信息论实验报告
信息论实验
实验一
* 哈夫曼编码(Huffman Coding)是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般叫作Huffman编码。
实验目的:
利用程序实现哈夫曼编码,以加深对哈夫曼编码的理解,并锻炼编程能力。
实验分析:
哈夫曼编码步骤:
一、对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合F= {T1,T2,T3,...,Ti,...,Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结点,它的左右子树均为空。(为方便在计算机上实现算 法,一般还要求以Ti的权值Wi的升序排列。)
二、在F中选取两棵根结点权值最小的树作为新构造的二叉树的左右子树,新二叉树的根结点的权值为其左右子树的根结点的权值之和。
三、从F中删除这两棵树,并把这棵新的二叉树同样以升序排列加入到集合F中。
四、重复二和三两步,直到集合F中只有一棵二叉树为止。
简易的理解就是,假如我有A,B,C,D,E五个字符,出现的频率(即权值)分别为5,4,3,2,1,那么我们第一步先取两个最小权值作为左右子树构造一个新树,即取1,2构成新树,其结点为1+2=3,如图:

虚线为新生成的结点,第二步再把新生成的权值为3的结点放到剩下的集合中,所以集合变成{5,4,3,3},再根据第二步,取最小的两个权值构成新树,如图:

再依次建立哈夫曼树,如下图:

其中各个权值替换对应的字符即为下图:

所以各字符对应的编码为:A->11,B->10,C->00,D->011,E->010
霍夫曼编码是一种无前缀编码。解码时不会混淆。其主要应用在数据压缩,加密解密等场合。
实验代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <conio.h>
#define MAXBIT 100
#define MAXVALUE 10000
#define MAXLEAF 30
#define MAXNODE MAXLEAF*2 -1
typedef struct
{
int bit[MAXBIT];
int start;
} HCodeType; /* 编码结构体 */
typedef struct
{
int weight;
int parent;
int lchild;
int rchild;
int value;
} HNodeType; /* 结点结构体 */
/* 构造一颗哈夫曼树 */
void HuffmanTree (HNodeType HuffNode[MAXNODE], int n)
{
/* i、j: 循环变量,m1、m2:构造哈夫曼树不同过程中两个最小权值结点的权值,
x1、x2:构造哈夫曼树不同过程中两个最小权值结点在数组中的序号。*/
int i, j, m1, m2, x1, x2;
/* 初始化存放哈夫曼树数组 HuffNode[] 中的结点 */
for (i=0; i<2*n-1; i++)
{
HuffNode[i].weight = 0;//权值
HuffNode[i].parent =-1;
HuffNode[i].lchild =-1;
HuffNode[i].rchild =-1;
HuffNode[i].value=i; //实际值,可根据情况替换为字母
} /* end for */
/* 输入 n 个叶子结点的权值 */
for (i=0; i<n; i++)
{
printf ("Please input weight of leaf node %d: \n", i);
scanf ("%d", &HuffNode[i].weight);
} /* end for */
/* 循环构造 Huffman 树 */
for (i=0; i<n-1; i++)
{
m1=m2=MAXVALUE; /* m1、m2中存放两个无父结点且结点权值最小的两个结点 */
x1=x2=0;
/* 找出所有结点中权值最小、无父结点的两个结点,并合并之为一颗二叉树 */
for (j=0; j<n+i; j++)
{
if (HuffNode[j].weight < m1 && HuffNode[j].parent==-1)
{
m2=m1;
x2=x1;
m1=HuffNode[j].weight;
x1=j;
}
else if (HuffNode[j].weight < m2 && HuffNode[j].parent==-1)
{
m2=HuffNode[j].weight;
x2=j;
}
} /* end for */
/* 设置找到的两个子结点 x1、x2 的父结点信息 */
HuffNode[x1].parent = n+i;
HuffNode[x2].parent = n+i;
HuffNode[n+i].weight = HuffNode[x1].weight + HuffNode[x2].weight;
HuffNode[n+i].lchild = x1;
HuffNode[n+i].rchild = x2;
printf ("x1.weight and x2.weight in round %d: %d, %d\n", i+1, HuffNode[x1].weight, HuffNode[x2].weight); /* 用于测试 */
printf ("\n");
} /* end for */
} /* end HuffmanTree */
//解码
void decodeing(char string[],HNodeType Buf[],int Num)
{
int i,tmp=0,code[1024];
int m=2*Num-1;
char *nump;
char num[1024];
for(i=0;i<strlen(string);i++)
{
if(string[i]=='0')
num[i]=0;
else
num[i]=1;
}
i=0;
nump=&num[0];
while(nump<(&num[strlen(string)]))
{tmp=m-1;
while((Buf[tmp].lchild!=-1)&&(Buf[tmp].rchild!=-1))
{
if(*nump==0)
{
tmp=Buf[tmp].lchild ;
}
else tmp=Buf[tmp].rchild;
nump++;
}
printf("%d",Buf[tmp].value);
}
}
int main(void)
{
HNodeType HuffNode[MAXNODE]; /* 定义一个结点结构体数组 */
HCodeType HuffCode[MAXLEAF], cd; /* 定义一个编码结构体数组, 同时定义一个临时变量来存放求解编码时的信息 */
int i, j, c, p, n;
char pp[100];
printf ("Please input n:\n");
scanf ("%d", &n);
HuffmanTree (HuffNode, n);
for (i=0; i < n; i++)
{
cd.start = n-1;
c = i;
p = HuffNode[c].parent;
while (p != -1) /* 父结点存在 */
{
if (HuffNode[p].lchild == c)
cd.bit[cd.start] = 0;
else
cd.bit[cd.start] = 1;
cd.start--; /* 求编码的低一位 */
c=p;
p=HuffNode[c].parent; /* 设置下一循环条件 */
} /* end while */
/* 保存求出的每个叶结点的哈夫曼编码和编码的起始位 */
for (j=cd.start+1; j<n; j++)
{ HuffCode[i].bit[j] = cd.bit[j];}
HuffCode[i].start = cd.start;
} /* end for */
/* 输出已保存好的所有存在编码的哈夫曼编码 */
for (i=0; i<n; i++)
{
printf ("%d 's Huffman code is: ", i);
for (j=HuffCode[i].start+1; j < n; j++)
{
printf ("%d", HuffCode[i].bit[j]);
}
printf(" start:%d",HuffCode[i].start);
printf ("\n");
}
printf("Decoding?Please Enter code:\n");
scanf("%s",&pp);
decodeing(pp,HuffNode,n);
getch();
return 0;
}
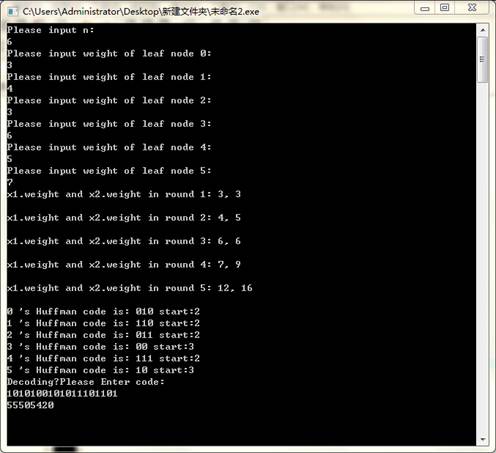
实验结果:
实验二
* 1950年,汉明描述了构造最小距离为3的编码的一般方法,现在称为汉明码。对于任意i值,其方法能产生(2i-1)位的编码,其中包含i个校验位和2i-1-i个信息位。
实验目的:
* 理解信道编码的原理,理解汉明码的基本原理与编码过程,利用程序实现汉明码编码,理解信道编码对可靠性的追求。
实验分析:
①汉明校验的基本思想
将有效信息按某种规律分成若干组,每组安排一个校验位,做奇偶测试,就能提供多位检错信息,以指出最大可能是哪位出错,从而将其纠正。实质上,汉明校验是一种多重校验。
②汉明校验的特点
它不仅具有检测错误的能力,同时还具有给出错误所在准确位置的能力。
一、校验位的位数 校验位的位数与有效信息的长度有关
设:N--为校验码的位数 K--是有效信息位 r--校验位(分成r组作奇偶校验,能产生r位检错信息)汉明码应满足 N=K+r≤2r-1 若r=3 则N=K+r≤7 所以K≤4

二.分组原则
在汉明码中, 位号数(1、2、3、……、n)为2的权值的那些位,即:
1(20)、2(21)、4(22)、8(23)、…2r-1位,作为奇偶校验位
并记作: P1、P2、P3 、P4、…Pr,余下各位则为有效信息位。
例如: N=11 K=7 r=4 相应汉明码可示意为
位号 1 2 3 4 5 6 7 8 9 10 11
P占位 P1 P2 × P3 × × × P4 × × ×
其中×均为有效信息,汉明码中的每一位分别被P1P2P3P4… Pr 中的一至若干位所校验,其规律是:
第i位由校验位位号之和等于i的那些校验位所校验
如:汉明码的位号为3,它被P1P2(位号分别为1,2)所校验
汉明码的位号为5,它被P1P3(位号分别为1,4)所校验
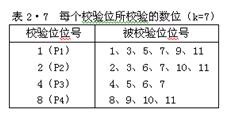
归并起来: 形成了4个小组,每个小组一个校验位,校验位的取值,仍采用奇偶校验方式确定。 如表 2·6 、表2·7所示:

三.编码、查错、纠错原理
以4位有效信息(b1、b2、b3、b4)和3位校验位(P1、P2、P3)为例: K=4 r=3
汉明序号 1 2 3 4 5 6 7
汉明码 P1 P2 b1 P3 b2 b3 b4
根据表2-8可以看到
(1)每个小组只有一位校验位,第一组是P1、第二组是P2、第三组是P3。
(2)每个校验位校验着它本身和它后面的一些确定位。

1.编码原理(采用偶校验)
1)若有效信息b1b2b3b4=1011 先将它们分别填入第3、5、6、7位
2)再分组进行奇偶统计,分别填入校验位P1、P2、P3的值
如:第一组有:P1b1b2b4 因b1b2b4含偶数个1,故P1应取值为0
第二组有:P2b1b3b4 因b1b3b4含奇数个1,故P2应取值为1
第三组有:P3b2b3b4 因b2b3b4含偶数个1,故P3应取值为0
汉明编码为:P1P2b1P3b2b3b4=0110011
2.查错与纠错
因为分三组校验,每组产生一位检错信息、3组共3位检错信息,便构成一个指误字,上例指误字由G1G2G3组成。
其中:
G3=P3?b2?b3?b4 P3b2b3b4=0011
G2=P2?b1?b3?b4 P2b1b3b4=1111
G1=P1?b1?b2?b4 P1b1b2b4=0101
采用偶校验,在没有出错情况下G1G2G3=000。由于在分组时,就确定了每一位参加校验的组别,所以指误字能准确地指出错误所在位。
如:若第3位b1出错,由于b1参加了第一组和第二组的校验,必然破坏了第一组和第二组的偶性,从而使G1和G2为1。 因为b1未参加第三组校验,故G3=0,所以构成的指误字G3G2G1=011它指出第3位出错。
反之:若G3G2G1=111 则说明汉明码第7位b4出错。因为只有第7位b4参加了3个小组的校验,破坏了三个小组的偶性。
假定:
源部件发送汉明码为:0110011 接收端接收汉明码为:0110011
则: 三个小组都满足偶校验要求,这时G3G2G1=000,表明收到信息正确,可以从中提出有效信息1011参与运算处理。
纠错:若接收端收到的汉明码为0110111,分组检测后指误字G3G2G1=101,它指出第5位出错,则只须将第5位变反,就可还原成正确的数码0110011。
实验代码:
//code by zxf 2010.4.10
#include <stdio.h>
#include <conio.h>
#include <math.h>
#include <stdlib.h>
//N代表待编码数据的上限位数
#define N 100
int HmLength(int k);//计算汉明码校验位位数
void InCode(char *data,char *c,int k,int r);//计算汉明码每个校验位的数值
int main()
{
int k=0,r=0,dnum=0,cnum=0;
char data[N];
char c[N];
system("cls");
printf("Now please input the data you want to Incode:");
for(k=0;k<N;k++)//循环输入待编码数据并记录数据长度,遇到非'1'非'0'输入结束输入
{
data[k]=getche();
if(data[k]!='0'&&data[k]!='1')
{
break;
}
}
printf("\n__________________________________________________________\n");
r=HmLength(k);//求取校验位数
printf("k=%d r=%d The length of Hamming code=%d\n",k,r,r+k);//输出汉明码相关位数信息
InCode(data,c,k,r);//计算汉明码
printf("The Hamming code is:");
for(int j=1;j<r+k+1;j++)//组合输出数据和校验码
{
if(j==(int)pow(2,cnum))
{
printf("%c",c[cnum]);
cnum++;
}
else
{
printf("%c",data[dnum]);
dnum++;
}
}
getch();
}
/*
*@func:计算校验码
*@param:data 待编码数据,c 校验码,k 数据长度,r 校验码位数
*code by zxf
*/
void InCode(char *data,char *c,int k,int r)
{
for(int i=0;i<r;i++)//循环计算第i位校验位
{
int sum=0,dnum=0,cnum=0;
for(int j=1;j<r+k+1;j++)//计算汉明码和矩阵第r-i列的乘积
{
if(j==(int)pow(2,cnum))//去掉矩阵的全零行
{
cnum++;//记录校验码循环位数
}
else
{
int x=0,y=0;
x=pow(2,i);
y=j%(x*2);
x=y/x;//通过取余取商计算获取矩阵第r-i列第j行元素的值
sum+=data[dnum]*x;//累加乘积
dnum++;//记录数据的循环位数
}
}
c[i]=sum%2==0?'0':'1';//通过结果的奇偶设置校验位的值
}
}
/*
*@func:计算校验码的位数
*@param: k 数据长度
*@return: 校验码位数
*code by zxf
*/
int HmLength(int k)
{
int r=0,flag=1;
while (flag!=0)//循环到2^r-1>=r+K时即得到校验码的位数
{
int temp=0;
temp=pow(2,r);
temp=temp-1;
flag=(temp-r-k<0);
r++;
}
return r-1;
}
实验结果:

实验三

实验分析:
卷积码的编码方法是对输入的数据流每次1比特或者K比特进行编码,输出N个编码字符。但输出的码字的每个码元不仅与当前时刻输入的K个信息有关也和之前的M个连续输入的信息员有关。因此卷积码是有记忆的。
输入信息序列为u=(u0,u1,…),其多项式表示为u(x)=u0+u1x+…+ulxl+…。编码器的连接可用多项式表示为g(1,1)(x)=1+x+x2和g(1,2)(x)=1+x2,称为码 的子生成多项式。它们的系数矢量g(1,1)=(111)和g(1,2)=(101)称作码的子生成元。以子生成多项式为阵元构成的多项式矩阵G(x)=[g(1,1)(x),g(1,2)(x)],称为码的生成多项式矩阵。
由生成元构成的半无限矩阵称为码的生成矩阵。其中(11,10,11)是由g(1,1)和g(1,2)交叉连接构成。编码器输出序列为c=u·G,称为码序列,其多项式表示为c(x),它可看作是两个子码序列c⑴(x)和c⑵(x)经过合路开关S合成的,其中c⑴(x)=u(x)g(1,1)(x)和c⑵(x)=u(x)g(1,2)(x),它们分别是信息序列和相应子生成元的卷积,卷积码由此得名。
在一般情况下,输入信息序列经过一个时分开关被分成k0个子序列,分别以u(x)表示,其中i=1,2,…k0,即u(x)=[u(x),…,u(x)]。编码器的结构由k0×n0阶生成多项式矩阵给定。输出码序列由n0个子序列组成,即c(x)=[c(x),c(x),…,c(x)],且c(x)=u(x)·G(x)。若m是所有子生成多项式g(x)中最高次式的次数,称这种码为(n0,k0,m)卷积码。
实验代码:
#include<iostream>
#include<math.h>
using namespace std;
int table1[8]={1,2,4,8,16,32,64,128};
int myn=0; //约束长度
int stalen=0; // 状态个数
int stan0[256][2]={0}; //输入0时个状态的输出
int stan1[256][2]={0}; //输入1时各状态的输出
int stachn[256][2]={0}; //状态转换表
int myg1[10]={0}; //用户输入生成序列1
int myg2[10]={0}; //用户输入生成序列2
int myout[100];
int myoutsym=0;
void chartobits(char ch,int *bits);
char bitstochar(int *bits);
void convolution(void);
//void creatsta(void);
void myoutput(int *p,int length,int depth);
void myinput(void); //用户可自行输入 约束长度和编码矢量
int main()
{
char exit_char;
myinput();
convolution();
cin>>exit_char;
}
void myinput(void)
{
int i,j,k,input[100]={0};
cout<<"请输入编码的约束长度M:(3<=M<=9)";
cin>>myn;
cout<<endl;
stalen=int(pow(2.0,myn-1));
cout<<"若选择默认的编码矢量则输入1,输入2则可输入其他的编码矢量:";
cin>>i;
cout<<endl;
cout<<"输入需要的二进制数据:";
cin>>k;
cout<<endl;
cout<<"请输入"<<k<<"位0、1序列:";
for(j=0;j<k;j++)
cin>>input[j];
cout<<endl;
if(i==1){
switch(myn){
case 3: myg1[0]=1,myg1[1]=1,myg1[2]=1;
myg2[0]=1,myg2[1]=0,myg2[2]=1;
break;
case 4: myg1[0]=1,myg1[1]=1,myg1[2]=1,myg1[3]=1;
myg2[0]=1,myg2[1]=0,myg2[2]=1,myg2[3]=1;
break;
case 5: myg1[0]=1,myg1[1]=0,myg1[2]=1,myg1[3]=1,myg1[4]=1;
myg2[0]=1,myg2[1]=1,myg2[2]=0,myg2[3]=1,myg2[4]=1;
break;
case 6: myg1[0]=1,myg1[1]=0,myg1[2]=1,myg1[3]=1,myg1[4]=1,myg1[5]=1;
myg2[0]=1,myg2[1]=1,myg2[2]=0,myg2[3]=1,myg2[4]=0,myg2[5]=1;
break;
case 7: myg1[0]=1,myg1[1]=0,myg1[2]=0,myg1[3]=1,myg1[4]=1,myg1[5]=1,myg1[6]=1;
myg2[0]=1,myg2[1]=1,myg2[2]=0,myg2[3]=1,myg2[4]=1,myg2[5]=0,myg2[6]=1;
break;
case 8: myg1[0]=1,myg1[1]=0,myg1[2]=0,myg1[3]=1,myg1[4]=1,myg1[5]=1,myg1[6]=1,myg1[7]=1;
myg2[0]=1,myg2[1]=1,myg2[2]=1,myg2[3]=0,myg2[4]=0,myg2[5]=1,myg2[6]=0,myg2[7]=1;
break;
case 9: myg1[0]=1,myg1[1]=1,myg1[2]=0,myg1[3]=1,myg1[4]=0,myg1[5]=1,myg1[6]=1,myg1[7]=1,myg1[8]=1;
myg2[0]=1,myg2[1]=0,myg2[2]=0,myg2[3]=0,myg2[4]=1,myg2[5]=1,myg2[6]=1,myg2[7]=0,myg2[8]=1;
break;
}
}
else{
cout<<"请输入生成序列g1"<<endl;
for(j=0;j<myn;j++)
cin>>myg1[j];
cout<<"输入g2"<<endl;
for(j=0;j<myn;j++)
cin>>myg2[j];
}
cout<<"生成序列g1为"<<endl;
for(j=0;j<myn;j++)
cout<<myg1[j]<<" ";
cout<<endl;
cout<<"生成序列g2为"<<endl;
for(j=0;j<myn;j++)
cout<<myg2[j]<<" ";
cout<<endl;
myoutput(input,k,myn);
}
void myoutput(int *p,int length,int depth)
{
int i,j,k,s[100],output[100];
int reg[depth];
for(i=0;i<depth;i++)
reg[i]=0;
for(i=0;i<length;i++)
{
output[i]=0;
s[i]=*p;
p++;
}
cout<<endl;
cout<<"寄存器状态 相应编码如下:"<<endl ;
for(i=0;i<length;i++)
{
for(j=depth-1;j>0;j--)
{
reg[j]=reg[j-1];
}
reg[0]=s[i];
for(j=0;j<depth;j++)
cout<<reg[j];
cout<<" ";
for(j=0;j<depth;j++)
{
output[i]+=myg1[j]*reg[j];
output[i+1]+=myg2[j]*reg[j];
}
output[i]=output[i]%2;
output[i+1]=output[i+1]%2;
cout<<output[i]<<output[i+1]<<endl;
output[i+1]=0;
}
cout<<endl;
}
void chartobits(char ch,int *bits)
{
int i;
for(i=0;i<8;i++){
if(ch<0)
bits[i]=1;
else
bits[i]=0;
ch=ch<<1;
}
}
char bitstochar(int *bits){
char temp=0;
int i;
for(i=0;i<8;i++){
if(bits[i]==1)
temp+=table1[7-i];
}
return temp;
}
void convolution(){
FILE *fp_input,*fp_output;
if(!(fp_input=fopen("D://input.txt","r"))==1){
cout<<endl<<"failed to open input_file"<<endl;
exit(0);
}
else
cout<<"we opened the input_file "<<endl;
if(!(fp_output=fopen("D://output.txt","w+"))==1){
cout<<"failed to open output_file"<<endl;
exit(0);
}
else
cout<<"we opened the output_file "<<endl;
char ch;
int i,j,temi;
int mybits[8],mytembits[8];
int mysta=0;
int wcout;
char wch;
for(ch=fgetc(fp_input);feof(fp_input)==0;ch=fgetc(fp_input)){
chartobits(ch,mybits);
cout<<"输入数据为"<<endl;
for(i=0;i<8;i++)
cout<<mybits[i]<<" ";
cout<<endl;
for(i=0;i<8;i++){
if(mybits[i]==0){
myout[myoutsym++]=stan0[mysta][0];
myout[myoutsym++]=stan0[mysta][1];
mysta=stachn[mysta][0];
}
else{
myout[myoutsym++]=stan1[mysta][0];
myout[myoutsym++]=stan1[mysta][1];
mysta=stachn[mysta][1];
}
}
cout<<"输出数据1为"<<endl;
for(temi=0;temi<myoutsym;temi++)
cout<<myout[temi]<<" ";
cout<<endl;
if(myoutsym>=8){
wcout=myoutsym/8;
for(i=0;i<wcout;i++){
for(j=0;j<8;j++)
mytembits[j]=myout[8*i+j];
wch=bitstochar(mytembits);
fputc(wch,fp_output);
cout<<"输出数据2为"<<endl;
cout<<wch<<" ";
}
for(i=0;i<myoutsym-wcout*8;i++)
myout[i]=myout[wcout*8+i];
myoutsym=myoutsym-wcout*8;
}
}
for(i=0;i<myn-1;i++){
myout[myoutsym++]=stan0[mysta][0];
myout[myoutsym++]=stan0[mysta][1];
mysta=stachn[mysta][0];
}
wcout=myoutsym/8;
for(i=0;i<wcout;i++){
for(j=0;j<8;j++)
mytembits[j]=myout[8*i+j];
wch=bitstochar(mytembits);
fputc(wch,fp_output);
}
for(i=0;i<myoutsym-wcout*8;i++)
myout[i]=myout[wcout*8+i];
myoutsym=myoutsym-wcout*8;
if(myoutsym!=0){
for(i=0;i<8-myoutsym;i++)
myout[myoutsym++]=0;
}
for(j=0;j<8;j++)
mytembits[j]=myout[j];
wch=bitstochar(mytembits);
fputc(wch,fp_output);
fclose(fp_input);
fclose(fp_output);
}
实验结果:

第四次实验
一.实验要求:信源编码和信道编码的联合编译码实现信源符号经过信源编码后在进行信道编码,经过信道后码字产生错误跳变,体现信道编码纠检错的功能,再进行信道译码和信源译码后,输出译出的信源符号。理解信源编码和信道编码的区别及联系。
二.实验代码:
代码:
#include<iostream>
#include<algorithm>
#include<string>
#define MAXNUM 1001
#define NUM 9
#define Pe 0.0001
using namespace std;
string input1();
void inputi();
void decode1(string);
class HMCoding
{
private:
int n,k,r;//汉明码参数
int i,j;//用于指示循环次数
int **H,*X,**G,**check_code;
string *H_Column,*H_Column_Z,code_str;
int code_num,code_num_z;
public:
void Initializing(int,int);
void Show_H(int,int);
void Get_G();
void Show_G(int,int);
void HM_Efficiency_Analysing();/*对汉明码进行编码效率分析*/
int Binary_Str_Check(string);
void Encoding();//汉明码编码
void Encoding_Z();//增余汉明码编码
void Decoding();//汉明码译码
void Decoding_Z();//增余汉明码译码
void Get_H_Column();//获取汉明码监督矩阵的每一列
void Get_H_Column_Z();//获取增余汉明码监督矩阵的每一列
void Get_Judge_Result();//获取汉明码校码结果
void Get_Judge_Result_Z();//获取增余汉明码校码结果
void Checking();//汉明码校码
void Checking_Z();//增余汉明码校码
void GOTO_HMCding_Z();
};
/********************************* 初 始 化 模 块 *********************************/
void HMCoding::Initializing(int _n,int _k)
{
n=_n;
k=_k;
r=_n-_k;
cout<<" 请 给 定 ( "<<n<<" , "<<k<<" ) 汉 明 码 的 监 督 矩 阵 H["<<r<<"]["<<n<<"]:"<<endl;
H=new int *[r+1]; //初始化(n,k)汉明码监督矩阵
for(i=0;i<r+1;i++)
H[i]=new int[n+1];
for(i=0;i<r;i++)
for(j=0;j<n;j++)
cin>>H[i][j]; //初始化增余项
for(j=0;j<n+1;j++)
H[r][j]=1;
for(i=0;i<r;i++)
H[i][n]=0; //为 X 分配存储单元
X=new int[n+1];
for(j=0;j<n+1;j++)
X[j]=0;
Get_H_Column();//获取监督矩阵的每一列
Get_H_Column_Z();//进一步获取增余监督矩阵的每一列
}
//获取监督矩阵的每一列,用于汉明码校码
void HMCoding::Get_H_Column()
{
string temp;
H_Column=new string[n+1];
for(i=0;i<n;i++)
{
temp="";
for(j=0;j<r;j++)
{
if(!H[j][i])
temp+='0';
else
temp+='1';
}
H_Column[i]=temp;
}
H_Column[n]="000";
}
//获取增余监督矩阵的每一列,用于增余汉明码校码
void HMCoding::Get_H_Column_Z()
{
H_Column_Z=new string[n+2];
for(i=0;i<n+1;i++)
H_Column_Z[i]=H_Column[i]+'1';
H_Column_Z[n+1]="0000";
}
void HMCoding::Show_H(int x,int y)
{
for(i=0;i<x;i++)
{
for(j=0;j<y;j++)
cout<<H[i][j]<<" ";
cout<<endl;
}
}
void HMCoding::Get_G()
{
G=new int *[k];
for(i=0;i<k;i++)
G[i]=new int[n];
for(i=0;i<k;i++)
for(j=0;j<k;j++)
{
if(i==j)
G[i][j]=1;
else G[i][j]=0;
}
for(i=0;i<r;i++)
for(j=0;j<k;j++)
G[j][i+k]=H[i][j];
}
void HMCoding::Show_G(int x,int y)
{
Get_G();
for(i=0;i<x;i++)
{
for(j=0;j<y;j++)
cout<<G[i][j]<<" ";
cout<<endl;
}
}
void HMCoding::HM_Efficiency_Analysing()
{
cout<<"对("<<n<<","<<k<<")汉明码的评价如下:"<<endl;
cout<<" ( "<<n<<" , "<<k<<" ) 汉 明 码 的 效 率 E=k/n*100%="<<k*1.0/n*100<<"%"<<endl;
cout<<" ( "<<n<<" , "<<k<<" ) 汉 明 码 的 错 误 概 率 P=n*(n-1)*Pe*Pe="<<n*(n-1)*Pe*Pe<<endl;
inputi();
}
/********************************* 编 码 模 块 *********************************/
//二进制序列合理性检测
int HMCoding::Binary_Str_Check(string temp)
{
int flag=1;//先假设输入的消息串不含除 0、1 外的字符
for(int i=0;i<temp.length();i++)
{
if(!(temp[i]=='0'||temp[i]=='1'))
{
flag=0;
break;
}
}
return flag;
}
//汉明码编码
void HMCoding::Encoding()
{
A: string binary_str;
int flag;
int binary_num=0;
binary_str=input1();//将Huffman编码后结果作为信道编码输入
flag=Binary_Str_Check(binary_str);
while(binary_num<binary_str.length())
binary_num++;/*统计输入的二进制序列所含码元个数*/
if(binary_num%k!=0&&flag)/*序列所含码元个数不是 k 的整数倍,无法全部编码*/
{
cout<<"您输入的二进制序列存在冗余,请重新输入!\n";
goto A;
}
if(binary_num%k!=0&&!flag)
{
cout<<"您输入的二进制序列存在冗余且含除 0、1 外的字符,请重新 输入!\n";
goto A;
}
if(binary_num%k==0&&!flag)
{
cout<<"您输入的二进制序列含除 0、1 外的字符,请重新输入!\n";
goto A;
}
code_str="";
for(i=0;i<binary_num;i=i+k)
{
for(j=0;j<k;j++)/*获取 k 位信息元*/
{
if(binary_str[i+j]=='0')
X[j]=0;
else X[j]=1;
}
int temp;
string partial_str="";
for(int t=0;t<n;t++)
{
/*用 k 位信息元组成的向量与生成矩阵作矩阵乘法,得到对应 n 元 码组*/
temp=0;
for(j=0;j<k;j++)
temp+=X[j]*G[j][t];
if(temp%2==0)
partial_str+='0';
else partial_str+='1';
}
code_str+=partial_str;
}
cout<<"进行("<<n<<","<<k<<")汉明码编码后的二进制序列为: \n"<<code_str<<endl;
}
//增余汉明码编码
void HMCoding::Encoding_Z()
{
code_str="";
A_Z:string binary_str;
int flag;
int binary_num=0;
binary_str=input1();//将Huffman编码后结果作为信道编码输入
flag=Binary_Str_Check(binary_str);
while(binary_num<binary_str.length())
binary_num++;/*统计输入的二进制序列所含码元个数*/
if(binary_num%k!=0&&flag)/*序列所含码元个数不是 k 的整数倍,无法全部编码*/
{
cout<<"您输入的二进制序列存在冗余,请重新输入!\n";
goto A_Z;
}
if(binary_num%k!=0&&!flag)
{
cout<<"您输入的二进制序列存在冗余且含除 0、1 外的字符,请重新 输入!\n";
goto A_Z;
}
if(binary_num%k==0&&!flag)
{
cout<<"您输入的二进制序列含除 0、1 外的字符,请重新输入!\n";
goto A_Z;
}
for(i=0;i<binary_num;i=i+k)
{
for(j=0;j<k;j++)/*获取 k 位信息元*/
{
if(binary_str[i+j]=='0')
X[j]=0;
else X[j]=1;
}
int temp;
string partial_str="";
for(int t=0;t<n;t++)
{
/*用 k 位信息元组成的向量与生成矩阵作矩阵乘法,得到对应 n 元 码组*/
temp=0;
for(j=0;j<k;j++)
temp+=X[j]*G[j][t];
if(temp%2==0)
{
partial_str+='0';
X[j+k]=0;
}
else
{
partial_str+='1';
X[j+k]=1;
}
} //生成增余汉明码最后一位
//监督规则:对原汉明码所有 n 个码元取模 2 和
int sum=0;
for(j=0;j<n;j++)
sum+=X[j];
if(sum%2==0)
partial_str+='0';
else
partial_str+='1';
code_str+=partial_str;
}
cout<<"进行 ("<<n+1<<", "<<k<<") 增余汉明码编码后的二进制序列为: \n"<<code_str<<endl;
}
/********************************* 校 码 模 块 *********************************/
//利用汉明码校码
void HMCoding::Checking()
{
B: string binary_str;
int flag;
int binary_num=0;
cout<<"请输入待译的二进制序列:"<<endl;
cin>>binary_str;
flag=Binary_Str_Check(binary_str);
while(binary_num<binary_str.length())
binary_num++;/*统计输入的二进制序列所含码元个数*/
if(binary_num%n!=0&&flag)/*序列所含码元个数不是 n 的整数倍,无法 全部译码*/
{
cout<<"您输入的二进制序列存在冗余,请重新输入!\n";
goto B;
}
if(binary_num%n!=0&&!flag)
{
cout<<"您输入的二进制序列存在冗余且含除 0、1 外的字符,请重新 输入!\n";
goto B;
}
if(binary_num%n==0&&!flag)
{
cout<<"您输入的二进制序列含除 0、1 外的字符,请重新输入!\n";
goto B;
}
code_num=binary_num/n;//统计 n 元码组的个数
check_code=new int*[code_num];
for(i=0;i<code_num;i++)
check_code[i]=new int[n];
for(i=0;i<code_num;i++)
{
/*每次取 n 个码元进行校正*/
for(j=0;j<n;j++)
{
check_code[i][j]=binary_str[i*n+j]-'0';
}
}
Get_Judge_Result();
}
//利用增余汉明码校码
void HMCoding::Checking_Z()
{
B_Z:string binary_str;
int flag;
int binary_num=0;
cout<<"请输入待译的二进制序列:"<<endl;
cin>>binary_str;
flag=Binary_Str_Check(binary_str);
while(binary_num<binary_str.length())
binary_num++;/*统计输入的二进制序列所含码元个数*/
if(binary_num%(n+1)!=0&&flag)/*序列所含码元个数不是 n+1 的整数倍, 无法全部译码*/
{
cout<<"您输入的二进制序列存在冗余,请重新输入!\n";
goto B_Z;
}
if(binary_num%(n+1)!=0&&!flag)
{
cout<<"您输入的二进制序列存在冗余且含除 0、1 外的字符,请重新输入!\n";
goto B_Z;
}
if(binary_num%(n+1)==0&&!flag)
{ cout<<"您输入的二进制序列含除 0、1 外的字符,请重新输入!\n";
goto B_Z;
}
code_num_z=binary_num/(n+1);//统计 n+1 元码组的个数
check_code=new int*[code_num_z];
for(i=0;i<code_num_z;i++)
check_code[i]=new int[n+2];
for(i=0;i<code_num_z;i++)
{
/*每次取 n+1 个码元进行校正*/
for(j=0;j<n+1;j++)
{
check_code[i][j]=binary_str[i*(n+1)+j]-'0';
}
}
Get_Judge_Result_Z();
}
//获取汉明码校码结果
void HMCoding::Get_Judge_Result()
{
int temp;
int flag;
string partial_str;
cout<<"("<<n<<","<<k<<")汉明码校码结果如下:"<<endl;
cout<<"码组 状态 "<<endl;
for(int t=0;t<code_num;t++)
{
flag=0;
partial_str="";
for(i=0;i<r;i++)
{
temp=0;
for(j=0;j<n;j++)
temp+=H[i][j]*check_code[t][j];
if(temp%2==0)
partial_str+='0';
else
partial_str+='1';
} //对 partial_str 进行判断校正后
for(i=0;i<n+1;i++)
{
if(H_Column[i]==partial_str)
{
flag=1;
break;
}
}
if(flag&&i<n)//表示第 i 个码元出错,将其改正
{
for(j=0;j<n;j++)
cout<<check_code[t][j];
cout<<" 第"<<i+1<<"位错,可纠正 ";
check_code[t][i]=(check_code[t][i]+1)%2;//1 变 0,0 变 1
for(j=0;j<n;j++)
cout<<check_code[t][j];
}
if(flag&&i==n)//表示全对
{
for(j=0;j<n;j++)
cout<<check_code[t][j];
cout<<" 全对 ";
for(j=0;j<n;j++)
cout<<check_code[t][j];
} cout<<endl;
}
}
//获取增余汉明码校码结果
void HMCoding::Get_Judge_Result_Z()
{
int temp;
int flag;
string partial_str;
cout<<"("<<n+1<<","<<k<<")增余汉明码校码结果如下(注:* 表示 无法识别的码元) :"<<endl;
cout<<"码组 状态 校正后 "<<endl;
for(int t=0;t<code_num_z;t++)
{
flag=0;
partial_str="";
for(i=0;i<r+1;i++)
{
temp=0;
for(j=0;j<n+1;j++)
temp+=H[i][j]*check_code[t][j];
if(temp%2==0)
partial_str+='0';
else
partial_str+='1';
}
//对 partial_str 进行判断
for(i=0;i<n+2;i++)
{
if(H_Column_Z[i]==partial_str)
{
flag=1;
break;
}
}
if(flag&&i<n+1)//表示第 i 个码元出错,将其改正
{
check_code[t][n+1]=1;//表示正确接收
for(j=0;j<n+1;j++)
cout<<check_code[t][j];
cout<<" 第"<<i+1<<"位错,可纠正 ";
check_code[t][i]=(check_code[t][i]+1)%2;//1 变 0,0 变 1
for(j=0;j<n+1;j++)
cout<<check_code[t][j];
}
if(flag&&i==n+1)//表示全对
{
check_code[t][n+1]=1;//表示正确接收
for(j=0;j<n+1;j++)
cout<<check_code[t][j];
cout<<" 全对 ";
for(j=0;j<n+1;j++)
cout<<check_code[t][j];
}
if(!flag)
{
check_code[t][n+1]=0;//表示两位出错并无法纠正
for(j=0;j<n+1;j++)
cout<<check_code[t][j];
cout<<" 某两位出错,无法纠正 ";
for(j=0;j<n+1;j++)
cout<<'*';//* 表示无法正确识别的码元
}
cout<<endl;
}
}
/********************************* 译 码 模 块 *********************************/
//利用汉明码译码
void HMCoding::Decoding()
{
string decstr;
cout<<"("<<n<<","<<k<<")汉明码译码结果为:"<<endl;
for(i=0;i<code_num;i++)
{
for(j=0;j<k;j++)
{
cout<<check_code[i][j];
if(!check_code[i][j])
decstr+='0';
else
decstr+='1';
}
}
cout<<endl;
cout<<"Huffman译码结果为:"<<endl;
decode1(decstr);//将信道译码结果作为信源译码的输入
cout<<endl;
}
//利用增余汉明码译码
void HMCoding::Decoding_Z()
{
string decstr;
cout<<"("<<n+1<<","<<k<<")增余汉明码译码结果为(注:* 表示无 法识别的码元,默认置为0) :"<<endl;
for(i=0;i<code_num_z;i++)
{
if(check_code[i][n+1]==1)
{
for(j=0;j<k;j++)
{
cout<<check_code[i][j];
if(!check_code[i][j])
decstr+='0';
else
decstr+='1';
}
}
else
{
for(j=0;j<k;j++) cout<<'*';
decstr+='0';
}
}
cout<<endl;
cout<<"Huffman译码结果为:"<<endl;
decode1(decstr);//将信道译码结果作为信源译码的输入
cout<<endl;
}
HMCoding hmcoding;//全局变量
//哈夫曼树的节点
typedef struct node
{
//树节点的标志
char data;
//树节点的权重
int weight;
//左右孩子
int lchild;
int rchild;
//是否已经被放入树中
bool tag;
}myNode;
myNode nodes[100];
char mycode[100];
char ch[]={'A','C','I','M','N','P','T','U','S'};
int index=-1;
int index1=-1;
//记录每个字母的哈弗曼编码
string str[NUM];
myNode recordNode;
/********************************* Huffman **********************************/
bool compare(myNode mynode1,myNode mynode2)
{
return mynode1.weight<mynode2.weight;
}
bool judge()
{
int record=0;
for(int i=0;i<=index;i++)
{
if(nodes[i].tag==false)
{
record++;
recordNode=nodes[i];
}
}
if(record==0||(record==1&&recordNode.data=='#'))
{
return true;
}
return false;
}
int findNode()
{
for(int i=0;i<=index;i++)
{
if(nodes[i].tag==false)
{
nodes[i].tag=true;
return i;
}
}
return -1;
}
//编码
bool code(myNode *root,char ch1)
{
bool tag=false;
if(root->data==ch1)
{
return true;
}
int arr[2];
arr[0]=root->lchild;
arr[1]=root->rchild;
for(int i=0;i<2;i++)
{
if(arr[i]!=-1)
{
tag=code(&nodes[arr[i]],ch1);
if(tag)
{
if(i==0)
{
mycode[++index1]='0';
}
else if(i==1)
{
mycode[++index1]='1';
}
}
if(tag)
{
return tag;
}
}
}
return tag;
}
//创建哈弗曼树
void createTree()
{
while(!judge())
{
//按照权重由小到大排序
sort(nodes,nodes+index+1,compare);
myNode newNode;
newNode.data='#';
newNode.lchild=findNode();
newNode.rchild=findNode();
newNode.weight=nodes[newNode.lchild].weight+nodes[newNode.rchild].weight;
newNode.tag=false;
nodes[++index]=newNode;
}
}
//输出字母对应的编码
string outputCode(char cha)
{
string outstr;
for(int i=0;i<NUM;i++)
{
if(cha==ch[i])
{
cout<<str[i];
outstr+=str[i];
}
}
return outstr;
}
//译码
void decode1(string inputstr)
{
int kkindex=-1;
int len=inputstr.length()-1;
while(kkindex<len)
{
bool find=false;
myNode tempNode=nodes[index];
char ch;
while(!find&&kkindex<len)
{
++kkindex;
if(inputstr[kkindex]=='0')
{
tempNode=nodes[tempNode.lchild];
}
else
{
tempNode=nodes[tempNode.rchild];
}
ch=tempNode.data;
if(ch!='#')
{
find=true;
}
}
if(ch!='#')
{
cout<<ch;
}
}
}
/********************************* 辅 助 函 数 *********************************/
void inputi()
{
cout<<"请给各字符赋权值~~\n";
for(int i=0;i<NUM;i++)
{
int data;
cin>>data;
nodes[++index].data=ch[i];
nodes[index].weight=data;
nodes[index].lchild=-1;
nodes[index].rchild=-1;
nodes[index].tag=false;
}
//构造哈夫曼树
createTree();
//recordNode故为树的根
for(int i=0;i<NUM;i++)
{
index1=-1;
code(&(nodes[index]),ch[i]);
str[i]="";
for(int j=index1;j>=0;j--)
{
str[i]+=mycode[j];
}
}
cout<<"对各字符的Huffman编码为:"<<endl;
//输出
for(int i=0;i<NUM;i++)
{
cout<<ch[i]<<": ";
cout<<str[i]<<endl;
}
}
string input1()
{
cout<<"请输入将要编码的字符串:"<<endl;
//获得输入的字符串
string inputstr;
string ouputstr;
cin>>inputstr;
cout<<"Huffman编码结果为:"<<endl;
for(int i=0;i<inputstr.length();i++)
{
ouputstr+=outputCode(inputstr[i]);
}
cout<<endl;
return ouputstr;
}
/********************************* 主 函 数 *********************************/
void HMCoding::GOTO_HMCding_Z()
{
char choice1=' ';
cout<<"\n ************欢迎进入Huffman码、("<<n+1<<","<<k<<")增余汉明码编码/校码/译码系统*************\n";
cout<<"由汉明监督矩阵导出的增余监督矩阵 H["<<r+1<<"]["<<n+1<<"] 为:"<<endl;
hmcoding.Show_H(r+1,n+1);
Z: cout<<"\n >>>>>>>>>>>>>>>>>>Huffman码、("<<n+1<<","<<k<<")增余汉明码编码/校码/译码系统<<<<<<<<<<<<<<<<<\n";
cout<<" "<<"E.信源、信道编码"<<" "<<"D.信道、信源校码 /译码"<<" "<<"R.返回"<<" "<<"Q.退出"<<endl;
cout<<"请输入您要操作的步骤:";
cin>>choice1;
if(choice1=='E'||choice1=='e')//进行编码
{
hmcoding.Encoding_Z();
goto Z;
}
else if(choice1=='D'||choice1=='d')
{
hmcoding.Checking_Z();
hmcoding.Decoding_Z();
goto Z;
}
else if(choice1=='R'||choice1=='r')
return;
else if(choice1=='Q'||choice1=='q')//退出
{
exit(0);
}
else//如果选了选项之外的就让用户重新选择
{
cout<<"您没有输入正确的步骤,请重新输入!"<<endl;
goto Z;
}
cout<<endl;
}
int main()
{
char choice=' '; //用于记录初始化情况
int flag=0;
int n,k;
cout<<"\n *************************信源、信道编码/ 校码/ 译码系统*************************\n";
cout<<"请输入汉明码的码长 n=";
cin>>n;
cout<<"请输入汉明码的信息元个数 k=";
cin>>k;
while(choice!='Q'&&choice!='q')//当 choice 的值不为 q 且不为 Q 时循环
{
C: cout<<"\n >>>>>>>>>>>>>>>>>>>>Huffman码、("<<n<<","<<k<<")汉明码编码/校码/译码系统<<<<<<<<<<<<<<<<<\n";
cout<<" "<<"I.输入建立"<<" "<<"E.信源、信道编码"<<" "<<"D.信道、信源校码/译码\n";
cout<<" "<<"Z. 进 入 相 应 的 增 余 汉 明 码 系 统 "<<" "<<"Q.退出\n"; cout<<"请输入您要操作的步骤:";
cin>>choice;
if(choice=='I'||choice=='i')//初始化
{
if(!flag)
{
//初次执行初始化操作
flag=1;
}
hmcoding.Initializing(n,k);
cout<<"您输入的监督矩阵 H["<<n-k<<"]["<<n<<"]为:"<<endl;
hmcoding.Show_H(n-k,n);
cout<<" 该 监 督 矩 阵 对 应 的 生 成 矩 阵 G["<<k<<"]["<<n<<"] 为:"<<endl;
hmcoding.Show_G(k,n); hmcoding.HM_Efficiency_Analysing();
}
else if(choice=='E'||choice=='e')//进行编码
{
if(!flag)
{
cout<<" 操 作 错 误 ! 请 执 行 输 入 建 立 操 作 后 再 进 行 本 操 作!"<<endl;
goto C;
}
hmcoding.Encoding();
}
else if(choice=='D'||choice=='d')//校码、译码
{
if(!flag)
{
cout<<" 操 作 错 误 ! 请 执 行 输 入 建 立 操 作 后 再 进 行 本 操 作!"<<endl;
goto C;
}
hmcoding.Checking();
hmcoding.Decoding();
}
else if(choice=='Z'||choice=='z')
{
if(!flag)
{
cout<<" 操 作 错 误 ! 请 执 行 输 入 建 立 操 作 后 再 进 行 本 操 作!"<<endl;
goto C;
}
//进入增余汉明码系统
hmcoding.GOTO_HMCding_Z();
}
else if(choice=='Q'||choice=='q')//退出
{
exit(0);
}
else//如果选了选项之外的就让用户重新选择
{
cout<<"您没有输入正确的步骤,请重新输入!"<<endl;
goto C;
}
cout<<endl;
}
return 0;
}
三.实验运行:




实验心得:
通过本次实验,我们小组成员对哈夫曼编码、汉明码和卷积码的概念有了进一步认识,并对其编码过程有了熟悉。并通过对程序的编写更形象生动地表现了其编码过程,并对其编码原理有了更深一层的认知。
-
大三下-信息论实验报告
实验1绘制二进熵函数曲线串联信道容量曲线一实验内容用Excel或Matlab软件制作二进熵函数曲线串联信道容量曲线二实验环境1计算…
-
信息论实验报告
信息论实验实验一哈夫曼编码HuffmanCoding是一种编码方式哈夫曼编码是可变字长编码VLC的一种Huffman于19xx年提…
-
信息论实验报告
信息论与编码上机实验报告实验名称信息论与编码学院计算机与通信工程学院专业班级计算机1004姓名李春醒学号4105034920xx年…
-
信息论实验报告
实验一唯一可译码的判决准则实验目的1进一步熟悉唯一可译码的判决准则2掌握程序字符处理程序的设计和调试技术实验要求已知信源个数r码字…
-
信息论与编码实验报告
中南大学(信息论与编码实验报告)姓名:xxxxx学号:xxxxxxxx专业:电子信息工程班级:电子信息xxxx班指导老师:xx实验…
-
信息论与编码实验报告
课程名称姓名系专业年级学号指导教师职称实验报告信息论与编码年月日目录实验一信源熵值的计算1实验二Huffman信源编码5实验三Sh…
-
信息论与编码实验报告-Shannon编码
课程名称姓名系专业年级学号指导教师职称实验报告信息论与编码年月日1实验三Shannon编码一实验目的1熟悉离散信源的特点2学习仿真…
-
信息论与编码实验指导书
信息论与编码实验指导书河北工业大学信息工程学院信息论与编码课程组20xx年2月前言当前信息论与编码已经成为电子信息类专业高年级学生…
-
信息论与编码实验2-实验报告
中南大学信息论与编码题目关于编码的实验学生姓名杨家骏指导教师赵颖学院信息科学与工程学院学号0909101123专业班级电子信息10…
-
《信息论与编码》实验讲义
信息论与编码实验讲义学生实验守则1进实验室前必须根据每个实验的预习要求阅读有关资料2按时进入实验室保持安静和整洁独立完成实验3实验…