信息论与编码实验报告-Shannon编码
课程名称:姓 名:
系:专 业:年 级:学 号:指导教师:职 称: 实验报告 信息论与编码
年 月 日
1
实验三 Shannon编码
一、实验目的
1、熟悉离散信源的特点;
2、学习仿真离散信源的方法
3、学习离散信源平均信息量的计算方法
4、熟悉 Matlab 编程
二、实验原理
给定某个信源符号的概率分布,通过以下的步骤进行香农编码
1、信源符号按概率从大到小排列;
p1?p2?.......?pn
2、确定满足下列不等式的整数码长Ki为
?lb(pi)?Ki??lb(pi)?1
3、为了编成唯一可译码,计算第i个消息的累加概率:
Pi??p(ak)
k?1i?1
4、将累加概率Pi变换成二进制数;
5、取Pi二进制数的小数点后Ki位即为该消息符号的二进制码字。
三、实验内容
1、写出计算自信息量的Matlab 程序
2、写出计算离散信源平均信息量的Matlab 程序。
3、将程序在计算机上仿真实现,验证程序的正确性并完成习题。
四、实验环境
Microsoft Windows 7
Matlab 6.5
五、编码程序
计算如下信源进行香农编码,并计算编码效率:
a1a2a3a4a5a6??X??a0??P??0.20.190.180.170.150.10.01?
????
MATLAB程序:
(1) a=[0.2 0.18 0.19 0.15 0.17 0.1 0.01];
k=length(a);y=0;
for i=1:k-1
2
for n=i+1:k
if (a(i)<a(n))
t=a(i);
a(i)=a(n);
a(n)=t;
end
end
end
s=zeros(k,1);b=zeros(k,1);
for m=1:k
s(m)=y;
y=y+a(m);
b(m)=ceil(-log2(a(m)));
z=zeros(b(m),1);
x=s(m);
p=b2d10(x);
for r=1:b(m)
z(r)=p(r);
end
disp('?????á??????')
disp('????????'),disp(a(m)) disp('?ó???á??'),disp(s(m)) disp('±à??????'),disp(b(m)) disp('×???±à??'),disp(z')
end
(2) function y=b2d10(x)
for i=1:8
temp=x.*2;
if(temp<1)
y(i)=0;
x=temp;
else
x=temp-1;
y(i)=1;
end
end
(3) p=[0.2 0.19 0.18 0.17 0.15 0.1 0.01]; sum=0;sum1=0;
for i=1:7
a(i)=-log2(p(i));
K(i)=ceil(a(i));
R(i)=p(i)*K(i);
sum=sum+R(i);
c(i)=a(i)*p(i);
3
sum1=sum1+c(i);
end
K1=sum;
H=sum1;
Y=H/K1;
disp('???ù??????'),disp(H)
disp('???ù???¤'),disp(K1)
disp('±à???§??'),disp(Y)
六、实验结果
输出结果为:
出事概率0.2000,求和结果0,编码位数3,最终编码000
出事概率0.1900,求和结果0.2000,编码位数3,最终编码001
出事概率0.1800,求和结果0.3900,编码位数3,最终编码011
出事概率0.1700,求和结果0.5700,编码位数3,最终编码100
出事概率0.1500,求和结果0.7400,编码位数3,最终编码101
出事概率0.1000,求和结果0.8900,编码位数4,最终编码1110
出事概率0.0100,求和结果0.9900,编码位数7,最终编码1111110
编码效率:
平均信息量2.6087
平均码长3.1400
编码效率0.8308
七、实验总结
通过本次的实验,掌握了Shannon编码的实验原理以及编码过程。Shannon编码中,对概率的排序是最基本的,如果没有将其按照从大到小的顺序排序,则经过MATLAB的程序运行后,将出现错误。在运用MATLAB编程的过程中,调用了各种函数,实现了编程。通过与队友的讨论,不但让我们更快的完成MATLAB编码,也深深体会到只有将大家的智慧融合起来,才能更快更好的解决难题。
4
第二篇:香农编码实验报告
中南大学
《信息论与编码》实验报告
目录
一、香农编码……………………………………….....3
实验目的.................................................................................3
实验要求.................................................................................3
编码算法.................................................................................3
调试过程.................................................................................3
参考代码.................................................................................4
调试验证.................................................................................7
实验总结.................................................................................7
二、哈夫曼编码……………………………………….8
实验目的.................................................................................8
实验原理.................................................................................8
数据记录.................................................................................9
实验心得................................................................................10
一、香农编码
1、实验目的
(1)进一步熟悉Shannon编码算法;
(2)掌握C语言程序设计和调试过程中数值的进制转换、数值与字符串之间的转换等技术。
2、实验要求
(1)输入:信源符号个数q、信源的概率分布p;
(2)输出:每个信源符号对应的Shannon编码的码字。
3、Shannon编码算法
1:procedure SHANNON(q,{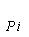 })
})
2: 降序排列{ }
}
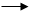 3: for i=1 q do
3: for i=1 q do
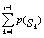
 4: F(
4: F(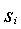 )
)
 5:
5:
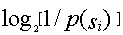
6:将累加概率F()(十进制小数)变换成二进制小数。
7:取小数点后个二进制数字作为第i个消息的码字。
8:end for
9:end procedure
------------------------------------------------------------------------------------------------------------------
4、调试过程
1、fatal error C1083: Cannot open include file: 'unistd.h': No such file or directory
fatal error C1083: Cannot open include file: 'values.h': No such file or directory
原因:unistd.h和values.h是Unix操作系统下所使用的头文件
纠错:删去即可
2、error C2144: syntax error : missing ')' before type 'int'
error C2064: term does not evaluate to a function
原因:l_i(int *)calloc(n,sizeof(int)); l_i后缺少赋值符号使之不能通过编译
纠错:添加上赋值符号
3、error C2018: unknown character '0xa1'
原因:有不能被识别的符号
纠错:在错误处将不能识别的符号改为符合C语言规范的符号
4、error C2021: expected exponent value, not ' '
原因:if(fabs(sum-1.0)>DELTA); 这一行中DELTA宏定义不正确
纠错:# define DELTA 0.000001
5、error C2143: syntax error : missing ';' before '}'
原因:少写了“;”号
纠错:在对应位置添加上“;”号
5、参考代码
# include<stdio.h>
# include<math.h>
# include<stdlib.h>
# include<string.h>
# define DELTA 0.000001/*精度*/
void sort(float*,int);/*排序*/
int main(void)
{
register int i,j;
int n; /*符号个数*/
int temp;/*中间变量*/
float *p_i; /*符号的概率*/
float *P_i; /*累加概率*/
int *l_i; /*码长*/
char * *C; /*码集合*/
/*用sum来检验数据,用p来缓存了中间数据*/
float sum,p;
/*输入符号数*/
fscanf(stdin,"%d",&n);
/*分配内存地址 */
p_i=(float *)calloc(n,sizeof(float));
P_i=(float *)calloc(n,sizeof(float));
l_i=(int *)calloc(n,sizeof(int));
/* 存储信道传输的概率*/
for(i=0;i<n;i++)
fscanf(stdin,"%f",&p_i[i]);
/*确认输入的数据*/
sum=0.0;
for(i=0;i<n;i++)
sum+=p_i[i];
if(fabs(sum-(1.0))>DELTA)
fprintf(stderr,"Invalid input data \n");
fprintf(stdout,"Starting…\n\n");
/*以降序排列概率*/
sort (p_i,n);
/*计算每个符号的码长*/
for(i=0;i<n;i++)
{
p=(float)(-(log(p_i[i])))/log(2.0);
l_i[i]=(int)ceil(p);
}
/*为码字分配内存地址*/
C=(char **)calloc(n,sizeof(char *));
for(i=0;i<n;i++)
{
C[i]=(char *)calloc(l_i[i]+1,sizeof(char));
C[i][0]='\0';
}
/*计算概率累加和*/
P_i[0]=0.0;
for(i=1;i<n;i++)
P_i[i]=P_i[i-1]+p_i[i-1];
/*将概率和转变为二进制编码*/
for(i=0;i<n;i++)
{
for(j=0;j<l_i[i];j++)
{
/*乘2后的整数部分即为这一位的二进制码元*/
P_i[i]=P_i[i]*2;
temp=(int)(P_i[i]);
P_i[i]=P_i[i]-temp;
/*整数部分大于0为1,等于0为0*/
if(temp==0)
C[i]=strcat(C[i],"0");
else
C[i]=strcat(C[i],"1");
}
}
/*显示编码结果*/
fprintf(stdout,"The output coding is :\n");
for(i=0;i<n;i++)
fprintf(stdout,"%s",C[i]);
fprintf(stdout,"\n\n");
/*释放内存空间*/
for(i=n-1;i>=0;i--)
free(C[i]);
free(C);
free(p_i);
free(P_i);
free(l_i);
exit(0);
}
/*冒泡排序法*/
void sort(float *k,int m)
{
int i=1;/*外层循环变量*/
int j=1;/*内层循环变量*/
int finish=0;/*结束标志*/
float temp;/*中间变量*/
while(i<m&&!finish)
{
finish=1;
for(j=0;j<m-i;j++)
{
/*将小的数后移*/
if(k[j]<k[j+1])
{
temp=k[j];
k[j]=k[j+1];
k[j+1]=k[j];
finish=0;
}
i++;
}
}
}
6、调试验证:
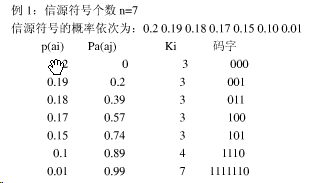
程序结果:
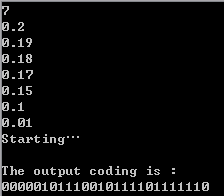
7、实验总结
1949年香农在《有噪声时的通信》一文中提出了信道容量的概念和信道编码定理,为信道编码奠定了理论基础。无噪信道编码定理(又称香农第一定理)指出,码字的平均长度只能大于或等于信源的熵。有噪信道编码定理(又称香农第二定理)则是编码存在定理。它指出只要信息传输速率小于信道容量,就存在一类编码,使信息传输的错误概率可以任意小。随着计算技术和数字通信的发展,纠错编码和密码学得到迅速的发展。香农编码定理虽然指出了理想编码器的存在性,但是并没有给出实用码的结构及构造方法,编码理论正是为了解决这一问题而发展起来的科学理论。编码的目的是为了优化通信系统。
香农编码是码符号概率大的用短码表示,概率小的是用长码表示,程序中对概率排序,最后求得的码字就依次与排序后的符号概率对应。
二、哈夫曼编码
1、实验目的和任务
1、 理解信源编码的意义;
2、 熟悉 MATLAB程序设计;
3、 掌握哈夫曼编码的方法及计算机实现;
4、 对给定信源进行香农编码,并计算编码效率;
2、实验原理介绍
1、把信源符号按概率大小顺序排列, 并设法按逆次序分配码字的长度;
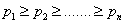
2、在分配码字长度时,首先将出现概率 最小的两个符号的概率相加合成一个概率;
3、把这个合成概率看成是一个新组合符号地概率,重复上述做法直到最后只剩下两个符号概率为止;
4、完成以上概率顺序排列后,再反过来逐步向前进行编码,每一次有二个分支各赋予一个二进制码,可以对概率大的赋为零,概率小的赋为1;
5、从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字。
3、实验内容和步骤
对如下信源进行哈夫曼编码,并计算编码效率。

(1)计算该信源的信源熵,并对信源概率进行排序
(2)首先将出现概率最小的两个符号的概率相加合成一个概率,把这个合成概率与其他的概率进行组合,得到一个新的概率组合,重复上述做法,直到只剩下两个概率为止。之后再反过来逐步向前进行编码,每一次有两个分支各赋予一个二进制码。对大的概率赋“1”,小的概率赋“0”。
(3)从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字。
(4)计算码字的平均码长得出最后的编码效率。
4、实验数据记录
>> clear all
>> p=[0.20 0.18 0.15 0.17 0.19 0.10 0.01];
l=0;
H=0;
N=length(p);
for i=1:N
H=H+(-p(i)*log2(p(i)));
end
fprintf('信源信息熵:\n');
disp(H);
for i=1:N-1
for j=i+1:N
if p(i)<p(j)
m=p(j);
p(j)=p(i);
p(i)=m;
end
end
end
for i=1:N-1
c(i,:)=blanks(N*N);
end
c(N-1,N)='0';
c(N-1,2*N)='1';
for i=1:N-1 %对字符数组c码字赋值过程,记下沿路径的“1”和"0";
c(N-i,1:N-1)=c(N-i+1,N*(find(m(N-i+1,:)==1))-(N-2):N*(find(m(N-i+1,:)==1)));
c(N-i,N)='0';
c(N-i,N+1;2*N-1)=c(N-i,1:N-1);
c(N-i,2*N)='1';
for j=1:i-1
c(N-i,(j+1)*N+1:(j+2)*N)=c(N-i+1,N*(find(m(N-i+1,:)==j+1)-1)+1:N*find(m(N-i+1,:)==j+1));
end
end
for i=1:N
h(i,1:N)=c(1,N*(find(m(1,:)==i)-1)+1:find(m(1,:)==i)*N);%码字赋值
ll(i)=length(find(abs(h(i,:))~=32));%各码字码长
end
l=sum(p.*ll);%计算平均码长
n=H/l;%计算编码效率
fprintf('编码的码字:\n');
disp(h)%按照输入顺序从大到小排列后的码字
fprintf('平均码长:\n');
disp(l)%输出平均码长
fprintf('编码效率:\n');
disp(n)%输出编码效率

5、实验心得
由于我们的知识浅薄,经验不足及阅历颇浅,因此,在该程序的设计方面还有很多的不足,会在以后的学习过程中,根据所学的知识不断的修改、完善,争取慢慢趋于完美。
-
大三下-信息论实验报告
实验1绘制二进熵函数曲线串联信道容量曲线一实验内容用Excel或Matlab软件制作二进熵函数曲线串联信道容量曲线二实验环境1计算…
-
信息论实验报告
信息论实验实验一哈夫曼编码HuffmanCoding是一种编码方式哈夫曼编码是可变字长编码VLC的一种Huffman于19xx年提…
-
信息论实验报告
信息论与编码上机实验报告实验名称信息论与编码学院计算机与通信工程学院专业班级计算机1004姓名李春醒学号4105034920xx年…
-
信息论实验报告
实验一唯一可译码的判决准则实验目的1进一步熟悉唯一可译码的判决准则2掌握程序字符处理程序的设计和调试技术实验要求已知信源个数r码字…
-
信息论与编码实验报告
中南大学(信息论与编码实验报告)姓名:xxxxx学号:xxxxxxxx专业:电子信息工程班级:电子信息xxxx班指导老师:xx实验…
-
信息论与编码实验报告
课程名称姓名系专业年级学号指导教师职称实验报告信息论与编码年月日目录实验一信源熵值的计算1实验二Huffman信源编码5实验三Sh…
-
信息论与编码实验2-实验报告
中南大学信息论与编码题目关于编码的实验学生姓名杨家骏指导教师赵颖学院信息科学与工程学院学号0909101123专业班级电子信息10…
-
中南大学信息论与编码编码部分实验报告
信息论与编码编码部分实验报告课程名称信息论与编码实验名称关于香农码费诺码Huffman码的实验学院信息科学与工程学院班级电子信息工…
-
二元霍夫曼编码 - 信息论与编码实验报告
计算机与信息工程学院综合性实验报告一实验目的根据霍夫曼编码的原理用MATLAB设计进行霍夫曼编码的程序并得出正确的结果二实验仪器或…
-
信息论与编码实验报告
信息论与编码实验报告学院计算机与通信工程学院专业计算机科学与技术班级计1203班学号姓名20xx年12月29日实验一唯一可译码判别…
-
信息论与编码课程总结
信息论与编码《信息论与编码》这门课程给我带了很深刻的感受。信息论是人类在通信工程实践之中总结发展而来的,它主要由通信技术、概率论、…