数据挖掘课程设计报告
ID3算法的改进
摘要:本文基于ID3算法的原有思路,再把属性的重要性程度值纳入了属性选择的度量标准中,以期获得更适合实际应用的分类划分结果。
一、ID3算法的不足
ID3算法使用信息增益作为属性选择度量值,其倾向于选择具有大量值的属性,但没有考虑到属性在实际应用分类中的重要程度,因为依靠取信息熵最大的属性在现实情况中却并不那么重要,因此可能会得到不太有用的划分结果。举个简单的例子,在对淘宝用户行为进行分析时,尽管依据用户ID可以得到最大的信息增益,但是这并不符合分析的要求,因为,我们需要得到的是用户的购买行为,在分析中,我们会更多的考虑用户曾经浏览过的商品或者已经购买了的商品。在这个情景中,根据信息熵来度量属性的选择就不太合理,所以需要对其进行改进。
二、改进思路
本次设计中在属性选择上加入了属性重要程度值:因为采用信息增益的方法会倾向于选择拥有较多可能属性值的属性,为了弥补这一缺陷,所以在选择时就加入了属性的重要程度值。属性重要程度值考虑了属性在分裂数据中所处的地位。在处理数据的时候,会首先根据经验或需要判断出数据集合里面的属性值的重要程度,例如,在上面淘宝用户行为分析中,我们可能会人为的给予属性(“浏览过的商品”)最高重要程度值:0.8,而给属性(“用户ID”)较低的重要程度值:0.2。在明确了属性重要程度值以后,我们会在计算每个属性信息增益后将信息增益与属性重要程度值相乘,由此来判断最终属性的选择。对于ID3算法的其他内容不做更改。
三、具体实现
以课本《数据挖掘》中193页的例6-1为例。例6-1中各属性的重要程度值即权值未知,我们可先分别假设属性age的重要程度值为0.1,属性income的重要程度值为0.6,属性student的重要程度值为0.2,属性credit_rating的重要程度值为0.1。在引入属性重要程度值以前,每个属性的信息增益为:
Gain(age)=0.246 , Gain(income)=0.029 ,
Gain(student)=0.151 , Gain(credit_rating)=0.048。
在引入属性重要程度值以后,信息增益*属性重要程度值分别为:
0.246*0.1=0.0246
0.029*0.6=0.0174
0.151*0.2=0.0302
0.048*0.1=0.0048
此时,决策树的属性分布就会和之前的不同,income属性会成为决策树的根节点。由此可见,属性的重要程度值会对决策属性的选择有着重要影响。
四、改进算法
因为仅仅只是把属性的重要程度值纳入到决策属性的选择中,所以原ID3算法的大部分代码都是一样的,唯一不同的是:改变了makeTree方法的impurityReduce值。在程序中添加了属性重要程度值数组priority,属性对应的重要程度值依次为priority[i],此处为了方便,其值直接采用Math.random()随机生成,然后将其与computeEntropyReduce(data, data.attribute(i))相乘,记得到新的impurityReduce值,从而影响了决策属性的选择。更改代码部分用淡蓝色标记。
private void makeTree(Instances data) throws Exception
{
if (data.numInstances() == 0) //假如没有
{
m_Attribute = null;
m_Instances = new Instances(data);
return;
}
// Compute attribute with maximum split value.
double impurityReduce = 0;
double maxValue = 0;
int maxIndex = -1;
int h=data.numAttributes();
double[] priority=new double[h];
for (int i = 0; i < h; i++)
{
priority[i]=Math.random();
if (i == data.classIndex())
continue;
impurityReduce=computeEntropyReduce(data,data.attribute(i))*priority[i];
if (impurityReduce > maxValue)
{
maxValue = impurityReduce;
maxIndex = i;
}
}
// Make leaf if information gain is zero, otherwise create successors.
if (Utils.eq(maxValue, 0))
{
m_Attribute = null;
m_Instances = new Instances(data);
return;
} else
{
m_Attribute = data.attribute(maxIndex);
Instances[] splitData = splitData(data, m_Attribute);
m_Successors = new MyID3[m_Attribute.numValues()];
for (int j = 0; j < m_Attribute.numValues(); j++)
{
m_Successors[j] = new MyID3();
m_Successors[j].makeTree(splitData[j]);
}
}
}
验证MyID3算法的结果如下图:
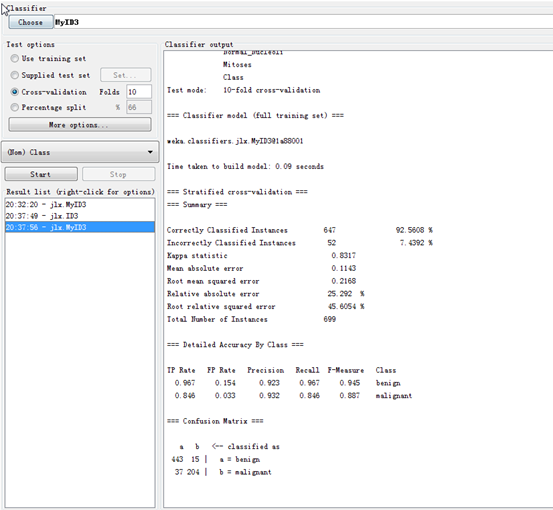
图1 改进后
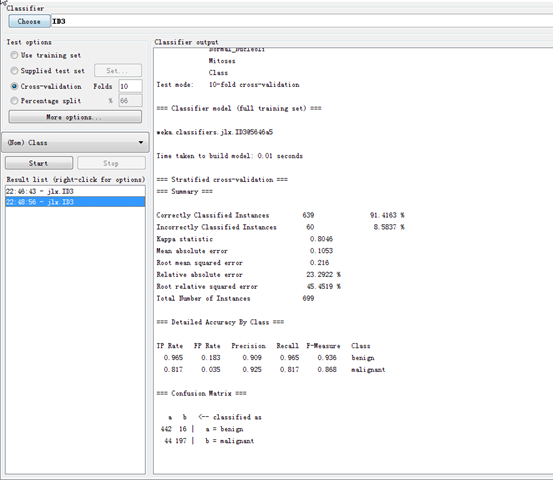
图2 改进前
五、结论
实验证明,将属性的重要程度值纳入属性度量选择的过程中有助于弥补采用信息增益的方法会倾向于选择拥有较多可能属性值的属性这一缺陷,使得属性的选择更加合理,更加贴近实际应用。
第二篇:数据挖掘报告(模板)
第一章:数据挖掘基本理论
数据挖掘的产生:
随着计算机硬件和软件的飞速发展,尤其是数据库技术与应用的日益普及,人们面临着快速扩张的数据海洋, 如何有效利用这一丰富数据海洋的宝藏为人类服务业已成为广大信息技术工作者的所重点关注的焦点之一。与日趋成熟的数据管理技术与软件工具相比,人们所依赖的数据分析工具功能,却无法有效地为决策者提供其决策支持所需要的相关知识,从而形成了一种独特的现象“丰富的数据,贫乏的知识” 。
为有效解决这一问题,自二十世纪90年代开始,数据挖掘技术逐步发展起来,数据挖掘技术的迅速发展,得益于目前全世界所拥有的巨大数据资源以及对将这些数据资源转换为信息和知识资源的巨大需求,对信息和知识的需求来自各行各业,从商业管理、生产控制、市场分析到工程设计、科学探索等。数据挖掘可以视为是数据管理与分析技术的自然进化产物。自六十年代开始,数据库及信息技术就逐步从基本的文件处理系统发展为更复杂功能更强大的数据库系统;七十年代的数据库系统的研究与发展,最终导致了关系数据库系统、数据建模工具、索引与数据组织技术的迅速发展,这时用户获得了更方便灵活的数据存取语言和界面;此外在线事务处理手段的出现也极大地推动了关系数据库技术的应用普及,尤其是在大数据量存储、检索和管理的实际应用领域。
自八十年代中期开始,关系数据库技术被普遍采用,新一轮研究与开发新型与强大的数据库系统悄然兴起,并提出了许多先进的数据模型:扩展关系模型、面向对象模型、演绎模型等;以及应用数据库系统:空间数据库、时序数据库、多媒体数据库等;日前异构数据库系统和基于互联网的全球信息系统也已开始出现并在信息工业中开始扮演重要角色。

被收集并存储在众多数据库中且正在快速增长的庞大数据,已远远超过人类的处理和分析理解能力 (在不借助功能强大的工具情况下) , 这样存储在数据库中的数据就成为“数据坟墓” ,即这些数据极少被访问,结果许多重要的决策不是基于这些基础数据而是依赖决策者的直觉而制定的,其中的原因很简单,这些决策的制定者没有合适的工具帮助其从数据中抽取出所需的信息知识。而数据挖掘工具可以帮助从大量数据中发现所存在的特定模式规律,从而可以为商业活动、科学探索和医学研究等诸多领域提供所必需的信息知识。数据与信息知识之间的巨大差距迫切需要系统地开发数据挖掘工具,来帮助实现将“数据坟墓”中的数据转化为知识财富。
数据挖掘的概念:
数据挖掘,在人工智能领域,习惯上又称为数据库中知识发现(Knowledge Discovery in Database, KDD), 也有人把数据挖掘视为数据库中知识发现过程的一个基本步骤。知识发现过程以下三个阶段组成:(1)数据准备,(2)数据挖掘,(3)结果表达和解释。数据挖掘可以与用户或知识库交互。
并非所有的信息发现任务都被视为数据挖掘。例如,使用数据库管理系统查找个别的记录,或通过因特网的搜索引擎查找特定的Web页面,则是信息检索(information retrieval)领域的任务。虽然这些任务是重要的,可能涉及使用复杂的算法和数据结构,但是它们主要依赖传统的计算机科学技术和数据的明显特征来创建索引结构,从而有效地组织和检索信息。尽管如此,数据挖掘技术也已用来增强信息检索系统的能力。
数据挖掘的步骤:
1.确定挖掘对象:定义清晰的挖掘对象,认清数据挖掘的目标是数据挖掘的第一步。数据挖掘的最后结果往往是不可预测的,但是要解决的问题应该是有预见性的、有目标的。在数据挖掘的第一步中,有时还需要用户提供一些先验知识。这些先验知识可能是用户的业务领域知识或是以前数据挖掘所得到的初步成果。这就意味着数据挖掘是一个过程,在挖掘过程中可能会提出新的问题;可能会尝试用其他的方法来检验数据,在数据的子集上展开研究。
2.数据收集:数据是挖掘知识最原始的资料。“垃圾进,垃圾出”,只有从正确的数据中才能挖掘到有用的知识。为特定问题选择数据需要领域专家参加。因此,领域问题的数据收集好之后,和目标信息相关的属性也选择好了。
3.数据预处理:数据选择好以后,就需要对数据进行预处理。数据预处理包括:去除错误数据和数据转换。错误数据,在统计学中称为异常值,应该在此阶段发现并且删除。否则,它们将导致产生错误的挖掘结果。同时,需要将数据转换成合适的形式。例如,在某些情况下,将数据转换成向量形式。另外,为了寻找更多重要的特征和减少数据挖掘步骤的负担,我们可以将数据从一个高维空间转换到一个低维空间。
4.数据挖掘:数据挖掘步骤主要是根据数据建立模型。我们可以在这个步骤使用各种数据挖掘算法和技术。然而,对于特定的任务,需要选择正确合适的算法,来解决相应的问题。
5.信息解释:首先,通过数据挖掘技术发现的知识需要专家对其进行解释,帮助解决实际问题。然后,根据可用性、正确性、可理解性等评价指标对解释的结果进行评估。只有经过这一步骤的过滤,数据挖掘的结果才能够被应用于实践。
6.可视化:可视化技术主要用来通过图形化的方式显示数据和数据挖掘的结果,从而帮助用户更好的发现隐藏在数据之后的知识。它可以被应用在数据挖掘的整个过程,包括数据预处理、数据挖掘和信息解释。数据和信息的可视化显示对用户来说非常重要,因为它能够增强可理解性和可用性。
第二章:系统分析
系统用户分析:
系统功能分析:
系统算法分析:
第三章:数据管理
数据管理的方法:
数据管理的具体实现:
第四章:数据采集
数据采集的方法
数据收集:数据是挖掘知识最原始的资料。“垃圾进,垃圾出”,只有从正确的数据中才能挖掘到有用的知识。为特定问题选择数据需要领域专家参加。因此,领域问题的数据收集好之后,和目标信息相关的属性也选择好了。
数据采集的具体实现过程
第五章:数据预处理
数据预处理的方法:
数据预处理:数据选择好以后,就需要对数据进行预处理。数据预处理包括:去除错误数据和数据转换。错误数据,在统计学中称为异常值,应该在此阶段发现并且删除。否则,它们将导致产生错误的挖掘结果。同时,需要将数据转换成合适的形式。例如,在某些情况下,将数据转换成向量形式。另外,为了寻找更多重要的特征和减少数据挖掘步骤的负担,我们可以将数据从一个高维空间转换到一个低维空间。
数据预处理的具体实现过程:
第六章:数据挖掘
算法描述与流程图
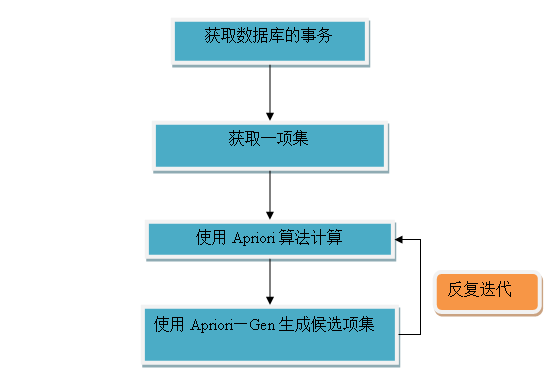
数据结构的设计
算法的具体实现
Apriori算法:
static List<ItemSet> Apriori(ArrayList D, ArrayList I, float sup)//传进的参数D为事务数据集,I为频繁一项集,sup为支持度阈值
{
List<ItemSet> L = new List<ItemSet>();//所有频繁项集
if (I.Count == 0) return L;
else
{
int[] Icount = new int[I.Count];//初始项集计数器,初始化为0
ArrayList Ifrequent = new ArrayList();//初始项集中的频繁项集
//遍历事务数据集,对项集进行计数
Regex r = new Regex(",");//正则表达式
for (int i = 0; i < D.Count; i++)
{
string[] subD = r.Split(D[i].ToString());
for (int j = 0; j < I.Count; j++)
{
string[] subI = r.Split(I[j].ToString());
bool subIInsubD = true;
for (int m = 0; m < subI.Length; m++)//频繁项集
{
bool subImInsubD = false;
for (int n = 0; n < subD.Length; n++)//事物数据集
if (subI[m] == subD[n])
{
subImInsubD = true;
continue;
}
if (subImInsubD == false) subIInsubD = false;
}
if (subIInsubD == true)
{
//int s = Icount[j];
Icount[j]++;//支持频度+1
//int t = Icount[j];
//float confi = s / t;
//ItemSet.confi = confi;
}
}
}
//从初始项集中将支持度大于给定值的项转到L中
for (int i = 0; i < Icount.Length; i++)
{
if (Icount[i] >= sup * D.Count)//判断支持度是否大于给定值,并且置信度大于给定值&&ItemSet.confi>=ItemSet.confidence*0.01
{
Ifrequent.Add(I[i]);
ItemSet iSet = new ItemSet();
iSet.Items = I[i].ToString();
iSet.Sup = Icount[i];
L.Add(iSet);
}
}
I.Clear();
I = AprioriGen(Ifrequent);//将频繁项集作为参数传给AprioriGen生成新的候选项集
L.AddRange(Apriori(D, I, sup));
return L;
}
}
Apriori—Gen方法:
static ArrayList AprioriGen(ArrayList L)
{
ArrayList Lk = new ArrayList();
Regex r = new Regex(",");
for (int i = 0; i < L.Count; i++)
{
string[] subL1 = r.Split(L[i].ToString());
for (int j = i + 1; j < L.Count; j++)
{
string[] subL2 = r.Split(L[j].ToString());
//比较L中的两个项集将它们的并集暂存于temp中
string temp = L[j].ToString();//存储两个项集的并集
for (int m = 0; m < subL1.Length; m++)
{
bool subL1mInsubL2 = false;
for (int n = 0; n < subL2.Length; n++)
{
if (subL1[m] == subL2[n]) subL1mInsubL2 = true;
}
if (subL1mInsubL2 == false) temp = temp + "," + subL1[m];
}
//当temp包含的项为(L中项集的大小)+1并且所求候选项集中没有与temp一样的项集
string[] subTemp = r.Split(temp);
if (subTemp.Length == subL1.Length + 1)
{
bool isExists = false;
for (int m = 0; m < Lk.Count; m++)
{
bool isContained = true;
for (int n = 0; n < subTemp.Length; n++)
{
if (!Lk[m].ToString().Contains(subTemp[n])) isContained = false;
}
if (isContained == true) isExists = true;
}
if (isExists == false) Lk.Add(temp);
}
}
}
return Lk;
}
第七章:结果显示与解释评估
参数设置:
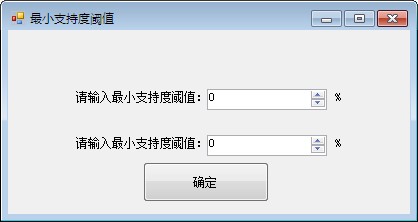
在程序开始计算之前,需要输入两个参数:最小支持度阈值与最小置信度阈值。
结果显示界面的具体实现
程序用一个C#里边的DataGridView显示,一个有两栏,左边的项集是生成的项集,右边的支持频度指的是该项集的出现的次数。
解释评估
学习体会
通过两周的软件开发综合训练,做了这个数据挖掘的题目,对数据挖掘有了生加深了的认识,因此认识到了数据挖掘的重要性,它很大程度的帮助人们把从大量的无序的数据中获得知识,指导人们做出决策。在这次数据挖掘的过程中,我做的是用Apriori算法对超市的销售记录进行数据挖掘。从而找出符合置信度阈值与支持度阈值的商品的项集。在编程的过程中,我也遇到过一些问题,通过对这些问题的解决,我发现自己的编程能力也有了一定的提高。
参考文献
[1].数据挖掘概念与技术,范明,孟小峰 译/20##年03月/机械工业出版社.
[2].数据挖掘原理与算法(第二版)毛国君等编著/20##年12月/清华大学出版社.
致谢
在这次课程设计中,得到了 孙士保、白秀玲、魏汪洋、赵海霞四位老师的耐心指导,帮助我解决了知识上的难题,教会我了很多的东西,再次,诚挚的感谢诸位老师,谢谢你们!
-
数据挖掘课程设计报告
ID3算法的改进摘要本文基于ID3算法的原有思路再把属性的重要性程度值纳入了属性选择的度量标准中以期获得更适合实际应用的分类划分结…
-
数据挖掘课程设计
本科课程设计及实验期末成绩评估系统的数据仓库和数据挖掘设计课程名称数据挖掘课程编号08060116学生姓名cwl学号20xx052…
-
数据挖掘课程设计报告正文
目录第1章数据挖掘基本理论211数据挖掘的产生212数据挖掘的概念313数据挖掘的步骤3第2章系统分析421系统用户分析422系统…
-
数据挖掘课程设计报告
数据挖掘课程设计报告题目姓名班级学号关联规则挖掘系统xxxxxx计算机0901xxxxxxxxxxx20xx年6月19日1一设计目…
-
数据挖掘聚类算法课程设计报告
数据挖掘聚类问题PlantsDataSet实验报告1数据源描述11数据特征本实验用到的是关于植物信息的数据集其中包含了每一种植物种…
-
数据挖掘课程设计报告正文
目录第1章数据挖掘基本理论211数据挖掘的产生212数据挖掘的概念313数据挖掘的步骤3第2章系统分析421系统用户分析422系统…
-
数据挖掘课程设计
本科课程设计及实验期末成绩评估系统的数据仓库和数据挖掘设计课程名称数据挖掘课程编号08060116学生姓名cwl学号20xx052…
-
数据挖掘课程设计报告
数据挖掘课程设计报告题目姓名班级学号关联规则挖掘系统xxxxxx计算机0901xxxxxxxxxxx20xx年6月19日1一设计目…
-
数据挖掘课程设计报告
一设计目的1更深的了解关联规则挖掘的原理和算法2能将数据挖掘知识与计算机编程相结合编写出合理的程序3深入了解Apriori算法二设…
-
数据挖掘聚类算法课程设计报告
数据挖掘聚类问题PlantsDataSet实验报告1数据源描述11数据特征本实验用到的是关于植物信息的数据集其中包含了每一种植物种…
-
数据挖掘实验报告
数据挖掘实验报告一实验名称有线电视服务销售CampR树二实验目的1学习和了解数据挖掘的基础知识学会使用SPSSClementine…