数据挖掘聚类算法课程设计报告
数据挖掘聚类问题(Plants Data Set)实验报告
1.数据源描述
1.1数据特征
本实验用到的是关于植物信息的数据集,其中包含了每一种植物(种类和科属)以及它们生长的地区。数据集中总共有68个地区,主要分布在美国和加拿大。一条数据(对应于文件中的一行)包含一种植物(或者某一科属)及其在上述68个地区中的分布情况。可以这样理解,该数据集中每一条数据包含两部分内容,如下图所示。

图1 数据格式
例如一条数据:abronia fragrans,az,co,ks,mt,ne,nm,nd,ok,sd,tx,ut,wa,wy。其中abronia fragrans是植物名称(abronia是科属,fragrans是名称),从az一直到wy是该植物的分布区域,采用缩写形式表示,如az代表的是美国Arizona州。植物名称和分布地区用逗号隔开,各地区之间也用逗号隔开。
1.2任务要求
聚类。采用聚类算法根据某种特征对所给数据集进行聚类分析,对于聚类形成的簇要使得簇内数据对象之间的差异尽可能小,簇之间的差距尽可能大。
2.数据预处理
2.1数据清理
所给数据集中包含一些对聚类过程无用的冗余数据。数据集中全部数据的组织结构是:先给出某一科属的植物及其所有分布地区,然后给出该科属下的具体植物及其分布地区。例如:
?abelmoschus,ct,dc,fl,hi,il,ky,la,md,mi,ms,nc,sc,va,pr,vi
?abelmoschus esculentus,ct,dc,fl,il,ky,la,md,mi,ms,nc,sc,va,pr,vi
?abelmoschus moschatus,hi,pr
上述数据中第?行给出了所有属于abelmoschus这一科属的植物的分布地区,接下来的??两行分别列出了属于abelmoschus科属的两种具体植物及其分布地区。从中可以看出后两行给出的所有地区的并集正是第一行给出的地区集合。在聚类过程中第?行数据是无用的,因此要对其进行清理。
2.2数据变换
本实验是依据植物的分布区域进行聚类,所给数据集中的分布区域是字符串形式,不适合进行聚类,因此将其变换成适合聚类的数值形式。具体思想如下:
数据集中总共包含68个区域,每一种植物的分布区域是这68个区域中的一部分。本实验中将68个区域看成是数据对象的68个属性,这68个属性是二元类型的变量,其值只能去0或者1。步骤如下:
1.把68个区域按一定顺序存放在字符串数组(记为str)中(顺序可以自己定,确定后不能改变)。
2.为数据集中的每个数据对象设置一个长度为68字符串数组,初始元素值全为0。将数据对象的分布区域逐个与str中的所有元素比较。如果存在于str中下标i的位置,就将该数据对象的字符串数组的第i位置为1。
例如,一个数据对象为:abies fraseri,ga,nc,tn,va。其分布区域包含ga,nc,tn和va四个地区,将这四个地区逐个与str中全部68个元素比较。假设这四个地区分别存在于str中的第0,1,2,3位置,则将为该数据对象设置的字符串数组中第0,1,2,3位置全部置为1。
★数据预处理代码(包括数据清理和数据变换):
public ArrayList<String> getRaw_DataSet() {
ArrayList<String> raw_dataSet = new ArrayList<String>();// 定义集合存储从本地获取的数据
BufferedReader bufferedReader = null;
FileReader fileReader = null;
File dataFile = new File(this.fileName);
if (dataFile.exists()) {// 如果数据文件存在
try {
fileReader = new FileReader(this.fileName);
bufferedReader = new BufferedReader(fileReader);
String data = null;
while ((data = bufferedReader.readLine()) != null) {
if (isRightData(data))
raw_dataSet.add(data);
}
} catch (Exception e) {
e.printStackTrace();
}
} else
this.isFileExit = false;
return raw_dataSet;
}// getRaw_DataSet,从本地txt文件获取数据集
public ArrayList<DataItem> getFinished_DataSet() {// 获取经过预处理,用来进行聚类的数据
ArrayList<DataItem> finished_DataSet = new ArrayList<DataItem>();
ArrayList<String> temp_DataSet = this.getRaw_DataSet();
for (int i = 0; i < temp_DataSet.size(); i++) {
ArrayList<String> eachRomItem = null;
eachRomItem = this.spilt(temp_DataSet.get(i), ',');// 除去","后的每一行数据
DataItem data_Item = new DataItem(eachRomItem, true);
finished_DataSet.add(data_Item);
}// for
return finished_DataSet;
}
publicboolean isRightData(String data) {// 筛选出合适的数据
ArrayList<String> tempArrayList = new ArrayList<String>();
tempArrayList = spilt(data, ' ');
if (tempArrayList.size() <= 1)
returnfalse;
returntrue;
}// isRightData,筛选出合适的数据
public ArrayList<String> spilt(String str, char ch) {
ArrayList<String> words = new ArrayList<String>();// 用来存放找到的单词
int beginIndex = 0;
for (int i = 0; i < str.length(); i++) {
if (str.charAt(i) != ch) {
if (i != str.length() - 1)
continue;
else {
words.add(str.substring(beginIndex));
}
} else {
String temp = str.substring(beginIndex, i);
words.add(temp);
beginIndex = i + 1;
}
}// for
return words;
}
3.聚类分析
3.1 算法描述
本实验采用了聚类分析中常用的K均值(K-Means)算法。该算法思想如下:
算法:K均值。用于划分的K均值算法,每个簇的中心用簇中对象的均值表示。
输入:
■k:簇的属目
■D:包含n个对象的数据集。
输出:k个簇的集合。
方法:
(1)从D中任意选择k个对象作为初始簇中心;
(2)repeat
(3) 根据簇中对象的均值,将每个对象(再)指派到最相似的簇;
(4) 更新簇均值,既计算每个簇中对象的均值;
(5)until 不再发生变化
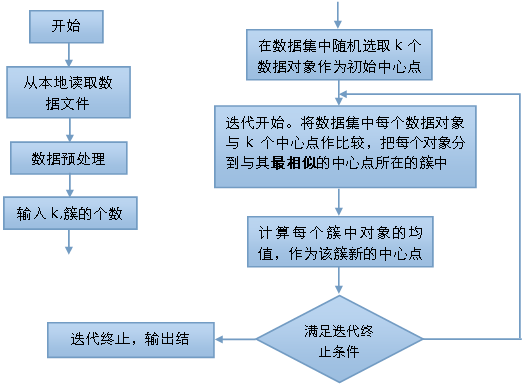 根据上述算法,结合本实验实际情况和数据集特征给出程序的执行流程图:
根据上述算法,结合本实验实际情况和数据集特征给出程序的执行流程图:
?

 ?
?
图2 程序执行流程
针对上面的流程图,有几点说明:
1.数据预处理主要包括前述数据清理和数据变换,最终生成用于聚类分析的数据集。
2.簇的个数k由用户指定,k越大聚类过程耗时越久。
3.图中“最相似”意思就是距离中心点距离最近,本实验中采用欧几里得距离,其定义如下:
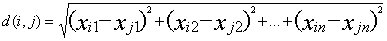
其中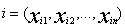 和
和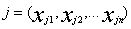 是两个n维数据对象。在本实验中,
是两个n维数据对象。在本实验中,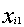 和
和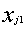 分别代表为i,j两个数据对象设置的字符串数组(参看2.2)中下标为1的元素值,此处n为68。
分别代表为i,j两个数据对象设置的字符串数组(参看2.2)中下标为1的元素值,此处n为68。
4.流程图中的终止条件指的是:前后两次中心点之间的距离(仍然用欧几里得距离)是否小于设定的值。例如,第n次迭代完成后重新生成了k个新的中心点,计算k个新中心点与k个旧的中心点距离之和并将结果与设定的值比较,若小于设定值则终止迭代,聚类完成,否则继续迭代。
3.2 算法实现
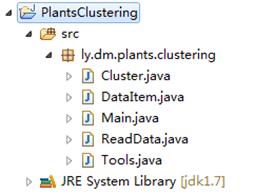
图3 代码文件的组织结构
上图是本实验源码的组织结构,该项目包含五个Java类。每个类的功能描述如下:
◆Cluster.java类 该类定义了簇的结构,包含簇标志,簇成员和簇中心点三个字段。该类的每一个实例对应于聚类过程中的一个簇。
◆DataItem.java类 该类定义了数据对象的结构,主要包含数据对象名称(即植物名称)和数据对象字符串数组(即植物的分布区域)。该类的每一个实例对应于数据集中的一个数据对象。
◆Main.java类 该类是程序的核心类,主要功能是执行聚类过程,包括中心点的选取与更新,计算各个数据对象与中心点之间的距离并把其派分到最相似的簇等。
◆ReadData.java类 该类主要功能是生成聚类过程适用的数据集,包括读取文件,数据预处理等。
◆Tools.java类 该类是一个工具类,其中定义了多个程序中使用到的静态方法。
★Mian.java类中的核心代码:
(1) 随机选取中心点
publicvoid setCenter_ran() {// 第一次,从数据集中随机选取中心点
beginTime = System.currentTimeMillis();
System.out.println("聚类过程开始,开始于:" + Tools.currentTime());
Random ran = new Random();
int order = 0;// 随机选取中心点
while (this.center.size() < numOfCluster) {
order = ran.nextInt(toBeProcessed.size());
if (Tools.isProCener(toBeProcessed.get(order), this.center))
this.center.add(toBeProcessed.get(order));
}// while
}
(2)初始化簇集合
publicvoid initArrayCluster(ArrayList<DataItem> center) {// 初始每个簇中的中心点属性
this.arrayCluster.clear();// 把簇集合清空
for (int i = 0; i < center.size(); i++) {
Cluster cluster = new Cluster(i, center.get(i));
if (this.center.get(i).getIsDataItem())
cluster.addMembers(center.get(i));
this.arrayCluster.add(cluster);
}
}
(3)执行聚类过程(计算距离,把数据对象派分到最相似簇中)
publicvoid runCluster(ArrayList<DataItem> center) {
int beyondIndex = 0;// 判断数据项属于哪一个簇,初始默认为是0簇
Random rd = new Random();// 随机函数
printBeginInfo();// 打印以此迭代开始前的信息。
for (int i = 0; i < toBeProcessed.size(); i++) {
beyondIndex = 0;
boolean isAlreadyExitInCluster = true;// 标记当前处理的数据对象是否已经存在于某个簇中
double minDistance = Tools.calcDistance(toBeProcessed.get(i),
center.get(0), 0);
int ranIndex = rd.nextInt(center.size());// 随机产生一个中心点集合的索引
for (int j = 0; j < center.size(); j++) {// 分别与每一个中心点进行比较
if (center.contains(toBeProcessed.get(i)))// 如果正在处理的数据对象存在于中心点集合中,则跳出循环
break;
isAlreadyExitInCluster = false;
if (ranIndex >= center.size())
ranIndex = ranIndex % center.size();
double correntDistance = Tools.calcDistance(
toBeProcessed.get(i), center.get(ranIndex), 0);
if (correntDistance < minDistance) {
minDistance = correntDistance;
beyondIndex = ranIndex;
}// 第二个if
ranIndex++;
}// 第二个for
if (!isAlreadyExitInCluster) {
this.arrayCluster.get(beyondIndex).addMembers(
toBeProcessed.get(i));// 把数据对象加入到对应的簇中
}
}// 第一个for
System.out.println("第" + this.count + "次迭代完成。");
printClusteringInfo();
}
(4)迭代过程(产生新的中心点,继续执行聚类过程直至满足终止条件)
publicvoid finishCluster() {
DecimalFormat df = new DecimalFormat("##.000");// 格式化数据,保留三位小数
for (int i = 0; i < NUM; i++) {
double moveDistance = 0.0;// 存放各个簇新旧中心点欧几里得距离之和
// 重新计算簇中心点
for (int j = 0; j < numOfCluster; j++) {
boolean isEmptyCluster = true;
DataItem newCenterItem;// 声明新的中心点对象
int size = this.arrayCluster.get(j).getMembers().size();
double[] newCenterArea = newdouble[NUMOFAREA];
// 计算簇中数据的均值
for (int index = 0; index < NUMOFAREA; index++) {
double tempValue = 0.0;// 暂存每一列区域值的加和
for (int k = 0; k < size; k++) {
isEmptyCluster = false;
tempValue += this.arrayCluster.get(j).getMembers()
.get(k).getAreas()[index];
}
if (!isEmptyCluster) {
newCenterArea[index] = Double.valueOf(df
.format(tempValue / size));
} else
break;
}// 第三个for
if (!isEmptyCluster) {// 如果簇不为空
String name = "cluster" + j;
newCenterItem = new DataItem(name, newCenterArea, false);// 新的簇中心点对象
DataItem oldCenter = this.center.get(j);// 获取旧的簇中心点
moveDistance += Tools.calcDistance(oldCenter,
newCenterItem, 0);// 计算新旧中心点移动的距离
this.center.remove(j);// 更新簇中心点集合
this.center.add(j, newCenterItem);
}
}// 第二个for,重新计算簇中心
// System.out.println(this.center.toString());// 打印新的中心点信息
if (moveDistance < EXIT * numOfCluster) {
break;
}
count++;
initArrayCluster(this.center);
runCluster(this.center);
}// 第一个for
}
3.3 问题与改进
聚类分析要求不同簇之间的距离尽可能大,初始随机选取的中心点并不能保证不同中心点之间的距离尽可能远,本程序对算法进行改进,在随机选取中心点时要求与已经选取的中心点之间的距离大于设定值。这样做保证了随机选取的中心点相对比较分散,提高了聚类效果。主要代码如下:
publicstaticboolean isProCener(DataItem centerItem,// 判断是不是合适的中心点
ArrayList<DataItem> center) {
if (center.size() > 0) {// 如果当前的中心点集合不为空
for (int i = 0; i < center.size(); i++) {
if (Tools.calcDistance(centerItem, center.get(i), 0) < DIFF)
returnfalse;
}
if (center.contains(centerItem))
returnfalse;
}
returntrue;
}
4.开发与运行环境配置
●操作系统:Windows 7
●开发工具:Eclipse
●开发语言:Java
●CPU频率:2.2GHz
●内存:3.5GB
两种运行方式:?解压源程序,将PlantsClustering工程导入Eclipse即可运行;?直接运行打包生成的exe文件。两种方式均要求电脑上安装有JDK1.5或更高版本。
5.程序运行情况分析
5.1 运行截图

图4 指定数据文件并输入聚类簇数
程序运行开始时需要用户指定数据文件的路径,不指定的话默认是D盘根目录下的plants.data.txt文件。之后需要用户输入聚类产生的簇数,簇数介于1到100之间。

图5 迭代过程,输出中心点信息
每次迭代会输出本次迭代的中心点信息。上图是第一次迭代的部分中心点信息(总共有50个中心点)。
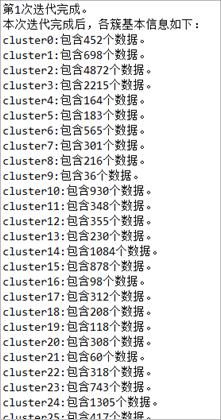
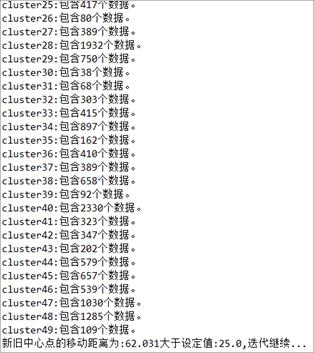
图6 第一次迭代后簇的信息 图7 簇的信息和终止条件的判定
一次迭代完成后会输出本次迭代后各簇的信息并计算新旧中心点的移动距离,与设定的值比较,判定是否继续迭代。
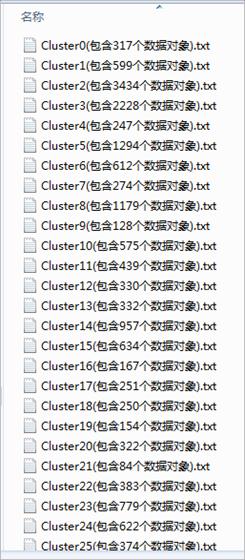
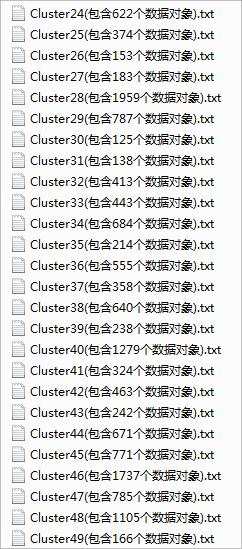
图8 把簇的信息保存到本地
满足终止条件,迭代结束,此时会在D:\DataMining\目录下生成保存各个簇信息的文件,里面是该簇中包含的数据对象。
5.2 聚类效果分析
聚类分析要求得到的簇之间相异度尽可能大,簇内的数据对象相异度尽可能小。本程序会在聚类分析完成后会输出各簇内的平均距离和簇间平均距离,作为对聚类效果评判的参考。如下截图:

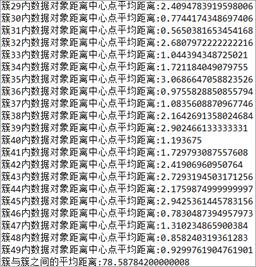
图9 聚类效果
5.3 总结
K均值聚类算法的效果与簇数和初始中心点有关。初始中心点选取应尽可能分散。簇数越多聚类效果越好,但同时程序运行的时间开销也会加大,平衡二者找到一个合适的k是该算法的一个重点。
-
数据挖掘课程设计报告
ID3算法的改进摘要本文基于ID3算法的原有思路再把属性的重要性程度值纳入了属性选择的度量标准中以期获得更适合实际应用的分类划分结…
-
数据挖掘课程设计
本科课程设计及实验期末成绩评估系统的数据仓库和数据挖掘设计课程名称数据挖掘课程编号08060116学生姓名cwl学号20xx052…
-
数据挖掘课程设计报告正文
目录第1章数据挖掘基本理论211数据挖掘的产生212数据挖掘的概念313数据挖掘的步骤3第2章系统分析421系统用户分析422系统…
-
数据挖掘课程设计报告
数据挖掘课程设计报告题目姓名班级学号关联规则挖掘系统xxxxxx计算机0901xxxxxxxxxxx20xx年6月19日1一设计目…
-
数据挖掘聚类算法课程设计报告
数据挖掘聚类问题PlantsDataSet实验报告1数据源描述11数据特征本实验用到的是关于植物信息的数据集其中包含了每一种植物种…
-
数据挖掘课程设计报告正文
目录第1章数据挖掘基本理论211数据挖掘的产生212数据挖掘的概念313数据挖掘的步骤3第2章系统分析421系统用户分析422系统…
-
数据挖掘课程设计报告
ID3算法的改进摘要本文基于ID3算法的原有思路再把属性的重要性程度值纳入了属性选择的度量标准中以期获得更适合实际应用的分类划分结…
-
数据挖掘课程设计
本科课程设计及实验期末成绩评估系统的数据仓库和数据挖掘设计课程名称数据挖掘课程编号08060116学生姓名cwl学号20xx052…
-
数据挖掘课程设计报告
数据挖掘课程设计报告题目姓名班级学号关联规则挖掘系统xxxxxx计算机0901xxxxxxxxxxx20xx年6月19日1一设计目…
-
数据挖掘课程设计报告
一设计目的1更深的了解关联规则挖掘的原理和算法2能将数据挖掘知识与计算机编程相结合编写出合理的程序3深入了解Apriori算法二设…
-
数据挖掘实验报告
数据挖掘实验报告一实验名称有线电视服务销售CampR树二实验目的1学习和了解数据挖掘的基础知识学会使用SPSSClementine…