的本地文件路径(可以是hadoop用户能够访问的任何本地目录)
v. Mapred-site.xml
<configuration>
<property> <name>mapred.job.tracker</name> <value>:8021</value> <description>MapReduce configure</description> </property>
</configuration>
指定JobTracker(主服务器位置),使用服务器别名标识
vi. Masters
用服务器别名标识出主服务器位置
vii. Slaves
用服务器别名标识出从服务器位置
d) 向从服务器发布
i. 在主服务器执行tar命令将,配置好的hadoop完整打包;
1. tar cfvz hadoop-1.0.4.tar.gz hadoop-1.0.4
2. scp hadoop-1.0.4.tar.gz hadoop@:/home/hadoop/. 逐个执行2将完整hadoop分发到从服务器
3. SSH到每个从服务器,解压这个hadoop包
4. 执行hadoop namenode -format
5. 执行start-dfs.sh启动DHFS守候进程
6. 在主服务器执行start-mapred.sh启动MapReduce守候程序或者执行start-all.sh
四、安装配置zookeeper
a) 用hadoop用户登录到主服务器并下载安装包zookeeper-3.4.5.tar.gz b) 在主服务器执行tar xfvz zookeeper-3.4.5.tar.gz
c) 修改如下配置文件
i. /etc/profile
1. 在该文件后添加zookeeper安装路径,示例如下:
ZOOKEEPER_HOME= /home/hadoop/zookeeper-3.4.5
export PATH=$PATH:$ ZOOKEEPER_HOME/bin
2. 执行source /etc/profile使得环境变量生效
ii. Zoo.cfg
1. 在conf目录下执行 cp zoo_sample.cfg zoo.cfg
2. 修改相关参数,缺省值可以不变
d) 启动zookeeper
i. 执行zkServer.sh start
ii. 执行jps如果看到进程QuorumPeerMain说明正常启动
iii. 执行zkCli.sh可以通过命令行方式访问zookeeper
五、安装配置HBase
a) 用hadoop用户登录到主服务器并下载安装包hbase-0.94.3.tar.gz b) 在主服务器执行tar xfvz hbase-0.94.3.tar.gz
c) 修改如下配置文件
i. /etc/profile
1. 在该文件后添加hbzse安装路径,示例如下:
HBASE_HOME= /home/hadoop/hbase-0.94.3
export PATH=$PATH:$ HBASE_HOME/bin
2. 执行source /etc/profile使得环境变量生效
ii. hbase-env.sh
1. 配置JAVA_HOME,如果linux设置了该系统变量则此处不需要单独设置。
iii. hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://:8020/hbase</value>
<description>指向hdfs的namenode URL </description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>true:集群部署,false:单机部署 </description> </property>
<property>
<name>hbase.master</name>
<value>hdfs://:60000</value>
<description>hbase web监控URL</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value></value>
<description>用逗号分割的zookeeper集群域名 </description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/tmp/zookeeper</value>
<description>zookeeper输出数据存放路径</description>
</property>
</configuration>
iv. regionservers
用服务器别名标识出从服务器位置
d) 启动hbase
i. 利用hadoop的HDFS建立hbase的存储位置,执行如下:
hadoop dfs –mkdir hbase (hbase是hbase配置文件hbase.rootdir中指定的名称) ii. 执行start-hbase.sh
iii. 执行jps如果看到主服务器有进程HMaster,regionserver中有HRegionServer说明正常启动
iv. 如果从日志查看某些服务没有启动,则有可能是服务器时钟不一致,最好用date –s命令把服务器时间设置相同,或者利用linux的时钟同步工具同步
v. 有时候服务器的别名可能和对应的域名不一致也会导致客户端出错,这时候要在客户端的host中设置服务器的别名对应的IP
-
personal narrative essay
KatieQEWRT1AEssay1GrowupinMyOwnWayOnesummerundertheglimmeringsunshineIwasst…
-
personal essay-working hard
ChenMartin142xxxxxxxx4December20xxWorkinghardIhavereadalinewhichisAllmagicc…
-
The collection of personal essay
ThecollectionofpersonalessayTheimportantofstudyingAsanoldsayinggoesthatAnid…
-
personal reflection essay
PersonalReflectionEssayAssignmentPreparedbyHowardHeA00688012InstructorJulie…
-
A Personal Essay
APersonalEssayWhenwetalkaboutmypersonalessaythefirstwordmostpeopleIknowwoul…
-
HBase 默认配置说明
HBase默认配置说明收藏版hbaserootdir这个目录是regionserver的共享目录用来持久化HbaseURL需要是3…
-
Hbase分布式详细安装步骤
Hbase分布式详细安装步骤Hbase版本0206安装注自0205以后版本集成了zookeeper可匹配Hadoop0202准备工…
-
hadoop端口
hadoop端口20xx年8月6日954端口作用9000fsdefaultFS如hdfs172254017190009001dfs…
-
Hadoop端口用途
Hadoop应用各端口具体用途Hadoop集群的各部分一般都会使用到多个端口有些是daemon之间进行交互之用有些是用于RPC访问…
-
Hbase Java API 介绍及使用示例
HbaseJavaAPI介绍及使用示例几个相关类与HBase数据模型之间的对应关系java类HBase数据模型HBaseAdmin…