商务智能与数据挖掘
管理学院实验(实训)报告
课程: 商务智能与数据挖掘
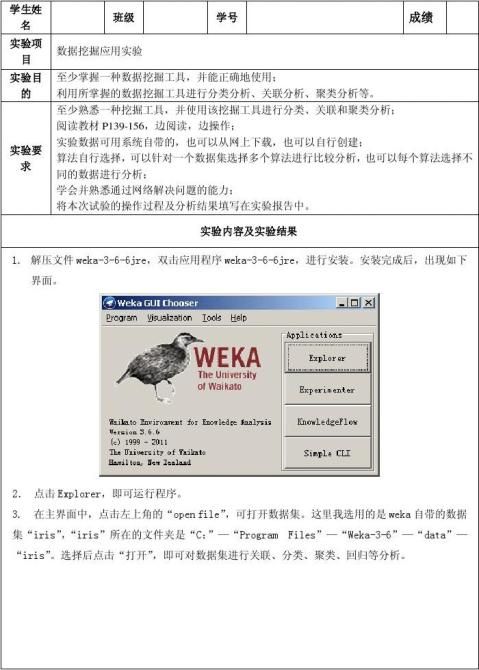
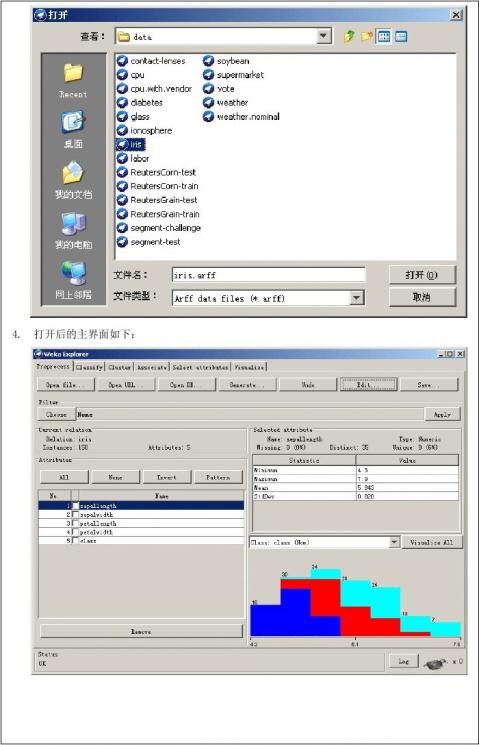
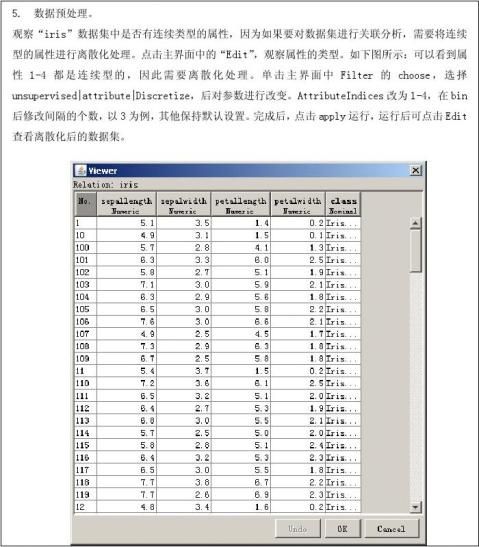
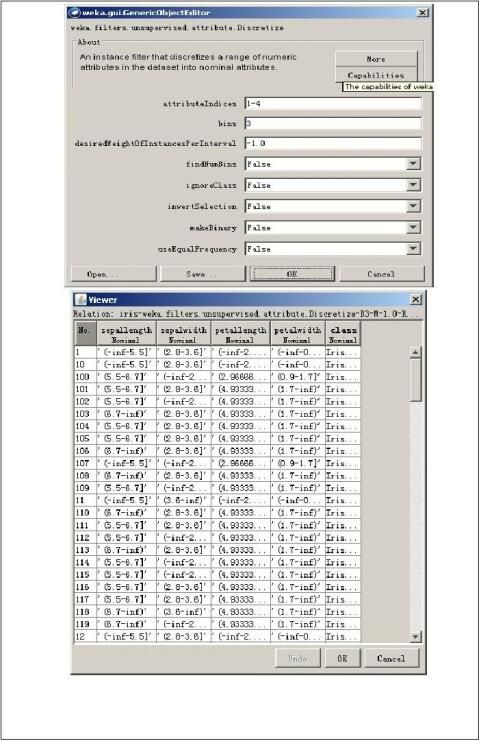
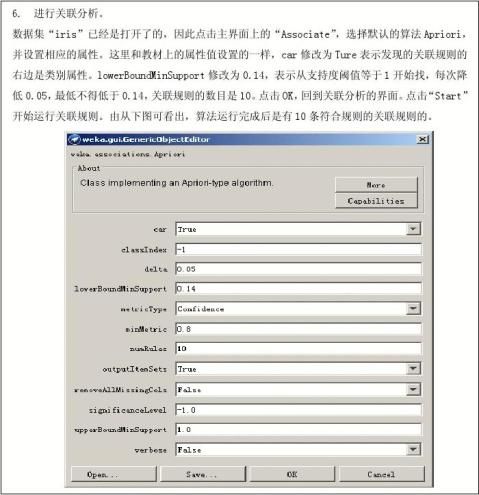
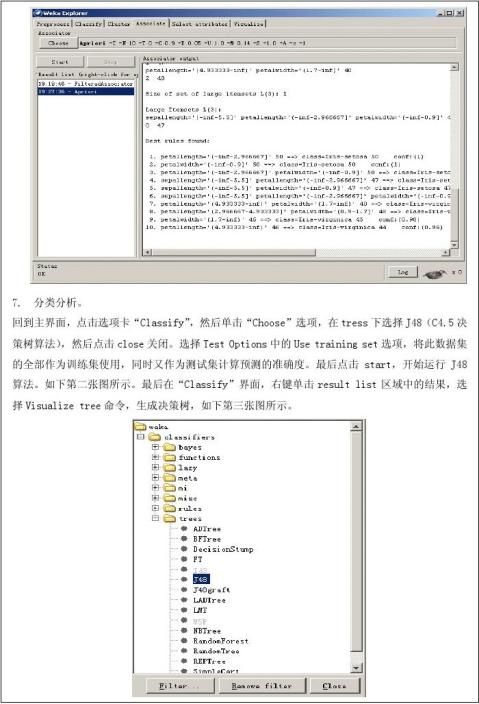
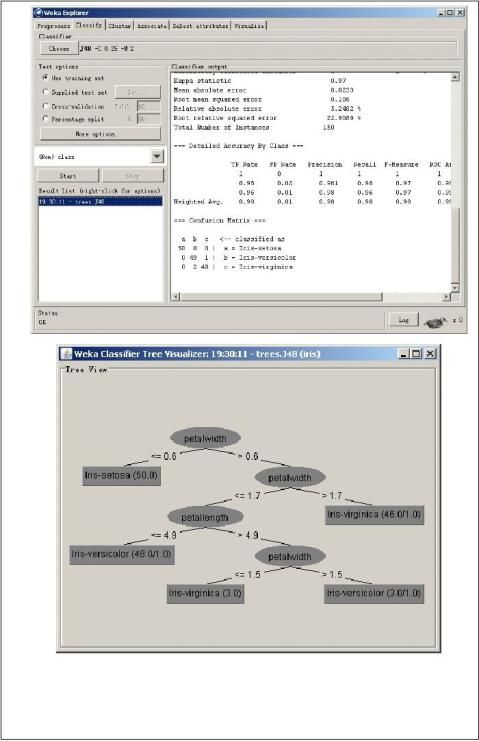
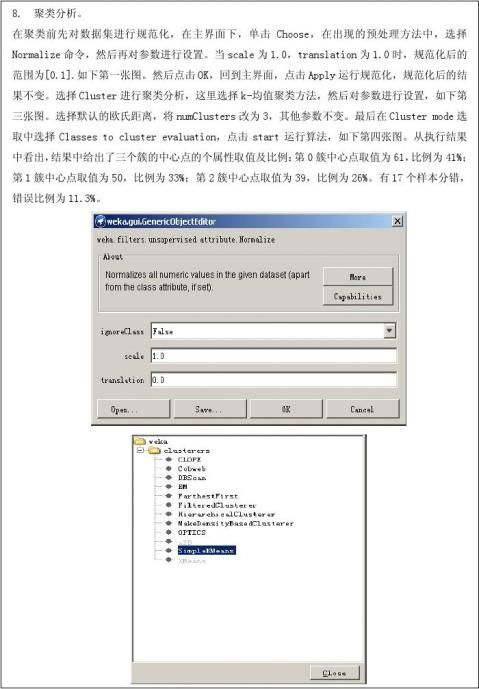
第二篇:数据挖掘与商务智能总结
第一章 绪论
什么是数据挖掘,什么是商业智能
从大型数据库中提取有趣的 (非平凡的、蕴涵的、先前未知的且是潜在有用的) 信息或模式。
商业智能是要在必须的时间段内,把正确有用的信息传递给适当的决策者,以便为有效决策提供信息支持。
分类算法的评价标准
召回率recall =系统检索到的相关文件数/相关文件总数
准确率precision(查准率)= 系统检索到的相关文件数/系统返回的文件总数
第二章 数据仓库
什么是数据仓库
是运用新信息科技所提供的大量数据存储、分析能力,将以往无法深入整理分析的客户数据建立成为一个强大的顾客关系管理系统,以协助企业制定精准的运营决策。
数据仓库的基本特征
1面向主题2整合性 3长期性 4稳定性
第三章 数据挖掘简介
数据挖掘的一般功能
1分类 2估计3 预测 4关联分类 5聚类
数据挖掘的完整步骤
1理解数据与数据所代表的含义
2获取相关知识与技术
3整合与检查数据
4取出错误或不一致的数据
5建模与假设
6数据挖掘运行
7测试与验证所挖掘的数据
8解释与使用数据
数据挖掘建模的标准 CRISP-CM
跨行业数据挖掘的标准化过程
第四章 数据挖掘中的主要方法
基于SQL Server 2005 SSAS的十种数据挖掘算法是什么
1.决策树 2.聚类 3.Bayes分类 4.有序规则 5. 关联规则 6.神经网络 7.线性回归 8. Logistic回归 9. 时间序列 10. 文本挖掘
第五章 数据挖掘与相关领域的关系
数据挖掘与机器学习、统计分析之间的区别与联系(再看看书 整理下) 32页
处理大量实际数据更具优势,并且使用数据挖掘工具无需具备专业的统计学背景。
数据分析的需求和趋势已经被许多大型数据库所实现,并且可以进行企业级别的
数据挖掘应用。
相对于重视理论和方法的统计学而言,数据挖掘更强调应用,毕竟数据挖掘目的是方便企业用户的使用。
第六章 SQL Server 2005中的商业智能
商业智能(BI)的核心技术是什么
数据仓库和数据挖掘
第七章 SQL Server 2005中的数据挖掘
Microsoft SQL Server Management Studio提供了两个用于管理数据库项目(如脚本、查询、数据连接和文件)的容器是什么?
1项目 2解决方案
第八章 SQL Server 2005的分析服务
什么是UDM?
统一维度模型
第九章 SQL Server 2005的报表服务
什么是报表服务,其功能
是一个基于服务器的完整平台,可创建、管理和交付传统报表和交互式报表。 1制作报表 2管理报表 3提交报表
第十章 决策树模型
什么是决策树?
是数据挖掘的一项主要分析工具。
(决策树能从一个或多个预测变量中,针对类别因变量的选项,预测出个例的趋势变化关系等。也可以由结果来反推原因。)
SQL Server 2005决策树算法步骤
第十一章 贝叶斯分类
什么是简单贝叶斯分类器
是简单又使用的分类方法。
SQL Server 2005贝叶斯分类算法步骤
第十二章 关联规则
什么是关联规则可解决哪些问题?
是分析发现数据库中不同变量或个体间(例如商品间的关系及年龄与购买行为?)之间关系程度,并用这些规则找出顾客购买行为模式,如购买了台式计算机外设产品(打印机、音箱、硬盘?)的相关影响。发现这样的规则可以应用于商品货架摆设、库存安排以及根据购买行为模式对客户进行分类。
兴趣度指标的意义
当兴趣度指标大于1的时候,这条规则就是比较好的;当兴趣度小于1的时候,这条规则就是没有很大意义的。兴趣度越大,规则的实际意义就越好。 SQL Server 2005关联规则算法步骤
第十三章 聚类分析
什么是聚类分析
聚类分析的思想与判断分析类似,同样是由样本分组,寻找到多维数据点中的差异之处。不同的地方有两点:(1)聚类分析的分类方式并不需要预先指定一个指针变量;(2)聚类分析属于一种非参数分析方法,所以并没有非常严谨的数理依据,也无需假设总体为正态分布。
在聚类方法中定量地描述研究对象之间的相近程度的指标
两个 1相似系数 2 距离(用的比较多)
聚类分析中“类”的具有什么特征(判断)
– 聚类所说的类不是事先给定的,而是根据数据的相似性和距离来划分 – 聚类的数目和结构都没有事先假定
聚类分析方法的分类
1基于层次的方法 2基于划分的方法
k-means(K均值聚类)属于哪种聚类
划分聚类的方法
欧式距离的计算
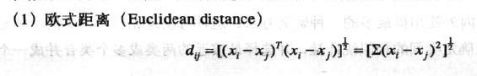
聚类的原则是最大化类内的相似性,最小化类间的相似性(选择)
SQL Server 2005聚类分析算法步骤
第十四章 时序聚类分析
序列聚类与关联规则挖掘区别是什么?
? Sequence Clustering:在找出先后发生事物的关系,重点在于分析数据
间先后序列关系。
? Association则是找出某一事件或资料中会同时出现的状态,例如项目A
是某事件的一部份,则项目B也出现在该事件中的机率有a %。
序列模式解决什么问题?
时序聚类算法用于根据某一顺序对数据分组。
? 例如,Web应用程序的用户经常按照各种路径浏览网站。此算法可以根
据浏览站点的页面顺序对用户进行分组,以帮助分析消费者并确定是否某个路径比其他路径具有更高的收益。
? 此算法还可以用于预测,例如预测用户可能访问的下一个页面。利用顾客
购买的时间间隔序列数据可以分析顾客的购买物和时间的相关性,有相同或类似行为的顾客会被分在相同的聚娄中,这样的分析不但可以包含物品购买的相关也包含了在时间上对购买物的关联性。因此若能针对这样的数据聚类,在应用上会更加灵活。
包含时间间间隔的有序序列的数值数据和定性数据相似度计算方法
1事件共同发生种类相似度 2事件发生周期相似度 3基于相同子序列长度的相
似度
SQL Server 2005时序聚类分析算法步骤
第十五章 线性回归模型
什么是线性回归
回归分析是以一个或多个自变量描述、预测或控制特定因变量的分析。
回归分析主要在了解自变量与因变量间的数量关系。主要目的:了解自变量与因变量关系方向及强度。 以自变量所建立模式对固变量作预测。
回归分析根据自变量个数的不同可以分为: 简单回归分析。 多元回归分析。回归分析中变量的筛选原则: 相关理论或逻辑。 研究人员探讨变量关系来决定。
什么是多元回归分析

多元回归:回归分析中自变量的数量有多个
选择回归变量的常用方法
1所有可能回归法 2向前选择法 3向后淘汰法 4逐步回归法
SQL Server 2005线性回归分析算法步骤
第十六章 罗吉斯回归模型
什么是罗吉斯回归
Logistic回归模型在分析二分类或有序因变量与解释变量的关系。
SQL Server 2005罗吉斯回归分析算法步骤
第十七章 神经网络模型
什么是人工神经网络
ANN 就是Artificial Neural Networks, 意思是人工神经网络。人工神经网络理论是用神经元这种抽象的数学模型来描述客观世界的生物细胞的。 在数据挖掘中能够得到应用。
神经网络的能力特征
1非线性 2非局域性 3非定常性 4非凸性
神经网络的算法
1单层知觉网络 2多层知觉网络

SQL Server 2005神经网络模型步骤
第十八章 时间序列模型
时间序列分析的目的
1对时间序列未来趋势作预测
2将时间序列分解成主要趋势成分、季节变化成分。
3检验理论模型是否能正确反映现象。
时间序列的特点
时间序列由四个影响成分所组成,分别是长期趋势(Trend),循环
变动(Cyclical Fluctuation),季节变动(Seasonal Fluctuation)、
不规则变动(Irregular Fluctuation)。因此进行时间序列时应先
将此四个成分分解出来,以了解各个成分的影响。
时间序列的各观测值通常自相关,且时间相隔越长,相关程度越小。
时间序列的时间单位可以年、季、月、周、日等,应划分为相同间
隔的时间单位。不同时间单位的时间序列可转换成相同时间单位的
时间序列。
时间序列应依时间顺序排列,不可任意变更。
时间序列分析前,须将数据按时间次序以纵轴为变量,横轴为时间
作图,即时间序列图。
在利用SQL SERVER 2005进行数据挖掘时,数据挖掘的任务中,什么可以没有输入
时间序列模型可以不用输入
时间序列的四个成分
趋势成分 循环成分 季节成分 随即成分
常见的时序预测方法
平滑法 回归模型 趋势投影
SQL Server 2005时间序列模型步骤
第十九章 SQL Server 2005整合服务
什么是SSIS
SQL server整合服务
SSIS designer几个重要部分
数据流 控制流程 控件
如何理解控制流与数据流分开
答 在SQL server中实验中数据与操作是分开的,数据流与控制流有各自的组建。 第二十章 文本挖掘模型
文本挖掘的数据预处理技术(文本分析技术)有哪些
三个:分词技术 特征表示 特征提取
文本分析处理的数据类型
结构化数据 和 非结构化数据
常用的文本挖掘技术有哪些
文本分类 文本聚类 自动摘要 关联分析 可视化。
第二十一章 SQL Server 2005的DMX语言
DMX全称
Data mining Extension
DMX是SQL Server用于建立和操作数据挖掘模型的语言,其组成有哪些 由数据定义语言、数据操作语言以及函数和运算子等组成。
- 数据仓库与数据挖掘实验报告3
-
数据仓库与数据挖掘 实验报告册
信息工程实验室实验报告册数据仓库与数据挖掘实验报告册2020学年第学期班级学号姓名授课教师杨丽华实验教师杨丽华实验学时16实验组号…
-
方1052-数据仓库与数据挖掘 实验报告
石家庄铁道大学四方学院学生实验报告书实验课程名称数据仓库与数据挖掘学生专业班级方1052信管学生学号学生姓名指导老师姓名刘桂贤20…
-
数据仓库与数据挖掘实验报告
数据仓库与数据挖掘课程APRIORI算法学习一简介Apriori算法是一种挖掘关联规则的频繁项集算法其核心思想是通过候选集生成和情…
- 数据仓库与数据挖掘实验一
-
儿科护士工作总结
新年的钟声即将敲响,20xx年的工作也将接近尾声。回顾一年来的工作,紧张中伴随着充实,忙碌中伴随着坚强,团结中伴随喜悦。在院领导、…
-
抗旱服务队工作总结
***抗旱服务工作总结20xx年x月x日***抗旱服务队成立于??年,几年来在上级有关部门的关心、支持,在局党组的领导和全体职工的…
-
赠书活动的总结
赠书活动的总结20xx年x月,正值雷锋月,我们理学院青年志愿者服务团成功地举行了一次“学长的火炬”赠书活动。在全团成员的努力下,我…
-
最近0年医院主管护师年终总结
20xx年医院主管护师年终总结20xx年医院主管护师年终总结:光阴似箭,日月如梭。作为一名光荣的白衣天使,我特别注重自己的廉洁自律…
-
绥德县吉镇中学“三爱、三节”活动总结--20xx.4.9
吉镇中学20xx--20xx学年度第二学期信息(第17期)绥德县吉镇中学“爱学习、爱劳动、爱祖国”系列教育活动总结根据市、县转发《…